

Использование TTL для управления данными
Обзор
Для таблиц семейства MergeTree доступна возможность устанавливать TTL (time-to-live) — интервал времени, по истечении которого старые данные будут удаляться в фоновом режиме. TTL можно установить как для всей таблицы (будут удаляться целые строки данных с устаревшими значениями), так и для каждого отдельного столбца (устаревшие значения в столбце будут заменяться значениями по умолчанию для типа данных столбца).
C помощью TTL на уровне таблицы можно также запланировать автоматическое выполнение следующих действий для строк данных:
-
Перемещение данных между дисками или томами хранилища ADQM — может быть полезно при развертывании архитектуры с разделением данных на "горячие", "теплые" и "холодные" (см. Настройка хранилищ данных).
-
Обобщение данных (агрегирование и выполнение различных вычислений) — можно снизить уровень детализации старых данных в целях экономии ресурсов для их хранения.
-
Применение более высокого уровня сжатия для старых данных.
Таким образом, управляя жизненным циклом данных с помощью механизма TTL, можно оптимизировать хранилище и повысить производительность запросов.
Когда срабатывают события TTL
Удаление строк с истекшим сроком хранения, установленным через TTL, не происходит немедленно — оно выполняется при слиянии кусков данных. ADQM с определенной периодичностью выполняет "внеплановые" слияния для удаления или сжатия данных по правилам TTL. Изменить частоту выполнения этих слияний можно с помощью специальных параметров таблицы MergeTree:
-
merge_with_ttl_timeout— минимальное время в секундах между слияниями для удаления данных по условию TTL; -
merge_with_recompression_ttl_timeout— минимальное время в секундах между слияниями для сжатия данных по условию TTL.
Значения этих параметров по умолчанию — 14400 секунд. Это значит, что удаление/сжатие устаревших по TTL данных будет выполняться каждые 4 часа или при фоновом слиянии кусков данных. Если нужно, чтобы эти операции применялись чаще, измените приведенные выше настройки. При этом стоит учитывать, что если значения этих параметров слишком низкие, будет выполняться много "внеплановых" слияний, а это может привести к потреблению значительной части ресурсов сервера — поэтому не рекомендуется использовать значения меньше 300 секунд.
Также в таблицах MergeTree есть настройка ttl_only_drop_parts, значение которой влияет на удаление данных согласно TTL следующим образом:
-
0(по умолчанию) — удаляются только записи, устаревшие в соответствии с их временем жизни (TTL); -
1— удаляется кусок данных целиком, когда в нем все записи устарели.
Удаление целых кусков данных вместо удаления отдельных записей позволяет установить меньший тайм-аут merge_with_ttl_timeout и уменьшить влияние операций TTL на производительность системы.
Операции перемещения между дисками/томами или повторного сжатия данных выполняются только когда устаревают все данные в куске данных.
При выполнении запроса SELECT между слияниями можно получить устаревшие данные в таблице. Чтобы этого избежать, перед выборкой можно выполнить запрос OPTIMIZE … FINAL (форсирует слияние кусков данных), но не рекомендуется делать это слишком часто, особенно для больших таблиц.
TTL таблицы
Создание таблицы с TTL
Чтобы установить TTL для таблицы при ее создании, используйте выражение TTL в конце описания таблицы в запросе CREATE TABLE. После выражения TTL можно указать одно правило для удаления старых данных и/или несколько правил TTL для обработки данных другим способом (например, для перемещения данных на другой диск/том или изменения уровня их сжатия).
Синтаксис запроса для создания таблицы с TTL в общем виде:
CREATE TABLE <table_name>
( <timestamp_column> Date|DateTime ...,
<column1> ...,
<column2> ...,
...)
ENGINE = MergeTree()
TTL <ttl_expr> [<ttl_action>] [, <ttl_expr2> [<ttl_action2>]] [, ...];где каждое правило TTL включает:
-
<ttl_expr>— выражение TTL, которое определяет когда данные будут считаться устаревшими; -
<ttl_action>— действие, которое будет выполняться по истечении определяемого выражением TTL времени.
Выражение TTL должно возвращать значение типа Date или DateTime и обычно указывается в следующем формате:
<timestamp_column> [+ INTERVAL <time_interval> <interval_type>]где:
-
<timestamp_column>— имя столбца типа Date или DateTime с временными метками, относительно которых будет определяться время хранения данных; -
INTERVAL <time_interval> <interval_type>— значение типа Interval, которое указывает длительность хранения строки данных относительно временной метки в столбце<timestamp_column>. В структуру этого значения входит интервал времени как целое число без знака и тип интервала — например,1 MONTH,3 DAY,5 HOUR.
Чтобы указать интервал времени, вместо оператора INTERVAL можно использовать функцию преобразования toInterval. В этом случае выражение TTL может выглядеть, например, следующим образом:
<timestamp_column> toIntervalMonth(1)
<timestamp_column> toIntervalDay(3)
<timestamp_column> toIntervalHour(5)Действия, которые должны выполняться для строк данных с истекшим согласно выражению TTL временем хранения, указываются с помощью перечисленных ниже выражений.
| Выражение | Синтаксис TTL в общем виде | Описание действия |
|---|---|---|
DELETE |
|
Удаление строк данных с истекшим сроком хранения. Это действие применяется по умолчанию (то есть строки удаляются, если после выражения |
TO DISK |
|
Перемещение данных на указанный диск |
TO VOLUME |
|
Перемещение данных на указанный том |
RECOMPRESS |
|
Сжатие данных указанным кодеком |
GROUP BY |
|
Агрегирование данных. При определении правила агрегирования устаревших данных необходимо учитывать следующие особенности:
|
С помощью выражения WHERE можно указать условие удаления (DELETE) или агрегирования (GROUP BY) устаревших строк. Для перемещения и сжатия данных условие WHERE не применимо.
Изменение TTL
Изменить TTL существующей таблицы можно с помощью следующего запроса:
ALTER TABLE <table_name> MODIFY TTL <new_ttl_rules>;После выполнения этого запроса при каждой вставке новых данных или создании новых кусков данных в результате фонового слияния TTL будет рассчитываться в соответствии с новым правилом.
Чтобы пересчитать TTL для уже существующих данных, необходимо выполнить материализацию TTL. Настройка materialize_ttl_after_modify (включена по умолчанию) контролирует, будет ли материализация TTL осуществляться автоматически после выполнения запроса ALTER TABLE … MODIFY TTL. Также можно форсировать материализацию TTL следующим запросом:
ALTER TABLE <table_name> MATERIALIZE TTL;Материализация TTL может быть достаточно тяжелой операцией (особенно для больших таблиц), так как при этом пересчитывается TTL во всех кусках данных (обновляются файлы ttl.txt) и перезаписываются данные во всех столбцах, что может привести к большому количеству операций чтения/записи. Чтобы облегчить операцию материализации TTL, можно в настройках таблицы MergeTree установить параметр materialize_ttl_recalculate_only = 1 — в этом случае будет выполняться только обновление ttl.txt (довольно легкая операция, так как считываются только столбцы, используемые в TTL) и копирование столбцов через жесткие ссылки, а через некоторое время данные с истекшим сроком хранения будут удалены во время слияния при включенной настройке ttl_only_drop_parts.
В некоторых случаях оптимальным решением будет отключить материализацию TTL (materialize_ttl_after_modify = 0) и удалить/переместить старые партиции вручную (с помощью запросов ALTER TABLE … DROP|MOVE PARTITION — см. Манипуляции с партициями и кусками данных).
Удаление TTL
Чтобы удалить правила TTL из таблицы, используйте запрос:
ALTER TABLE <table_name> REMOVE TTL;Примеры
-
Создайте таблицу с правилом TTL для удаления строк, которые будут считаться устаревшими, если с момента времени в столбце
timeпрошло 10 минут:CREATE TABLE test_table (time DateTime, value UInt64) ENGINE = MergeTree ORDER BY time TTL time + INTERVAL 10 MINUTE;Заполните таблицу тестовыми данными:
INSERT INTO test_table SELECT now() - toIntervalMinute(number), number FROM numbers(10);SELECT * FROM test_table;┌────────────────time─┬─value─┐ 1. │ 2024-06-07 13:15:49 │ 9 │ 2. │ 2024-06-07 13:16:49 │ 8 │ 3. │ 2024-06-07 13:17:49 │ 7 │ 4. │ 2024-06-07 13:18:49 │ 6 │ 5. │ 2024-06-07 13:19:49 │ 5 │ 6. │ 2024-06-07 13:20:49 │ 4 │ 7. │ 2024-06-07 13:21:49 │ 3 │ 8. │ 2024-06-07 13:22:49 │ 2 │ 9. │ 2024-06-07 13:23:49 │ 1 │ 10. │ 2024-06-07 13:24:49 │ 0 │ └─────────────────────┴───────┘ -
Через 5 минут после вставки данных выполните запрос:
OPTIMIZE TABLE test_table FINAL;Повторите запрос на выборку данных из таблицы:
SELECT * FROM test_table;В результате видно, что первые пять строк удалены из таблицы, так как для каждой из них прошло 10 минут с момента времени, которое представлено значением столбца
time:┌────────────────time─┬─value─┐ 1. │ 2024-06-07 13:20:49 │ 4 │ 2. │ 2024-06-07 13:21:49 │ 3 │ 3. │ 2024-06-07 13:22:49 │ 2 │ 4. │ 2024-06-07 13:23:49 │ 1 │ 5. │ 2024-06-07 13:24:49 │ 0 │ └─────────────────────┴───────┘
Если не использовать запрос
OPTIMIZE TABLE … FINALи выполнить запросSELECTмежду слияниями, в таблице все еще можно увидеть устаревшие данные.
-
Создайте таблицу оповещений (
alerts) с правилом TTL для удаления строк со значениемCriticalв столбцеalertи значением времени в столбцеtime, с момента которого прошло 10 минут:CREATE TABLE alerts (time DateTime, value UInt64, alert String) ENGINE = MergeTree ORDER BY time TTL time + INTERVAL 10 MINUTE DELETE WHERE alert = 'Critical';Заполните таблицу тестовыми данными:
INSERT INTO alerts SELECT now() - toIntervalMinute(number), number, ['Warning', 'Critical', 'Info'][(rand() % 3) + 1] FROM numbers(10);SELECT * FROM alerts;┌────────────────time─┬─value─┬─alert────┐ 1. │ 2024-06-10 07:14:56 │ 9 │ Critical │ 2. │ 2024-06-10 07:15:56 │ 8 │ Warning │ 3. │ 2024-06-10 07:16:56 │ 7 │ Info │ 4. │ 2024-06-10 07:17:56 │ 6 │ Critical │ 5. │ 2024-06-10 07:18:56 │ 5 │ Warning │ 6. │ 2024-06-10 07:19:56 │ 4 │ Info │ 7. │ 2024-06-10 07:20:56 │ 3 │ Critical │ 8. │ 2024-06-10 07:21:56 │ 2 │ Warning │ 9. │ 2024-06-10 07:22:56 │ 1 │ Warning │ 10. │ 2024-06-10 07:23:56 │ 0 │ Critical │ └─────────────────────┴───────┴──────────┘ -
Через 10 минут после вставки данных инициируйте слияние кусков данных таблицы и посмотрите ее содержимое:
OPTIMIZE TABLE alerts FINAL;SELECT * FROM alerts;Из таблицы удалены все старые оповещения типа
Critical:┌────────────────time─┬─value─┬─alert───┐ 1. │ 2024-06-10 07:15:56 │ 8 │ Warning │ 2. │ 2024-06-10 07:16:56 │ 7 │ Info │ 3. │ 2024-06-10 07:18:56 │ 5 │ Warning │ 4. │ 2024-06-10 07:19:56 │ 4 │ Info │ 5. │ 2024-06-10 07:21:56 │ 2 │ Warning │ 6. │ 2024-06-10 07:22:56 │ 1 │ Warning │ └─────────────────────┴───────┴─────────┘
Если необходимо переместить данные в другую таблицу перед их удалением из основной таблицы, можно использовать TTL в сочетании с материализованным представлением (materialized view).
-
Создайте таблицу
alertsс правилом TTL для удаления оповещений через 10 минут относительно времени, указанного в столбцеtime, и таблицуalerts_history, в которую будут сохраняться оповещения типаCriticalиз таблицыalerts:DROP TABLE IF EXISTS alerts;CREATE TABLE alerts (time DateTime, value UInt64, alert String) ENGINE = MergeTree ORDER BY time TTL time + INTERVAL 10 MINUTE DELETE;CREATE TABLE alerts_history (time DateTime, value UInt64, alert String) ENGINE = MergeTree ORDER BY time;Обратите внимание, таблица
alerts_historyимеет ту же структуру, что иalerts, но не стоит использовать запросCREATE TABLE alerts_history AS alerts, так как в этом случае правило TTL тоже скопируется, а это не нужно. -
Создайте материализованное представление для автоматической загрузки оповещений
Criticalв таблицуalerts_historyпри вставке вalerts:CREATE MATERIALIZED VIEW alerts_history_mv TO alerts_history AS SELECT * FROM alerts WHERE alert = 'Critical'; -
Вставьте тестовые данные в таблицу
alerts:INSERT INTO alerts SELECT now() - toIntervalMinute(number), number, ['Warning', 'Critical', 'Info'][(rand() % 3) + 1] FROM numbers(10);SELECT * FROM alerts;┌────────────────time─┬─value─┬─alert────┐ 1. │ 2024-06-10 08:02:16 │ 9 │ Warning │ 2. │ 2024-06-10 08:03:16 │ 8 │ Warning │ 3. │ 2024-06-10 08:04:16 │ 7 │ Info │ 4. │ 2024-06-10 08:05:16 │ 6 │ Critical │ 5. │ 2024-06-10 08:06:16 │ 5 │ Warning │ 6. │ 2024-06-10 08:07:16 │ 4 │ Warning │ 7. │ 2024-06-10 08:08:16 │ 3 │ Critical │ 8. │ 2024-06-10 08:09:16 │ 2 │ Warning │ 9. │ 2024-06-10 08:10:16 │ 1 │ Critical │ 10. │ 2024-06-10 08:11:16 │ 0 │ Warning │ └─────────────────────┴───────┴──────────┘ -
Подождите 10 минут и выполните запрос:
OPTIMIZE TABLE alerts FINAL;В результате, TTL удалит записи из таблицы
alerts, но записи со значениемCriticalв столбцеalertбудут сохранены в таблицеalerts_history:SELECT * FROM alerts_history;┌────────────────time─┬─value─┬─alert────┐ 1. │ 2024-06-10 08:05:16 │ 6 │ Critical │ 2. │ 2024-06-10 08:08:16 │ 3 │ Critical │ 3. │ 2024-06-10 08:10:16 │ 1 │ Critical │ └─────────────────────┴───────┴──────────┘
-
Создайте таблицу
alertsи заполните ее тестовыми данными:DROP TABLE IF EXISTS alerts;CREATE TABLE alerts (time DateTime, value UInt64, alert String) ENGINE = MergeTree ORDER BY (toHour(time), alert);INSERT INTO alerts SELECT now() - toIntervalMinute(number), toInt64(randUniform(0, 100)), ['Warning', 'Critical', 'Info'][(rand() % 3) + 1] FROM numbers(15);SELECT * FROM alerts;┌────────────────time─┬─value─┬─alert────┐ 1. │ 2024-07-26 21:51:41 │ 5 │ Critical │ 2. │ 2024-07-26 21:48:41 │ 18 │ Critical │ 3. │ 2024-07-26 21:46:41 │ 53 │ Critical │ 4. │ 2024-07-26 21:43:41 │ 33 │ Critical │ 5. │ 2024-07-26 21:50:41 │ 98 │ Info │ 6. │ 2024-07-26 21:49:41 │ 74 │ Info │ 7. │ 2024-07-26 21:47:41 │ 73 │ Info │ 8. │ 2024-07-26 21:42:41 │ 52 │ Info │ 9. │ 2024-07-26 21:41:41 │ 92 │ Info │ 10. │ 2024-07-26 21:39:41 │ 70 │ Info │ 11. │ 2024-07-26 21:38:41 │ 81 │ Info │ 12. │ 2024-07-26 21:37:41 │ 72 │ Info │ 13. │ 2024-07-26 21:45:41 │ 7 │ Warning │ 14. │ 2024-07-26 21:44:41 │ 96 │ Warning │ 15. │ 2024-07-26 21:40:41 │ 0 │ Warning │ └─────────────────────┴───────┴──────────┘ -
Через пять минут после вставки данных (относительно сгенерированных выше временных значений — в
21:56:41) добавьте в таблицу правило TTL, по которому устаревшие строки данных (если с момента времени в столбцеtimeпрошло 10 минут) будут сгруппированы по времени и типу оповещения, при этом в каждой группе в столбцеvalueбудет сохраняться максимальное значение, а в столбцеtime— самое последнее время:ALTER TABLE alerts MODIFY TTL time + INTERVAL 10 MINUTE GROUP BY toHour(time), alert SET value = max(value), time = max(time);Обратите внимание, столбцы
GROUP BYв TTL должны быть префиксом первичного ключа таблицы (ORDER BY, если отдельно не указанPRIMARY KEY). -
Выполните материализацию TTL, чтобы применить правило TTL к существующим данным таблицы:
ALTER TABLE alerts MATERIALIZE TTL; -
Проверьте содержимое таблицы:
SELECT * FROM alerts;Строки, для которых выполнилось правило TTL (с момента времени
timeпрошло 10 минут), сгруппировались, остальные строки остались в прежнем виде:┌────────────────time─┬─value─┬─alert────┐ 1. │ 2024-07-26 21:51:41 │ 5 │ Critical │ 2. │ 2024-07-26 21:48:41 │ 18 │ Critical │ 3. │ 2024-07-26 21:46:41 │ 53 │ Critical │ 4. │ 2024-07-26 21:50:41 │ 98 │ Info │ 5. │ 2024-07-26 21:49:41 │ 74 │ Info │ 6. │ 2024-07-26 21:47:41 │ 73 │ Info │ 7. │ 2024-07-26 21:42:41 │ 92 │ Info │ 8. │ 2024-07-26 21:45:41 │ 96 │ Warning │ └─────────────────────┴───────┴──────────┘
Если еще через 10 минут выполнить оптимизацию, данные будут доагрегированы — в таблице останется по одной строке для самого последнего оповещения каждого типа:
OPTIMIZE TABLE alerts FINAL;┌────────────────time─┬─value─┬─alert────┐ 1. │ 2024-07-26 21:51:41 │ 53 │ Critical │ 2. │ 2024-07-26 21:50:41 │ 98 │ Info │ 3. │ 2024-07-26 21:45:41 │ 96 │ Warning │ └─────────────────────┴───────┴──────────┘
-
Создайте таблицу с правилом TTL, по которому устаревшие данные будут сжиматься кодеком
LZ4HC(10), а также укажите параметрmerge_with_recompression_ttl_timeout = 1200(в секундах), чтобы определить, как часто будет запускаться действие TTL для сжатия старых данных (в данном примере каждые 20 минут):DROP TABLE IF EXISTS alerts;CREATE TABLE alerts (time DateTime, value UInt64, alert String) ENGINE = MergeTree ORDER BY time TTL time + INTERVAL 10 MINUTE RECOMPRESS CODEC(LZ4HC(10)) SETTINGS merge_with_recompression_ttl_timeout = 1200; -
Вставьте данные:
INSERT INTO alerts SELECT now() - toIntervalMinute(number), number, ['Warning', 'Critical', 'Info'][(rand() % 3) + 1] FROM numbers(100); -
Посмотрите информацию о кусках данных таблицы
alertsв системной таблицеsystem.parts:SELECT name, active, rows, data_compressed_bytes, data_uncompressed_bytes FROM system.parts WHERE table = 'alerts' FORMAT Vertical;Вставленные 100 строк данных записались в виде одного куска:
Row 1: ────── name: all_1_1_0 active: 1 rows: 100 data_compressed_bytes: 1114 data_uncompressed_bytes: 1933
-
Повторите приведенные выше запросы
INSERT INTOиSELECT … FROM system.parts. В результате в таблице будет два куска данных:Row 1: ────── name: all_1_1_0 active: 1 rows: 100 data_compressed_bytes: 1114 data_uncompressed_bytes: 1933 Row 2: ────── name: all_2_2_0 active: 1 rows: 100 data_compressed_bytes: 1125 data_uncompressed_bytes: 1931
-
Через некоторое время повторите запрос
SELECT … FROM system.parts. В результате вставленные куски данных сливаются в один кусокall_1_2_1, который содержит 200 строк. Размер несжатых данных в этом куске равен сумме несжатых данных объединенных кусков, а размер сжатых данных меньше, так как при слиянии устаревшие данные были сжаты кодеком LZ4HC(10):Row 1: ────── name: all_1_2_1 active: 1 rows: 200 data_compressed_bytes: 1509 data_uncompressed_bytes: 3864
В данном примере для хранения "горячих" и "холодных" данных будут использоваться разные диски — SSD- и HDD-диск, примонтированные в следующие каталоги:
-
/mnt/ssd/adqm/
-
/mnt/hdd/adqm/
Каждому каталогу назначен владелец clickhouse:
$ sudo chown clickhouse:clickhouse -R /mnt/ssd/adqm/ /mnt/hdd/adqm/-
В интерфейсе ADCM сконфигурируйте многоуровневое хранилище для ADQM следующим образом.
Добавьте локальные диски на странице конфигурации сервиса ADQMDB в секции Enable additional local storage (секция должна быть активирована).
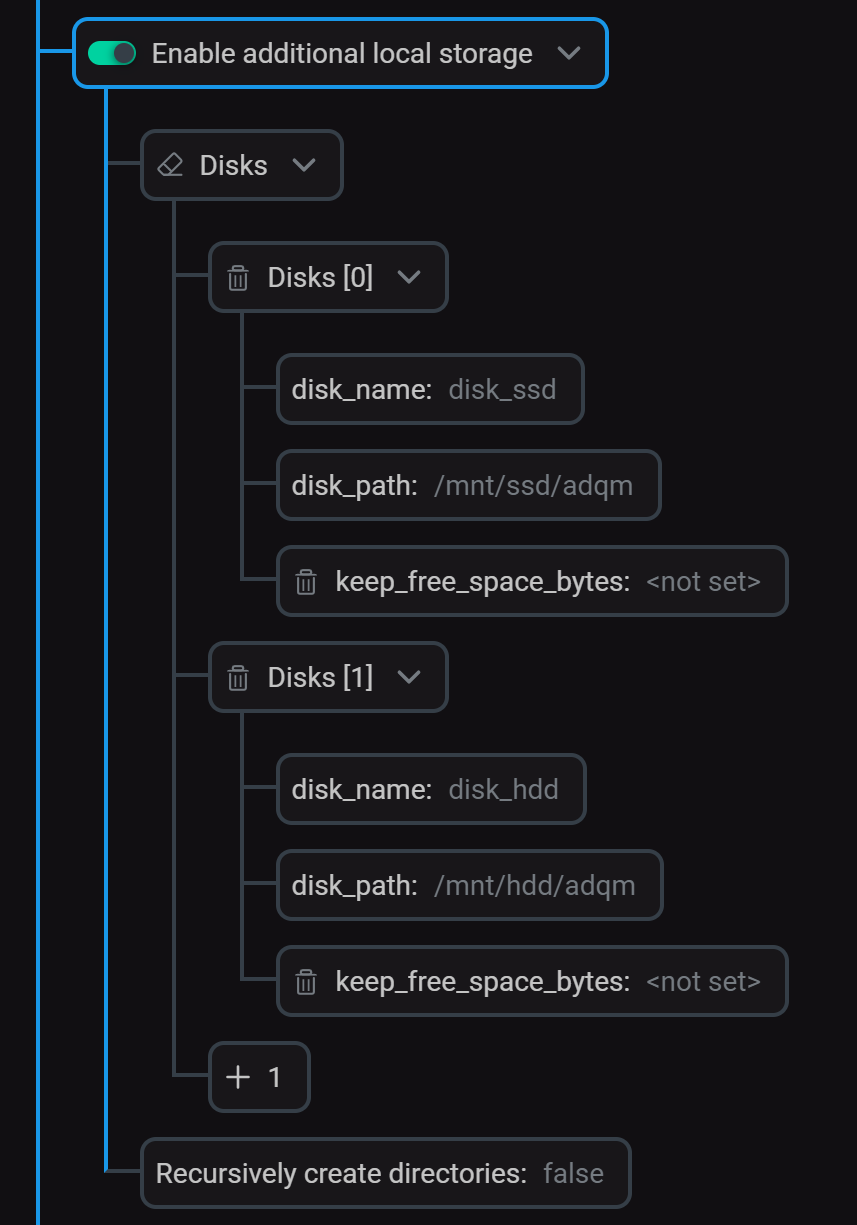 Конфигурирование локальных дисков
Конфигурирование локальных дисковВ секции Storage policies создайте политику (
hot_to_cold), которая включает два тома для хранения "горячих" и "холодных" данных.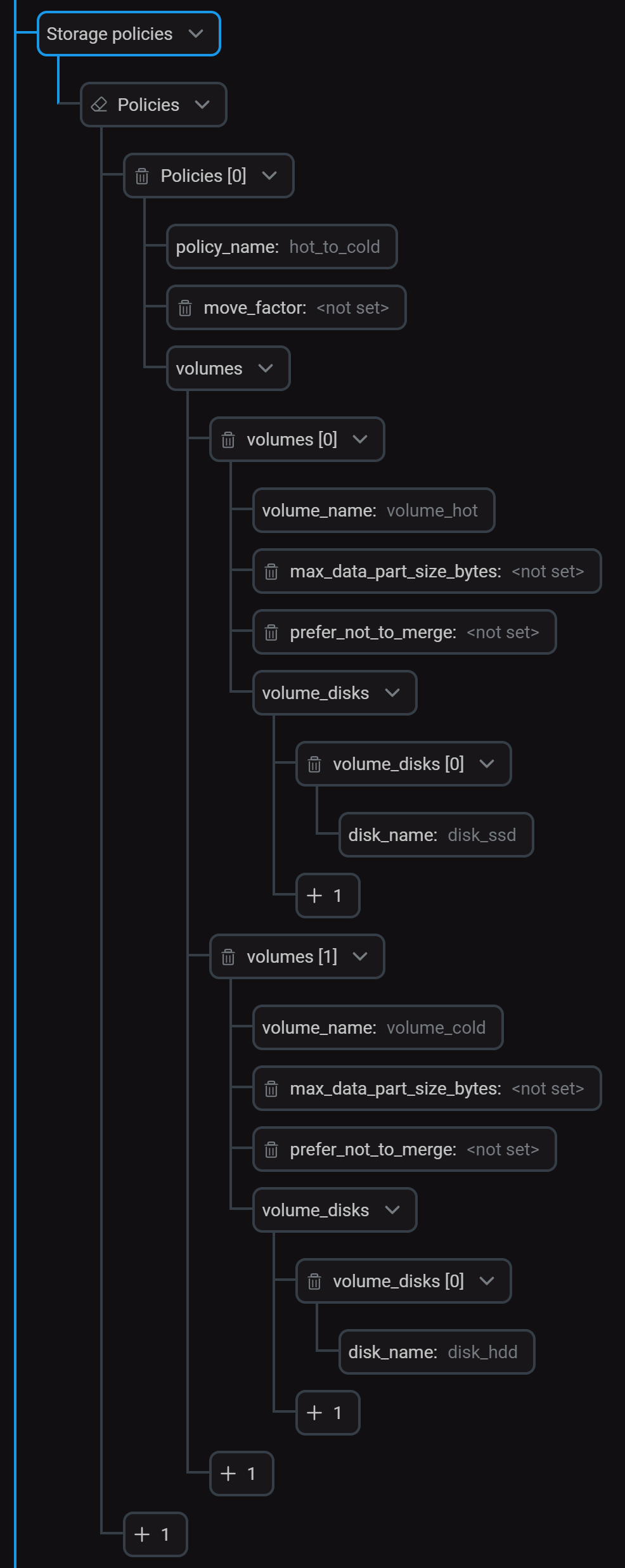 Конфигурирование политики хранения
Конфигурирование политики храненияНажмите Save и выполните действие Reconfig для сервиса, чтобы применить изменения.
После этого информация о дисках и политике появится в соответствующих тегах внутри секции
<storage_configuration>файла /etc/clickhouse-server/config.d/storage.xml.storage.xml<storage_configuration> <disks> <disk_ssd> <type>local</type> <path>/mnt/ssd/adqm/</path> </disk_ssd> <disk_hdd> <type>local</type> <path>/mnt/hdd/adqm/</path> </disk_hdd> </disks> <policies> <hot_to_cold> <volumes> <volume_hot> <disk>disk_ssd</disk> </volume_hot> <volume_cold> <disk>disk_hdd</disk> </volume_cold> </volumes> </hot_to_cold> </policies> </storage_configuration>Доступные диски можно посмотреть в системной таблице
system.disks, а политики хранения — в таблицеsystem.storage_policies:SELECT name, path, free_space, total_space FROM system.disks;┌─name─────┬─path─────────────────┬──free_space─┬─total_space─┐ 1. │ default │ /var/lib/clickhouse/ │ 45148381184 │ 53674487808 │ 2. │ disk_hdd │ /mnt/hdd/adqm/ │ 45148381184 │ 53674487808 │ 3. │ disk_ssd │ /mnt/ssd/adqm/ │ 45148381184 │ 53674487808 │ └──────────┴──────────────────────┴─────────────┴─────────────┘
SELECT policy_name, volume_name, disks FROM system.storage_policies;┌─policy_name─┬─volume_name─┬─disks────────┐ 1. │ default │ default │ ['default'] │ 2. │ hot_to_cold │ volume_hot │ ['disk_ssd'] │ 3. │ hot_to_cold │ volume_cold │ ['disk_hdd'] │ └─────────────┴─────────────┴──────────────┘
-
Создайте таблицу с правилом TTL, по которому данные будут перемещаться между томами
volume_hotиvolume_cold:DROP TABLE IF EXISTS alerts;CREATE TABLE alerts (time DateTime, value UInt64, alert String) ENGINE = MergeTree ORDER BY time TTL time TO VOLUME 'volume_hot', time + INTERVAL 5 MINUTE TO VOLUME 'volume_cold' SETTINGS storage_policy = 'hot_to_cold'; -
Вставьте в таблицу тестовые данные:
INSERT INTO alerts SELECT now() - toIntervalMinute(number), number, ['Warning', 'Critical', 'Info'][(rand() % 3) + 1] FROM numbers(5);Повторите запрос
INSERT INTOчерез некоторое время.В результате в таблице будет два куска данных, расположенных на диске
disk_ssd(томvolume_hot):SELECT name, rows, active, disk_name FROM system.parts WHERE table = 'alerts';┌─name──────┬─rows─┬─active─┬─disk_name─┐ 1. │ all_1_1_0 │ 5 │ 1 │ disk_ssd │ 2. │ all_2_2_0 │ 5 │ 1 │ disk_ssd │ └───────────┴──────┴────────┴───────────┘
-
Через 5 минут после первой вставки первый кусок данных будет перемещен на диск
disk_hdd(томvolume_cold). Чтобы убедиться в этом, повторите запросSELECT … FROM system.parts:┌─name──────┬─rows─┬─active─┬─disk_name─┐ 1. │ all_1_1_0 │ 5 │ 1 │ disk_hdd │ 2. │ all_2_2_0 │ 5 │ 1 │ disk_ssd │ └───────────┴──────┴────────┴───────────┘
TTL столбцов
В столбце с установленным TTL по истечении указанного срока хранения значений ADQM заменяет их значениями по умолчанию для типа данных столбца (или значением, указанным через DEFAULT). Если все значения столбца в куске данных устарели, этот столбец удаляется из каталога куска данных в файловой системе.
|
ВАЖНО
TTL нельзя использовать для ключевых столбцов.
|
Установка TTL для столбцов
Для указания времени хранения значений в столбце используйте выражение TTL в описании столбца при создании таблицы с помощью запроса CREATE TABLE:
CREATE TABLE <table_name>
( <timestamp_column> Date|DateTime,
...,
<column_name1> [<data_type1>] TTL <timestamp_column> + INTERVAL <time_interval1> <interval_type1>,
<column_name2> [<data_type2>] TTL <timestamp_column> + INTERVAL <time_interval2> <interval_type2>,
...)
ENGINE = MergeTree()
...;Выражение TTL, определяющее когда значения столбца должны быть удалены, указывается тем же способом, что и выражение TTL на уровне таблицы.
Изменение TTL
Чтобы добавить TTL в столбец существующей таблицы или изменить TTL столбца, используйте запрос ALTER TABLE … MODIFY COLUMN:
ALTER TABLE <table_name> MODIFY COLUMN <column_name> <data_type> TTL <new_ttl_expr>;Удаление TTL
Удалить TTL столбца можно через следующий запрос:
ALTER TABLE <table_name> MODIFY COLUMN <column_name> REMOVE TTL;Примеры
-
Создайте таблицу и установите следующие правила TTL для столбцов:
-
value1— значение в столбце заменяется на100, если прошло 5 минут с момента времени, указанного в столбцеtime; -
value2— устанавливается значение по умолчанию (0для типа данных Int), если с момента времениtimeпрошло 10 минут.
CREATE TABLE column_ttl_test ( time DateTime, value1 Int DEFAULT 100 TTL time + INTERVAL 5 MINUTE, value2 Int TTL time + INTERVAL 10 MINUTE, alert String ) ENGINE = MergeTree ORDER BY time SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0;Настройки
min_rows_for_wide_partиmin_bytes_for_wide_partиспользуются, чтобы куски данных хранились в форматеWide(для тестовых целей) — каждый столбец в отдельном файле. -
-
Вставьте в таблицу данные:
INSERT INTO column_ttl_test SELECT now() - toIntervalMinute(number), number, number + 10, ['Warning', 'Critical', 'Info'][(rand() % 3) + 1] FROM numbers(10);Первые пять строк в столбце
value1содержат100, так как на момент вставки значения времени в столбцеtimeбыли уже устаревшими:SELECT * FROM column_ttl_test;┌────────────────time─┬─value1─┬─value2─┬─alert────┐ 1. │ 2024-06-25 11:42:36 │ 100 │ 19 │ Warning │ 2. │ 2024-06-25 11:43:36 │ 100 │ 18 │ Critical │ 3. │ 2024-06-25 11:44:36 │ 100 │ 17 │ Warning │ 4. │ 2024-06-25 11:45:36 │ 100 │ 16 │ Info │ 5. │ 2024-06-25 11:46:36 │ 100 │ 15 │ Info │ 6. │ 2024-06-25 11:47:36 │ 4 │ 14 │ Info │ 7. │ 2024-06-25 11:48:36 │ 3 │ 13 │ Warning │ 8. │ 2024-06-25 11:49:36 │ 2 │ 12 │ Info │ 9. │ 2024-06-25 11:50:36 │ 1 │ 11 │ Critical │ 10. │ 2024-06-25 11:51:36 │ 0 │ 10 │ Critical │ └─────────────────────┴────────┴────────┴──────────┘ -
Через 3 минут после вставки данных в таблицу, выполните запрос:
OPTIMIZE TABLE column_ttl_test FINAL;Снова запросите данные из таблицы. В результате будут заменены значения столбца
value1в строках 6-8 и столбцаvalue2в строках 1-3:┌────────────────time─┬─value1─┬─value2─┬─alert────┐ 1. │ 2024-06-25 11:42:36 │ 100 │ 0 │ Warning │ 2. │ 2024-06-25 11:43:36 │ 100 │ 0 │ Critical │ 3. │ 2024-06-25 11:44:36 │ 100 │ 0 │ Warning │ 4. │ 2024-06-25 11:45:36 │ 100 │ 16 │ Info │ 5. │ 2024-06-25 11:46:36 │ 100 │ 15 │ Info │ 6. │ 2024-06-25 11:47:36 │ 100 │ 14 │ Info │ 7. │ 2024-06-25 11:48:36 │ 100 │ 13 │ Warning │ 8. │ 2024-06-25 11:49:36 │ 100 │ 12 │ Info │ 9. │ 2024-06-25 11:50:36 │ 1 │ 11 │ Critical │ 10. │ 2024-06-25 11:51:36 │ 0 │ 10 │ Critical │ └─────────────────────┴────────┴────────┴──────────┘ -
Еще через 2 минуты (5 минут после первоначальной вставки данных в таблицу) все значения в столбце
value1будут считаться устаревшими (заменены на100):OPTIMIZE TABLE column_ttl_test FINAL;SELECT * FROM column_ttl_test;┌────────────────time─┬─value1─┬─value2─┬─alert────┐ 1. │ 2024-06-25 11:42:36 │ 100 │ 0 │ Warning │ 2. │ 2024-06-25 11:43:36 │ 100 │ 0 │ Critical │ 3. │ 2024-06-25 11:44:36 │ 100 │ 0 │ Warning │ 4. │ 2024-06-25 11:45:36 │ 100 │ 0 │ Info │ 5. │ 2024-06-25 11:46:36 │ 100 │ 0 │ Info │ 6. │ 2024-06-25 11:47:36 │ 100 │ 14 │ Info │ 7. │ 2024-06-25 11:48:36 │ 100 │ 13 │ Warning │ 8. │ 2024-06-25 11:49:36 │ 100 │ 12 │ Info │ 9. │ 2024-06-25 11:50:36 │ 100 │ 11 │ Critical │ 10. │ 2024-06-25 11:51:36 │ 100 │ 10 │ Critical │ └─────────────────────┴────────┴────────┴──────────┘После этого столбец
value1будет удален из каталога куска данных в файловой системе. Проверить это можно следующим образом.В таблице
system.partsпосмотрите путь к каталогу с файлами активного куска данных (all_1_1_3):SELECT name, active, path FROM system.parts WHERE table = 'column_ttl_test';┌─name──────┬─active─┬─path──────────────────────────────────────────────────────────────────────────┐ 1. │ all_1_1_0 │ 0 │ /var/lib/clickhouse/store/62a/62a16a55-c91c-4c6b-9386-f4347ffac137/all_1_1_0/ │ 2. │ all_1_1_1 │ 0 │ /var/lib/clickhouse/store/62a/62a16a55-c91c-4c6b-9386-f4347ffac137/all_1_1_1/ │ 3. │ all_1_1_2 │ 0 │ /var/lib/clickhouse/store/62a/62a16a55-c91c-4c6b-9386-f4347ffac137/all_1_1_2/ │ 4. │ all_1_1_3 │ 1 │ /var/lib/clickhouse/store/62a/62a16a55-c91c-4c6b-9386-f4347ffac137/all_1_1_3/ │ └───────────┴────────┴───────────────────────────────────────────────────────────────────────────────┘
Убедитесь, что в этом каталоге нет файлов с данными столбца
value1(value1.bin и value1.cmrk2):$ sudo ls /var/lib/clickhouse/store/62a/62a16a55-c91c-4c6b-9386-f4347ffac137/all_1_1_3/alert.bin checksums.txt count.txt metadata_version.txt serialization.json time.cmrk2 value2.bin alert.cmrk2 columns.txt default_compression_codec.txt primary.cidx time.bin ttl.txt value2.cmrk2
В файле columns.txt нет информации о столбце
value1:$ sudo cat /var/lib/clickhouse/store/62a/62a16a55-c91c-4c6b-9386-f4347ffac137/all_1_1_3/columns.txtcolumns format version: 1 3 columns: `time` DateTime `value2` Int32 `alert` String
Используйте запрос ALTER TABLE … MODIFY COLUMN … TTL, чтобы изменить TTL столбца value2 таблицы, созданной в предыдущем примере:
ALTER TABLE column_ttl_test MODIFY COLUMN value2 Int TTL time + INTERVAL 1 HOUR;Проверьте текущие настройки TTL с помощью запроса SHOW CREATE TABLE:
SHOW CREATE TABLE column_ttl_test;Новое правило для столбца value2 применилось:
CREATE TABLE default.column_ttl_test
(
`time` DateTime,
`value1` Int32 DEFAULT 100 TTL time + toIntervalMinute(5),
`value2` Int32 TTL time + toIntervalHour(1),
`alert` String
)
ENGINE = MergeTree
ORDER BY time
SETTINGS min_rows_for_wide_part = 0, min_bytes_for_wide_part = 0, index_granularity = 8192