Создание заметки Spark
В данной статье описан процесс создания и запуска заметок Spark в Zeppelin. По умолчанию сервис Zeppelin использует ядро Spark3-сервиса в качестве бэкенда для выполнения заметок Spark. Если сервисы Spark3 и Zeppelin установлены в ADH, для выполнения кода заметок Zeppelin запускает задачи Spark в режиме YARN-кластера ADH.
Интерпретаторы Spark
Сервис Zeppelin поставляется с группой интерпретаторов spark, которая включает набор интерпретаторов для работы с различными языками, такими как Scala, Python и R.
В следующей таблице перечислены доступные интерпретаторы.
| Интерпретатор | Класс | Описание |
|---|---|---|
%spark |
SparkInterpreter |
Предоставляет среду для выполнения кода Spark на Scala |
%spark.sql |
SparkSQLInterpreter |
Позволяет выполнять ANSI SQL-запросы к объектам Spark DataFrame/DataSet |
%spark.pyspark |
PySparkInterpreter |
Предоставляет среду для выполнения кода Spark на Python |
%spark.ipyspark |
IPySparkInterpreter |
Предоставляет среду для выполнения кода Spark с использованием IPython |
%spark.r |
SparkRInterpreter |
Предоставляет среду для выполнения кода Spark на языке R с поддержкой SparkR |
%spark.ir |
SparkIRInterpreter |
Предоставляет среду на основе Jupyter IRKernel для выполнения кода Spark на языке R с поддержкой SparkR |
%spark.shiny |
SparkShinyInterpreter |
Используется для запуска приложений на языке R с поддержкой фреймворка Shiny и SparkR |
Общие объекты контекста
В данной статье предполагается, что интерпретатор spark используется со стандартными настройками биндинга (shared binding mode), то есть интерпретатор инстанциируется глобально в shared-режиме.
Это означает, что Zeppelin создает один JVM-процесс c одной группой интерпретаторов (interpreter group) для обслуживания всех заметок Spark.
В результате переменные, объявленные в одной заметке, доступны в других заметках при условии, что заметки используют один и тот же тип интерпретатора (например, обе заметки используют %spark.pyspark).
Для среды Scala, Python и R Zeppelin автоматически создает объекты SparkContext, SQLContext, SparkSession и ZeppelinContext и помещает их в переменные sc, sqlContext, spark и z соответственно.
Являясь shared-переменными, одни и те же экземпляры этих объектов одновременно доступны в разных заметках Spark.
Тестовые данные
В статье в качестве примера используется тестовый набор данных people.csv. Для работы некоторых примеров датасет необходимо загрузить в HDFS. Для этого воспользуйтесь следующими командами:
$ hdfs dfs -mkdir /user/zeppelin/test_data
$ hdfs dfs -chown zeppelin:hadoop /user/zeppelin/test_data
$ hdfs dfs -put people.csv /user/zeppelin/test_data/people.csvСоздание и запуск заметки Spark
-
В веб-интерфейсе Zeppelin кликните Create new note или выберите пункт основного меню Notebook → Create new note.
 Добавление новой заметки
Добавление новой заметки Добавление новой заметки
Добавление новой заметки -
В открывшемся диалоге введите имя и укажите интерпретатор по умолчанию, который будет использован в случаях, когда явно не указан тип интерпретатора. Обратите внимание, что вы можете создавать папки для ваших заметок. Затем кликните Create.
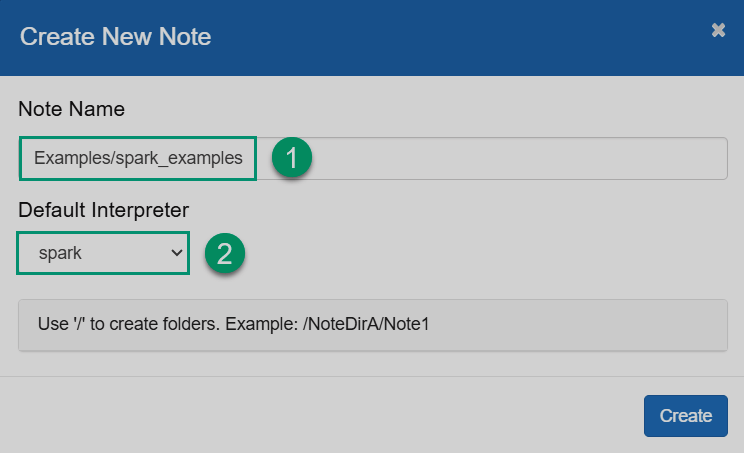 Создание новой заметки
Создание новой заметки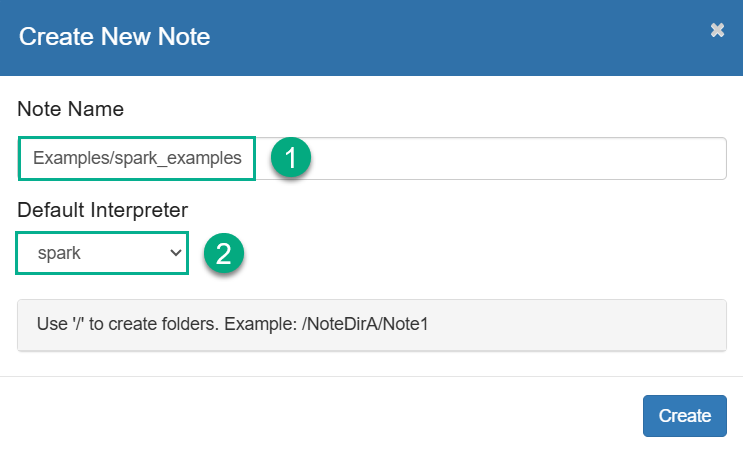 Создание новой заметки
Создание новой заметки -
Введите код Spark в параграфе (paragraph) заметки и запустите параграф.
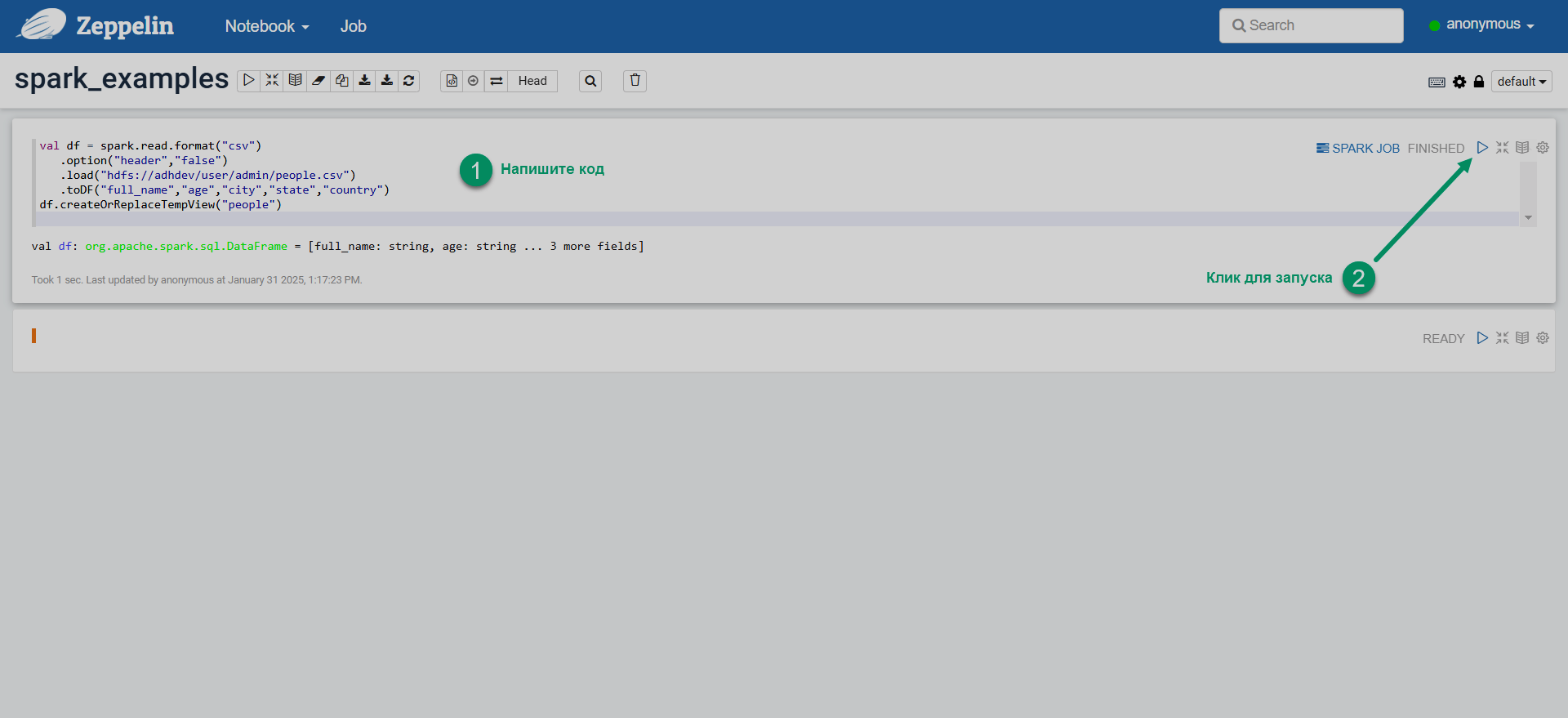 Запуск кода Spark в Zeppelin
Запуск кода Spark в Zeppelin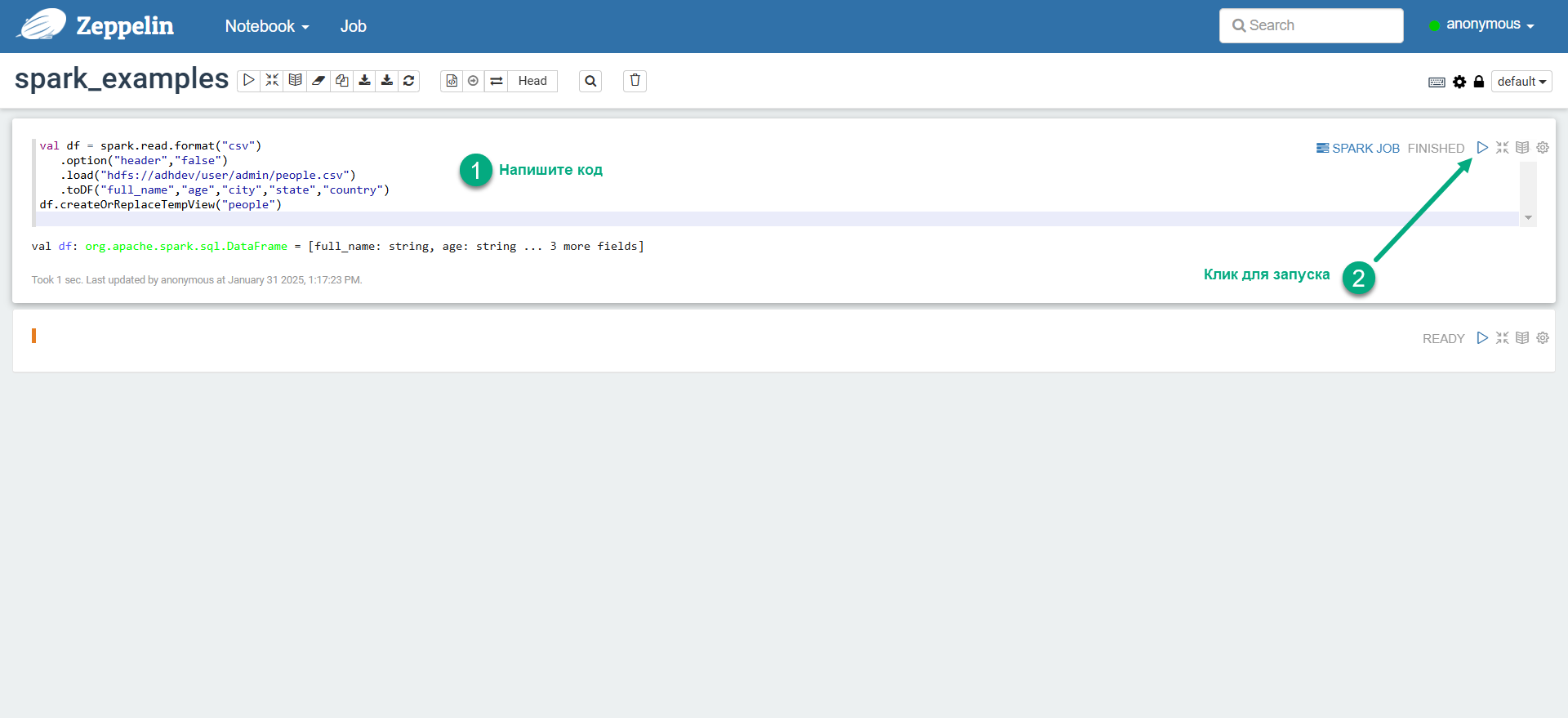 Запуск кода Spark в Zeppelin
Запуск кода Spark в Zeppelin
Далее приведены примеры кода Spark на Scala, PySpark и SparkSQL. Больше примеров доступно в заметках Spark-туториала, доступном в Zeppelin (Notebook → Spark Tutorial).
Scala
Для запуска Spark-заметки на Scala укажите интерпретатор %spark в первой строке параграфа.
Технически интерпретатор %spark можно не указывать, так как он является стандартным в группе, однако рекомендуется объявлять интерпретаторы для каждого параграфа заметки.
%spark (1)
val df_people = spark.read.format("csv") (2)
.option("header","false")
.load("hdfs://adhdev/user/zeppelin/test_data/people.csv")
.toDF("full_name","age","city","state","country")
df_people.printSchema()
case class SW_movie(id:Int, name:String, episode:Int, year:Int)
val df_sw_movies = spark.createDataFrame(Seq (3)
(
SW_movie(1, "Revenge of the Sith", 3, 2005),
SW_movie(2, "Attack of the Clones", 2, 2002),
SW_movie(3, "The Phantom Menace", 1, 1999),
SW_movie(4, "A New Hope", 4, 1977),
SW_movie(5, "Return of the Jedi", 6, 1983),
SW_movie(6, "The Empire Strikes Back", 5, 1980)
)
)
df_sw_movies.printSchema()
val df_sw_movies_comments = df_sw_movies.withColumn("rank", lit(0.0)) (4)
df_sw_movies_comments.printSchema()
df_sw_movies_comments.drop("rank") (5)
val sorted_by_year = rdd.map(mv => (6)
(mv._1,mv._2,mv._3)
).sortBy(_._3).toDF("name", "episode", "year")
sorted_by_year.show()
sorted_by_year.write (7)
.mode("overwrite")
.json("/user/zeppelin/test_data/star_wars_movies")| 1 | Явное указание интерпретатора для выполнения кода Spark на языке Scala. |
| 2 | Создание DataFrame из тестовых данных в HDFS. |
| 3 | Создание DataFrame из кортежа Сase-class объектов. |
| 4 | Добавление в DataFrame столбца со статическими данными. |
| 5 | Создание DataFrame с применением сортировки по произвольному столбцу. |
| 6 | Удаление столбца из DataFrame. |
| 7 | Запись содержимого DataFrame в HDFS в виде JSON. |
PySpark
Чтобы выполнить заметку PySpark, объявите интерпретатор %spark.pyspark в первой строке параграфа.
%spark.pyspark (1)
df = spark.createDataFrame([ (2)
(1, "Ivan", 20, "Russia"),
(2, "Yao", 23, "China"),
(3, "Ann", 28, "Russia"),
(4, "John", 20, "USA")
]).toDF("id", "name", "age", "country")
df.printSchema()
df.show()
from pyspark.sql.types import StructType
peopleSchema = StructType() \
.add("full_name", "string") \
.add("age", "integer") \
.add("city", "string") \
.add("state", "string") \
.add("country", "string")
df_people = spark.read.csv("hdfs://adhdev/user/zeppelin/test_data/people.csv", schema=peopleSchema) (3)
df_people.printSchema();
df_name_city = df_people.select("full_name", "city") (4)
df_name_city.show(10)
import pyspark.sql.functions as f
df_name_uppered = df_people.withColumn("full_name_upper", f.upper(df_people["full_name"])) (5)
df_name_uppered.printSchema()
df_people_stateless = df_people.drop("state"); (6)
df_people_stateless.printSchema();
df = df_people.filter( (7)
(df_people["age"] >= 20) & (df_people["city"] == "Houston")
)
df.show()
from pyspark.sql.functions import udf
from pyspark.sql.types import BooleanType
@udf(returnType=BooleanType()) (8)
def udf_older_than(e):
if e > 60:
return True;
else:
return False
df_people_older_than60 = df_people.filter(udf_older_than(df_people["age"]))
df_people_older_than60.show()| 1 | Явное указание интерпретатора для выполнения кода PySpark. |
| 2 | Создание DataFrame из списка кортежей Python. |
| 3 | Создание DataFrame из тестовых данных в HDFS. |
| 4 | Создание нового DataFrame путем выборки определенных столбцов из другого DataFrame. |
| 5 | Добавление столбца в DataFrame; строки в столбце приведены к верхнему регистру с помощью pyspark.sql.functions. |
| 6 | Удаление столбца из DataFrame. |
| 7 | Применение нескольких фильтров выборки. |
| 8 | Объявление UDF, которая далее используется при фильтрации. |
SparkSQL
В заметках Scala/PySpark можно выполнять SQL-запросы к DataFrame с помощью конструкции spark.sql().
Например:
%spark.pyspark (1)
from pyspark.sql.types import StructType
peopleSchema = StructType() \
.add("full_name", "string") \
.add("age", "integer") \
.add("city", "string") \
.add("state", "string") \
.add("country", "string")
df_people = spark.read.csv("hdfs://adhdev/user/zeppelin/test_data/people.csv", schema=peopleSchema)
df_people.createOrReplaceTempView("people") (2)
df_people30 = spark.sql("select full_name, age from people where age=30") (3)| 1 | Явное указание интерпретатора для выполнения кода PySpark. |
| 2 | Создание временного представления (temporary view) на основе содержимого DataFrame. Это действие необходимо для выполнения запросов SparkSQL. |
| 3 | SQL-запрос к временному представлению. Результаты запроса сохраняются в отдельный DataFrame. |
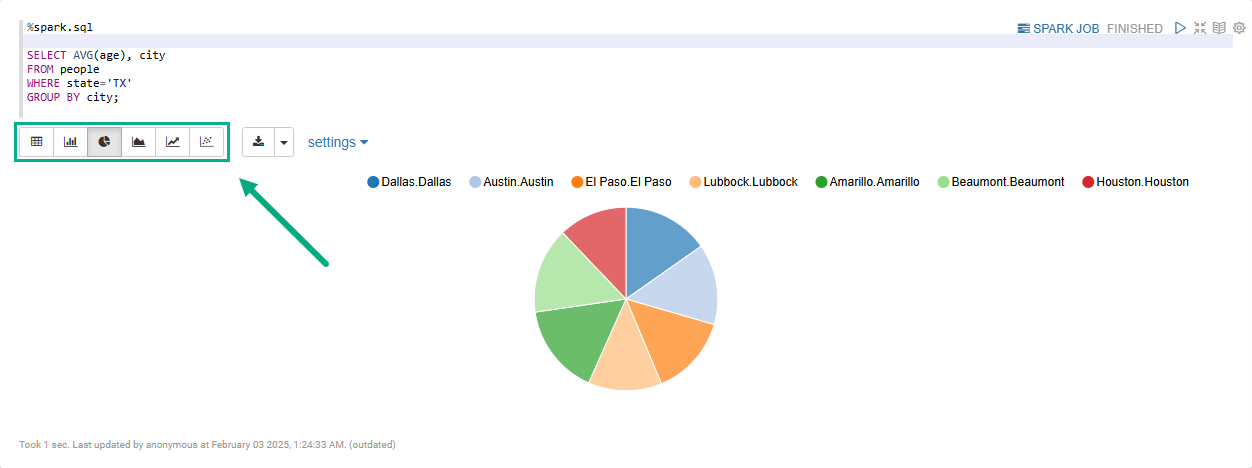
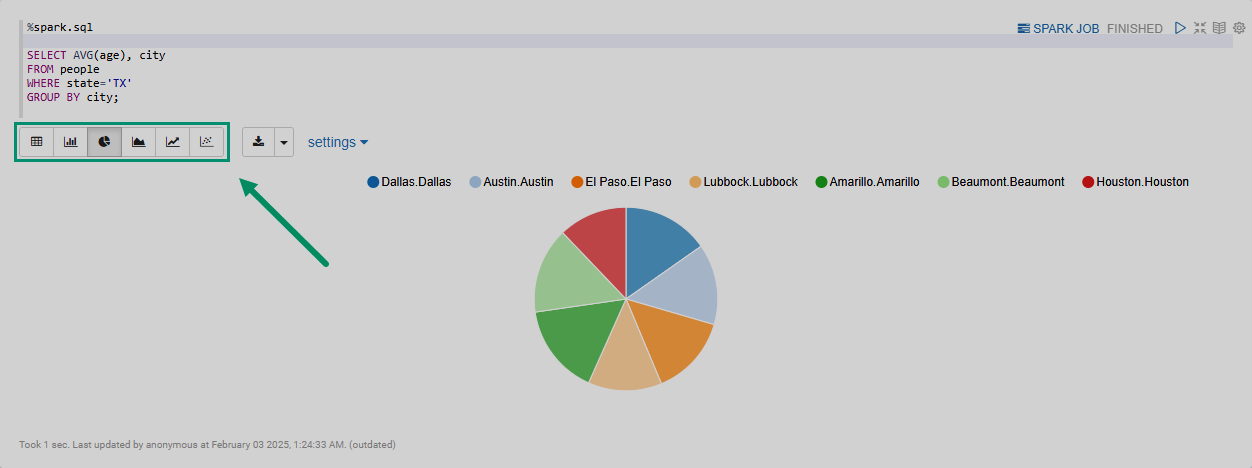
Указав интерпретатор %spark.sql в первой строке параграфа, можно визуализировать результаты запросов к объектам Spark DataFrame с помощью встроенных виджетов (диаграммы, графики, таблицы и так далее).
Например:
%spark.sql
SELECT AVG(age), city
FROM people (1)
WHERE state='TX'
GROUP BY city;| 1 | Перед выполнением запроса объект people должен быть зарегистрирован в качестве временного представления (temporary view). |
При выполнении заметки с интерпретатором %spark.sql результаты по умолчанию отображаются в виде таблицы.
Используя встроенные виджеты, можно визуализировать данные в виде круговой диаграммы, линейного графика и прочих, как показано на рисунке ниже.