

Add services
In ADCM, a service means a software that performs some function. Examples of services for ADH clusters: HDFS, HBase, Hive, etc. The steps for adding services to a cluster are listed below:
-
Select a cluster on the Clusters page. To do this, click a cluster name in the Name column.
 Select a cluster
Select a cluster -
Open the Services tab on the cluster page and click Add services (Add service in first versions of ADCM).
 Switch to adding services
Switch to adding services -
In the opened dialog, select services that should be added to the cluster and click Add.
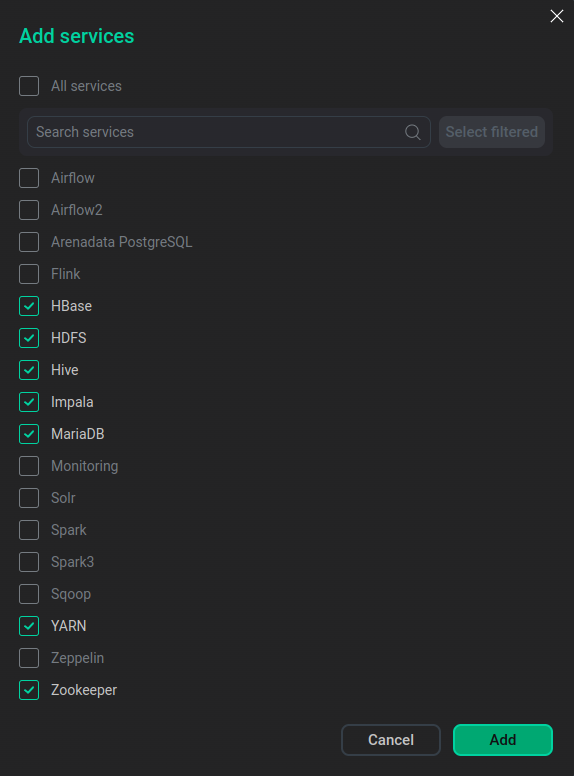 Select services
Select servicesThe brief description of available services is listed below.
Services that can be added to the ADH cluster Service Purpose A relational PostgreSQL database used by the ADH services
In comparison with the Airflow 1.x version, it offers the following features: High Availability, lowered task latency, full REST API, TaskFlow API, task groups, independent providers, and others
Core configuration
A service that contains common Hadoop packages required by every other service except ADPG, Solr, Zookeeper, and Monitoring. This service is installed on all nodes. If an already installed Hadoop service is expanded to another host, the Core configuration service is automatically installed on the host. The service is supported since ADH version 3.3.6.2.b1. Configuration parameters of this service are described in the Configuration parameters article. After applying any changes to this service configuration, you need to run the Update Core configuration action for this service
A distributed platform used in high-load Big Data applications for analyzing data stored in Hyperwave clusters. It can be used in different streaming use cases: event-driven applications, stream and batch analytics, data pipelines and ETL, etc.
Flink2
Flink-based service with version 2.x. This service is in the technical preview mode, may have a number of limitations, and is not recommended for production use
А non-relational, distributed database written in Java and used on the top of HDFS. Belongs to the class of column-oriented key-value storages. It is useful for random, real-time read/write access to Big Data
A distributed file system used in Hyperwave clusters for storing large files. Provides the possibility of the streaming access to the information distributed block-by-block across cluster nodes
A software designed for building data warehouses (DWH) and analyzing Big Data. It runs on the top of HDFS and other compatible systems, such as Apache HBase. It facilitates writing, reading, and managing large datasets stored in distributed systems
Apache HUE is a UI-based SQL assistant that provides interpreters for various data sources, like Impala, Hive, Kyuubi, and many more. It has a handy query editor with intelligent autocomplete, drag and drop, quick browse, and other features
Impala provides fast, interactive SQL queries on data stored in HDFS, HBase, or S3. In addition to the unified storage platform, Impala also uses the same metadata, SQL syntax (Hive SQL), and JDBC driver as Apache Hive. It makes Impala a unified platform for real-time or batch-oriented queries
Apache Kyuubi is a distributed and multi-tenant gateway to provide SQL on Data Warehouses and Lakehouses. It builds distributed SQL query engines on top of various kinds of modern computing frameworks, e.g. Apache Spark, Flink, Hive, Impala, etc., to query massive datasets distributed over fleets of machines from heterogeneous data sources
Monitoring
A service that should be added if monitoring of the ADH cluster is planned
Apache Ozone (O3) is a distributed object storage that is optimized for working with both Hadoop services and S3 storages. It’s highly scalable, can share the same cluster and security policies with HDFS, and is capable of effectively handling files no matter the size
A search platform based on the Apache Lucene project. Its main features include full-text search, faceted search, highlighting search results, distributed indexing, integration with databases, processing documents with a complex format (Word, PDF, etc.), load-balanced querying, centralized configuration, and others
A fast analytics engine used for large-scale data processing and is compatible with Hadoop data. It can run in Hyperwave clusters using YARN or Spark’s standalone mode. It can process data in HDFS, HBase, Cassandra, Hive, and other Hadoop input formats. It supports both batch processing and new workloads like streaming, machine learning, interactive queries, etc. Spark 3.x offers such new features as adaptive execution of Spark SQL, dynamic partition pruning (DPP), graph processing, enhanced support for deep learning, and others
Spark4
Spark-based service with version 4.x. This service is in the technical preview mode, may have a number of limitations, and is not recommended for production use
Smart Storage Manager is a service that aims to optimize the efficiency of storing and managing data in the Hadoop Distributed File System. SSM collects HDFS operation data and system state information, and based on the collected metrics can automatically use methodologies such as cache, storage policies, heterogeneous storage management (HSM), data compression, and Erasure Coding. In addition, SSM provides the ability to configure asynchronous replication of data and namespaces to a backup cluster for the purpose of organizing DR
Trino is an open-source SQL query engine used for processing data in parallel, distributed over multiple storages, such as object storages, databases, and file systems
A service needed for managing cluster resources and scheduling/monitoring jobs. Uses a special daemon (ResourceManager) that abstracts all the computing resources of the cluster and manages their provision to distributed applications
A service that plays a role of a web-based notebook and enables interactive data analytics. Allows to create queries to data in Hyperwave clusters and display the results in the form of tables, graphs, charts, etc.
A centralized coordination service for distributed applications. It is used in Hyperwave clusters for failure detection, active NameNode election, health monitoring, session management, etc.
The minimal set of services recommended for ADH clusters is described below:
-
Core configuration;
-
HDFS/Ozone;
-
YARN;
-
Zookeeper (optional for the Community Edition of ADH).
These services make up the core of Hyperwave and are sufficient to organize distributed data storage and processing. The full list of services depends on the requirements of a particular project.
-
-
As a result, the added services are displayed at the Services tab.
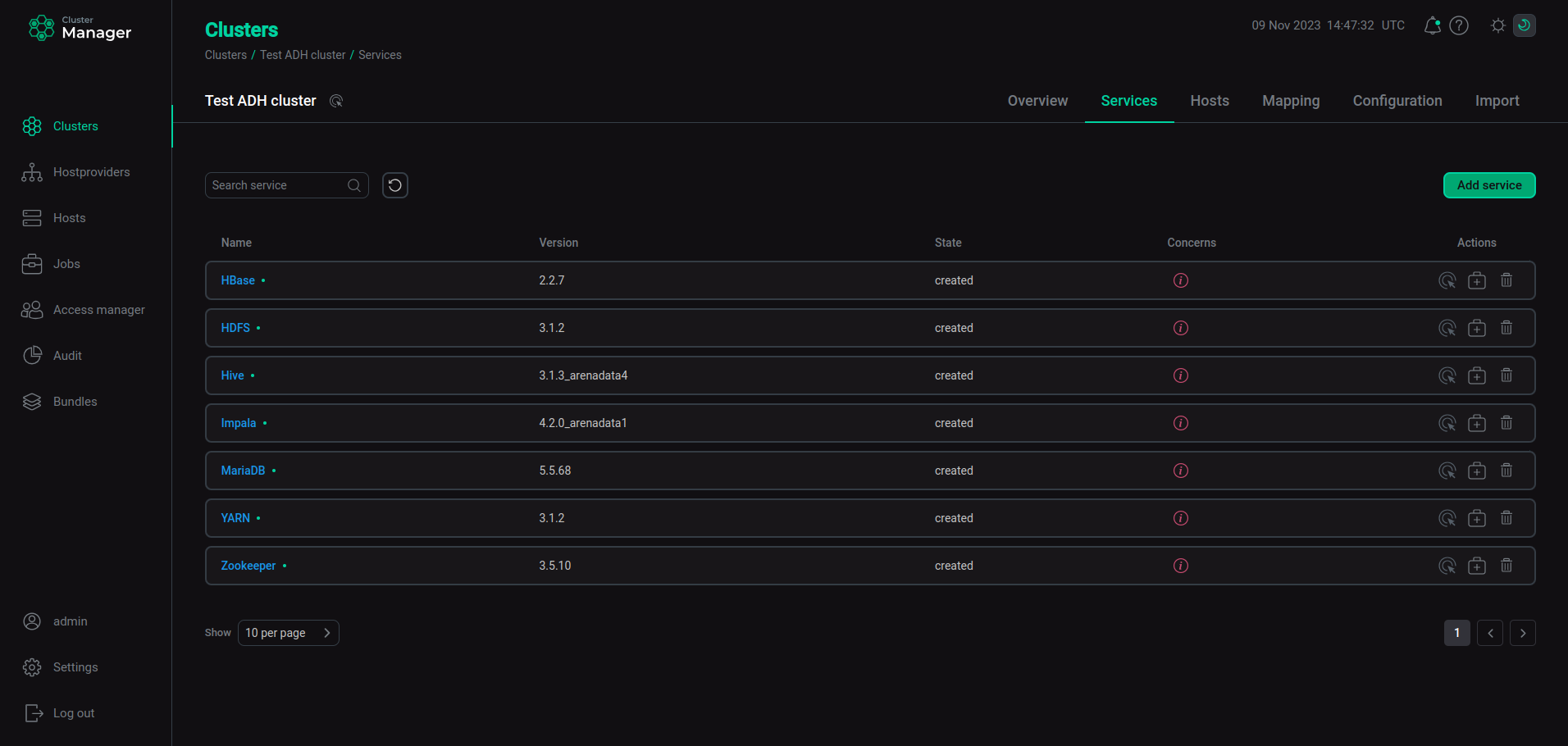 The result of successful adding services to a cluster
The result of successful adding services to a cluster
|
NOTE
You can also add services later. The process of adding new services to already running cluster does not differ from installing a service from scratch.
|