

Build a dataflow
This article describes an example of building a dataflow in the NiFi Server interface that implements the following tasks:
-
Write to a dataflow from a file located in a local directory.
The text file below is taken as an example. It contains descriptions of the processors that will be used to build the dataflow within the article.
Test filePutFile (put, local, copy, archive, files, filesystem) - NiFi processor that writes the contents of a FlowFile to the local file system. ConsumeKafka (kafka, get, ingest, ingress, topic, pubsub, consume) - NiFi processor that consumes messages from Apache Kafka specifically built against the Kafka Consumer API. GetFile (local, files, filesystem, ingest, ingress, get, source, input) - NiFi processor that creates FlowFiles from files in a directory. RouteText (attributes, routing, text, regexp, regex, filter, search, detect) - NiFi processor that routes textual data based on a set of user-defined rules. PublishKafka (kafka, put, send, message, pubsub) - NiFi processor that sends the contents of a FlowFile as a message to Apache Kafka using the Kafka Producer API. ReplaceText (text, update, change, replace, modify, regex) - NiFi processor that updates the content of a FlowFile by evaluating a Regular Expression (regex) against it and replacing the section of the content that matches the Regular Expression with some alternate value.
-
Replace the text
NiFiwithApache NiFiin the file. -
Post the contents of a file to a Kafka topic and view the topic.
-
Write to the dataflow from the same topic.
-
Split entries into three dataflows based on the tag:
-
files; -
kafka; -
text.
-
-
Write each dataflow to a local file.
|
NOTE
|
Prepare to create a dataflow
Before creating a dataflow, the following steps must be taken:
-
If it is necessary to restrict access on the cluster, authentication is configured in the Kafka and NiFi services in accordance with the articles:
-
Make sure the file is written to a local folder. Each folder must have read/write permission set so that the restricted processor can access the file.
Permission can be given with the
chmodcommand.An example of a command that assigns all rights to the /tmp/new folder to everyone:
$ sudo chmod -R 777 /tmp/new -
Make it possible to read the Kafka topic used in the dataflow. For information about working in Kafka, see Quick start with Kafka.
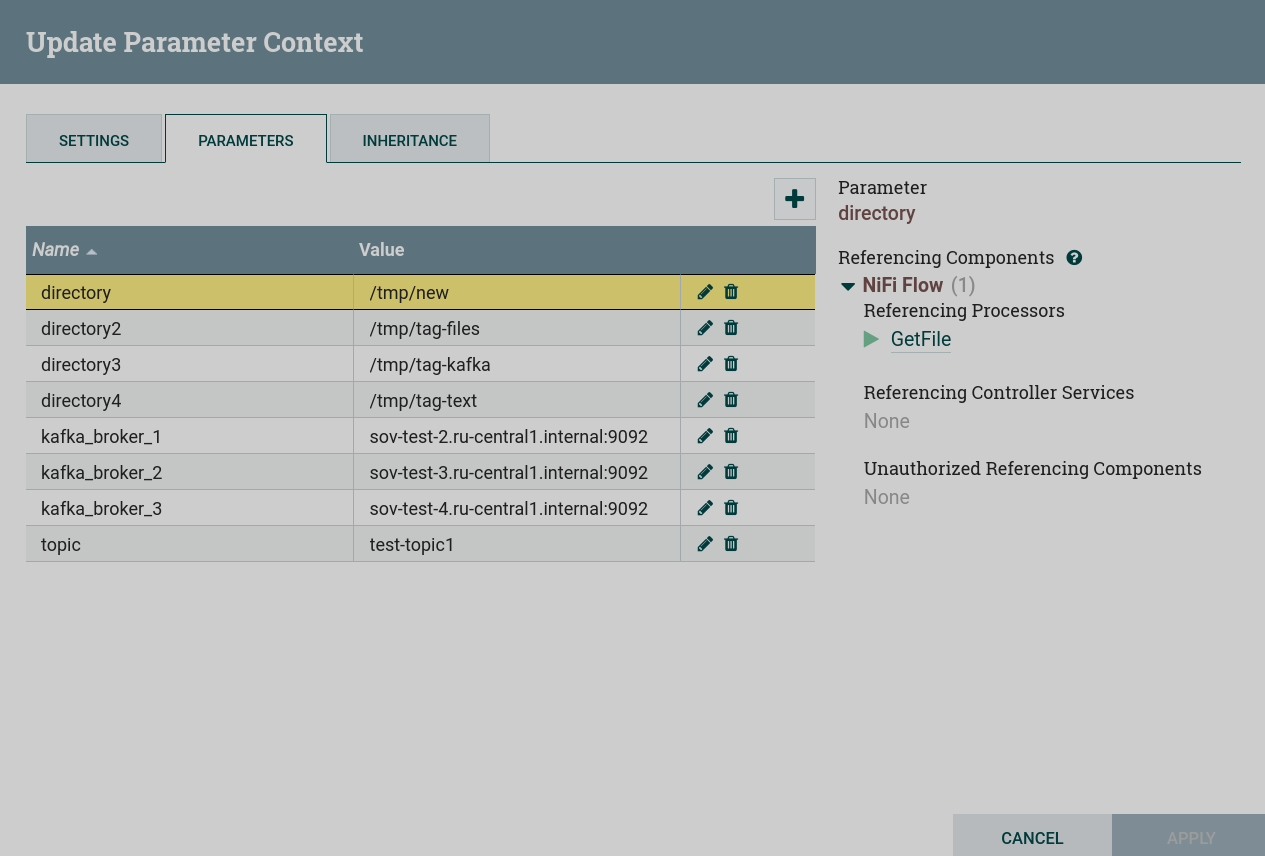
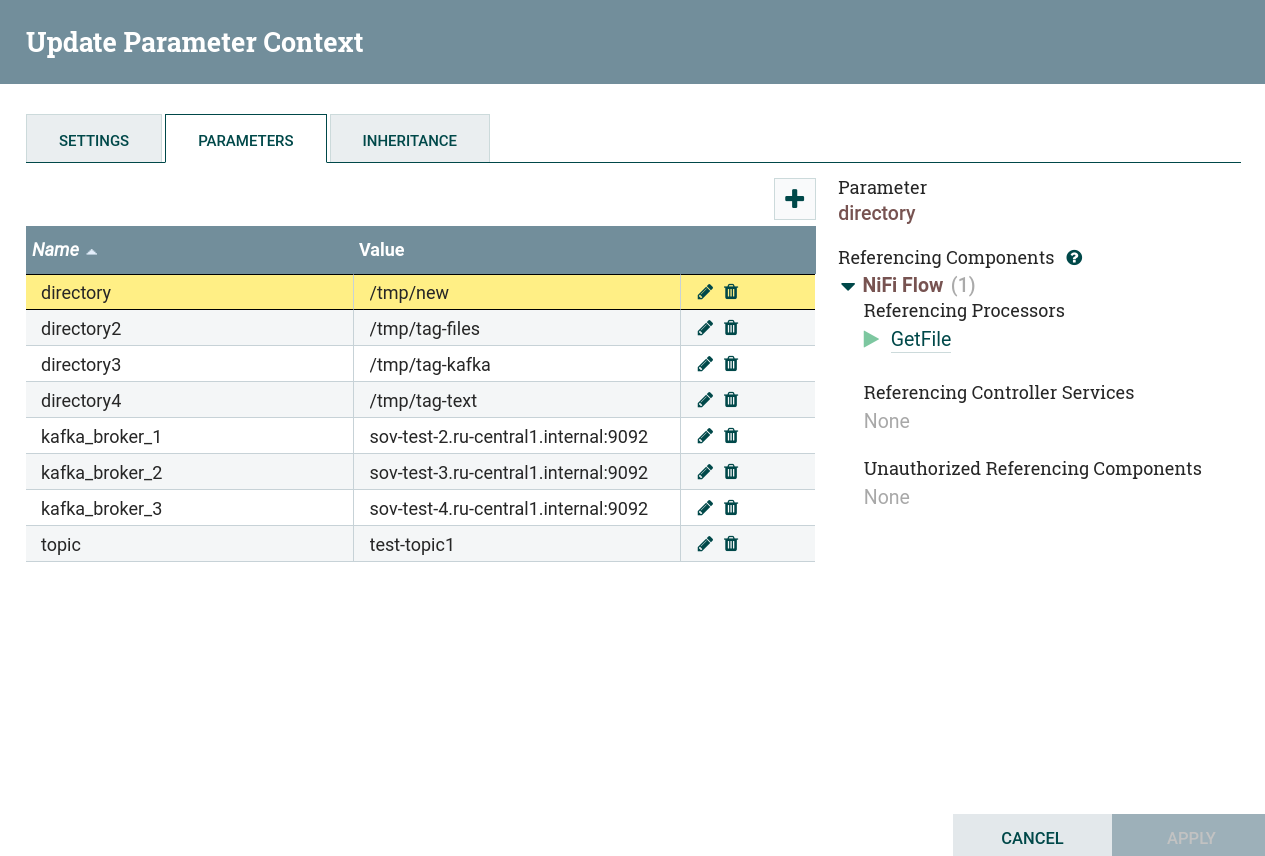
Configure permanent parameters
Parameters that need to be configured before creating this dataflow:
-
Kafka Brokers— a comma-separated list of Kafka brokers in thehost:portformat, required for all connections to a Kafka broker. -
Topic Name— the name of the Kafka topic from which data is being retrieved or written to. -
Directory— the directory where files are to be written to or from which they are to be retrieved.
For this task, the parameters are configured using the parameter context.
|
NOTE
How to create and manage parameters and attributes is described in the article Work with attributes. |
Write to a dataflow from a file
Writing to a dataflow from a local file is produced in the following sequence:
-
Create a processor. To obtain data from external sources, you can use processors that can be found by the
gettag. This task uses the processor GetFile. This processor is restricted. To use this processor, you must grant read and write permission to the corresponding folder when preparing to create a dataflow.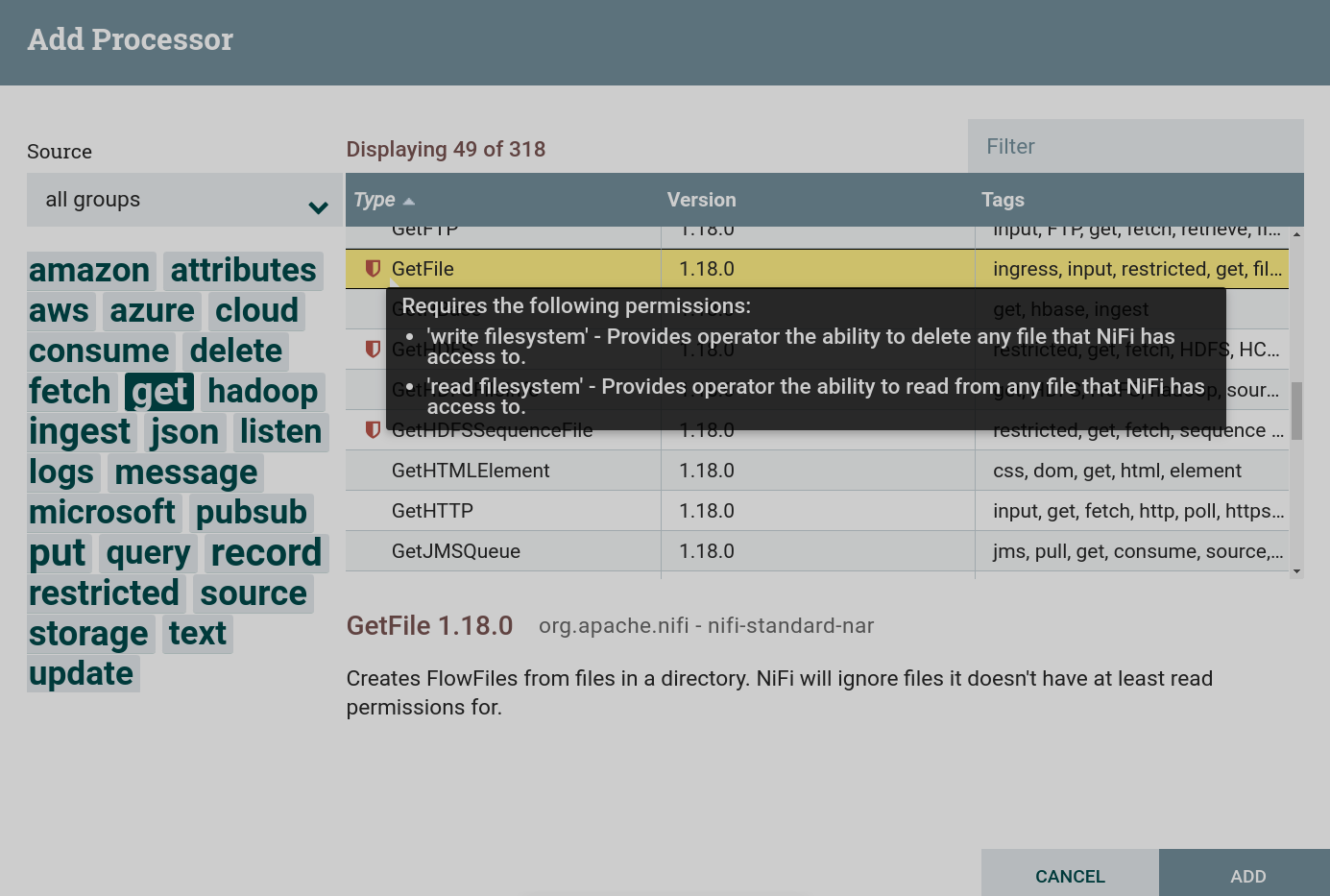 Creating a GetFile processor
Creating a GetFile processor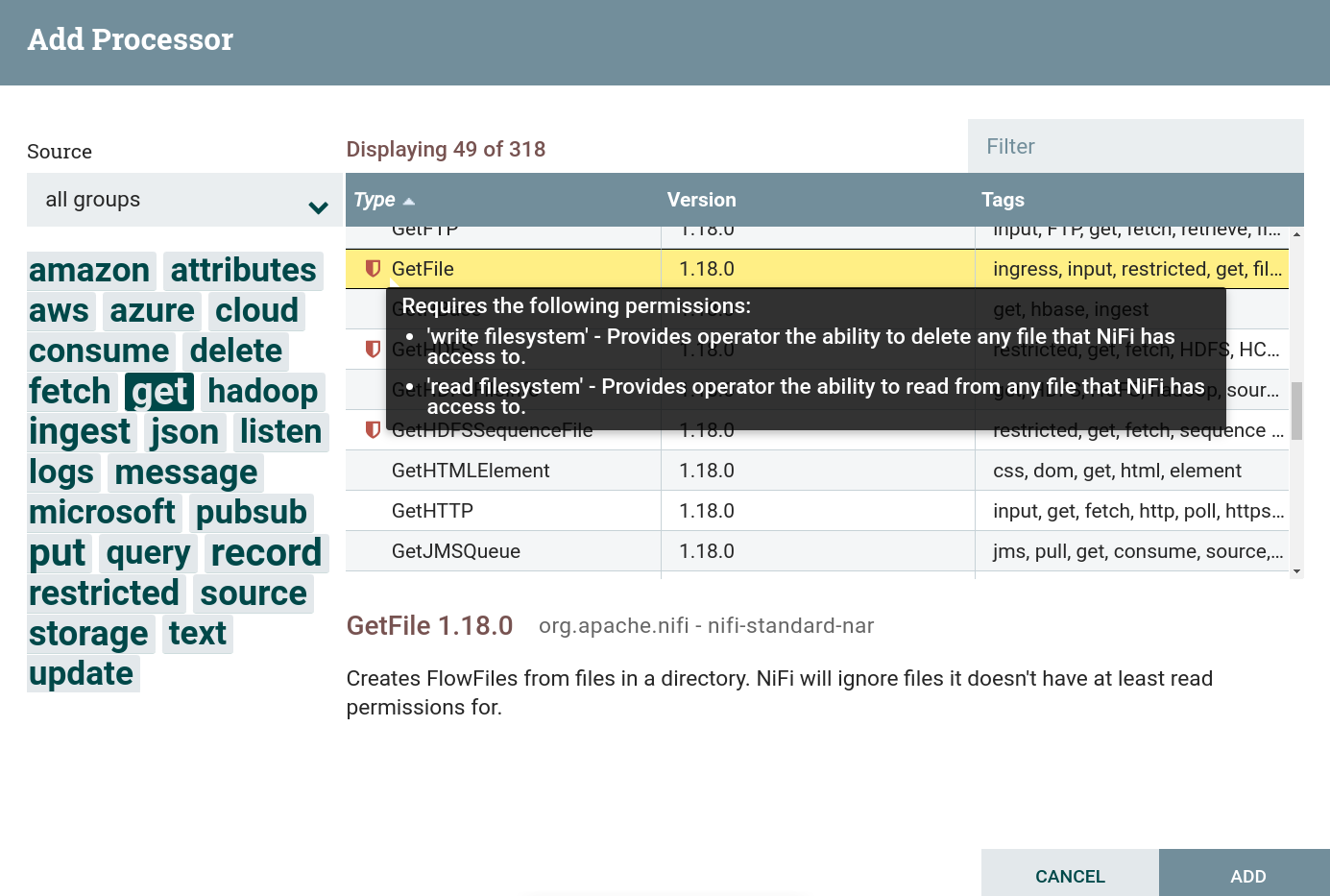 Creating a GetFile processor
Creating a GetFile processor -
Configure required processor options:
-
On the PROPERTIES tab the Input Directory parameter — the directory from which the file should be read (for this dataflow, the value is entered from the parameter context).
-
On the RELATIONSHIPS tab parameter Relationships success — the relationship determined by the processor relative to the thread connected to it.
As a result of setting the necessary parameters, the processor state is displayed as an indicator
 .
.
-
-
Start the created processor. If there is a file in the local folder, then after the processor starts, the contents of the file enter the dataflow. When working correctly, the processor image in the corresponding line of 5-minute statistics displays the amount of data read by the processor.
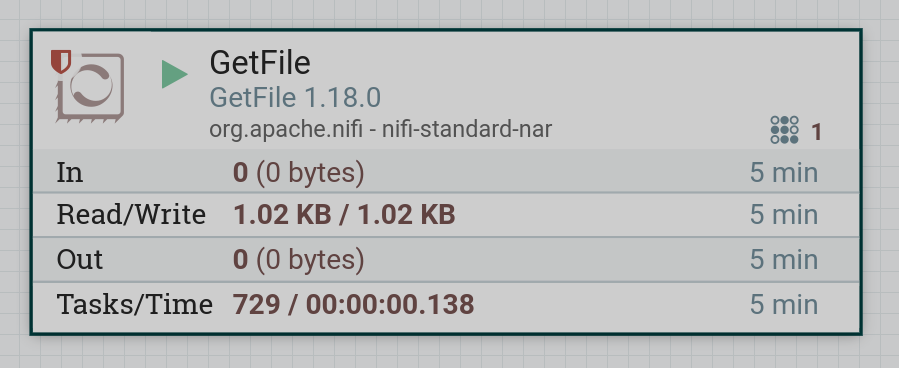
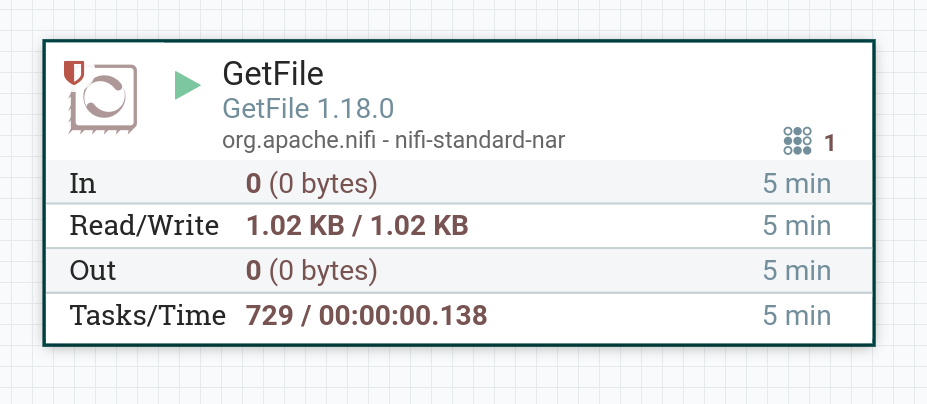
|
CAUTION
A GetFile processor after reading removes the read file from the directory. Therefore, each time before starting the dataflow, it is necessary to write the file to the specified directory. |
Replace a text in a dataflow
Replacing text in a dataflow file is produced in the following sequence:
-
Create a processor. To work with text, you can use processors that can be found under the
texttag. This task uses the processor ReplaceText.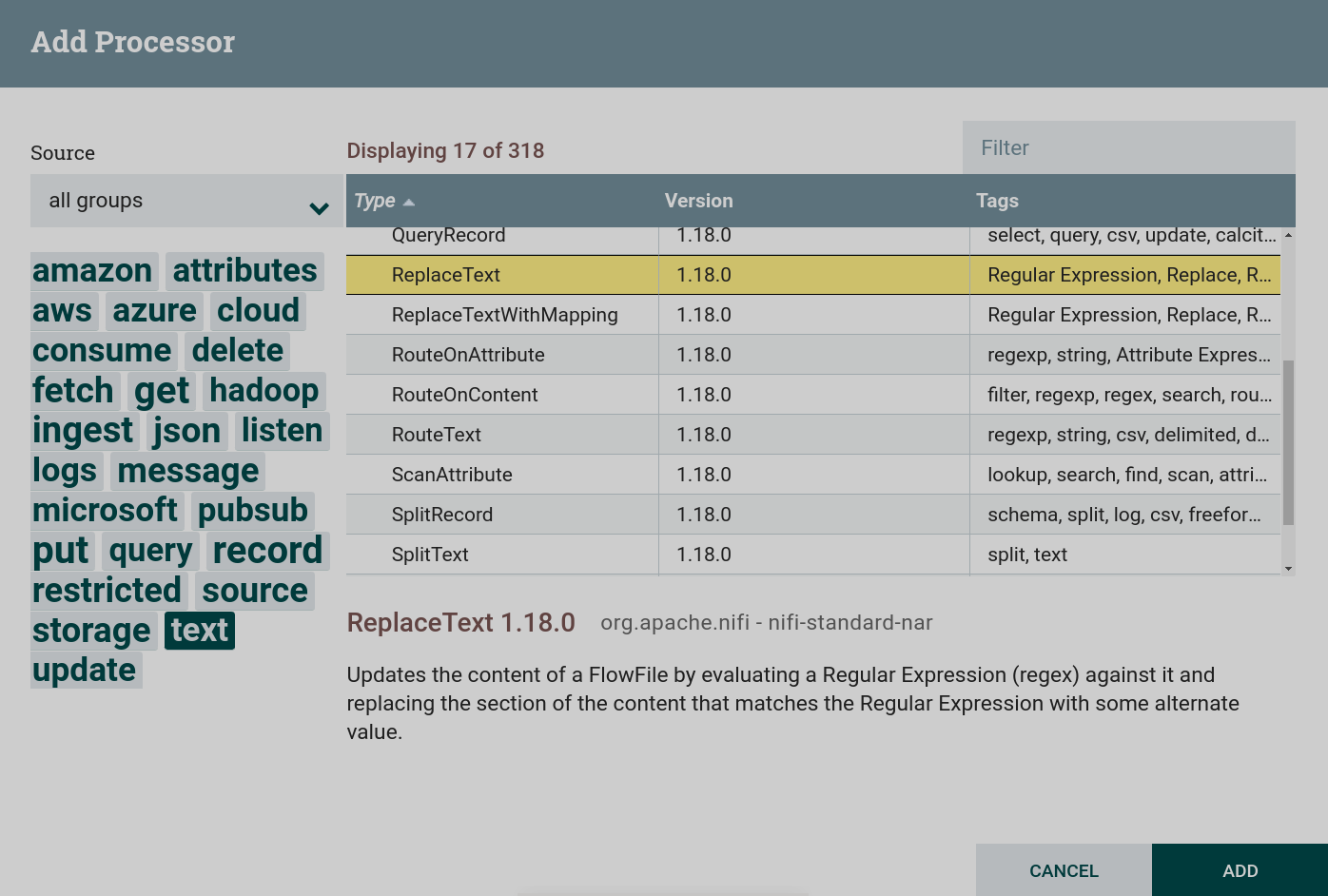 Creating a ReplaceText Processor
Creating a ReplaceText Processor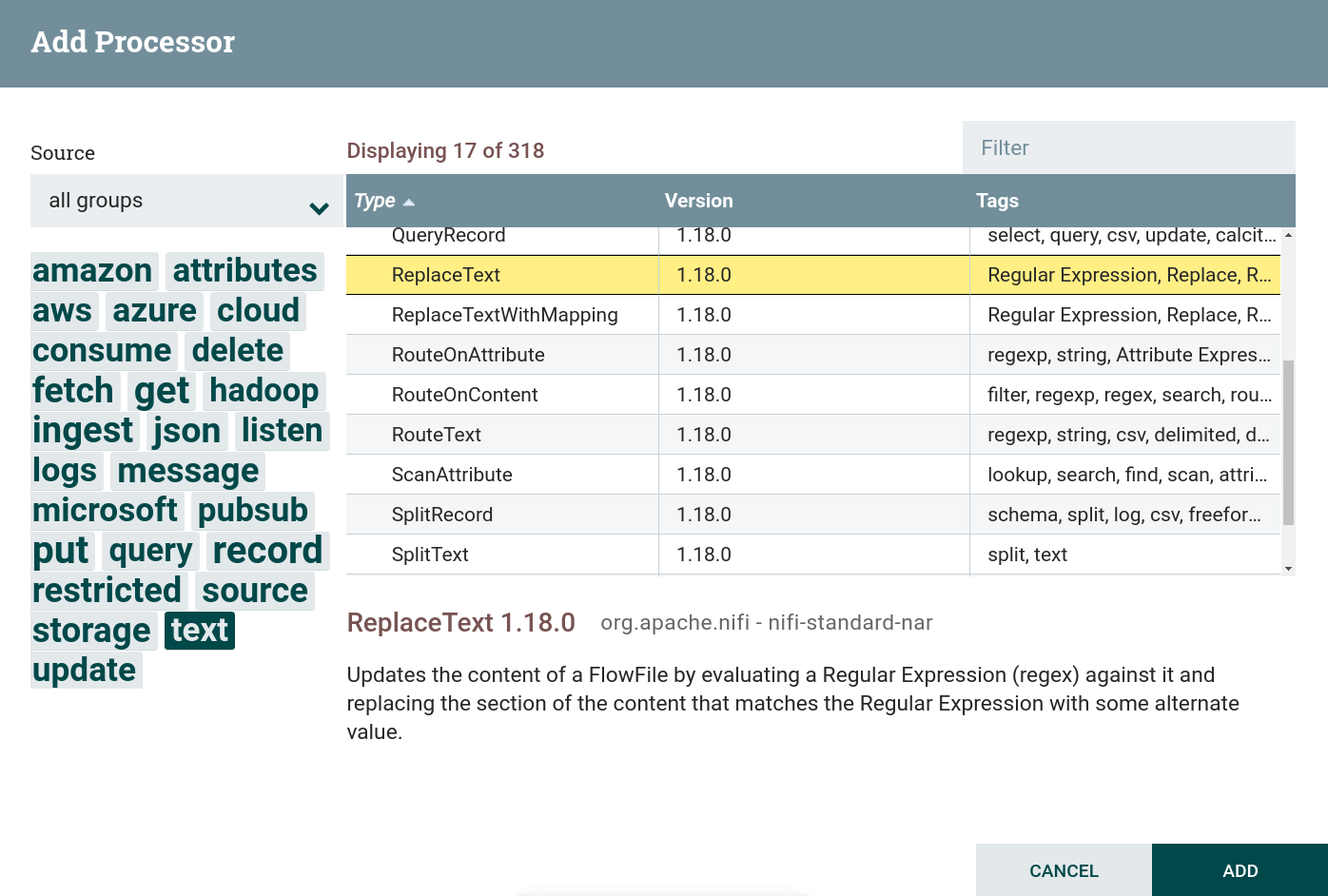 Creating a ReplaceText Processor
Creating a ReplaceText Processor -
Configure required processor options:
-
On the PROPERTIES tab :
-
Search Value — part of the text to be replaced. In this dataflow, this value is
NiFi. -
Replacement Value — replacement text. In this dataflow, this value is
Apache NiFi.
-
-
On the RELATIONSHIPS tab parameter Relationships success — the relationship determined by the processor relative to the thread connected to it.
As a result of setting the necessary parameters, the processor state is displayed as an indicator
.
-
-
Create and configure a processor connection with the GetFile processor.
-
Start created processors. After the processor starts, the contents of the file from the GetFile processor are queued to the ReplaceText processor. When working correctly, the processor image in the corresponding line of 5-minute statistics displays the amount of data read by the processor. The amount of recorded (modified) data is also given. The volume of the written down data differs from read — the part of the text is replaced.


Publish dataflow content to a Kafka topic
Publishing the contents of a file to a Kafka topic is produced in the following sequence:
-
Create a processor. To work with writing data to external file systems, including Kafka, you can use processors that can be found by the
pubsubtag. This task uses the processor PublishKafka.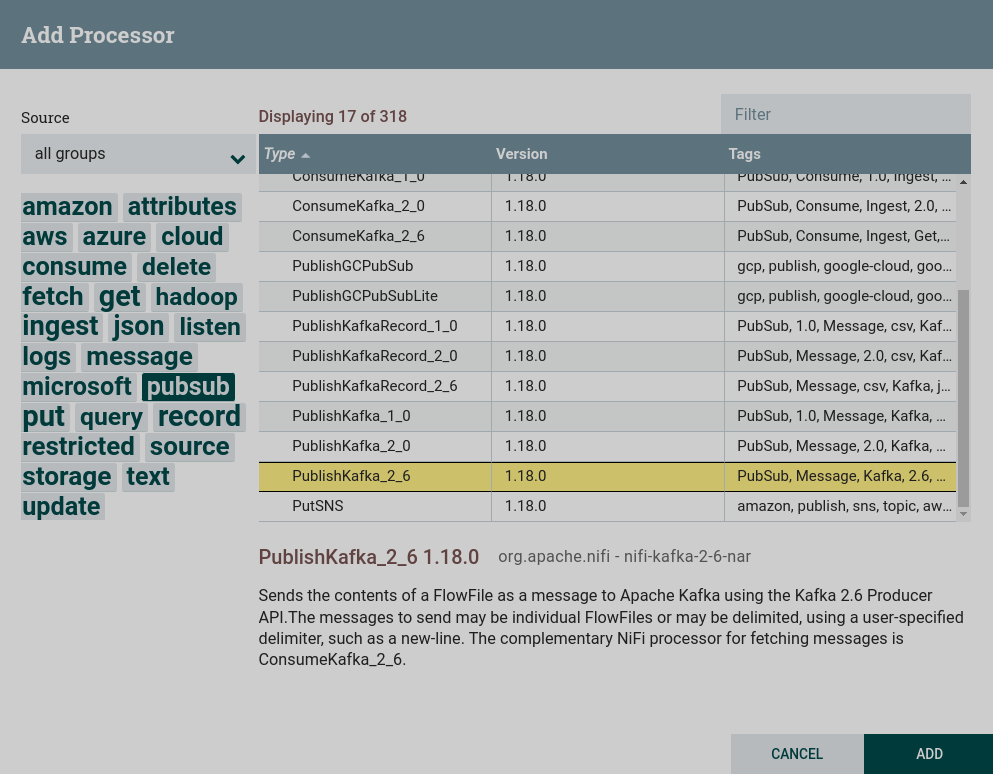 Creating a PublishKafka processor
Creating a PublishKafka processor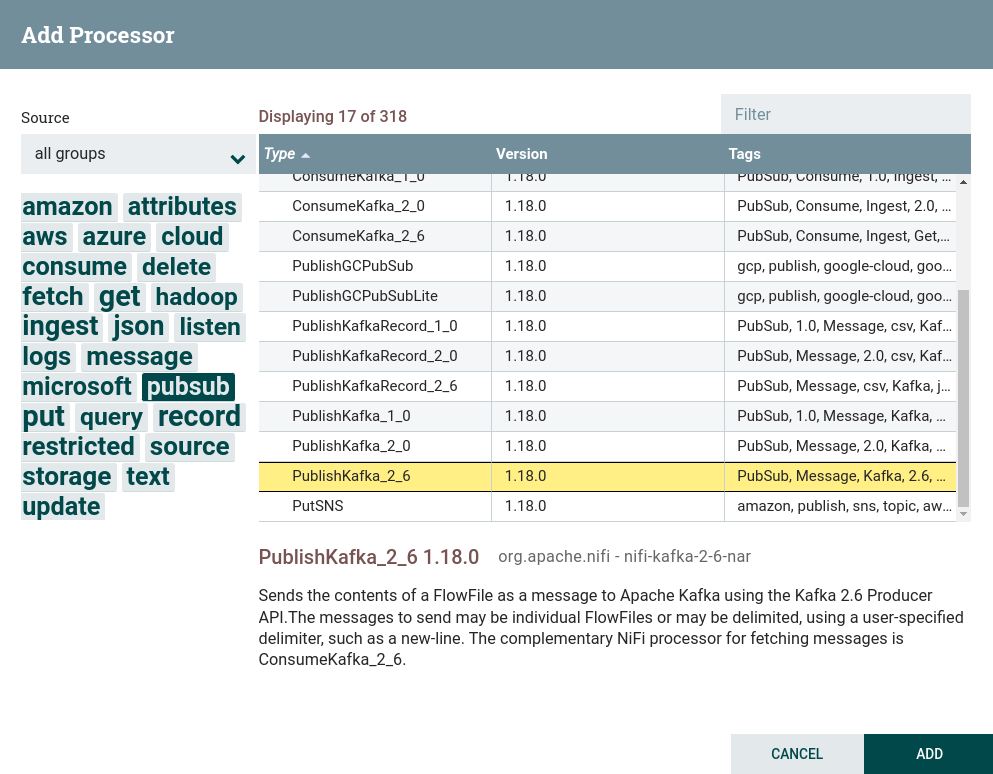 Creating a PublishKafka processor
Creating a PublishKafka processor -
Configure required processor options:
-
On the PROPERTIES tab :
-
Kafka Brokers — brokers for connecting to Kafka.
-
Topic Name — the topic to which the data is published.
For this dataflow, the values are from the preconfigured parameter context.
-
-
On the RELATIONSHIPS tab parameter Relationships success — the relationship determined by the processor relative to the thread connected to it.
As a result of setting the necessary parameters, the processor state is displayed as an indicator
.
-
-
Create and configure a processor connection with the ReplaceText processor.
-
Start created processors. After starting the processors, the contents of the file from the ReplaceText processor are queued to the PublishKafka processor and published to the specified topic. When working correctly, the processor image in the corresponding line of 5-minute statistics displays the amount of data read by the processor.
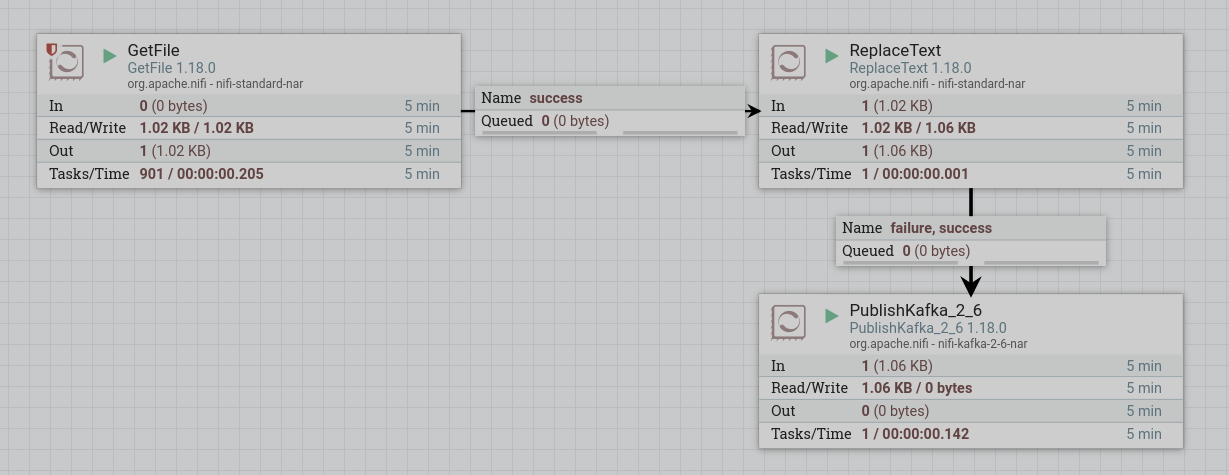
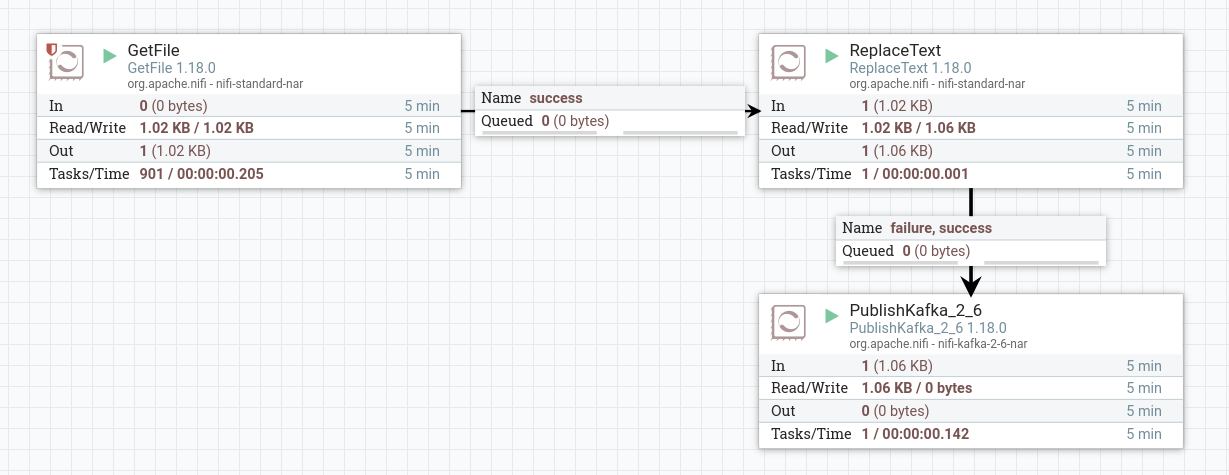
To view the received data, you need to read the data from a Kafka topic using the command line. If the processors are configured correctly, as a result, lines with changed text are displayed.
PutFile (put, local, copy, archive, files, filesystem) - Apache NiFi processor that writes the contents of a FlowFile to the local file system. ConsumeKafka (kafka, get, ingest, ingress, topic, pubsub, consume) - Apache NiFi processor that consumes messages from Apache Kafka specifically built against the Kafka Consumer API. GetFile (local, files, filesystem, ingest, ingress, get, source, input) - Apache NiFi processor that creates FlowFiles from files in a directory. RouteText (attributes, routing, text, regexp, regex, filter, search, detect) - Apache NiFi processor that routes textual data based on a set of user-defined rules. PublishKafka (kafka, put, send, message, pubsub) - Apache NiFi processor that sends the contents of a FlowFile as a message to Apache Kafka using the Kafka Producer API. ReplaceText (text, update, change, replace, modify, regex) - Apache NiFi processor that updates the content of a FlowFile by evaluating a Regular Expression (regex) against it and replacing the section of the content that matches the Regular Expression with some alternate value.
|
NOTE
Data written from a NiFi dataflow to a Kafka topic can be used in further transfer to file platforms or databases, for example using Kafka Connect tools. Also, after processing the data, they can be written to Kafka, processed and transmitted further by the NiFi dataflow. |
Get data from a Kafka topic
Getting data from a Kafka topic is produced in the following sequence:
-
Create a processor. To work with receiving data from external file systems, including Kafka, you can use processors that can be found by the
consumetag. This task uses a processor ConsumeKafka.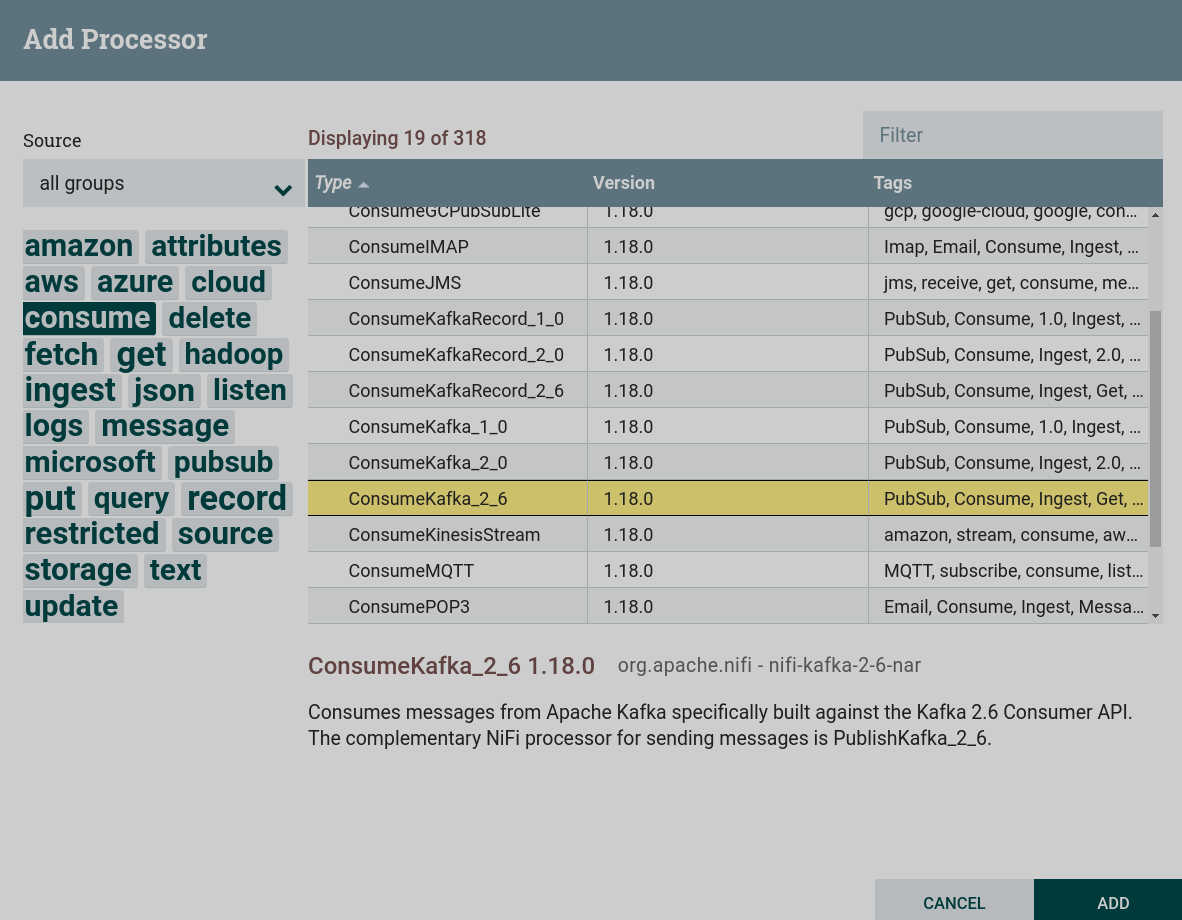 Creating a ConsumeKafka processor
Creating a ConsumeKafka processor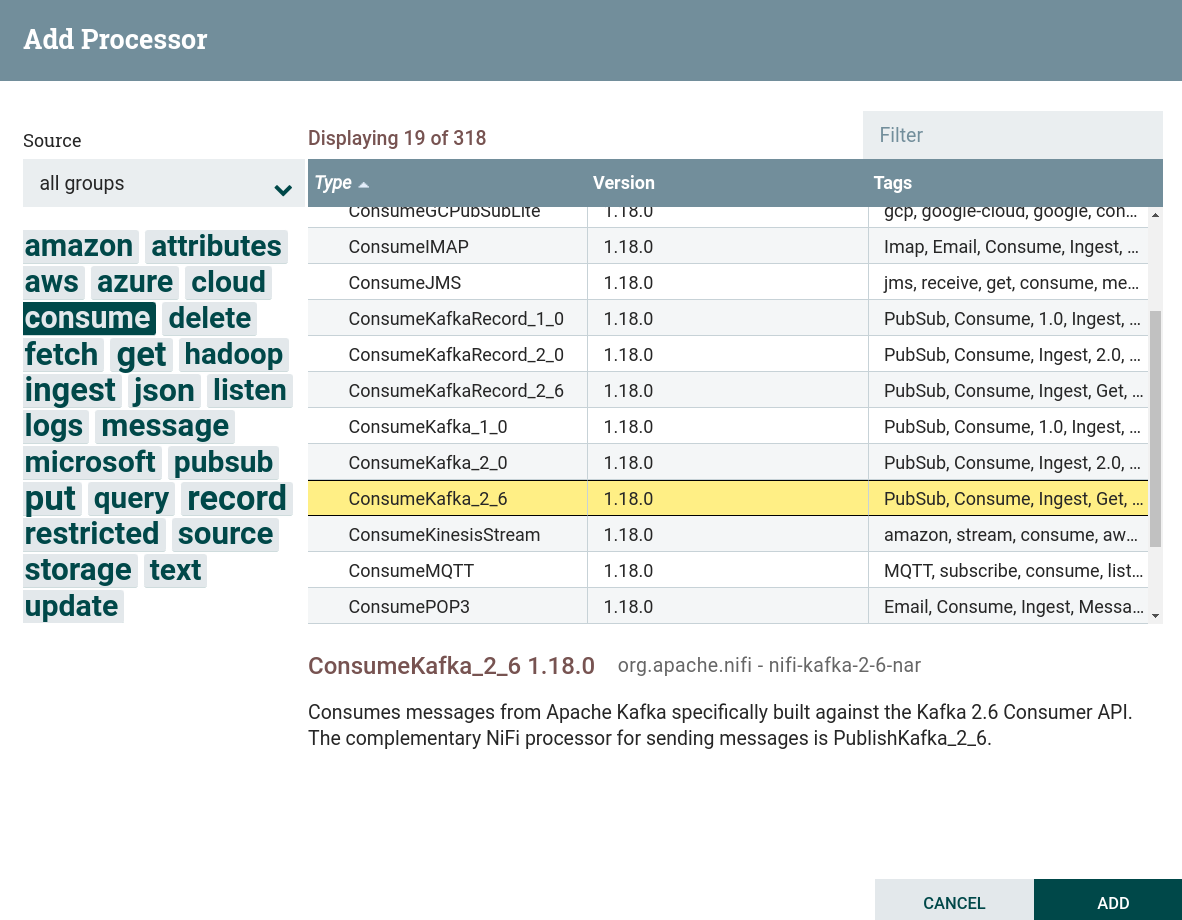 Creating a ConsumeKafka processor
Creating a ConsumeKafka processor -
Configure required processor options:
-
On the PROPERTIES tab :
-
Kafka Brokers — brokers for connecting to Kafka.
-
Topic Name — the topic to which the data is published.
-
Group ID — group ID to identify consumers that belong to the same consumer group. Corresponds to the
group.idparameter in Kafka.For this dataflow, the values are from the preconfigured parameter context.
-
-
On the RELATIONSHIPS tab parameter Relationships success — the relationship determined by the processor relative to the thread connected to it.
As a result of setting the necessary parameters, the processor state is displayed as an indicator
.
-
-
Start created processors. After the processor starts, the content of the topic is written to the dataflow file. When working correctly, the processor image in the corresponding line of 5-minute statistics displays the amount of data read by the processor.
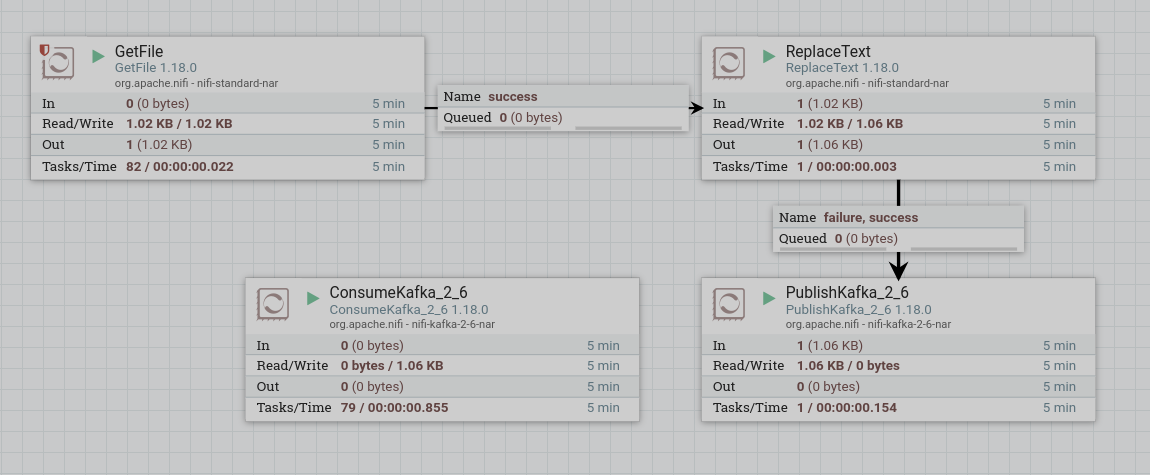
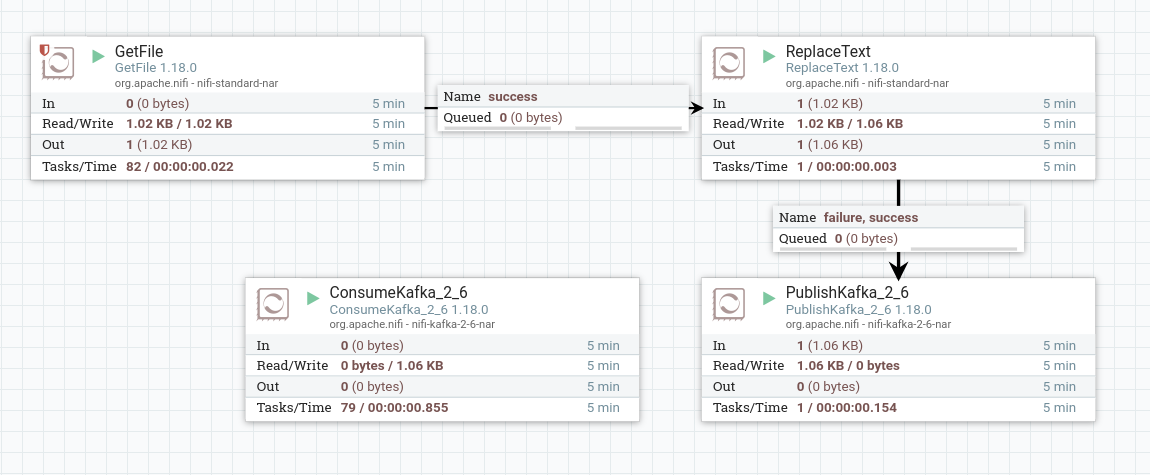
Split the data into multiple dataflows
Splitting the data into multiple dataflows is produced in the following sequence:
-
Create a processor. To work with data and text filtering, you can use processors that can be found by the
textandfiltertags. This task uses a processor RouteText.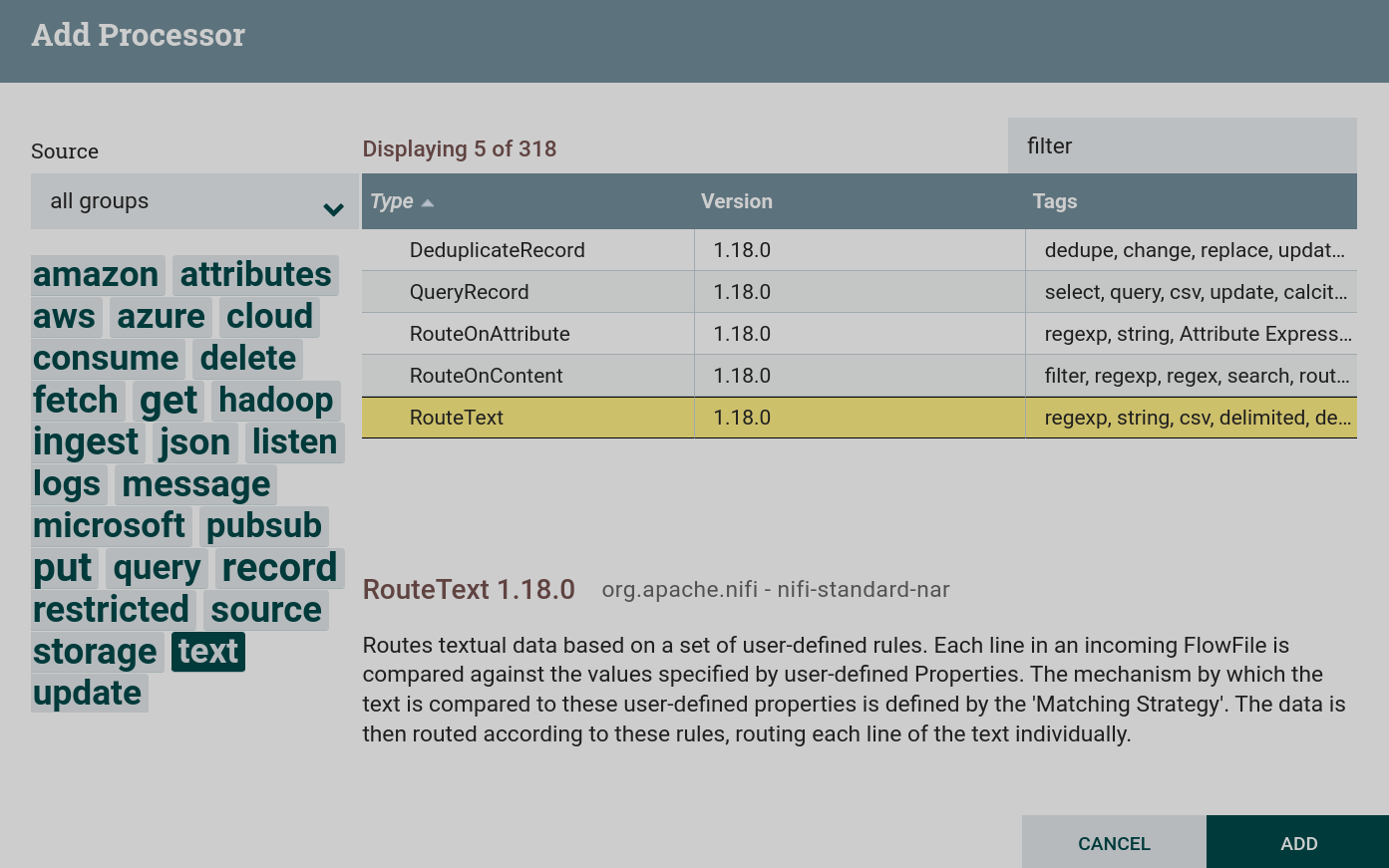 Creating a RouteText processor
Creating a RouteText processor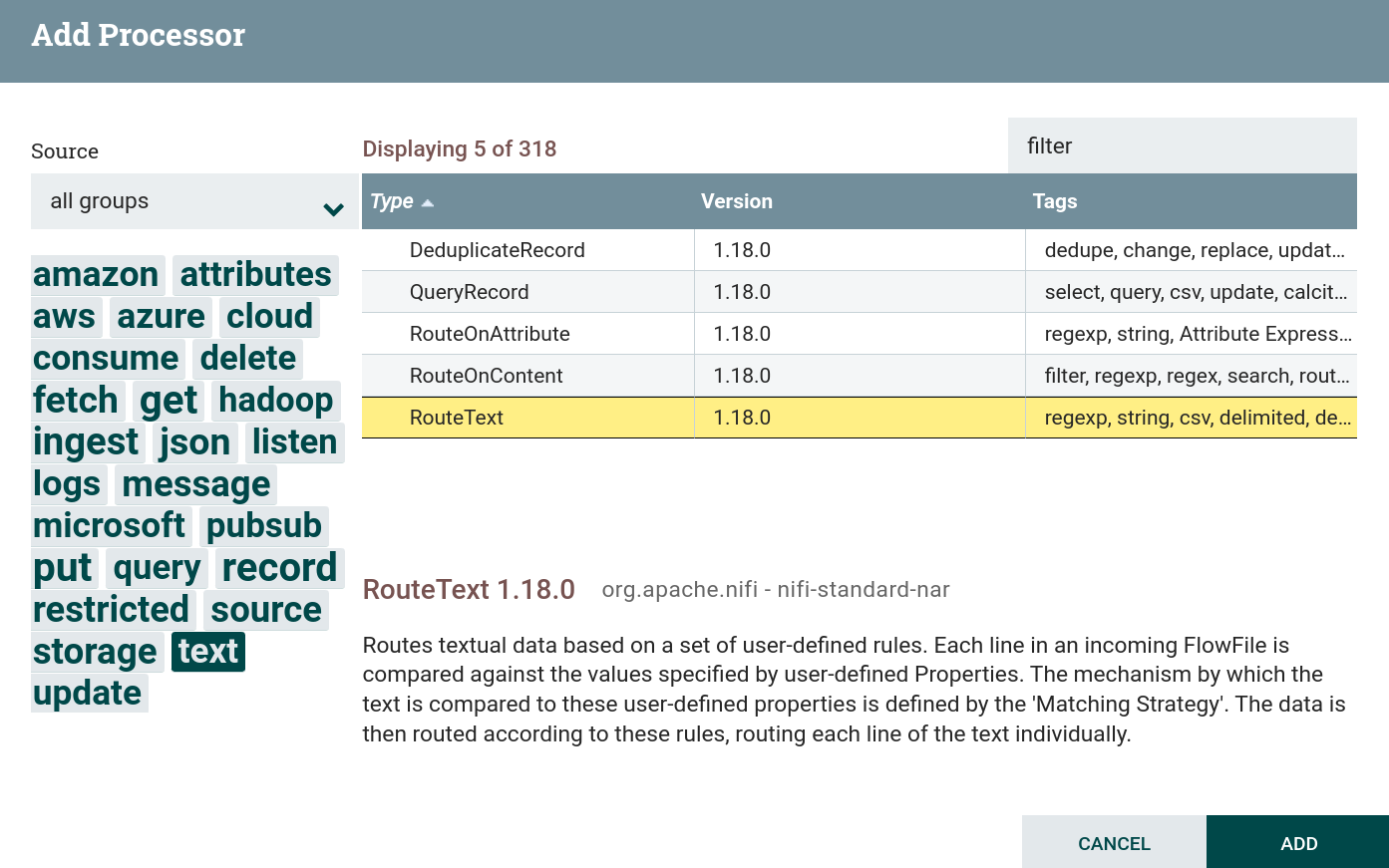 Creating a RouteText processor
Creating a RouteText processor -
Configure required processor options:
-
On the PROPERTIES tab :
-
Routing Strategy — set to
Route to "matched" if lines matches any condition. This setting will send to the matched dataflow all lines matching the given condition. -
Matching Strategy — set to
Contains Regular Expression. This sets the string to check against the content of the text specified in the regular expression specified as a custom property. -
A custom property that will be a condition for selecting the desired rows. For the text used in the example, you can filter lines by tags written in brackets. For example, if you set the custom property
tagswith the value given by the regular expression(.*files.*), then the processor will select only lines taggedfilesfrom all the lines provided.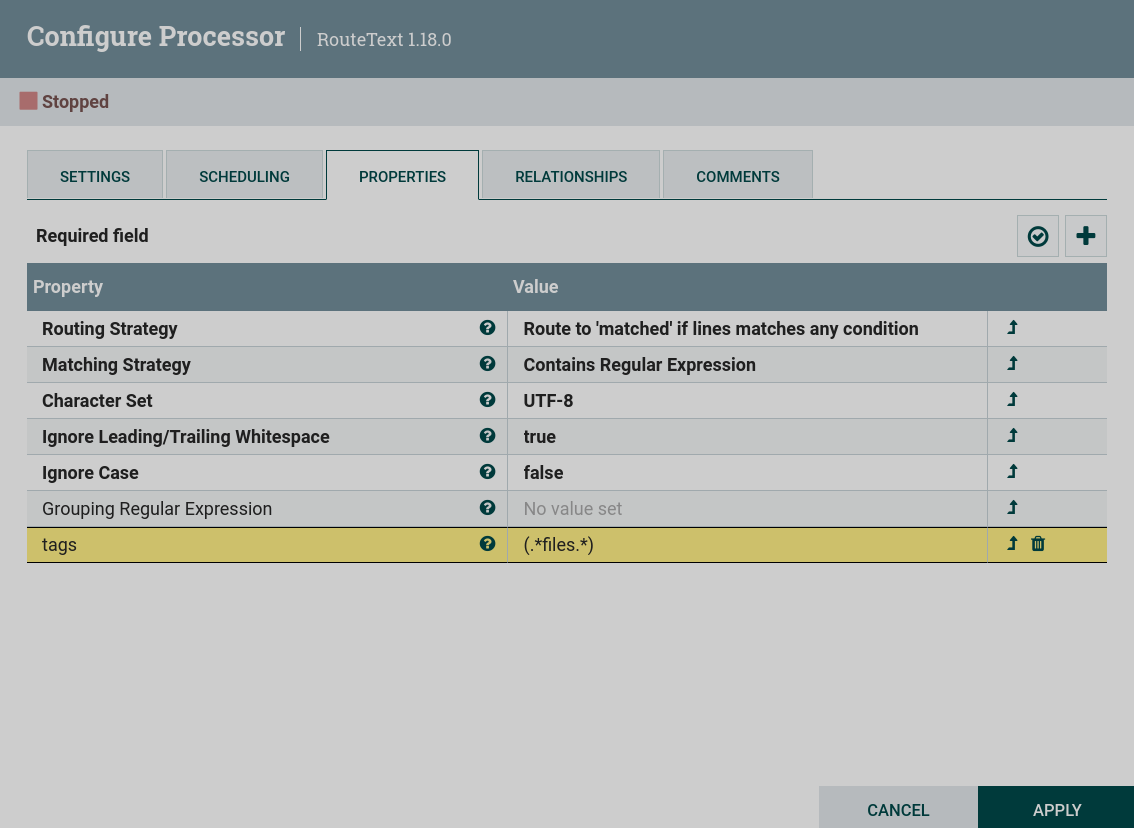 Configuring the RouteText processor
Configuring the RouteText processor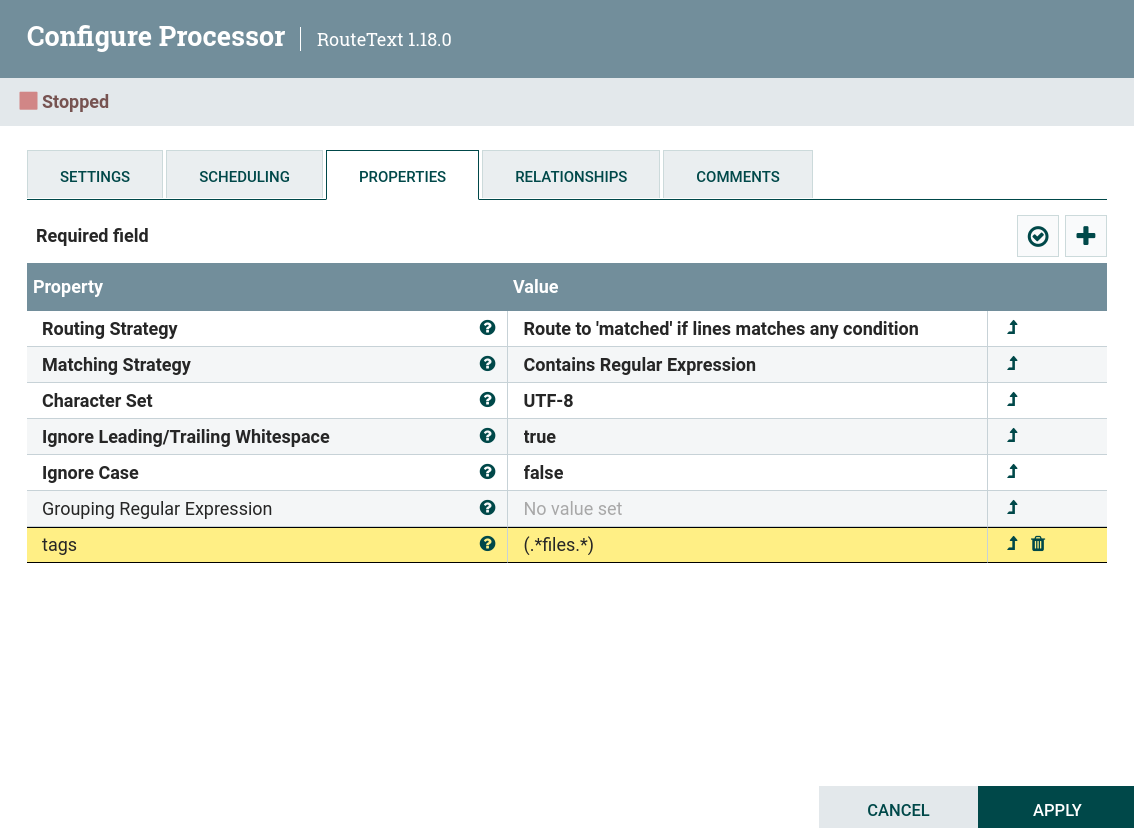 Configuring the RouteText processor
Configuring the RouteText processorFor example, three processors are created in the dataflow, dividing the text into three dataflows:
-
processors containing the
filestag; -
processors containing the
kafkatag; -
processors containing the
texttag.
-
-
-
On the RELATIONSHIPS tab parameter Relationships success — the relationship determined by the processor relative to the thread connected to it.
As a result of setting the necessary parameters, the processor state is displayed as an indicator
.
-
-
Create and configure a processor connection with the ConsumeKafka processor.
-
Start created processors. After starting the entire group of processes, the processors read the contents of the dataflow. When working correctly, the processor image in the corresponding line of 5-minute statistics displays the amount of data read by the processor.
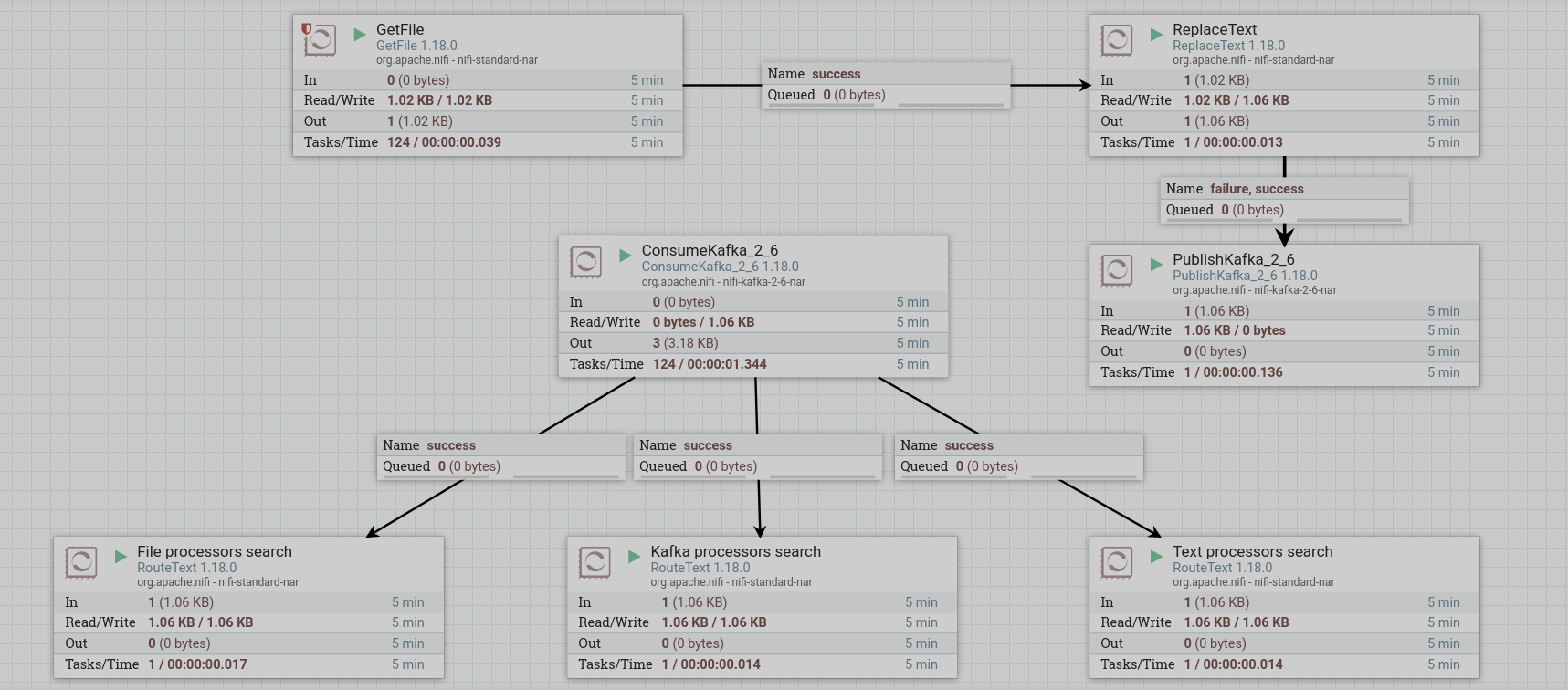
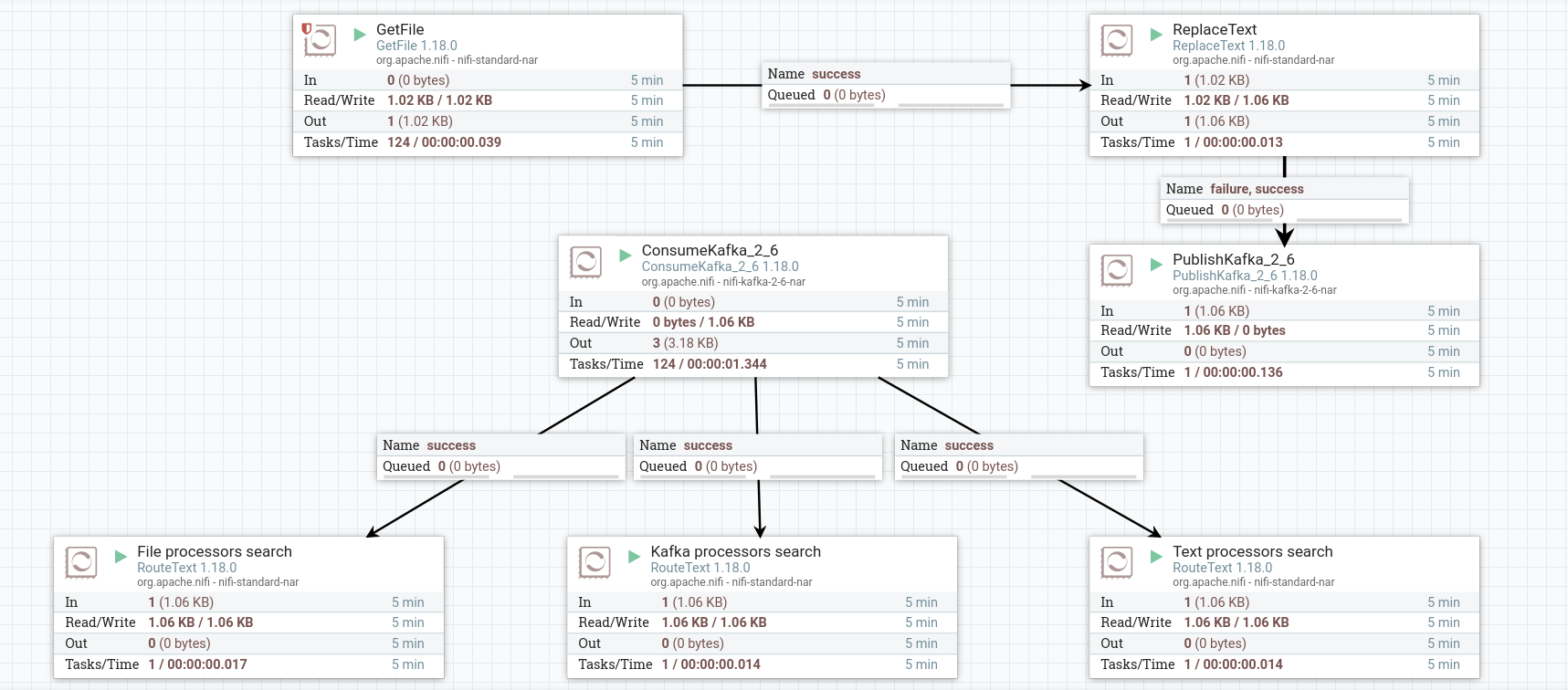
Write dataflow content to a file
In order to see how the RouteText processors filtered out the source lines, you can write the contents of each dataflow created into three different files.
Writing a dataflow to a local file is produced in the following sequence:
-
Create a processor. To write data from a dataflow, you can use processors that can be found by the
puttag. This task uses the processor PutFile. This processor is restricted. To use this processor, grant read and write permission to the corresponding folder when preparing to create a dataflow.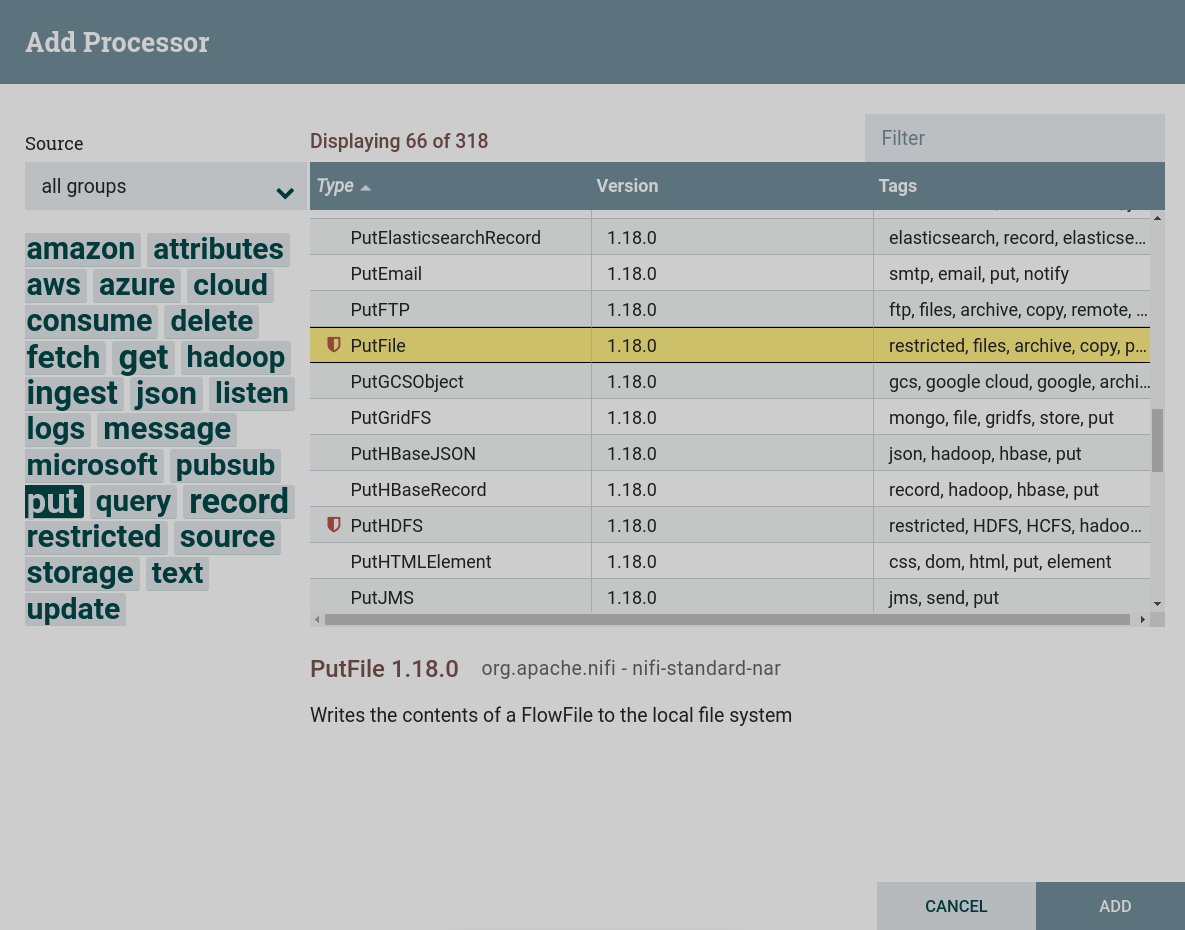 Creating a PutFile processor
Creating a PutFile processor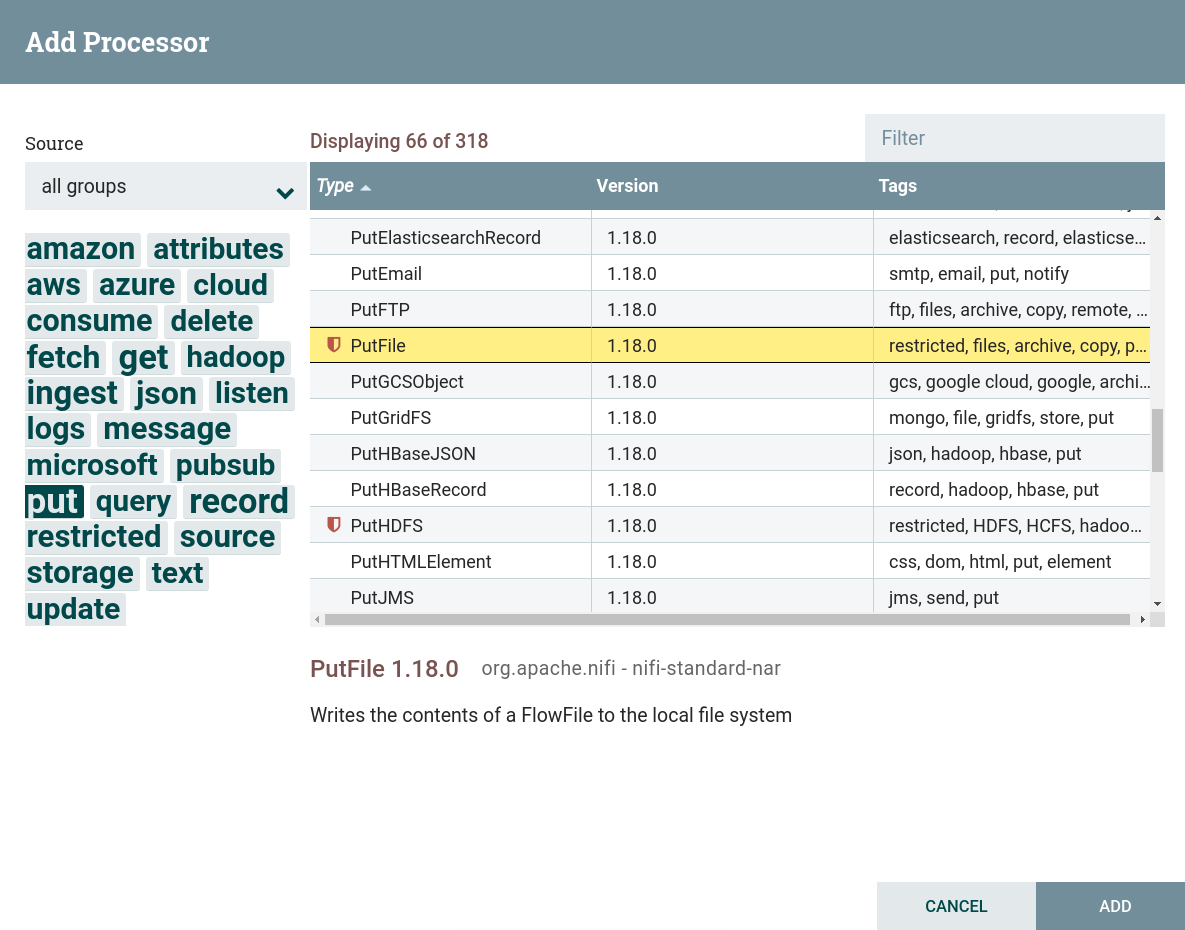 Creating a PutFile processor
Creating a PutFile processor -
Configure required processor options:
-
On the PROPERTIES tab options:
-
Directory — directory where the file should be written. To simplify, for three different PutFile processors, it is better to specify different folders, since the file will be written with the name of the dataflow.
For this dataflow, the per-processor values are populated from the preconfigured parameter context.
-
Conflict Resolution Strategy — specifies what should happen if a file with the same name already exists in the output directory. In this case,
replaceis chosen. -
Create Missing Directories — if set to
true, missing destination directories will be created. Iffalse, dataflow files are penalized and sent to failure.trueis selected in this dataflow.
-
-
On the RELATIONSHIPS tab parameter Relationships success — the relationship determined by the processor relative to the thread connected to it.
As a result of setting the necessary parameters, the processor state is displayed as an indicator
.
-
-
Create and configure a processor connection with the RouteText processor. For this dataflow on the Create connection page, the flag is set to
matchedonly. As a result of processing the RouteText processor, only one dataflow gets into the GetFile processor — with lines matching the condition specified in the RouteText configuration.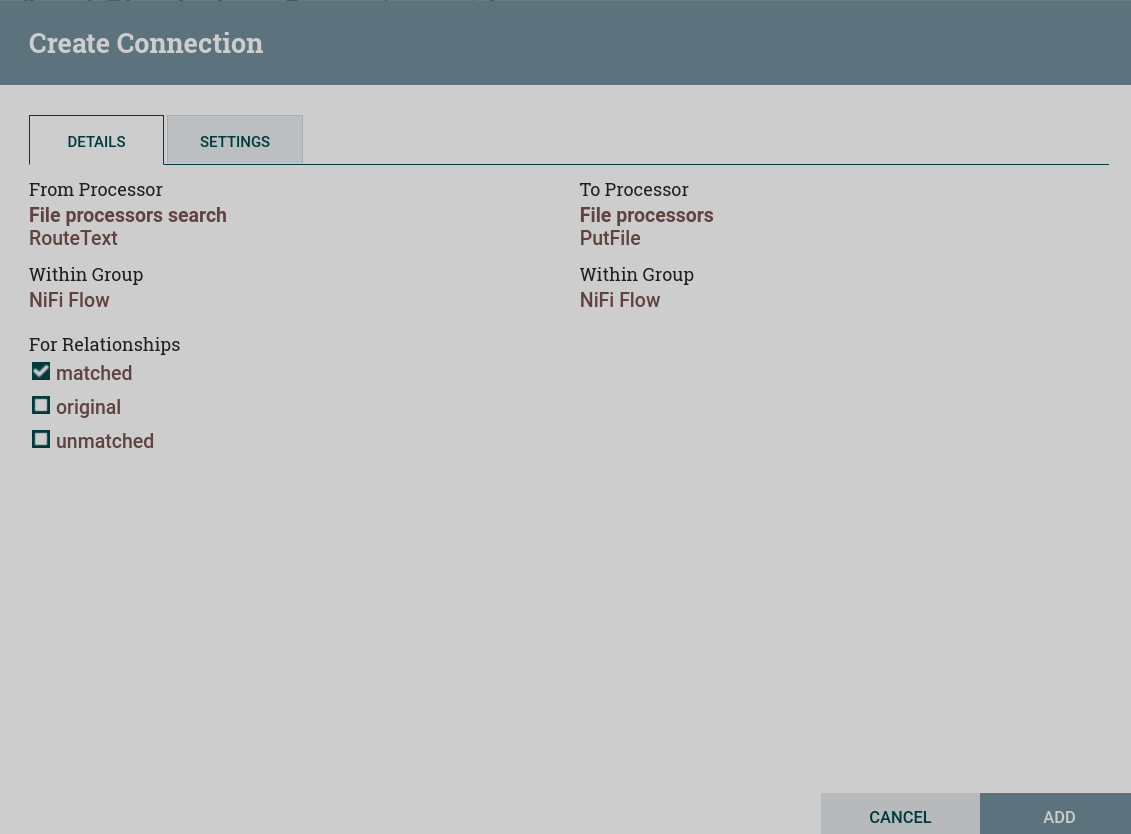 Configuring a connection to the RouteText processor
Configuring a connection to the RouteText processor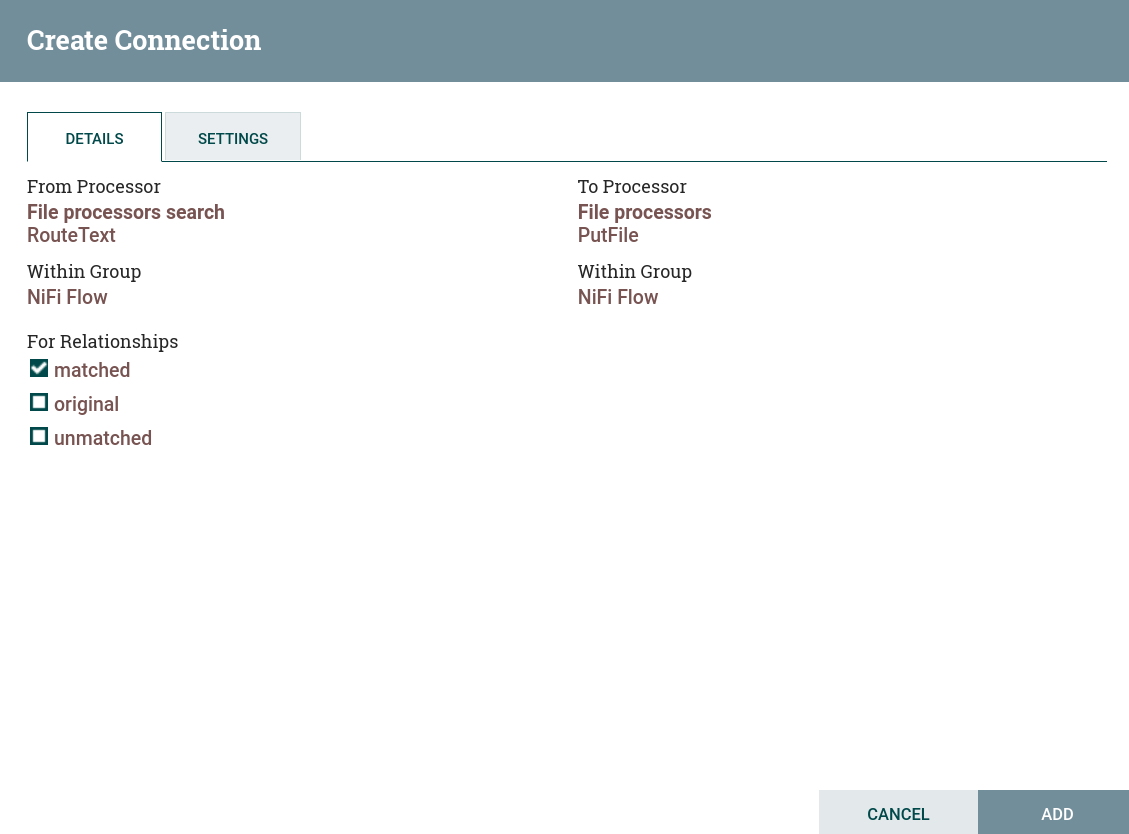 Configuring a connection to the RouteText processor
Configuring a connection to the RouteText processor -
Start created processors. After the process group starts, the contents of the file from the RouteText processor are queued to the PutFile processors. When working correctly, the processor image in the corresponding line of 5-minute statistics displays the amount of data read by the processor. The amount of data received by the PutFile processors differs from those read by the RouteText processors — lines were filtered according to the specified condition.
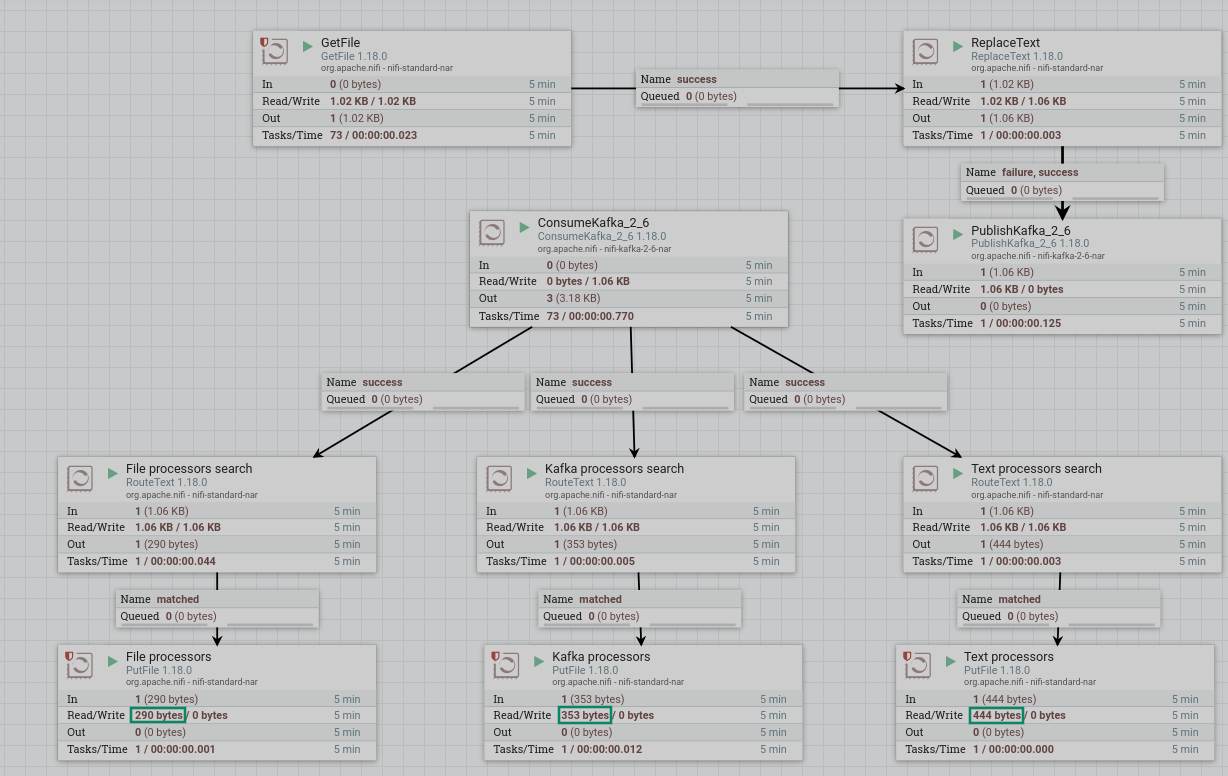
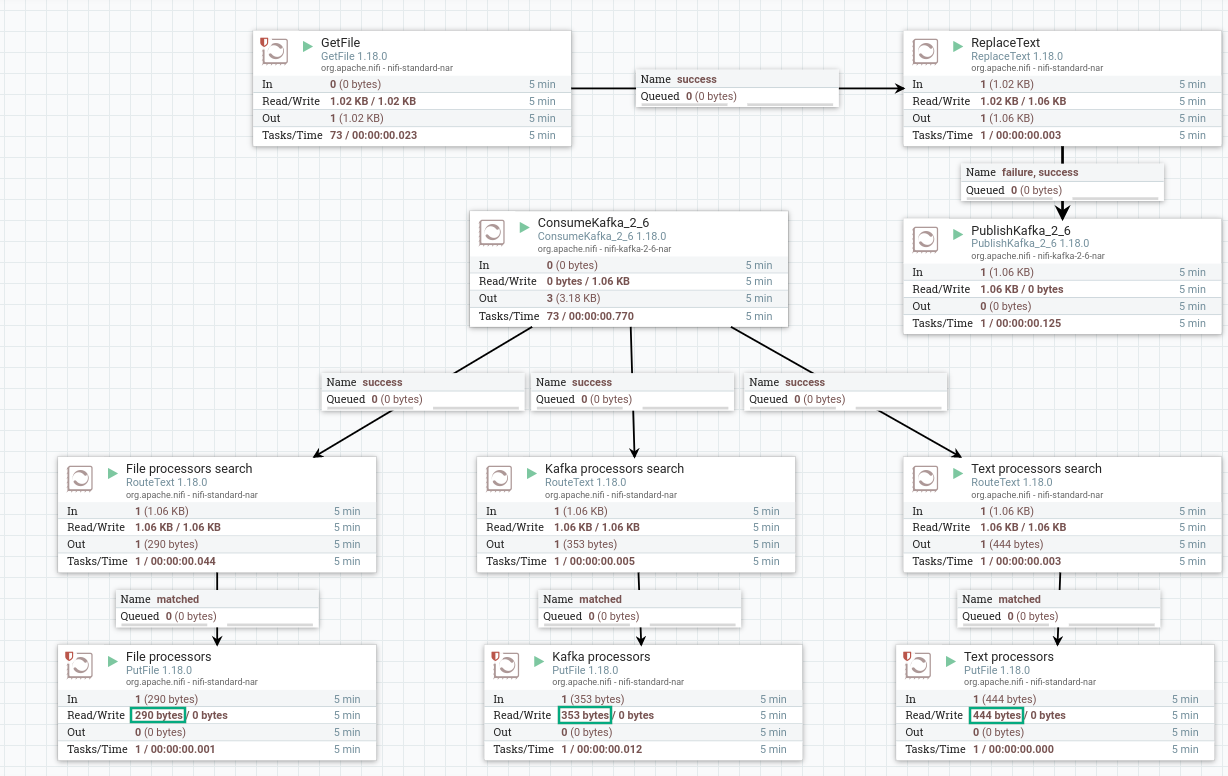
As a result, lines are written to the file in the specified directory for each GetFile processor in accordance with the condition specified for the RouteFile processor:
PutFile (put, local, copy, archive, files, filesystem) - Apache NiFi processor that writes the contents of a FlowFile to the local file system. GetFile (local, files, filesystem, ingest, ingress, get, source, input) - Apache NiFi processor that creates FlowFiles from files in a directory.
ConsumeKafka (kafka, get, ingest, ingress, topic, pubsub, consume) - Apache NiFi processor that consumes messages from Apache Kafka specifically built against the Kafka Consumer API. PublishKafka (kafka, put, send, message, pubsub) - Apache NiFi processor that sends the contents of a FlowFile as a message to Apache Kafka using the Kafka Producer API.
RouteText (attributes, routing, text, regexp, regex, filter, search, detect) - Apache NiFi processor that routes textual data based on a set of user-defined rules. ReplaceText (text, update, change, replace, modify, regex) - Apache NiFi processor that updates the content of a FlowFile by evaluating a Regular Expression (regex) against it and replacing the section of the content that matches the Regular Expression with some alternate value.