

Настройка имперсонации в ADH
Обзор
В экосистеме Hadoop под имперсонацией понимается механизм, позволяющий сервису производить действия от имени другого пользователя. Имперсонация реализуется для соответствия политикам безопасности (например, Kerberos или Ranger-политика), изоляции данных и ресурсов между пользователями, а также аудита действий с фиксацией в логах имени пользователя, который осуществил запуск действия.
ADH поддерживает имперсонацию для следующих сервисов: HBase (Phoenix, Thrift), Spark (Livy), Hive, Zeppelin, Flink, Solr, Sqoop, Airflow. По умолчанию имперсонация включена для всех сервисов, но некоторым из них требуются дополнительные настройки, описанные ниже. Чтобы настроить сервис для имперсонации определенных пользователей, измените значения параметров hadoop.proxyuser.<service>.groups и hadoop.proxyuser.<service>.hosts в группе параметров core-site.xml сервиса Core configuration.
Имперсонация для Livy
Пример ниже демонстрирует, как настроить имперсонацию для Livy.
Подготовка кластера в ADCM
-
В ADCM выберите ваш кластер ADH и перейдите к настройкам сервиса Spark. Раскройте группу параметров livy.conf и убедитесь, что параметру livy.impersonation.enabled присвоено значение
true. -
Перейдите к настройкам сервиса Core configuration и отредактируйте параметры hadoop.proxyuser.livy.groups и hadoop.proxyuser.livy.hosts. По умолчанию они заполнены значением
*, а вам нужно предоставить настоящие имена групп и адреса хостов. Сервис сможет имперсонировать пользователей из указанных групп при условии, что запрос приходит с разрешенного хоста. -
Сохраните конфигурацию и запустите действие Update Core configuration.
Подготовка на хосте
-
Создайте пользовательские директории в HDFS:
$ sudo -u hdfs hdfs dfs -mkdir /user/<username> $ sudo -u hdfs hdfs dfs -chown <username>:<group> /user/<username> -
Выдайте необходимые права пользователю и скопируйте JAR-примеры Spark в HDFS:
$ hdfs dfs -chmod -R a+rwx /user/<username> $ hdfs dfs -chmod -R a+rwx /var/log/spark/apps $ hdfs dfs -mkdir /user/<username>/spark_examples $ hdfs dfs -put /usr/lib/spark/examples/jars/* /user/<username>/spark_examples
Тестирование
-
Создайте JSON-файл, подобный представленному:
{ "file": "/user/<username>/spark_examples/spark-examples_2.11-2.3.2.3.1.0.15-1.jar", "className": "org.apache.spark.examples.SparkPi", "name": "test-livy-1", "args": [10], "proxyUser": "<username>" } -
Отправьте запрос с созданным JSON в Livy:
$ curl --negotiate -v -u: -d @app_spark.json -H "X-Requested-By: <username>" -H 'Content-Type: application/json' -X POST 'http://kru-adh-22.ru-central1.internal:8998/batches'
Имперсонация для SSM
Чтобы настроить имперсонацию для SSM, выполните следующие шаги:
-
Перейдите в веб-интерфейс ADCM и выберите свой кластер на странице Clusters.
-
Откройте вкладку Services и выберите сервис SSM.
-
Переведите в активное состояние переключатель Show advanced и раскройте группу параметров Custom smart-site.xml.
-
Нажмите Add property и задайте следующие значения:
-
Имя параметра —
smart.proxy.user; -
Значение параметра — имя пользователя для имперсонации.
-
-
Нажмите Apply.
-
Раскройте группу параметров smart-site.xml и задайте значения следующих параметров:
-
smart.proxy.user.strategy — определяет используемую стратегию имперсонации. Выберите одно из следующих значений:
-
NODE_SCOPE— включить имперсонацию на уровне узла. Все действия будут выполняться от имени ранее заданного пользователя. -
CMDLET_SCOPE— включить имперсонацию на уровне cmdlet. Все действия будут выполняться от имени владельца cmdlet (создателя cmdlet).
-
-
smart.proxy.users.cache.ttl — интервал времени с момента последнего осуществления доступа к записи пользователя в кеше механизма имперсонации, прежде чем эта запись будет удалена.
-
smart.proxy.users.cache.size — размер кеша механизма имперсонации.
-
-
Нажмите Save, затем Create.
-
Нажмите Actions и выберите Restart.
Имперсонация для Zeppelin
Для настройки имперсонации для Zeppelin требуется включить Active Directory Kerberos как для кластера ADH, так и для связанного кластера ADPS. Также необходимо активировать Ranger-плагины для HDFS, YARN и Hive.
Чтобы увидеть эффект от имперсонации для Zeppelin, следуйте шагам ниже:
-
В ADCM выберите ваш кластер ADH и перейдите к настройкам сервиса Zeppelin. Активируйте параметр Shiro LDAP auth и заполните необходимые данные. После этого перезапустите Zeppelin.
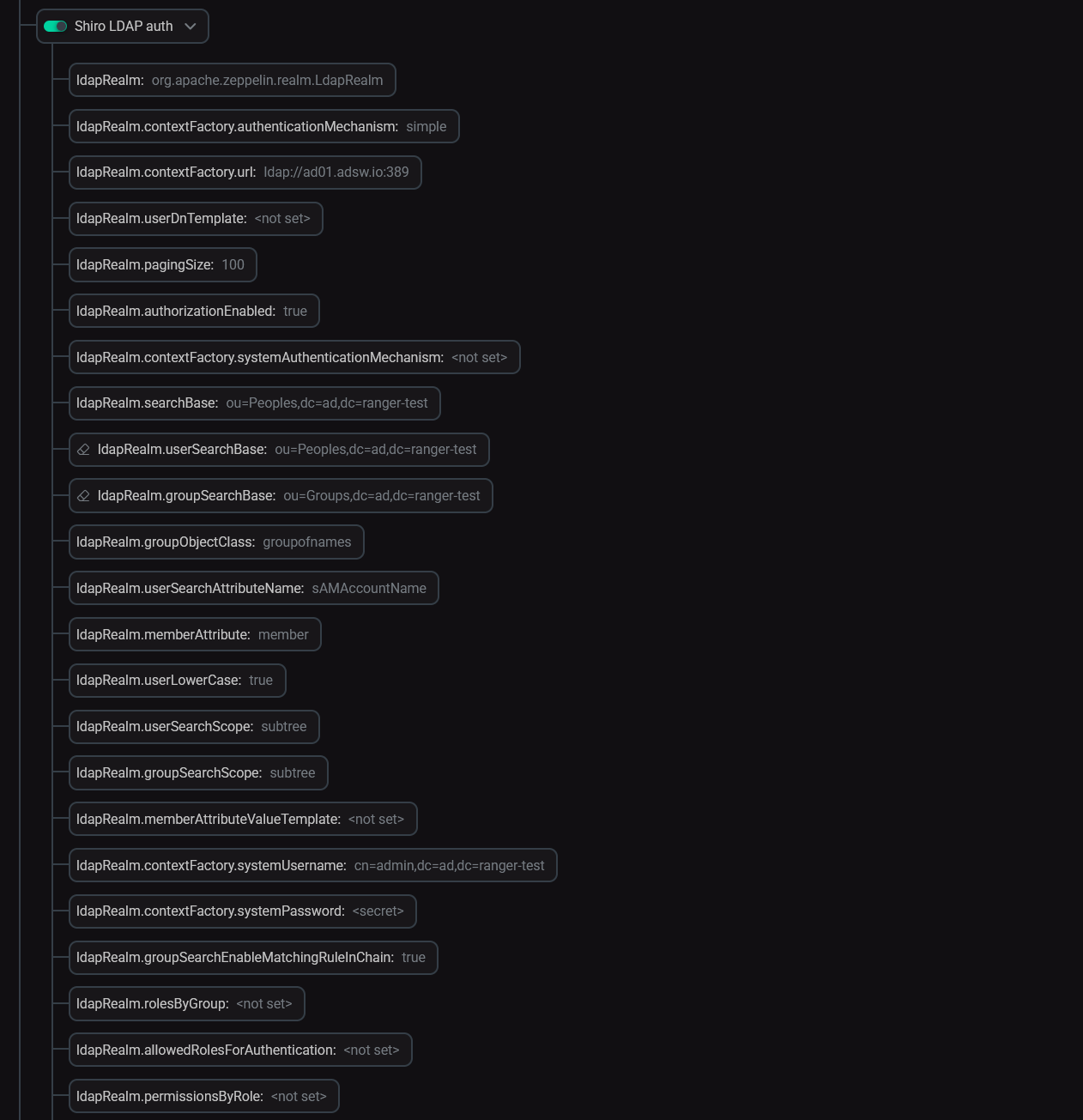 Параметры LDAP-аутентификации в Zeppelin
Параметры LDAP-аутентификации в Zeppelin -
Авторизуйтесь в веб-интерфейсе Zeppelin с данными пользователя Active Directory.
 Авторизация в веб-интерфейсе Zeppelin
Авторизация в веб-интерфейсе Zeppelin Авторизация в веб-интерфейсе Zeppelin
Авторизация в веб-интерфейсе Zeppelin -
Выберите интерпретатор, создайте заметку и запустите ее на выбранном интерпретаторе.
-
В веб-интерфейсе Ranger Admin перейдите на страницу Audit → Access. В логах вы увидите запись с именем пользователя Active Directory.