

Zeppelin architecture
Zeppelin is an interactive web-based notebook useful for multiple purposes while working with Big Data:
-
Data ingestion/discovery from different sources. Due to the Interpreters mechanism, in fact, it is possible to plug any language or data processing backend into Zeppelin.
-
Data visualization and analytics. Zeppelin Web UI supports several built-in tools for visualizing the results of code execution: tables, bar charts, pie charts, area charts, line charts, scatter charts. To add some input forms into notes, you can use dynamic forms. Besides that, Zeppelin allows to add html into any output. All these features help data scientists to get the comprehensive data for analytics.
-
Data collaboration. A Zeppelin Note URL can be shared among different collaborators. Any changes are broadcasted in the real time.
Components
The high-level architecture view of Zeppelin is shown below.


Let’s discuss the main points of the scheme:
-
Users connect to Zeppelin via one of the configured authentication systems. For example, Nginx, Apache Shiro, etc.
-
Authorized users can interact either with the Zeppelin Web UI or directly with the Zeppelin server — via the available REST API.
-
Notes created by users can be saved in different storages. Among them are Git, S3, MongoDB, ZeppelinHub, etc.
-
The main functionality in Zeppelin is performed by interpreters that are responsible for using different programming languages and data processing backends: Spark, Python, JDBC, SQL, etc. Interpreters communicate with Zeppelin Server via Apache Thrift.
-
By default, Zeppelin uses the central Maven repository for resolving dependencies and loading libraries that are required for interpreters. You can also load libraries from the local file system and add external repositories. Read more about dependency management in the Zeppelin documentation.
Interpreters
A Zeppelin Interpreter is a plug-in that enables to use a specific language or data processing backend platform for querying and analyzing data. For example, the interpreter %sh is designed for running shell commands, the interpreter %jdbc — for jdbc calls, etc.
Every interpreter belongs to some group. Interpreters from the same group are running in the same JVM process. So a group is a unit of starting and stopping interpreters. Every group can contain several interpreters, but one interpreter belongs only to one group. For example, the Spark interpreter group includes such interpreters as %spark, %sql, %pyspark, %ipyspark, %r, and the dependency loader %dep. Interpreters in the same group can reference each other.
The list of available community managed interpreters can be found in the Zeppelin documentation. In fact, these are interpreter groups, some of them contain one interpreter, others — several. You can always add a new interpreter within one of the existing groups. Besides that, there are some 3rd party interpreters that can be loaded to Zeppelin too. At least, it is possible to create your own interpreter that is not based on existing groups.
The table below shows the main actions available for interpreters.
| Action | Example/Documentation |
|---|---|
Adding a new interpreter into the existing group |
|
Writing an interpreter |
|
Installing a 3rd party interpreter |
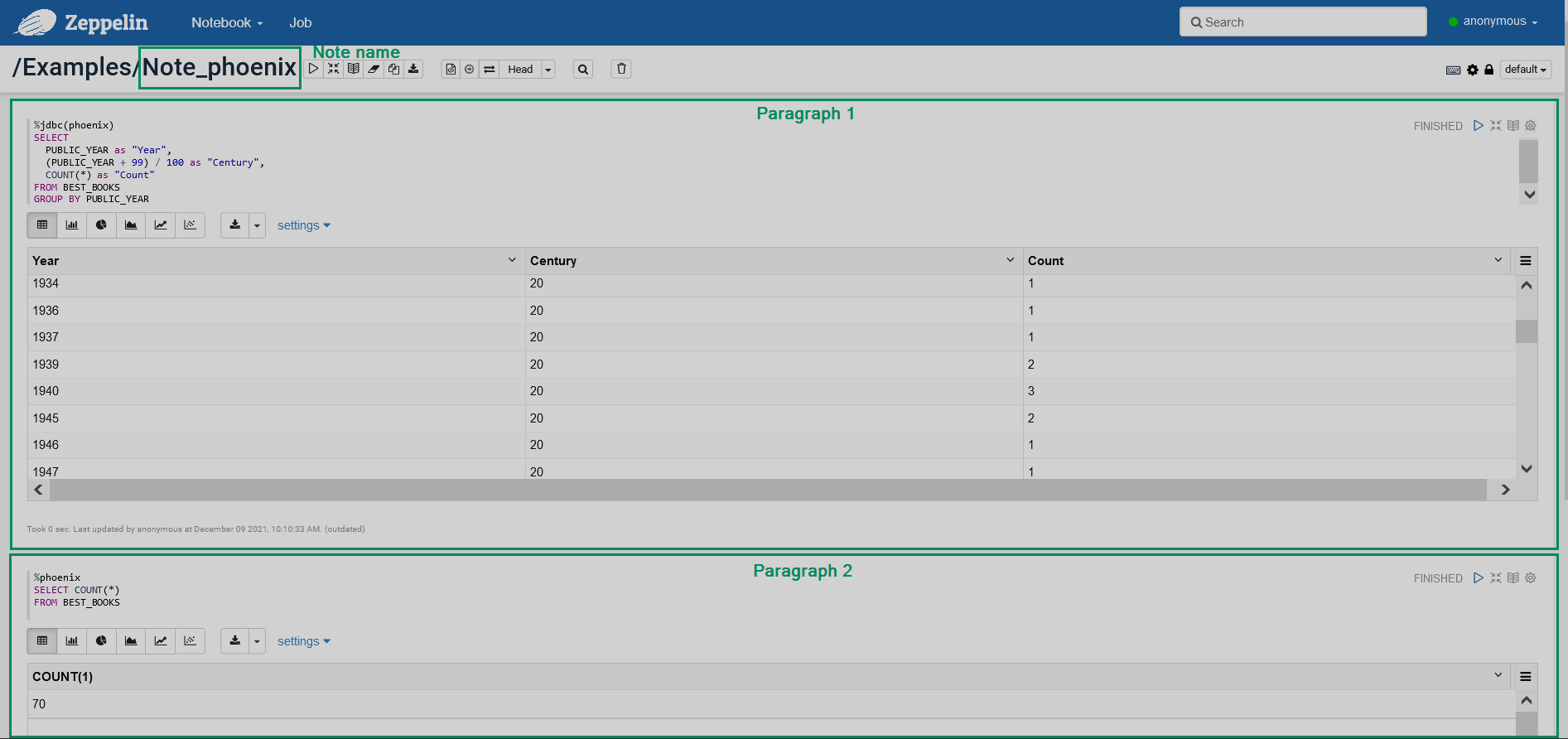
Notes and paragraphs
A Zeppelin Note is a collection of code snippets written in the languages that are supported by the interpreters bound to this note. Every note has a URL that can be shared with other users.
One note can include several Paragraphs. These paragraphs can be both requests to the different backend systems and explanatory text labels built with html. Every paragraph includes the code and the result. Any of these sections can be hidden.
Zeppelin Web UI supports several viewing modes of notes including the complete hiding of the source code.
|
NOTE
For more information about notes and paragraphs, see the Zeppelin documentation.
|