

Создание стримингового ETL-пайплайна с помощью Flink
Обзор
В данной статье описан процесс создания стримингового ETL-пайплайна с использованием сервиса Flink (ADH) и других продуктов Arenadata. Ядром демонстрационного пайплайна служит приложение Flink, которое анализирует поток данных (Kafka) в режиме реального времени, извлекает определенные сообщения и направляет их в другой поток при соблюдении условий.
На следующей схеме представлена визуализация пайплайна.


Основные этапы обработки описаны ниже:
-
В PostgreSQL-сервере (ADPG) хранится таблица
transactions, которая имеет следующую структуру:txn_id | acc_id | txn_value | txn_date | txn_type --------+--------+-----------+---------------------+------------ 1 | 1001 | 130.00 | 2025-07-01 10:15:00 | spb 2 | 1002 | -50.00 | 2025-07-02 09:45:00 | withdrawal 3 | 1002 | -50.25 | 2025-07-01 11:00:00 | withdrawal ...| ... | ... | ... | ...Содержимое таблицы постоянно обновляется командами
INSERT/UPDATE/DELETEот внешних клиентов. -
В кластере ADS развернут сервер Kafka. В кластере также установлен CDC-плагин (Debezium), который отслеживает изменения в таблице
transactions. Плагин сканирует write-ahead log (WAL) ADPG на предмет новых записей и отправляет информацию об изменениях в очередь Kafka в виде отдельных сообщений. -
В кластере ADH приложение Flink подписывается на Kafka-топик в ADS, используя Flink-коннектор для Kafka. Flink парсит тело каждого сообщения и, если соблюдается определенное условие (
txn_type=withdrawal), направляет сообщения в специальный топик Kafka.ПРИМЕЧАНИЕВ пайплайне, описанном в данной статье, Flink выполняет простую проверку на наличие определенной строки в теле сообщения. В реальных пайплайнах Flink может использоваться для более глубокого анализа потока данных, позволяя выявлять неочевидные закономерности с помощью stateful-вычислений.
Описанный в данной статье пайплайн построен с использованием следующего программного стека Arenadata.
| Продукт | Версия |
|---|---|
Arenadata Postgres (ADPG) |
|
Arenadata Streaming (ADS) |
|
Arenadata Streaming Control (ADS Control) |
|
Arenadata Hyperwave (ADH) |
Подготовка продуктов Arenadata
Далее показано, как с нуля установить и настроить продукты Arenadata, задействованные в тестовом пайплайне:
ADPG
-
Установите ADPG-кластер, следуя инструкциям в статье Online-установка.
-
Убедитесь, что ADPG-сервис использует порт по умолчанию (
5432) для входящих соединений. -
Создайте роль
demo_user. Для этого запуститеpsqlна хосте с сервисом ADPG:$ sudo su - postgres $ psqlИ затем выполните команду:
CREATE ROLE demo_user WITH LOGIN SUPERUSER PASSWORD 'password'; -
В установленном ADPG-кластере создайте базу данных
demo_db. Для этого выполните командуpsql:CREATE DATABASE demo_db OWNER demo_user; -
В базе данных
demo_dbсоздайте таблицуtransactionsв схемеpublic:\c demo_dbCREATE TABLE transactions ( txn_id BIGINT, acc_id INTEGER, txn_value DOUBLE PRECISION, txn_date TIMESTAMP, txn_type TEXT ); -
Отредактируйте конфигурацию pg_hba.conf, чтобы разрешить доступ к ADPG. Для этого добавьте следующую строку в поле PG_HBA на странице настроек сервиса ADPG:
host demo_db demo_user all trustПРИМЕЧАНИЕДанная запись разрешает TCP/IP-соединения к серверу ADPG с любого IP-адреса, что небезопасно в производственной среде. Для лучшей безопасности явно укажите IP-адреса хостов, которые будут подключаться к серверу ADPG. -
Установите конфигурационный параметр
wal_level=logical. Это добавляет в лог информацию для логического декодирования, что необходимо для работы Debezium. Чтобы установить параметр, укажите его в поле postgresql.conf custom section на странице настроек ADPG-сервиса.
ADS и ADS Control
-
Установите кластер ADS, следуя инструкциям в статье Online-установка. Кластер должен включать сервисы ZooKeeper, Kafka и Kafka Connect.
-
Активируйте конфигурационный параметр Kafka auto.create.topics.enable в секции server.properties. Это необходимо, чтобы Debezium мог автоматически создавать топики Kafka.
-
Установите кластер ADS Control в соответствии с инструкциями.
-
Интегрируйте ADS Control с кластером ADS в соответствии с инструкциями.
-
В веб-интерфейсе ADS Control создайте коннектор Debezium для ADPG согласно инструкциям. Коннектор Debezium, используемый в этом сценарии, имеет следующую JSON-конфигурацию:
{ "connector.class": "io.debezium.connector.postgresql.PostgresConnector", "publication.autocreate.mode": "filtered", "database.user": "demo_user", (1) "database.dbname": "demo_db", (2) "tasks.max": 1, "database.port": 5432, "plugin.name": "pgoutput", "topic.prefix": "postgres", "database.hostname": "10.92.43.174", (3) "database.password": "password", (4) "name": "PostgresConnector", "value.converter": "org.apache.kafka.connect.storage.StringConverter", "key.converter": "org.apache.kafka.connect.storage.StringConverter" }1 Роль PostgreSQL для подключения Debezium к ADPG. 2 База данных ADPG для отслеживания изменений. 3 Адрес сервера ADPG. Используйте IP-адрес вашего ADPG-сервера. 4 Пароль для доступа к ADPG.
В результате Debezium считывает записи WAL-файла ADPG и направляет сообщения в Kafka-топик postgres.public.transactions.
Пример сообщения:
Struct{after=Struct{txn_id=1,acc_id=1001,txn_value=250.0,txn_date=1751364900000000,txn_type=deposit},source=Struct{version=2.7.0.Final,connector=postgresql,name=postgres,ts_ms=1752485024943,snapshot=first,db=demo_db,sequence=[null,"29241720"],ts_us=1752485024943896,ts_ns=1752485024943896000,schema=public,table=transactions,txId=758,lsn=29241720},op=r,ts_ms=1752485025133,ts_us=1752485025133518,ts_ns=1752485025133518357}
ADH
Установите кластер ADH, следуя инструкциям в статье Online-установка. Кластер ADH должен включать следующие сервисы:
-
Core configuration
-
HDFS
-
YARN
-
ZooKeeper
-
Flink
Создание приложения Flink
Ниже описаны шаги по созданию Flink-приложения на Java с помощью Maven.
|
ПРИМЕЧАНИЕ
Подробная информация о создании приложений Flink на Python доступна в статье Примеры использования PyFlink.
|
Установите Maven (если он еще не установлен):
-
Скачайте Maven:
$ wget https://dlcdn.apache.org/maven/maven-3/3.9.10/binaries/apache-maven-3.9.10-bin.tar.gz -P /tmp -
Распакуйте архив:
$ sudo tar -zxf /tmp/apache-maven-3.9.10-bin.tar.gz -C /opt -
Проверьте версию Maven:
$ /opt/apache-maven-3.9.10/bin/mvn -versionПример вывода:
Apache Maven 3.9.10 (5f519b97e944483d878815739f519b2eade0a91d) Maven home: /opt/apache-maven-3.9.10 Java version: 1.8.0_412, vendor: Red Hat, Inc., runtime: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.412.b08-1.el7_9.x86_64/jre Default locale: en_US, platform encoding: UTF-8 OS name: "linux", version: "3.10.0-1160.59.1.el7.x86_64", arch: "amd64", family: "unix"
Установив Maven, выполните следующие шаги для сборки проекта.
-
Создайте новый Maven-проект со следующей структурой:
flink-app-demo │ pom.xml └───src └───main └───java └───io └───arenadata └─KafkaFlinkApp.javaПример тестового pom.xml представлен ниже.
pom.xml<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>io.arenadata</groupId> <artifactId>flink-app-demo</artifactId> <version>1.0-SNAPSHOT</version> <packaging>jar</packaging> <name>Flink-app-demo</name> <properties> <flink.version>1.20.1</flink.version> <kafka.connector.version>3.3.0-1.20</kafka.connector.version> <java.version>1.8</java.version> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-base</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka</artifactId> <version>${kafka.connector.version}</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.17.1</version> </dependency> </dependencies> </project>ПРИМЕЧАНИЕВ данном примере показано, как собрать и запустить приложение Flink в кластере ADH, который уже содержит базовые библиотеки, необходимые для работы Flink-приложений. В зависимости от версии Flink, запуск проекта в IDE (вне кластера ADH) может привести к исключениям
java.lang.NoClassDefFoundErrorиз-за отсутствия базовых зависимостей. Для тестирования Flink-приложения в IDE вне кластера ADH добавьте библиотеки Flink в pom.xml. Пример такого "толстого" pom.xml приведен ниже.pom.xml для запуска в IDE<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>io.arenadata</groupId> <artifactId>flink-app-demo</artifactId> <version>1.0-SNAPSHOT</version> <packaging>jar</packaging> <name>Flink-app-demo</name> <properties> <flink.version>1.20.1</flink.version> <kafka.connector.version>3.3.0-1.20</kafka.connector.version> <java.version>1.8</java.version> <maven.compiler.source>8</maven.compiler.source> <maven.compiler.target>8</maven.compiler.target> </properties> <!-- This dependency is provided, because it should not be packaged into the JAR file. --> <dependencies> <!-- Flink Streaming API --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-base</artifactId> <version>${flink.version}</version> </dependency> <!-- Flink Kafka Connector --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka</artifactId> <version>${kafka.connector.version}</version> </dependency> <!-- Kafka client (optional, provided by connector) --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>3.7.2</version> </dependency> <!-- Flink Core (optional) --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-core</artifactId> <version>${flink.version}</version> </dependency> <!-- Logging (required for output visibility) --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.36</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.17.1</version> </dependency> <!-- To make it work in IntelliJ IDEA: --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-runtime</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-runtime-web</artifactId> <version>${flink.version}</version> <optional>true</optional> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-test-utils</artifactId> <version>${flink.version}</version> <scope>test</scope> </dependency> </dependencies> </project> -
Вставьте следующий код в KafkaFlinkApp.java:
package io.arenadata; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.connector.kafka.sink.KafkaSink; import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema; import org.apache.flink.connector.kafka.source.KafkaSource; import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; public class KafkaFlinkApp { public static void main(String[] args) throws Exception { final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); KafkaSource<String> src_kafka_transactions = KafkaSource.<String>builder() (1) .setBootstrapServers("ka-ads-1.ru-central1.internal:9092,ka-ads-2.ru-central1.internal:9092,ka-ads-3.ru-central1.internal:9092") (2) .setTopics("postgres.public.transactions") (3) .setGroupId("flink-consumer-group") .setStartingOffsets(OffsetsInitializer.earliest()) .setValueOnlyDeserializer(new SimpleStringSchema()) .build(); DataStream<String> stream = env.fromSource(src_kafka_transactions, (4) WatermarkStrategy.noWatermarks(), "Kafka Source"); DataStream<String> filtered = stream.filter(msg -> { (5) boolean isWithdrawal = msg.contains("txn_type=withdrawal"); if (isWithdrawal) { System.out.println("Withdrawal detected in message: " + msg); } return isWithdrawal; }); KafkaSink<String> sink_kafka_withdrawals = KafkaSink.<String>builder() (6) .setBootstrapServers("ka-ads-1.ru-central1.internal:9092,ka-ads-2.ru-central1.internal:9092,ka-ads-3.ru-central1.internal:9092") .setRecordSerializer( KafkaRecordSerializationSchema.<String>builder() .setTopic("postgres.public.transactions.withdrawals") .setValueSerializationSchema(new SimpleStringSchema()) .build()) .build(); filtered.sinkTo(sink_kafka_withdrawals); (7) env.execute("My Flink demo app"); (8) } }1 Объявление KafkaSource в качестве источника (source) входных данных. 2 Список адресов брокеров Kafka для подключения к кластеру ADS. Актуальная строка подключения доступна в ADCM (Clusters → <ADS_cluster> → Services → Kafka → Info). 3 Топик Kafka, из которого приложение будет получать сообщения об изменениях в таблице. Debezium автоматически создает данный топик и направляет в него CDC-сообщения об изменениях в таблице ADPG. 4 Создание объекта DataStreamна основе источника Kafka.5 Создание еще одного DataStream, в который попадают только сообщения, содержащие txn_type=withdrawal. В реальных пайплайнах можно выполнять более глубокий анализ элементов DataStream с помощью продвинутых инструментов Flink API (например, обнаружение последовательности транзакций, совершенных одним аккаунтом за определенный отрезок времени).6 Объявление KafkaSink для отправки данных в Kafka. 7 Отправка содержимого DataStream в ADS. 8 Запуск приложения. -
Скомпилируйте проект:
$ cd flink-app-demo $ /opt/apache-maven-3.9.10/bin/mvn clean package
Запуск пайплайна
-
Перезапустите кластеры ADPG, ADS, ADS Control и ADH.
-
На любом ADH-хосте, где установлен компонент Flink client, запустите приложение Flink:
$ flink run flink-app-demo/target/flink-app-demo-1.0-SNAPSHOT.jarПосле этого JAR-файл приложения передается компоненту JobManager, и далее приложение выполняется на хостах TaskManager. Пример вывода:
Setting HBASE_CONF_DIR=/etc/hbase/conf because no HBASE_CONF_DIR was set. SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/lib/flink/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/lib/hadoop/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Job has been submitted with JobID c917cc83500f4866e3aeb67d1d17dbf7
-
Убедитесь, что приложение успешно запустилось, используя команду
flink listили веб-интерфейс Flink.Пример вывода:
[konstantin@ka-adh-2 ~]$ flink list ------------------ Running/Restarting Jobs ------------------- 14.07.2025 12:36:13 : 57ff8e66a5a76cf80da5b760b44ac0ad : My Flink demo app (RUNNING) -------------------------------------------------------------- No scheduled jobs.
-
Запишите тестовые данные в таблицу ADPG. Для этого запустите
psqlна хосте ADPG-сервера:$ sudo su - postgres $ psqlПодключитесь к тестовой БД и выполните операцию
INSERT:\c demo_dbINSERT INTO public.transactions VALUES (1, 1002, 130.00, '2025-07-14 14:21:00', 'withdrawal'); (2, 1001, 50.00, '2025-07-14 14:22:00', 'deposit'); (3, 1002, 50.25, '2025-07-14 14:23:00', 'spb'); (4, 1003, 75.15, '2025-07-14 14:24:00', 'withdrawal'); -
В веб-интерфейсе ADS Control перейдите на страницу Clusters → <ADS_cluster> → Topics → postgres.public.transactions.withdrawals → Messages, как показано ниже.
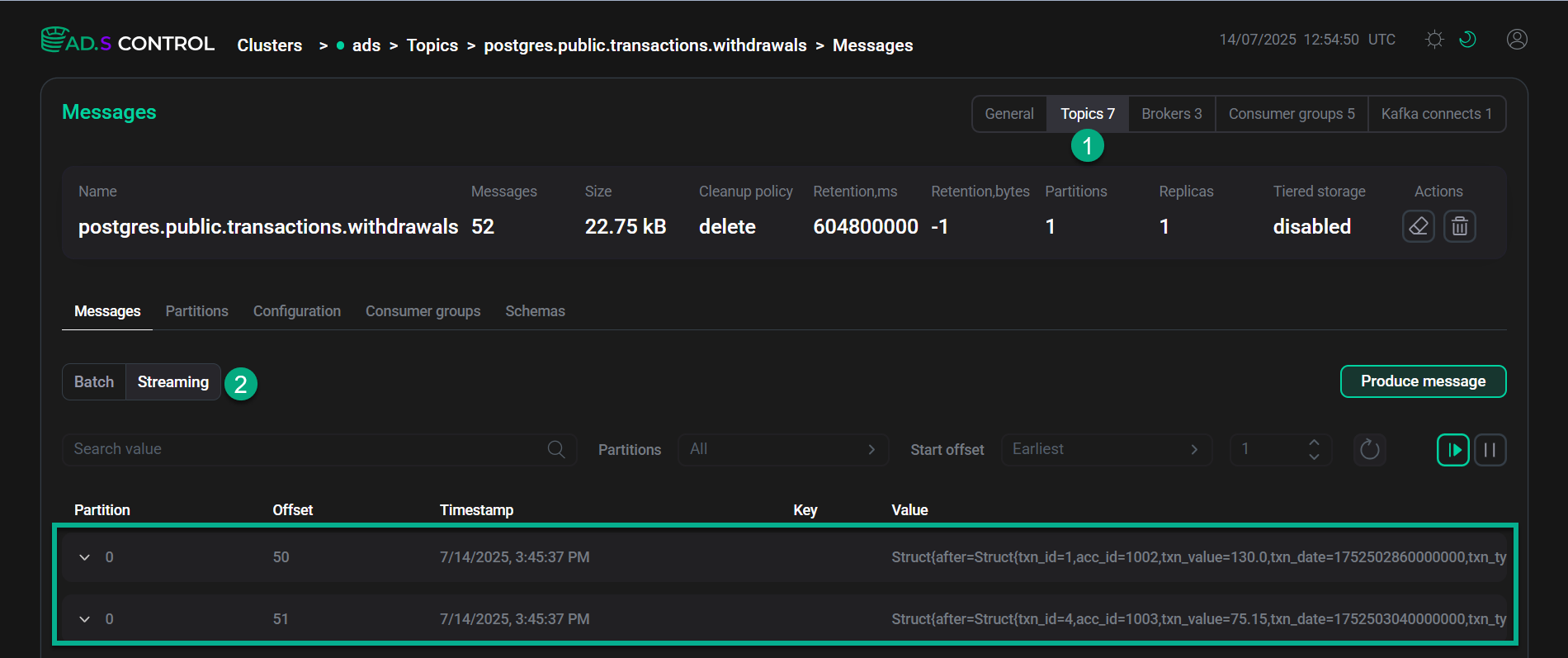 Веб-интерфейс ADS Control
Веб-интерфейс ADS Control
Веб-интерфейс ADS Control
Веб-интерфейс ADS ControlПосле небольшой задержки в топике
postgres.public.transactions.withdrawalsпоявятся 2 сообщения, отфильтрованные Flink по наличиюtxn_type=withdrawal. Проверьте тело сообщений, развернув их в веб-интерфейсе. -
Остановите приложение Flink вручную. Для этого выполните следующие команды на любом ADH-хосте с компонентом Flink client.
Получите ID Flink-приложения:
$ flink listОстановите приложение:
$ flink cancel <application_id>Пример вывода:
Cancelling job c917cc83500f4866e3aeb67d1d17dbf7. Cancelled job c917cc83500f4866e3aeb67d1d17dbf7.