

Построение потока данных
В данной статье описан пример построения в интерфейсе NiFi Server потока данных, реализующего следующие задачи:
-
Запись в поток данных из файла, расположенного в локальной директории.
Для примера взят текстовый файл, приведенный ниже. Он содержит описания процессоров, которые будут использованы для построения потока данных в рамках статьи.
Тестовый файлPutFile (put, local, copy, archive, files, filesystem) - NiFi processor that writes the contents of a FlowFile to the local file system. ConsumeKafka (kafka, get, ingest, ingress, topic, pubsub, consume) - NiFi processor that consumes messages from Apache Kafka specifically built against the Kafka Consumer API. GetFile (local, files, filesystem, ingest, ingress, get, source, input) - NiFi processor that creates FlowFiles from files in a directory. RouteText (attributes, routing, text, regexp, regex, filter, search, detect) - NiFi processor that routes textual data based on a set of user-defined rules. PublishKafka (kafka, put, send, message, pubsub) - NiFi processor that sends the contents of a FlowFile as a message to Apache Kafka using the Kafka Producer API. ReplaceText (text, update, change, replace, modify, regex) - NiFi processor that updates the content of a FlowFile by evaluating a Regular Expression (regex) against it and replacing the section of the content that matches the Regular Expression with some alternate value.
-
Замена в файле текста
NiFiнаApache NiFi. -
Публикация содержимого файла в топик Kafka и просмотр топика.
-
Запись в поток данных из этого же топика.
-
Разделение записей на три потока, исходя из тега:
-
files; -
kafka; -
text.
-
-
Запись каждого потока в локальный файл.
|
ПРИМЕЧАНИЕ
|
Подготовка к созданию потока
Перед созданием потока должны быть осуществлены следующие действия:
-
При необходимости ограничения доступа в кластере настроить аутентификацию в сервисах Kafka и NiFi в соответствии со статьями:
-
Обеспечить запись файла в локальную папку. Для каждой папки должно быть настроено разрешение для чтения и записи — для того, чтобы у процессора, имеющего ограничения, был доступ к файлу.
Разрешение можно дать при помощи команды
chmod.Пример команды, назначающей всем все права на папку /tmp/new:
$ sudo chmod -R 777 /tmp/new -
Обеспечить возможность чтения топика Kafka, участвующего в потоке. Для получения информации о работе в Kafka можно обратиться к статье Начало работы c Kafka.
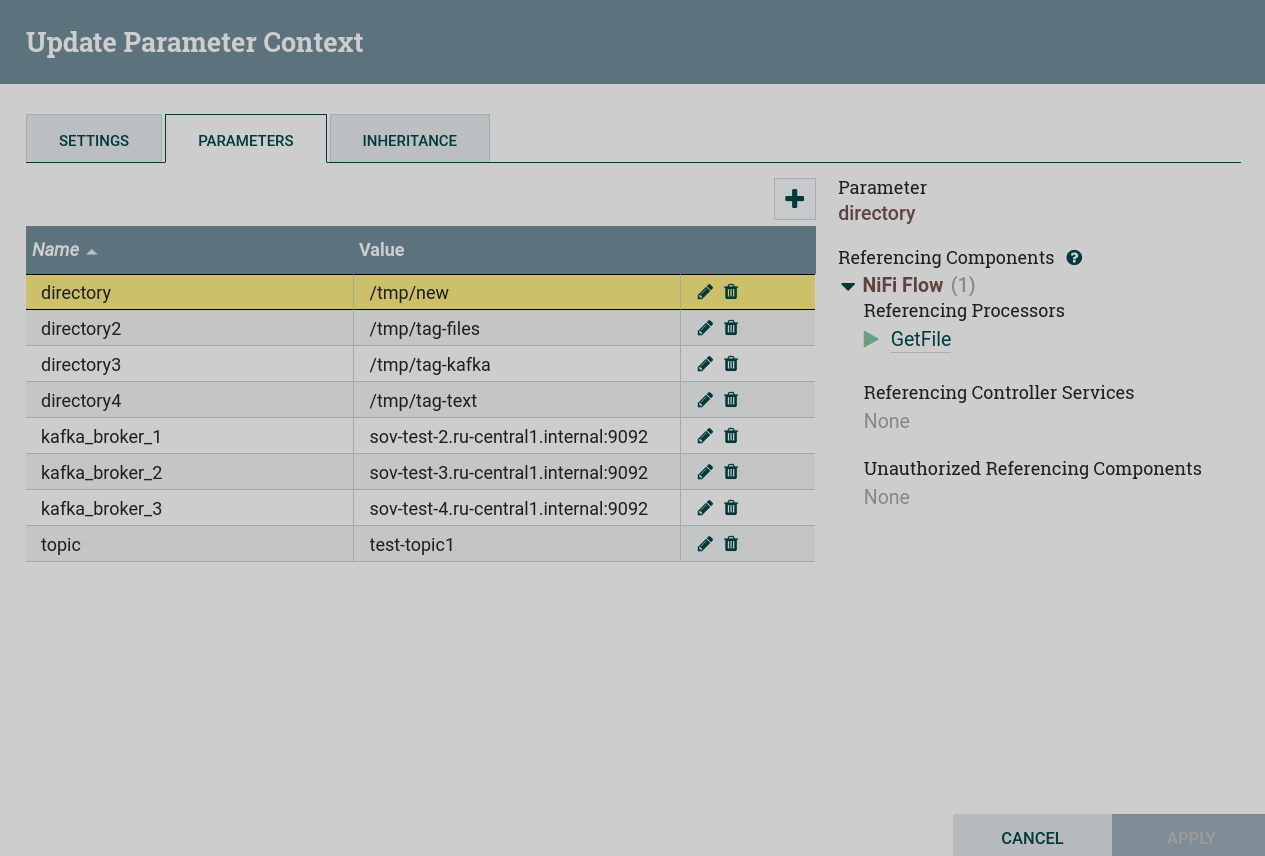
Настройка постоянных параметров
Параметры, которые необходимо настроить перед созданием данного потока:
-
Kafka Brokers— разделенный запятыми список брокеров Kafka в форматеhost:port, необходим для всех подключений к брокеру Kafka. -
Topic Name— название топиков Kafka, из которых извлекаются или в которые записываются данные. -
Directory— каталог, в который файлы должны быть записаны или из которого они должны быть извлечены.
Для данной задачи параметры настроены при помощи контекста параметров.
|
ПРИМЕЧАНИЕ
Способы создания и управления параметрами и атрибутами описаны в статье Работа с атрибутами. |
Запись в поток данных из файла
Запись в поток данных из локального файла производится в следующей последовательности:
-
Создать процессор. Для получения данных из внешних источников используются процессоры, которые можно найти по тегу
get. В данной задаче используется процессор GetFile. Для данного процессора установлены ограничения. Для использования данного процессора необходимо дать разрешение для чтения и записи в соответствующей папке при подготовке к созданию потока.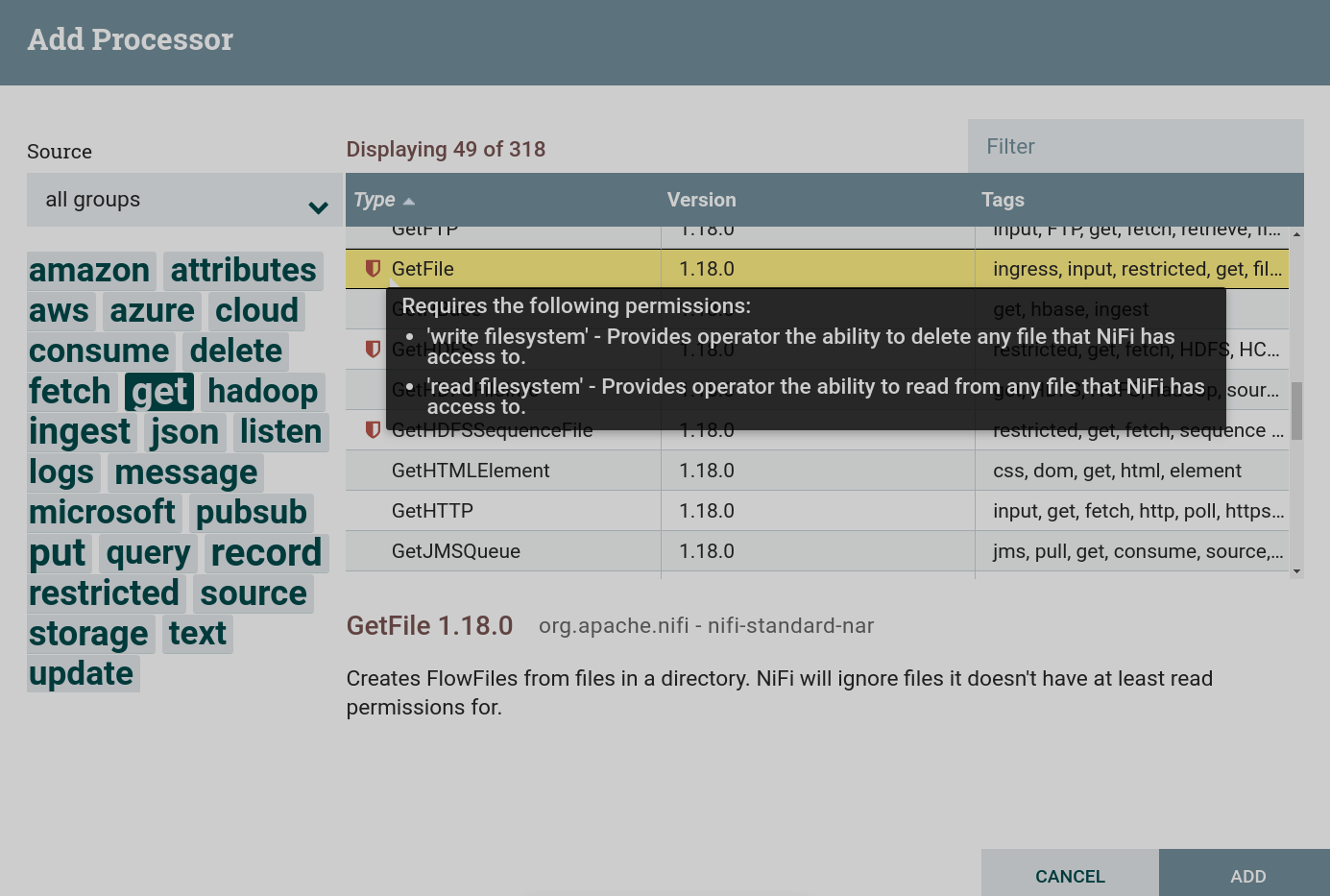 Создание процессора GetFile
Создание процессора GetFile Создание процессора GetFile
Создание процессора GetFile -
Настроить обязательные параметры процессора:
-
На вкладке PROPERTIES параметр Input Directory — папка, из которой должен быть считан файл (для данного потока значение внесено из контекста параметров).
-
На вкладке RELATIONSHIPS параметр Relationships success — отношения, определяемые процессором относительно подключенного к нему потока.
В результате настройки необходимых параметров состояние процессора отображается в виде индикатора
 .
.
-
-
Запустить созданный процессор. Если в локальной папке находится файл, то после запуска процессора содержимое файла поступает в поток. При правильной работе на изображении процессора в соответствующей строке 5-минутной статистики отображается обьем данных, прочитанных процессором.
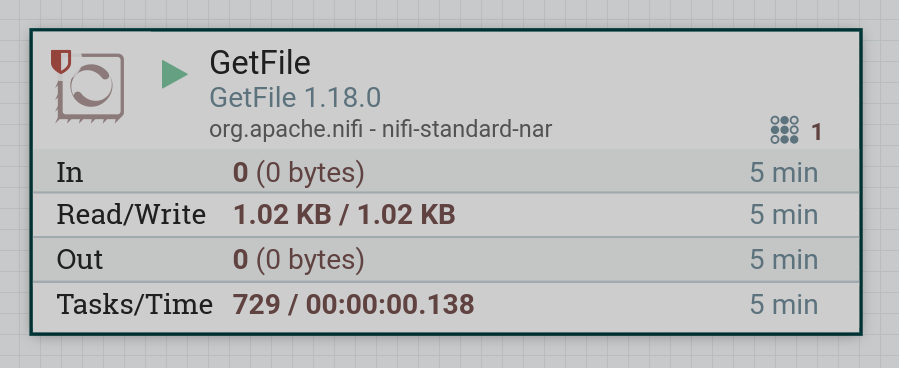
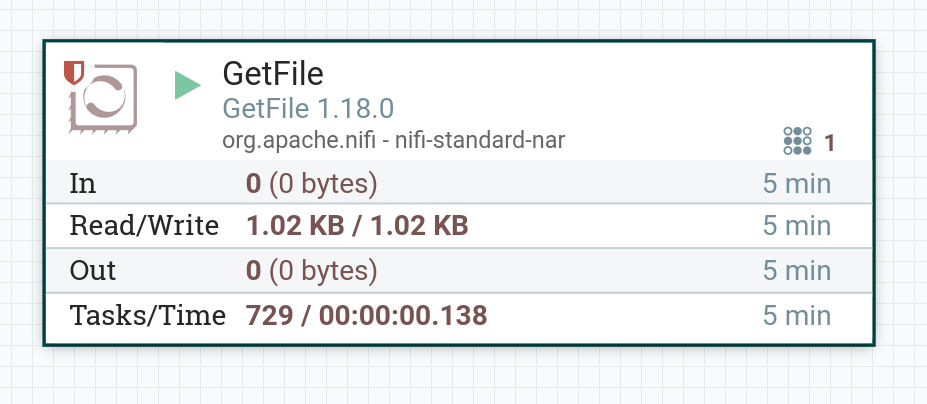
|
ВНИМАНИЕ
Процессор GetFile после считывания удаляет считанный файл из директории. Поэтому каждый раз перед запуском потока необходимо записать нужный файл в указанную директорию. |
Замена текста в потоковом файле
Замена текста в потоковом файле производится в следующей последовательности:
-
Создать процессор. Для работы с текстом используются процессоры, которые можно найти по тегу
text. В данной задаче используется процессор ReplaceText.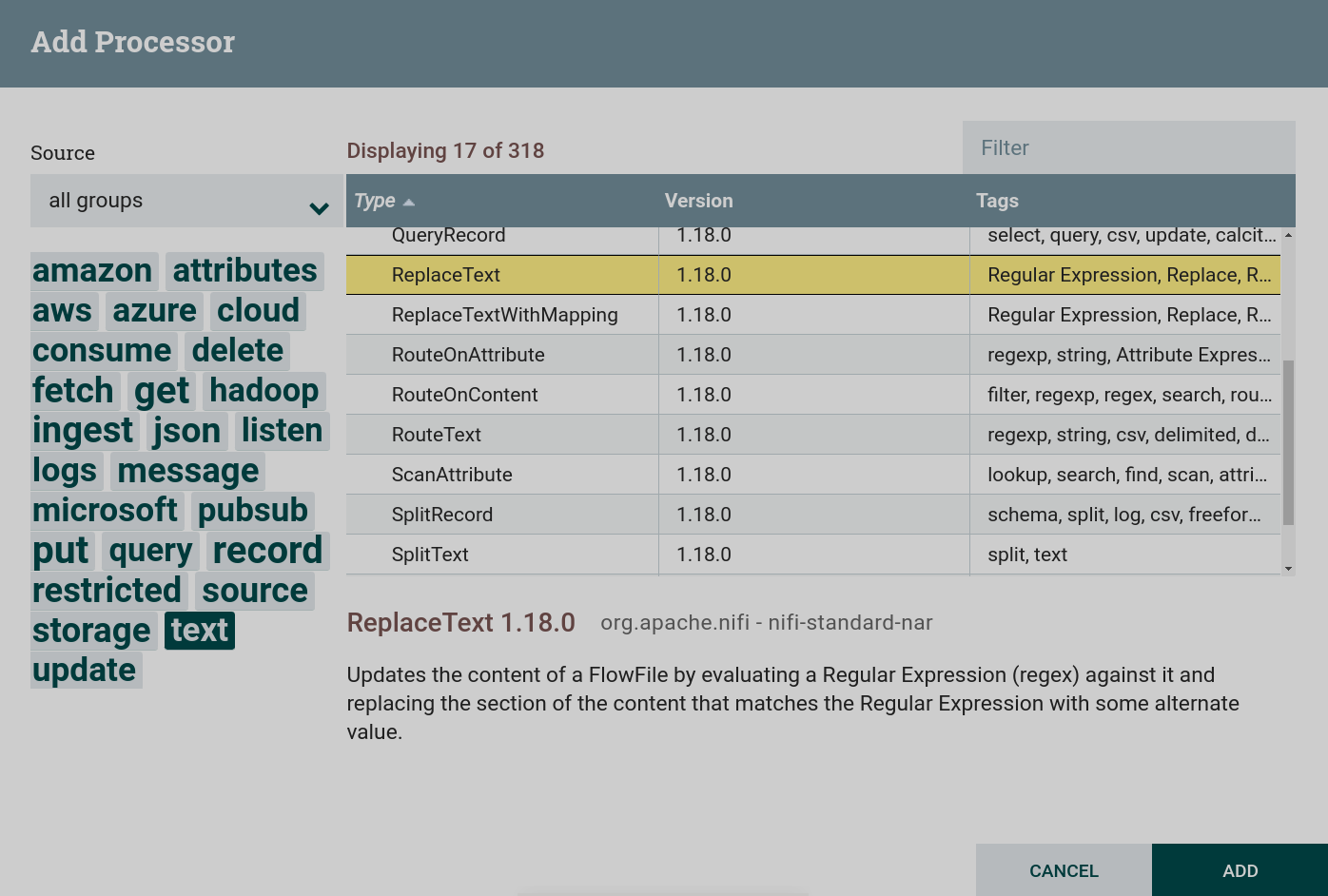 Создание процессора ReplaceText
Создание процессора ReplaceText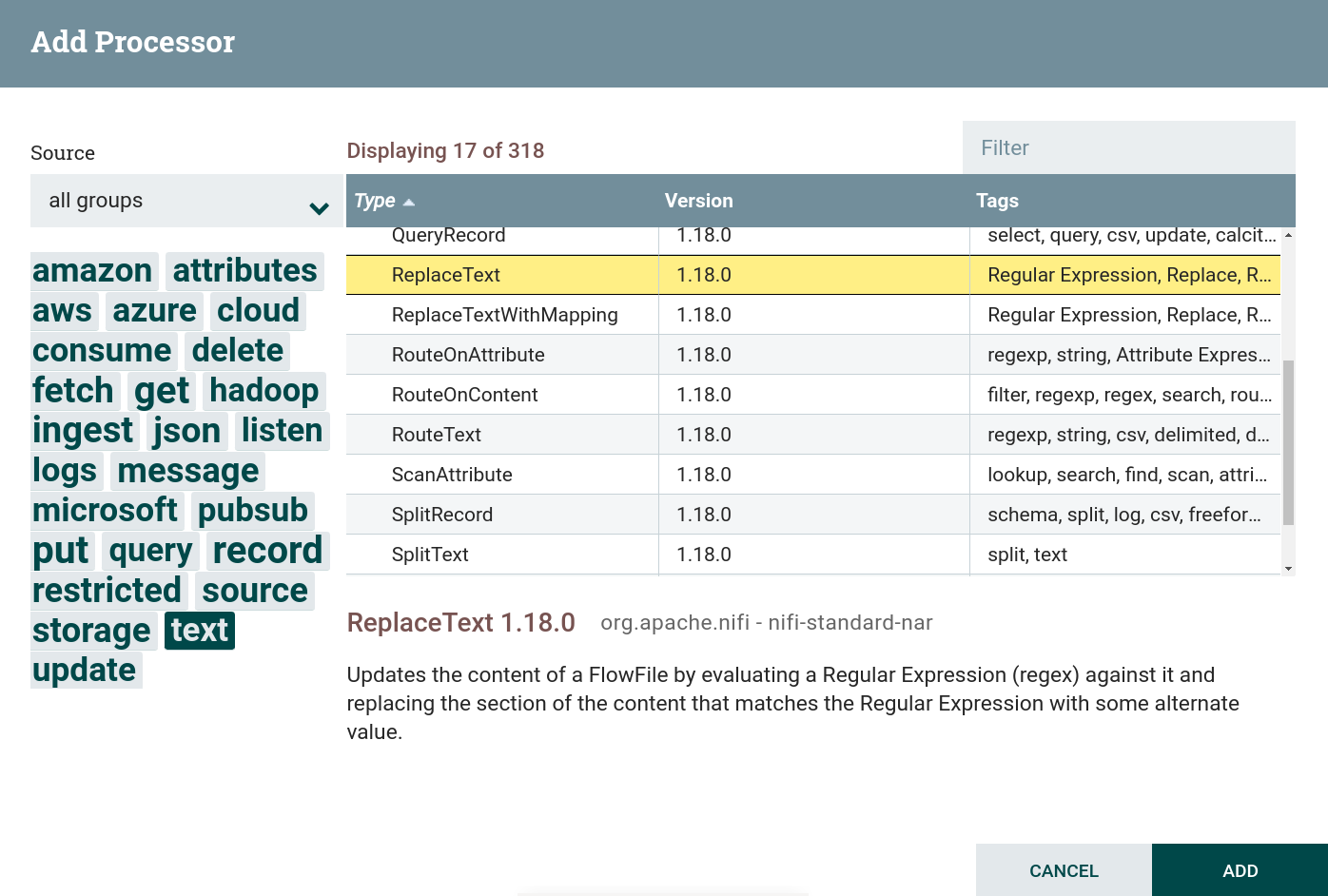 Создание процессора ReplaceText
Создание процессора ReplaceText -
Настроить обязательные параметры процессора:
-
На вкладке PROPERTIES параметры:
-
Search Value — часть текста, которая должна быть заменена. В данном потоке это значение
NiFi. -
Replacement Value — заменяющий текст. В данном потоке это значение
Apache NiFi.
-
-
На вкладке RELATIONSHIPS параметр Relationships success — отношения, определяемые процессором относительно подключенного к нему потока.
В результате настройки необходимых параметров состояние процессора отображается в виде индикатора
.
-
-
Запустить созданные процессоры. После запуска процессора содержимое файла из процессора GetFile поступает через очередь в процессор ReplaceText. При правильной работе на изображении процессора в соответствующей строке 5-минутной статистики отображается обьем данных, прочитанных процессором. Также приводится обьем записанных (измененных) данных. Обьем записанных данных отличается от прочитанных — часть текста заменена.


Публикация содержимого потока в топик Kafka
Публикация содержимого файла в топик Kafka производится в следующей последовательности:
-
Создать процессор. Для работы с записью данных во внешние файловые системы, в том числе в Kafka, используются процессоры, которые можно найти по тегу
pubsub.В данной задаче используется процессор PublishKafka.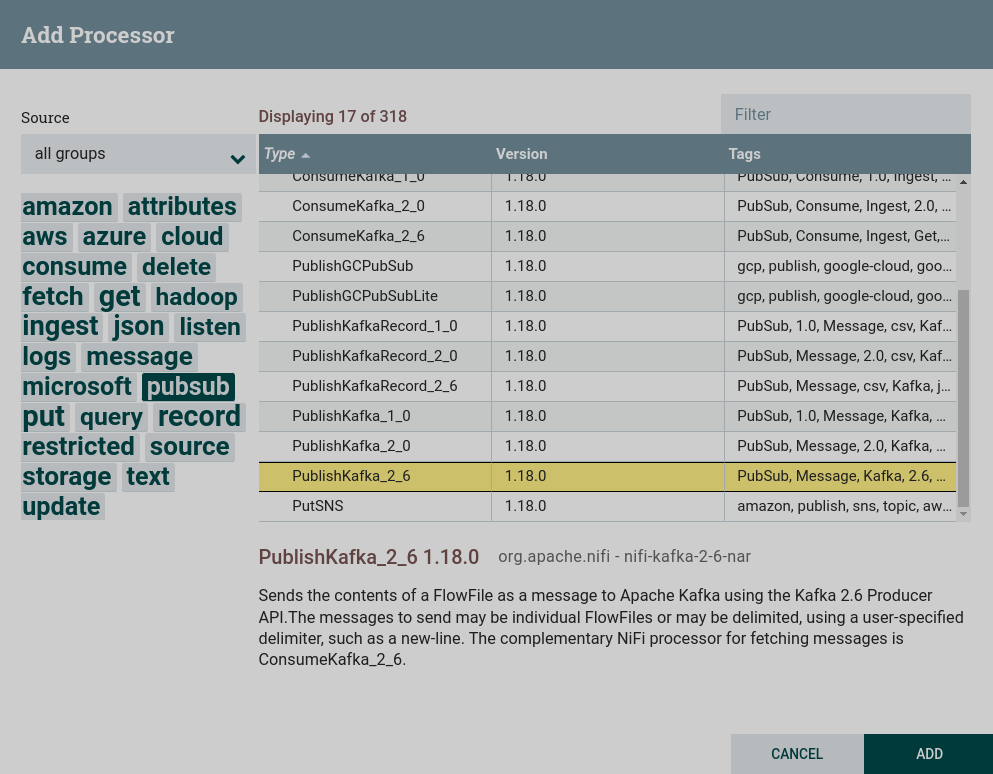 Создание процессора PublishKafka
Создание процессора PublishKafka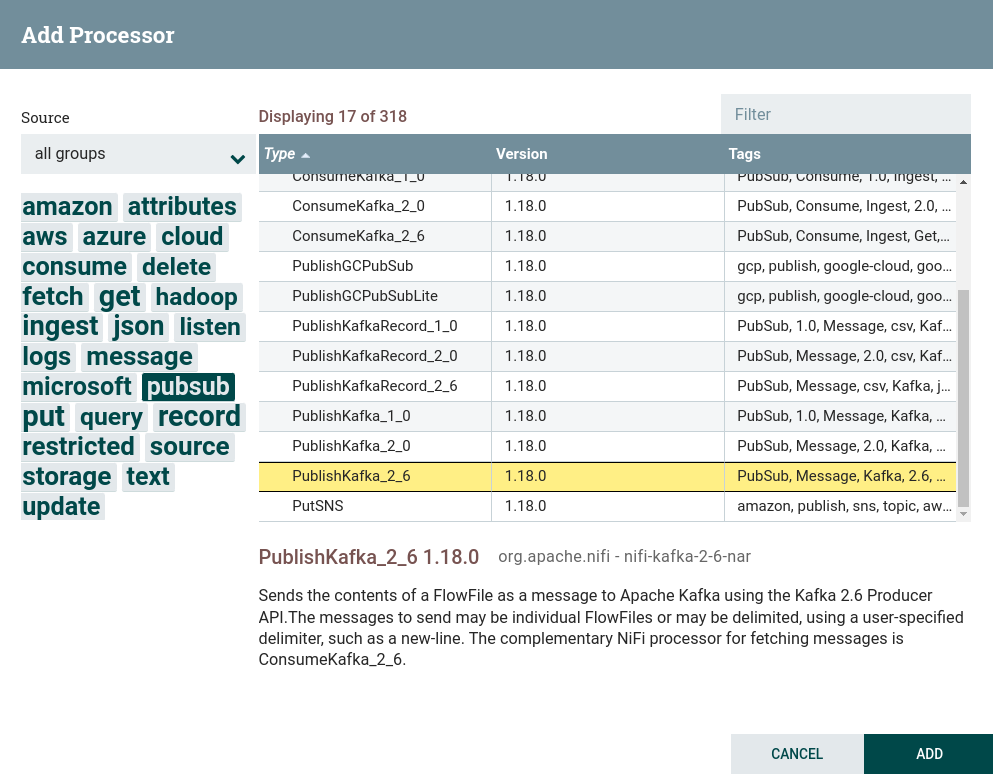 Создание процессора PublishKafka
Создание процессора PublishKafka -
Настроить обязательные параметры процессора:
-
На вкладке PROPERTIES параметры:
-
Kafka Brokers — брокеры для подключения к Kafka.
-
Topic Name — топик, в который публикуются данные.
Для данного потока значения внесены из предварительно настроенного контекста параметров.
-
-
На вкладке RELATIONSHIPS параметр Relationships success — отношения, определяемые процессором относительно подключенного к нему потока.
В результате настройки необходимых параметров состояние процессора отображается в виде индикатора
.
-
-
Запустить созданные процессоры. После запуска процессора содержимое файла из процессора ReplaceText поступает через очередь в процессор PublishKafka и публикуется в указанный топик. При правильной работе на изображении процессора в соответствующей строке 5-минутной статистики отображается обьем данных, прочитанных процессором.
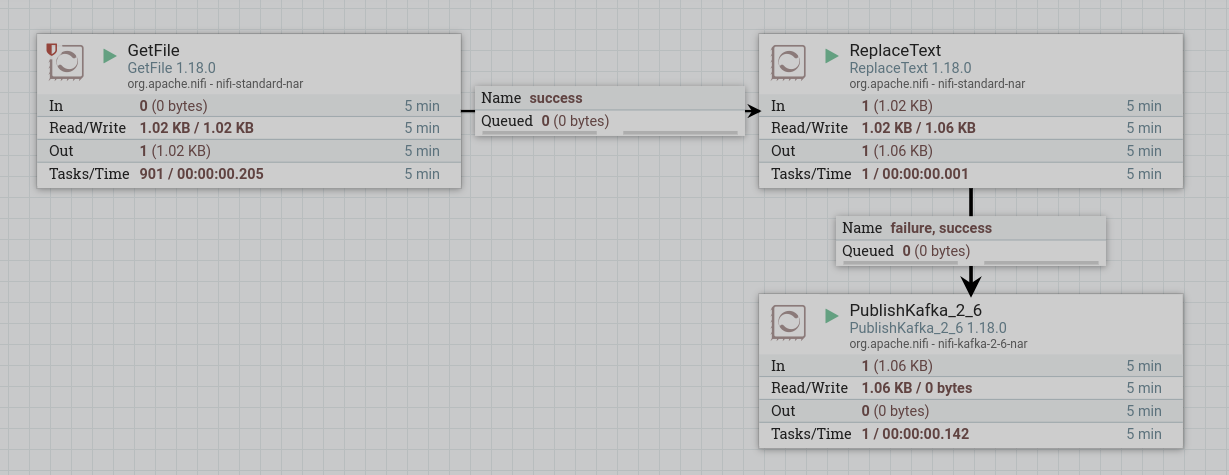
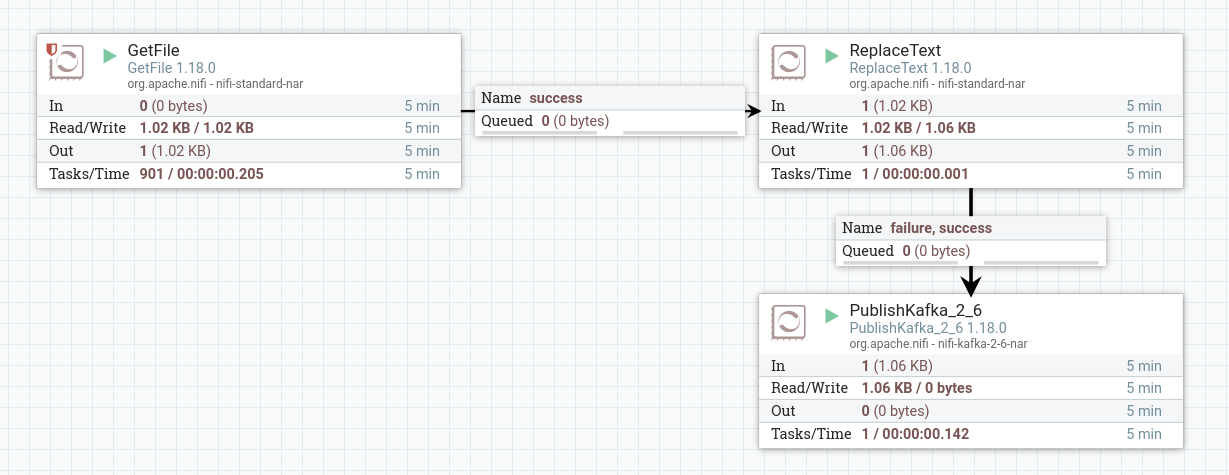
Для просмотра полученных данных необходимо прочитать данные из топика Kafka при помощи командной строки. Если работа процессоров настроена корректно, в результате выводятся строки с измененным текстом.
PutFile (put, local, copy, archive, files, filesystem) - Apache NiFi processor that writes the contents of a FlowFile to the local file system. ConsumeKafka (kafka, get, ingest, ingress, topic, pubsub, consume) - Apache NiFi processor that consumes messages from Apache Kafka specifically built against the Kafka Consumer API. GetFile (local, files, filesystem, ingest, ingress, get, source, input) - Apache NiFi processor that creates FlowFiles from files in a directory. RouteText (attributes, routing, text, regexp, regex, filter, search, detect) - Apache NiFi processor that routes textual data based on a set of user-defined rules. PublishKafka (kafka, put, send, message, pubsub) - Apache NiFi processor that sends the contents of a FlowFile as a message to Apache Kafka using the Kafka Producer API. ReplaceText (text, update, change, replace, modify, regex) - Apache NiFi processor that updates the content of a FlowFile by evaluating a Regular Expression (regex) against it and replacing the section of the content that matches the Regular Expression with some alternate value.
|
ПРИМЕЧАНИЕ
Данные, записаннные из потока NiFi в топик Kafka, могут быть использованы в дальнейшей передаче в файловые платформы или базы данных, например при помощи инструментов Kafka Connect. Также после обработки данных они могут быть записаны в Kafka, обработаны и переданы далее потоком NiFi. |
Получение данных из топика Kafka
Получение данных из топика Kafka производится в следующей последовательности:
-
Создать процессор. Для работы с получением данных из внешних файловых систем, в том числе в Kafka, используются процессоры, которые можно найти по тегу
consume. В данной задаче используется процессор ConsumeKafka.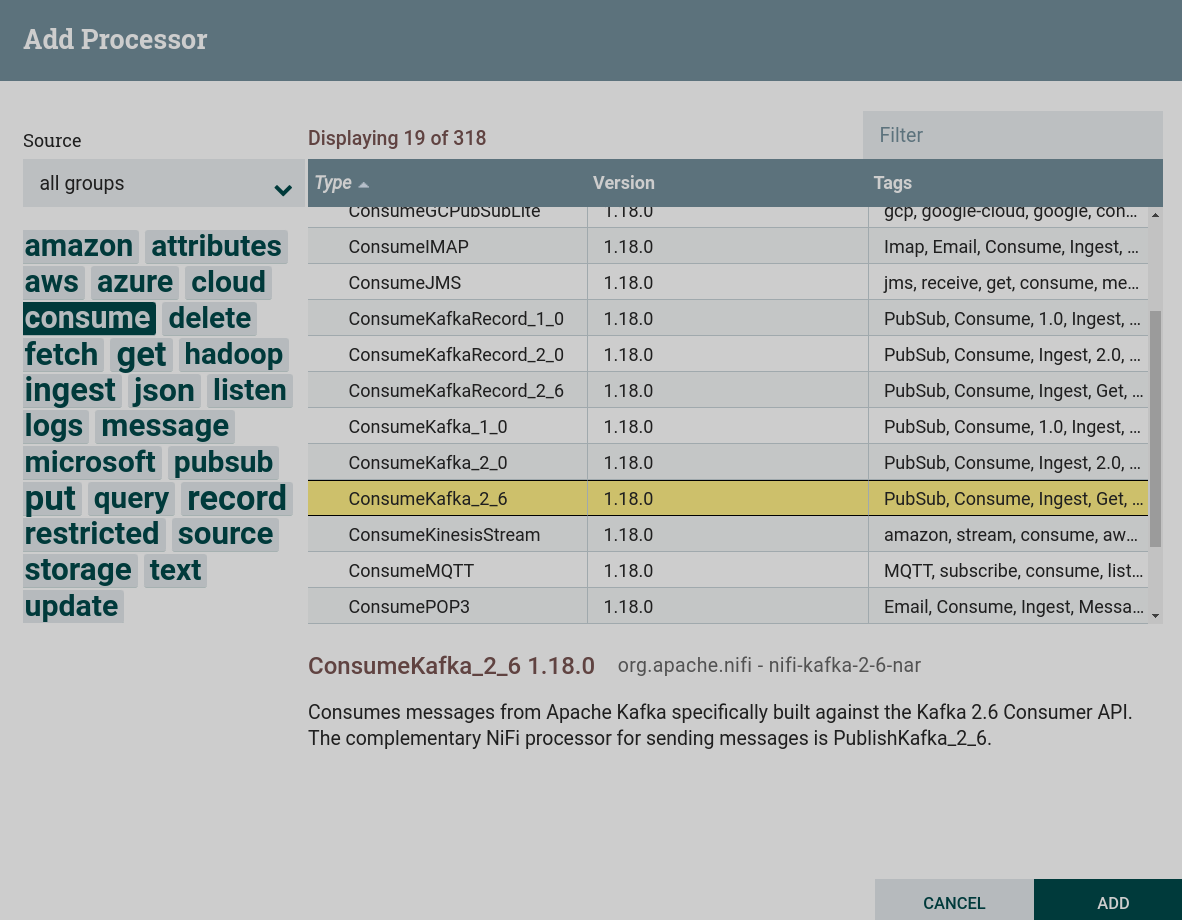 Создание процессора ConsumeKafka
Создание процессора ConsumeKafka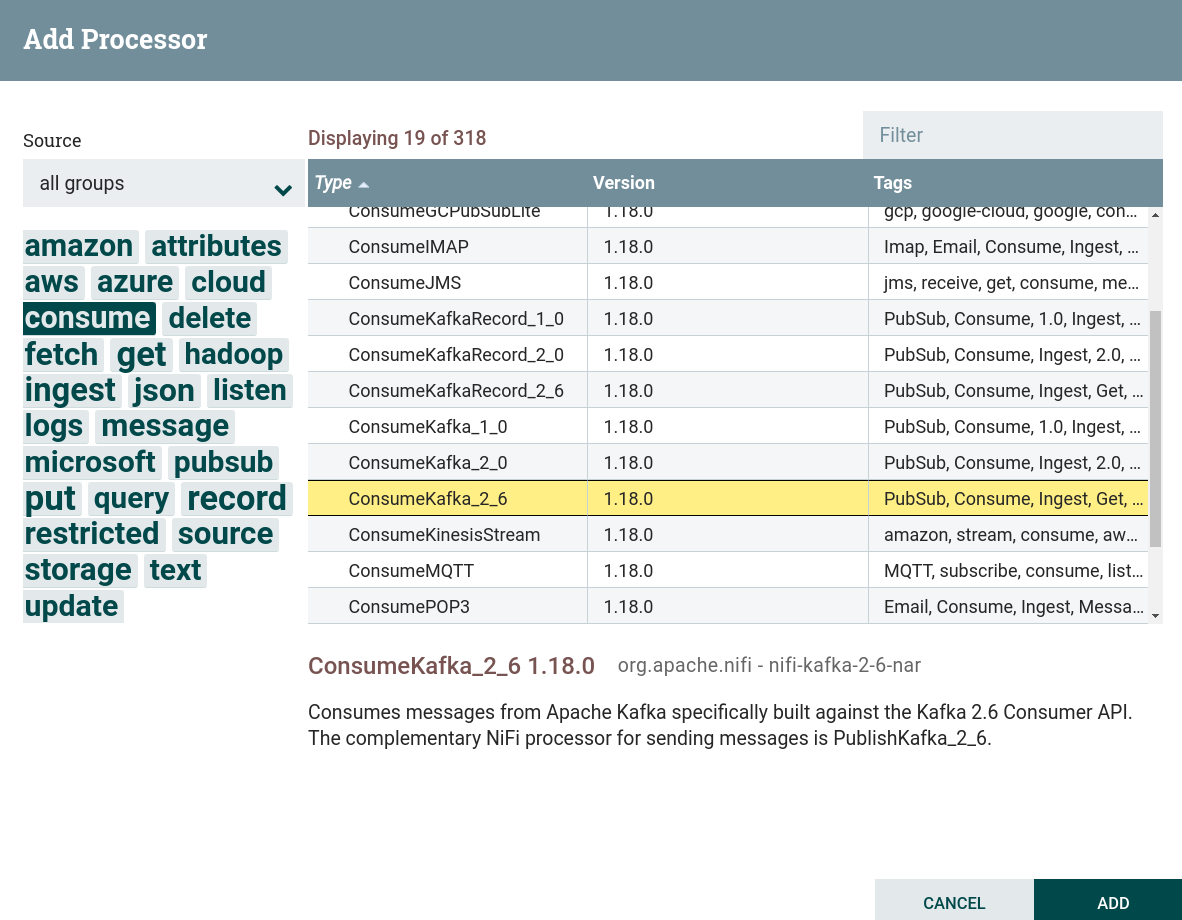 Создание процессора ConsumeKafka
Создание процессора ConsumeKafka -
Настроить обязательные параметры процессора:
-
На вкладке PROPERTIES параметры:
-
Kafka Brokers — брокеры для подключения к Kafka.
-
Topic Name — топик, в который публикуются данные.
-
Group ID — идентификатор группы для определения потребителей, входящих в одну и ту же группу. Соответствует параметру
group.idв Kafka.Для данного потока значения внесены из предварительно настроенного контекста параметров.
-
-
На вкладке RELATIONSHIPS параметр Relationships success — отношения, определяемые процессором относительно подключенного к нему потока.
В результате настройки необходимых параметров состояние процессора отображается в виде индикатора
.
-
-
Запустить созданные процессоры. После запуска процессора содержимое топика записывается в потоковый файл. При правильной работе на изображении процессора в соответствующей строке 5-минутной статистики отображается обьем данных, прочитанных процессором.
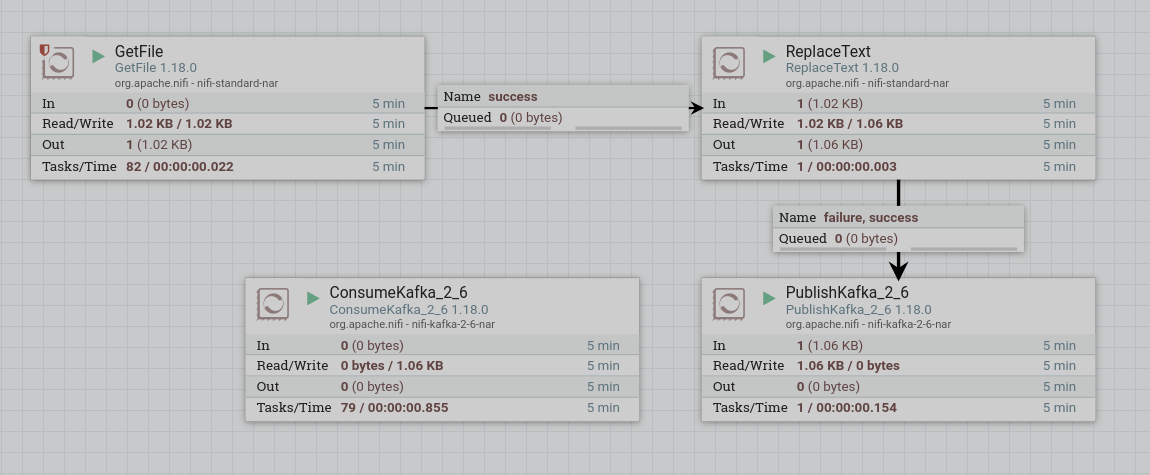
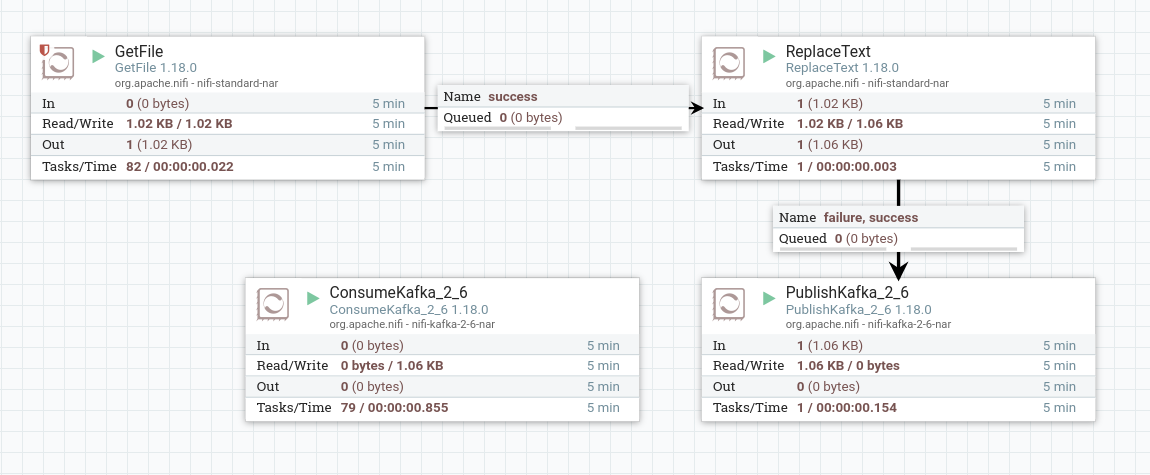
Разделение записей на несколько потоков
Разделение записей на несколько потоков производится в следующей последовательности:
-
Создать процессор. Для работы с фильтрацией данных и текстом используются процессоры, которые можно найти по тегам
textиfilter. В данной задаче используется процессор RouteText.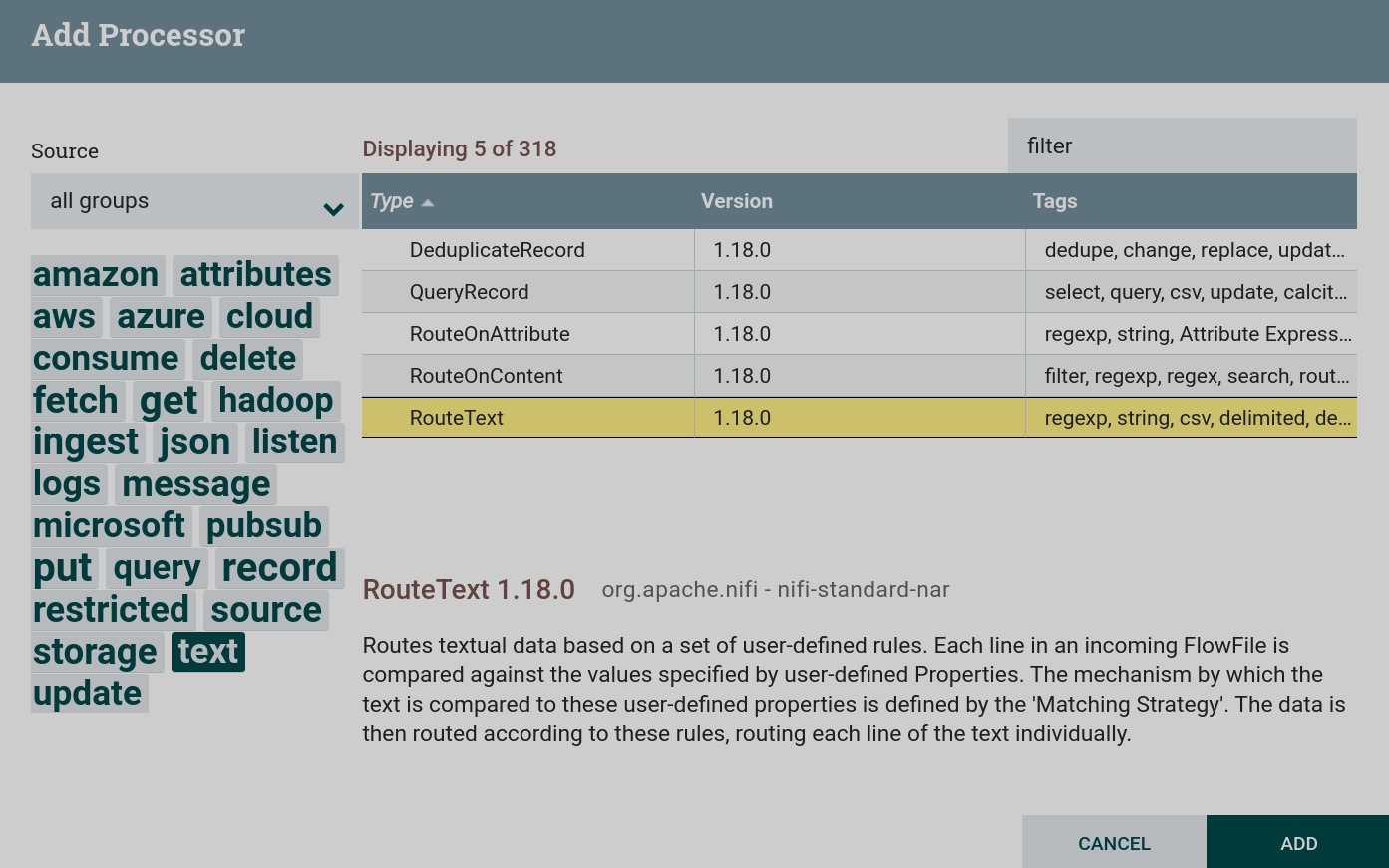 Создание процессора RouteText
Создание процессора RouteText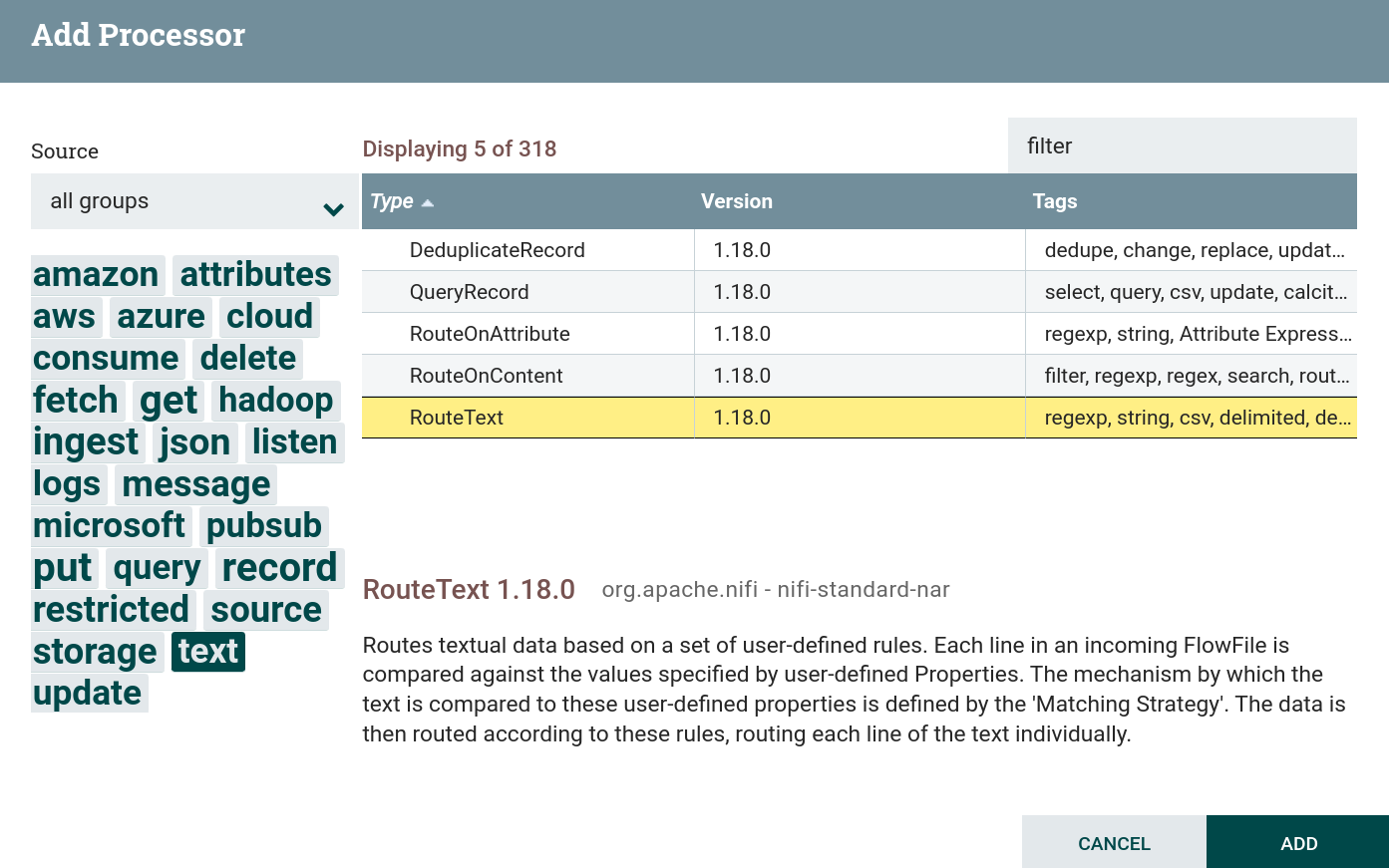 Создание процессора RouteText
Создание процессора RouteText -
Настроить обязательные параметры процессора:
-
На вкладке PROPERTIES параметры:
-
Routing Strategy установить в
Route to "matched" if lines matches any condition. Эта установка направляет в поток matched все строки, соответствующие заданному условию. -
Matching Strategy установить в
Contains Regular Expression. Эта установка проверяет строки на содержание текста в регулярном выражении, указанного в качестве пользовательского свойства. -
Пользовательское свойство, которое является условием выбора нужных строк. Для используемого в примере текста можно сделать фильтрацию строк по тегам, записанным в скобках. Например, если в пользовательском свойстве
tagsустановить значение при помощи регулярного выражения(.*files.*), то процессор выберет только строки с тегомfilesиз всех представленных строк.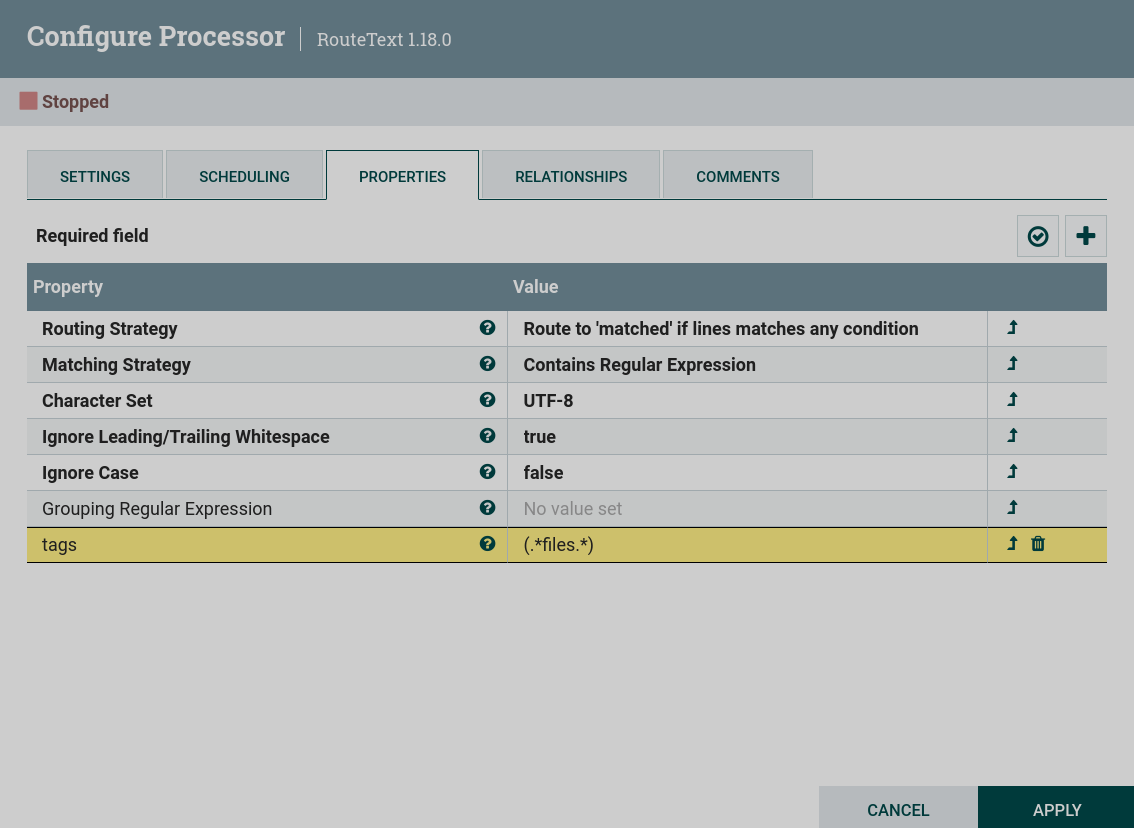 Настройка процессора RouteText
Настройка процессора RouteText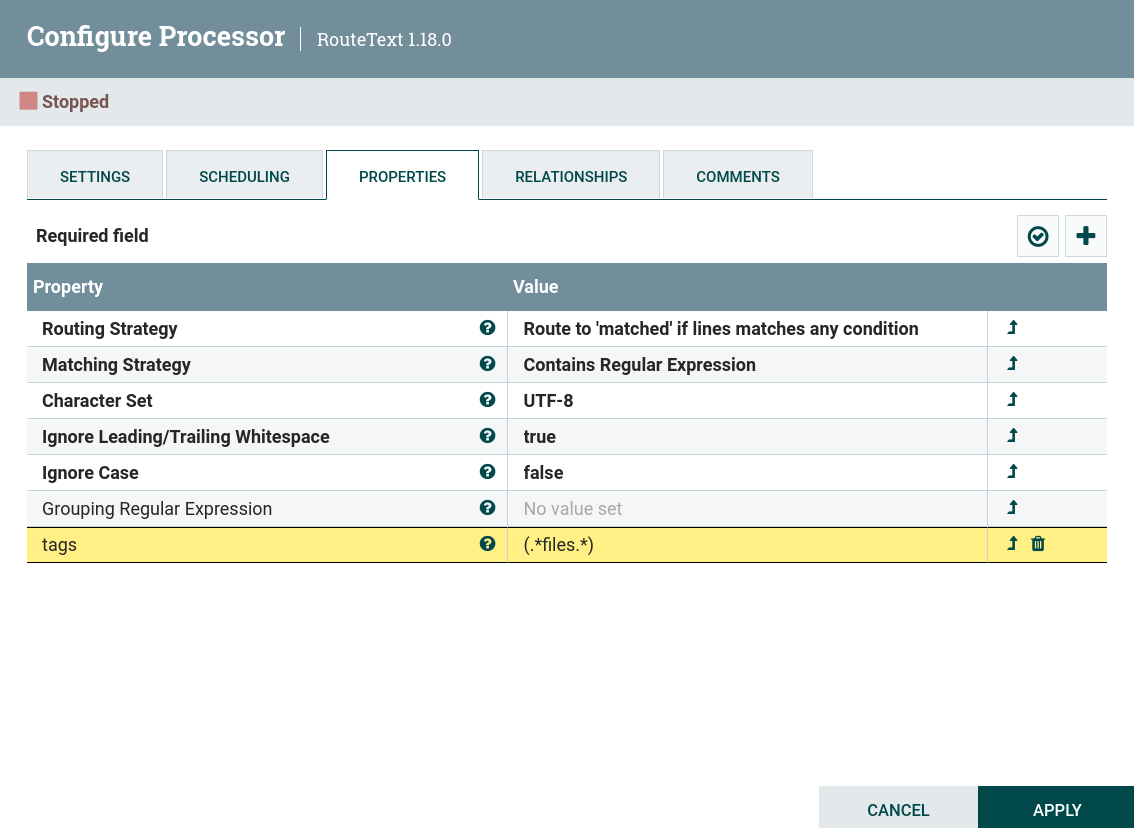 Настройка процессора RouteText
Настройка процессора RouteTextДля примера в потоке создано три процессора, разделяющие текст на три потока:
-
процессоры, содержащие тег
files; -
процессоры, содержащие тег
kafka; -
процессоры, содержащие тег
text.
-
-
-
На вкладке RELATIONSHIPS параметр Relationships success — отношения, определяемые процессором относительно подключенного к нему потока.
В результате настройки необходимых параметров состояние процессора отображается в виде индикатора
.
-
-
Запустить созданные процессоры. После запуска всей группы процессов процессоры считают содержимое потоков. При правильной работе на изображении процессора в соответствующей строке 5-минутной статистики отображается обьем данных, прочитанных процессором.
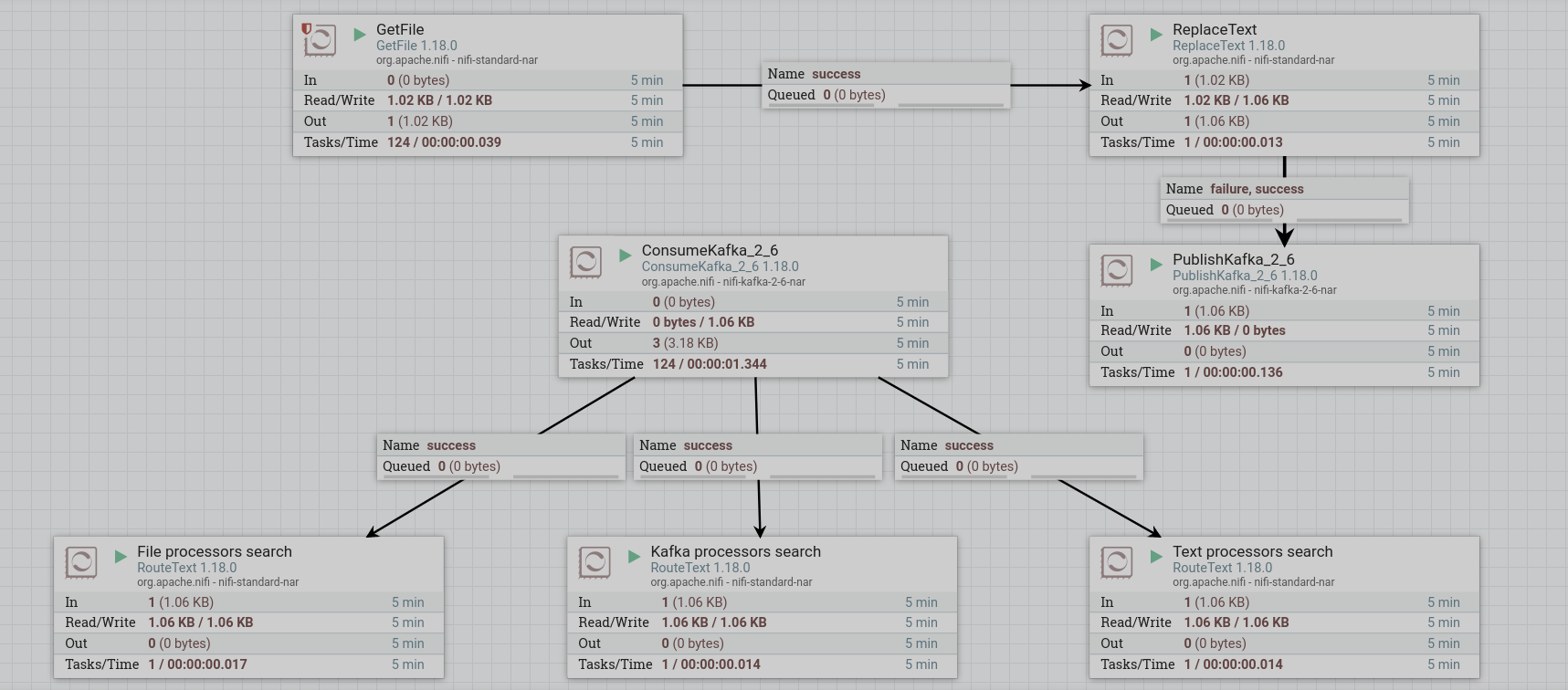
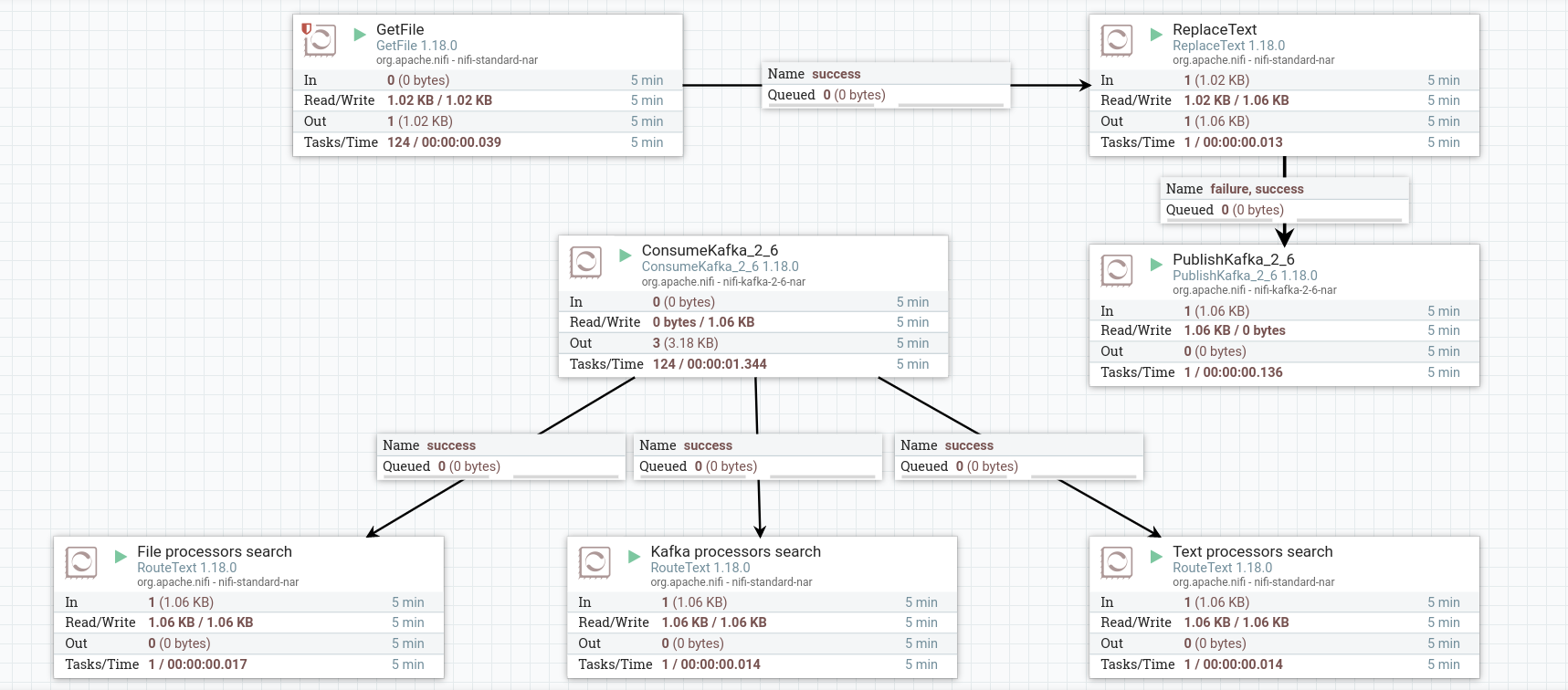
Запись содержимого потока в файл
Для того, чтобы увидеть, как процессоры RouteText отфильтовали исходные строки, можно записать содержимое каждого созданного потока в три разных файла.
Запись потока в локальный файл производится в следующей последовательности:
-
Создать процессор. Для записи данных из потока используются процессоры, которые можно найти по тегу
put. В данной задаче используется процессор PutFile. Для данного процессора установлены ограничения. Для использования данного процессора необходимо дать разрешение для чтения и записи в соответствующей папке, при подготовке к созданию потока.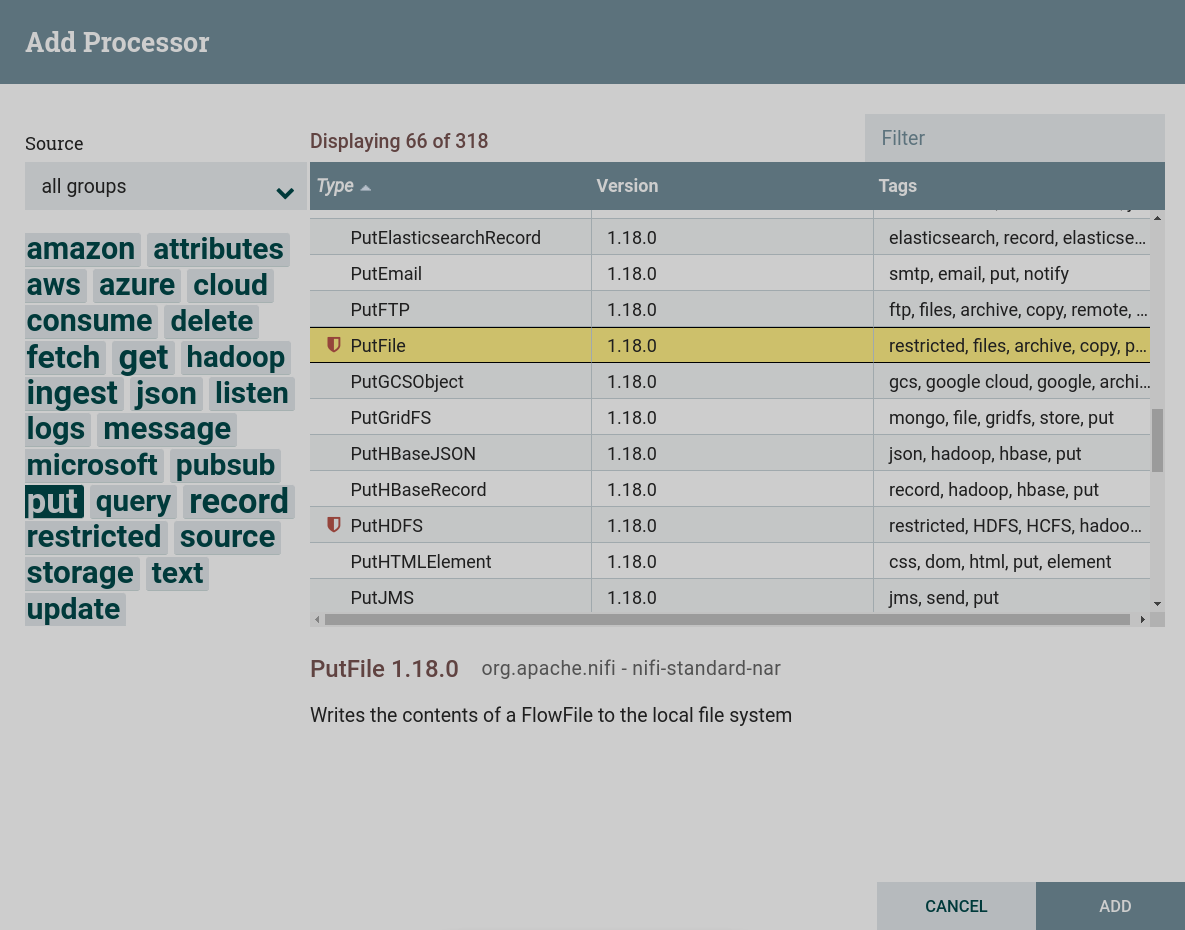 Создание процессора PutFile
Создание процессора PutFile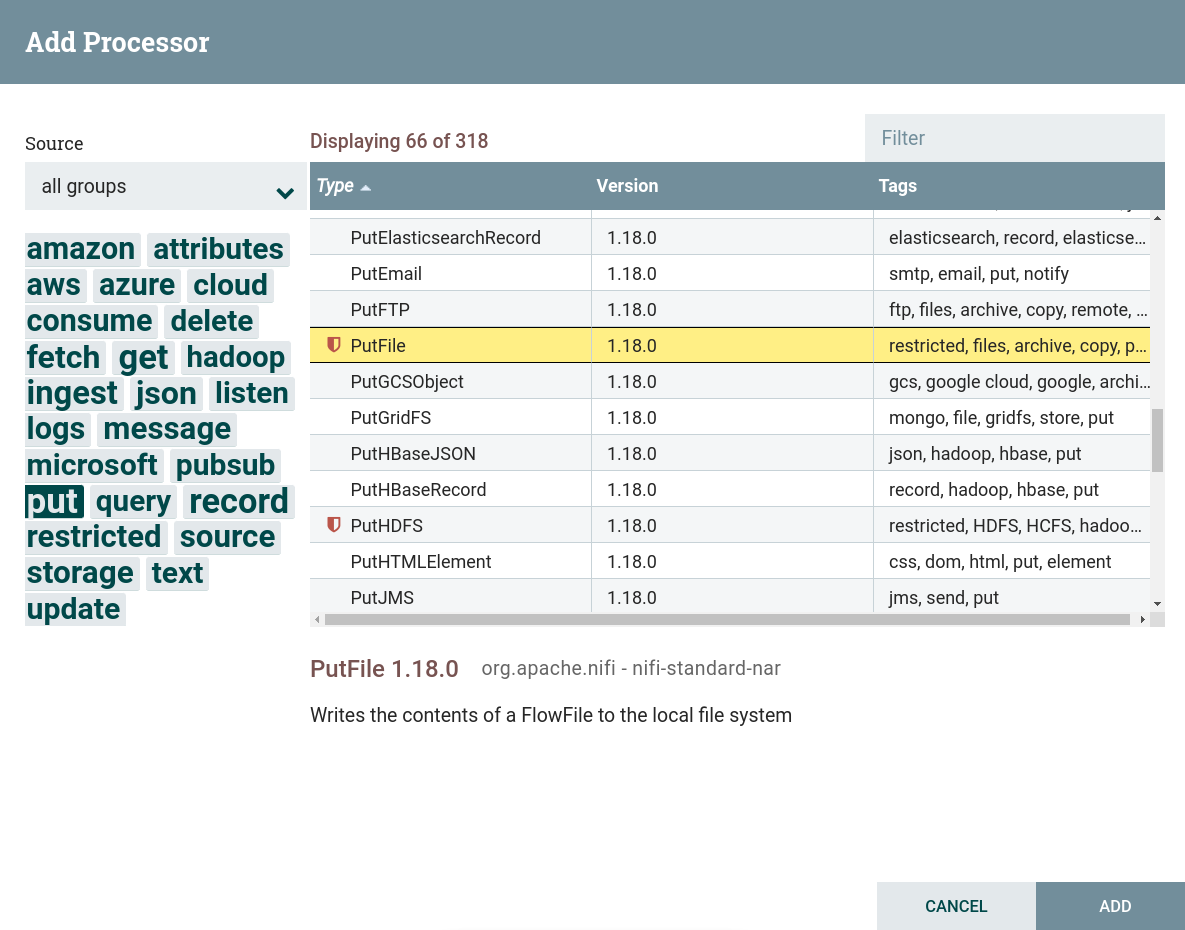 Создание процессора PutFile
Создание процессора PutFile -
Настроить обязательные параметры процессора:
-
На вкладке PROPERTIES параметры:
-
Directory — папка, куда должен быть записан файл. В целях упрощения для трех разных процессоров PutFile лучше указать разные папки, так как файл будет записан с названием потока.
Для данного потока значения для каждого процессора внесены из предварительно настроенного контекста параметров.
-
Conflict Resolution Strategy — указывает, что должно произойти, если файл с таким именем уже существует в выходном каталоге. В данном случае выбрано
replace. -
Create Missing Directories — если выбрать
true, то будут созданы отсутствующие каталоги назначения. Если выбратьfalse, при отсутствии каталогов назначения обработка потоковых файлов прекращается и файлы отправляются к ошибочным. В данном потоке выбраноtrue.
-
-
На вкладке RELATIONSHIPS параметр Relationships success — отношения, определяемые процессором относительно подключенного к нему потока.
В результате настройки необходимых параметров состояние процессора отображается в виде индикатора
.
-
-
Создать и настроить подключение к процессору RouteText. Для данного потока на странице Create connection флаг установлен только на
matched. В результате отработки процессора RouteText в процессор GetFile попадает только один поток — со строками, подходящими под условие, заданное при настройке RouteText.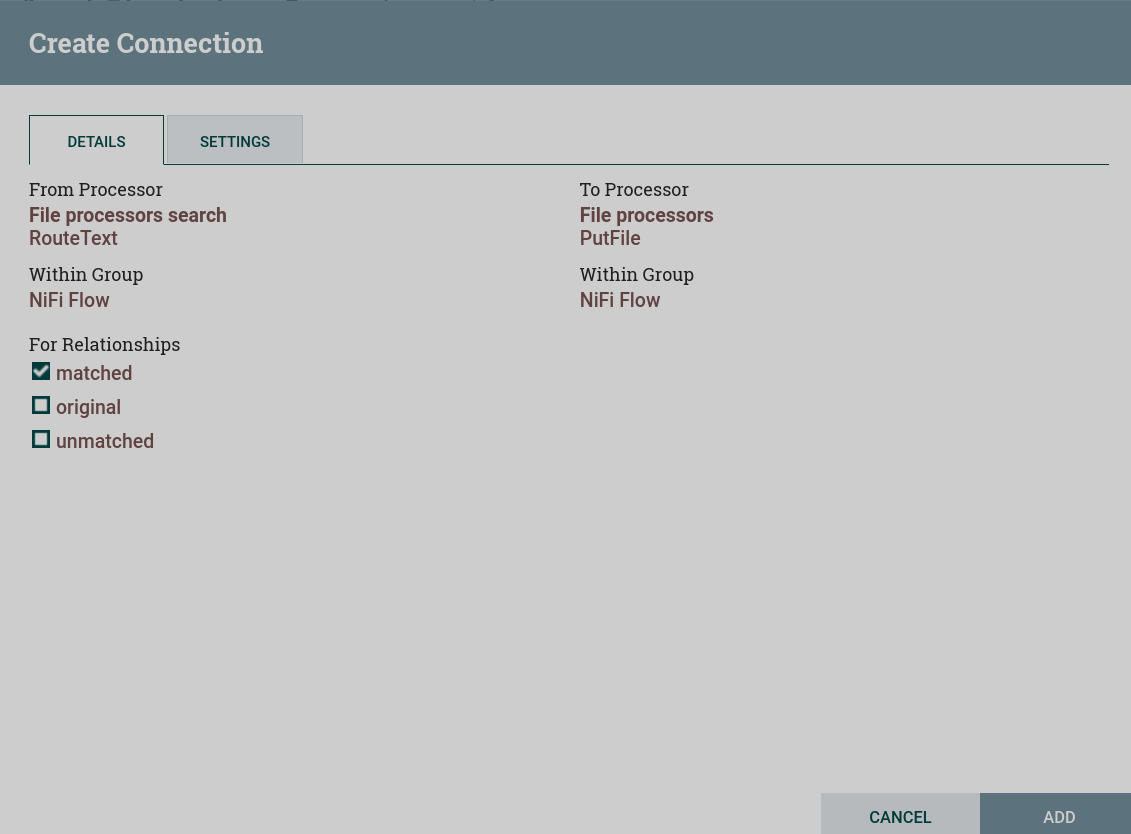 Настройка соединения с процессором RouteText
Настройка соединения с процессором RouteText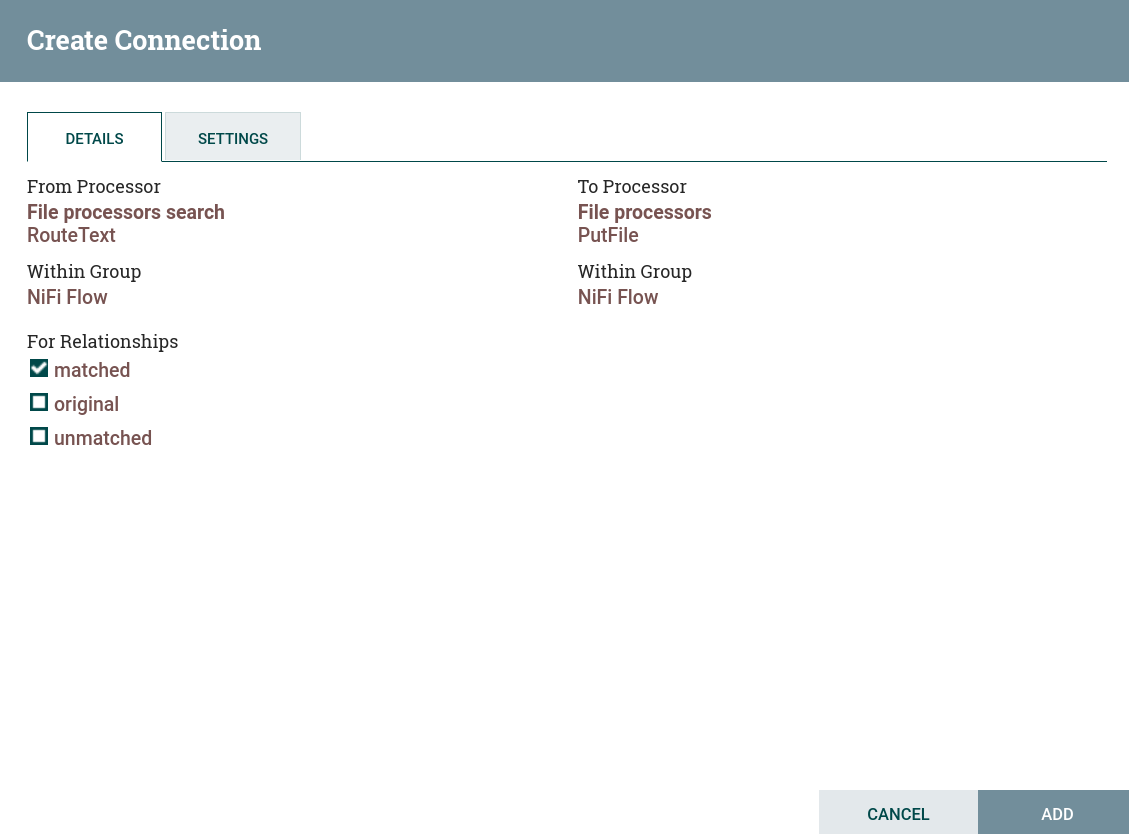 Настройка соединения с процессором RouteText
Настройка соединения с процессором RouteText -
Запустить созданные процессоры. После запуска группы процессов содержимое файла из процессоров RouteText поступает через очередь в процессоры PutFile. При правильной работе на изображении процессора в соответствующей строке 5-минутной статистики отображается обьем данных, прочитанных процессором. Обьем данных, поступивших в процессоры PutFile, отличается от прочитанных процессорами RouteText — произошла фильтрация строк в соответствии с указанным условием.
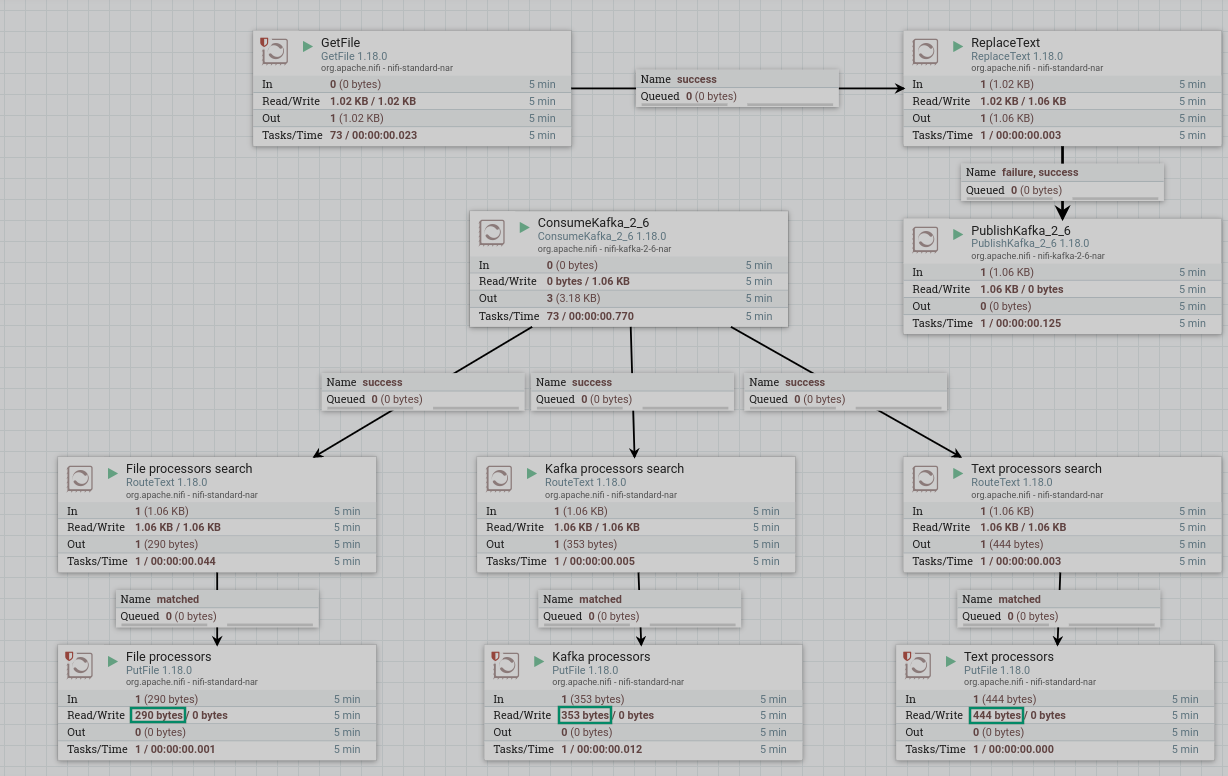
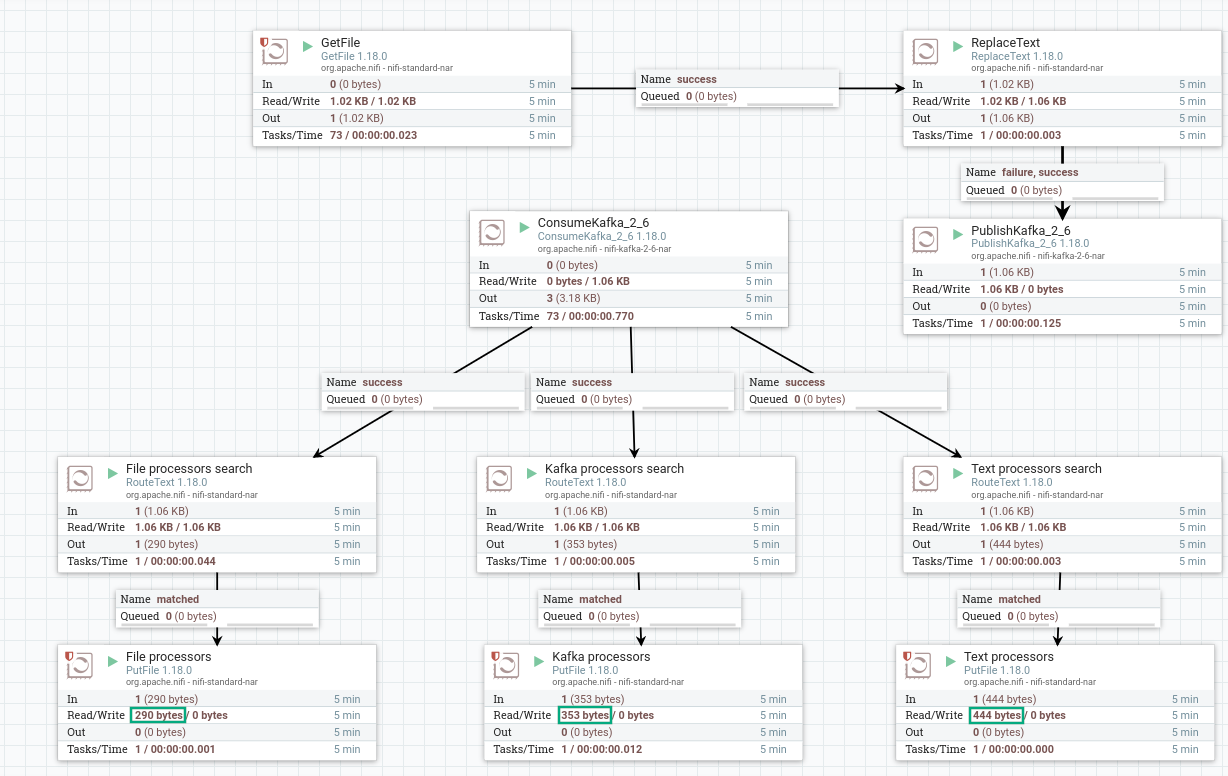
В результате в каждый файл в указанной директории для каждого процессора GetFile записаны строки в соответствии с указанным для процессора RouteFile условием:
PutFile (put, local, copy, archive, files, filesystem) - Apache NiFi processor that writes the contents of a FlowFile to the local file system. GetFile (local, files, filesystem, ingest, ingress, get, source, input) - Apache NiFi processor that creates FlowFiles from files in a directory.
ConsumeKafka (kafka, get, ingest, ingress, topic, pubsub, consume) - Apache NiFi processor that consumes messages from Apache Kafka specifically built against the Kafka Consumer API. PublishKafka (kafka, put, send, message, pubsub) - Apache NiFi processor that sends the contents of a FlowFile as a message to Apache Kafka using the Kafka Producer API.
RouteText (attributes, routing, text, regexp, regex, filter, search, detect) - Apache NiFi processor that routes textual data based on a set of user-defined rules. ReplaceText (text, update, change, replace, modify, regex) - Apache NiFi processor that updates the content of a FlowFile by evaluating a Regular Expression (regex) against it and replacing the section of the content that matches the Regular Expression with some alternate value.