

Deduplication in Solr
Overview
Deduplication in Solr refers to the process of identifying and deleting duplicate documents from the index to ensure that only unique entities are returned in search results. Duplicate or near-duplicate documents that appear in a Solr index may result in multiple documents representing the same business entity, leading to cluttered search results and inefficiencies.
This article describes two major techniques for detecting duplicates in a Solr index:
-
Unique key deduplication. This approach relies on preventing duplicate injections based on a document field chosen to be unique among all the documents in a collection. This is very similar to primary keys in traditional databases.
-
Signature-based deduplication. This method assumes calculating a signature (hash) for each document during the indexing phase and comparing the hashes before adding new documents to the collection.
More details about each technique are described below.
Unique key deduplication
In Solr, the uniqueKey configuration property defines a field to uniquely identify each document in a collection.
It ensures that every document has a distinct identifier, preventing duplicate entries from getting into the index.
When a new document is indexed with a uniqueKey value that is already present in the index, Solr replaces the old document with the new one rather than indexing it as a separate record.
The uniqueKey property is set in the Solr schema and by default uses the id field as a unique key.
The default unique key definition in the Solr schema is as follows:
<uniqueKey>id</uniqueKey>Auto-generated IDs
Ingesting documents to Solr without providing the id field (or any other field used as uniqueKey) forces Solr to auto-generate a UUID (universally unique identifier) for that field to identify the document internally.
An auto-generated identifier is a random UUID that guarantees collection-wide uniqueness; however, it is agnostic of the data carried by other document fields.
When ingesting uniqueKey-less documents to Solr, you might want to track the auto-generated UUIDs returned by the Solr server.
However, in most cases, the responsibility to generate a unique key lies with the client or the data source feeding the documents to Solr.
Signature-based deduplication
Another approach to preventing duplicates assumes calculating a signature (hash) for each document during the indexing phase and checking whether the index already contains records with the matching hash. If the calculated signature is already present in the index, Solr can either overwrite or skip such a document. You can configure Solr to calculate the signature based on one or more fields, and specify a custom document field to carry the hash value.
Solr natively supports this approach using update request processors and a low collision or fuzzy hash algorithms.
Out-of-the-box, Solr provides the following implementations of the Signature class used to generate the signature:
-
MD5Signature — generates a 128-bit MD5 hash.
-
Lookup3Signature — generates a 64-bit hash, which is much faster than MD5 and produces a smaller output to index.
-
TextProfileSignature — a fuzzy hash implementation for near-duplicate detection that works best on longer texts.
Deduplication example
The following steps walk you through a basic signature-based deduplication scenario. To configure the deduplication processes using this approach, you have to modify the solrconfig.xml and schema.xml files as described further.
Step 1. Create a test collection
First, create a test collection by running the following command on a host with the Solr Server component:
$ /usr/lib/solr/bin/solr create -c test_collection -s 1 -rf 1This creates a new collection (test_collection) with one shard and the replication factor set to 1.
The collection is created using the default _default configset.
The output:
WARNING: Using _default configset with data driven schema functionality. NOT RECOMMENDED for production use.
To turn off: bin/solr config -c demo_collection_dedup -p 8983 -action set-user-property -property update.autoCreateFields -value false
Created collection 'test_collection' with 1 shard(s), 1 replica(s) with config-set 'test_collection'
Step 2. Modify a Solr schema
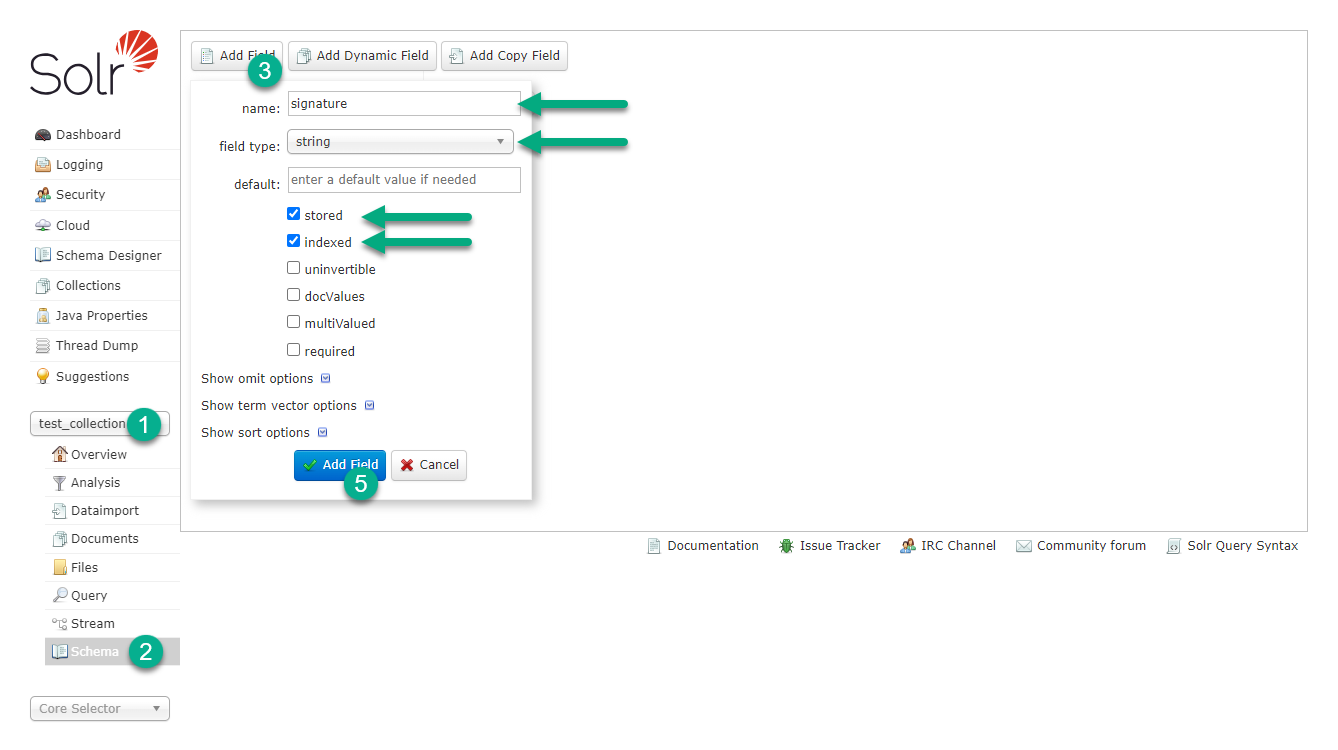
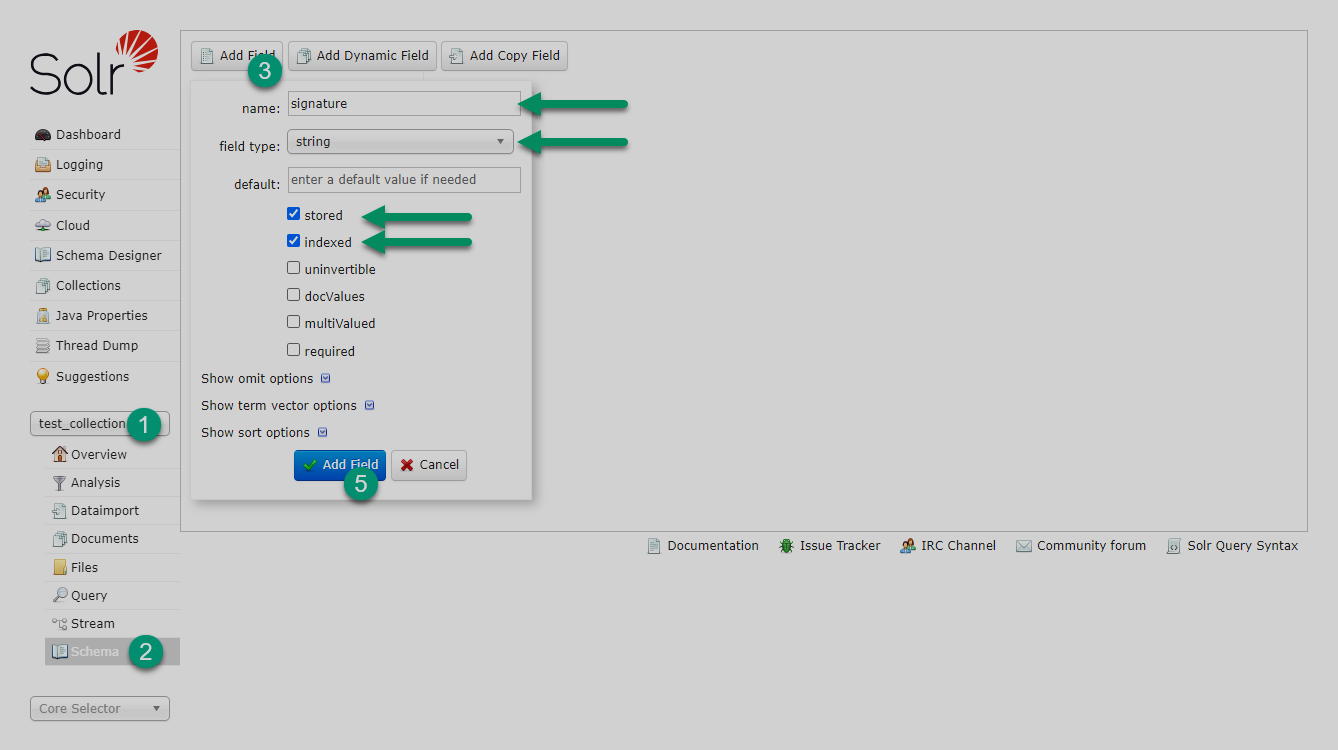
In the Solr schema, define a new string field (for example, signature) where Solr will store hash values calculated for each document.
The field must have the stored=true and indexed=true properties.
To create the field, use Solr Admin UI as shown in the image below.
Step 3. Modify solrconfig.xml
Since in ADH Solr always runs in the SolrCloud mode, the configuration files like solrconfig.xml are managed by ZooKeeper to sync configs among several cluster nodes. Follow the steps below to update solrconfig.xml via ZooKeeper:
-
On the host with the Solr server and ZooKeeper server components, connect to ZooKeeper via CLI:
$ sudo /usr/lib/zookeeper/bin/zkCli.sh -
In the opened ZooKeeper shell, list all the znodes:
$ ls /The output:
[zk: localhost:2181(CONNECTED) 4] ls / [Arenadata.Hadoop-11.solr.server, arenadata, hadoop-ha, zookeeper]
In this example, Arenadata.Hadoop-11.solr.server is the znode under which all Solr configuration files are stored. It will be needed on further steps.
-
Download the Solr configset from ZooKeeper to the local file system using the zk downconfig command:
$ /usr/lib/solr/bin/solr zk downconfig -n test_collection -d ~/test_collectionwhere:
-
-n test_collectionis the name of the Solr configuration for the test collection in ZooKeeper. The full ZooKeeper path to the configuration is /Arenadata.Hadoop-11.solr.server/configs/test_collection. -
-d ~/test_collectionis the path to a local directory to save the configuration.
The command output is as follows:
Downloading configset test_collection from ZooKeeper at ka-adh-1.ru-central1.internal:2181,ka-adh-2.ru-central1.internal:2181,ka-adh-3.ru-central1.internal:2181/Arenadata.Hadoop-11.solr.server to directory /home/admin/test_collection/conf
-
-
In the downloaded configuration directory, edit the solrconfig.xml file, for example, using
vi:$ vi test_collection/conf/solrconfig.xml -
Add the following update request processor chain definition to solrconfig.xml:
<updateRequestProcessorChain name="my-dedup"> (1) <processor class="solr.processor.SignatureUpdateProcessorFactory"> <bool name="enabled">true</bool> <bool name="overwriteDupes">false</bool> (2) <str name="signatureField">signature</str> (3) <str name="fields">txn_id,acc_id,txn_value</str> (4) <str name="signatureClass">solr.processor.Lookup3Signature</str> (5) </processor> <processor class="solr.LogUpdateProcessorFactory" /> <processor class="solr.RunUpdateProcessorFactory" /> </updateRequestProcessorChain>1 Specifies a name for the processor chain. Later, when submitting an indexing request, this processor chain can be explicitly called by name. 2 Tells Solr whether to overwrite documents with matching signatures. Overwriting works only if uniqueKeyis used assignatureField. For more information, see Deduplication restrictions in SolrCloud.3 Specifies the field name to store calculated signatures. In this scenario, the corresponding field has already been defined in the schema. 4 Specifies one or more document fields to calculate the signature. 5 The Signatureclass implementation to use. -
Save the file and upload the modified configuration to ZooKeeper using the zk upconfig command:
$ /usr/lib/solr/bin/solr zk upconfig -n test_collection -d ~/test_collectionThe output:
Uploading /home/admin/test_collection/conf for config test_collection to ZooKeeper at ka-adh-1.ru-central1.internal:2181,ka-adh-2.ru-central1.internal:2181,ka-adh-3.ru-central1.internal:2181/Arenadata.Hadoop-11.solr.server
-
Restart the Solr service.
-
Verify that Solr has picked up the updated configuration. For this, in Solr Admin UI, select the test collection and go to Files. The solrconfig.xml and managed-schema files must contain the updated configuration.
Step 4. Submit data for indexing
On a host with the Solr Server component, create a file with test documents as shown below.
[
{
"id": 1,
"txn_id": "1",
"acc_id": 1001,
"txn_value": 75.0,
"comment": "The first transaction."
},
{
"id": 2,
"txn_id": "1",
"acc_id": 1001,
"txn_value": 75.0,
"comment": "Intentionally duplicate transaction record."
}
]The two documents refer to the same business entity — a transaction with identical txn_id, acc_id, txn_value fields.
However, the documents have different id values, which makes Solr treat them as non-duplicates.
To engage the deduplication mechanism, submit the test documents to Solr using the following request:
$ curl -X POST 'http://ka-adh-3.ru-central1.internal:8983/solr/demo_collection_dedup/update?commit=true&update.chain=mydedupechain' -H 'Content-Type: application/json' --data-binary @transactions.jsonwhere:
-
ka-adh-3.ru-central1.internal— the name of the host with a running Solr server component; -
update.chain=mydedupechain— the name of the update request processor chain to route the indexing request through.
The sample response:
{
"responseHeader":{
"rf":1,
"status":0,
"QTime":168}}
Now query Solr to view the indexed documents:
http://ka-adh-3.ru-central1.internal:8983/solr/test_collection/select?indent=true&q.op=OR&q=*%3A*&omitHeader=trueThe response:
{
"response": {
"numFound": 2,
"start": 0,
"numFoundExact": true,
"docs": [
{
"id": "1",
"txn_id": [1],
"acc_id": [1001],
"txn_value": [75],
"comment": [
"The first transaction."
],
"signature": "3db4527ba951dcd3",
"_version_": 1.8136481935224996e+18
},
{
"id": "2",
"txn_id": [1],
"acc_id": [1001],
"txn_value": [75],
"comment": [
"Intentionally duplicate transaction record."
],
"signature": "3db4527ba951dcd3",
"_version_": 1.8136481935256453e+18
}
]
}
}Notice the signature field, which is identical for both documents as they carry almost identical data.
Having your documents tagged with signatures, you can easily detect duplicates in your collection and delete them if needed.
Deduplication restrictions in SolrCloud
Although Solr provides an option to overwrite documents with matching signatures (<bool name="overwriteDupes">true</bool>), this feature works only if the uniqueKey field is used as signatureField.
This restriction applies to the SolrCloud which is how Solr works in ADH.
Thus, attempting deduplication with signatureField other than uniqueKey will not work correctly due to the collisions when routing updates to replicas on other cluster nodes.