

Reindex data in Solr
In Solr, reindexing is the process of deleting all the content from a Solr index followed by re-ingesting the data from a data source (database, file, or other data storage) to build a fresh index. It is important that all the documents and Lucene segments have to be dropped in order to avoid collisions during the re-creation of an index.
This article lists common situations when reindexing is required and describes popular reindexing strategies. The major challenges while performing reindexing are possible downtime and performance impact. Reindexing large datasets is a time-consuming and resource-intensive process that may lead to a temporary collection downtime or inconsistent results returned by search queries. Techniques like aliasing described in the article can help mitigate this.
Cases when reindexing is required
Below are some common cases that require a full reindexing of a collection. For other cases, using partial updates may suffice.
Schema updates
Changing the schema of a Solr collection (for example, modifying field types, adding new fields, or changing the way how fields are analyzed) almost always requires full reindexing.
This requirement derives from the design of the underlying Lucene search engine. Lucene segments that actually store raw data are immutable, meaning that once a segment is written to disk, it cannot be changed. The segments can be added, merged, deleted, but not altered. Lucene segments are loosely coupled with the Solr schema since the schema is a Solr-only concept. The schema file only tells Solr how the data should be placed into a Lucene index and how it should be queried later. After the data is written into a Lucene index, Solr’s schema has no control over the stored data structures.
Data updates
If the source data has been significantly updated or changed (for example, due to bulk updates or corrections), it might be more efficient to reindex the entire dataset rather than applying updates incrementally.
Corrupted index
If a Solr index becomes corrupted or some documents get indexed incorrectly, reindexing can restore the index to a consistent state.
Performance improvements
Changes to indexing settings (such as tokenization, filters, or analyzers) or optimizations may require reindexing to take effect. The rule is the same: if you update the settings related to writing data into the index, reindexing is necessary; updating the query-time logic does not necessarily require reindexing.
Reindexing strategies
There are two major reindexing strategies described below. These strategies help to ensure that the Lucene index is completely empty before re-ingesting data into it.
Delete all documents
The first approach assumes manually deleting all documents from the target Solr index. For example, you can delete all documents from a collection by submitting the following request:
$ curl http://ka-adh-1.ru-central1.internal:8983/solr/test_collection/update?commit=true -H "Content-Type: application/json" --data-binary '{"delete": { "query": "*:*" }}'where:
-
ka-adh-1.ru-central1.internal— the name of the host with running Solr server; -
test_collection— the name of the collection to purge.
Sample response:
{
"responseHeader":{
"rf":1,
"status":0,
"QTime":40}}
|
TIP
After the delete operation, perform another search query to verify that all the documents have been deleted from the collection, as that ensures the Lucene index segments have been deleted as well.
|
To verify that there are no Lucene segments left in your index, check the collection’s {SOLR_HOME}/<collection_name>_*/data/index/ directory and confirm it has no segment files. It is necessary to verify that the index data has been removed in every shard and every replica of your Solr cluster. To locate Lucene shards and replicas that belong to a given collection, use the Solr UI page as shown in the image.
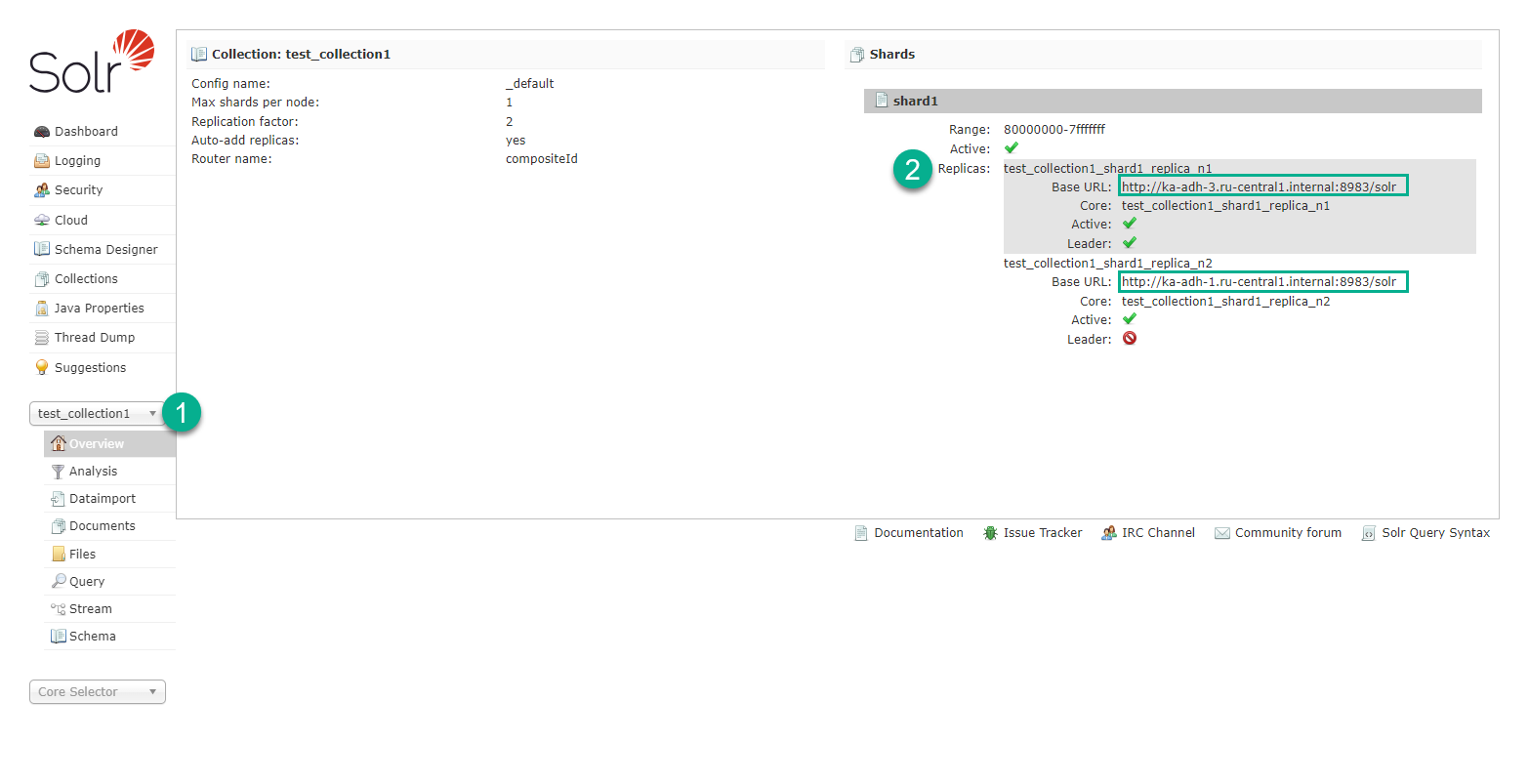
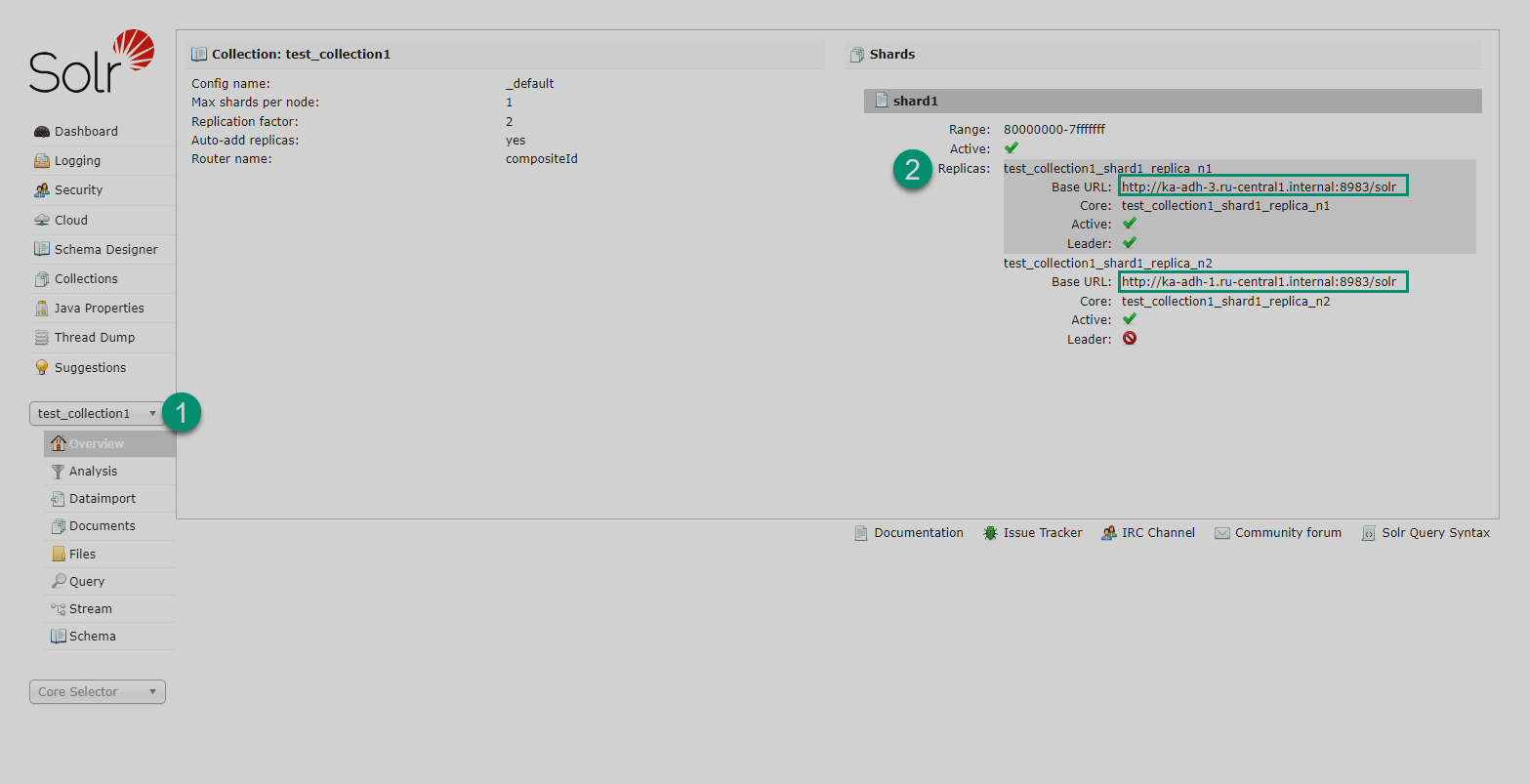
Then, connect to each host that stores shards and replicas and run the command:
$ ls -l /srv/solr/server/test_collection_*/data/indexwhere:
-
/srv/solr/server/is the default location where Solr stores index data (SOLR_HOME); -
test_collectionis the collection name.
The following output indicates that the collection data has been deleted and the index is empty:
[admin@ka-adh-3 ~]$ ls -l /srv/solr/server/test_collection_*/data/index total 4 -rw-r--r--. 1 solr solr 135 Oct 11 12:37 segments_7 -rw-r--r--. 1 solr solr 0 Oct 11 09:00 write.lock
The segments_N and write.lock files are auxiliary and should not be deleted during the reindexing. If this is the state of your data/index/ directory, your collection is ready for re-ingesting the data.
|
IMPORTANT
Do not delete files manually in the data/index/ directory as this will likely lead to an index corruption.
|
The major disadvantage of this approach is possible downtime or inconsistent search results during the re-ingesting of the fresh data. The next described approach can mitigate this.
Index to another collection
Another approach to reindexing involves using the collection alias feature that allows routing client applications to a different collection through an alias without downtime.
By following this approach, the simplified reindexing flow comprises the following steps:
-
Create a new collection. The old collection that requires reindexing continues its operation.
-
Index fresh data into the new collection.
-
After the indexing is complete, create an alias that routes your client application requests to the new collection. You can create a collection alias using Solr web UI as shown in the image below.
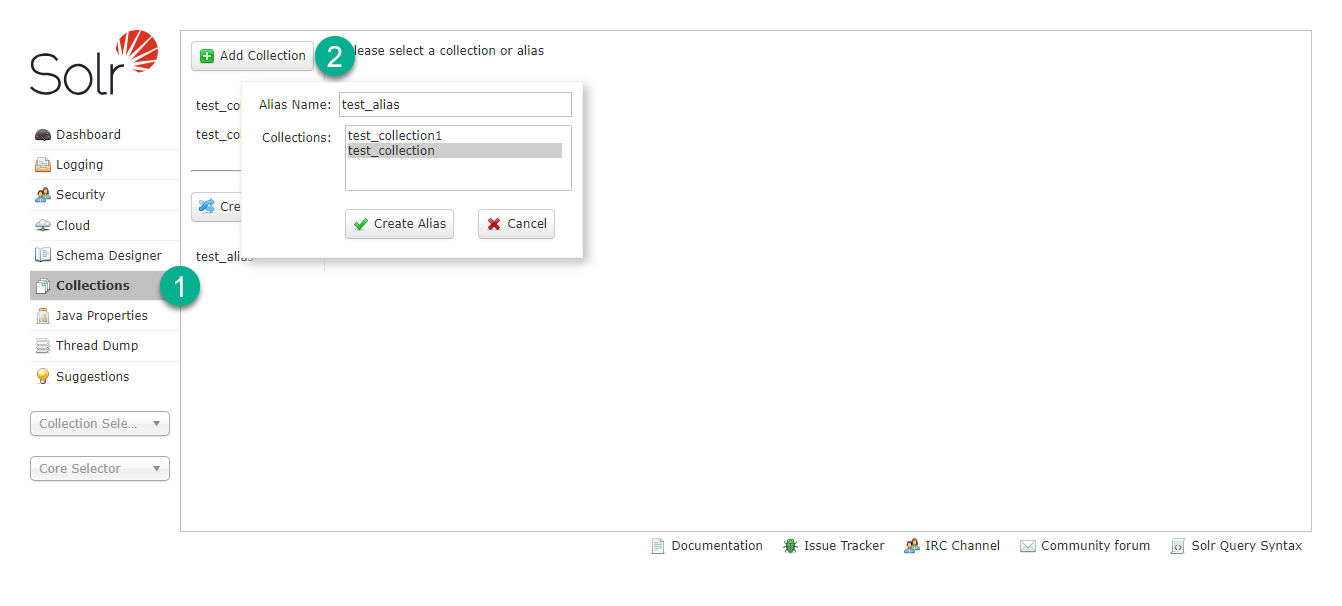 Create alias
Create alias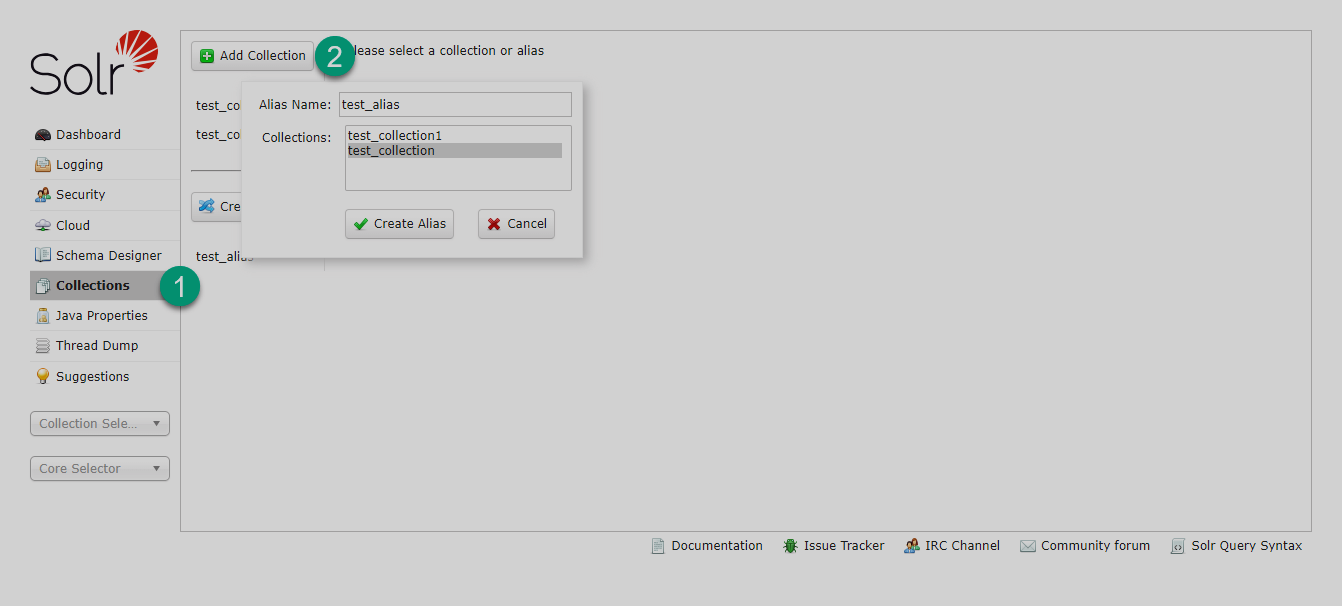 Create alias
Create alias -
Delete the old collection as no longer needed.
REINDEXCOLLECTION command
Solr provides the REINDEXCOLLECTION command that allows reindexing a collection using existing data from the source collection.
|
NOTE
REINDEXCOLLECTION is potentially a lossy operation since it preserves only the data with stored=true fields.
It is recommended not to delete the source collection immediately after reindexing, but
keep it as a backup in case some data is lost.
|
To run the command, submit a GET request to the /admin/collections?action=REINDEXCOLLECTION&name=<collection_name> URL. When reindexing is started using this command, the source collection transitions to the read-only mode to ensure that all source documents are properly processed. Only one reindexing operation may run for a given source collection. Long-running, failed, or hanging reindexing operations can be terminated by using the abort option, which also removes partial results. If an error occurs while transferring documents to a new collection, Solr deletes temporary/target collections and resets the read-only state of the source collection.
Command parameters
The REINDEXCOLLECTION command accepts the following parameters as URL query strings.
| Parameter | Description |
|---|---|
name |
Mandatory. The source collection name or alias |
cmd |
|
target |
Name of the target collection. If not specified, Solr creates a collection with a unique name and after reindexing is done, creates an alias that points to the newly created collection, thus "isolating" the original source collection from read and update operations |
q |
An optional query to select documents for reindexing.
The default value is |
fl |
An optional list of fields to reindex.
The default value is |
rows |
Specifies the batch size to transfer documents. Depending on the average size of the document, large batch sizes may cause memory issues. Defaults to 100 |
configName |
An optional name of the configset for the target collection. By default, Solr uses the same configset as the source collection |
removeSource |
If set to |
Command usage example
To run the examples below, create a sample collection and index a dummy document as described in the Solr indexing overview article.
The following request starts reindexing of the source collection named test_collection.
$ curl 'http://localhost:8983/solr/admin/collections?action=REINDEXCOLLECTION&name=test_collection'Sample response:
{
"responseHeader":{
"status":0,
"QTime":6453},
"reindexStatus":{
"actualSourceCollection":"test_collection",
"actualTargetCollection":".rx_test_collection_3",
"alias":"test_collection -> .rx_test_collection_3",
"checkpointCollection":".rx_ck_test_collection",
"inputDocs":1,
"phase":"done",
"processedDocs":1,
"state":"finished"}}As the response suggests, Solr has created a new collection .rx_test_collection_3 and the test_collection alias that points to the new collection.
Check the contents of the new collection by explicitly specifying the collection name and bypassing the alias:
$ curl 'http://ka-adh-1.ru-central1.internal:8983/solr/.rx_test_collection_3/select?indent=true&q.op=OR&q=*%3A*'The response contains the dummy document copied from the original source collection.
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"*:*",
"indent":"true",
"q.op":"OR"}},
"response":{"numFound":1,"start":0,"numFoundExact":true,"docs":[
{
"txn_id":[1],
"txn_date":["2024-01-02T00:00:00Z"],
"txn_value":[75.0],
"comment":["The first transaction."],
"id":"1",
"acc_id":[1001],
"_version_":1812905933055983616}]
}}The source collection (test_collection) is not removed, however now Solr routes all read/update requests to the new .rx_test_collection_3 collection through the alias.
The following example starts the reindexing process and specifies parameters to select only specific data to be reindexed to the target collection.
$ curl 'http://localhost:8983/solr/admin/collections?action=REINDEXCOLLECTION&name=test_collection&q=txn_id:1&fl=id,txn_id,txn_value,acc_id&target=test_collection2'Sample response:
{
"responseHeader":{
"status":0,
"QTime":6215},
"reindexStatus":{
"actualSourceCollection":"test_collection",
"actualTargetCollection":"test_collection2",
"checkpointCollection":".rx_ck_test_collection",
"inputDocs":1,
"phase":"done",
"processedDocs":1,
"state":"finished"}}Check the contents of the target collection:
$ curl 'http://ka-adh-1.ru-central1.internal:8983/solr/test_collection2/select?indent=true&q.op=OR&q=*%3A*'Solr returns the test document that was reindexed with a reduced set of fields as defined by command parameters.
{
"responseHeader":{
"zkConnected":true,
"status":0,
"QTime":0,
"params":{
"q":"*:*",
"indent":"true",
"q.op":"OR",
"_":"1728921728844"}},
"response":{"numFound":1,"start":0,"numFoundExact":true,"docs":[
{
"txn_id":[1],
"txn_value":[75.0],
"id":"1",
"acc_id":[1001],
"_version_":1812908971102568448}]
}}