

Обзор отказоустойчивости ADP
|
ПРИМЕЧАНИЕ
Функционал, поддерживающий отказоустойчивость (High Availability, HA), реализован в версии ADP Enterprise.
|
Серверы базы данных могут работать совместно для обеспечения возможности быстрого переключения на другой сервер в случае отказа основного. Такое поведение называется отказоустойчивостью (High Availability, HA). ADP использует Patroni для создания кластера на основе потоковой репликации PostgreSQL и реализации отказоустойчивости. Кластер ADP, поддерживающий HA, должен содержать несколько нод ADP.
Каждая нода содержит сервер PostgreSQL и агент Patroni, обслуживающий локальный экземпляр PostgreSQL. Одна нода ADP является лидером, остальные — репликами. Лидер обслуживает транзакции на чтение и запись (read-write), если иное не указано в настройках сервиса балансировки, а реплики только запросы на чтение (read-only). Потоковая репликация PostgreSQL — это метод, при котором записи WAL передаются от лидера к репликам. В случае отказа лидера Patroni выбирает нового лидера из реплик и кластер ADP продолжает работу.


Параметры Patroni, доступные из ADCM, описаны в статье Конфигурационные параметры.
Вкладка Info сервиса ADPG отображает имена членов кластера Patroni, а также ссылки: Postgres JDBC URL, Patroni REST API и PgBouncer JDBC URL.
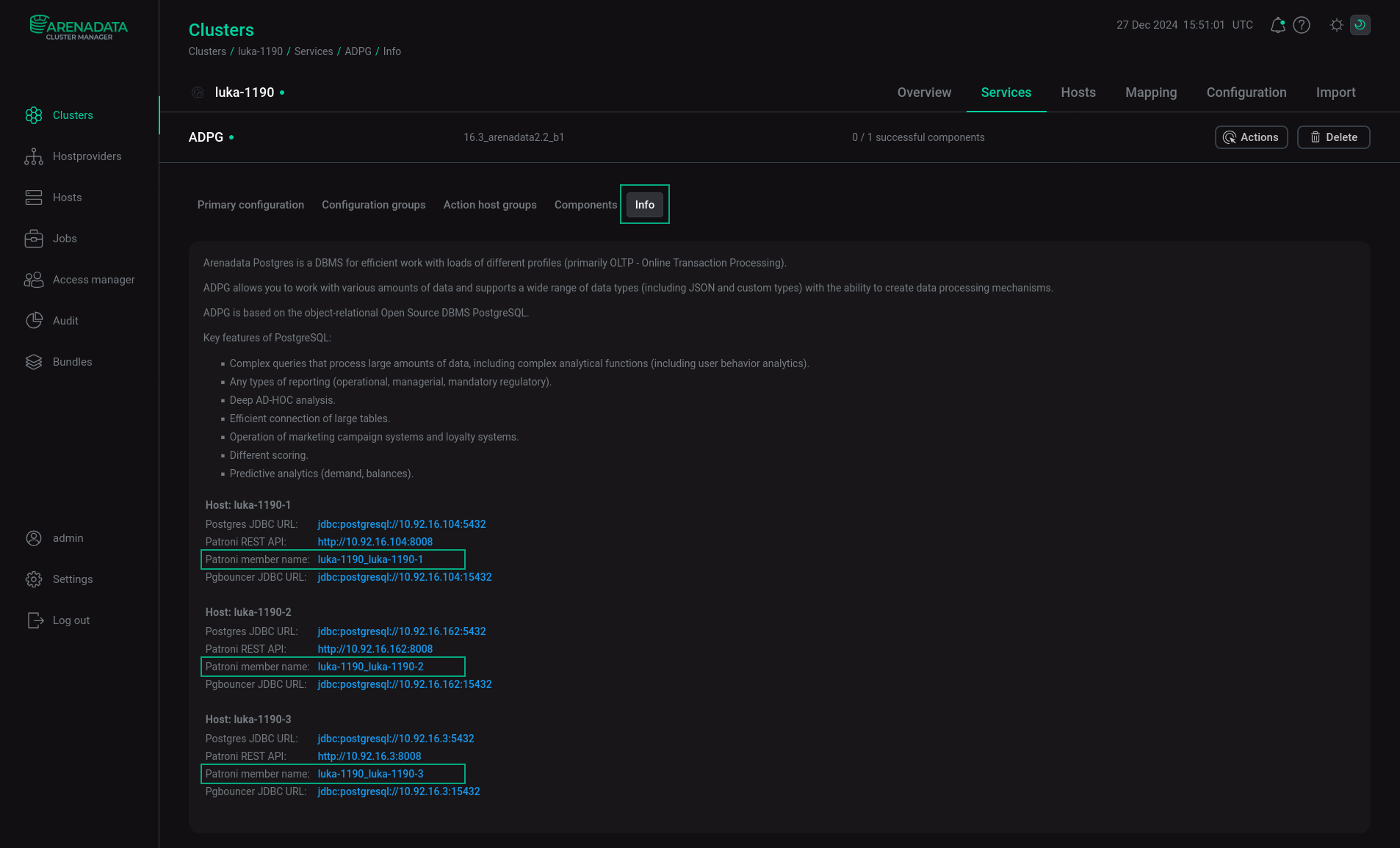
Можно включить базовую аутентификацию Patroni (Patroni basic auth) для Patroni REST API, активировав переключатель Enable Patroni basic auth в конфигурационных настройках сервиса ADPG и выполнив действие сервиса ADPG Reconfigure & Restart.
После включения Patroni Basic auth для небезопасных (POST) вызовов Patroni необходима аутентификация, но безопасные (GET) вызовы будут обрабатываться без нее. Примеры:
Аутентификация выключена, пароль не требуется:
$ curl -X POST http://10.92.43.184:8008/reloadreload scheduled
Аутентификация включена, пароль не указан:
$ curl -X POST http://10.92.43.184:8008/reloadno auth header received
Аутентификация включена, указан некорректный пароль:
$ curl -X POST -u "admin:wrongpassword" http://10.92.43.184:8008/reloadnot authenticatedpostgres
Аутентификация включена, передан корректный пароль:
$ curl -X POST -u "admin:12345678" http://10.92.43.184:8008/reloadreload scheduled
Режимы репликации
Потоковая репликация имеет два режима: асинхронный режим, который используется по умолчанию, и синхронный режим.
Асинхронный режим
В асинхронном режиме лидер выполняет запросы сразу, а изменения из журнала WAL передаются на реплики отдельно. В случае сбоя лидера незавершенные транзакции могут не успеть реплицироваться, что приведет к потере данных.
Параметр maximum_lag_on_failover определяет количество данных журнала транзакций, которые могут быть потеряны в байтах. Превышение этого параметра не влияет на процесс асинхронной репликации, но реплики, у которых отставание больше чем maximum_lag_on_failover, не участвуют в выборах лидера. Параметр maximum_lag_on_failover можно изменить на вкладке Primary configuration сервиса ADPG. Чтобы это сделать, откройте Clusters → Кластер ADP → Services → ADPG → Primary configuration, как описано в статье Настройка сервисов и раскройте ноду Patroni ADPG configurations, содержащую настройки Patroni.
На самом деле количество потерянных данных может быть больше. Для худшего случая его можно рассчитать как сумму maximum_lag_on_failover байт журнала транзакций и количества данных, которые были записаны в последние ttl секунд. Однако типичная задержка репликации составляет менее секунды.
Если лидер выходит из строя или становится недоступным по любой другой причине, Patroni автоматически промоутит реплику до лидера. После этой операции невозможно восстановить транзакции, которые не были реплицированы.
Преимущество асинхронного режима репликации — быстрое подтверждение транзакций, не нужно ждать пока все реплики применят изменения.
Синхронный режим
Синхронная репликация гарантирует, что все изменения, сделанные транзакцией, переносятся на одну или несколько реплик. Каждый коммит транзакции записи ожидает подтверждения того, что коммит записан в WAL на диске ноды лидера и ноды реплики. Синхронная репликация обеспечивает более высокий уровень отказоустойчивости, но также увеличивает время отклика для запрашивающей транзакции. Минимальное время ожидания — это время обмена данными между лидером и репликой.
Следующие транзакции не ждут ответа от реплик:
-
транзакции, выполняющие операции только на чтение;
-
откаты транзакций (rollbacks);
-
коммиты подтранзакций.
Длительные действия, такие как загрузка данных или построение индекса, не ждут окончательного коммит-сообщения.
Чтобы включить синхронный режим Patroni, активируйте флажок synchronous_mode на вкладке Primary configuration сервиса ADPG. Для этого откройте Clusters → Кластер ADP → Services → ADPG → Primary configuration, как описано в Настройка сервисов.
В этом режиме Patroni может запромоутить до лидера только те реплики, которые содержат все транзакции, вернувшие клиенту статус успешного коммита. Однако синхронный режим Patroni не гарантирует, что коммиты будут храниться на нескольких нодах при любых обстоятельствах. Когда подходящая реплика недоступна, лидер по-прежнему предоставляет доступ для записи, но не гарантирует репликацию. Если лидер выходит из строя, никакая другая реплика не становится лидером. Когда нода, которая раньше была лидером, становится снова доступной для Patroni, он автоматически делает её лидером, если системный администратор не выполнил переключение лидера вручную. Такое поведение позволяет использовать синхронный режим в кластерах, состоящих из двух ADP-нод.
В случае сбоя реплики коммиты блокируются до тех пор, пока Patroni не запустится и не переключит лидера в автономный режим. В худшем случае задержка составляет ttl секунд. Выключение или перезапуск реплики вручную не приводит к нарушению работы сервиса репликации коммитов. Реплика передает сигнал лидеру о необходимости освободить её от синхронизации, до того как PostgreSQL завершит работу.
Чтобы гарантировать, что каждая запись хранится как минимум на двух нодах, включите режим synchronous_mode_strict в дополнение к synchronous_mode. Вы можете активировать эту опцию на вкладке Primary configuration сервиса ADPG. Этот параметр запрещает Patroni отключать синхронную репликацию на лидере, когда реплики недоступны. В результате лидер перестает предоставлять доступ на запись и блокирует все клиентские запросы на запись до тех пор, пока хотя бы одна реплика не станет доступной.
|
ПРИМЕЧАНИЕ
Из-за того, как синхронная репликация реализована в PostgreSQL, по-прежнему возможна потеря транзакций, даже если используется synchronous_mode_strict. Если операции на сервере PostgreSQL отменяются во время ожидания подтверждения репликации (в результате пакетной отмены из-за превышения тайм-аута или сбоя сервера), изменения транзакций становятся видимыми для других серверов. Такие изменения еще не реплицируются и могут быть потеряны в случае смены лидера.
|
Patroni использует параметр synchronous_node_count для управления количеством синхронных резервных баз данных. Его значение по умолчанию равно 1. Этот параметр не применяется, когда synchronous_mode отключен. Если включен режим synchronous_mode, Patroni управляет точным количеством синхронных резервных баз данных на основе synchronous_node_count. За дополнительной информацией обратитесь к статье Replication modes.
Можно хранить файлы логов Patroni в произвольной директории. Для того, чтобы настроить кастомное логирование, откройте вкладку Clusters → Кластер ADP → Services → ADPG → Primary configuration, активируйте переключатель Show advanced и разверните ноду Patroni ADPG Configurations. Установите для параметра use_custom_patroni_log_dir значение true и укажите путь к директории.
Кластер etcd
Patroni сохраняет конфигурацию кластера в распределенном хранилище конфигурации (Distributed Configuration Storage, DCS). ADP требует наличия кластер etcd, чтобы использовать его в качестве DCS для Patroni. Настройки etcd listen_peer_urls_port и listen_client_urls_port необходимо указать при установке, после установки их изменить нельзя.
Вы можете использовать встроенный ADPG-сервис Etcd или внешний кластер etcd. Если вы хотите использовать встроенный сервис Etcd, обратитесь к статье Добавление сервисов, в которой описывается, как добавить Etcd-сервис. Для Etcd необходимо нечетное количество нод. Рекомендуется использовать три или более ноды. На нодах с Etcd не должно быть ADPG-сервиса. Обратите внимание, что после добавления нод для расширения уже работающего сервиса Etcd необходимо выполнить действие Reconfigure & Restart сервисов ADPG и Balancer.
Etcd сохраняет весь лог на диске до тех пор, пока не будет выполнена процедура сжатия, что может привести к нехватке места. Чтобы избежать этой проблемы, в ADP включено автосжатие. Значением по умолчанию Autocompaction mode является periodic, а Autocompaction retention — 10h. Максимальное количество байт, которое может использовать файл базы данных etcd (параметр Space quota), установлено в 2147483648 байт. Вы можете изменить эти настройки на странице Clusters → Кластер ADP → Services → Etcd → Primary configuration.
Для возврата дискового пространства от etcd в файловую систему хоста необходима дефрагментация. Рекомендуется выполнять дефрагментацию по расписанию (например, с помощью cron). Обратите внимание, что при дефрагментации ноды кластера блокируются и становятся недоступными.
Команда дефрагментации всего кластера (блокирует весь кластер на некоторое время):
$ etcdctl defrag --clusterДля локальной ноды (на определенный период блокируется только локальная нода):
$ etcdctl defragЕсли включен SSL:
$ /usr/lib/adpg16/usr/bin/etcdctl defrag --cluster --cacert="/etc/adpg/ssl/etcd/ca.crt" \
--cert="/etc/adpg/ssl/etcd/client.crt" --key="/etc/adpg/ssl/etcd/client.key"Если вы хотите использовать внешний кластер etcd, установите настройки внешнего etcd на вкладке Primary configuration сервиса ADPG. Чтобы указать их, откройте Clusters → Кластер ADP → Services → ADPG → Primary configuration, как описано в статье Configure services.
|
РЕКОМЕНДАЦИЯ
Вы можете использовать действие Expand для добавления новых нод в кластер ADP и встроенный Etcd-сервис.
|