

Интеграция HDFS с S3
Обзор
Simple Storage Service (S3) — это объектное хранилище, доступ к которому осуществляется по протоколу типа S3. Отдельный контейнер хранения в объектном хранилище S3 называется бакет. Бакеты могут быть публичными, что означает, что любой может получить доступ к хранилищу, или частными, требующими аутентификации.
Hadoop поддерживает протокол S3A для подключения к хранилищу S3. Это позволяет использовать инструменты командной строки HDFS для взаимодействия с удаленными объектными хранилищами.
В этой статье представлен пример подключения к внешнему хранилищу S3 для копирования данных в локальную HDFS с помощью команды distcp.
Дополнительную информацию о возможных конфигурациях HDFS для работы с хранилищем S3 можно получить в статье Hadoop-AWS module: Integration with Amazon Web Services. Поставщики хранилищ S3 могут поддерживать различные инструменты для подключения к хранилищу. Проконсультируйтесь с вашим провайдером S3 для получения информации о других способах интеграции с хранилищем.
Настройка интеграции с S3
Подготовительные шаги
Убедитесь, что на стороне хранилища создан пользователь для HDFS и у него есть необходимый доступ к файлам. Для прохождения аутентификации потребуются идентификатор ключа доступа (access key ID) и секретный ключ доступа (secret access key).
Если бакет публичный, к нему можно подключиться анонимно.
Зависимости
В ADH есть встроенный коннектор для объектного хранилища — S3A. Для корректной работы коннектора необходимо добавить две дополнительные библиотеки в classpath:
Добавьте эти библиотеки в директорию usr/lib/hadoop/lib/ на хостах кластера.
Аутентификация
Чтобы подключиться к частному бакету S3, необходимо предоставить корректные ключи доступа. При подключении к хранилищу HDFS пробует следующие типы аутентификации в таком порядке:
-
аргументы в URI (предупреждает о возможном нарушении безопасности);
-
конфигурация HDFS;
-
переменные среды AWS;
-
Amazon EC2 Instance Metadata Service.
Дополнительную информацию о настройке каждого типа аутентификации можно получить в статье Hadoop-AWS module: Integration with Amazon Web Services.
|
ВНИМАНИЕ
Потеря учетных данных может поставить под угрозу учетную запись. Убедитесь, что ключи доступа не попадают в логи и баг-репорты. По этой причине избегайте передачи ключей в S3A URL-запросах. |
Для аутентификации с использованием конфигурации HDFS добавьте в core-site.xml параметры из таблице ниже.
| Параметр | Описание | Значение по умолчанию |
|---|---|---|
fs.s3a.access.key |
Идентификатор ключа доступа. Не указывать для анонимного подключения |
— |
fs.s3a.secret.key |
Секретный ключ доступа. Не указывать для анонимного подключения |
— |
fs.s3a.endpoint |
S3-эндпоинт для подключения. Обратитесь к своему провайдеру S3 за информацией о том, какой эндпоинт использовать |
s3.amazonaws.com |
Дополнительные параметры описаны в документации Apache Hadoop — Hadoop-AWS module: Integration with Amazon Web Services.
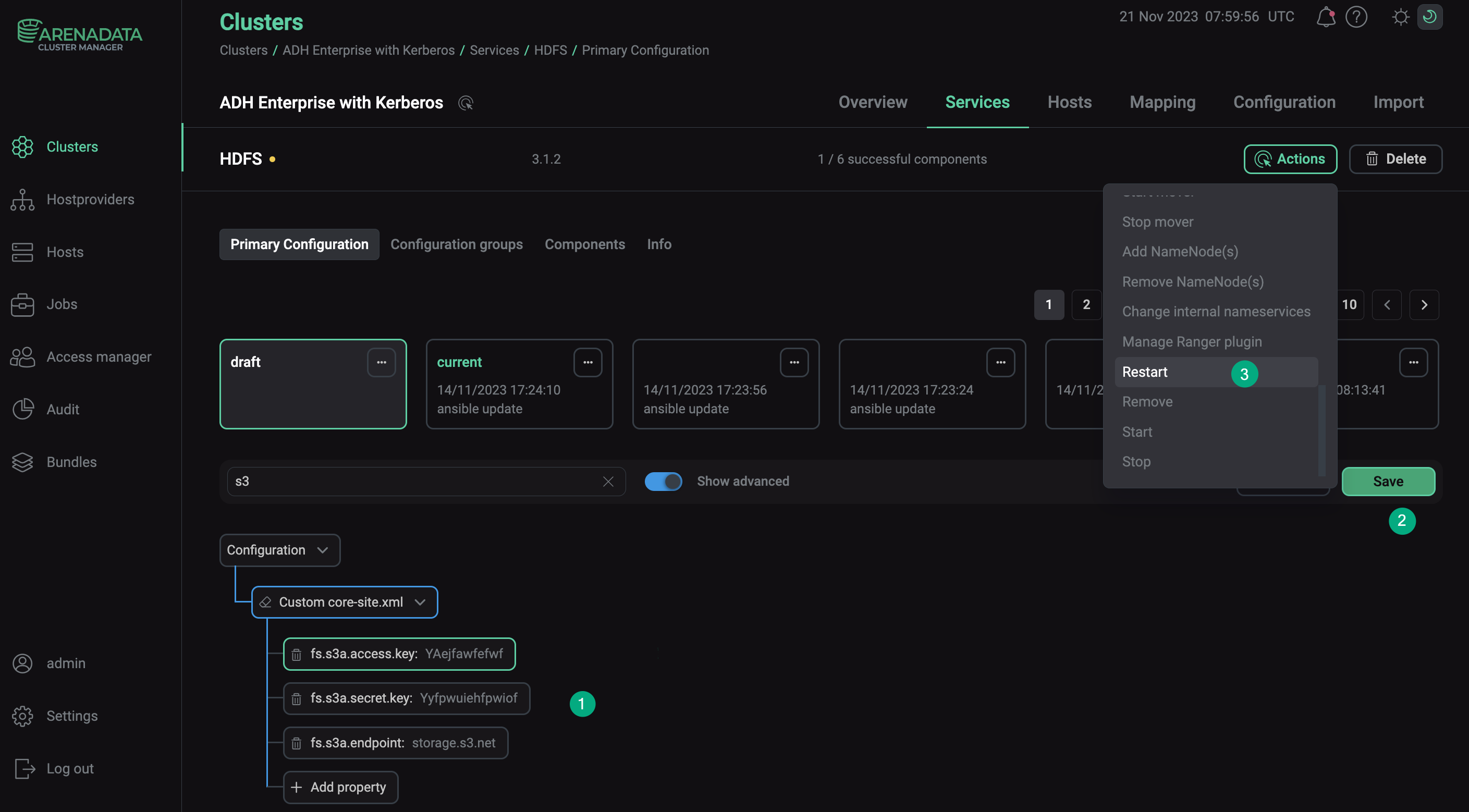
Чтобы настроить эти параметры с помощью ADCM:
-
Перейдите в раздел Clusters и выберите нужный кластер.
-
Перейдите на вкладку Services и нажмите на HDFS.
-
Включите параметр Show advanced, разверните список свойств Custom core-site.xml и выберите Add property.
-
Добавьте необходимый параметр с его значением и нажмите Apply.
-
Подтвердите изменения в конфигурации HDFS, нажав Save.
-
В меню Actions выберите Restart, убедитесь, что для параметра Apply configs from ADCM установлено значение
true, и нажмите Run.
Анонимное соединение
К публичному бакету S3 можно подключиться анонимно. Для этого укажите org.apache.hadoop.fs.s3a.AnonymousAWSCredentialsProvider в качестве значения параметра fs.s3a.aws.credentials.provider.
Эту опцию также можно использовать для проверки того, что бакет недоступен для анонимных пользователей. Для этого выполните команду:
$ hadoop fs -D fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.AnonymousAWSCredentialsProvider \
-ls s3a://<bucket>/Здесь <bucket> — это имя бакета, с которым необходимо установить соединение.
Если доступ без аутентификации запрещен, попытка подключения должна завершиться такой ошибкой:
ls: s3a://develop-test-bucket/: getFileStatus on s3a://develop-test-bucket/: com.amazonaws.services.s3.model.AmazonS3Exception: Access Denied (Service: Amazon S3; Status Code: 403; Error Code: AccessDenied; Request ID: dc82c760b5ab707e; S3 Extended Request ID: null; Proxy: null), S3 Extended Request ID: null:AccessDenied
Подключение к хранилищу
Чтобы проверить подключение к хранилищу, выполните команду -ls:
$ hadoop fs -ls s3a://<bucket>/Здесь <bucket> — это имя бакета, с которым необходимо установить соединение.
Пример вывода:
Found 3 items drwxrwxrwx - admin admin 0 2023-11-14 17:28 s3a://develop-test-bucket/adbm_n1 drwxrwxrwx - admin admin 0 2023-11-14 17:28 s3a://develop-test-bucket/adbm_n2 drwxrwxrwx - admin admin 0 2023-11-14 17:28 s3a://develop-test-bucket/repo
Копирование данных
Копировать данные между HDFS и S3 можно с помощью команды distcp. Чтобы скопировать данные из S3, выполните команду:
$ hadoop distcp \
s3a://<bucket>/<path>/ \
hdfs://<host>/<path>/Здесь:
-
<bucket>— имя бакета, с которым устанавливается соединение; -
<host>— nameservice кластера, FQDN или IP-адрес узла NameNode; -
<path>— путь к копируемым данным или путь для сохранения данных.