

ADP high availability overview
|
NOTE
The high availability (HA) feature is available for ADP Enterprise Edition.
|
Database servers can work together to be able to switch quickly to another server in case of a primary server failure. This behavior is called high availability (HA). ADP uses Patroni to build the cluster based on the PostgreSQL streaming replication and implement HA. An ADP cluster that supports HA should contain several ADP nodes.
Each node consists of a PostgreSQL server and a Patroni agent that serves the local PostgreSQL instance. One ADP node is the leader, others are replica instances. The leader serves read-write transactions (unless otherwise specified in load balancing settings), and replicas process only read-only requests. PostgreSQL streaming replication is a method that transfers WAL records from a leader to replicas. In case of the leader failure, Patroni elects a new leader from replicas and the ADP cluster continues to operate.


The Patroni settings available from ADCM are described in Configuration settings.
The Info tab of the ADPG service displays the names of the Patroni cluster members, as well as links: Postgres JDBC URL, Patroni REST API, and PgBouncer JDBC URL.
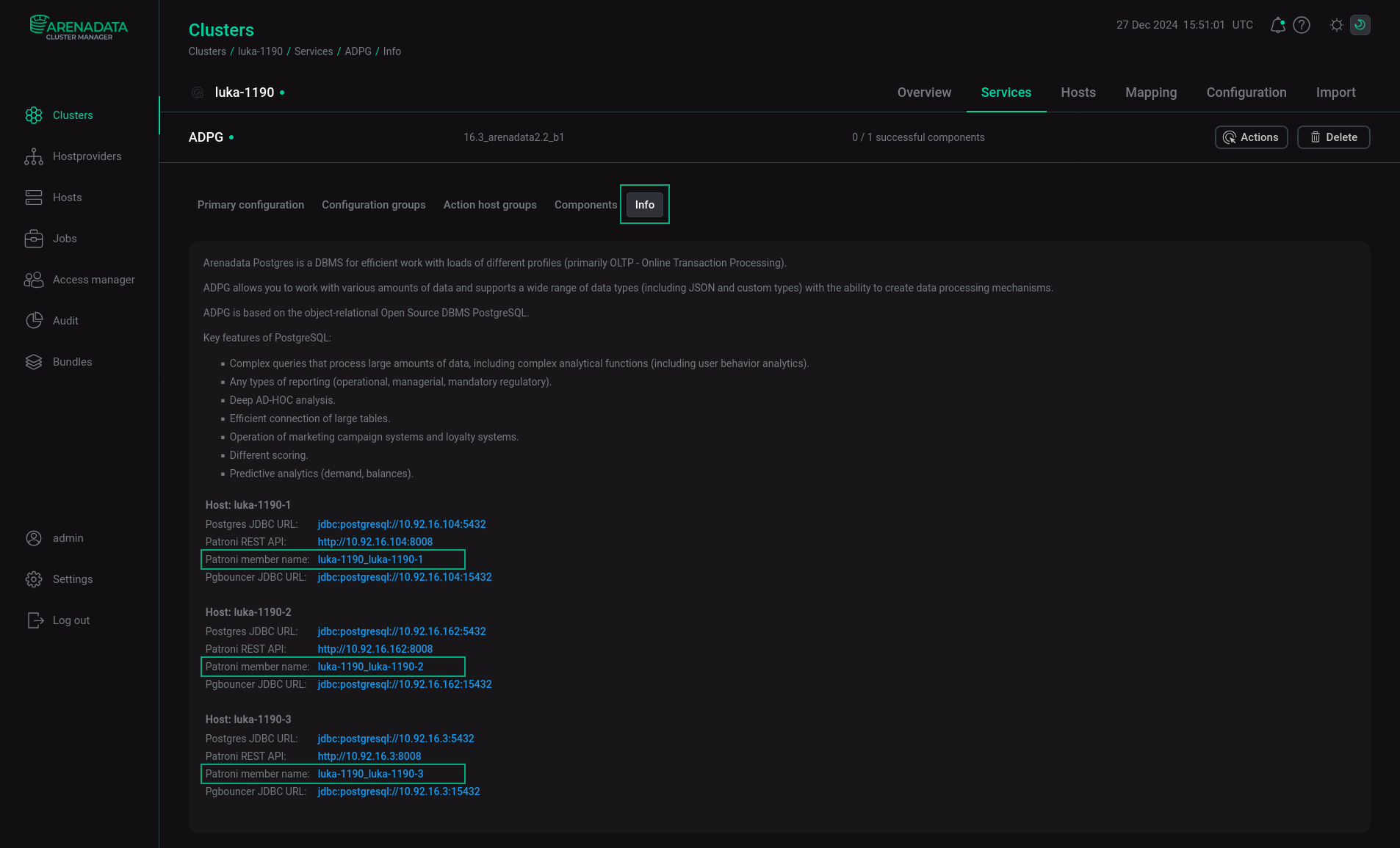
You can enable Patroni basic auth for Patroni REST API. To do this, activate the Enable Patroni basic auth toggle button in the ADPG service configuration settings and run the Reconfigure & Restart action of the ADPG service.
After enabling Patroni basic auth, unsafe (POST) calls to Patroni are authenticated, but safe (GET) calls will be processed without authentication. Examples:
Auth is disabled, no password is required:
$ curl -X POST http://10.92.43.184:8008/reloadreload scheduled
Auth is enabled, no password is specified:
$ curl -X POST http://10.92.43.184:8008/reloadno auth header received
Auth is enabled, the password is incorrect:
$ curl -X POST -u "admin:wrongpassword" http://10.92.43.184:8008/reloadnot authenticatedpostgres
Auth is enabled, the password is correct:
$ curl -X POST -u "admin:12345678" http://10.92.43.184:8008/reloadreload scheduled
Replication modes
The streaming replication has two modes: the asynchronous mode, which is used by default, and the synchronous mode.
Asynchronous mode
In asynchronous mode, a leader executes requests immediately, while changes from WAL are transmitted to replicas separately. If the leader crashes, uncommitted transactions may not be replicated, causing data loss.
The maximum_lag_on_failover parameter sets the amount of transaction log that can be lost in bytes. Exceeding this parameter does not affect the asynchronous replication process, but replicas with a lag greater than maximum_lag_on_failover do not participate in the leader election. You can change maximum_lag_on_failover on the Primary configuration tab of the ADPG service. To specify it, open Clusters → ADP cluster → Services → ADPG → Primary configuration as described in Configure services and expand the Patroni ADPG configurations node, which contains Patroni settings.
The amount of lost data can be greater. In the worst case, it can be calculated as maximum_lag_on_failover bytes of the transaction log plus the amount that is written in the last ttl seconds. However, a typical replication delay is less than a second.
If the leader fails or becomes unavailable for any other reason, Patroni automatically promotes a replica to the leader. After this operation, it is impossible to recover any not replicated transactions.
The advantage of the asynchronous replication mode is the fast transaction commit, you do not need to wait for all replicas to apply the changes.
Synchronous mode
The synchronous replication ensures that all changes made by a transaction are transferred to one or more replica nodes. Each commit of a write transaction waits for a confirmation that the commit is written to WAL on the disk of the leader and replica hosts. The synchronous replication provides a higher level of durability, but it also increases the response time for the requesting transaction. The minimum wait time is the round-trip time between a leader and a replica.
The following transactions do not wait for a response from replicas:
-
read-only transactions;
-
transaction rollbacks;
-
subtransaction commits.
Long-running actions such as data loading or index building do not wait for the final commit message.
To turn on Patroni synchronous mode, select the synchronous_mode checkbox on the Primary configuration tab of the ADPG service. To do this, open Clusters → ADP cluster → Services → ADPG → Primary configuration as described in Configure services.
In this mode, Patroni can promote a replica only if the replica contains all transactions that returned a successful commit status to a client. However, Patroni synchronous mode does not guarantee that commits will be stored on multiple nodes under all circumstances. When no suitable replica is available, the leader still provides write access but does not guarantee replication. If the leader fails, no replica is promoted. When the host that used to be the leader comes back, Patroni promotes it to the leader automatically, unless a system administrator changes the leader manually. This behavior allows you to use the synchronous mode with clusters that consist of two ADP nodes.
If a replica crashes, commits are blocked until Patroni runs and switches the leader to standalone mode. In the worst case, the delay is ttl seconds. Manually shutting down or restarting a replica does not cause a commit service interruption. The replica signals the leader to release itself from synchronization before the PostgreSQL shutdown.
To guarantee that each record is stored on at least two nodes, enable synchronous_mode_strict in addition to synchronous_mode. You can enable this option on the Primary configuration tab of the ADPG service. This parameter prevents Patroni from switching off the synchronous replication on the leader when no replicas are available. As a result, the leader does not provide write access and blocks all client write requests until at least one replica becomes available.
|
NOTE
Because of the way synchronous replication is implemented in PostgreSQL it is still possible to lose transactions even when the synchronous_mode_strict is used. If the PostgreSQL backend is canceled while waiting to acknowledge a replication (as a result of a packet cancellation due to client timeout or backend failure) transaction changes become visible for other backends. Such changes are not yet replicated and may be lost in case of replica promotion.
|
Patroni uses the synchronous_node_count parameter to manage the number of synchronous standby databases. Its default value is 1. This parameter has no effect when synchronous_mode is disabled. When synchronous_mode is enabled, Patroni manages the precise number of synchronous standby databases based on synchronous_node_count. For details, see Replication modes.
You can store Patroni log files to a custom directory. To set up custom logging, open the Clusters → ADP cluster → Services → ADPG → Primary configuration tab, activate the Show advanced toggle button, and expand the Patroni ADPG configurations node. Set the use_custom_patroni_log_dir parameter to true and specify a path to a custom directory.
The etcd cluster
Patroni saves the cluster configuration in the Distributed Configuration Storage (DCS). ADP requires an etcd cluster to use it as Patroni DCS. The listen_peer_urls_port and listen_client_urls_port etcd settings must be specified during installation, after installation they cannot be changed.
You can use the built-in ADP Etcd service or an external etcd cluster. If you wish to utilize the built-in Etcd service, refer to the Add services article that describes how to add services. You must use an odd number of nodes for the Etcd service. Three or more nodes are recommended. Nodes for Etcd must not contain the ADPG service. Note, after you add nodes to expand the working Etcd service, it is necessary to execute the Reconfigure & Restart action of the ADPG and Balancer services.
Etcd keeps the whole log on the disk until the compaction procedure is performed. This may result in the lack of the disk space. To avoid this problem, the autocompaction is enabled in ADP. The default Autocompaction mode value is periodic, Autocompaction retention — 10h. The max number of bytes the etcd db file can consume (the Space quota parameter) is set to 2147483648 bytes. You can change these settings on the Clusters → ADP cluster → Services → Etcd → Primary configuration page.
The defragmentation of the disk space is required to return the disk space from the etcd backend to the host file system. It is recommended to schedule the defragmentation (e.g. with cron). Note, that the defragmentation blocks the cluster nodes, and they become unavailable.
The defragmentation command for the whole cluster (it blocks the whole cluster for a period of time):
$ etcdctl defrag --clusterFor the local node (it blocks only the local node for a period of time):
$ etcdctl defragIf SSL is enabled:
$ /usr/lib/adpg16/usr/bin/etcdctl defrag --cluster --cacert="/etc/adpg/ssl/etcd/ca.crt" \
--cert="/etc/adpg/ssl/etcd/client.crt" --key="/etc/adpg/ssl/etcd/client.key"If you want to use an external etcd cluster, set external Etcd settings on the Primary configuration tab of the ADPG service. To specify them, open Clusters → ADP cluster → Services → ADPG → Primary configuration as described in Configure services.
|
TIP
You can use the Expand action to add new nodes to the ADP cluster and built-in Etcd service.
|