

Kyuubi architecture
Apache Kyuubi is a distributed and multi-tenant JDBC interface for large-scale data processing and analytics. It’s built on top of the Apache Spark engine and is able to run any custom JDBC-compliant tool (such as Hive, Flink, etc.).
It’s designed with purpose to create an SQL gateway for operations on data warehouses and data lakes. Kyuubi implements the Hive Service RPC module, the data access interface used in HiveServer2. For more information about what distinguishes Kyuubi from them, read the Kyuubi vs HiveServer vs Spark Thrift Server article.
Kyuubi’s main features:
-
Multi-tenancy — end-to-end multi-tenancy support for resource acquisition and data access through a unified authentication and authorization layer;
-
High availability — load balancing through ZooKeeper;
-
Multiple workloads — supports multiple different workloads with one platform, one data copy and one SQL interface.
Components
The main Kyuubi component is Kyuubi Server — a daemon process that handles concurrent connections and execution requests from clients and manages their execution.
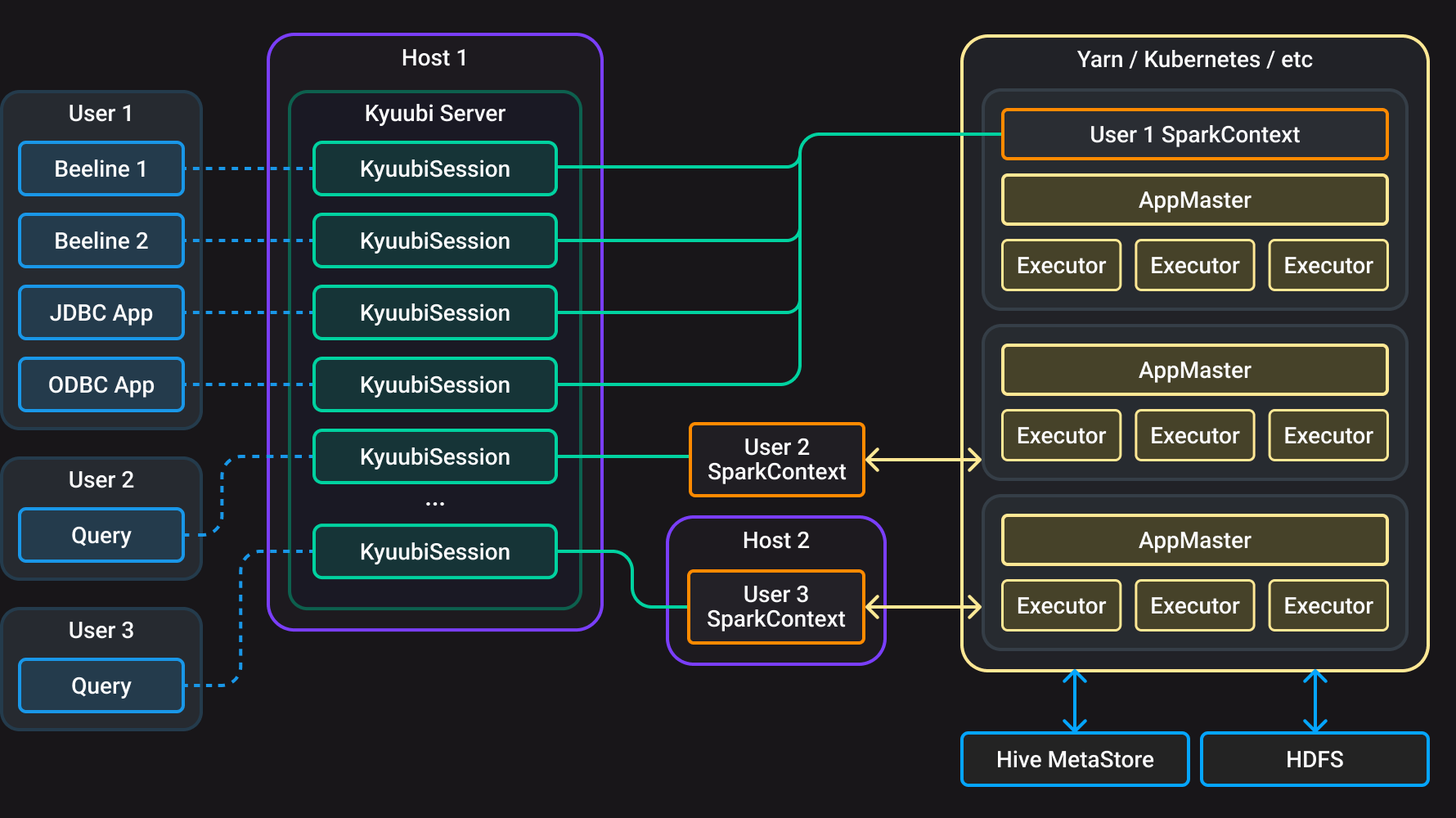
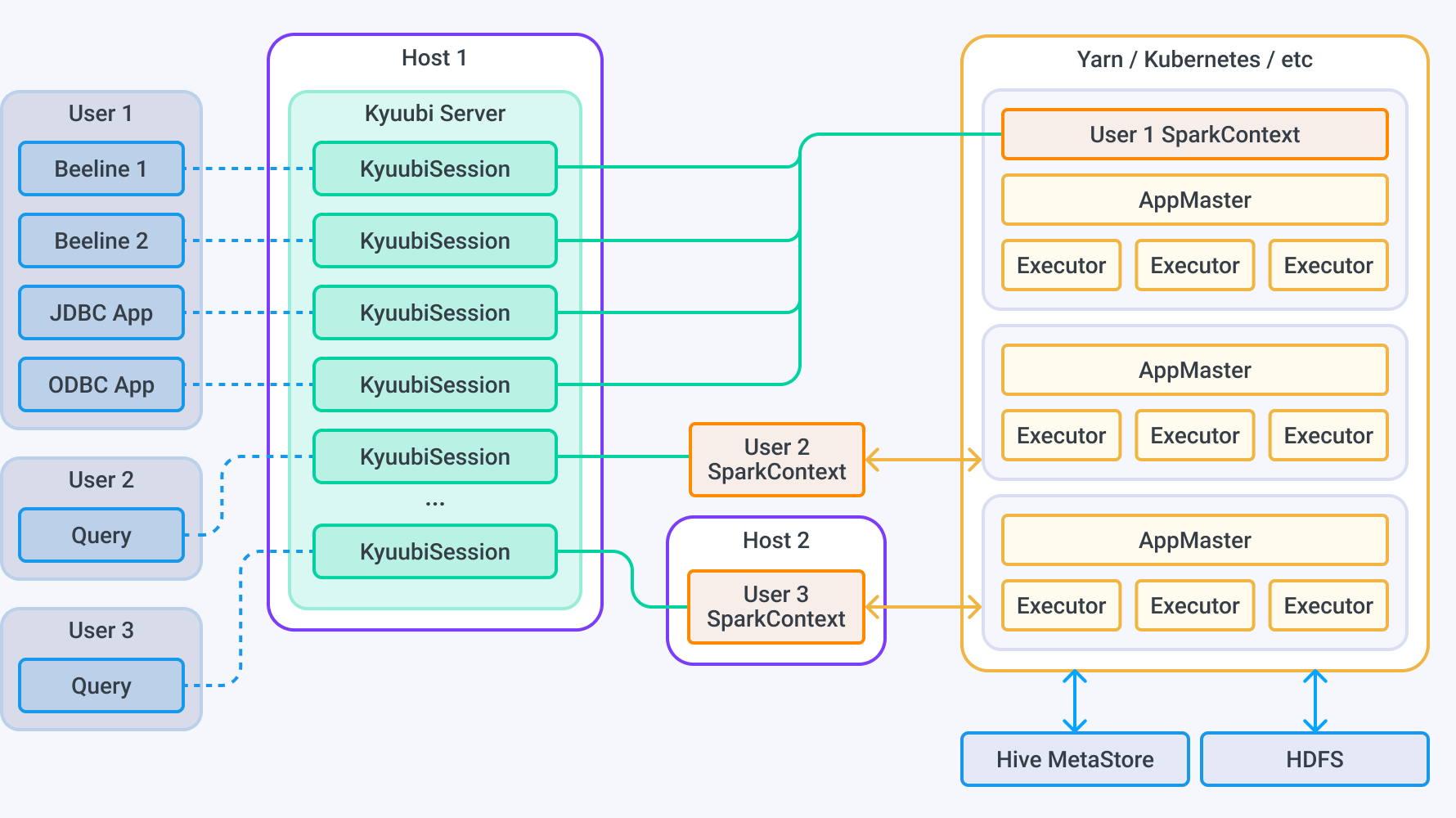
When a user requests access to data via one or several clients, the server creates a Kyuubi session for that user. All of the user’s requests are bound to the corresponding session.
For each session, Kyuubi creates a dedicated SparkContext for processing user requests: to compile, optimize, and execute SQL statements.
SparkContexts can be created locally, in client deploy mode (--deploy-mode client) by this service instance, or in YARN or Kubernetes clusters in cluster deploy mode (--deploy-mode cluster). They can manage their lifecycle, cache and recycle themselves, and are not affected by failover on the Kyuubi server.
If there are no active sessions for a SparkContext, Kyuubi frees its resources.
High availability
Kyuubi provides high availability (HA) and load balancing capabilities based on ZooKeeper.
In HA mode, SparkConexts can be created by several Kyuubi instances and shared between all servers. Kyuubi instances registered to the same namespace provide the ability to load balance each other.
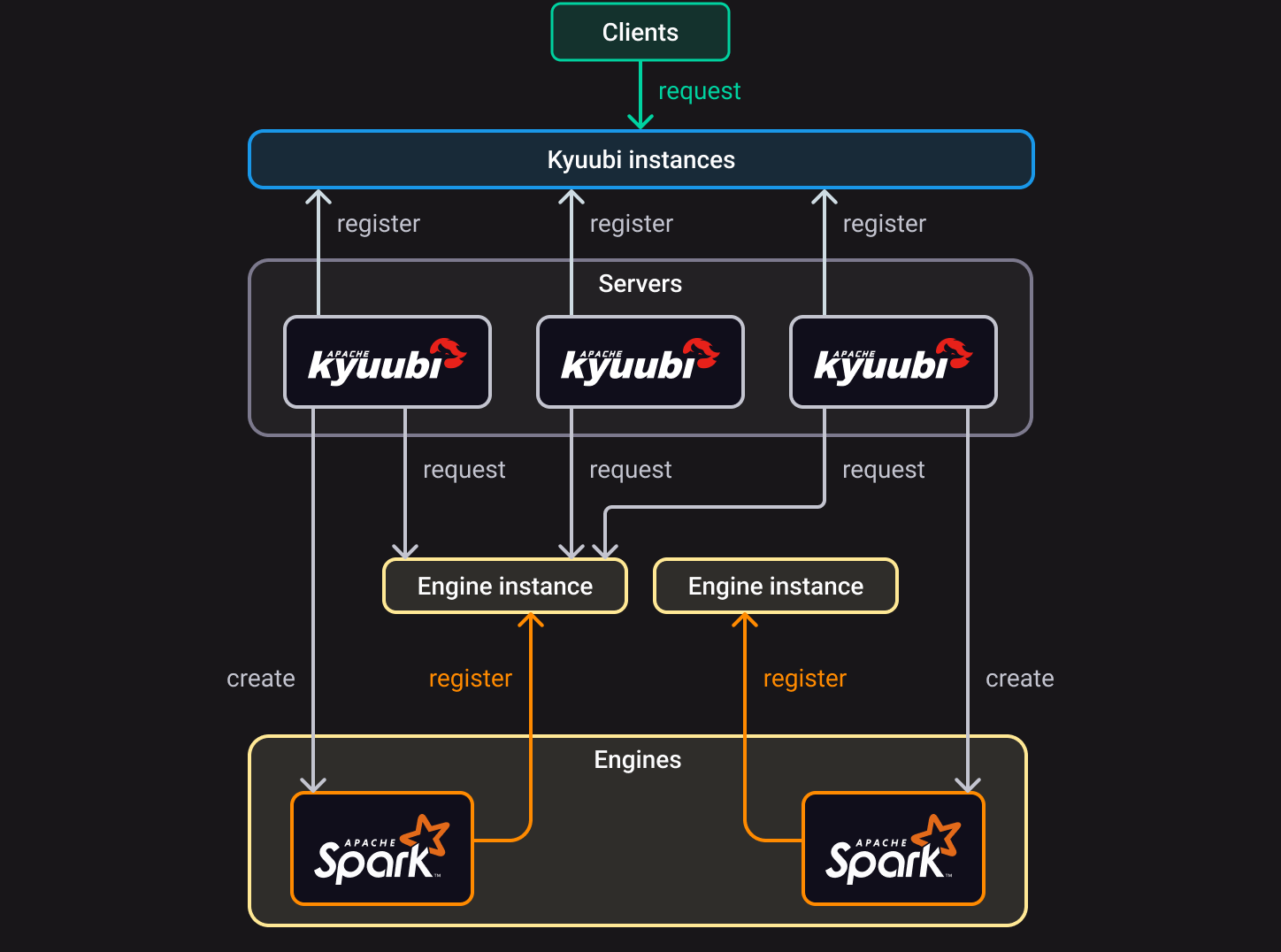
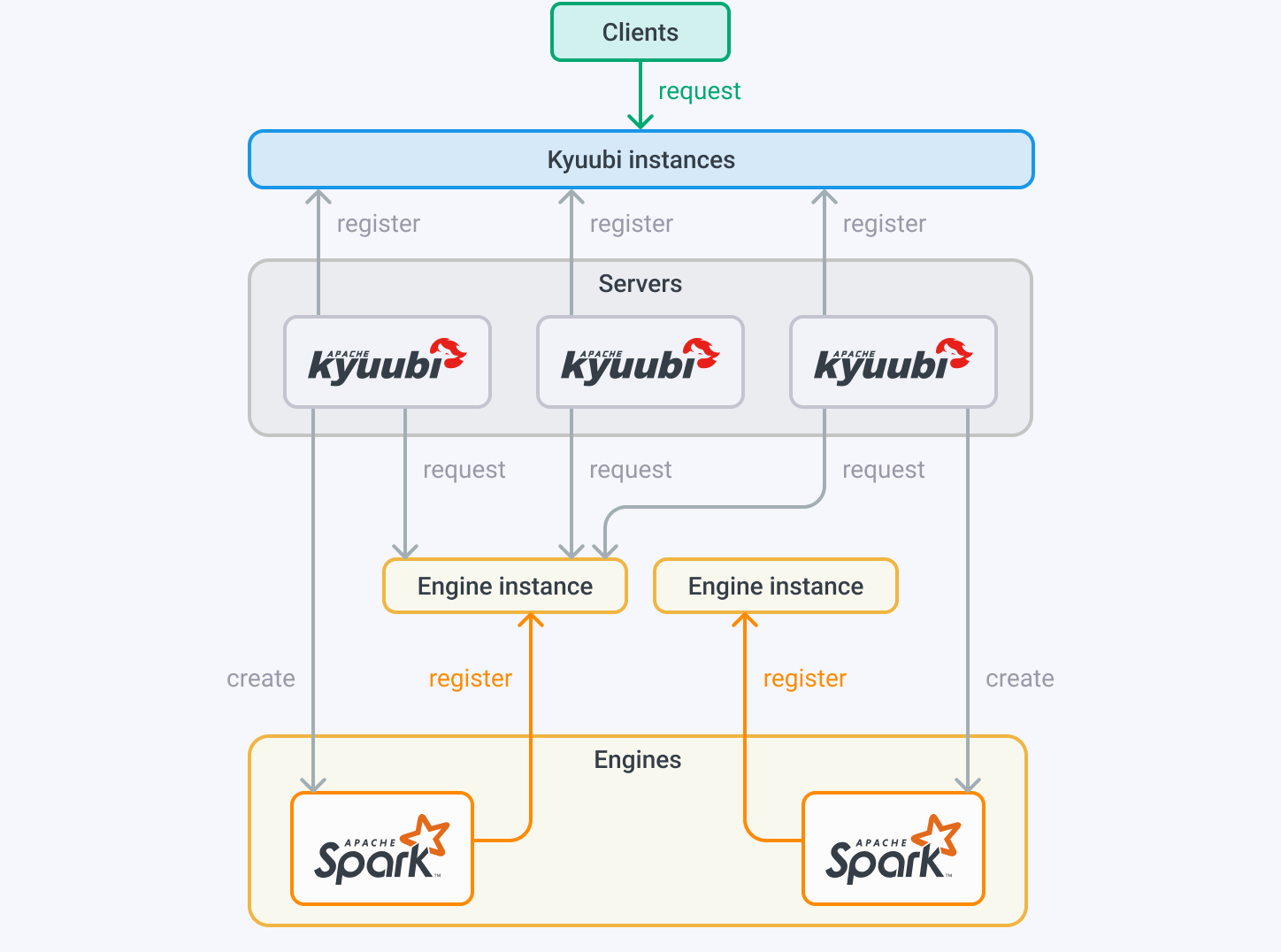
When a client makes a request, it can choose between multiple servers.
The selected Kyuubi instance picks an available SparkContext. If none is available, the server creates a new one.
If the same user requests a new connection, it will be created on the same or another Kyuubi instance, but SparkContext will be reused.
When another user makes a request, the whole process is repeated. When a client chooses a Kyuubi instance, the namespaces used to store the address of the engine instances are isolated based on the user (by default), and different users cannot access other’s instances across the namespace.