Подключение к Hive через JDBC
В данной статье показаны способы подключения к HiveServer2 с использованием интерфейса JDBC, который является рекомендуемым методом клиентского взаимодействия с Hive. В статье представлены примеры подключения с помощью простой Java-программы, а также с использованием DBeaver — средства работы с базами данных, которое использует JDBC.
Для подключения к Hive в керберизированном кластере необходимо выполнить действия Kerberos, такие как установка клиента Kerberos, получение тикета, настройка krb5.conf и так далее. Больше подробной информации доступно в статье Обзор Kerberos.
Строка JDBC-подключения
Ниже доступны примеры строк JDBC-подключения в зависимости от используемых в ADH-кластере механизмов безопасности. Актуальная для вашего ADH-кластера строка JDBC-подключения доступна на странице Hive Info в ADCM (Clusters → Services → Hive → Info).
Устанавливает соединение в режиме высокой доступности, соединение не защищено:
jdbc:hive2://<cluster_host_0>:2181,<cluster_host_1>:2181,<cluster_host_N>:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=arenadata/cluster/<cluster_id>/<namespace>Устанавливает соединение в HTTP-режиме, соединение не защищено:
jdbc:hive2://<cluster_host_0>:2181,<cluster_host_1>:2181,<cluster_host_N>:2181/;transportMode=http;httpPath=<hive_endpoint>где <hive_endpoint> — это HTTP endpoint, установленный параметром hive.server2.thrift.http.path в hive-site.xml.
Устанавливает соединение в режиме высокой доступности, соединение защищено с помощью SSL:
jdbc:hive2://<cluster_host_0>:2181,<cluster_host_1>:2181,<cluster_host_N>:2181;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=arenadata/cluster/<cluster_id>/<namespace>;ssl=true;sslTrustStore=/tmp/truststore.jks;trustStorePassword=bigdataУстанавливает соединение в режиме высокой доступности, соединение защищено с помощью SSL+Kerberos:
jdbc:hive2://<cluster_host_0>:2181,<cluster_host_1>:2181,<cluster_host_N>:2181;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=arenadata/cluster/<cluster_id>/<namespace>;ssl=true;sslTrustStore=/tmp/truststore.jks;trustStorePassword=bigdata;principal=hive/_HOST@EXAMPLE.COMгде EXAMPLE.COM — ваш Kerberos realm, например RU-CENTRAL1.INTERNAL.
Представленные выше примеры JDBC-подключений предназначены для соединения с HiveServer2 в режиме высокой доступности (High Availability, HA).
Однако вы также можете подключиться к HiveServer2 напрямую, в non-HA режиме, используя порт сервера Thrift (по умолчанию 10000).
В таком случае строка JDBC-подключения имеет вид jdbc:hive2://<cluster_host>:10000/.
Соотношение типов данных JDBC
В таблице ниже описано соответствие типов данных Hive и Java.
| Тип данных Hive | Тип данных Java | Примечание |
|---|---|---|
TINYINT |
byte |
Знаковое/беззнаковое целое число (1 байт) |
SMALLINT |
short |
Знаковое целое число (2 байта) |
INT |
int |
Знаковое целое число (4 байта) |
BIGINT |
long |
Знаковое целое число (8 байт) |
FLOAT |
double |
Число одинарной точности |
DOUBLE |
double |
Число двойной точности |
DECIMAL |
java.math.BigDecimal |
Число с фиксированной точностью |
BOOLEAN |
boolean |
1 бит (0 или 1) |
STRING |
String |
Последовательность символов произвольной длины |
TIMESTAMP |
java.sql.Timestamp |
Значения даты/времени |
BINARY |
String |
Бинарные данные |
ARRAY |
String (json-encoded) |
Значения одного типа |
MAP |
String (json-encoded) |
Пары ключ/значение |
STRUCT |
String (json-encoded) |
Структурированные данные |
Примеры
Java
Следующий Java-код реализует подключение к HiveServer2 с помощью стандартных средств JDBC.
В программе используется класс драйвера org.apache.hive.jdbc.HiveDriver из hive-jdbc-3.1.1-arenadata-standalone.jar, который можно загрузить из Maven-репозитория.
Данный standalone JAR содержит все зависимости, необходимые для использования драйвера на хостах за пределами кластера ADH.
import java.sql.SQLException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.sql.DriverManager;
public class HiveJdbcClient {
private static String driverName = "org.apache.hive.jdbc.HiveDriver"; (1)
public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
System.exit(1);
}
Connection con = DriverManager.getConnection("jdbc:hive2://ka-adh-1.ru-central1.internal:2181," +
"ka-adh-3.ru-central1.internal:2181,ka-adh-2.ru-central1.internal:2181/;serviceDiscoveryMode=zooKeeper;" +
"zooKeeperNamespace=arenadata/cluster/2/hiveserver2", "hive", ""); (2)
// Connection con = DriverManager.getConnection("jdbc:hive2://ka-adh-1.ru-central1.internal:10000/test_db", "hive", ""); (3)
Statement stmt = con.createStatement();
String tableName = "testHiveDriverTable";
stmt.execute("drop table if exists " + tableName);
stmt.execute("create table " + tableName + " (key int, value string)");
// show tables
String sql = "show tables '" + tableName + "'";
System.out.println("Running query: " + sql);
ResultSet res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
}
// other Hive queries
}
}| 1 | Имя класса драйвера. |
| 2 | Строка подключения JDBC для соединения с Hive в режиме высокой доступности. |
| 3 | Строка подключения JDBC для соединения с Hive в non-HA режиме, через порт Thrift-сервера. |
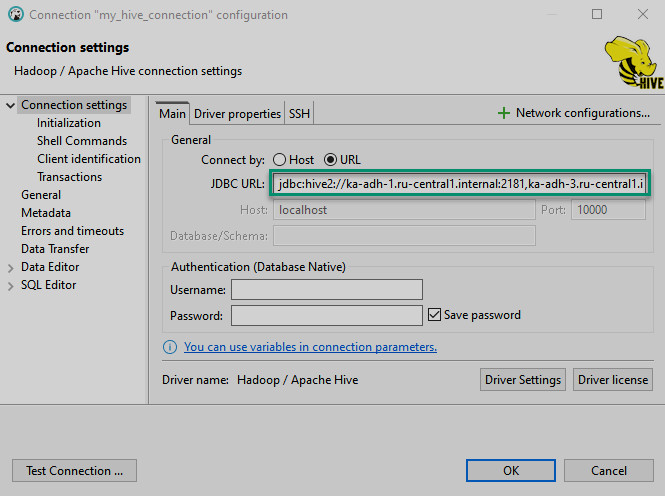
Подключение с помощью DBeaver
DBeaver — это инструмент для работы с базами данных с открытым исходным кодом, который использует интерфейс JDBC для подключения к Hive.
Для подключения к HiveServer2 из DBeaver достаточно указать соответствующую строку подключения JDBC, и Hive автоматически загрузит драйвер по умолчанию org.apache.hive.jdbc.HiveDriver.