

Добавление сервисов
В ADCM сервис означает программное обеспечение, выполняющее некоторую функцию. Примеры сервисов в кластерах ADH: HDFS, HBase, Hive и другие. Для добавления сервисов в кластер:
-
Выберите кластер на странице Clusters. Для этого нажмите на имя кластера в столбце Name.
 Выбор кластера
Выбор кластера -
Откройте вкладку Services на странице кластера и нажмите Add services (Add service в первых версиях ADCM).
 Переход к добавлению сервисов
Переход к добавлению сервисов -
В открывшемся окне выберите сервисы для добавления в кластер и нажмите Add.
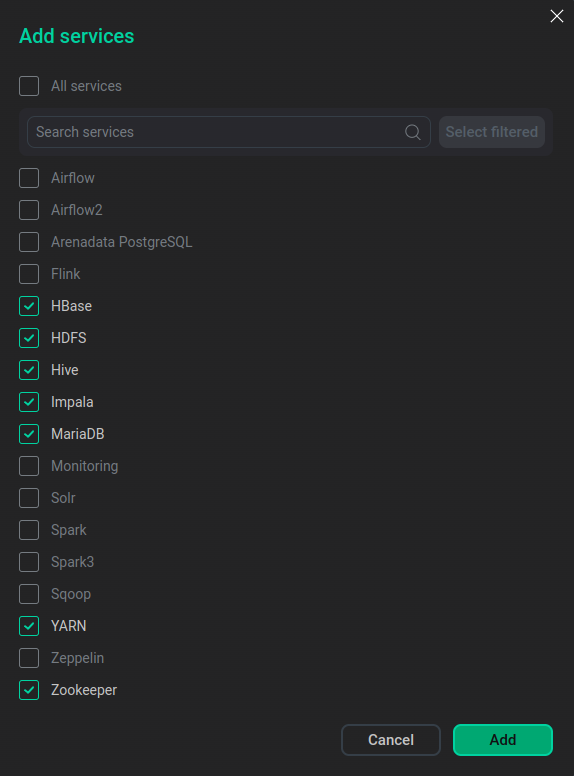 Выбор сервисов
Выбор сервисовКраткое описание доступных сервисов приведено ниже.
Сервисы, которые могут быть добавлены в кластер ADH Сервис Назначение Реляционная база данных PostgreSQL, используемая сервисами ADH
По сравнению с версией Airflow 1.x, Airflow2 предлагает дополнительные функции: высокая отказоустойчивость (High Availability), уменьшенная задержка выполнения задач, полный REST API, TaskFlow API, группы задач, независимые провайдеры и другие
Core configuration
Сервис, содержащий общие пакеты Hadoop, необходимые для всех остальных сервисов, кроме ADPG, Solr, Zookeeper и Monitoring. Этот сервис устанавливается на все узлы. Если уже установленный сервис Hadoop расширяется на другой хост, сервис Core configuration автоматически устанавливается на этот хост. Сервис Core configuration поддерживается начиная с версии ADH 3.3.6.2.b1. Конфигурационные параметры сервиса описаны в статье Конфигурационные параметры. После применения любых изменений в конфигурации сервиса необходимо выполнить его действие Update Core configuration
Распределенная платформа, используемая в высоконагруженных приложениях Big Data для анализа данных, хранимых в кластерах Hyperwave. Наиболее частые сценарии использования: приложения, управляемые событиями (event-driven), потоковая и пакетная аналитика, конвейеры данных, ETL и другое
Flink2
Сервис Flink с версией 2.x. Сервис добавлен в режиме технологического превью, может иметь ряд ограничений и не предназначен для использования в производственных средах
Нереляционная распределенная база данных, написанная на Java и работающая поверх HDFS. Относится к классу колоночных СУБД, хранящих данные в формате key-value. Используется для произвольного доступа к большим данным на чтение и запись в режиме реального времени
Распределенная файловая система, используемая в кластерах Hyperwave для хранения больших файлов. Обеспечивает возможность потокового доступа к информации, распределенной поблочно по нодам кластера
Сервис, предназначенный для создания корпоративных хранилищ данных (Data Warehouse, DWH) и анализа Big Data. Работает поверх HDFS и других совместимых систем, таких как Apache HBase. Использование Hive облегчает запись, чтение и управление большими наборами данных, хранимыми в распределенных системах
Apache HUE — это SQL-помощник с графическим интерфейсом, который предоставляет интерпретаторы для различных источников данных, таких как Impala, Hive, Kyuubi и многих других. Он обладает удобным редактором запросов с умной автоподстановкой, функцией "drag and drop", меню быстрой навигации и другими полезными функциями
Impala обеспечивает быстрые интерактивные SQL-запросы к данным, хранящимся в HDFS, HBase или S3-хранилище. В дополнение к унифицированной платформе хранения Impala также использует те же метаданные, синтаксис SQL (Hive SQL) и драйвер JDBC, что и Apache Hive. Это делает Impala унифицированной платформой для запросов в режиме реального времени или пакетных запросов
Apache Kyuubi — это распределенный многопользовательский шлюз для предоставления SQL для DWH и DataLake. Kyuubi создает распределенные механизмы запросов SQL поверх различных видов современных вычислительных платформ, например, Apache Spark, Flink, Hive, Impala и т. д., чтобы получать и обрабатывать большие наборы распределенных данных из разнородных источников
Monitoring
Сервис, добавляемый в случаях, когда запланирована настройка мониторинга ADH через ADCM
Apache Ozone (O3) — распределенное хранилище объектов, оптимизированное для работы как с сервисами Hadoop, так и с хранилищами S3. Ozone обладает высокой масштабируемостью, может использовать те же политики безопасности кластера, что и HDFS, и способен эффективно обрабатывать файлы любого размера
Поисковая платформа, основанная на проекте Apache Lucene. Основные функции Solr включают полнотекстовый поиск, фасетный поиск, выделение результатов поиска (highlighting), распределенное индексирование, интеграцию с базами данных, обработку документов со сложными форматами (Word, PDF и так далее), запросы с балансировкой нагрузки, централизованную настройку и другое
Аналитический фреймворк, используемый для быстрой обработки больших объемов данных. Spark3 может работать в кластерах Hyperwave, используя standalone-режим YARN или Spark. Он может обрабатывать данные, поступающие в форматах HDFS, HBase, Cassandra, Hive и любых других форматах, поддерживаемых в Hadoop. Применяется для пакетной обработки и других задач: потоковой передачи, машинного обучения, интерактивных запросов и так далее. Версия Spark 3.x предлагает дополнительные функции: адаптивное выполнение Spark SQL, Dynamic Partition Pruning (DPP), обработку графов, расширенную поддержку Deep Learning и другое
Spark4
Сервис Spark с версией 4.x. Сервис добавлен в режиме технологического превью, может иметь ряд ограничений и не предназначен для использования в производственных средах
Smart Storage Manager — это сервис, цель которого — оптимизировать эффективность хранения и управления данными в Hadoop Distributed File System. SSM собирает данные о работе HDFS и информацию о состоянии системы и на основе собранных показателей может автоматически использовать такие методологии как кеш, политики хранения данных, управление гетерогенными хранилищами (HSM), сжатие данных и Erasure Coding. Кроме того, SSM предоставляет возможность настройки асинхронной репликации данных и пространства имен на резервный кластер с целью организации DR
Trino — это движок SQL-запросов с открытым исходным кодом, используемый для параллельной обработки данных, распределенных по хранилищам разного типа, таких как объектные хранилища (S3), базы данных и файловые системы
Сервис, необходимый для управления ресурсами кластера и планирования/мониторинга задач (jobs). Использует специальный демон (Resource Manager), абстрагирующий все вычислительные ресурсы кластера и управляющий их предоставлением распределенным приложениям
Сервис, который играет роль web-блокнота и обеспечивает интерактивный анализ данных. Позволяет создавать запросы к данным в кластерах Hyperwave и отображать результаты в виде таблиц, графиков, диаграмм и так далее
Сервис централизованного управления распределенными приложениями. Он используется в кластерах Hyperwave для обнаружения сбоев, выбора активных NameNode, мониторинга работоспособности (health checks), управления сеансами и так далее
Минимальный набор сервисов, рекомендуемый для кластеров ADH, приведен ниже:
-
Core configuration;
-
HDFS/Ozone;
-
YARN;
-
Zookeeper (опционально для Community-версии ADH).
Эти сервисы составляют ядро Hadoop и являются достаточными для организации распределенного хранения и обработки данных. Полный перечень сервисов будет зависеть от требований конкретного проекта.
-
-
В результате успешно добавленные сервисы отображаются на вкладке Services.
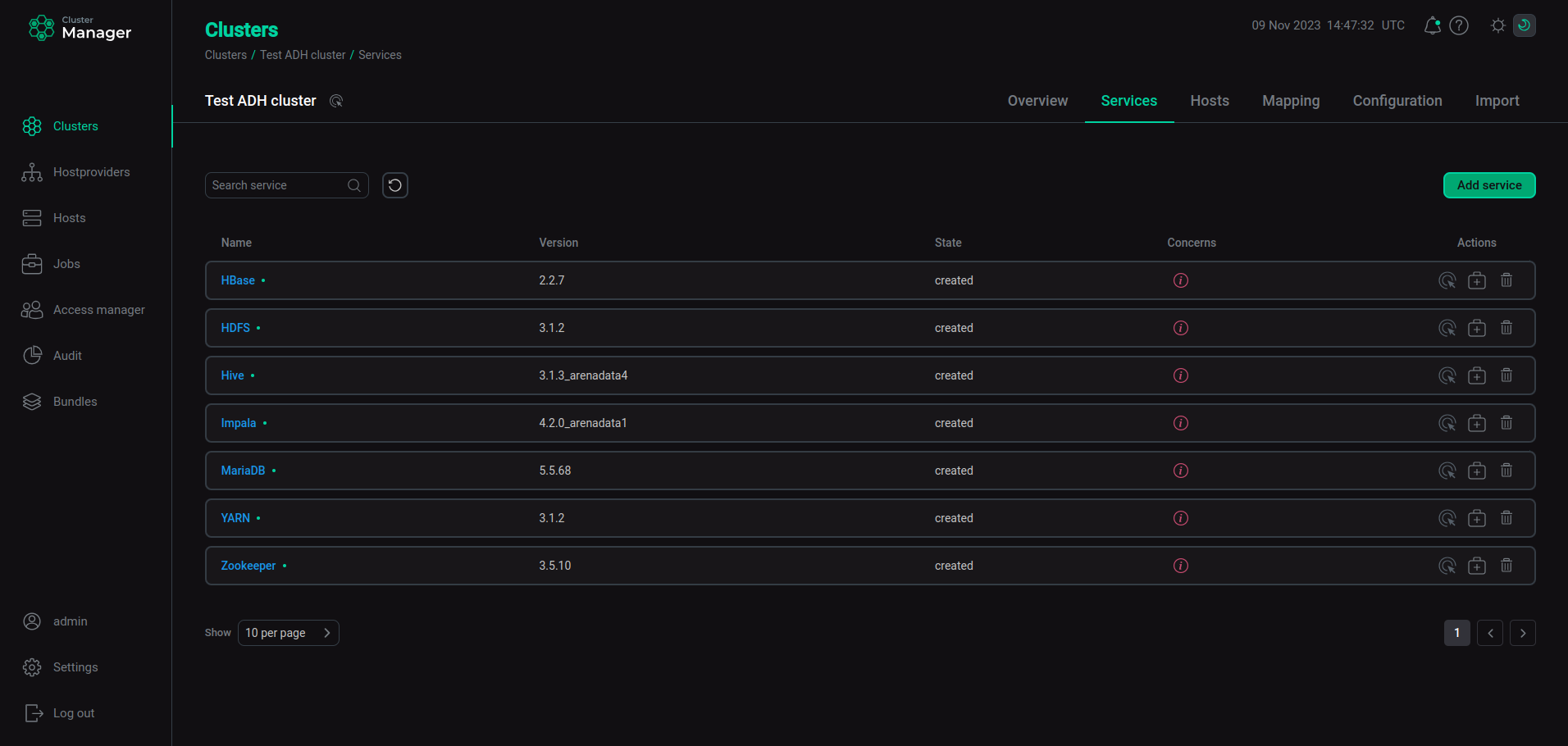 Результат успешного добавления сервисов в кластер
Результат успешного добавления сервисов в кластер
|
ПРИМЕЧАНИЕ
Опциональные сервисы могут быть добавлены в кластер позднее. Процесс добавления сервисов в уже развернутый кластер не отличается от описанного выше.
|