

Index nested documents in Solr
Overview
In Solr, nested documents are regular documents that were indexed as part of another (parent) document. For example, multiple comments related to the same blog post can be stored in Solr as nested documents within one post document. Below is a sample document that models such parent-child relationships:
[
{
"post_id":"blog_post0001",
"nodeType":"post",
"comments":[
{
"comment_id":"comment_1",
"nodeType":"comment",
"content":"foo bar"
},
{
"comment_id":"comment_2",
"nodeType":"comment",
"content":"buzz"
}
]
}, {
"post_id":"blog_post0002",
"nodeType":"post",
"comments":[
{
"comment_id":"comment_3",
"nodeType":"comment",
"content":"Some text"
}
]
}
]Nesting documents may yield much faster queries since the parent-child relationships between the documents are already stored in the index and do not have to be computed at the query time. However, nested documents are less flexible than query-time joins since they impose strict rules that may be sometimes unacceptable for applications.
Nested documents can be indexed as XML, JSON, or SolrJ data formats.
Regardless of the input format, each document must contain a field that identifies the document as either a parent or child.
This field can have any name except for reserved field names defined in the schema.
In the example above, it is the nodeType field that serves this purpose — the field carries either post or comment values.
When searching for nested objects, this field is used as an input for the block join query parsers.
Schema configuration
Working with nested documents requires your schema to have an indexed field named _root_ that looks as follows:
<field name="_root_" type="string" indexed="true" stored="false" docValues="false" />Also, for proper operation of the child document transformer, your schema file must have the _nest_path_ field, which is shown below:
<fieldType name="_nest_path_" class="solr.NestPathField" />
<field name="_nest_path_" type="_nest_path_" />By default, these fields are present in the default schema file and will be inherited by schemas created from the default one.
Anonymous nested documents
Sometimes you may encounter the following syntax for nesting anonymous documents:
[
{
"post_id":"blog_post0001",
"nodeType":"post",
"_childDocuments_":[
{
"comment_id":"comment_1",
"nodeType":"comment",
"content":"foo bar"
},
{
"comment_id":"comment_2",
"nodeType":"comment",
"content":"buzz"
}
]
}
]Notice the _childDocuments_ field holding an array of documents.
This is an explicit indication to Solr that the array carries children elements.
This approach was common in older versions of Solr and now is deprecated.
However, it still works with single-level nested documents that do not contain any other nested fields apart from _root_.
Index nested documents
The following steps show how to index a Solr document with nested children.
-
Open Solr Admin UI. The up-to-date web UI link is available in ADCM (Clusters → <clusterName> → Services → Solr → Info).
-
Go to the Collections page and create a test collection with the following parameters.
Parameter Description name
posts
config set
_default
* This inherits the default schema configuration with basic features to work with nested documents
numShards
1
replicationFactor
1
-
Select the newly created collection and open the collection’s Documents page, as shown in the image.
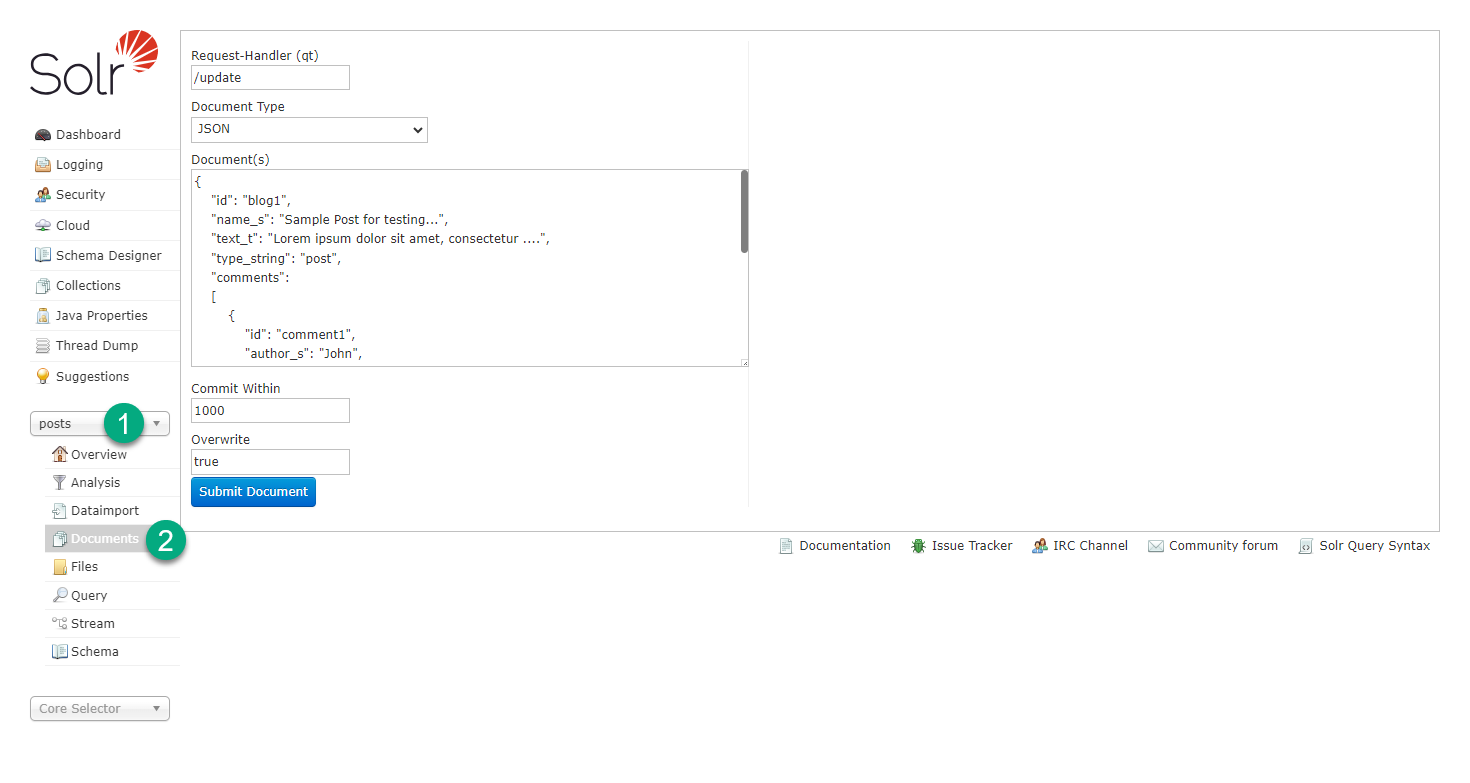 Documents page
Documents page Documents page
Documents page -
Upload the following test documents to Solr by pasting their content into the Document(s) field and clicking Submit Document.
post1.json{ "id": "post1", "name_s": "Sample Post for testing...", "text_t": "Lorem ipsum dolor sit amet, consectetur ....", "content_type": "post", "comments": [ { "id": "comment1", "author_s": "John", "text_t": "Nice post!", "rated_i": 5, "content_type": "comment" }, { "id": "comment2", "author_s": "Ann", "text_t": "Not interesting post...", "rated_i": 3, "content_type": "comment" } ] }post2.json{ "id": "post2", "name_s": "Another demo post...", "text_t": "Foo Bar Buzz ....", "content_type": "post", "comments": [ { "id": "comment3", "author_s": "Luke", "text_t": "I like this post!", "rated_i": 4, "content_type": "comment" } ] }NOTEDo not use the Post tool for uploading nested documents since the tool automatically flattens their JSON structure during the upload.As an alternative to the UI, you can use curl to upload the sample documents to Solr. An example command is below.
curl upload command$ curl -X POST -H 'Content-Type: application/json' 'http://ka-adh-1.ru-central1.internal:8983/solr/posts/update' --data-binary '[ { "id": "blog1", "name_s": "Sample Post for testing...", "text_t": "Lorem ipsum dolor sit amet, consectetur ....", "comments": [ { "id": "comment1", "author_s": "John", "text_t": "Nice post!", "rated_i": 5 }, { "id": "comment2", "author_s": "Ann", "text_t": "Not interesting post...", "rated_i": 3 } ] }, { "id": "blog2", "name_s": "Another demo post...", "text_t": "Foo Bar Buzz ....", "comments": [ { "id": "comment3", "author_s": "Luke", "text_t": "I like this post!", "rated_i": 4 } ] } ]' -
Go to the collection’s Query page and click Execute Query with default parameters to retrieve all documents from the index. The response from Solr looks as follows:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"*:*",
"indent":"true",
"q.op":"OR",
"_":"1724336874767"}},
"response":{"numFound":5,"start":0,"numFoundExact":true,"docs":[
{
"id":"comment1",
"author_s":"John",
"text_t":"Nice post!",
"rated_i":5,
"content_type":["comment"],
"_version_":1808098244634345472},
{
"id":"comment2",
"author_s":"Ann",
"text_t":"Not interesting post...",
"rated_i":3,
"content_type":["comment"],
"_version_":1808098244634345472},
{
"id":"post1",
"name_s":"Sample Post for testing...",
"text_t":"Lorem ipsum dolor sit amet, consectetur ....",
"content_type":["post"],
"_version_":1808098244634345472},
{
"id":"comment3",
"author_s":"Luke",
"text_t":"I like this post!",
"rated_i":4,
"content_type":["comment"],
"_version_":1808098259769491456},
{
"id":"post2",
"name_s":"Another demo post...",
"text_t":"Foo Bar Buzz ....",
"content_type":["post"],
"_version_":1808098259769491456}]
}}Notice that the documents are returned as a flat structure, with children documents piled upon the parent ones — this is the way Solr stores nested objects internally.
Search nested data
By default, documents that match a search query do not include nested children in the response.
For example, submit a search request using the q=id:post1 query string.
The request URL looks as follows:
http://ka-adh-1.ru-central1.internal:8983/solr/posts/select?indent=true&q.op=OR&q=id%3Apost1The response contains a single document without descendants:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"id:post1",
"indent":"true",
"q.op":"OR",
"_":"1724336874767"}},
"response":{"numFound":1,"start":0,"numFoundExact":true,"docs":[
{
"id":"post1",
"name_s":"Sample Post for testing...",
"text_t":"Lorem ipsum dolor sit amet, consectetur ....",
"content_type":["post"],
"_version_":1808098244634345472}]
}}Child document transformer
To add a document’s children to the response, use the child document transformer.
The following request includes the fl=*,[child] parameter that tells Solr to return all the document fields and additionally all the document’s children.
Sample request URL:
http://ka-adh-1.ru-central1.internal:8983/solr/posts/select?fl=*%2C%5Bchild%5D&indent=true&q.op=OR&q=id%3Apost1The response:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"id:post1",
"indent":"true",
"fl":"*,[child]",
"q.op":"OR",
"_":"1724336874767"}},
"response":{"numFound":1,"start":0,"numFoundExact":true,"docs":[
{
"id":"post1",
"name_s":"Sample Post for testing...",
"text_t":"Lorem ipsum dolor sit amet, consectetur ....",
"content_type":["post"],
"_version_":1808098244634345472,
"comments":[
{
"id":"comment1",
"author_s":"John",
"text_t":"Nice post!",
"rated_i":5,
"content_type":["comment"],
"_version_":1808098244634345472},
{
"id":"comment2",
"author_s":"Ann",
"text_t":"Not interesting post...",
"rated_i":3,
"content_type":["comment"],
"_version_":1808098244634345472}]}]
}}Block join query parsers
There are two block join query parsers that allow indexing and searching for relational content that has been indexed as nested documents. These parsers are:
-
Block join children query parser. Used to get the children of an object matched by a query.
-
Block join parent parser. Matches one or more child documents and returns their parent.
The following search query engages the block join children query parser:
q={!child of="content_type:post"}text_t:"Lorem"Solr interprets this query string as follows:
-
Find all documents whose
text_tfield contains theLoremstring. -
Get children of all the matched documents and add them to the response.
Notice the of="content_type:post" part which is a Block Mask.
It tells Solr that parent objects are those objects whose content_type value is post.
The request URL for such a query looks as follows:
http://ka-adh-1.ru-central1.internal:8983/solr/posts/select?indent=true&q.op=OR&q=q%3D%7B!child%20of%3D%22content_type%3Apost%22%7Dtext_t%3A%22Lorem%22The sample response:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"q={!child of=\"content_type:post\"}text_t:\"Lorem\"",
"indent":"true",
"q.op":"OR",
"_":"1724274693355"}},
"response":{"numFound":2,"start":0,"numFoundExact":true,"docs":[
{
"id":"comment1",
"author_s":"John",
"text_t":"Nice post!",
"rated_i":5,
"content_type":["comment"],
"_version_":1808018337579401216},
{
"id":"comment2",
"author_s":"Ann",
"text_t":"Not interesting post...",
"rated_i":3,
"content_type":["comment"],
"_version_":1808018337579401216}]
}}The following search query engages the block join parent query parser:
q={!parent which="content_type:post"}author_s:JohnSolr interprets this query string as follows:
-
Find documents whose
author_sfield isJohn. -
Get the ancestor of the matched document and add it to the response.
Notice the which="content_type:post" part, which is a Block Mask.
It tells Solr that parent objects are those objects whose content_type value is post.
The request URL for such a query looks as follows:
http://ka-adh-1.ru-central1.internal:8983/solr/posts/select?indent=true&q.op=OR&q=q%3D%7B!parent%20which%3D%22content_type%3Apost%22%7Dauthor_s%3AJohnThe sample response:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"q={!parent which=\"content_type:post\"}author_s:John",
"indent":"true",
"q.op":"OR",
"_":"1724260126428"}},
"response":{"numFound":1,"start":0,"numFoundExact":true,"docs":[
{
"id":"blog1",
"name_s":"Sample Post for testing...",
"text_t":"Lorem ipsum dolor sit amet, consectetur ....",
"content_type":["post"],
"_version_":1808018337579401216}]
}}