

Дедупликация в Solr
Обзор
Дедупликация в Solr — это процесс выявления и удаления дублирующихся документов в индексе, чтобы гарантировать, что результаты поиска не содержат повторяющихся сущностей. Дублирующиеся записи в индексе Solr, которые представляют одну и ту же бизнес-сущность, приводят к нагромождению результатов поиска и ухудшают эффективность поисковых запросов.
В данной статье описаны два основных способа идентификации дубликатов в индексе Solr:
-
Дедупликация по уникальному ключу. Этот подход основан на предотвращении записи дублирующихся документов с помощью специального поля, которое выступает уникальным идентификатором для каждого документа в коллекции. Такой подход похож на использование первичных ключей (primary key) в традиционных базах данных.
-
Дедупликация с использованием сигнатуры. Данный метод предполагает вычисление сигнатуры (хеша) для каждого документа на этапе индексирования, а также сравнение этих хешей перед добавлением новых документов в коллекцию.
Более подробная информация о каждом подходе приведена ниже.
Дедупликация по уникальному ключу
Конфигурационный параметр uniqueKey определяет поле, по которому Solr может идентифицировать каждый документ в коллекции.
Данный параметр позволяет присвоить уникальный идентификатор каждому документу, тем самым предотвращая попадание дубликатов в индекс.
Если Solr индексирует документ со значением uniqueKey, которое уже присутствует в индексе, Solr перезаписывает старый документ на новый, а не индексирует его как отдельную запись.
Параметр uniqueKey указывается в схеме Solr и по умолчанию определяет поле id в качестве уникального ключа.
По умолчанию определение уникального ключа в файле Solr-схемы имеет следующий вид:
<uniqueKey>id</uniqueKey>Автоматическая генерация ID
При записи документов в индекс Solr без указания поля id (или любого другого поля, используемого в качестве uniqueKey) Solr автоматически генерирует UUID (универсальный уникальный идентификатор) для этого поля, чтобы идентифицировать документ среди других.
Такой UUID уникален в рамках коллекции, однако при его генерации не учитывается содержимое других полей документа.
При индексировании документов без указания uniqueKey вам может понадобиться сохранять автоматически генерируемые UUID, возвращаемые сервером Solr.
В большинстве случаев ответственность за генерацию уникального ключа лежит на клиенте или источнике данных, поставляющем документы в Solr.
Дедупликация с использованием сигнатуры
Другой метод предотвращения дубликатов заключается в вычислении сигнатуры (хеша) для каждого документа на этапе индексирования с последующей проверкой индекса на наличие документа с таким хешем. Если сигнатура уже присутствует в индексе, Solr может либо перезаписать, либо пропустить такой документ. Вычисление сигнатуры можно настроить по одному или нескольким полям, а также указать произвольное поле документа, в котором будет храниться сигнатура документа.
Для реализации данного подхода используются обработчики запросов обновления (update request processors) и алгоритмы хеширования с низким числом коллизий (low collision algorithms) или алгоритмы с нечеткой логикой (fuzzy algorithms).
Solr предоставляет "из коробки" следующие реализации класса Signature, который используется для генерации сигнатуры:
-
MD5Signature — генерирует 128-битный хеш MD5.
-
Lookup3Signature — генерирует 64-битный хеш. Процесс гораздо быстрее, чем у MD5, а также на выходе получается более короткая сигнатура, что оптимально с точки зрения индексирования.
-
TextProfileSignature — реализация хеширования с нечеткой логикой для обнаружения дубликатов, которая лучше всего подходит для длинных текстов.
Пример дедупликации
В следующих шагах рассмотрен базовый сценарий дедупликации на основе сигнатур. Чтобы настроить процесс дедупликации с использованием этого подхода, необходимо редактирование файлов solrconfig.xml и schema.xml, как описано далее.
Шаг 1. Создание тестовой коллекции
Сначала создайте тестовую коллекцию, выполнив следующую команду на хосте с компонентом Solr Server:
$ /usr/lib/solr/bin/solr create -c test_collection -s 1 -rf 1Данная команда создает новую коллекцию (test_collection) с одним шардом (shard) и фактором репликации (replication factor), равным 1.
Коллекция создается с использованием стандартного конфигсета (configset) _default.
Вывод команды:
WARNING: Using _default configset with data driven schema functionality. NOT RECOMMENDED for production use.
To turn off: bin/solr config -c demo_collection_dedup -p 8983 -action set-user-property -property update.autoCreateFields -value false
Created collection 'test_collection' with 1 shard(s), 1 replica(s) with config-set 'test_collection'
Шаг 2. Изменение схемы Solr
В Solr-схеме добавьте новое строковое поле (например, signature), в котором Solr будет хранить сигнатуры каждого документа.
Поле должно иметь свойства stored=true и indexed=true.
Чтобы добавить поле, используйте Solr Admin UI, как показано на рисунке ниже.
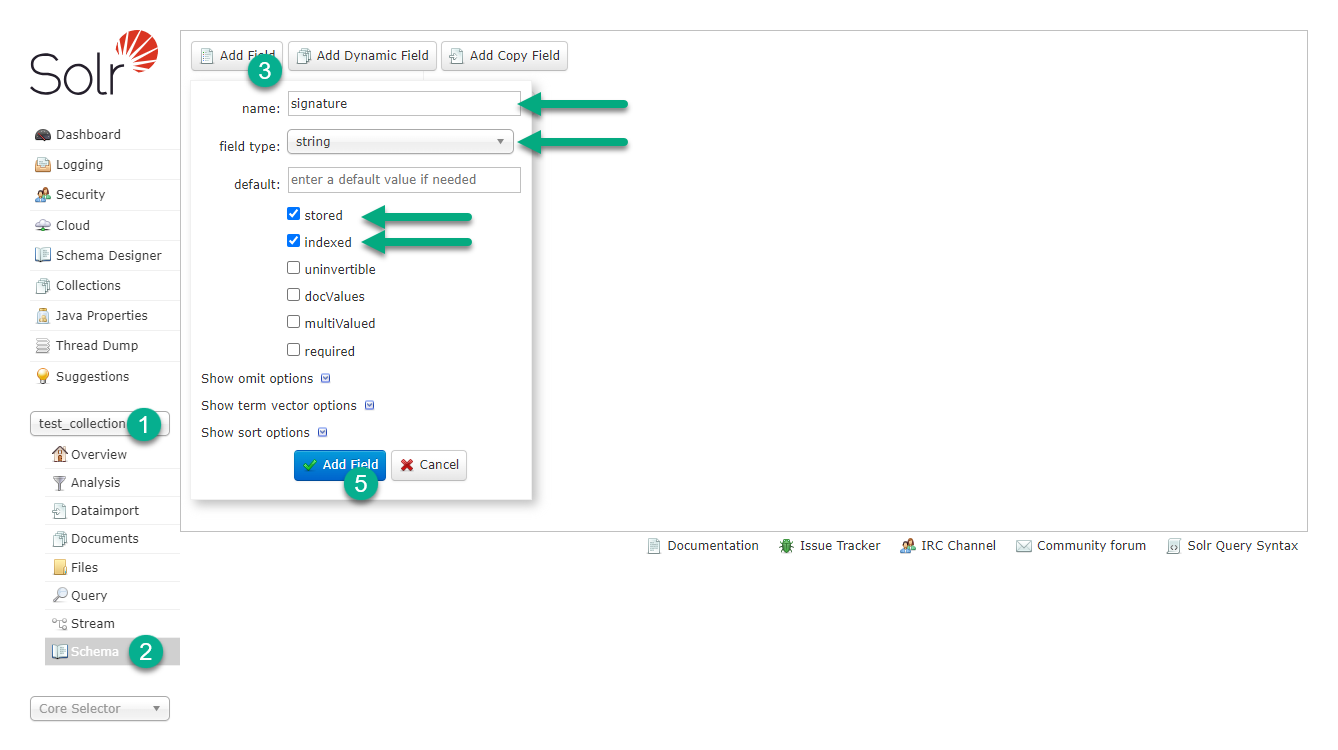
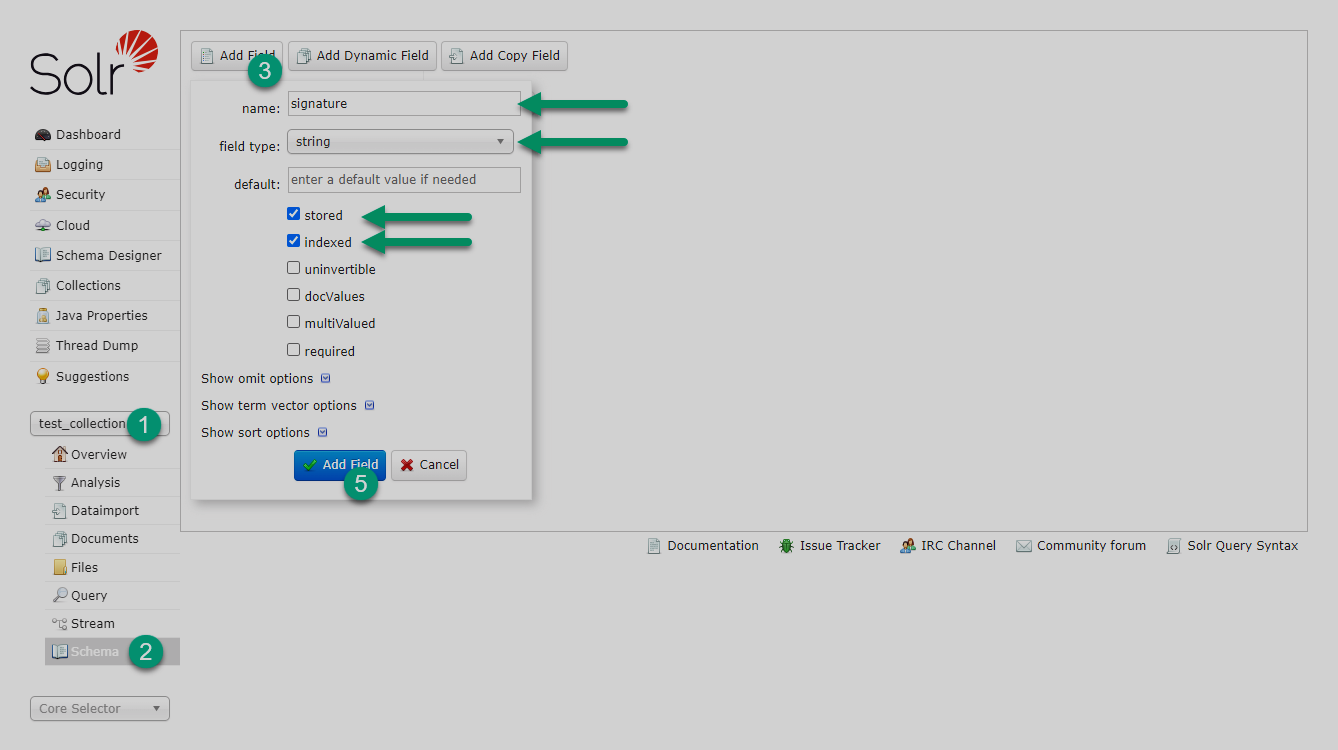
Шаг 3. Изменение файла solrconfig.xml
Поскольку в ADH Solr всегда работает в режиме SolrCloud, конфигурационные файлы, такие как solrconfig.xml, хранятся в ZooKeeper для синхронизации конфигураций между несколькими узлами кластера. Выполните следующие шаги, чтобы обновить solrconfig.xml через ZooKeeper:
-
На хосте с компонентами Solr Server и ZooKeeper Server подключитесь к ZooKeeper через CLI:
$ sudo /usr/lib/zookeeper/bin/zkCli.sh -
В открывшейся оболочке ZooKeeper получите список всех znodes:
$ ls /Вывод:
[zk: localhost:2181(CONNECTED) 4] ls / [Arenadata.Hadoop-11.solr.server, arenadata, hadoop-ha, zookeeper]
В этом примере Arenadata.Hadoop-11.solr.server — это Znode, в котором хранятся все файлы конфигурации Solr. Данный znode понадобится на дальнейших шагах.
-
Загрузите конфигсет из ZooKeeper в локальную файловую систему с помощью команды zk downconfig:
$ /usr/lib/solr/bin/solr zk downconfig -n test_collection -d ~/test_collectionгде:
-
-n test_collection— это имя Solr-конфигурации для тестовой коллекции, хранящейся в ZooKeeper. Полный путь к конфигурации в ZooKeeper выглядит следующим образом: /Arenadata.Hadoop-11.solr.server/configs/test_collection. -
-d ~/test_collection— директория в локальной файловой системе для сохранения конфигурации.
Вывод команды:
Downloading configset test_collection from ZooKeeper at ka-adh-1.ru-central1.internal:2181,ka-adh-2.ru-central1.internal:2181,ka-adh-3.ru-central1.internal:2181/Arenadata.Hadoop-11.solr.server to directory /home/admin/test_collection/conf
-
-
В загруженной директории отредактируйте файл solrconfig.xml, например, с помощью
vi:$ vi test_collection/conf/solrconfig.xml -
Добавьте следующий блок цепочки обработчиков запросов обновления (update request processor chain) в solrconfig.xml:
<updateRequestProcessorChain name="mydedupechain"> (1) <processor class="solr.processor.SignatureUpdateProcessorFactory"> <bool name="enabled">true</bool> <bool name="overwriteDupes">false</bool> (2) <str name="signatureField">signature</str> (3) <str name="fields">txn_id,acc_id,txn_value</str> (4) <str name="signatureClass">solr.processor.Lookup3Signature</str> (5) </processor> <processor class="solr.LogUpdateProcessorFactory" /> <processor class="solr.RunUpdateProcessorFactory" /> </updateRequestProcessorChain>1 Имя цепочки обработчиков запросов обновления. В будущем, при отправке запросов на индексирование в Solr, эту цепочку обработчиков можно будет явно указать по имени. 2 Определяет, следует ли перезаписывать документы с совпадающими сигнатурами. Перезапись работает только если поле uniqueKeyиспользуется в качествеsignatureField. Больше информации доступно в разделе Ограничения дедупликации в режиме SolrCloud.3 Имя поля для хранения вычисляемых сигнатур. В текущем примере соответствующее поле ( signature) было добавлено в схему ранее.4 Одно или несколько полей документов для вычисления сигнатуры документа. 5 Реализация класса Signatureдля генерации хеша. -
Сохраните изменения и загрузите обновленную конфигурацию в ZooKeeper с помощью команды zk upconfig:
$ /usr/lib/solr/bin/solr zk upconfig -n test_collection -d ~/test_collectionВывод:
Uploading /home/admin/test_collection/conf for config test_collection to ZooKeeper at ka-adh-1.ru-central1.internal:2181,ka-adh-2.ru-central1.internal:2181,ka-adh-3.ru-central1.internal:2181/Arenadata.Hadoop-11.solr.server
-
Выполните рестарт Solr-сервиса.
-
Убедитесь, что Solr использует обновленную конфигурацию. Для этого в Solr Admin UI выберите тестовую коллекцию и перейдите в раздел Files. Файлы solrconfig.xml и managed-schema должны содержать обновленную конфигурацию.
Шаг 4. Отправка данных для индексации
На хосте с компонентом Solr Server создайте файл с тестовыми документами, как показано ниже.
[
{
"id": 1,
"txn_id": "1",
"acc_id": 1001,
"txn_value": 75.0,
"comment": "The first transaction."
},
{
"id": 2,
"txn_id": "1",
"acc_id": 1001,
"txn_value": 75.0,
"comment": "Intentionally duplicate transaction record."
}
]Эти два документа описывают одну и ту же бизнес-сущность — транзакцию с идентичными значениями txn_id, acc_id, txn_value и, по сути, являются дубликатами.
Однако у них разные поля id, что заставляет Solr считать их не дубликатами.
Чтобы активировать механизм дедупликации, отправьте тестовые документы в Solr с помощью следующего запроса:
$ curl -X POST 'http://ka-adh-3.ru-central1.internal:8983/solr/demo_collection_dedup/update?commit=true&update.chain=mydedupechain' -H 'Content-Type: application/json' --data-binary @transactions.jsonгде:
-
ka-adh-3.ru-central1.internal— имя хоста, на котором запущен компонент Solr Server; -
update.chain=mydedupechain— имя цепочки обработчиков обновления, через которую следует направить запрос на индексирование.
Вывод:
{
"responseHeader":{
"rf":1,
"status":0,
"QTime":168}}
Теперь выполните запрос, чтобы увидеть проиндексированные документы:
http://ka-adh-3.ru-central1.internal:8983/solr/test_collection/select?indent=true&q.op=OR&q=*%3A*&omitHeader=trueПример вывода:
{
"response": {
"numFound": 2,
"start": 0,
"numFoundExact": true,
"docs": [
{
"id": "1",
"txn_id": [1],
"acc_id": [1001],
"txn_value": [75],
"comment": [
"The first transaction."
],
"signature": "3db4527ba951dcd3",
"_version_": 1.8136481935224996e+18
},
{
"id": "2",
"txn_id": [1],
"acc_id": [1001],
"txn_value": [75],
"comment": [
"Intentionally duplicate transaction record."
],
"signature": "3db4527ba951dcd3",
"_version_": 1.8136481935256453e+18
}
]
}
}Обратите внимание на поле signature, которое идентично для обоих документов, поскольку они содержат почти идентичные данные.
Добавляя сигнатуру в каждый документ, можно легко обнаружить накопившиеся в коллекции дубликаты и при необходимости удалить их.
Ограничения дедупликации в режиме SolrCloud
Хотя Solr предоставляет возможность перезаписывать документы с совпадающими сигнатурами (<bool name="overwriteDupes">true</bool>), эта функция работает только в том случае, если поле uniqueKey используется в качестве SignatureField.
Это ограничение касается режима SolrCloud, в котором Solr функционирует в ADH.
Таким образом, попытка дедупликации с указанием signatureField, отличного от значения параметра uniqueKey, не будет работать корректно из-за коллизий при роутинге обновлений к репликам на других узлах кластера.