

Настройка и использование Kafka Tiered Storage
Обзор
Опция Tiered Storage в ADS может быть включена при помощи конфигурационных параметров сервиса Kafka одновременно только для одного из вариантов хранилищ:
Ниже подробно описаны шаги включения опции Tiered Storage.
Hadoop Distributed File System (HDFS)
Для данного примера в качестве хранилища используется сервис HDFS кластера Arenadata Hadoop (ADH).
Предварительные требования
-
ADH
-
Кластер ADH развернут согласно руководству Online-установка.
Минимальная версия ADH — 3.3.6.2.b1.
-
Сервисы HDFS, Core configuration, YARN и Zookeeper добавлены и установлены в кластере ADH.
-
В HDFS cоздана директория, путь и название которой совпадает со значением конфигурационного параметра storage.hdfs.root, и настроены права доступа, как показано ниже:
$ sudo -u hdfs hdfs dfs -mkdir /kafka $ sudo -u hdfs hdfs dfs -chown kafka:hadoop /kafka
-
-
ADS
-
Кластер ADS развернут согласно руководству Online-установка.
Минимальная версия ADS — 3.6.2.2.b1.
-
Сервисы Kafka и Zookeeper добавлены и установлены в кластере ADS.
-
Для Kafka не включена опция Tiered Storage — в конфигурационном файле брокера Kafka /etc/kafka/conf/server.properties (/usr/lib/kafka/config/kafka-controller.properties, если активирован режим KRaft) не установлены значения для параметров групп
rsm.config.storageиremote.log.storage. -
В ADS выполнен импорт данных ADH. Для выполнения импорта в интерфейсе ADCM откройте страницу Clusters и кликните по имени кластера ADS. Затем на открывшейся странице кластера перейдите на вкладку Import, выберите Cluster configuration напротив названия кластера ADH и нажмите Import.
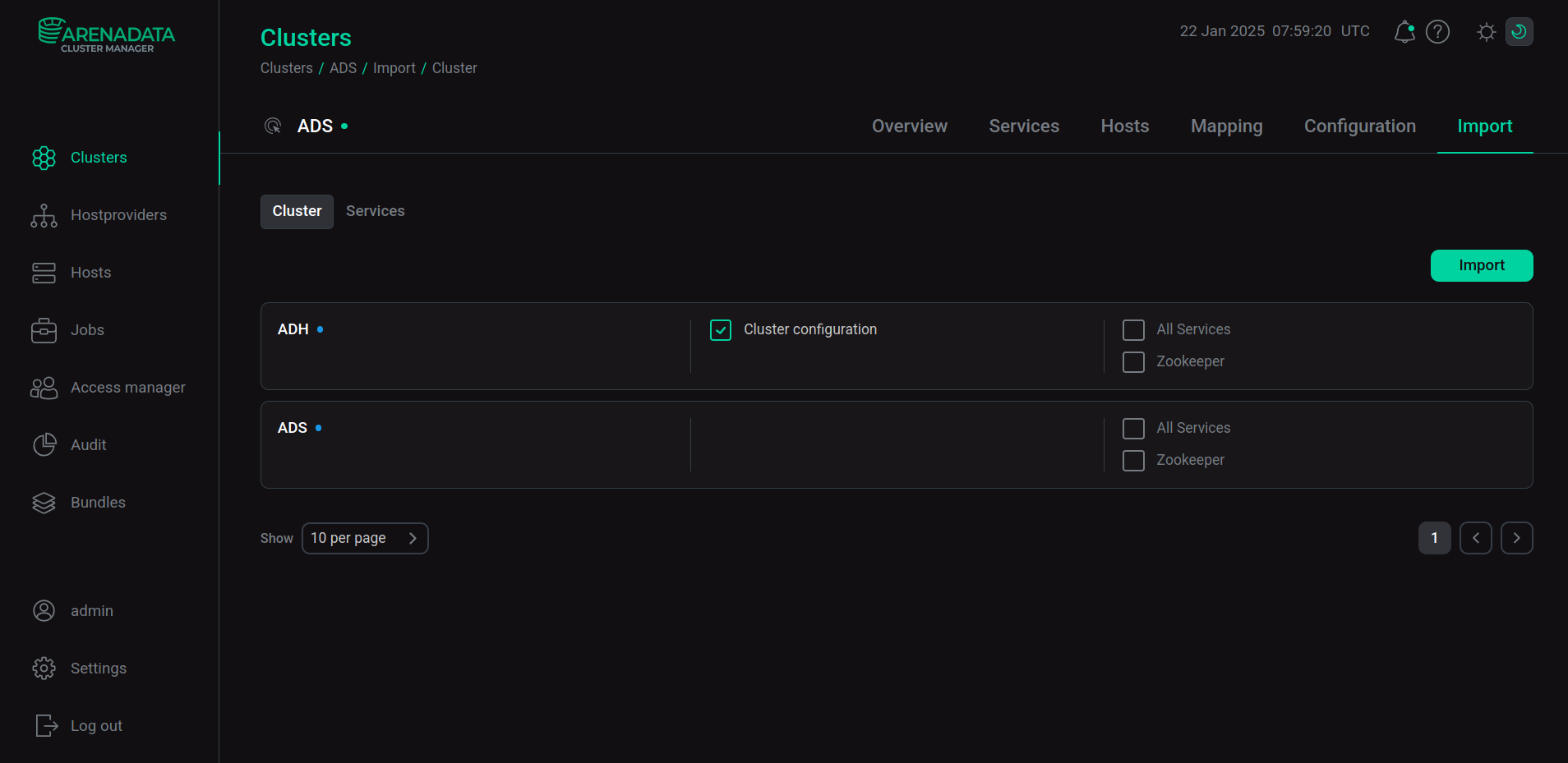 Импорт данных ADH
Импорт данных ADHПерезагрузите кластер при помощи действия Restart.
В результате импорта на хостах с сервисом Kafka в каталоге /usr/lib/kafka/config/ находятся конфигурационные файлы ADH:
А также в результате импорта в конфигурационном файле /etc/kafka/conf/kafka-java.yaml устанавливается значение для параметра
HADOOP_CONF_DIR— место, куда скопированы файлы конфигурации кластера ADH.
-
Шаг 1. Настройка и включение Tiered Storage
-
Откройте вкладку Services на странице кластера и кликните по имени сервиса Kafka в столбце Name.
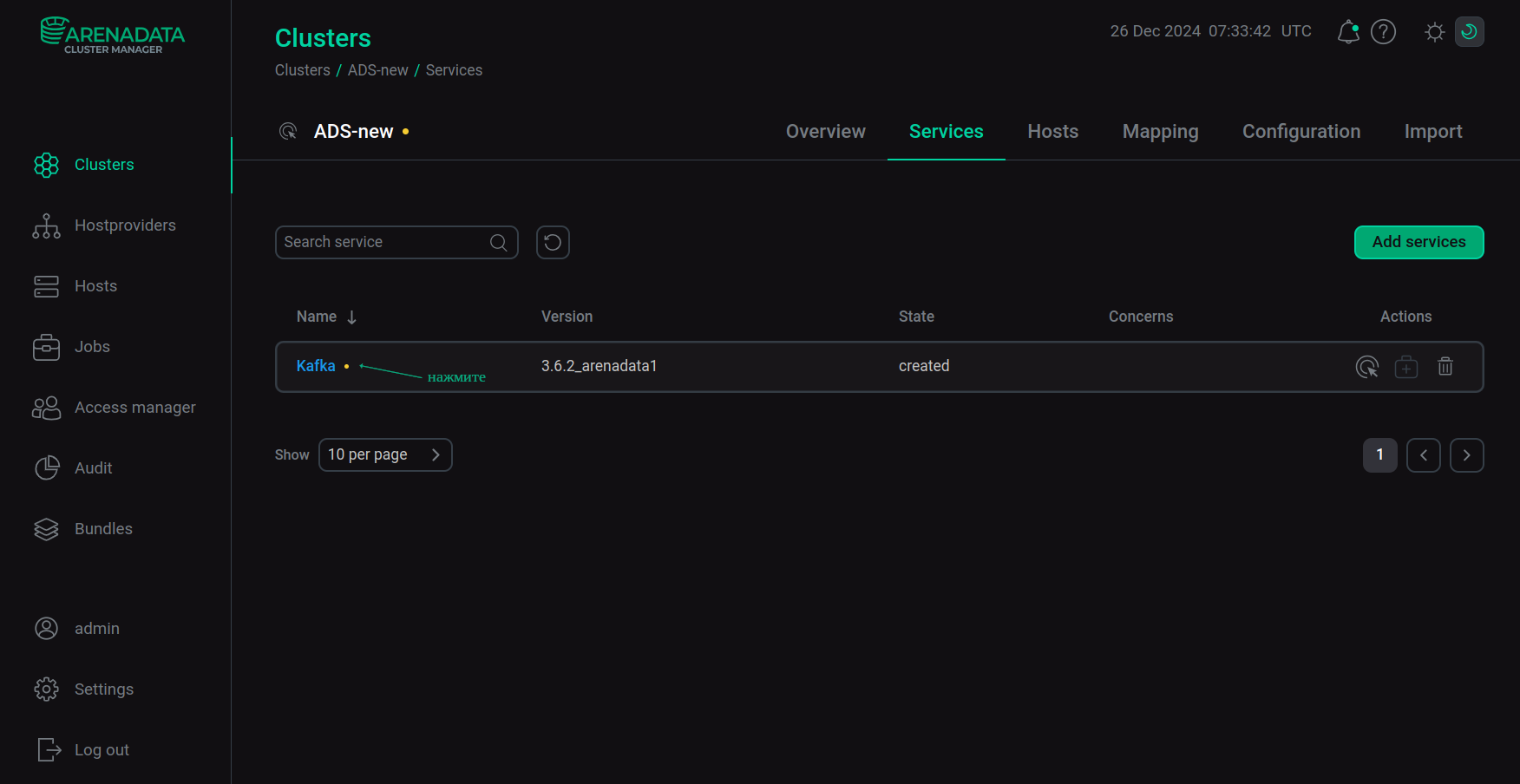 Переход к настройке сервиса
Переход к настройке сервиса -
В открывшемся окне Primary configuration:
-
Переведите в активное состояние переключатель HDFS Tiered Storage и при необходимости измените значения параметров, установленные по умолчанию.
-
При необходимости раскройте группу Tiered Storage General и измените значения параметров, установленные по умолчанию.
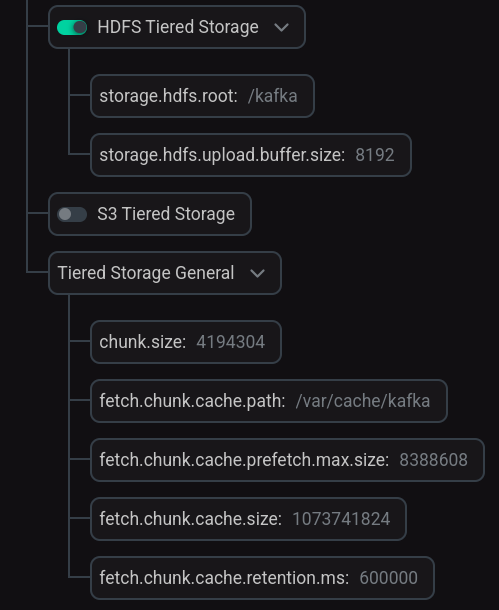 Настройка Tiered Storage
Настройка Tiered StorageОписания параметров приведены в статье Конфигурационные параметры Kafka.
-
-
Нажмите Save и перезагрузите сервис Kafka при помощи действия Restart, нажав на иконку

 в столбце Actions.
в столбце Actions. -
Дождитесь завершения перезагрузки сервиса. Проанализируйте и исправьте ошибки в случае их возникновения на странице Jobs.
Шаг 2. Проверка результатов
При включении опции Tiered Storage через интерфейс ADCM в конфигурационном файле Kafka /etc/kafka/conf/server.properties (/usr/lib/kafka/config/kafka-controller.properties, если активирован режим KRaft) автоматически устанавливаются все необходимые параметры для работы с хранилищем: параметры компонентов Remote Manager, StorageBackend (определяющиеся автоматически для выбранного вида хранилища) и механизма chunking.
Ниже приведен пример измененного при помощи ADCM файла конфигурации.
# Managed by ADCM
node.id=1
reserved.broker.max.id=5000
auto.create.topics.enable=False
listeners=PLAINTEXT://:9092
log.dirs=/kafka-logs
default.replication.factor=1
num.partitions=1
delete.topic.enable=true
log.retention.hours=168
log.roll.hours=168
queued.max.requests=500
num.network.threads=3
num.io.threads=8
auto.leader.rebalance.enable=True
unclean.leader.election.enable=False
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
zookeeper.connect=sov-ads-test-4.ru-central1.internal:2181/arenadata/cluster/148
zookeeper.connection.timeout.ms=30000
zookeeper.session.timeout.ms=30000
zookeeper.sync.time.ms=2000
zookeeper.set.acl=false
log.cleaner.enable=True
log.cleanup.policy=delete
log.cleanup.interval.mins=10
log.cleaner.min.compaction.lag.ms=0
log.cleaner.delete.retention.ms=86400000
security.inter.broker.protocol=PLAINTEXT
remote.log.metadata.manager.listener.name=PLAINTEXT
remote.log.storage.manager.class.name=io.aiven.kafka.tieredstorage.RemoteStorageManager
remote.log.storage.manager.class.path=/usr/lib/kafka/libs/tiered-storage/*
remote.log.storage.system.enable=true
rsm.config.chunk.size=4194304
rsm.config.fetch.chunk.cache.class=io.aiven.kafka.tieredstorage.fetch.cache.DiskChunkCache
rsm.config.fetch.chunk.cache.path=/var/cache/kafka
rsm.config.fetch.chunk.cache.prefetch.max.size=8388608
rsm.config.fetch.chunk.cache.size=1073741824
rsm.config.fetch.chunk.cache.retention.ms=600000
rsm.config.storage.backend.class=io.aiven.kafka.tieredstorage.storage.hdfs.HdfsStorage
rsm.config.storage.hdfs.core-site.path=/usr/lib/kafka/config/core-site.xml
rsm.config.storage.hdfs.hdfs-site.path=/usr/lib/kafka/config/hdfs-site.xml
rsm.config.storage.hdfs.root=/kafka
rsm.config.storage.hdfs.upload.buffer.size=8192Для проверки правильной настройки многоуровневого хранилища для Kafka можно выполнить запись данных в тестовый топик и проконтролировать перенос данных в хранилище, как описано ниже.
Simple Storage Service (S3)
Для данного примера в качестве сервера S3 используется хранилище MinIO.
Предварительные требования
-
ADS
-
Кластер ADS развернут согласно руководству Online-установка.
Минимальная версия ADS — 3.6.2.2.b1.
-
Сервисы Kafka и Zookeeper добавлены и установлены в кластере ADS.
-
Для Kafka не включена опция Tiered Storage — в конфигурационном файле брокера Kafka /etc/kafka/conf/server.properties (/usr/lib/kafka/config/kafka-controller.properties, если активирован режим KRaft) не установлены значения для параметров групп
rsm.config.storageиremote.log.storage.
-
-
В облачном хранилище MinIO cоздан бакет для хранения данных.
|
ПРИМЕЧАНИЕ
В реализации Tiered Storage на основе сервера S3 перенос записей на remote-уровень контролируется при помощи специального топика |
Шаг 1. Настройка и включение Tiered Storage
-
Откройте вкладку Services на странице кластера и кликните по имени сервиса Kafka в столбце Name.
Переход к настройке сервиса -
В открывшемся окне Primary configuration:
-
Для серверов S3, у которых ссылка на бакет задается не в формате FQDN, а в виде пути (например, для MinIO ссылка на бакет выглядит так: http://<s3hostname:port>/browser/<bucket.name>), установите параметр удаленного хранилища, который определяет соответствующий вид ссылки к бакету:
rsm.config.storage.s3.path.style.access.enabled=trueДля этого раскройте группу server.properties и, используя поле Add key,value, выберите Add property и введите наименование параметра и его значение.
-
Переведите в активное состояние переключатель S3 Tiered Storage и введите значения параметров для подключения к хранилищу S3.
ПРИМЕЧАНИЕЗначение параметра storage.s3.region не может быть пустым. Если на сервере S3 не предусмотрен такой параметр, установите для него любое значение, например,
none. -
При необходимости раскройте группу Tiered Storage General и измените значения параметров, установленные по умолчанию.
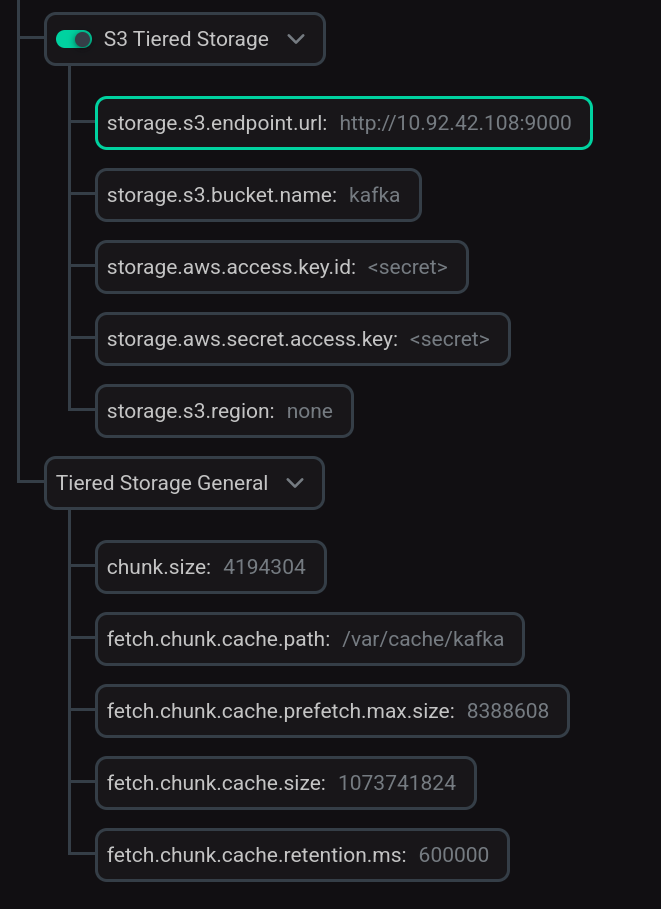 Настройка Tiered Storage
Настройка Tiered StorageОписания параметров приведены в статье Конфигурационные параметры Kafka.
-
-
Нажмите Save и перезагрузите сервис Kafka при помощи действия Restart, нажав на иконку
в столбце Actions. -
Дождитесь завершения перезагрузки сервиса. Проанализируйте и исправьте ошибки в случае их возникновения на странице Jobs.
Шаг 2. Проверка результатов
При включении опции Tiered Storage через интерфейс ADCM в конфигурационном файле Kafka /etc/kafka/conf/server.properties (/usr/lib/kafka/config/kafka-controller.properties, если активирован режим KRaft) автоматически устанавливаются все необходимые параметры для работы с хранилищем: параметры компонентов Remote Manager, StorageBackend (определяющиеся автоматически для выбранного вида хранилища) и механизма chunking.
Ниже приведен пример измененного при помощи ADCM файла конфигурации.
# Managed by ADCM
node.id=1
reserved.broker.max.id=5000
auto.create.topics.enable=False
listeners=PLAINTEXT://:9092
log.dirs=/kafka-logs
default.replication.factor=1
num.partitions=1
delete.topic.enable=true
log.retention.hours=168
log.roll.hours=168
queued.max.requests=500
num.network.threads=3
num.io.threads=8
auto.leader.rebalance.enable=True
unclean.leader.election.enable=False
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
zookeeper.connect=sov-ads-test-2.ru-central1.internal:2181/arenadata/cluster/154
zookeeper.connection.timeout.ms=30000
zookeeper.session.timeout.ms=30000
zookeeper.sync.time.ms=2000
zookeeper.set.acl=false
log.cleaner.enable=True
log.cleanup.policy=delete
log.cleanup.interval.mins=10
log.cleaner.min.compaction.lag.ms=0
log.cleaner.delete.retention.ms=86400000
rlmm.config.remote.log.metadata.topic.replication.factor=1
rsm.config.storage.s3.path.style.access.enabled=true
security.inter.broker.protocol=PLAINTEXT
remote.log.metadata.manager.listener.name=PLAINTEXT
remote.log.storage.manager.class.name=io.aiven.kafka.tieredstorage.RemoteStorageManager
remote.log.storage.manager.class.path=/usr/lib/kafka/libs/tiered-storage/*
remote.log.storage.system.enable=true
rsm.config.chunk.size=4194304
rsm.config.fetch.chunk.cache.class=io.aiven.kafka.tieredstorage.fetch.cache.DiskChunkCache
rsm.config.fetch.chunk.cache.path=/var/cache/kafka
rsm.config.fetch.chunk.cache.prefetch.max.size=8388608
rsm.config.fetch.chunk.cache.size=1073741824
rsm.config.fetch.chunk.cache.retention.ms=600000
rsm.config.storage.backend.class=io.aiven.kafka.tieredstorage.storage.s3.S3Storage
rsm.config.storage.s3.endpoint.url=http://<s3hostname:port>
rsm.config.storage.s3.bucket.name=kafka
rsm.config.storage.aws.access.key.id=<access key>
rsm.config.storage.aws.secret.access.key=<secret key>
rsm.config.storage.s3.region=noneДля проверки правильной настройки многоуровневого хранилища для Kafka можно выполнить запись данных в тестовый топик и проконтролировать перенос данных в хранилище, как описано ниже.
Ozone
Для данного примера в качестве хранилища используется сервис Ozone кластера Arenadata Hadoop (ADH).
Предварительные требования
-
ADH
-
Кластер ADH развернут согласно руководству Online-установка.
Минимальная версия ADH — 3.3.6.2.b1.
-
Сервисы Zookeeper, Core configuration, HDFS, YARN и Ozone добавлены и установлены в кластере ADH.
-
Созданы том и бакет Ozone на хосте, где установлен Ozone:
$ ozone sh volume create volumetest $ sudo ozone sh bucket create /volumetest/testbucket
-
-
ADS
-
Кластер ADS развернут согласно руководству Online-установка.
Минимальная версия ADS — 3.9.1.2.b1.
-
Сервисы Kafka и Zookeeper добавлены и установлены в кластере ADS.
-
Для Kafka не включена опция Tiered Storage — в конфигурационном файле брокера Kafka /etc/kafka/conf/server.properties (/usr/lib/kafka/config/kafka-controller.properties, если активирован режим KRaft) не установлены значения для параметров групп
rsm.config.storageиremote.log.storage. -
В ADS выполнен импорт данных ADH. Для выполнения импорта в интерфейсе ADCM откройте страницу Clusters и кликните по имени кластера ADS. Затем на открывшейся странице кластера перейдите на вкладку Import, выберите Cluster configuration напротив названия кластера ADH и нажмите Import.
Импорт данных ADHПерезагрузите кластер при помощи действия Restart.
В результате импорта на хостах с сервисом Kafka в каталоге /usr/lib/kafka/config/ находятся конфигурационные файлы ADH:
А также в результате импорта в конфигурационном файле /etc/kafka/conf/kafka-java.yaml устанавливается значение для параметра
HADOOP_CONF_DIR— место, куда скопированы файлы конфигурации кластера ADH.
-
Шаг 1. Настройка и включение Tiered Storage
-
Откройте вкладку Services на странице кластера и кликните по имени сервиса Kafka в столбце Name.
Переход к настройке сервиса -
В открывшемся окне Primary configuration:
-
Переведите в активное состояние переключатель Ozone Tiered Storage и установите необходимые значения.
Значение параметра Ozone Path устанавливается как
<ozone.om.service.ids>/volumetest/testbucket, где:-
<ozone.om.service.ids>— значение соответствующего параметра компонента Ozone Manager (группа параметров ozone-site.xml) сервиса Ozone кластера ADH, настроенное во время установки кластера. -
/volumetest/testbucket— том и бакет Ozone, созданные ранее.
-
-
При необходимости раскройте группу Tiered Storage General и измените значения параметров, установленные по умолчанию.
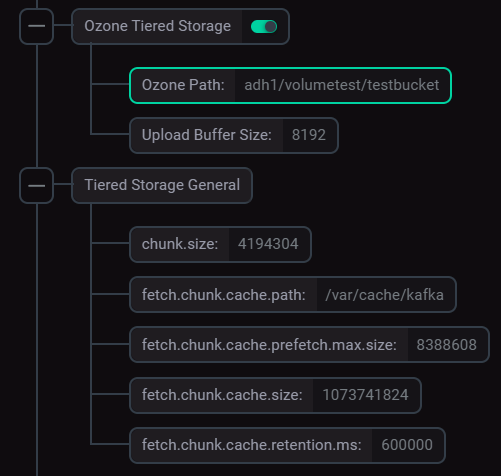 Настройка Tiered Storage
Настройка Tiered Storage
Описания параметров приведены в статье Конфигурационные параметры Kafka.
-
-
Нажмите Save и перезагрузите сервис Kafka при помощи действия Restart, нажав на иконку
в столбце Actions. -
Дождитесь завершения перезагрузки сервиса. Проанализируйте и исправьте ошибки в случае их возникновения на странице Jobs.
Шаг 2. Проверка результатов
При включении опции Tiered Storage через интерфейс ADCM в конфигурационном файле Kafka /etc/kafka/conf/server.properties (/usr/lib/kafka/config/kafka-controller.properties, если активирован режим KRaft) автоматически устанавливаются все необходимые параметры для работы с хранилищем: параметры компонентов Remote Manager, StorageBackend (определяющиеся автоматически для выбранного вида хранилища) и механизма chunking.
Ниже приведен пример измененного при помощи ADCM файла конфигурации.
# Managed by ADCM
node.id=3
reserved.broker.max.id=5000
auto.create.topics.enable=False
listeners=PLAINTEXT://:9092
log.dirs=/kafka-logs
default.replication.factor=1
num.partitions=1
delete.topic.enable=true
log.retention.hours=168
log.roll.hours=168
queued.max.requests=500
num.network.threads=3
num.io.threads=8
auto.leader.rebalance.enable=True
unclean.leader.election.enable=False
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
listener.security.protocol.map=PLAINTEXT:PLAINTEXT
zookeeper.connect=sov-ads-3.ru-central1.internal:2181,sov-ads-4.ru-central1.internal:2181,sov-ads-2.ru-central1.internal:218>
zookeeper.connection.timeout.ms=30000
zookeeper.session.timeout.ms=30000
zookeeper.sync.time.ms=2000
zookeeper.set.acl=false
log.cleaner.enable=True
log.cleanup.policy=delete
log.cleanup.interval.mins=10
log.cleaner.min.compaction.lag.ms=0
log.cleaner.delete.retention.ms=86400000
security.inter.broker.protocol=PLAINTEXT
remote.log.metadata.manager.listener.name=PLAINTEXT
remote.log.storage.manager.class.name=io.aiven.kafka.tieredstorage.RemoteStorageManager
remote.log.storage.manager.class.path=/usr/lib/kafka/libs/tiered-storage/*
remote.log.storage.system.enable=true
rsm.config.chunk.size=4194304
rsm.config.fetch.chunk.cache.class=io.aiven.kafka.tieredstorage.fetch.cache.DiskChunkCache
rsm.config.fetch.chunk.cache.path=/var/cache/kafka
rsm.config.fetch.chunk.cache.prefetch.max.size=8388608
rsm.config.fetch.chunk.cache.size=1073741824
rsm.config.fetch.chunk.cache.retention.ms=600000
rsm.config.storage.backend.class=io.arenadata.kafka.tieredstorage.storage.hdfs.HdfsStorage
rsm.config.storage.hdfs.core-site.path=/usr/lib/kafka/config/core-site.xml
rsm.config.storage.hdfs.root=ofs://adh1/volumetest/testbucket
rsm.config.storage.hdfs.upload.buffer.size=8192Для проверки правильной настройки многоуровневого хранилища для Kafka можно выполнить запись данных в тестовый топик и проконтролировать перенос данных в хранилище, как описано ниже.
Использование Tiered Storage
При создании топика, сегменты которого должны быть перемещены в хранилище, необходимо включить для данного топика опцию Tiered Storage при помощи параметра remote.storage.enable.
Если для топика не указан параметр local.retention.ms, время локального хранения данных будет соответствовать времени, указанному для брокера.
Ниже приведен пример создания топика с указанием параметров, а также с указанием времени общего хранения и размера сегмента:
$ /usr/lib/kafka/bin/kafka-topics.sh --create --topic tieredTopic --bootstrap-server sov-ads-2.ru-central1.internal:9092 --config remote.storage.enable=true --config local.retention.ms=1000 --config retention.ms=300000 --config segment.bytes=1048576После записи сообщений по истечении интервала, с которым RemoteLogManager выполняет копирование сегментов (30 секунд по умолчанию), файл появляется в директории хранилища. Данные сообщения могут быть прочитаны как обычно.
Просмотр директории топика в хранилищах
-
HDFS
Проверить наличие директории для топика в хранилище HDFS можно, выполнив команду:
$ sudo -u hdfs hdfs dfs -ls /kafkaДиректория для записи сегментов топика tieredTopic на remote-уровне:
Found 1 items drwxr-xr-x - kafka hadoop 0 2026-03-25 12:30 /kafka/tieredTopic-ku0BMor0TzC1UEkL6aVbNg
-
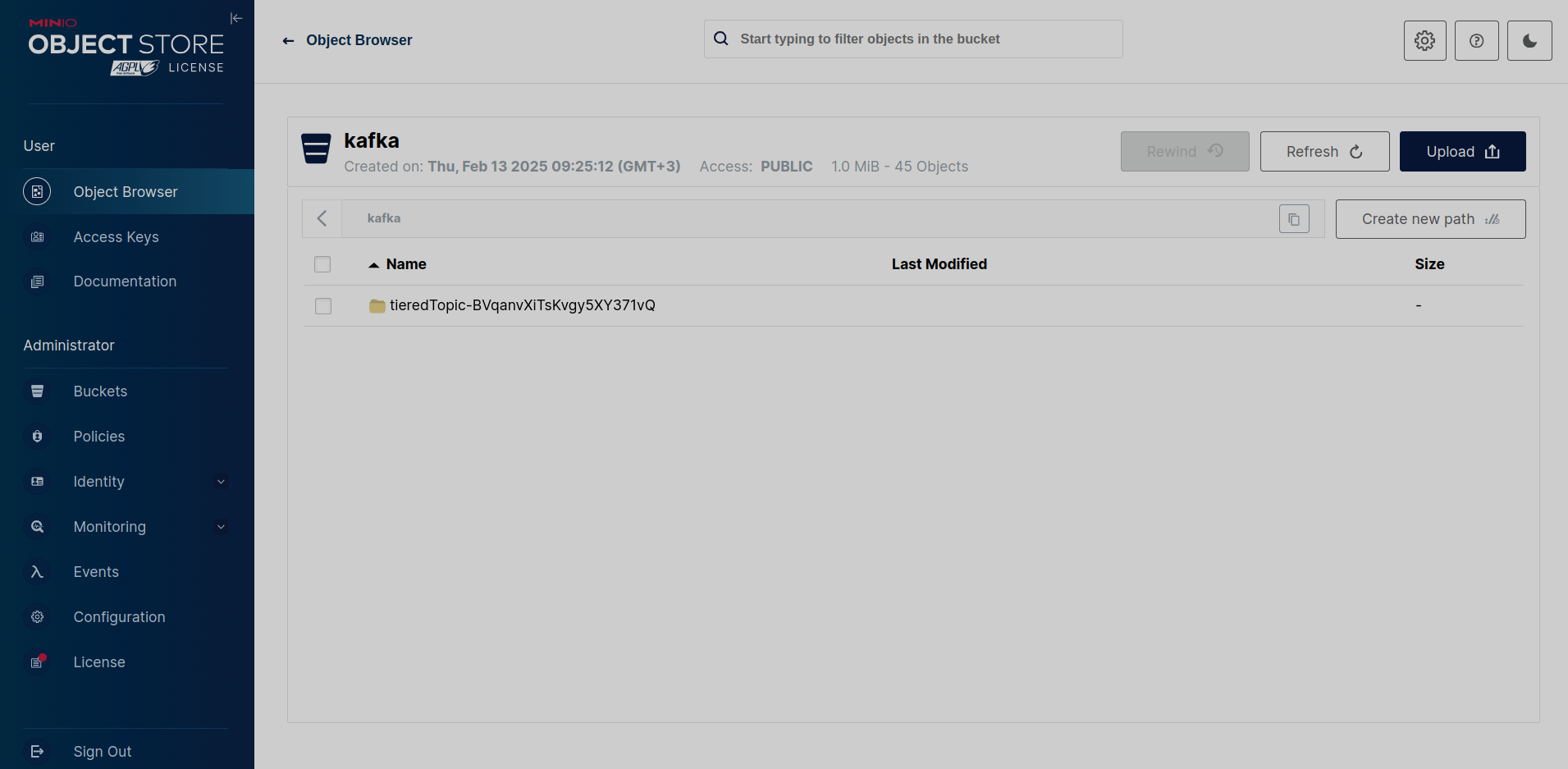
S3
Ниже на рисунке показана директория с сегментами топика на remote-уровне в бакете хранилища MinIO.
-
Ozone
Проверить наличие директории для топика в хранилище Ozone можно, выполнив команду:
sudo hdfs dfs -ls ofs://adh1/volumetest/testbucketДиректория для записи сегментов топика tieredTopic на remote-уровне:
Found 1 items drwxrwxrwx - kafka root 0 2026-03-25 12:26 ofs://adh1/volumetest/testbucket/tieredTopic-ku0BMor0TzC1UEkL6aVbNg
|
ПРИМЕЧАНИЕ
Просмотр томов и бакетов Ozone доступен также в интерфейсе Ozone Recon. |
Обзор данных в Tiered Storage
Созданная в хранилище директория tieredTopic-BVqanvXiTsKvgy5XY371vQ имеет имя, состоящее из названия топика tieredTopic, за которым следуют тире и идентификатор топика.
Эта директория в свою очередь содержит папки, соответствующие номерам партиций. Папки партиций содержат по три файла для каждого сохраненного на remote-уровне сегмента:
-
00000000000000000009-UzfbrQXzQKOt7IqzpRh1kA.indexes — файл, содержащий индексы Kafka, которые связаны с каждым сегментом журнала.
-
00000000000000000009-UzfbrQXzQKOt7IqzpRh1kA.log — файл, являющийся сегментом журнала и содержащий записи Kafka.
-
00000000000000000009-UzfbrQXzQKOt7IqzpRh1kA.rsm-manifest — файл, содержащий метаданные о сегменте журнала и индексах.
Такие файлы имеют название, состоящее из номера смещения и идентификатора сегмента журнала.