

Репликация Hive Metastore с помощью SSM
SSM предоставляет механизм для репликации хранилищ Hive Metastore (HMS), расположенных в разных кластерах ADH. В данной статье описаны основные концепции, принцип работы, а также показан пошаговый пример репликации.
Под капотом HMS хранит все метаданные в реляционной БД. По умолчанию в ADH это база данных, предоставляемая сервисом ADPG. В этой БД хранятся метаданные о различных Hive-сущностях, таких как таблицы, партиции, функции и прочие. SSM поддерживает репликацию следующих сущностей Hive:
-
базы данных;
-
таблицы;
-
партиции;
-
функции;
-
ограничения (constraint) типа
PRIMARY KEY,FOREIGN KEY,UNIQUE,NOT NULL,DEFAULT,CHECK.
Прежде чем переходить к подробностям репликации, стоит упомянуть базовые концепции, на которых строится механизм репликации.
Репликация на основе событий
Механизм репликации в SSM реализован на основе событий Hive (Hive event), которые генерируются при изменении содержимого HMS.
События Hive
Событие Hive — это текстовая запись, которая отражает одну операцию над сущностью Hive, например, создание Hive-таблицы.
События Hive генерируются org.apache.hive.hcatalog.listener.DbNotificationListener при каждой операции, приводящей к изменению данных в HMS.
События Hive хранятся в таблице NOTIFICATION_LOG базы данных HMS.
Примеры событий:
NL_ID|EVENT_ID|EVENT_TIME|EVENT_TYPE |CAT_NAME|DB_NAME|TBL_NAME |MESSAGE |MESSAGE_FORMAT| -----+--------+----------+-------------------------+--------+-------+---------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------+ 12| 8|1771231855|CREATE_TABLE |hive |hr |employees|H4sIAAAAAAAAAL1WbU/bMBD+K1M+l7ROYYV+K23Q2DpATZAmrShymyv1cF7mOLBS9b/vbDejCS6DSUOqYvce3/l8fu7Oa6cAcQ/C6TtyKdhC9tvtO3pA42UM9wddV5QHc0iloJy4LJUgUsr7J53jrtPSmmwOV4Klc5ZTjjZQGs9wXAqcSTrjgH8gyXm2AigqWbjKldz/FvqTi8E4CgenY78CL2c/PhdZivh66pCp08ehkAIn0ydLU2fTmjpeHV0|gzip(json-2.0)| 13| 9|1771231928|ALTER_TABLE |hive |hr |employees|H4sIAAAAAAAAAO1WbW/aMBD+K1M+00BCO16+UUo1NlYmSKVJY4oMOcCr8zLbKaMV/31nO1lJGmg7adoXJBSbe7HP5+fu8aMlgN8Dt7qWXHO6lN16/Y6ckWAdwP1Z0+bp2QIiyQlzbBpJ4BFh3U6j3bRq2pMu4Aun0YImhOEaKA3mOK45ziSZM8A/ECYs3gKIXOZtEyUffPUGk5veyPd6l6NBrhzPf1zCMubwUcQRWj3OLGdmdXEQkuNk9rTezNr|gzip(json-2.0)| 14| 10|1771231928|INSERT |hive |hr |employees|H4sIAAAAAAAAAJ1WbW/aMBD+K1P6NYQktOPlGwWqdWNlglSatFSRIQd4dV7mOO0o4r/vbCctSUO3DqHYPM/d5Xy+F/ZGBvwBuDEwxJbTtRi02/ekRcJtCA+tjsXz1gpiwQlzLBoL4DFhg77d6xim0qQr+MZpvKIpYWgD0XCJ65bjTpAlA/wBUcqSHUBWYt4ulfjkuzeZ3wyngTe8nE5Kcrb8+TlLYuT3vuH4xgCXTHDc+C+WfONg+oZbZbdcw50|gzip(json-2.0)|
Обратите внимание на столбец MESSAGE — в нем хранится сериализованное сообщение с описанием, что именно произошло.
В этом сообщении содержится подробная информация о выполненной операции, например:
{
"eventType": "CREATE_TABLE",
"server": "thrift://metastore:9083",
"servicePrincipal": "hive/_HOST@REALM",
"db": "hr",
"table": "employees",
"timestamp": 1771231855,
"tableObj": {
"tableName": "employees",
"sd": {
"location": "hdfs://warehouse/hr.db/employees",
"inputFormat": "org.apache.hadoop.mapred.TextInputFormat",
"cols": [
{"name":"id","type":"int"},
{"name":"name","type":"string"}
]
}
}
}Анализируя события исходного HMS и выполняя соответствующие команды в правильном порядке в целевом HMS, SSM может воссоздать все необходимые Hive-сущности, на чем и построен механизм репликации.
SSM поддерживает репликацию событий следующих типов.
| Объект | Реплицируемые события |
|---|---|
База данных |
CREATE, DROP, ALTER |
Таблица |
CREATE, DROP, ALTER |
Партиция |
CREATE, DROP, ALTER |
Функция |
CREATE, DROP |
Ограничения (constraints) |
CREATE, DROP |
Hive Metastore fetcher
Hive Metastore fetcher — это внутренний процесс SSM, отвечающий за извлечение событий из Hive Metastore. При включенной репликации процесс запускается вместе с SSM, асинхронно извлекает события из исходного HMS и сохраняет их в базе данных. Затем SSM анализирует полученные события и выполняет соответствующие действия на стороне целевого HMS (создает таблицы, переименовывает столбцы и так далее). На следующей схеме представлен высокоуровневый процесс репликации.


Основные этапы репликации:
-
SSM-правило срабатывает и инициирует процесс репликации.
-
Hive Metastore fetcher извлекает снепшот Hive-событий из исходного HMS. В снепшот попадают все события, доступные в исходном HMS в данный момент времени.
-
Hive Metastore fetcher переходит в фазу прослушивания (listening phase) и подписывается на события Hive, чтобы получать информацию о событиях, происходящих после формирования снепшота.
-
SSM анализирует полученные события и для каждого отдельного события выполняет соответствующее действие в целевом HMS (например, создает новую Hive-таблицу).
-
После того как все события Hive обработаны, SSM продолжает работать в режиме прослушивания, периодически опрашивая исходный HMS на наличие новых событий, пока SSM-правило активно.
Как видно из процесса, SSM использует особый двухэтапный алгоритм для извлечения событий из Hive Metastore, который описан далее.
Получение событий. Фаза снепшота и прослушивания
При выполнении цикла репликации SSM считывает события из исходного HMS в два этапа:
-
Получение снепшота. В начале процесса репликации SSM извлекает снепшот с событиями Hive. В этот снепшот попадают все события, доступные в данный момент в HMS.
-
Прослушивание событий. Получив снепшот, SSM переходит в режим прослушивания, периодически опрашивая HMS на наличие новых событий.
|
ПРИМЕЧАНИЕ
Репликация HMS с помощью SSM предполагает, что база данных целевого HMS пуста, для избежания возможных конфликтов.
|
Включение репликации
Для включения механизма репликации HMS необходимо установить следующие параметры конфигурации в исходном ADH-кластере (из которого будут реплицироваться данные).
| Параметр | Значение | Локация |
|---|---|---|
Enable SmartFileSystem for Hadoop |
true |
Clusters → <source_ADH_cluster> → Services → SSM → Primary configuration |
smart.hive.event.fetch.enabled |
true |
Clusters → <source_ADH_cluster> → Services → SSM → Primary configuration → smart-site.xml |
hive.metastore.event.listeners |
org.apache.hive.hcatalog.listener.DbNotificationListener |
Clusters → <source_ADH_cluster> → Services → Hive → Primary configuration → Custom hive-site.xml |
hive.metastore.event.db.listener.timetolive |
86400s |
Clusters → <source_ADH_cluster> → Services → Hive → Primary configuration → Custom hive-site.xml |
|
РЕКОМЕНДАЦИЯ
Дополнительные параметры для настройки процесса репликации доступны в разделе smart-site.xml.
|
Для запуска процесса репликации используйте правило SSM с объектом hms и действием hms-sync, например:
hms: name matches "test_db.*" | hms-sync -dest thrift://ka-adh-1.ru-central1.internal:9083Более подробная информация о запуске процесса репликации приведена в примере ниже.
Пример
Следующий пример показывает, как реплицировать содержимое HMS из одного ADH-кластера в другой с помощью SSM. Данный сценарий может быть использован, например, при необходимости иметь резервный HMS, который включается в качестве варианта аварийного восстановления (disaster recovery), если основной HMS выходит из строя.
В примере используются два тестовых кластера ADH. В обоих кластерах установлен сервис Hive, а в исходном кластере дополнительно установлен сервис SSM.
-
В исходном кластере включите механизм репликации HMS. После установки конфигурационных параметров перезапустите сервисы Hive и SSM.
-
В исходном кластере на хосте с компонентом Hive Client запустите /bin/beeline и создайте тестовую Hive-таблицу:
CREATE DATABASE test_db; CREATE TABLE test_db.t1 (i int); INSERT INTO test_db.t1 VALUES (1), (2), (3);При выполнении этих операций Hive сгенерирует несколько событий в HMS.
-
Откройте SSM UI. Актуальный URL доступен в ADCM (Clusters → <source_ADH_cluster> → Services → SSM → Info).
-
На странице Rules создайте новое правило:
hms : name matches "test_db.*" | hms-sync -dest thrift://ka-adh2-3.ru-central1.internal:9083 -cascade -nameservice_rename "adh1 adh2"где:
-
name matches "test_db.*"— правило для репликации всех сущностей из базы данных Hivetest_db. -
-dest thrift://ka-adh2-3.ru-central1.internal:9083— адрес целевого HMS. Thrift-адрес HMS можно найти в разделе настроек hive-site.xml сервиса Hive (включите опцию Advanced). -
-cascade— указывает, следует ли выполнять каскадное удаление родительских сущностей при репликации событий типаDROP. -
-nameservice_rename "adh1 adh2"— переименовывает значения HDFS nameservice при репликации сущностей (параметрdfs.internal.nameservicesсервиса HDFS).
-
-
Запустите правило.
-
Подождите несколько секунд, а затем проверьте страницу Actions. Страница отображает действия, выполненные SSM-агентом для репликации операций
CREATE/INSERTнад тестовой Hive-таблицей.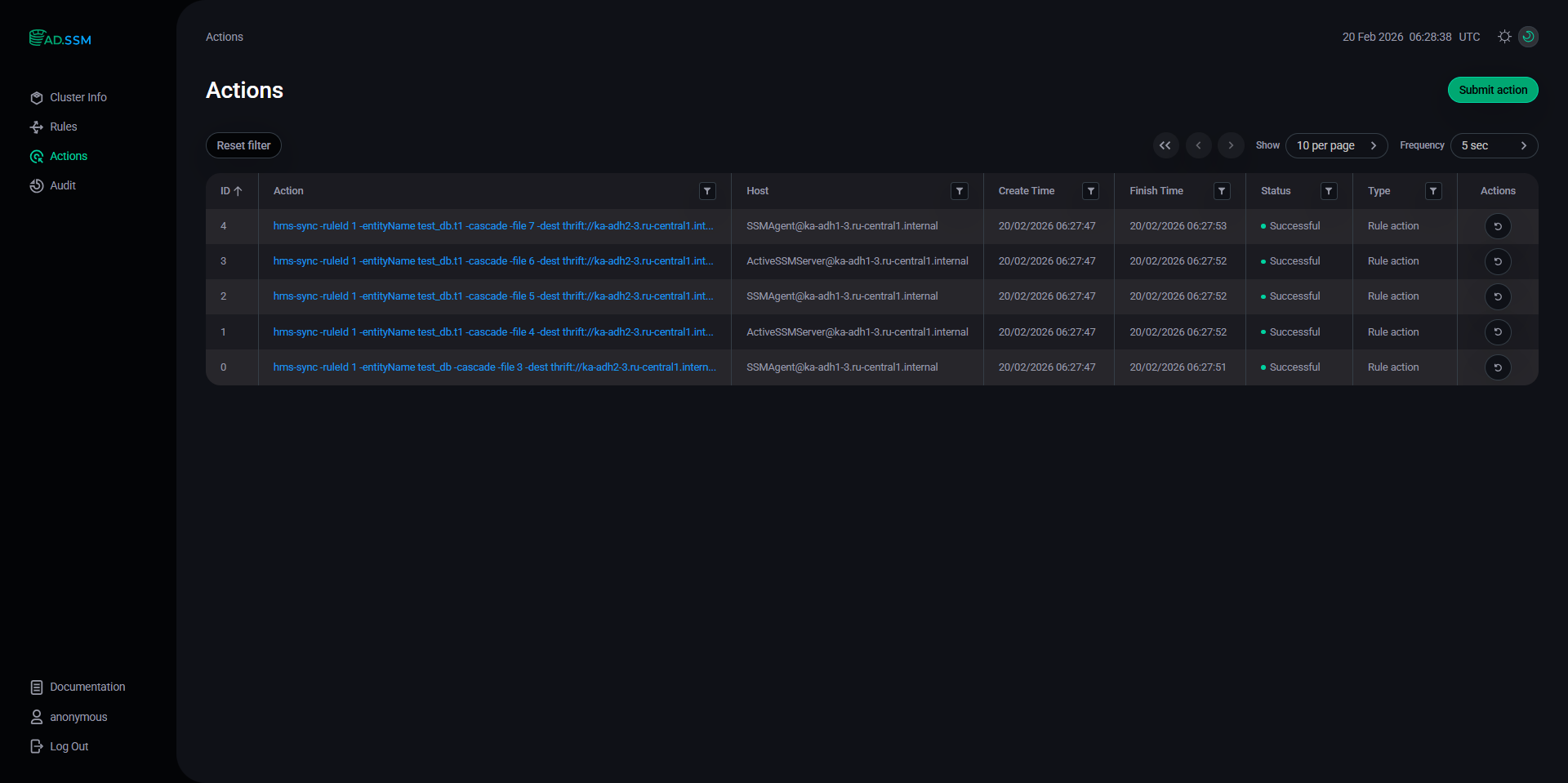 Страница Actions
Страница Actions -
В целевом кластере запустите /bin/beeline и проверьте реплицированную таблицу Hive:
SHOW DATABASES; SHOW TABLES IN test_db;Тестовые база данных/таблица успешно реплицированы в целевой HMS:
SHOW DATABASES; +----------------+ | database_name | +----------------+ | default | | test_db | +----------------+ SHOW TABLES in test_db; +-----------+ | tab_name | +-----------+ | t1 | +-----------+
-
В целевом кластере выполните команду
DESCRIBEдля реплицированной таблицы:DESCRIBE EXTENDED test_db.t1;Вывод:
+-----------------------------+----------------------------------------------------+----------+ | col_name | data_type | comment | +-----------------------------+----------------------------------------------------+----------+ | i | int | | | | NULL | NULL | | Detailed Table Information | Table(tableName:t1, dbName:test_db, owner:hive, createTime:1771568872, lastAccessTime:0, retention:0, sd:StorageDescriptor(cols:[FieldSchema(name:i, type:int, comment:null)], location:hdfs://adh2/apps/hive/warehouse/test_db.db/t1, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format=1}), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[], parameters:{external.table.purge=TRUE, totalSize=0, numRows=1, rawDataSize=1, EXTERNAL=TRUE, COLUMN_STATS_ACCURATE={\"COLUMN_STATS\":{\"i\":\"true\"}}, numFiles=0, transient_lastDdlTime=1771566711, TRANSLATED_TO_EXTERNAL=TRUE, bucketing_version=2, numFilesErasureCoded=0}, viewOriginalText:null, viewExpandedText:null, tableType:EXTERNAL_TABLE, rewriteEnabled:false, catName:hive, ownerType:USER, writeId:0, accessType:8, id:11) | | +-----------------------------+----------------------------------------------------+----------+Обратите внимание на строку
location:hdfs://adh2/apps/hive/…. С помощью параметра-nameservice_rename "adh1 adh2"в SSM-правиле значение nameserviceadh1было переименовано вadh2при репликации. -
Пока SSM-правило активно, SSM постоянно опрашивает исходный HMS на наличие новых событий и реплицирует их, если таковые имеются. В исходном кластере удалите тестовую таблицу:
DROP TABLE test_db.t1; -
В целевом кластере проверьте, что операция
DROP TABLEбыла реплицирована, а соответствующая таблица удалена:SHOW TABLES in test_db;Вывод:
+-----------+ | tab_name | +-----------+ +-----------+