

Configure processors and process groups
Configure a processor
To configure a processor, right-click the processor and select the Configure option from the context menu. The configuration dialog opens with four different tabs, each of which is described below. After completing the processor setup, it is possible to apply the changes by clicking APPLY, or cancel all changes by clicking CANCEL.
|
CAUTION
[#x0], [#x1], [#x2], [#x3], [#x4], [#x5], [#x6], [#x7], [#x8], [#xB], [#xC], [#xE], [#xF], [#x10], [#x11], [#x12], [#x13], [#x14], [#x15], [#x16], [#x17], [#x18], [#x19], [#x1A], [#x1B], [#x1C], [#x1D], [#x1E], [#x1F], [#xFFFE], [#xFFFF] |
SETTINGS tab
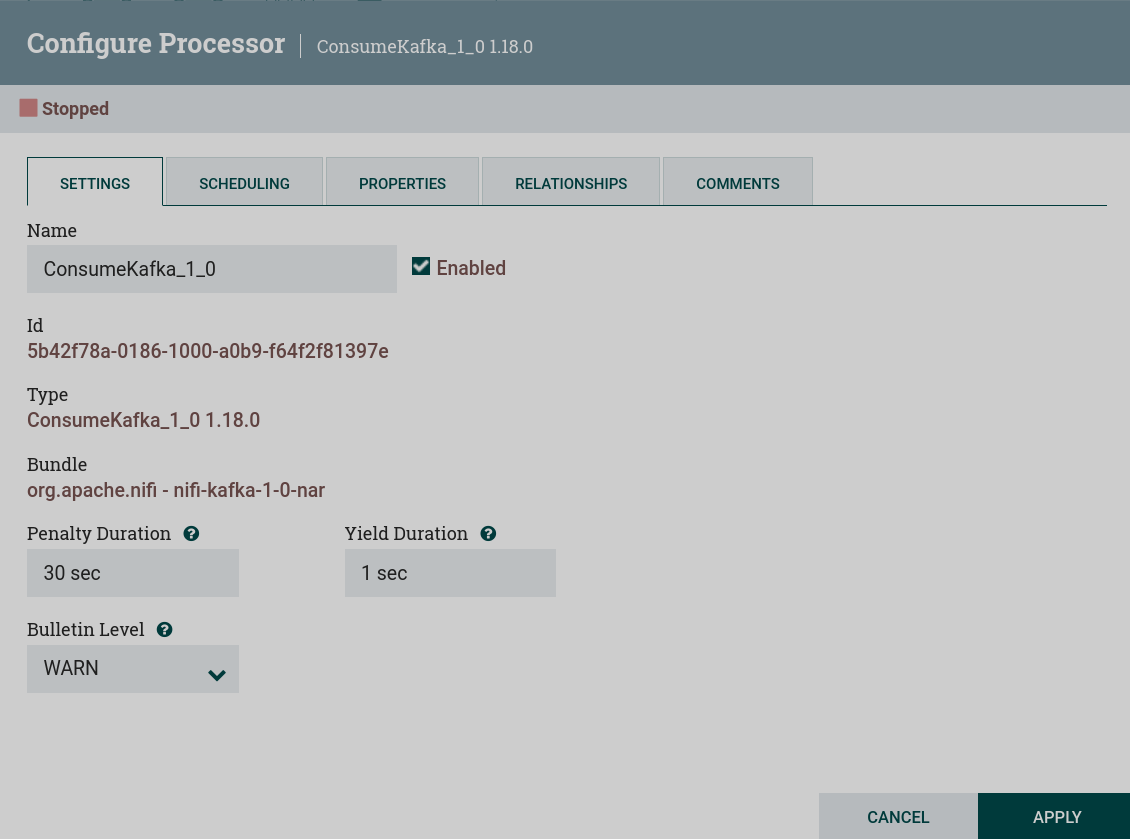
Name — processor name. The default processor name is the same as the processor type. Next to the processor name is an Enabled flag indicating whether the processor is enabled.
Id — the unique processor identifier.
Type — the processor type.
Bundle — the NAR bundle.
Yield Duration — the period of time without a response from the remote service, after which the processor must "yield", which will prevent the processor from being scheduled to run for some period of time.
Penalty Duration — the period of time during which scheduled processor execution is prevented in case of an error in receiving or sending files to a remote service.
Bulletin Level — the lowest bulletin level that should be displayed in the user interface.
SCHEDULING tab
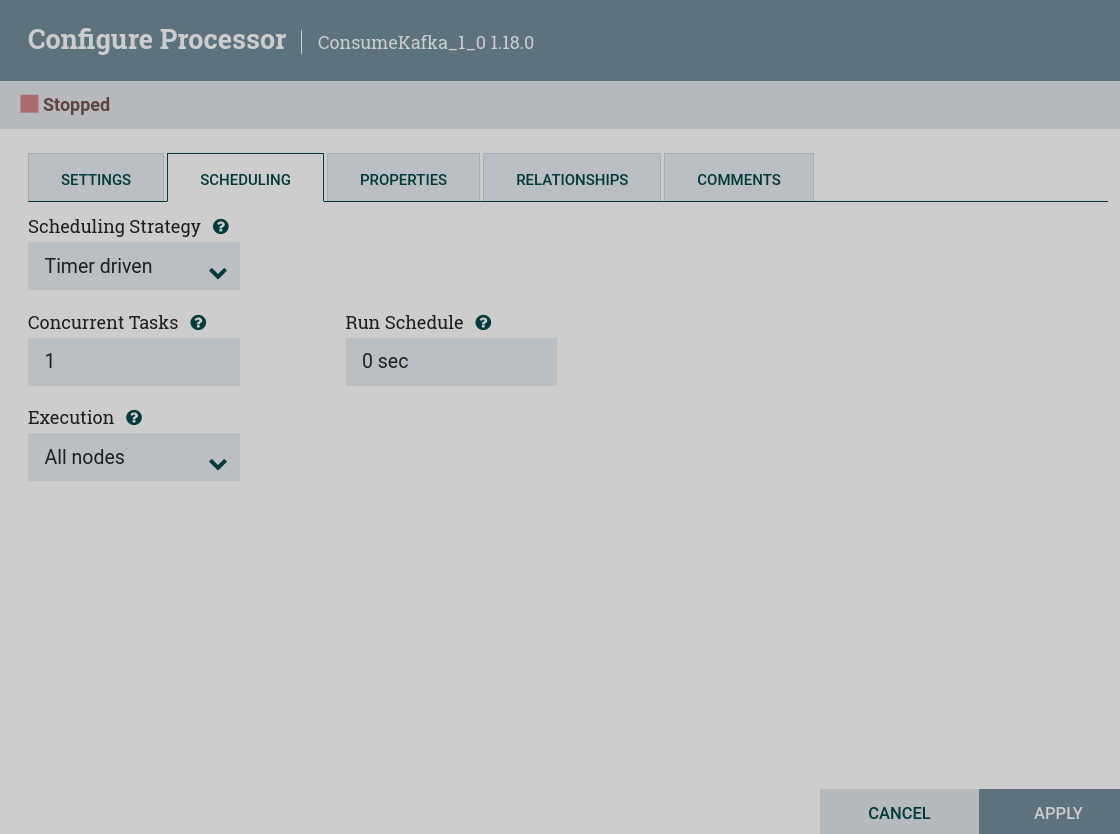
Scheduling Strategy — the scheduling strategy. Possible options for scheduling components:
-
Timer driven — the processor will run at regular intervals. The processor startup interval is determined by the Startup Schedule parameter.
-
CRON driven — when using CRON driven scheduling mode, the processor is scheduled to run periodically, similar to timer driven scheduling mode. However, CRON-managed mode provides much more flexibility at the cost of increased configuration complexity. The CRON-managed scheduling value is a string of six required fields and one optional field, each separated by a space.
Concurrent Tasks — determines how many threads will use the processor. In other words, this determines how many FlowFiles should be processed by this processor at the same time.
Run Schedule — determines how often the processor should be scheduled to run. Valid values for this field depend on the selected planning strategy.
Execution — determines which node(s) the processor will be scheduled to execute on.
PROPERTIES tab
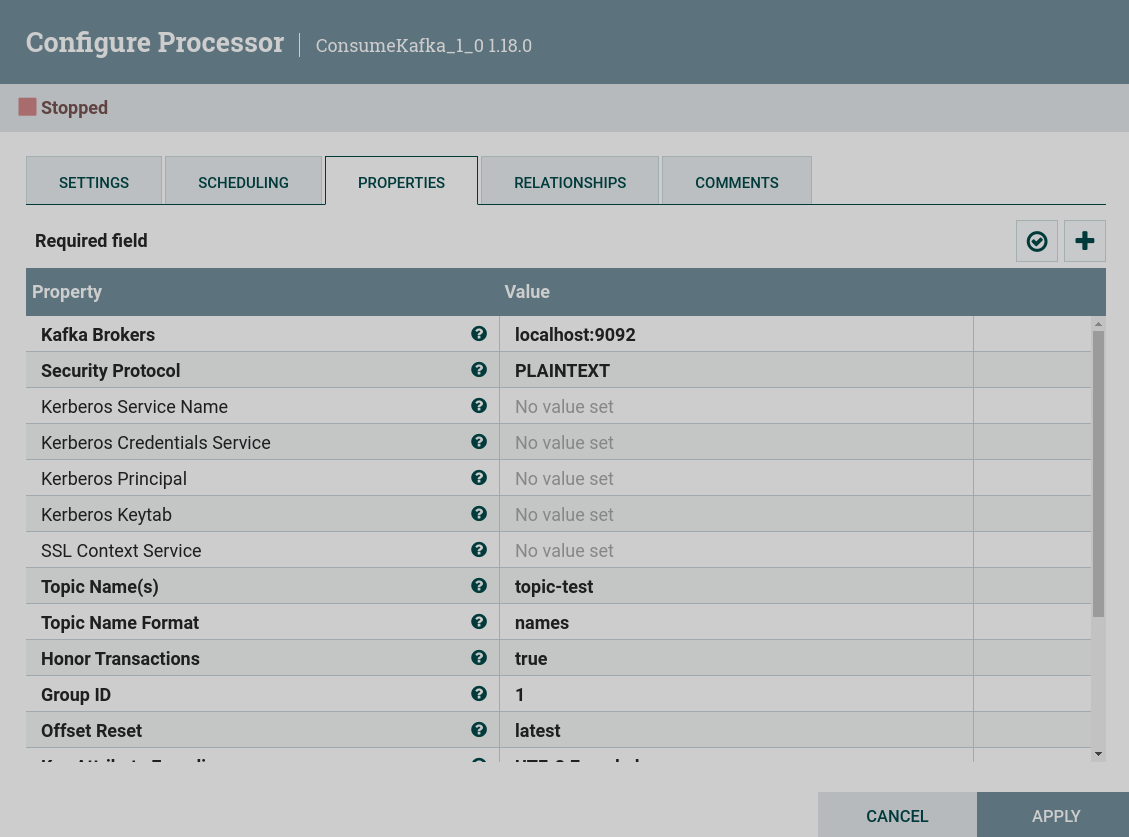
The PROPERTIES tab provides a mechanism for customizing the behavior of a particular processor. There are no default properties. Each processor type must determine which properties make sense for its use case.
Setting processor properties is described in the article Work with attributes.
RELATIONSHIP tab
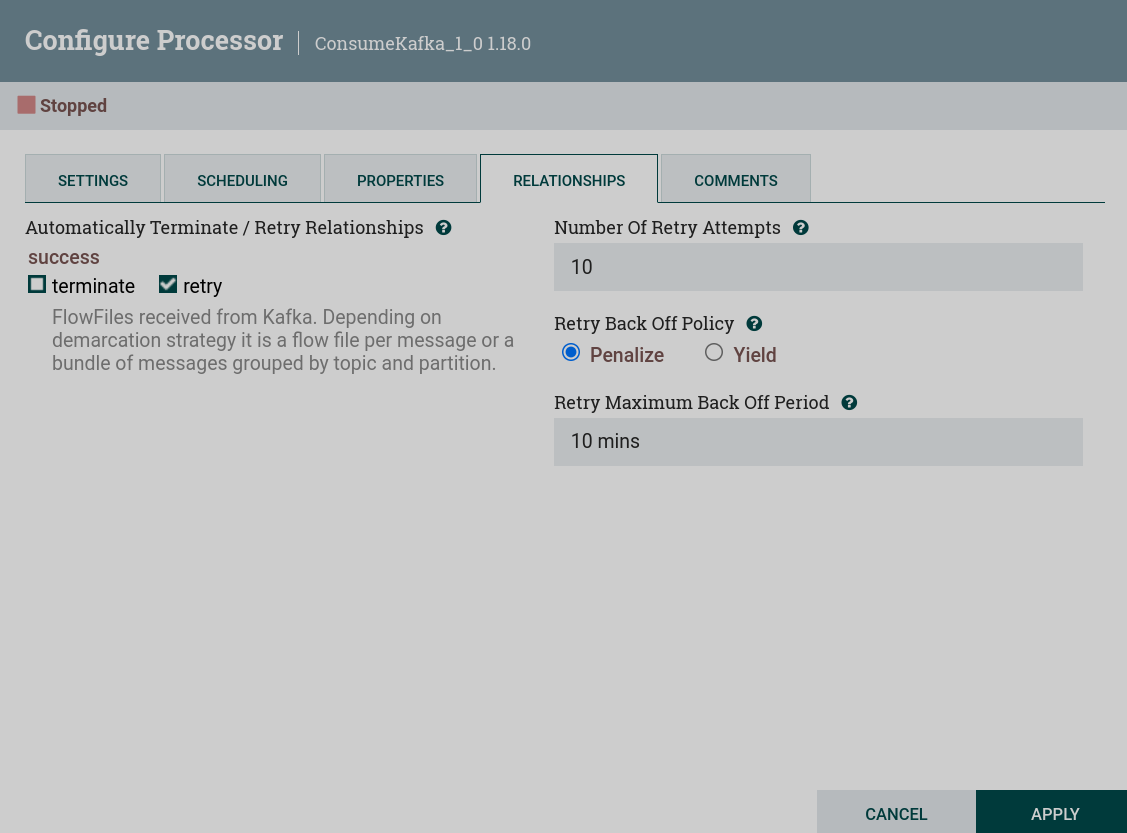
Automatically Terminate / Retry Relationships:
-
Automatically Terminate — for a processor to be considered valid and able to run, each relationship defined by the processor must either be connected to a child component or automatically terminated. If the relationship terminates automatically, any FlowFile routed to that relationship will be removed from the flow and its processing will be considered complete. Any association that is already associated with a child component cannot be automatically terminated. The relation must first be removed from any connection that uses it. Also, for any relationship that is selected for auto-completion, the auto-complete status will be cleared (disabled) if the relationship is added to the connection.
-
Automatically Retry — users can also configure whether or not to retry FlowFiles routed to this link.
Number of Retry Attempts — for relationships configured to retry, this number specifies how many times the FlowFile will try to retry before it is routed to another location.
Retry Back Off Policy — when a FlowFile needs to be retried, the user can configure a retry back policy with two options:
-
Penalize — retries will occur on time, but the processor will continue to process other FlowFiles.
-
Yield — no other processing of the FlowFile will be performed until all retries have been made.
Retry Maximum Back Off Period — initial retries are based on the Yield Duration and Penalty Duration specified in the SETTINGS tab. The duration time is doubled many times for each successive retry attempt. This number specifies the maximum amount of time allowed before the next retry attempt.
COMMENTS tab
The tab simply provides an area for users to include any comments that are appropriate for that component.
|
NOTE
For more information on configuring NiFi processors, see Configuring a processor. |
Configure process groups
GENERAL tab
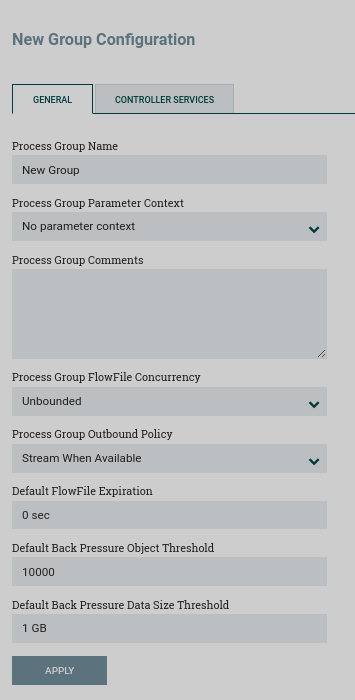
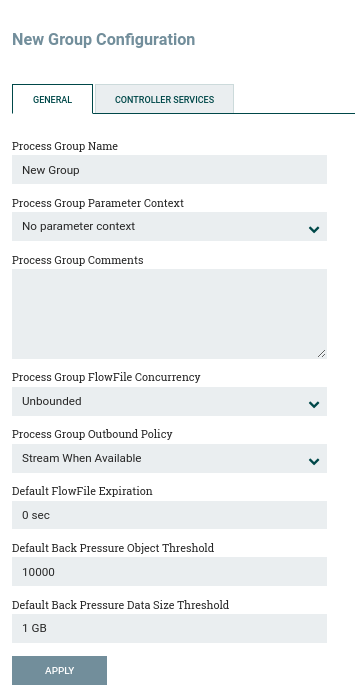
Process Group Name — the process group name. This name appears at the top of the process group on the canvas, as well as in the breadcrumbs at the bottom of the user interface. For the root process group (i.e., the highest level group), this is also the name that appears as the title of the browser tab. Note that this information is visible to any other NiFi instance that remotely connects to that instance (using remote process groups, also known as Site-to-Site).
Process Group Parameter Context — the process group parameter context that is used to provide parameters to flow components. From this drop-down list, the user can select which settings context should be bound to this process group, and can optionally create a new context to bind to the process group.
Process Group Comments — process group comments. This provides a mechanism for adding any useful information about the process group.
Process Group FlowFile Concurrency — used to control how data is passed to the process group.
Three options are available:
-
Unbounded — the input ports in a process group will receive data as fast as possible, provided that backpressure does not prevent them from doing so.
-
Single FlowFile Per Node — the input ports will only pass one FlowFile at a time. Once this FlowFile enters a process group, no additional FlowFiles will be added until all FlowFiles have left the process group (either by being purged/auto-terminated or exited via exit port).
-
Single Batch Per Node — the input ports will behave the same as in Single FlowFile Per Node mode, but when receiving a FlowFile, the input ports will continue to receive all data until all queues feeding the input ports , will not be emptied. At this point, they will no longer contribute data to the process group until all data has finished processing and leaves the process group.
Process Group Outbound Policy — while the FlowFile Concurrency dictates how data should be delivered to the process group, the outbound policy controls the flow of data out of the process group. There are two options available:
-
Stream When Available — data arriving at the output port is immediately streamed from the process group, provided no backpressure is applied.
-
Batch Output — the output ports will not transmit data from the process group until all data in the process group has been queued at the output port (i.e. no data has left the process group until processing all data is completed). It doesn’t matter if all data is queued to the same output port, or if some data is queued to output port A and other data is queued to output port B. Both of these conditions are considered the same in terms of the completion of FlowFile processing.
Default Settings for Connections — the default FlowFile expiration.
Default Back Pressure Object Threshold — the default backpressure object threshold.
Default Back Pressure Data Size Threshold — the default backpressure data size threshold.
CONTROLLER SERVICES tab
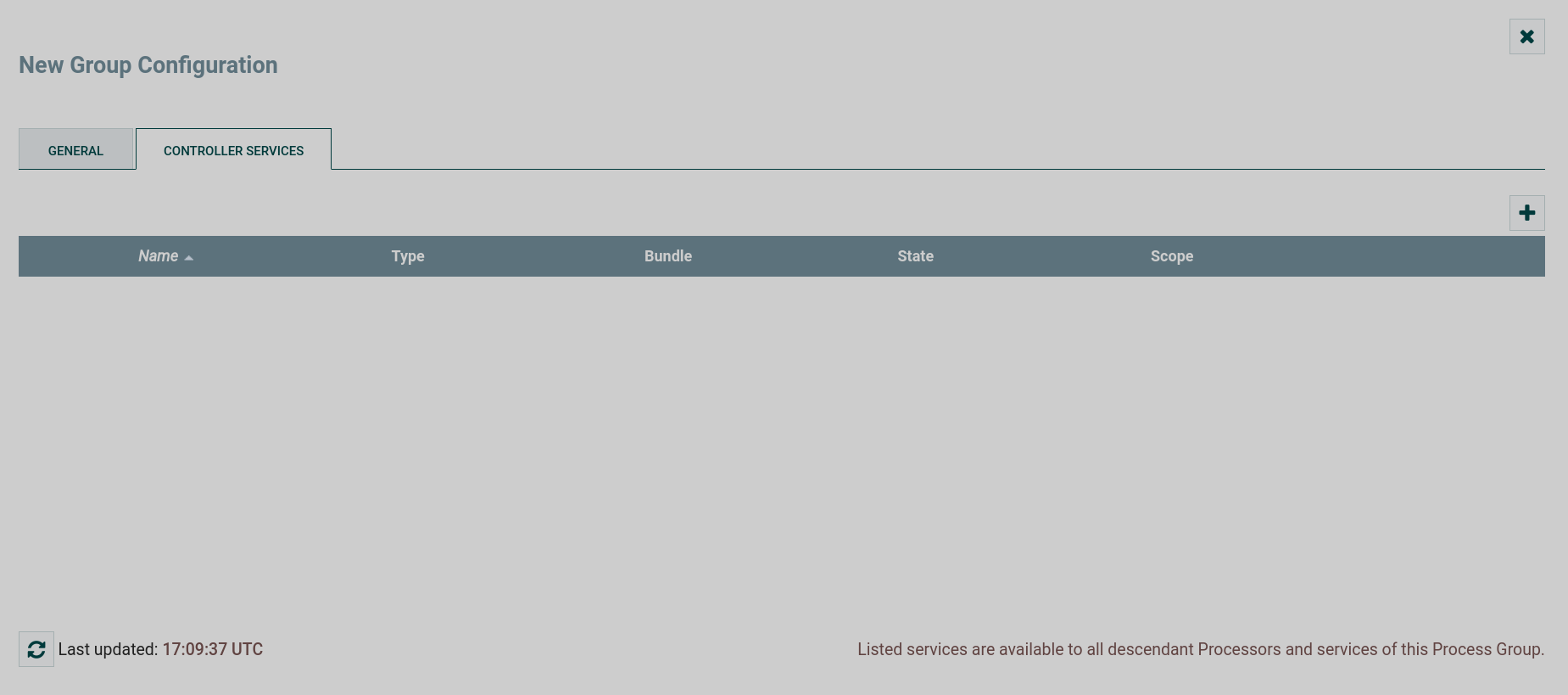
The tab displays controller services for data flows.
|
NOTE
For more information on configuring NiFi process groups, refer to Configuring a Process Group. |
Configure connections
DETAILS tab
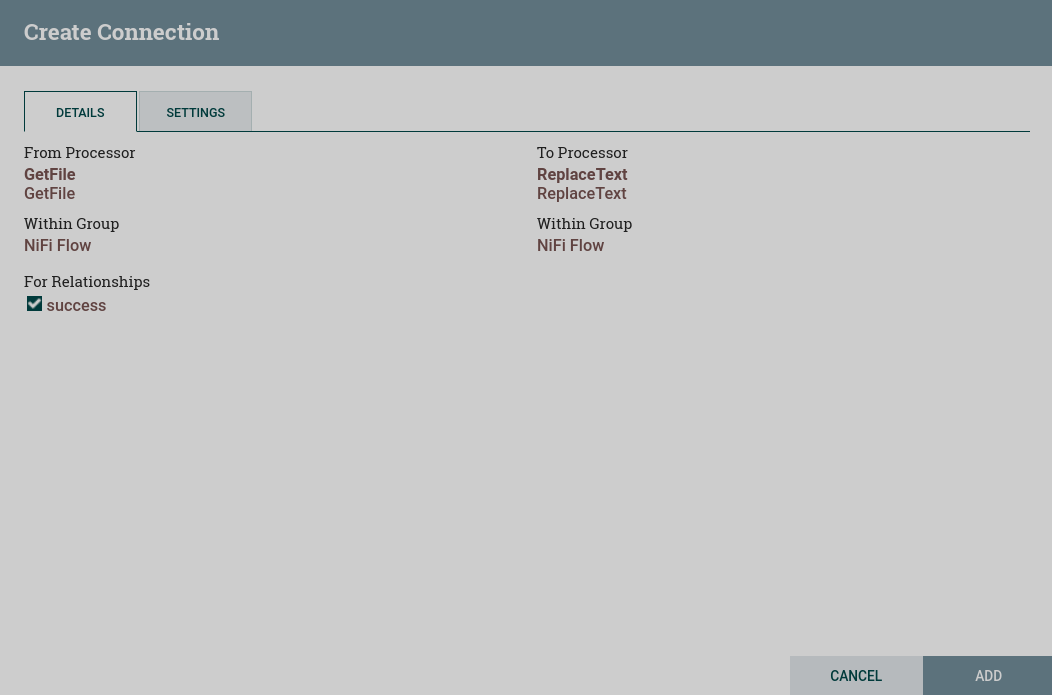
The DETAILS tab provides information about the source and target components, including the name of the component, the type of the component, and the process group the component is in.
For Relationships — provides the ability to select which relationships should be included in this connection. At least one relationship must be selected. If only one relationship is available, it is selected automatically.
If multiple connections are added with the same relation, any FlowFile routed to that relation will automatically be "cloned" and a copy of it will be sent to each of those connections.
SETTINGS tab
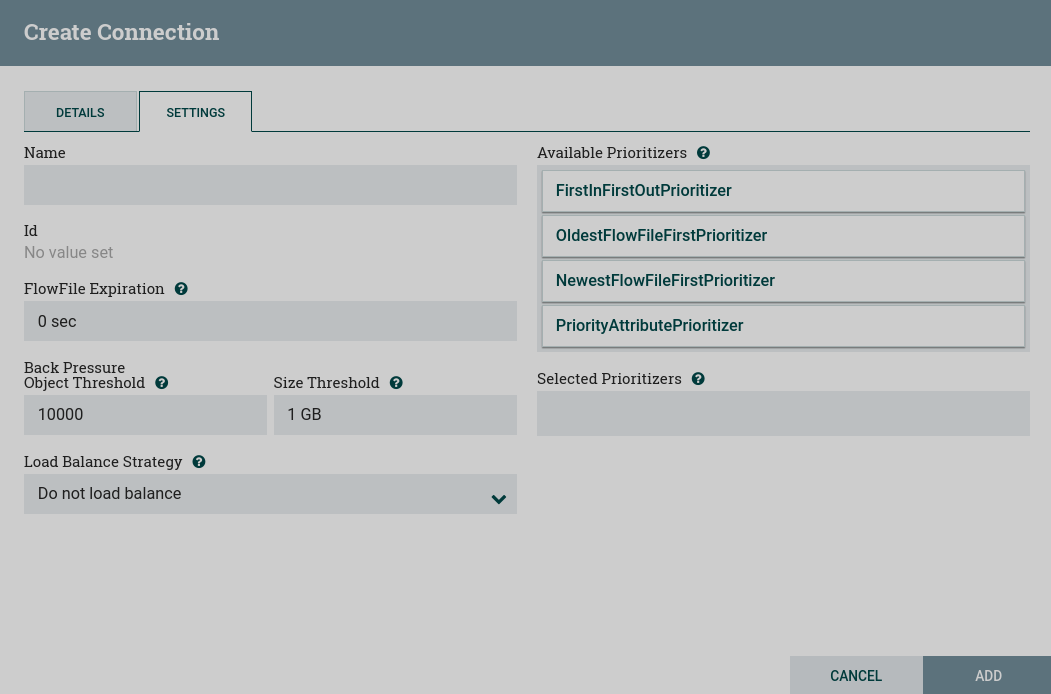
Name — connection name. Can be left blank.
FlowFile Expiration — the concept that data that cannot be processed in a timely manner can be automatically removed from the flow. This is useful, for example, when the amount of data is expected to exceed the amount that can be sent to the remote host.
Back Pressure — two configuration items for backpressure:
-
Object Threshold — number of FlowFiles that can be queued before being applied. The default value is
10,000. -
Size Threshold — the maximum amount of data (in size) that must be queued before backpressure is applied. The default value is
1 GB.
Load Balance Strategy — to distribute data in a stream across nodes in a cluster, NiFi offers the following load balancing strategies:
-
Do not load balance — do not load balance FlowFiles across nodes in the cluster. This is the default value.
-
Partition by attribute — determines which node to send this FlowFile to, based on the value of the user-specified FlowFile attribute. All FlowFiles with the same attribute value will be sent to the same node in the cluster. If the destination node is disconnected from the cluster or cannot communicate, no data is sent to the other node. The data will queue up, waiting for the node to become available again. Also, if a node joins or leaves the cluster, which requires the data to be rebalanced, consistent hashing is applied to avoid redistributing all data.
-
Round robin — FlowFiles will be distributed across the nodes in the cluster in a round robin fashion. If a node is disconnected from the cluster or cannot communicate with a node, data queued for that node will be automatically redistributed to other nodes. If a node cannot receive data as fast as other nodes in the cluster, that node may also be skipped for one or more iterations to maximize the throughput of data distribution across the cluster.
-
Single node — all FlowFiles will be sent to one node in the cluster. Which node they are sent to cannot be configured. If a node is disconnected from the cluster or cannot contact the node, data queued for that node will remain in the queue until the node becomes available again.
Prioritization — prioritize data in the queue so that data with a higher priority is processed first. Prioritizers can be dragged from the top (Available prioritizers) to the bottom (Selected prioritizers). You can select multiple priorities. The priority at the top of the Selected prioritizers list has the highest priority. If two FlowFiles have the same value according to this prioritizer, the second prioritizer will determine which FlowFile to process first, and so on. If a prioritizer is no longer needed, it can be dragged from the Selected prioritizers list to the Available prioritizers list.
The following priorities are available:
-
FirstInFirstOutPrioritizer — given two FlowFiles, the one that reaches the connection first will be processed first.
-
NewestFlowFileFirstPrioritizer — given two FlowFiles, the one that is the newest in the dataflow will be processed first.
-
OldestFlowFileFirstPrioritizer — given two FlowFiles, the one that is the oldest in the dataflow will be processed first. This is the default schema that is used if no priorities are selected.
-
PriorityAttributePrioritizer — given two FlowFiles, an attribute called
prioritywill be retrieved. The one with the lowest priority value will be processed first.
|
NOTE
For more information on configuring NiFi processor connections, see Connecting Components. |