

Configure and use Kafka Tiered Storage
Overview
The Tiered Storage option in ADS can be enabled in the Kafka service configuration parameters at a time for only one of the following storage options:
Below are detailed steps to enable the Tiered Storage option.
Hadoop Distributed File System (HDFS)
For this example, the HDFS service of the Arenadata Hadoop (ADH) cluster is used as storage.
Prerequisites
-
ADH
-
The ADH cluster is installed according to the Online installation guide.
The minimum version of ADH is 3.3.6.2.b1.
-
HDFS, Core configuration, YARN, and Zookeeper services are added and installed in the ADH cluster.
-
In HDFS, a directory has been created, the path and name of which correspond to the value of the storage.hdfs.root configuration parameter, and the access rights are configured as follows:
$ sudo -u hdfs hdfs dfs -mkdir /kafka $ sudo -u hdfs hdfs dfs -chown kafka:hadoop /kafka
-
-
ADS
-
The ADS cluster is installed according to the Online installation guide.
The minimum version of ADS is 3.6.2.2.b1.
-
Kafka and Zookeeper services are added and installed in the ADS cluster.
-
The Tiered Storage option is not enabled for Kafka — in the /etc/kafka/conf/server.properties configuration file (/usr/lib/kafka/config/kafka-controller.properties, if KRaft mode is enabled), no values are set for the
rsm.config.storageandremote.log.storageparameter groups. -
In ADS, ADH data import has been completed. To perform the import in the ADCM interface, open the Clusters page and click on the ADS cluster name. Then, on the cluster page that opens, go to the Import tab, select Cluster configuration next to the ADH cluster name, and click Import.
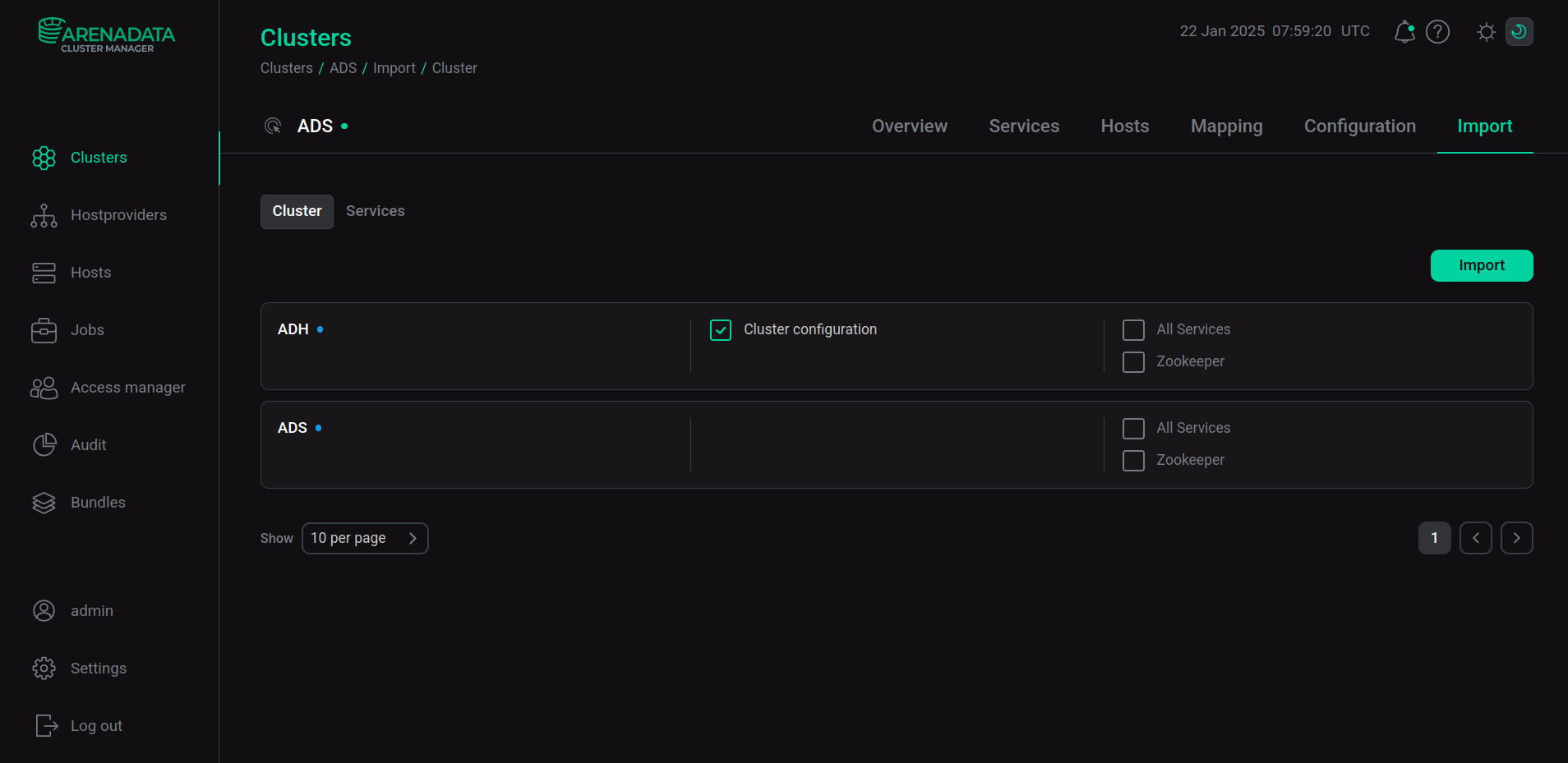 Import ADH data
Import ADH dataRestart the cluster using the Restart action.
As a result of the import, on hosts with the Kafka service, ADH configuration files are located in the /usr/lib/kafka/config/ folder:
Also, as a result of the import in the /etc/kafka/conf/kafka-java.yaml configuration file, a value for the
HADOOP_CONF_DIRparameter is set — the location where the ADH cluster configuration files are copied.
-
Step 1. Configure and enable Tiered Storage
-
Open the Services tab on the cluster page and click on the Kafka service name in the Name column.
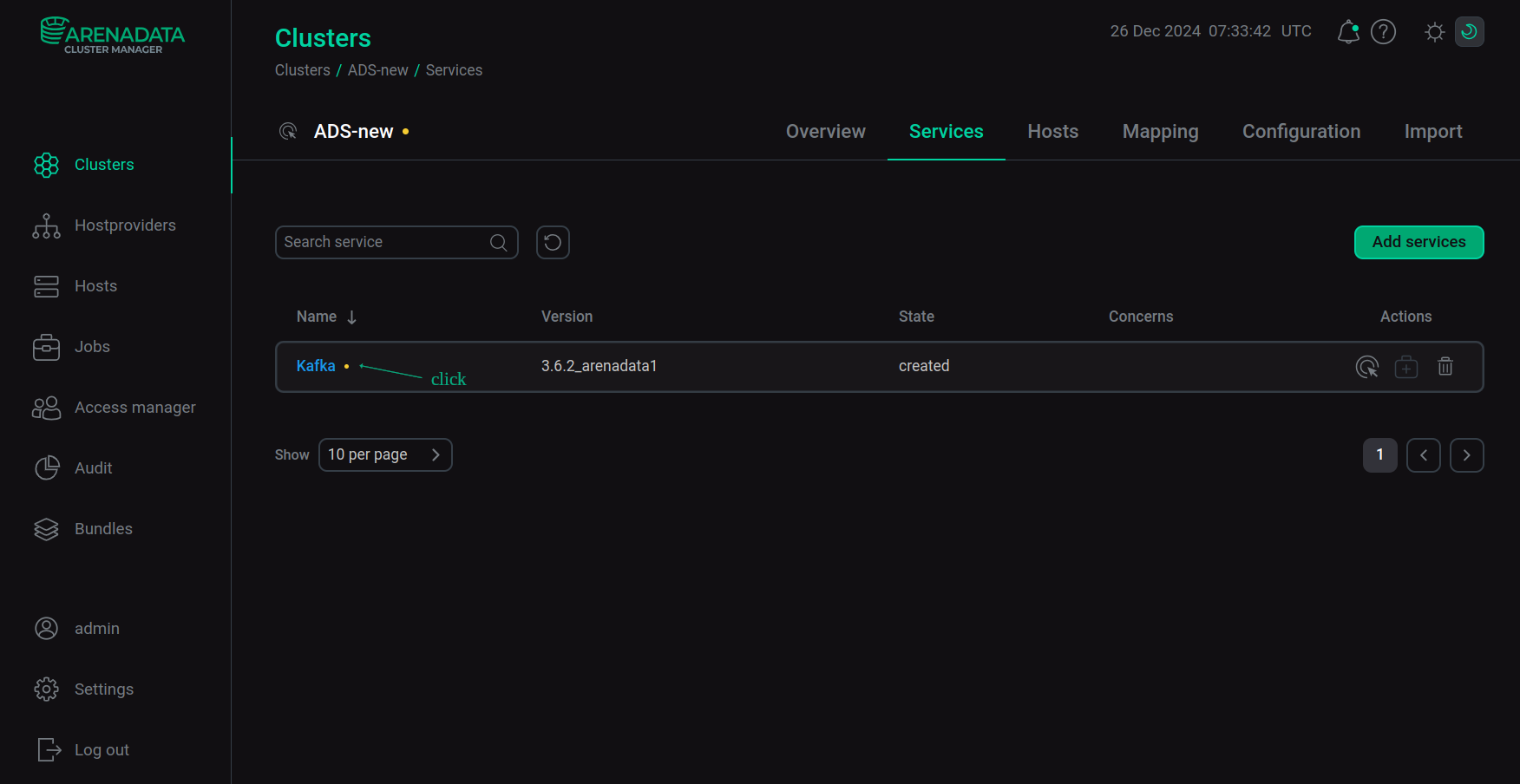 Switch to the service configuration
Switch to the service configuration -
In the Primary configuration window that opens:
-
Set the HDFS Tiered Storage switch to active and change the default settings as necessary.
-
If necessary, expand the Tiered Storage General group and change the default settings.
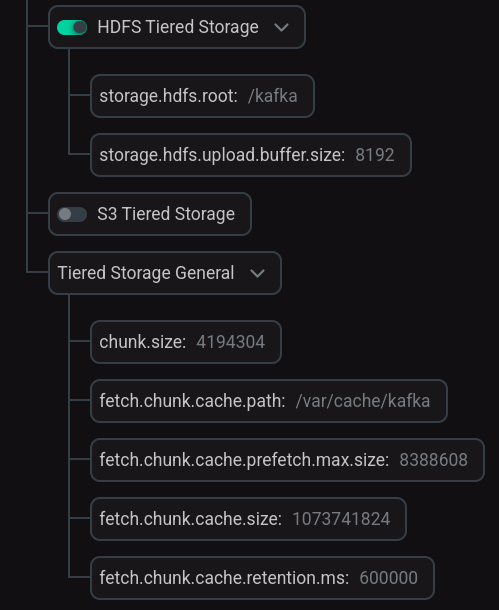 Tiered Storage configuration
Tiered Storage configurationParameter descriptions are provided in the Kafka configuration parameters article.
-
-
Click Save and restart the Kafka service using the Restart action by clicking

 in the Actions column.
in the Actions column. -
Wait until the service restarts. Analyze and correct errors if they occur on the Jobs page.
Step 2. Check the results
When you enable the Tiered Storage option via the ADCM interface, all the necessary parameters for working with storage are automatically set in the Kafka broker configuration file /etc/kafka/conf/server.properties (/usr/lib/kafka/config/kafka-controller.properties if KRaft mode is enabled): parameters of Remote Manager components , StorageBackend (automatically determined for the selected type of storage), and the chunking mechanism.
Below is an example of a configuration file modified by ADCM.
# Managed by ADCM
node.id=1
reserved.broker.max.id=5000
auto.create.topics.enable=False
listeners=PLAINTEXT://:9092
log.dirs=/kafka-logs
default.replication.factor=1
num.partitions=1
delete.topic.enable=true
log.retention.hours=168
log.roll.hours=168
queued.max.requests=500
num.network.threads=3
num.io.threads=8
auto.leader.rebalance.enable=True
unclean.leader.election.enable=False
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
zookeeper.connect=sov-ads-test-4.ru-central1.internal:2181/arenadata/cluster/148
zookeeper.connection.timeout.ms=30000
zookeeper.session.timeout.ms=30000
zookeeper.sync.time.ms=2000
zookeeper.set.acl=false
log.cleaner.enable=True
log.cleanup.policy=delete
log.cleanup.interval.mins=10
log.cleaner.min.compaction.lag.ms=0
log.cleaner.delete.retention.ms=86400000
security.inter.broker.protocol=PLAINTEXT
remote.log.metadata.manager.listener.name=PLAINTEXT
remote.log.storage.manager.class.name=io.aiven.kafka.tieredstorage.RemoteStorageManager
remote.log.storage.manager.class.path=/usr/lib/kafka/libs/tiered-storage/*
remote.log.storage.system.enable=true
rsm.config.chunk.size=4194304
rsm.config.fetch.chunk.cache.class=io.aiven.kafka.tieredstorage.fetch.cache.DiskChunkCache
rsm.config.fetch.chunk.cache.path=/var/cache/kafka
rsm.config.fetch.chunk.cache.prefetch.max.size=8388608
rsm.config.fetch.chunk.cache.size=1073741824
rsm.config.fetch.chunk.cache.retention.ms=600000
rsm.config.storage.backend.class=io.aiven.kafka.tieredstorage.storage.hdfs.HdfsStorage
rsm.config.storage.hdfs.core-site.path=/usr/lib/kafka/config/core-site.xml
rsm.config.storage.hdfs.hdfs-site.path=/usr/lib/kafka/config/hdfs-site.xml
rsm.config.storage.hdfs.root=/kafka
rsm.config.storage.hdfs.upload.buffer.size=8192To check the correct configuration of Tiered Storage for Kafka, you can write data to a test topic and monitor the data transfer to the storage, as described below.
Simple Storage Service (S3)
For this example, the MinIO storage is used as the S3 server.
Prerequisites
-
ADS
-
The ADS cluster is installed according to the Online installation guide.
The minimum version of ADS is 3.6.2.2.b1.
-
Kafka and Zookeeper services are added and installed in the ADS cluster.
-
The Tiered Storage option is not enabled for Kafka — in the /etc/kafka/conf/server.properties configuration file (/usr/lib/kafka/config/kafka-controller.properties, if KRaft mode is enabled), no values are set for the
rsm.config.storageandremote.log.storageparameter groups.
-
-
A bucket for storing data was created in the MinIO cloud storage.
|
NOTE
In the Tiered Storage implementation based on the S3 server, the transfer of records to the remote level is controlled using a special |
Step 1. Configure and enable Tiered Storage
-
Open the Services tab on the cluster page and click on the Kafka service name in the Name column.
Switch to the service configuration -
In the Primary configuration window that opens:
-
For S3 servers where the link to the bucket is specified not in the FQDN format, but as a path (for example, for MinIO, the link to the bucket looks like this: http://<s3hostname:port>/browser/<bucket.name>), set the remote storage parameter, which determines the appropriate type of a link to the bucket:
rsm.config.storage.s3.path.style.access.enabled=trueTo do this, expand the server.properties group and, using the Add key,value field, select Add property and enter the name of the parameter and its value.
-
Set the S3 Tiered Storage switch to active and enter the parameter values for connecting to S3 storage.
NOTEThe value of the storage.s3.region parameter cannot be empty. If the S3 server does not provide such a parameter, set it to any value, for example,
none. -
If necessary, expand the Tiered Storage General group and change the default settings.
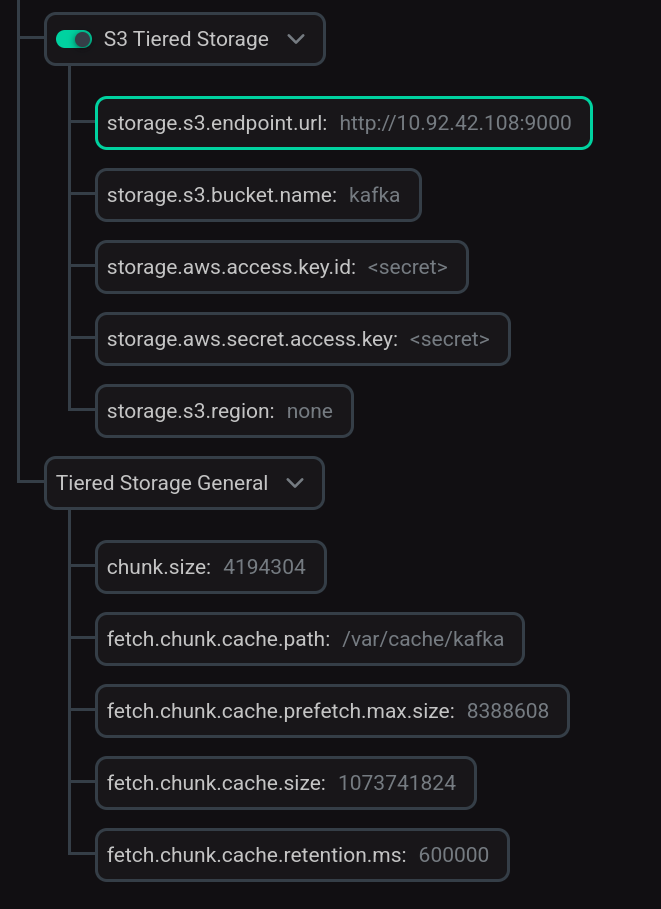 Tiered Storage configuration
Tiered Storage configurationParameter descriptions are provided in the Kafka configuration parameters article.
-
-
Click Save and restart the Kafka service using the Restart action by clicking
in the Actions column. -
Wait until the service restarts. Analyze and correct errors if they occur on the Jobs page.
Step 2. Check the results
When you enable the Tiered Storage option via the ADCM interface, all the necessary parameters for working with storage are automatically set in the Kafka broker configuration file /etc/kafka/conf/server.properties (/usr/lib/kafka/config/kafka-controller.properties if KRaft mode is enabled): parameters of Remote Manager components , StorageBackend (automatically determined for the selected type of storage), and the chunking mechanism.
Below is an example of a configuration file modified by ADCM.
# Managed by ADCM
node.id=1
reserved.broker.max.id=5000
auto.create.topics.enable=False
listeners=PLAINTEXT://:9092
log.dirs=/kafka-logs
default.replication.factor=1
num.partitions=1
delete.topic.enable=true
log.retention.hours=168
log.roll.hours=168
queued.max.requests=500
num.network.threads=3
num.io.threads=8
auto.leader.rebalance.enable=True
unclean.leader.election.enable=False
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
zookeeper.connect=sov-ads-test-2.ru-central1.internal:2181/arenadata/cluster/154
zookeeper.connection.timeout.ms=30000
zookeeper.session.timeout.ms=30000
zookeeper.sync.time.ms=2000
zookeeper.set.acl=false
log.cleaner.enable=True
log.cleanup.policy=delete
log.cleanup.interval.mins=10
log.cleaner.min.compaction.lag.ms=0
log.cleaner.delete.retention.ms=86400000
rlmm.config.remote.log.metadata.topic.replication.factor=1
rsm.config.storage.s3.path.style.access.enabled=true
security.inter.broker.protocol=PLAINTEXT
remote.log.metadata.manager.listener.name=PLAINTEXT
remote.log.storage.manager.class.name=io.aiven.kafka.tieredstorage.RemoteStorageManager
remote.log.storage.manager.class.path=/usr/lib/kafka/libs/tiered-storage/*
remote.log.storage.system.enable=true
rsm.config.chunk.size=4194304
rsm.config.fetch.chunk.cache.class=io.aiven.kafka.tieredstorage.fetch.cache.DiskChunkCache
rsm.config.fetch.chunk.cache.path=/var/cache/kafka
rsm.config.fetch.chunk.cache.prefetch.max.size=8388608
rsm.config.fetch.chunk.cache.size=1073741824
rsm.config.fetch.chunk.cache.retention.ms=600000
rsm.config.storage.backend.class=io.aiven.kafka.tieredstorage.storage.s3.S3Storage
rsm.config.storage.s3.endpoint.url=http://<s3hostname:port>
rsm.config.storage.s3.bucket.name=kafka
rsm.config.storage.aws.access.key.id=<access key>
rsm.config.storage.aws.secret.access.key=<secret key>
rsm.config.storage.s3.region=noneTo check the correct configuration of Tiered Storage for Kafka, you can write data to a test topic and monitor the data transfer to the storage, as described below.
Ozone
For this example, the Ozone service of the Arenadata Hadoop (ADH) cluster is used as storage.
Prerequisites
-
ADH
-
The ADH cluster is installed according to the Online installation guide.
The minimum version of ADH is 3.3.6.2.b1.
-
Zookeeper, Core configuration, HDFS, YARN, and Ozone services are added and installed in the ADH cluster.
-
The Ozone volume and bucket are created on the host where Ozone is installed:
$ ozone sh volume create volumetest $ sudo ozone sh bucket create /volumetest/testbucket
-
-
ADS
-
The ADS cluster is installed according to the Online installation guide.
The minimum version of ADS is 3.9.1.2.b1.
-
Kafka and Zookeeper services are added and installed in the ADS cluster.
-
The Tiered Storage option is not enabled for Kafka — in the /etc/kafka/conf/server.properties configuration file (/usr/lib/kafka/config/kafka-controller.properties, if KRaft mode is enabled), no values are set for the
rsm.config.storageandremote.log.storageparameter groups. -
In ADS, ADH data import has been completed. To perform the import in the ADCM interface, open the Clusters page and click on the ADS cluster name. Then, on the cluster page that opens, go to the Import tab, select Cluster configuration next to the ADH cluster name, and click Import.
Import ADH dataRestart the cluster using the Restart action.
As a result of the import, on hosts with the Kafka service, ADH configuration files are located in the /usr/lib/kafka/config/ folder:
Also, as a result of the import in the /etc/kafka/conf/kafka-java.yaml configuration file, a value for the
HADOOP_CONF_DIRparameter is set — the location where the ADH cluster configuration files are copied.
-
Step 1. Configure and enable Tiered Storage
-
Open the Services tab on the cluster page and click on the Kafka service name in the Name column.
Switch to the service configuration -
In the Primary configuration window that opens:
-
Set the Ozone Tiered Storage switch to active and change the default settings as necessary.
The value of the Ozone Path parameter is set to
<ozone.om.service.ids>/volumetest/testbucket, where:-
<ozone.om.service.ids>— the value of the corresponding parameter of the Ozone Manager component (the ozone-site.xml parameter group) of the Ozone service, configured during the ADH cluster installation. -
/volumetest/testbucket— the Ozone volume and bucket created earlier.
-
-
If necessary, expand the Tiered Storage General group and change the default settings.
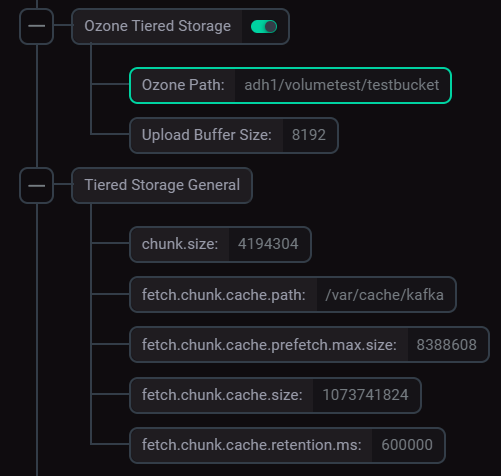 Tiered Storage configuration
Tiered Storage configuration
Parameter descriptions are provided in the Kafka configuration parameters article.
-
-
Click Save and restart the Kafka service using the Restart action by clicking
in the Actions column. -
Wait until the service restarts. Analyze and correct errors if they occur on the Jobs page.
Step 2. Check the results
When you enable the Tiered Storage option via the ADCM interface, all the necessary parameters for working with storage are automatically set in the Kafka broker configuration file /etc/kafka/conf/server.properties (/usr/lib/kafka/config/kafka-controller.properties if KRaft mode is enabled): parameters of Remote Manager components , StorageBackend (automatically determined for the selected type of storage), and the chunking mechanism.
Below is an example of a configuration file modified by ADCM.
# Managed by ADCM
node.id=3
reserved.broker.max.id=5000
auto.create.topics.enable=False
listeners=PLAINTEXT://:9092
log.dirs=/kafka-logs
default.replication.factor=1
num.partitions=1
delete.topic.enable=true
log.retention.hours=168
log.roll.hours=168
queued.max.requests=500
num.network.threads=3
num.io.threads=8
auto.leader.rebalance.enable=True
unclean.leader.election.enable=False
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
listener.security.protocol.map=PLAINTEXT:PLAINTEXT
zookeeper.connect=sov-ads-3.ru-central1.internal:2181,sov-ads-4.ru-central1.internal:2181,sov-ads-2.ru-central1.internal:218>
zookeeper.connection.timeout.ms=30000
zookeeper.session.timeout.ms=30000
zookeeper.sync.time.ms=2000
zookeeper.set.acl=false
log.cleaner.enable=True
log.cleanup.policy=delete
log.cleanup.interval.mins=10
log.cleaner.min.compaction.lag.ms=0
log.cleaner.delete.retention.ms=86400000
security.inter.broker.protocol=PLAINTEXT
remote.log.metadata.manager.listener.name=PLAINTEXT
remote.log.storage.manager.class.name=io.aiven.kafka.tieredstorage.RemoteStorageManager
remote.log.storage.manager.class.path=/usr/lib/kafka/libs/tiered-storage/*
remote.log.storage.system.enable=true
rsm.config.chunk.size=4194304
rsm.config.fetch.chunk.cache.class=io.aiven.kafka.tieredstorage.fetch.cache.DiskChunkCache
rsm.config.fetch.chunk.cache.path=/var/cache/kafka
rsm.config.fetch.chunk.cache.prefetch.max.size=8388608
rsm.config.fetch.chunk.cache.size=1073741824
rsm.config.fetch.chunk.cache.retention.ms=600000
rsm.config.storage.backend.class=io.arenadata.kafka.tieredstorage.storage.hdfs.HdfsStorage
rsm.config.storage.hdfs.core-site.path=/usr/lib/kafka/config/core-site.xml
rsm.config.storage.hdfs.root=ofs://adh1/volumetest/testbucket
rsm.config.storage.hdfs.upload.buffer.size=8192To check the correct configuration of Tiered Storage for Kafka, you can write data to a test topic and monitor the data transfer to the storage, as described below.
Use Tiered Storage
When creating a topic whose segments are to be moved to storage, you should enable the Tiered Storage option for this topic using the remote.storage.enable parameter.
If the local.retention.ms parameter is not specified for the topic, the local data storage time will correspond to the time specified for the broker.
Below is an example of creating a topic indicating the parameters, as well as indicating total storage time and segment size:
$ /usr/lib/kafka/bin/kafka-topics.sh --create --topic tieredTopic --bootstrap-server sov-ads-2.ru-central1.internal:9092 --config remote.storage.enable=true --config local.retention.ms=1000 --config retention.ms=300000 --config segment.bytes=1048576After message recording, upon expiration of the interval, with which RemoteLogManager performs segment copying (30 seconds by default), the file appears in the HDFS storage directory. These messages can be read as usual.
View a topic directory in storage
-
HDFS
You can check for the presence of a directory for the topic in the HDFS storage by executing the command:
$ sudo -u hdfs hdfs dfs -ls /kafkaDirectory for writing segments of the tieredTopic topic at the remote level:
Found 1 items drwxr-xr-x - kafka hadoop 0 2026-03-25 12:30 /kafka/tieredTopic-ku0BMor0TzC1UEkL6aVbNg
-
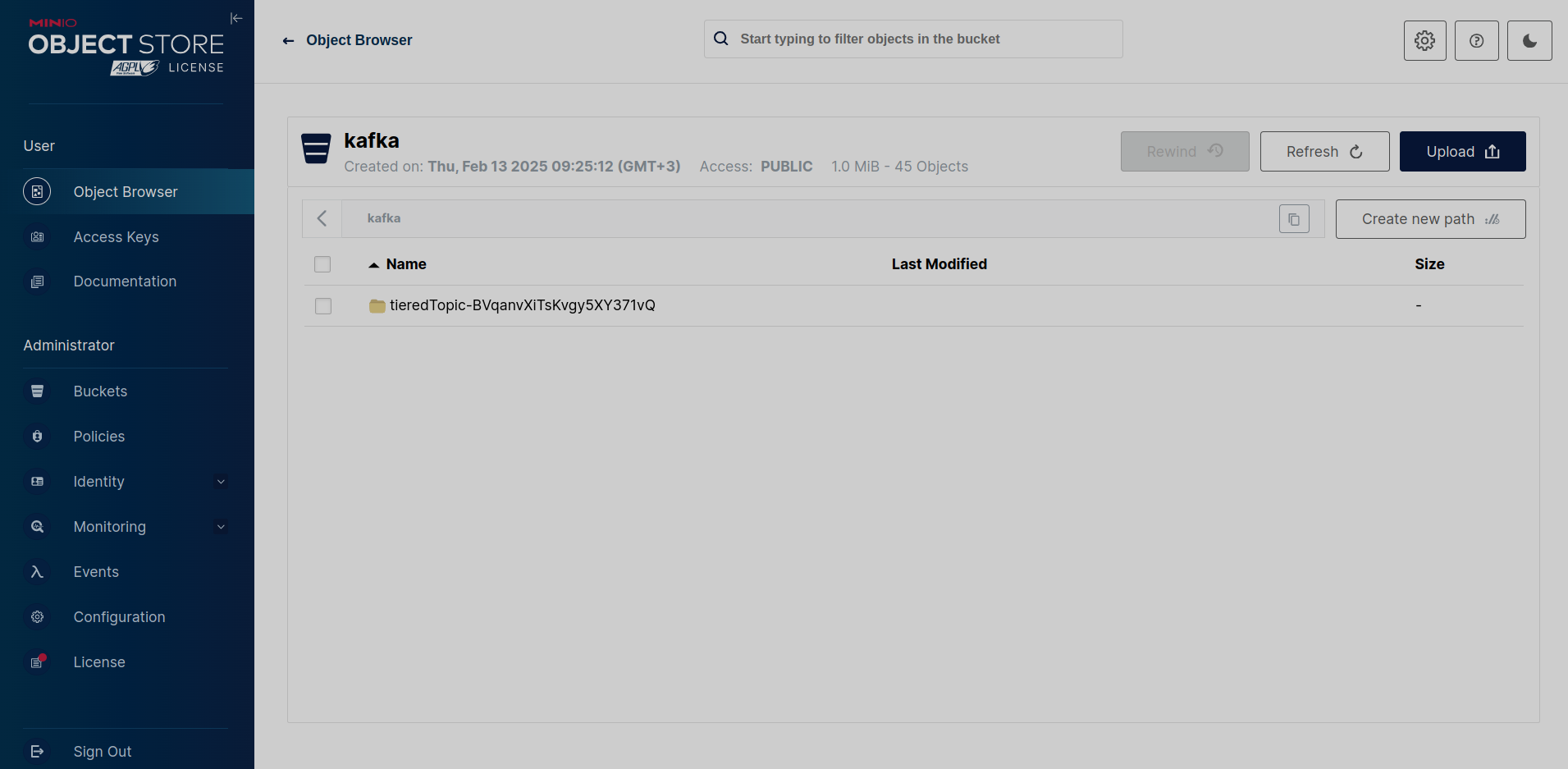
S3
The figure below shows a directory with topic segments at the remote level in the MinIO storage bucket.
-
Ozone
You can check for the presence of a directory for the topic in the Ozone storage by executing the command:
sudo hdfs dfs -ls ofs://adh1/volumetest/testbucketDirectory for writing segments of the tieredTopic topic at the remote level:
Found 1 items drwxrwxrwx - kafka root 0 2026-03-25 12:26 ofs://adh1/volumetest/testbucket/tieredTopic-ku0BMor0TzC1UEkL6aVbNg
|
NOTE
Also you can view Ozone volumes and buckets in the Ozone Recon UI. |
Overview of data stored in Tiered Storage
The tieredTopic-BVqanvXiTsKvgy5XY371vQ directory created in the repository has the name that includes the topic name (tieredTopic), followed by a dash and the topic identifier.
This directory, in turn, contains folders corresponding to partition numbers. The partition folders contain three files for each segment saved at the remote level:
-
00000000000000000009-UzfbrQXzQKOt7IqzpRh1kA.indexes — a file containing Kafka indexes that are associated with each log segment.
-
00000000000000000009-UzfbrQXzQKOt7IqzpRh1kA.log — the file, which is a log segment, contains Kafka records.
-
00000000000000000009-UzfbrQXzQKOt7IqzpRh1kA.rsm-manifest — a file containing metadata about the log segment and indexes.
Such files have a name consisting of an offset number and a log segment ID.