

Настройка производительности
В Impala есть операторы, с помощью которых можно получить информацию о производительности запросов. Impala также предоставляет веб-интерфейсы, которые отображают статистику производительности. Наиболее полезной является страница queries веб-интерфейса impalad. Она содержит планы запросов, отчеты PROFILE и SUMMARY, и другую информацию о производительности запросов.
Операторы для настройки производительности
В Impala есть следующие операторы, которые можно использовать для настройки производительности:
EXPLAIN
Оператор EXPLAIN отображает план выполнения, который Impala генерирует для указанного запроса. При вызове этой команды запрос не выполняется.
План включает механизмы низкого уровня, которые Impala будет использовать для чтения данных. Он описывает, как операции будут распределяться между нодами кластера и как промежуточные результаты будут объединяться для получения окончательного результата. Вы можете просмотреть эти сведения перед выполнением запроса, чтобы убедиться, что запрос будет выполнен эффективно. Если полученный план не соответствует вашим требованиям, вы можете изменить запрос, чтобы повысить производительность. Например, можно изменить условия в выражении WHERE, порядок таблиц в операторе JOIN, добавить подзапросы, изменить партиционирование таблицы, а также выполнить сбор статистики по столбцам и таблицам в Hive (см. COMPUTE STATS Statement).
Например, запрос explain select count(*) from table1; имеет следующий результат:
Query: explain select count(*) from table1 +------------------------------------------------------------+ | Explain String | +------------------------------------------------------------+ | Max Per-Host Resource Reservation: Memory=8.00KB Threads=2 | | Per-Host Resource Estimates: Memory=10MB | | Codegen disabled by planner | | | | PLAN-ROOT SINK | | | | | 03:AGGREGATE [FINALIZE] | | | output: sum(count(*)) | | | | | 02:EXCHANGE [UNPARTITIONED] | | | | | 01:AGGREGATE | | | output: count(*) | | | | | 00:SCAN HDFS [default.table1] | | HDFS partitions=1/1 files=5 size=3.99KB | | row-size=8B cardinality=5 | +------------------------------------------------------------+
Прочитаем план, созданный EXPLAIN, снизу вверх:
-
Последняя часть (
00:SCAN HDFS [default.table1]) плана показывает информацию низкого уровня, такую как ожидаемый объем данных, которые будут прочитаны. Это позволяет оценить эффективность стратегии партиционирования и время сканирования таблицы на основе общего размера данных. -
На следующем шаге вы увидите операции, которые будут распараллелены и выполнены на каждой ноде Impala.
-
Следующие уровни показывают, как промежуточные наборы результатов объединяются и передаются от одного узла к другому.
Вы можете использовать опцию запроса EXPLAIN_LEVEL для управления уровнем детализации, предоставляемой в результате EXPLAIN. Допустимые значения EXPLAIN_LEVEL:
-
0илиMINIMAL— отображает список с одной строкой для каждой операции. В первую очередь это применяется для проверки порядка объединения в оператореJOINв больших запросах, где обычный выводEXPLAINслишком длинный, чтобы его можно было легко прочитать. -
1илиSTANDARD— значение по умолчанию, показывающее план выполнения запроса на логическом уровне. -
2илиEXTENDED— включает дополнительную информацию, иллюстрирующую, как планировщик запросов использует статистику в процессах принятия решений. -
3илиVERBOSE— обеспечивает максимальный уровень детализации и показывает, как запрос разбивается на фрагменты, которые собираются в пайплайн для каждой ноды. Эта информация полезна для низкоуровневого тестирования производительности и настройки Impala, а не для оптимизации SQL-кода на уровне пользователя.
На всех уровнях детализации вывод EXPLAIN содержит предупреждение, если в каких-либо таблицах запроса отсутствует статистика. Используйте оператор COMPUTE STATS для сбора статистики для каждой таблицы и предотвращения появления этого предупреждения.
Результат EXPLAIN также печатается в начале отчета команды PROFILE, описанной ниже.
SUMMARY
Команда SUMMARY отображает время выполнения этапов запроса. Это позволяет определить потенциальные проблемы с производительностью. Вы можете запустить SUMMARY после выполнения запроса, чтобы увидеть фактические характеристики его производительности.
Пример:
SELECT AVG(salary) FROM table1 WHERE position like 'manager%';
summary;Результат:
+--------------+--------+--------+----------+----------+-------+------------+----------+---------------+-----------------+ | Operator | #Hosts | #Inst | Avg Time | Max Time | #Rows | Est. #Rows | Peak Mem | Est. Peak Mem | Detail | +--------------+--------+--------+----------+----------+-------+------------+----------+---------------+-----------------+ | 03:AGGREGATE | 1 | 1 | 1.03ms | 1.03ms | 1 | 1 | 48.00 KB | -1 B | MERGE FINALIZE | | 02:EXCHANGE | 1 | 1 | 0ns | 0ns | 1 | 1 | 0 B | -1 B | UNPARTITIONED | | 01:AGGREGATE | 1 | 1 |30.79ms | 30.79ms | 1 | 1 | 80.00 KB | 10.00 MB | | | 00:SCAN HDFS | 1 | 1 | 5.45s | 5.45s | 2.21M | -1 | 64.05 MB | 432.00 MB | default.table1 | +--------------+--------+--------+----------+----------+-------+------------+----------+---------------+-----------------+
Различные этапы запроса и их время показаны с фактическими и расчетными значениями, используемыми в плане выполнения запроса EXPLAIN. Функция AVG() вычисляется для подмножества данных на каждой ноде (этап 01), а затем в конце объединяются агрегированные результаты со всех нод (этап 03). Вы можете увидеть, какие этапы заняли больше всего времени и существенно ли какие-либо оценки отличались от фактических.
В Impala есть параметр запроса MT_DOP, определяющий степень параллелизма внутри одной ноды, используемого для определенных операций, которые могут выиграть от многопоточного выполнения. Если MT_DOP установлен больше 0, столбец #Inst в выходных данных показывает количество экземпляров фрагмента. Impala разбивает каждый запрос на более мелкие блоки, распределенные по кластеру, и эти блоки называются фрагментами. Когда для параметра запроса MT_DOP установлено значение 0, столбец #Inst показывает то же значение, что и столбец #Hosts, поскольку для каждого хоста существует только один фрагмент.
Результат SUMMARY также печатается в начале отчета команды PROFILE, описанной ниже.
PROFILE
Команда PROFILE создает подробный низкоуровневый отчет, показывающий, как был выполнен последний запрос. Отчет содержит множество параметров. Вы можете найти фрагменты вывода PROFILE ниже.
Query Runtime Profile:
Query (id=36493a18ee92e275:1c04f39000000000):
- InactiveTotalTime: 0.000ns
- TotalTime: 0.000ns
Summary:
Session ID: ed440ba9e107f951:3ae2c27f67a7d6ae
Session Type: HIVESERVER2
HiveServer2 Protocol Version: V6
Start Time: 2023-08-24 13:23:10.491153000
End Time: 2023-08-24 13:23:10.604175000
Query Type: QUERY
Query State: FINISHED
Impala Query State: FINISHED
Query Status: OK
Impala Version: impalad version 4.2.0-RELEASE RELEASE (build 978afcfae9aa626de182b2872c4469646f42e0f6)
User: admin
Connected User: admin
Delegated User:
Network Address: 10.92.6.52:47426
Default Db: default
Sql Statement: SELECT AVG(field1) FROM table1 WHERE field3 like 'row%'
Coordinator: ees-1adh.ru-central1.internal:27000
Query Options (set by configuration): EXPLAIN_LEVEL=VERBOSE,TIMEZONE=UTC,CLIENT_IDENTIFIER=Impala Shell v4.2.0-RELEASE (978afcf) built on Mon Jun 5 16:33:03 UTC 2023,DEFAULT_FILE_FORMAT=PARQUET
Query Options (set by configuration and planner): EXPLAIN_LEVEL=VERBOSE,NUM_NODES=1,NUM_SCANNER_THREADS=1,RUNTIME_FILTER_MODE=OFF,MT_DOP=0,TIMEZONE=UTC,CLIENT_IDENTIFIER=Impala Shell v4.2.0-RELEASE (978afcf) built on Mon Jun 5 16:33:03 UTC 2023,DEFAULT_FILE_FORMAT=PARQUET,SPOOL_QUERY_RESULTS=0
...
Estimated Per-Host Mem: 16793600
Request Pool: default-pool
Per Host Min Memory Reservation: ees-1adh.ru-central1.internal:27000(16.00 KB)
Per Host Number of Fragment Instances: ees-1adh.ru-central1.internal:27000(1)
Admission result: Admitted immediately
Cluster Memory Admitted: 16.02 MB
Executor Group: empty group (using coordinator only)
ExecSummary:
Operator #Hosts #Inst Avg Time Max Time #Rows Est. #Rows Peak Mem Est. Peak Mem Detail
-------------------------------------------------------------------------------------------------------------
F00:ROOT 1 1 0.000ns 0.000ns 0 0
01:AGGREGATE 1 1 0.000ns 0.000ns 1 1 37.00 KB 16.00 KB FINALIZE
00:SCAN HDFS 1 1 5.000ms 5.000ms 15 1 85.00 KB 16.00 MB default.table1
Errors:
Query Compilation: 8.502ms
- Metadata of all 1 tables cached: 1.585ms (1.585ms)
- Analysis finished: 3.044ms (1.459ms)
- Authorization finished (noop): 3.203ms (159.571us)
- Value transfer graph computed: 3.362ms (158.312us)
- Single node plan created: 6.038ms (2.676ms)
- Distributed plan created: 6.121ms (83.217us)
- Lineage info computed: 6.312ms (190.851us)
- Planning finished: 8.502ms (2.189ms)
Query Timeline: 113.002ms
- Query submitted: 0.000ns (0.000ns)
- Planning finished: 10.000ms (10.000ms)
- Submit for admission: 10.000ms (0.000ns)
- Completed admission: 10.000ms (0.000ns)
- Ready to start on 1 backends: 10.000ms (0.000ns)
- All 1 execution backends (1 fragment instances) started: 11.000ms (1.000ms)
- Rows available: 16.000ms (5.000ms)
- First row fetched: 112.002ms (96.001ms)
- Last row fetched: 112.002ms (0.000ns)
- Released admission control resources: 113.002ms (1.000ms)
- Unregister query: 113.002ms (0.000ns)
- AdmissionControlTimeSinceLastUpdate: 18.000ms
- ComputeScanRangeAssignmentTimer: 0.000ns
- InactiveTotalTime: 0.000ns
- TotalTime: 0.000ns
...
Вывод показывает физические детали запроса (количество прочитанных байтов, максимальное использование памяти и т. д.) для каждой ноды. Можно использовать эту информацию, чтобы определить, существенно ли запрос зависит от операций ввода-вывода или работы процессора, приводит ли какое-либо состояние сети к проблемам, влияет ли замедление выполнения запроса только на некоторые ноды, или на все сразу.
Вы можете найти описание параметров PROFILE на странице /profile_docs в веб-интерфейсе impalad. Для доступа к этой странице используйте следующий шаблон адреса: http://<server‑hostname>:<port>/profile_docs. Пример: http://ees-1adh.ru-central1.internal:25000/profile_docs.
Значения в выводе PROFILE отражают время, затраченное на операцию, в режиме реального времени. Для значений, которые представляют системное время или время пользователя, способ измерения отображается в имени метрики, например ScannerThreadsSysTime или ScannerThreadsUserTime. Например, многопоточная операция ввода-вывода может показывать небольшое значение в режиме реального времени, в то время как соответствующее системное время может быть больше. Оно представляет собой сумму времени процессора, затрачиваемого каждым потоком. Значение в режиме реального времени также может быть больше, поскольку оно может включать время ожидания, в то время как соответствующие значения системного и пользовательского времени измеряют только время, в течение которого операция активно использует ЦП.
Impala отображает результаты EXPLAIN и SUMMARY в начале отчета PROFILE, что позволяет изучить как логический, так и физический уровни выполнения запроса.
В результате команды PROFILE присутствует раздел Per Node Profiles. Он включает следующие показатели, которыми можно управлять с помощью параметра запроса RESOURCE_TRACE_RATIO:
-
CpuIoWaitPercentage — процент времени, в течение которого ЦП (один или несколько) простаивал, и система имела ожидающие запросы дискового ввода-вывода.
-
CpuSysPercentage — процент использования процессора системой.
-
CpuUserPercentage — процент использования процессора пользователем.
-
HostDiskReadThroughput — данные, считываемые хостом в рамках выполнения этого запроса, data-нодой HDFS и другими процессами, работающими в той же системе.
-
HostDiskWriteThroughput — данные, записываемые хостом в рамках выполнения этого запроса, data-нодой HDFS и другими процессами, работающими в той же системе.
-
HostNetworkRx — данные, полученные хостом в рамках выполнения этого запроса, других запросов и других процессов, выполняемых в той же системе.
-
HostNetworkTx — данные, передаваемые хостом в рамках выполнения этого запроса, других запросов и других процессов, выполняемых в той же системе.
В настоящее время страница /profile_docs не содержит эти показатели.
Страница queries веб-интерфейса impalad
Страница queries собирает статистику выполнения запросов. Для доступа к этой странице используйте следующий шаблон адреса: http://<server‑hostname>:<port>/queries. Пример: http://ees-1adh.ru-central1.internal:25000/queries.
Страница queries группирует запросы в несколько таблиц:
-
Queries in flight — выполняемые запросы.
-
Waiting to be closed — запросы, которые закончили выполнять действия, но еще не были завершены.
-
Last 100 completed queries — последние завершенные запросы. Вы можете управлять количеством запросов и, следовательно, объемом памяти, выделенной для хранения информации о завершенных запросах, используя параметр запуска
--query_log_sizeдля impalad. -
Query Locations — отображает, как запущенные запросы распределяются между хостами impalad.
Последние по времени запросы отображаются в верхней части таблиц.
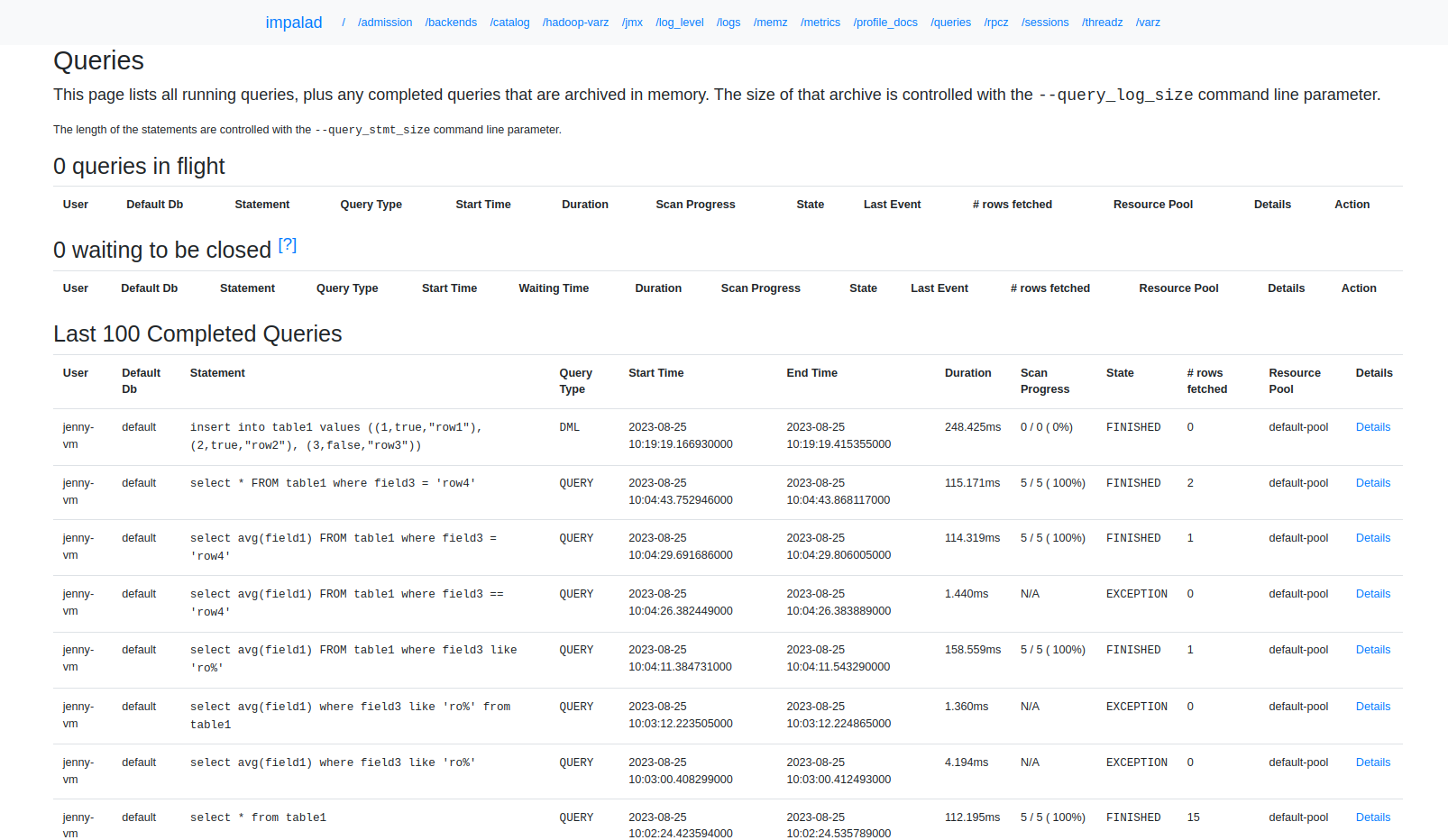
Ссылка Details для каждого запроса отображает подробную информацию о запросе, включая графическое представление плана.
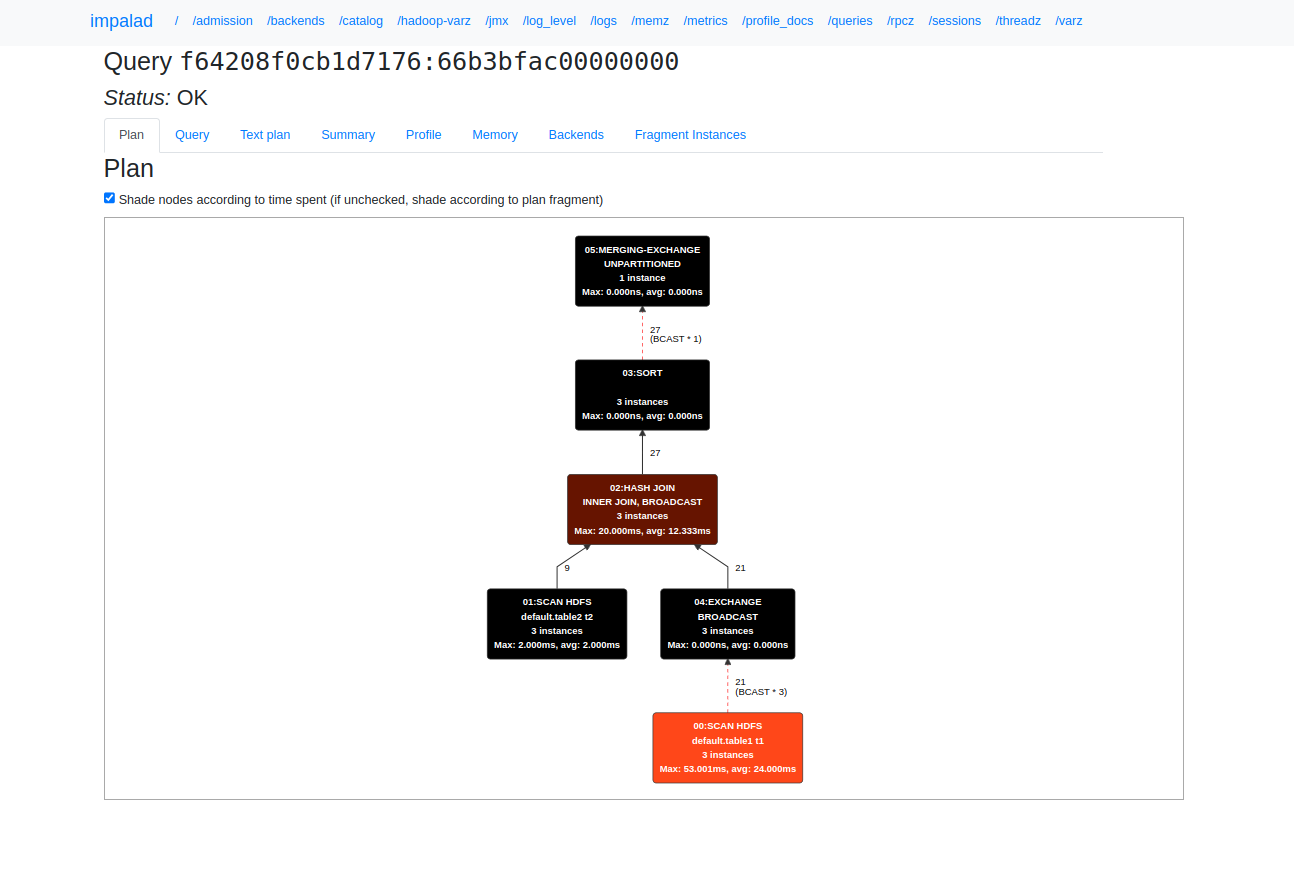
На странице Details доступны следующие вкладки:
-
Plan — графическое представление плана запроса.
-
Query — текст запроса.
-
Text plan — план запроса, являющийся результатом команды
EXPLAIN. -
Summary — результат команды
SUMMARY. -
Profile — результат команды
PROFILE. -
Memory — потребление памяти. Доступно во время выполнения запроса.
-
Backends — используемые экземпляры Impala. Доступно во время выполнения запроса.
-
Fragment instances — информация об экземплярах фрагментов. Доступно во время выполнения запроса.
На вкладке Profile можно экспортировать результат в Thrift, JSON или текстовый формат.