

Индексирование вложенных документов в Solr
Обзор
В Solr вложенные документы — это обычные документы, которые были проиндексированы в составе другого (родительского) документа. Например, несколько комментариев, которые относятся к одной и той же публикации в блоге, могут храниться в виде объектов, вложенных в документ публикации. Ниже приведен пример документа, моделирующего такие отношения между родительскими и вложенными объектами:
[
{
"post_id":"blog_post0001",
"nodeType":"post",
"comments":[
{
"comment_id":"comment_1",
"nodeType":"comment",
"content":"foo bar"
},
{
"comment_id":"comment_2",
"nodeType":"comment",
"content":"buzz"
}
]
}, {
"post_id":"blog_post0002",
"nodeType":"post",
"comments":[
{
"comment_id":"comment_3",
"nodeType":"comment",
"content":"Some text"
}
]
}
]Использование вложенных документов позволяет увеличить скорость выполнения запросов, поскольку отношения "родитель-потомок" между документами уже присутствуют в индексе и их не нужно вычислять при каждом обращении. Однако структуры с вложенными объектами менее гибкие, чем операции соединения при запросе (query-time joins), поскольку они накладывают строгие правила, которые могут быть неприемлемы для некоторых приложений.
Вложенные документы могут быть проиндексированы в форматах XML, JSON или SolrJ.
Независимо от формата, каждый документ должен содержать поле, идентифицирующее документ как родительский или дочерний.
Это поле может иметь любое имя, за исключением зарезервированных полей, определенных в схеме.
В приведенном выше примере этой цели служит поле nodeType — оно содержит значения post или comment.
При поиске по вложенным документам это поле используется в качестве входного параметра для семейства парсеров block join query.
Конфигурация схемы
Для работы с вложенными документами необходимо наличие в файле схемы поля с именем _root_, которое выглядит следующим образом:
<field name="_root_" type="string" indexed="true" stored="false" docValues="false" />Также для корректной работы трансформера child document transformer в файле схемы должно быть объявлено поле _nest_path_, как показано ниже:
<fieldType name="_nest_path_" class="solr.NestPathField" />
<field name="_nest_path_" type="_nest_path_" />По умолчанию данные поля присутствуют в стандартном файле схемы и будут унаследованы схемами, созданными на основе стандартной.
Анонимные вложенные документы
Иногда можно встретить следующий синтаксис для объявления вложенных анонимных документов:
[
{
"post_id":"blog_post0001",
"nodeType":"post",
"_childDocuments_":[
{
"comment_id":"comment_1",
"nodeType":"comment",
"content":"foo bar"
},
{
"comment_id":"comment_2",
"nodeType":"comment",
"content":"buzz"
}
]
}
]Обратите внимание на поле _childDocuments_ с массивом документов.
Это явное указание для Solr, что элементы в данном массиве — дочерние по отношению к текущему документу.
Такой подход был распространен в старых версиях Solr и теперь устарел, однако он по-прежнему работает при одноуровневой вложенности.
Индексирование вложенных документов
В следующем примере описан процесс индексирования Solr-документа с вложенными элементами.
-
Откройте Solr Admin UI. Актуальную ссылку на веб-интерфейс можно найти в ADCM (Clusters → <clusterName> → Services → Solr → Info).
-
Перейдите на страницу Collections и создайте тестовую коллекцию, используя параметры в таблице.
Параметр Описание name
posts
config set
_default
* Используя этот параметр, новая коллекция наследует конфигурацию дефолтной схемы, включая базовые функции для работы с вложенными документами
numShards
1
replicationFactor
1
-
Выберите новую коллекцию из списка и перейдите на страницу Documents, как показано на рисунке.
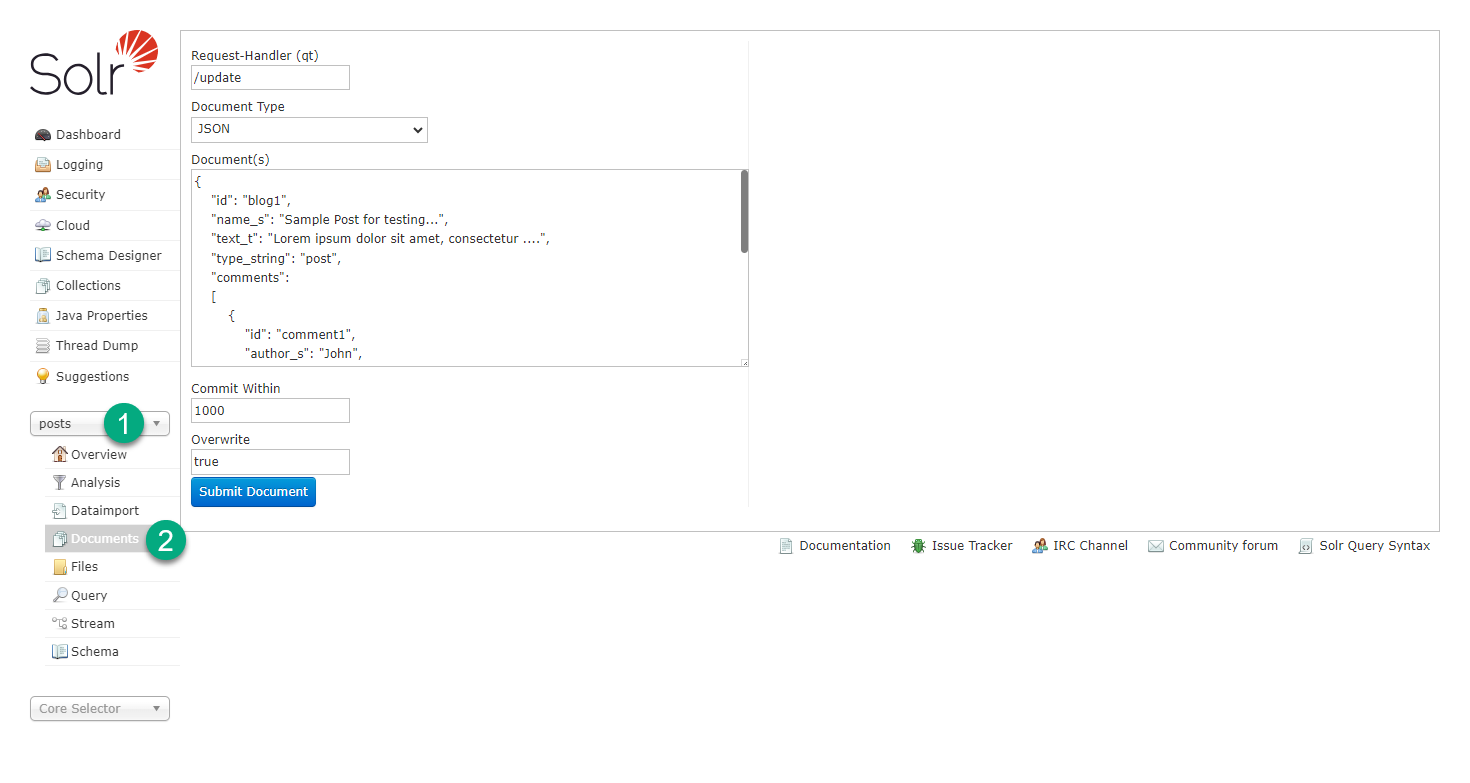 Страница Documents
Страница Documents Страница Documents
Страница Documents -
Загрузите в Solr следующие тестовые документы. Для этого поочередно вставьте содержимое документа в поле Document(s) и кликните Submit Document.
post1.json{ "id": "post1", "name_s": "Sample Post for testing...", "text_t": "Lorem ipsum dolor sit amet, consectetur ....", "content_type": "post", "comments": [ { "id": "comment1", "author_s": "John", "text_t": "Nice post!", "rated_i": 5, "content_type": "comment" }, { "id": "comment2", "author_s": "Ann", "text_t": "Not interesting post...", "rated_i": 3, "content_type": "comment" } ] }post2.json{ "id": "post2", "name_s": "Another demo post...", "text_t": "Foo Bar Buzz ....", "content_type": "post", "comments": [ { "id": "comment3", "author_s": "Luke", "text_t": "I like this post!", "rated_i": 4, "content_type": "comment" } ] }ПРИМЕЧАНИЕНе используйте Post tool для загрузки вложенных документов, так как данный инструмент автоматически делает их JSON-структуру "плоской" при загрузке.В качестве альтернативы пользовательскому интерфейсу вы можете использовать curl для загрузки тестовых документов в Solr. Пример команды приведен ниже.
Команда загрузки с помощью curl$ curl -X POST -H 'Content-Type: application/json' 'http://ka-adh-1.ru-central1.internal:8983/solr/posts/update' --data-binary '[ { "id": "blog1", "name_s": "Sample Post for testing...", "text_t": "Lorem ipsum dolor sit amet, consectetur ....", "comments": [ { "id": "comment1", "author_s": "John", "text_t": "Nice post!", "rated_i": 5 }, { "id": "comment2", "author_s": "Ann", "text_t": "Not interesting post...", "rated_i": 3 } ] }, { "id": "blog2", "name_s": "Another demo post...", "text_t": "Foo Bar Buzz ....", "comments": [ { "id": "comment3", "author_s": "Luke", "text_t": "I like this post!", "rated_i": 4 } ] } ]' -
На странице Query кликните Execute Query, не изменяя параметры поиска по умолчанию, чтобы получить все документы из индекса. Ответ Solr-сервера выглядит следующим образом:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"*:*",
"indent":"true",
"q.op":"OR",
"_":"1724336874767"}},
"response":{"numFound":5,"start":0,"numFoundExact":true,"docs":[
{
"id":"comment1",
"author_s":"John",
"text_t":"Nice post!",
"rated_i":5,
"content_type":["comment"],
"_version_":1808098244634345472},
{
"id":"comment2",
"author_s":"Ann",
"text_t":"Not interesting post...",
"rated_i":3,
"content_type":["comment"],
"_version_":1808098244634345472},
{
"id":"post1",
"name_s":"Sample Post for testing...",
"text_t":"Lorem ipsum dolor sit amet, consectetur ....",
"content_type":["post"],
"_version_":1808098244634345472},
{
"id":"comment3",
"author_s":"Luke",
"text_t":"I like this post!",
"rated_i":4,
"content_type":["comment"],
"_version_":1808098259769491456},
{
"id":"post2",
"name_s":"Another demo post...",
"text_t":"Foo Bar Buzz ....",
"content_type":["post"],
"_version_":1808098259769491456}]
}}Обратите внимание, что в ответе сервера документы имеют "плоскую" структуру, т.е. дочерние документы сгруппированы над родительскими. Именно в таком виде Solr хранит документы с вложенными элементами под капотом.
Поиск по вложенным данным
По умолчанию документы, удовлетворяющие поисковому запросу, не включают вложенных элементов, даже если таковые присутствуют в индексе.
Например, выполните поиск документа, используя строку запроса q=id:post1.
URL-адрес для такого запроса выглядит следующим образом:
http://ka-adh-1.ru-central1.internal:8983/solr/posts/select?indent=true&q.op=OR&q=id%3Apost1В ответе содержится один документ без вложенных объектов:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"id:post1",
"indent":"true",
"q.op":"OR",
"_":"1724336874767"}},
"response":{"numFound":1,"start":0,"numFoundExact":true,"docs":[
{
"id":"post1",
"name_s":"Sample Post for testing...",
"text_t":"Lorem ipsum dolor sit amet, consectetur ....",
"content_type":["post"],
"_version_":1808098244634345472}]
}}Child document transformer
Для добавления дочерних документов в ответ Solr, используйте child document transformer.
Следующий запрос содержит параметр fl=*,[child], с помощью которого в ответ сервера попадают все поля найденных документов и дополнительно все их дочерние элементы.
Пример URL запроса:
http://ka-adh-1.ru-central1.internal:8983/solr/posts/select?fl=*%2C%5Bchild%5D&indent=true&q.op=OR&q=id%3Apost1Ответ Solr:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"id:post1",
"indent":"true",
"fl":"*,[child]",
"q.op":"OR",
"_":"1724336874767"}},
"response":{"numFound":1,"start":0,"numFoundExact":true,"docs":[
{
"id":"post1",
"name_s":"Sample Post for testing...",
"text_t":"Lorem ipsum dolor sit amet, consectetur ....",
"content_type":["post"],
"_version_":1808098244634345472,
"comments":[
{
"id":"comment1",
"author_s":"John",
"text_t":"Nice post!",
"rated_i":5,
"content_type":["comment"],
"_version_":1808098244634345472},
{
"id":"comment2",
"author_s":"Ann",
"text_t":"Not interesting post...",
"rated_i":3,
"content_type":["comment"],
"_version_":1808098244634345472}]}]
}}Block join query parsers
Существует два парсера типа block join query, которые позволяют индексировать и выполнять поиск по вложенным документам. К ним относятся:
-
Block join children query parser. Используется для получения дочерних объектов документа, который удовлетворяет запросу.
-
Block join parent parser. Находит один или несколько дочерних документов и возвращает их родителя.
Следующий поисковый запрос задействует парсер block join children query:
q={!child of="content_type:post"}text_t:"Lorem"Solr интерпретирует эту строку запроса следующим образом:
-
Найти все родительские документы, у которых в поле
text_tсодержится строкаLorem. -
Получить дочерние объекты найденных документов и добавить их в ответ сервера.
Обратите внимание на выражение of="content_type:post", которое называется Block Mask.
Данное выражение сообщает серверу Solr, что родительскими документами следует считать те объекты, у которых "content_type"="post".
URL для такого запроса выглядит следующим образом:
http://ka-adh-1.ru-central1.internal:8983/solr/posts/select?indent=true&q.op=OR&q=q%3D%7B!child%20of%3D%22content_type%3Apost%22%7Dtext_t%3A%22Lorem%22Ответ:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"q={!child of=\"content_type:post\"}text_t:\"Lorem\"",
"indent":"true",
"q.op":"OR",
"_":"1724274693355"}},
"response":{"numFound":2,"start":0,"numFoundExact":true,"docs":[
{
"id":"comment1",
"author_s":"John",
"text_t":"Nice post!",
"rated_i":5,
"content_type":["comment"],
"_version_":1808018337579401216},
{
"id":"comment2",
"author_s":"Ann",
"text_t":"Not interesting post...",
"rated_i":3,
"content_type":["comment"],
"_version_":1808018337579401216}]
}}Следующий поисковый запрос задействует парсер block join parent query:
q={!parent which="content_type:post"}author_s:JohnSolr интерпретирует эту строку запроса следующим образом:
-
Найти вложенные документы, у которых поле
author_sравноJohn. -
Получить родителя найденного документа и вернуть его в ответе сервера.
Обратите внимание на выражение which="content_type:post", которое называется Block Mask.
Данное выражение сообщает серверу Solr, что родительскими документами следует считать те объекты, у которых "content_type"="post".
URL запроса выглядит следующим образом:
http://ka-adh-1.ru-central1.internal:8983/solr/posts/select?indent=true&q.op=OR&q=q%3D%7B!parent%20which%3D%22content_type%3Apost%22%7Dauthor_s%3AJohnОтвет:
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"q={!parent which=\"content_type:post\"}author_s:John",
"indent":"true",
"q.op":"OR",
"_":"1724260126428"}},
"response":{"numFound":1,"start":0,"numFoundExact":true,"docs":[
{
"id":"blog1",
"name_s":"Sample Post for testing...",
"text_t":"Lorem ipsum dolor sit amet, consectetur ....",
"content_type":["post"],
"_version_":1808018337579401216}]
}}