

HDFS integration with S3
Overview
Simple Storage Service (S3) is an object storage that can be accessed via the S3-type protocol. A single storage container within S3 object storage is called a bucket. Buckets can be public, which means that anyone can access the storage, or private, which require authentication.
Hadoop supports S3A protocol for connecting to S3 storage. This enables using HDFS command line tools for interacting with remote object storages.
This article provides an example of connecting to an external S3 storage to copy data to local HDFS using the distcp command.
For more information on HDFS configuration for working with an S3 storage, see the Hadoop-AWS module: Integration with Amazon Web Services article. S3 storage providers may support different instruments for connecting to the storage. Consult with your S3 provider for information on other ways of integrating with the storage.
Configure S3 integration
Preparation steps
On the storage side, make sure that the user for HDFS is created and has the right type of access. Passing authentication requires credentials: the access key ID and secret access key.
If the bucket is public, you can access it anonymously.
Dependencies
ADH has a built-in object storage connector — S3A. It requires two additional libraries in the classpath:
Add the libraries to the usr/lib/hadoop/lib/ directory for each host.
Authentication
To connect to a private S3 bucket, a user must provide the correct credentials. When connecting to a storage, HDFS tries the following types of authentication in this order:
-
URI arguments (triggers a warning);
-
HDFS configuration;
-
AWS Environment Variables;
-
Amazon EC2 Instance Metadata Service.
For more information on how to configure each type of authentication, see the Hadoop-AWS module: Integration with Amazon Web Services article.
|
CAUTION
Loss of credentials can compromise the account. Protect your credentials from leaking into logs and bug reports. For this reason, avoid embedding credentials in S3A URLs. |
To authenticate using HDFS configuration, update the core-site.xml according to the table below.
| Parameter | Description | Default value |
|---|---|---|
fs.s3a.access.key |
Access key ID. Do not specify for anonymous connection |
— |
fs.s3a.secret.key |
Secret access key. Do not specify for anonymous connection |
— |
fs.s3a.endpoint |
S3 endpoint to connect to. Consult with your S3 provider for information on what endpoint to use |
s3.amazonaws.com |
Additional properties are described in the Apache Hadoop documentation — Hadoop-AWS module: Integration with Amazon Web Services.
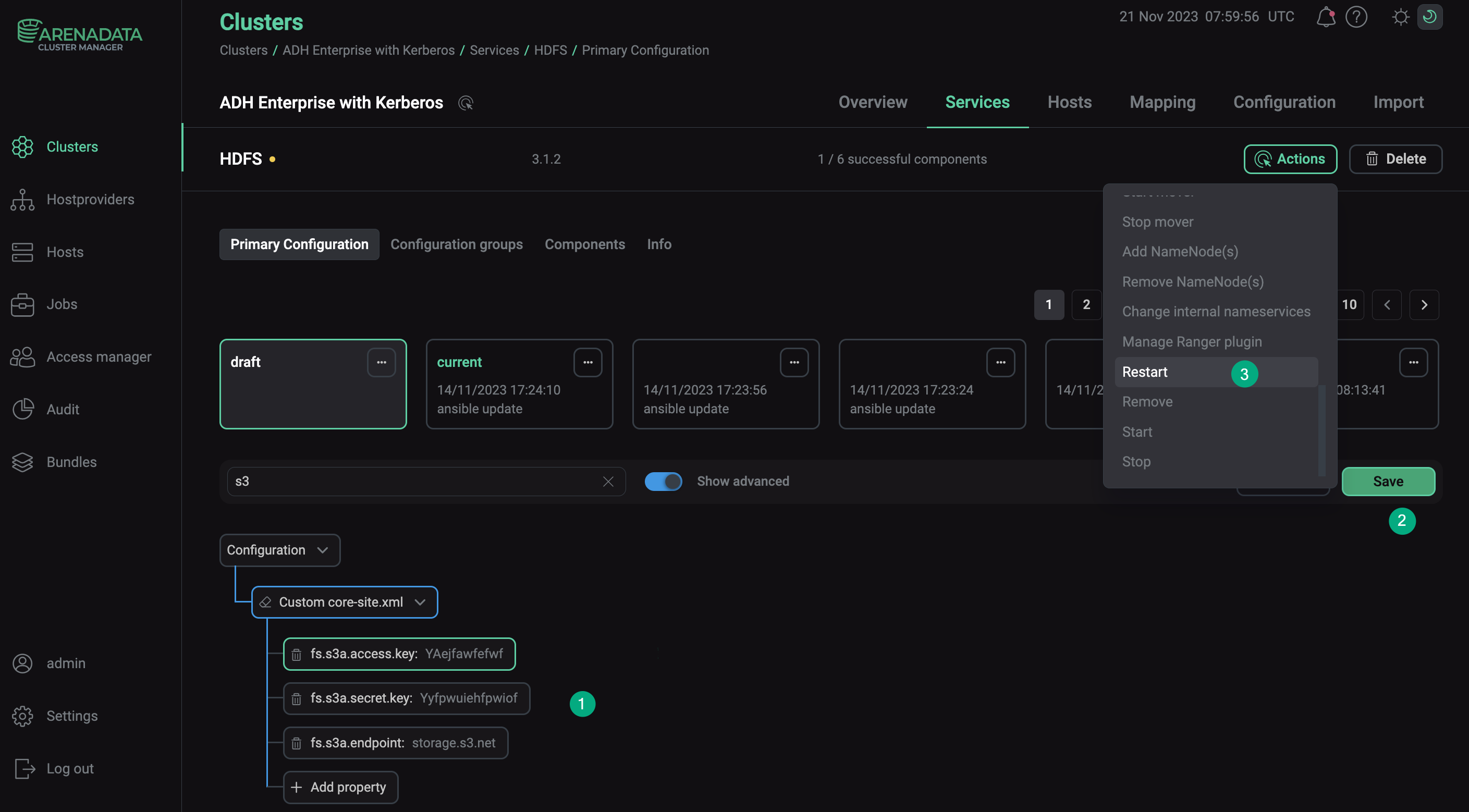
To configure these parameters using ADCM:
-
Navigate to the Clusters section and select the desired cluster.
-
Go to the Services tab and click at HDFS.
-
Toggle the Show advanced option, expand the Custom core-site.xml properties list, and select Add property.
-
Add the required parameter with its value and click Apply.
-
Confirm changes to HDFS configuration by clicking Save.
-
In the Actions drop-down menu, select Restart, make sure the Apply configs from ADCM option is set to
trueand click Run.
Anonymous connection
You can connect to a public S3 bucket anonymously. To do this, specify org.apache.hadoop.fs.s3a.AnonymousAWSCredentialsProvider as the value of the fs.s3a.aws.credentials.provider parameter.
This option can be used to verify that an object storage does not permit unauthenticated access. To do this, run:
$ hadoop fs -D fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.AnonymousAWSCredentialsProvider \
-ls s3a://<bucket>/Where <bucket> is the name of the bucket with which to establish a connection.
If unauthenticated access is prohibited, the connection attempt should fail like this:
ls: s3a://develop-test-bucket/: getFileStatus on s3a://develop-test-bucket/: com.amazonaws.services.s3.model.AmazonS3Exception: Access Denied (Service: Amazon S3; Status Code: 403; Error Code: AccessDenied; Request ID: dc82c760b5ab707e; S3 Extended Request ID: null; Proxy: null), S3 Extended Request ID: null:AccessDenied
Connect to the storage
To test the connection to the storage, run the -ls command:
$ hadoop fs -ls s3a://<bucket>/Where <bucket> is the name of the bucket with which to establish a connection.
Output example:
Found 3 items drwxrwxrwx - admin admin 0 2023-11-14 17:28 s3a://develop-test-bucket/adbm_n1 drwxrwxrwx - admin admin 0 2023-11-14 17:28 s3a://develop-test-bucket/adbm_n2 drwxrwxrwx - admin admin 0 2023-11-14 17:28 s3a://develop-test-bucket/repo
Copy data
You can copy data between HDFS and S3 using the distcp command. To copy data from S3, run:
$ hadoop distcp \
s3a://<bucket>/<path>/ \
hdfs://<host>/<path>/where:
-
<bucket>— the name of the bucket with which to establish a connection; -
<host>— the cluster nameservice or the NameNode host FQDN/IP address; -
<path>— the source and destination paths.