Создание заметки Python
В данной статье описан процесс создания и запуска заметок Python в Zeppelin.
По умолчанию для выполнения кода заметок на Python сервис Zeppelin использует интерпретатор Python, доступный в переменной окружения $PATH.
Интерпретатор Python, используемый сервисом Zeppelin, можно изменить с помощью свойства zeppelin.interpreter.
Больше информации доступно в разделе Выбор Python-интерпретатора.
Выбор Python-интерпретатора
Различные дистрибутивы операционных систем поставляются с разными версиями Python, добавленными в $PATH.
ОС может поставляться с Python 2.x, Python 3 или вообще не содержать Python.
В Zeppelin можно указать Python-интерпретатор определенной версии для выполнения кода заметок.
Для этого выполните следующие действия:
-
Выберите Interpreter в меню аккаунта, расположенном в правом верхнем углу домашней страницы Zeppelin.
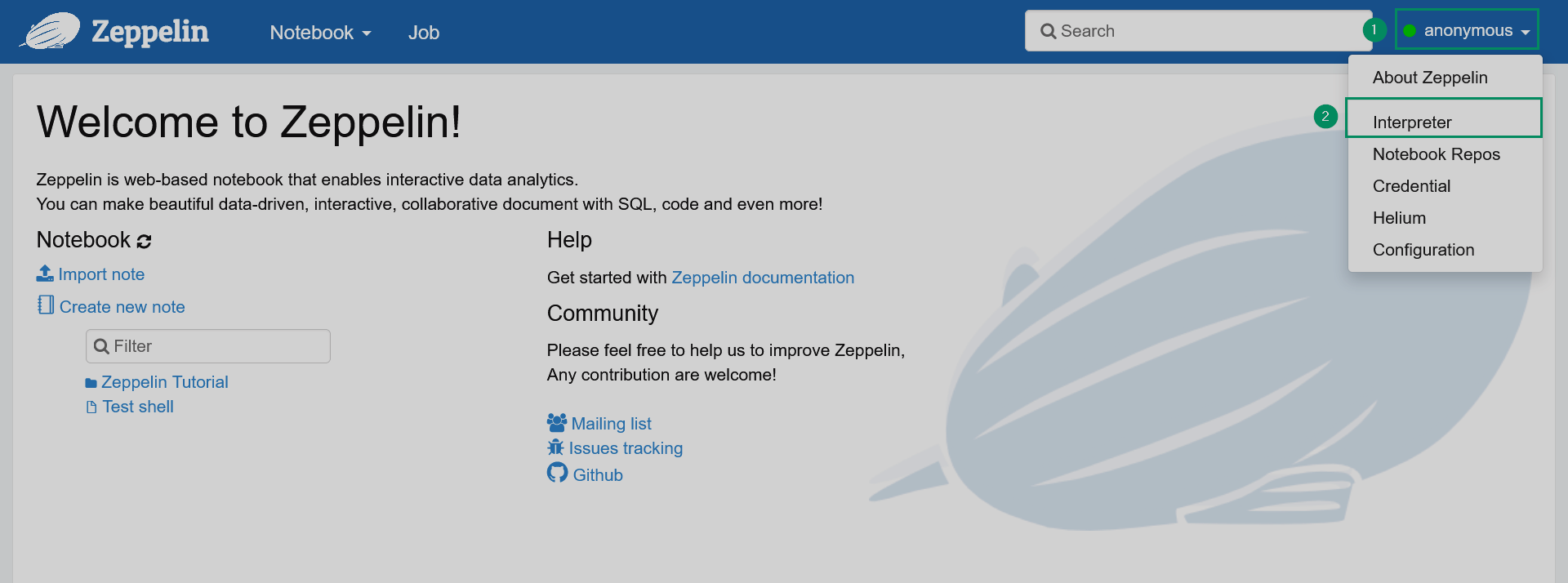 Список интерпретаторов
Список интерпретаторов Список интерпретаторов
Список интерпретаторов -
Найдите интерпретатор
pythonи кликните Edit. -
В параметре
zeppelin.pythonукажите путь к нужному исполняемому файлу Python.РЕКОМЕНДАЦИЯИнтерпретатор Python, поставляемый с ADH, находится в директории /opt/<python_env>. -
Сохраните конфигурацию и перезапустите интерпретатор.
-
Выполните тестовую заметку, чтобы убедиться, что Zeppelin использует новый интерпретатор Python:
%python import sys print(f"""Current note has been executed using: Python location: {sys.executable} Python version: {sys.version_info[0]} """)Пример вывода:
Current note has been executed using: Python location: /opt/python3.10/bin/python3 Python version: 3
Интерпретаторы Zeppelin для Python
Сервис Zeppelin поставляется с группой интерпретаторов python, которая включает набор интерпретаторов, перечисленных в таблице.
Все перечисленные интерпретаторы поддерживают Python 2 и Python 3.
| Интерпретатор | Класс | Описание |
|---|---|---|
%python |
PythonInterpreter |
Ванильный интерпретатор Python с базовыми зависимостями. Требует установки только среды Python. Использует возможности IPython, если выполняются предварительные условия |
%python.ipython |
IPythonInterpreter |
Предоставляет более функциональное окружение Python, построенное на IPython. Данный интерпретатор считается предпочтительным вариантом для работы с заметками Python |
%python.sql |
PythonInterpreterPandasSql |
Предоставляет SQL-возможности для работы с Pandas DataFrames через |
Общие переменные
В данной статье предполагается, что интерпретатор python используется со стандартными настройками биндинга (shared binding mode), то есть интерпретатор инстанциируется глобально в shared-режиме.
Это означает, что Zeppelin создает один JVM-процесс c одной группой интерпретаторов (interpreter group) для обслуживания всех заметок Python.
В результате переменные, объявленные в одной заметке, доступны и в других заметках.
Совместное использование переменных также работает между заметками типа %python и %python.ipython.
Создание и запуск заметки Python
-
В веб-интерфейсе Zeppelin кликните Create new note или выберите пункт основного меню Notebook → Create new note.
 Добавление новой заметки
Добавление новой заметки Добавление новой заметки
Добавление новой заметки -
В открывшемся диалоге введите имя и укажите интерпретатор по умолчанию, который будет использован в случаях, когда явно не указан тип интерпретатора. Обратите внимание, что вы можете создавать папки для ваших заметок. Затем кликните Create.
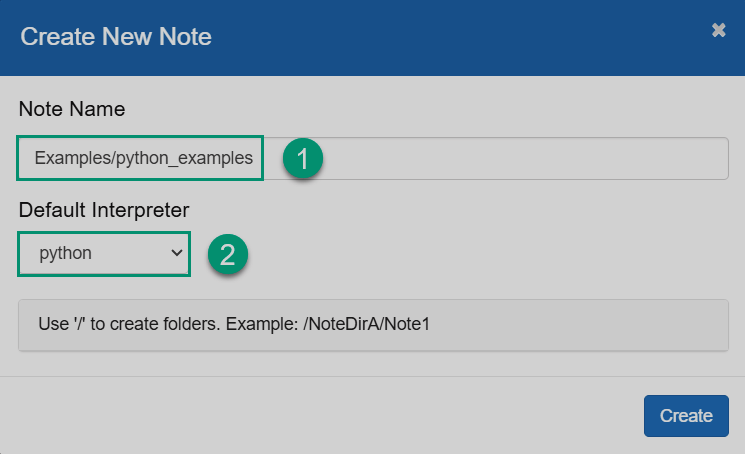 Создание новой заметки
Создание новой заметки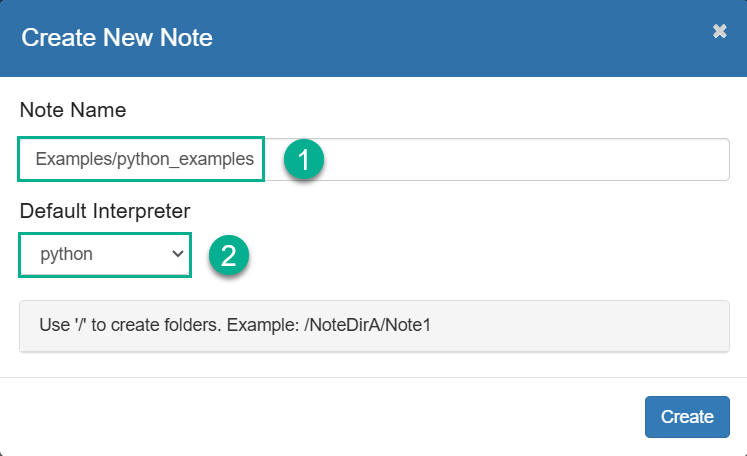 Создание новой заметки
Создание новой заметки -
Введите код Python в параграфе (paragraph) заметки и выполните параграф.
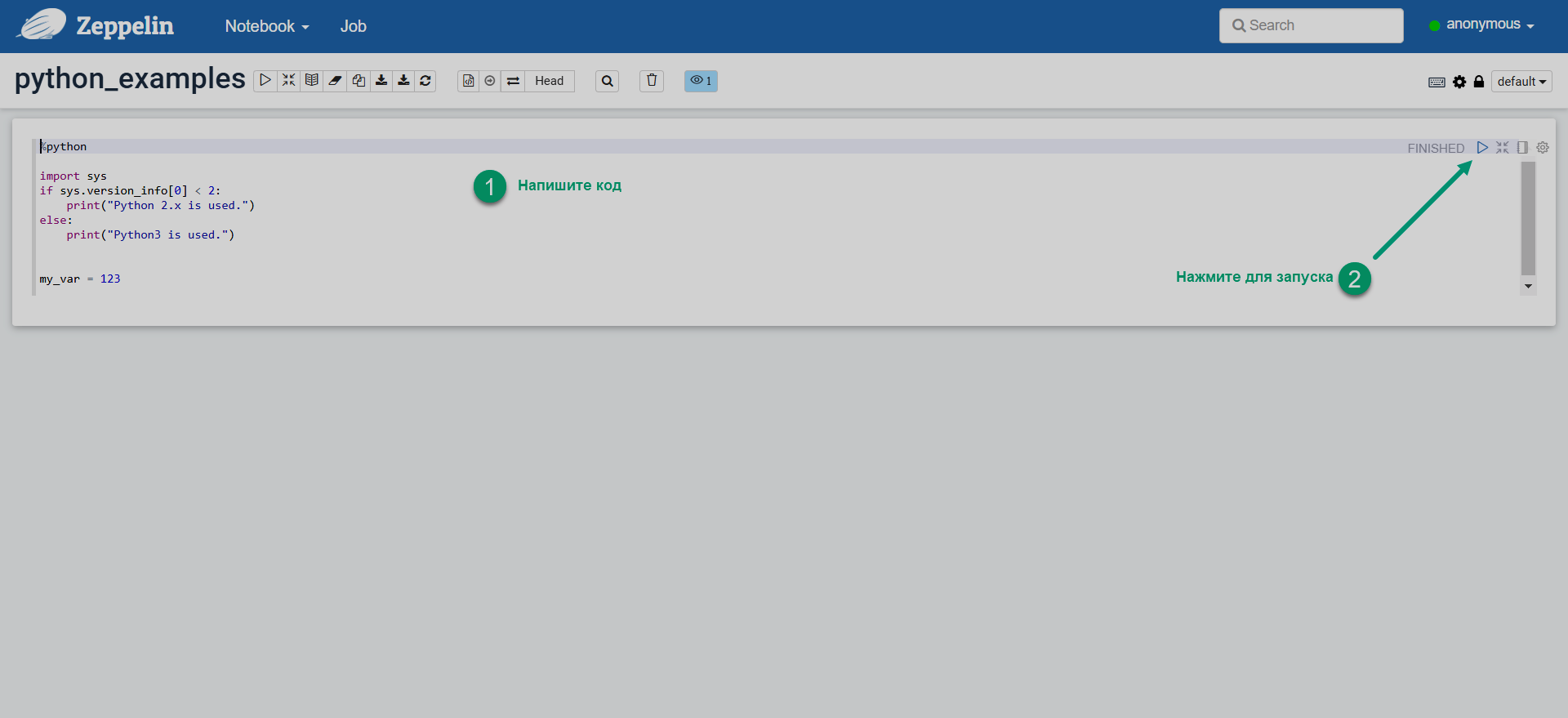 Запуск кода Python в Zeppelin
Запуск кода Python в Zeppelin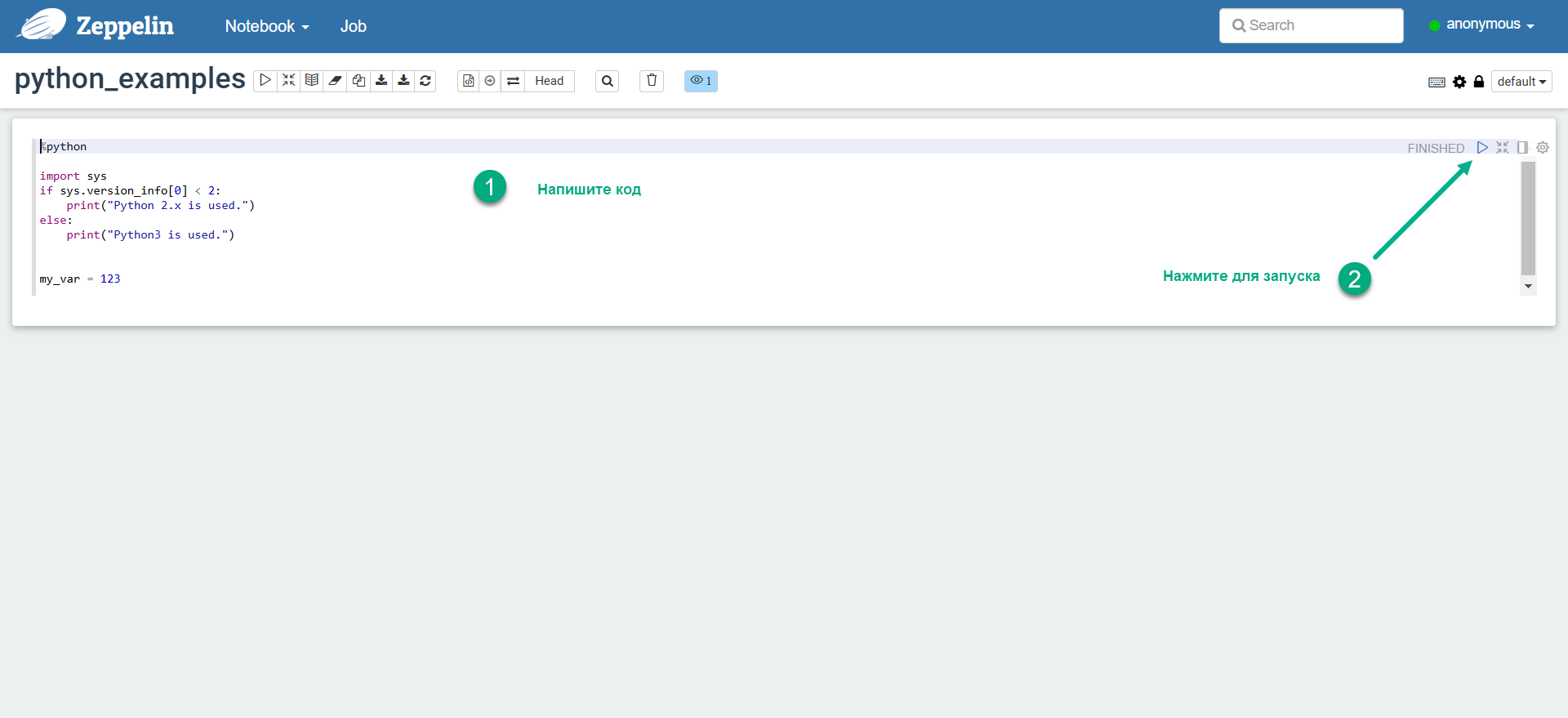 Запуск кода Python в Zeppelin
Запуск кода Python в Zeppelin
Ниже приведены примеры заметок на Python. Код заметок доступен в виде архива .zpln, который можно импортировать в веб-интерфейс Zeppelin (Zeppelin → Import Note). Больше примеров доступно в Zeppelin UI (Notebook → Python Tutorial).
Python (%python)
Чтобы использовать ванильный Zeppelin-интерпретатор для Python, укажите %python в первой строке параграфа.
Используйте %python когда нужна только базовая среда Python без дополнительных зависимостей.
В следующем примере показано базовое использование Pandas DataFrame и встроенной визуализации Zeppelin.
%python (1)
import pandas as pd (2)
txn_data = {'acc_id': [1001,1003,1002,1001,1001,1002,1003,1001,1003],
'txn_value': [25.00, 30.00, 100.00, 250.00, 98.50, 23.50, 45.00, 60.00, 75.15],
'txn_date': ['2025-01-07', '2025-01-03', '2025-01-09', '2025-01-02', '2025-01-01', '2025-01-04', '2025-01-08', '2025-01-11', '2025-01-03']}
df = pd.DataFrame(txn_data) (3)
z.show(df) (4)| 1 | Явное указание Zeppelin-интерпретатора для Python. |
| 2 | Перед запуском заметки импортируемые модули должны быть установлены с помощью pip install <module_name>. |
| 3 | Создание Pandas DataFrame. |
| 4 | Визуализация DataFrame с помощью встроенных виджетов Zeppelin. Больше примеров визуализации доступно в разделе IPython. |
Результат выполнения заметки представлен ниже.
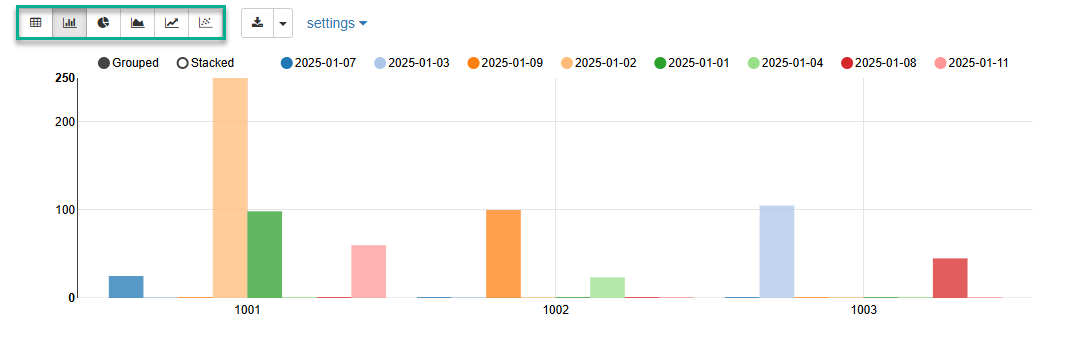
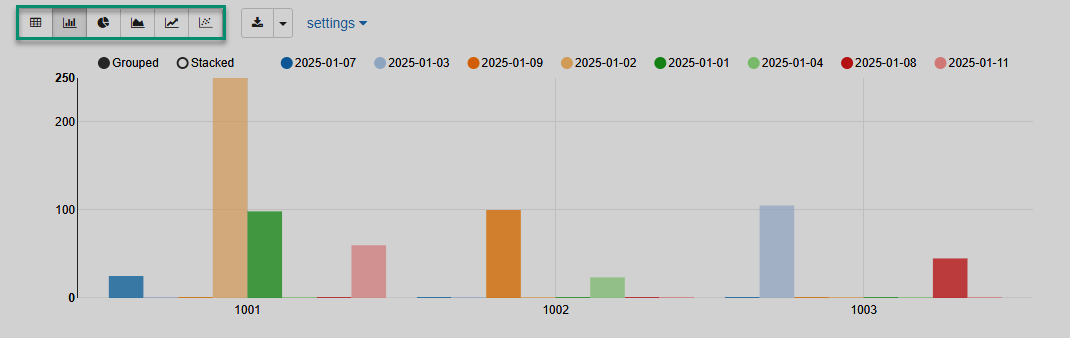
IPython (%python.ipython)
IPython (%python.ipython) — это Jupyter-подобный интерпретатор, построенный на IPython и предоставляющий богатую среду для интерактивных вычислений, например:
-
Улучшенное автозаполнение, подсветка синтаксиса и вывода.
-
Специальные функции, такие как
%timeit,%matplotlib inlineи так далее. -
Расширенные возможности визуализации с использованием сторонних библиотек, таких как Seaborn, Plotly, Bokeh и так далее.
Чтобы использовать Zeppelin-интерпретатор %python.ipython, установите следующие pip-модули в Python-бэкенд, используемый Zeppelin:
-
jupyter-client -
ipython -
ipykernel -
grpcio -
protobufПРИМЕЧАНИЕВ зависимости от версии Python, который используется сервисом Zeppelin, возможны конфликты при установке последней версииprotobuf. Одним из вариантов обхода проблемы является понижение версии или установка более старой версииprotobuf. Например, по состоянию на Python 3.10, который использовался для примеров в этой статье, версияprotobuf3.19.6 работала корректно.
Чтобы использовать возможности IPython, укажите %python.ipython в первой строке параграфа.
Пример:
%python.ipython (1)
import pandas as pd
data = {
'full_name': ['Sarah Connor',
'Kirk Hammett',
'Ivan Ivanov'],
'age': [25, 30, 35],
'dep': ['it', 'sales', 'hr']}
df = pd.DataFrame(data) (2)
print(" Describe DF:".center(50, "*"))
print(df.describe())
print(" DF types: ".center(50, "*"))
print(df.dtypes)
print(" Filter DF: ".center(50, "*"))
df1 = df[df['age'] > 30]
print(df1)
print(" Add column to DF: ".center(50, "*"))
df['salary'] = [100000, 200000, 300000]
print(df)
print(" Magic functions: ".center(50, "*"))
range? (3)
%timeit range(100) (4)| 1 | Явное указание интерпретатора IPython. |
| 2 | Создание Pandas DataFrame с последующими базовыми операциями. |
| 3 | Специальная функция IPython, которая выводит справочную информацию о методе. |
| 4 | Специальная функция IPython для замера длительности работы метода. |
****************** Describe DF:*******************
age
count 3.0
mean 30.0
std 5.0
min 25.0
25% 27.5
50% 30.0
75% 32.5
max 35.0
******************* DF types: ********************
full_name object
age int64
dep object
dtype: object
******************* Filter DF: *******************
full_name age dep
2 Ivan Ivanov 35 hr
*************** Add column to DF: ****************
full_name age dep salary
0 Sarah Connor 25 it 100000
1 Kirk Hammett 30 sales 200000
2 Ivan Ivanov 35 hr 300000
**************** Magic functions: ****************
108 ns ± 0.816 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)
Init signature: range(self, /, *args, **kwargs)
Docstring:
range(stop) -> range object
range(start, stop[, step]) -> range object
Return an object that produces a sequence of integers from start (inclusive)
to stop (exclusive) by step. range(i, j) produces i, i+1, i+2, ..., j-1.
start defaults to 0, and stop is omitted! range(4) produces 0, 1, 2, 3.
These are exactly the valid indices for a list of 4 elements.
When step is given, it specifies the increment (or decrement).
Type: type
Subclasses:
Ниже приведены примеры визуализации данных в Zeppelin с помощью различных библиотек Python.
Чтобы выполнить следующую заметку, установите Matplotlib в интерпретатор Python, который используется сервисом Zeppelin. Например:
$ /opt/python3.10/bin/python3 -m pip install matplotlibКод заметки:
%python.ipython (1)
import sys
import numpy as np (2)
import matplotlib.pyplot as plt
print("Dummy text")
plt.figure(figsize=(6, 3))
x = np.linspace(1.5, 15, 100)
y = np.sin(x)
plt.plot(x, y, label="Sine wave")
plt.xlabel("Time")
plt.ylabel("Load")
plt.title("A dummy sine using matplotlib")
plt.legend()
plt.show() (3)| 1 | Явное указание интерпретатора IPython. |
| 2 | Перед запуском заметки импортируемые модули должны быть установлены с помощью pip install <module_name>. |
| 3 | Рендеринг графика с помощью библиотеки matplotlib. |
Пример графика приведен ниже.
Чтобы выполнить следующую заметку, установите Seaborn в интерпретатор Python, который используется сервисом Zeppelin. Например:
$ /opt/python3.10/bin/python3 -m pip install seabornКод заметки:
%python.ipython (1)
%matplotlib inline (2)
import seaborn as sns (3)
import matplotlib.pyplot as plt
import pandas as pd
txn_data = {'acc_id': [1001,1003,1002,1001,1001,1002,1003,1001,1003],
'txn_value': [25.00, 30.00, 100.00, 250.00, 98.50, 23.50, 45.00, 60.00, 150.15],
'txn_date': ['2025-01-07', '2025-01-03', '2025-01-09', '2025-01-02', '2025-01-01', '2025-01-04', '2025-01-08', '2025-01-11', '2025-01-03']}
df = pd.DataFrame(txn_data)
plt.figure(figsize=(6, 4))
sns.boxplot(y='txn_value', x='acc_id', data=df) (4)
plt.title("Transactions by account")
plt.xlabel("Account")
plt.ylabel("Transaction value")
plt.show()| 1 | Явное указание интерпретатора IPython. |
| 2 | Специальная функция IPython для отображения графика непосредственно в блокноте. |
| 3 | Перед запуском заметки импортируемые модули должны быть установлены с помощью pip install <module_name>. |
| 4 | Генерация графика с помощью библиотеки seaborn. |
Пример графика приведен ниже.
Чтобы использовать Plotly для визуализации данных, установите следующие pip-модули в интерпретатор Python, который используется сервисом Zeppelin.
$ /opt/python3.10/bin/python3 -m pip install plotly
$ /opt/python3.10/bin/python3 -m pip install nbformatКод заметки:
%python.ipython (1)
%matplotlib inline (2)
import plotly.express as px (3)
import matplotlib.pyplot as plt (3)
import pandas as pd (3)
txn_data = {'acc_id': [1001,1003,1002,1001,1001,1002,1003,1001,1003],
'txn_value': [25.00, 30.00, 100.00, 250.00, 98.50, 23.50, 45.00, 60.00, 150.15],
'txn_date': ['2025-01-02', '2025-01-03', '2025-01-04', '2025-01-01', '2025-01-01', '2025-01-05', '2025-01-03', '2025-01-06', '2025-01-05']}
df = pd.DataFrame(txn_data)
fig = px.scatter(df, (4)
x='txn_date',
y='txn_value',
color='acc_id',
size="txn_value",
title="Dummy Plotly scatter chart")
fig.update_layout(width=800, height=600)
fig.show()| 1 | Явное указание интерпретатора IPython. |
| 2 | Специальная функция IPython для отображения графика непосредственно в блокноте. |
| 3 | Перед запуском заметки импортируемые модули должны быть установлены с помощью pip install <module_name>. |
| 4 | Генерация графика с помощью библиотеки Plotly. |
Пример графика приведен ниже.
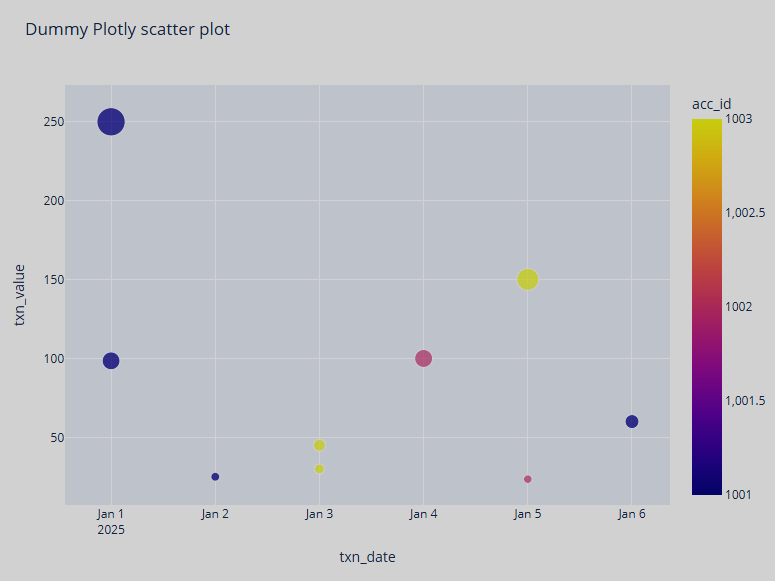
SQL для Pandas DataFrames (%python.sql)
С помощью Zeppelin-интерпретатора %python.sql можно использовать SQL для запросов к Pandas DataFrames и визуализации их содержимого.
Данный интерпретатор требует установки следующих pip-модулей:
-
pandas -
pandasql
Пример заметки:
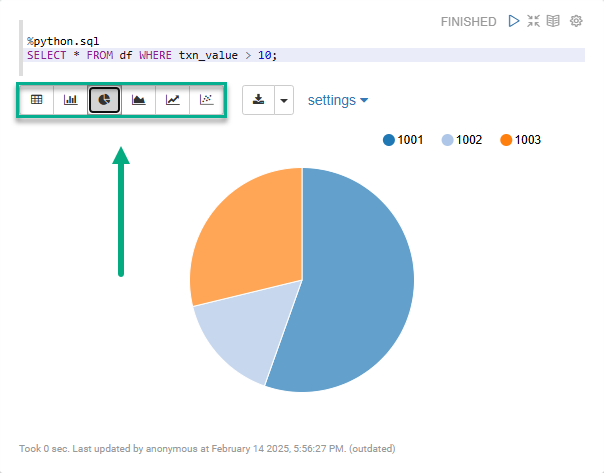
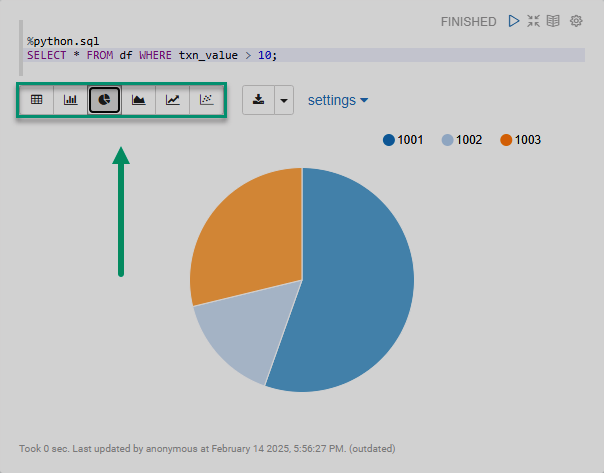
%python.sql (1)
SELECT * FROM df WHERE txn_value > 100; (2)| 1 | Указание интерпретатора для использования SQL поверх Pandas DataFrames. |
| 2 | DataFrame df должен быть создан до выполнения запроса (в другом параграфе). |
Использование интерпретатора %spark.sql активирует встроенную визуализацию Zeppelin.
Можно переключаться между виджетами для отображения данных на круговой диаграмме, линейном графике и так далее.