

Use TTL to manage data
Overview
For MergeTree tables, it is possible to set TTL (time-to-live) — time interval after which old data will be deleted from a table in the background. TTL can be set for a whole table (entire data rows with outdated values will be deleted) and for each individual column (outdated values in a column will be replaced with default values for the column data type).
Table-level TTL also allows you to schedule the following actions to be performed automatically on expired data rows:
-
Move data between disks or volumes of an ADQM storage — this can be useful when you deploy an architecture to separate data into "hot", "warm", and "cold" (see Configure data storages).
-
Rollup data into some aggregations and computations — you can store old data with a lower level of detail to save resources.
-
Apply a higher level of compression to old data.
Thus, you can optimize a storage and improve query performance by managing your data lifecycle with the TTL mechanism.
When TTL events are triggered
ADQM deletes data with expired TTL when merging data parts (not immediately). It periodically performs "off-schedule" merges to delete or compress data according to TTL rules. You can control the frequency of such merges with the special parameters of a MergeTree table:
-
merge_with_ttl_timeout— minimum delay in seconds between merges to delete data based TTL; -
merge_with_recompression_ttl_timeout— minimum delay in seconds between merges for data compression based on TTL.
By default, these parameters are set to 14400 seconds. This means that deletion/compression of outdated data will be performed every 4 hours or when a background merge of data parts occurs. If you want TTL rules to apply more frequently, change the corresponding setting above for your table. Note that too low value can lead to performing many "off-schedule" merges and consuming a lot of server resources — so it is not recommended to use values smaller than 300 seconds.
A MergeTree table also has the ttl_only_drop_parts setting that affects the expired data deletion as follows (depending on this parameter value):
-
0(default) — ADQM deletes only rows expired according to their TTL; -
1— ADQM deletes a whole data part when all rows in it are expired.
Deleting whole parts instead of individual rows allows you to set a smaller merge_with_ttl_timeout timeout and reduce the impact of TTL operations on system performance.
Operations of moving data between disks/volumes or recompressing data are performed only when all rows in a data part are out of date.
When you run a SELECT query between merges, you can get expired data in a table. To avoid this, run the OPTIMIZE … FINAL query before selecting (to force merging). However, it is not recommended to use it frequently, especially for large tables.
Table TTL
Create a table with TTL
To set TTL for a table when creating it, use the TTL clause at the end of the table definition in the CREATE TABLE query. After the TTL clause, you can specify one rule to delete expired rows and/or multiple TTL rules to process data in a different way (for example, to move data to another disk/volume or recompress it).
Below is the basic syntax of a query for creating a table with TTL:
CREATE TABLE <table_name>
( <timestamp_column> Date|DateTime ...,
<column1> ...,
<column2> ...,
...)
ENGINE = MergeTree()
TTL <ttl_expr> [<ttl_action>] [, <ttl_expr2> [<ttl_action2>]] [, ...];where each TTL rule includes:
-
<ttl_expr>— TTL expression that specifies when data to be considered outdated; -
<ttl_action>— action to be performed after the time specified by the TTL expression has passed.
A TTL expression that should return a value of the Date or DateTime type is usually specified in the following format:
<timestamp_column> [+ INTERVAL <time_interval> <interval_type>]where:
-
<timestamp_column>— name of a column of the Date or DateTime type with timestamps relative to which a time to live of data will be determined; -
INTERVAL <time_interval> <interval_type>— value of the Interval type that describes how long a data row should live, relative to the timestamp from the<timestamp_column>column. The structure of this value includes a time interval as a positive integer value and an interval type — for example,1 MONTH,3 DAY,5 HOUR.
To specify a time interval, you can use the toInterval conversion function instead of the INTERVAL operator. In this case, an example of a TTL expression can look like one of the following:
<timestamp_column> toIntervalMonth(1)
<timestamp_column> toIntervalDay(3)
<timestamp_column> toIntervalHour(5)To specify actions to be performed on data rows that have expired according to their TTL expressions, use clauses listed in the table below.
| Clause | Basic TTL syntax | Action description |
|---|---|---|
DELETE |
|
Delete expired data rows. This is the default action (in other words, expired rows are removed if another action is not specified explicitly after the |
TO DISK |
|
Move data to the specified disk |
TO VOLUME |
|
Move data to the specified volume |
RECOMPRESS |
|
Compress data using the specified codec |
GROUP BY |
|
Aggregate data. When defining a rule for aggregating old data, take into account the following points:
|
For the DELETE or GROUP BY action, you can specify a filtering condition with the WHERE clause to delete/aggregate only some of the expired rows. For moving and compressing data, the WHERE clause is not applicable.
Modify TTL
You can change TTL of an existing table using the following query:
ALTER TABLE <table_name> MODIFY TTL <new_ttl_rules>;After this query execution, each time new data is inserted or a new data part is created as a result of a background merge operation, TTL will be calculated according to a new rule.
To recalculate TTL for existing data, TTL materialization is required. The materialize_ttl_after_modify setting (enabled by default) controls whether TTL materialization should be performed automatically after the ALTER TABLE … MODIFY TTL query execution. You can also force TTL materialization with the following query:
ALTER TABLE <table_name> MATERIALIZE TTL;TTL materialization can be a quite heavy operation (especially for large tables), as it recalculates TTL in all data parts (updates ttl.txt files) and rewrites data for all columns, which can result in a lot of read/write operations. To facilitate the TTL materialization operation, you can set materialize_ttl_recalculate_only = 1 in the MergeTree table settings. In this case, only ttl.txt recalculation will be performed (it is a lightweight operation as only columns used in the TTL expression are read) and all columns will be copied via hard links. Some time later, expired data will be deleted during merge with ttl_only_drop_parts = 1.
In some cases, an optimal solution can be to disable TTL materialization (materialize_ttl_after_modify = 0) and delete/move old partitions manually (using the ALTER TABLE … DROP|MOVE PARTITION queries — see Manipulate partitions and data parts for details).
Examples
-
Create a table with a TTL rule to remove rows that will be considered outdated when 10 minutes have passed since the time in the
timecolumn:CREATE TABLE test_table (time DateTime, value UInt64) ENGINE = MergeTree ORDER BY time TTL time + INTERVAL 10 MINUTE;Fill the table with test data:
INSERT INTO test_table SELECT now() - toIntervalMinute(number), number FROM numbers(10);SELECT * FROM test_table;┌────────────────time─┬─value─┐ 1. │ 2024-06-07 13:15:49 │ 9 │ 2. │ 2024-06-07 13:16:49 │ 8 │ 3. │ 2024-06-07 13:17:49 │ 7 │ 4. │ 2024-06-07 13:18:49 │ 6 │ 5. │ 2024-06-07 13:19:49 │ 5 │ 6. │ 2024-06-07 13:20:49 │ 4 │ 7. │ 2024-06-07 13:21:49 │ 3 │ 8. │ 2024-06-07 13:22:49 │ 2 │ 9. │ 2024-06-07 13:23:49 │ 1 │ 10. │ 2024-06-07 13:24:49 │ 0 │ └─────────────────────┴───────┘ -
Wait for 5 minutes after inserting data and run the query:
OPTIMIZE TABLE test_table FINAL;Repeat the query to select data from the table:
SELECT * FROM test_table;You can see that the first five rows have been removed from the table (for each row, 10 minutes have passed since the time specified in the
timecolumn):┌────────────────time─┬─value─┐ 1. │ 2024-06-07 13:20:49 │ 4 │ 2. │ 2024-06-07 13:21:49 │ 3 │ 3. │ 2024-06-07 13:22:49 │ 2 │ 4. │ 2024-06-07 13:23:49 │ 1 │ 5. │ 2024-06-07 13:24:49 │ 0 │ └─────────────────────┴───────┘
If you do not use the
OPTIMIZE TABLE … FINALquery and runSELECTbetween merges, outdated records can still exist in the table.
-
Create the
alertstable and define a TTL rule to remove rows with theCriticalvalue in thealertcolumn and a time value in thetimecolumn after which 10 minutes have passed:CREATE TABLE alerts (time DateTime, value UInt64, alert String) ENGINE = MergeTree ORDER BY time TTL time + INTERVAL 10 MINUTE DELETE WHERE alert = 'Critical';Insert test data into the table:
INSERT INTO alerts SELECT now() - toIntervalMinute(number), number, ['Warning', 'Critical', 'Info'][(rand() % 3) + 1] FROM numbers(10);SELECT * FROM alerts;┌────────────────time─┬─value─┬─alert────┐ 1. │ 2024-06-10 07:14:56 │ 9 │ Critical │ 2. │ 2024-06-10 07:15:56 │ 8 │ Warning │ 3. │ 2024-06-10 07:16:56 │ 7 │ Info │ 4. │ 2024-06-10 07:17:56 │ 6 │ Critical │ 5. │ 2024-06-10 07:18:56 │ 5 │ Warning │ 6. │ 2024-06-10 07:19:56 │ 4 │ Info │ 7. │ 2024-06-10 07:20:56 │ 3 │ Critical │ 8. │ 2024-06-10 07:21:56 │ 2 │ Warning │ 9. │ 2024-06-10 07:22:56 │ 1 │ Warning │ 10. │ 2024-06-10 07:23:56 │ 0 │ Critical │ └─────────────────────┴───────┴──────────┘ -
10 minutes after inserting the data, initiate a merge of data parts and look at the table contents:
OPTIMIZE TABLE alerts FINAL;SELECT * FROM alerts;All old
Criticalalerts have been removed from the table:┌────────────────time─┬─value─┬─alert───┐ 1. │ 2024-06-10 07:15:56 │ 8 │ Warning │ 2. │ 2024-06-10 07:16:56 │ 7 │ Info │ 3. │ 2024-06-10 07:18:56 │ 5 │ Warning │ 4. │ 2024-06-10 07:19:56 │ 4 │ Info │ 5. │ 2024-06-10 07:21:56 │ 2 │ Warning │ 6. │ 2024-06-10 07:22:56 │ 1 │ Warning │ └─────────────────────┴───────┴─────────┘
If you need to move data to another table before it is deleted from the main table, you can use TTL in combination with a materialized view.
-
Create:
-
the
alertstable with a TTL rule to remove alerts after 10 minutes relative to the time from thetimecolumn; -
the
alerts_historytable to storeCriticalalerts from thealertstable.
DROP TABLE IF EXISTS alerts;CREATE TABLE alerts (time DateTime, value UInt64, alert String) ENGINE = MergeTree ORDER BY time TTL time + INTERVAL 10 MINUTE DELETE;CREATE TABLE alerts_history (time DateTime, value UInt64, alert String) ENGINE = MergeTree ORDER BY time;Note that the
alerts_historytable has the same structure asalerts, but do not use theCREATE TABLE alerts_history AS alertsquery as it will also copy the TTL rule which is not needed. -
-
Create a materialized view that will be triggered on inserting data into the
alertstable and automatically loadCriticalalerts intoalerts_history:CREATE MATERIALIZED VIEW alerts_history_mv TO alerts_history AS SELECT * FROM alerts WHERE alert = 'Critical'; -
Insert test data into the
alertstable:INSERT INTO alerts SELECT now() - toIntervalMinute(number), number, ['Warning', 'Critical', 'Info'][(rand() % 3) + 1] FROM numbers(10);SELECT * FROM alerts;┌────────────────time─┬─value─┬─alert────┐ 1. │ 2024-06-10 08:02:16 │ 9 │ Warning │ 2. │ 2024-06-10 08:03:16 │ 8 │ Warning │ 3. │ 2024-06-10 08:04:16 │ 7 │ Info │ 4. │ 2024-06-10 08:05:16 │ 6 │ Critical │ 5. │ 2024-06-10 08:06:16 │ 5 │ Warning │ 6. │ 2024-06-10 08:07:16 │ 4 │ Warning │ 7. │ 2024-06-10 08:08:16 │ 3 │ Critical │ 8. │ 2024-06-10 08:09:16 │ 2 │ Warning │ 9. │ 2024-06-10 08:10:16 │ 1 │ Critical │ 10. │ 2024-06-10 08:11:16 │ 0 │ Warning │ └─────────────────────┴───────┴──────────┘ -
Wait for 10 minutes and run the query:
OPTIMIZE TABLE alerts FINAL;TTL will delete records from the
alertstable, but rows with theCriticalvalue in thealertcolumn will be retained in thealerts_historytable:SELECT * FROM alerts_history;┌────────────────time─┬─value─┬─alert────┐ 1. │ 2024-06-10 08:05:16 │ 6 │ Critical │ 2. │ 2024-06-10 08:08:16 │ 3 │ Critical │ 3. │ 2024-06-10 08:10:16 │ 1 │ Critical │ └─────────────────────┴───────┴──────────┘
-
Create the
alertstable and fill it with test data:DROP TABLE IF EXISTS alerts;CREATE TABLE alerts (time DateTime, value UInt64, alert String) ENGINE = MergeTree ORDER BY (toHour(time), alert);INSERT INTO alerts SELECT now() - toIntervalMinute(number), toInt64(randUniform(0, 100)), ['Warning', 'Critical', 'Info'][(rand() % 3) + 1] FROM numbers(15);SELECT * FROM alerts;┌────────────────time─┬─value─┬─alert────┐ 1. │ 2024-07-26 21:51:41 │ 5 │ Critical │ 2. │ 2024-07-26 21:48:41 │ 18 │ Critical │ 3. │ 2024-07-26 21:46:41 │ 53 │ Critical │ 4. │ 2024-07-26 21:43:41 │ 33 │ Critical │ 5. │ 2024-07-26 21:50:41 │ 98 │ Info │ 6. │ 2024-07-26 21:49:41 │ 74 │ Info │ 7. │ 2024-07-26 21:47:41 │ 73 │ Info │ 8. │ 2024-07-26 21:42:41 │ 52 │ Info │ 9. │ 2024-07-26 21:41:41 │ 92 │ Info │ 10. │ 2024-07-26 21:39:41 │ 70 │ Info │ 11. │ 2024-07-26 21:38:41 │ 81 │ Info │ 12. │ 2024-07-26 21:37:41 │ 72 │ Info │ 13. │ 2024-07-26 21:45:41 │ 7 │ Warning │ 14. │ 2024-07-26 21:44:41 │ 96 │ Warning │ 15. │ 2024-07-26 21:40:41 │ 0 │ Warning │ └─────────────────────┴───────┴──────────┘ -
Five minutes after inserting data (at
21:56:41relative to timestamps generated above), modify the table to add a TTL rule that groups outdated data rows (if 10 minutes have passed since the time in thetimecolumn) by time and alert type, with each group storing the maximum value in thevaluecolumn and the most recent time in thetimecolumn:ALTER TABLE alerts MODIFY TTL time + INTERVAL 10 MINUTE GROUP BY toHour(time), alert SET value = max(value), time = max(time);Note that
GROUP BYcolumns in TTL should be a prefix of the table primary key (ORDER BYifPRIMARY KEYis not specified separately). -
Perform TTL materialization to apply the TTL rule to existing data:
ALTER TABLE alerts MATERIALIZE TTL; -
Check the contents of the table:
SELECT * FROM alerts;Rows for which the TTL rule was met (10 minutes have passed since their
timevalues) were grouped, while the rest of the rows remained as before:┌────────────────time─┬─value─┬─alert────┐ 1. │ 2024-07-26 21:51:41 │ 5 │ Critical │ 2. │ 2024-07-26 21:48:41 │ 18 │ Critical │ 3. │ 2024-07-26 21:46:41 │ 53 │ Critical │ 4. │ 2024-07-26 21:50:41 │ 98 │ Info │ 5. │ 2024-07-26 21:49:41 │ 74 │ Info │ 6. │ 2024-07-26 21:47:41 │ 73 │ Info │ 7. │ 2024-07-26 21:42:41 │ 92 │ Info │ 8. │ 2024-07-26 21:45:41 │ 96 │ Warning │ └─────────────────────┴───────┴──────────┘
If you run optimization after another 10 minutes, the data will be aggregated further — the table will have one row for the most recent alert of each type:
OPTIMIZE TABLE alerts FINAL;┌────────────────time─┬─value─┬─alert────┐ 1. │ 2024-07-26 21:51:41 │ 53 │ Critical │ 2. │ 2024-07-26 21:50:41 │ 98 │ Info │ 3. │ 2024-07-26 21:45:41 │ 96 │ Warning │ └─────────────────────┴───────┴──────────┘
-
Create a table with a TTL rule to compress old data with the
LZ4HC(10)codec and also setmerge_with_recompression_ttl_timeout = 1200(in seconds) in the table settings to specify how often data should be recompressed according to TTL (in this example, every 20 minutes):DROP TABLE IF EXISTS alerts;CREATE TABLE alerts (time DateTime, value UInt64, alert String) ENGINE = MergeTree ORDER BY time TTL time + INTERVAL 10 MINUTE RECOMPRESS CODEC(LZ4HC(10)) SETTINGS merge_with_recompression_ttl_timeout = 1200; -
Insert data:
INSERT INTO alerts SELECT now() - toIntervalMinute(number), number, ['Warning', 'Critical', 'Info'][(rand() % 3) + 1] FROM numbers(100); -
View information about data parts of the
alertstable in thesystem.partssystem table:SELECT name, active, rows, data_compressed_bytes, data_uncompressed_bytes FROM system.parts WHERE table = 'alerts' FORMAT Vertical;Inserted data rows were written as one part:
Row 1: ────── name: all_1_1_0 active: 1 rows: 100 data_compressed_bytes: 1114 data_uncompressed_bytes: 1933
-
Repeat the above
INSERT INTOandSELECT … FROM system.partsqueries. Now the table has two data parts:Row 1: ────── name: all_1_1_0 active: 1 rows: 100 data_compressed_bytes: 1114 data_uncompressed_bytes: 1933 Row 2: ────── name: all_2_2_0 active: 1 rows: 100 data_compressed_bytes: 1125 data_uncompressed_bytes: 1931
-
Some time later, repeat the
SELECT … FROM system.partsquery. In the query results, you can see:-
initial data parts have been merged into one part (
all_1_2_1) containing 200 rows; -
the size of uncompressed data in the resulting part is equal to the total amount of uncompressed data in two merged parts;
-
the size of compressed data in the resulting part is smaller than the size of compressed data in both initial parts because the outdated data has been recompressed with the LZ4HC(10) codec during merging.
Row 1: ────── name: all_1_2_1 active: 1 rows: 200 data_compressed_bytes: 1509 data_uncompressed_bytes: 3864
-
In this example, separate disks are used to store "hot" and "cold" data — SSD and HDD disks mounted on the following directories:
-
/mnt/ssd/adqm/
-
/mnt/hdd/adqm/
Each directory is assigned the clickhouse owner:
$ sudo chown clickhouse:clickhouse -R /mnt/ssd/adqm/ /mnt/hdd/adqm/-
In the ADCM interface, configure a tiered storage for ADQM as described below.
Specify local disks in the Enable additional local storage section (previously enabled) of the ADQMDB service’s configuration page:
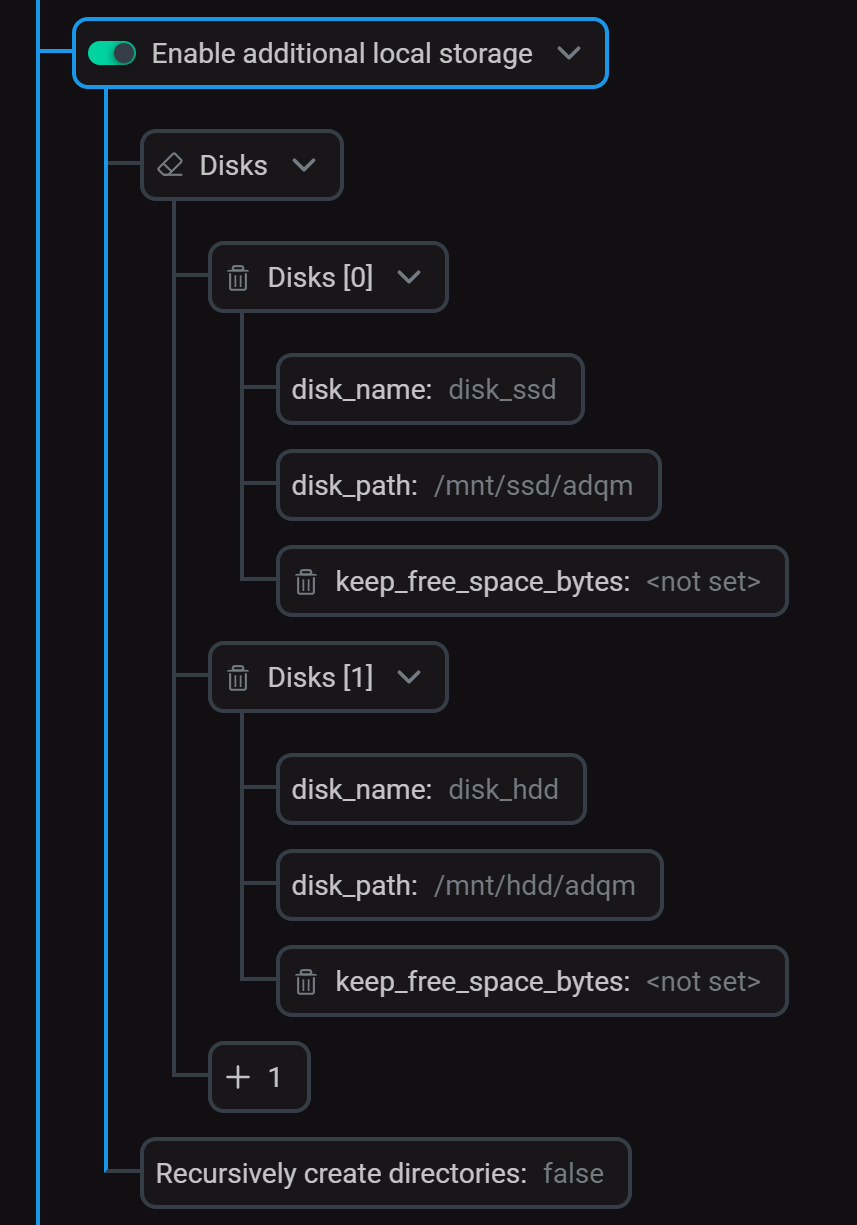 Configure local disks
Configure local disksIn the Storage policies section, create a policy (
hot_to_cold) that includes two volumes for storing "hot" and "cold" data.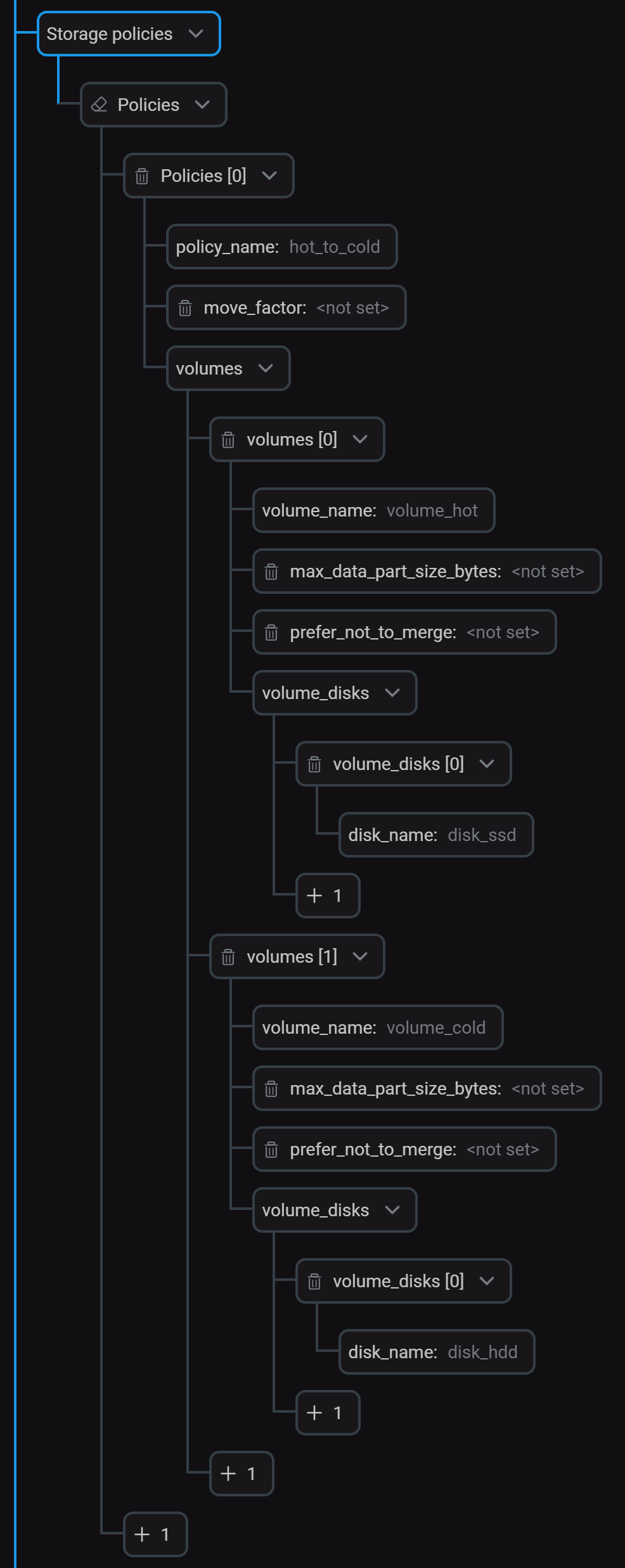 Configure storage policy
Configure storage policyClick Save and run the Reconfig action for the service to apply the changes.
After that, information about disks and policy will appear in the appropriate tags inside the
<storage_configuration>section in the /etc/clickhouse-server/config.d/storage.xml file.storage.xml<storage_configuration> <disks> <disk_ssd> <type>local</type> <path>/mnt/ssd/adqm/</path> </disk_ssd> <disk_hdd> <type>local</type> <path>/mnt/hdd/adqm/</path> </disk_hdd> </disks> <policies> <hot_to_cold> <volumes> <volume_hot> <disk>disk_ssd</disk> </volume_hot> <volume_cold> <disk>disk_hdd</disk> </volume_cold> </volumes> </hot_to_cold> </policies> </storage_configuration>You can view available disks in the
system.diskssystem table and storage policies in thesystem.storage_policiestable:SELECT name, path, free_space, total_space FROM system.disks;┌─name─────┬─path─────────────────┬──free_space─┬─total_space─┐ 1. │ default │ /var/lib/clickhouse/ │ 45148381184 │ 53674487808 │ 2. │ disk_hdd │ /mnt/hdd/adqm/ │ 45148381184 │ 53674487808 │ 3. │ disk_ssd │ /mnt/ssd/adqm/ │ 45148381184 │ 53674487808 │ └──────────┴──────────────────────┴─────────────┴─────────────┘
SELECT policy_name, volume_name, disks FROM system.storage_policies;┌─policy_name─┬─volume_name─┬─disks────────┐ 1. │ default │ default │ ['default'] │ 2. │ hot_to_cold │ volume_hot │ ['disk_ssd'] │ 3. │ hot_to_cold │ volume_cold │ ['disk_hdd'] │ └─────────────┴─────────────┴──────────────┘
-
Create a table with a TTL rule to move data between the
volume_hotandvolume_coldvolumes:DROP TABLE IF EXISTS alerts;CREATE TABLE alerts (time DateTime, value UInt64, alert String) ENGINE = MergeTree ORDER BY time TTL time TO VOLUME 'volume_hot', time + INTERVAL 5 MINUTE TO VOLUME 'volume_cold' SETTINGS storage_policy = 'hot_to_cold'; -
Insert test data into the table:
INSERT INTO alerts SELECT now() - toIntervalMinute(number), number, ['Warning', 'Critical', 'Info'][(rand() % 3) + 1] FROM numbers(5);Repeat the
INSERT INTOquery some time later.As a result, the table will have two data parts located on the
disk_ssddisk (thevolume_hotvolume):SELECT name, rows, active, disk_name FROM system.parts WHERE table = 'alerts';┌─name──────┬─rows─┬─active─┬─disk_name─┐ 1. │ all_1_1_0 │ 5 │ 1 │ disk_ssd │ 2. │ all_2_2_0 │ 5 │ 1 │ disk_ssd │ └───────────┴──────┴────────┴───────────┘
-
5 minutes after the first insertion, the first data part will be moved to the
disk_hdddisk (thevolume_coldvolume). To verify this, repeat theSELECT … FROM system.partsquery:┌─name──────┬─rows─┬─active─┬─disk_name─┐ 1. │ all_1_1_0 │ 5 │ 1 │ disk_hdd │ 2. │ all_2_2_0 │ 5 │ 1 │ disk_ssd │ └───────────┴──────┴────────┴───────────┘
Column TTL
When values in a column with TTL expire, ADQM replaces them with the default value for the column data type (or the value specified via DEFAULT). If all values in a column expire, the column is removed from the data part in the file system.
|
IMPORTANT
TTL cannot be used for key columns.
|
Assign TTL to columns
To specify a time to live for column values, use the TTL clause in the column description when creating a table with the CREATE TABLE query:
CREATE TABLE <table_name>
( <timestamp_column> Date|DateTime,
...,
<column_name1> [<data_type1>] TTL <timestamp_column> + INTERVAL <time_interval1> <interval_type1>,
<column_name2> [<data_type2>] TTL <timestamp_column> + INTERVAL <time_interval2> <interval_type2>,
...)
ENGINE = MergeTree()
...;A TTL expression specifying when column values should be deleted is described in the same way as a table-level TTL expression.
Modify TTL
To add a TTL to a column of an existing table or change the existing TTL of a column, use the ALTER TABLE … MODIFY COLUMN query:
ALTER TABLE <table_name> MODIFY COLUMN <column_name> <data_type> TTL <new_ttl_expr>;Remove TTL
The following query allows you to delete TTL from a column:
ALTER TABLE <table_name> MODIFY COLUMN <column_name> REMOVE TTL;Examples
-
Create a table and set the following TTL rules for the columns:
-
value1— a value in the column should be replaced with100if 5 minutes have passed since the time in thetimecolumn; -
value2— a column value should be replaced with the default one (0for the Int data type) if 10 minutes have passed since the time in thetimecolumn.
CREATE TABLE column_ttl_test ( time DateTime, value1 Int DEFAULT 100 TTL time + INTERVAL 5 MINUTE, value2 Int TTL time + INTERVAL 10 MINUTE, alert String ) ENGINE = MergeTree ORDER BY time SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0;The
min_rows_for_wide_partandmin_bytes_for_wide_partsettings are used to store data parts in theWideformat (for testing purposes) — each column in a separate file. -
-
Insert data into the table:
INSERT INTO column_ttl_test SELECT now() - toIntervalMinute(number), number, number + 10, ['Warning', 'Critical', 'Info'][(rand() % 3) + 1] FROM numbers(10);The first five rows in the
value1column contain100because their values in thetimecolumn were already outdated at the time of insertion:SELECT * FROM column_ttl_test;┌────────────────time─┬─value1─┬─value2─┬─alert────┐ 1. │ 2024-06-25 11:42:36 │ 100 │ 19 │ Warning │ 2. │ 2024-06-25 11:43:36 │ 100 │ 18 │ Critical │ 3. │ 2024-06-25 11:44:36 │ 100 │ 17 │ Warning │ 4. │ 2024-06-25 11:45:36 │ 100 │ 16 │ Info │ 5. │ 2024-06-25 11:46:36 │ 100 │ 15 │ Info │ 6. │ 2024-06-25 11:47:36 │ 4 │ 14 │ Info │ 7. │ 2024-06-25 11:48:36 │ 3 │ 13 │ Warning │ 8. │ 2024-06-25 11:49:36 │ 2 │ 12 │ Info │ 9. │ 2024-06-25 11:50:36 │ 1 │ 11 │ Critical │ 10. │ 2024-06-25 11:51:36 │ 0 │ 10 │ Critical │ └─────────────────────┴────────┴────────┴──────────┘ -
3 minutes after inserting data into the table, run the query:
OPTIMIZE TABLE column_ttl_test FINAL;Select data from the table again. In the results, you can see that values of the
value1column in rows 6-8 and values of thevalue2column in rows 1-3 have been replaced:┌────────────────time─┬─value1─┬─value2─┬─alert────┐ 1. │ 2024-06-25 11:42:36 │ 100 │ 0 │ Warning │ 2. │ 2024-06-25 11:43:36 │ 100 │ 0 │ Critical │ 3. │ 2024-06-25 11:44:36 │ 100 │ 0 │ Warning │ 4. │ 2024-06-25 11:45:36 │ 100 │ 16 │ Info │ 5. │ 2024-06-25 11:46:36 │ 100 │ 15 │ Info │ 6. │ 2024-06-25 11:47:36 │ 100 │ 14 │ Info │ 7. │ 2024-06-25 11:48:36 │ 100 │ 13 │ Warning │ 8. │ 2024-06-25 11:49:36 │ 100 │ 12 │ Info │ 9. │ 2024-06-25 11:50:36 │ 1 │ 11 │ Critical │ 10. │ 2024-06-25 11:51:36 │ 0 │ 10 │ Critical │ └─────────────────────┴────────┴────────┴──────────┘ -
After another 2 minutes (5 minutes after the initial data insert), all values in the
value1column will be considered outdated and replaced with100:OPTIMIZE TABLE column_ttl_test FINAL;SELECT * FROM column_ttl_test;┌────────────────time─┬─value1─┬─value2─┬─alert────┐ 1. │ 2024-06-25 11:42:36 │ 100 │ 0 │ Warning │ 2. │ 2024-06-25 11:43:36 │ 100 │ 0 │ Critical │ 3. │ 2024-06-25 11:44:36 │ 100 │ 0 │ Warning │ 4. │ 2024-06-25 11:45:36 │ 100 │ 0 │ Info │ 5. │ 2024-06-25 11:46:36 │ 100 │ 0 │ Info │ 6. │ 2024-06-25 11:47:36 │ 100 │ 14 │ Info │ 7. │ 2024-06-25 11:48:36 │ 100 │ 13 │ Warning │ 8. │ 2024-06-25 11:49:36 │ 100 │ 12 │ Info │ 9. │ 2024-06-25 11:50:36 │ 100 │ 11 │ Critical │ 10. │ 2024-06-25 11:51:36 │ 100 │ 10 │ Critical │ └─────────────────────┴────────┴────────┴──────────┘The
value1column has been removed from the data part directory in the file system. You can check this as follows.Obtain the path to the directory with files of the active data part (
all_1_1_3) from thesystem.partstable:SELECT name, active, path FROM system.parts WHERE table = 'column_ttl_test';┌─name──────┬─active─┬─path──────────────────────────────────────────────────────────────────────────┐ 1. │ all_1_1_0 │ 0 │ /var/lib/clickhouse/store/62a/62a16a55-c91c-4c6b-9386-f4347ffac137/all_1_1_0/ │ 2. │ all_1_1_1 │ 0 │ /var/lib/clickhouse/store/62a/62a16a55-c91c-4c6b-9386-f4347ffac137/all_1_1_1/ │ 3. │ all_1_1_2 │ 0 │ /var/lib/clickhouse/store/62a/62a16a55-c91c-4c6b-9386-f4347ffac137/all_1_1_2/ │ 4. │ all_1_1_3 │ 1 │ /var/lib/clickhouse/store/62a/62a16a55-c91c-4c6b-9386-f4347ffac137/all_1_1_3/ │ └───────────┴────────┴───────────────────────────────────────────────────────────────────────────────┘
Make sure that there are no files with data of the
value1column (value1.bin and value1.cmrk2) in this directory:$ sudo ls /var/lib/clickhouse/store/62a/62a16a55-c91c-4c6b-9386-f4347ffac137/all_1_1_3/alert.bin checksums.txt count.txt metadata_version.txt serialization.json time.cmrk2 value2.bin alert.cmrk2 columns.txt default_compression_codec.txt primary.cidx time.bin ttl.txt value2.cmrk2
The columns.txt file also has no information about the
value1column:$ sudo cat /var/lib/clickhouse/store/62a/62a16a55-c91c-4c6b-9386-f4347ffac137/all_1_1_3/columns.txtcolumns format version: 1 3 columns: `time` DateTime `value2` Int32 `alert` String
Use the ALTER TABLE … MODIFY COLUMN … TTL query to change the TTL for the value2 column of the table created in the previous example:
ALTER TABLE column_ttl_test MODIFY COLUMN value2 Int TTL time + INTERVAL 1 HOUR;Check the current TTL settings with the SHOW CREATE TABLE query:
SHOW CREATE TABLE column_ttl_test;As you can see, the new TTL rule is applied to the value2 column:
CREATE TABLE default.column_ttl_test
(
`time` DateTime,
`value1` Int32 DEFAULT 100 TTL time + toIntervalMinute(5),
`value2` Int32 TTL time + toIntervalHour(1),
`alert` String
)
ENGINE = MergeTree
ORDER BY time
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, index_granularity = 8192