

Интеграция ADQM и Kafka
ClickHouse поддерживает возможность интеграции с Apache Kafka через специальный табличный движок — Kafka. Этот движок позволяет:
-
подписываться на топики Kafka, чтобы организовать потоковую загрузку данных из Kafka в ClickHouse (наиболее частый сценарий использования интеграции) или публиковать данные из ClickHouse в Kafka;
-
создавать отказоустойчивые хранилища;
-
обрабатывать потоки по мере их появления.
В данной статье описываются особенности работы с табличным движком Kafka на примере ADQM и ADS (Arenadata Streaming), который предоставляет сервис Kafka.
Обзор
Движок Kafka позволяет ClickHouse читать данные напрямую из топика Kafka и отслеживать поток сообщений, но каждое сообщение из таблицы Kafka можно получить только один раз. Как только данные запрашиваются из таблицы Kafka, они считаются уже полученными (consumed) из очереди и перед возвратом результата увеличивается смещение для потребителя (offset). Данные невозможно повторно считать без сброса этих смещений, поэтому не следует делать выборку данных из таблицы Kafka напрямую (через запрос SELECT) — вместо этого рекомендуется использовать материализованное представление. Такой подход предполагает создание следующих таблиц на стороне ClickHouse:
-
Таблица на базе движка Kafka — потребитель Kafka, который подписывается на топик и читает поток данных.
-
Целевая таблица с нужной структурой для постоянного хранения данных, полученных из Kafka. Обычно это таблица на базе движка семейства MergeTree.
-
Материализованное представление, которое в фоновом режиме собирает данные из таблицы Kafka (получает новые данные блоками при срабатывании триггера на вставку данных в таблицу Kafka), преобразует их в необходимый формат и помещает в заранее созданную целевую таблицу.
Иногда необходимо применять различные преобразования к данным, поступающим из Kafka — например, для хранения необработанных и агрегированных данных. В этом случае к одной таблице Kafka можно привязать несколько материализованных представлений, чтобы сохранять данные с разным уровнем детализации в несколько таблиц.
Чтобы записывать данные из ClickHouse в Kafka, можно вставлять их напрямую в таблицу на базе движка Kafka.
Табличный движок Kafka
Создание таблицы Kafka
Базовый синтаксис запроса для создания таблицы Kafka в ADQM:
CREATE TABLE <table_name> (<column_name> <column_type> [ALIAS <expr>], ...)
ENGINE = Kafka()
SETTINGS
kafka_broker_list = '<host_name>:9092,...',
kafka_topic_list = '<topic_name>,...',
kafka_group_name = '<consumer_group_name>',
kafka_format = '<data_format>'[,]
[kafka_schema = '',]
[kafka_num_consumers = <N>,]
[kafka_max_block_size = 0,]
[kafka_skip_broken_messages = <N>,]
[kafka_commit_every_batch = 0,]
[kafka_client_id = '',]
[kafka_poll_timeout_ms = 0,]
[kafka_poll_max_batch_size = 0,]
[kafka_flush_interval_ms = 0,]
[kafka_thread_per_consumer = 0,]
[kafka_handle_error_mode = 'default',]
[kafka_commit_on_select = false,]
[kafka_max_rows_per_message = 1];Табличный движок Kafka имеет следующие обязательные параметры. Эти параметры можно указывать в круглых скобках при создании таблицы (см. пример).
kafka_broker_list |
Список брокеров (разделяются запятыми) |
kafka_topic_list |
Список топиков Kafka (разделяются запятыми) |
kafka_group_name |
Группа потребителей Kafka. Смещения для чтения отслеживаются для каждой группы отдельно. Если нужно, чтобы сообщения в кластере не дублировались, используйте одно имя группы потребителей для всех таблиц Kafka |
kafka_format |
Формат сообщений Kafka. Для определения этого параметра используются такие же названия форматов, как для выражения |
kafka_schema |
Параметр, который необходимо использовать, если формат требует определения схемы. Например, CapnProto требует путь к файлу со схемой и название корневого объекта |
kafka_num_consumers |
Количество потребителей (consumer) на таблицу. По умолчанию: |
kafka_max_block_size |
Максимальный размер блока (в сообщениях) для poll. Значение по умолчанию равно значению параметра max_insert_block_size |
kafka_skip_broken_messages |
Максимальное количество допустимых некорректных (несовместимых со схемой) сообщений в блоке. Если |
kafka_commit_every_batch |
Включает или отключает режим коммита (commit) каждого принятого и обработанного пакета по отдельности вместо одного коммита после записи целого блока. Значение по умолчанию: |
kafka_client_id |
Идентификатор клиента. По умолчанию не указывается |
kafka_poll_timeout_ms |
Тайм-аут для одного опроса (poll) Kafka. Значение по умолчанию равно значению параметра stream_poll_timeout_ms |
kafka_poll_max_batch_size |
Максимальное количество сообщений, опрашиваемых в одном вызове опроса (poll) Kafka. Значение по умолчанию равно значению параметра max_block_size |
kafka_flush_interval_ms |
Тайм-аут для сброса данных из Kafka. Значение по умолчанию равно значению параметра stream_flush_interval_ms |
kafka_thread_per_consumer |
Включает или отключает предоставление отдельного потока каждому потребителю. При включенном режиме каждый потребитель сбрасывает данные независимо и параллельно, при отключенном — строки данных от нескольких потребителей собираются в один блок. Значение по умолчанию: |
kafka_handle_error_mode |
Способ обработки ошибок для движка Kafka. Возможные значения:
|
kafka_commit_on_select |
Включает или отключает коммит (commit) сообщений при выполнении запроса |
kafka_max_rows_per_message |
Максимальное количество строк в одном сообщении Kafka для форматов row-based. Значение по умолчанию: |
|
РЕКОМЕНДАЦИЯ
В реальных системах рекомендуется передавать параметры через именованные коллекции (named collections).
|
Расширенная настройка
В файле конфигурации ClickHouse можно указать дополнительные настройки для таблиц Kafka:
-
глобальные настройки в секции
<kafka>; -
настройки на уровне топика в секции
<kafka_topic>внутри тега<kafka>(имя топика указывается через параметр<name>).
Например, ведение журнала отладки (debug) для библиотеки Kafka (librdkafka) активируется с помощью следующего параметра в файле config.xml:
<kafka>
<debug>all</debug>
</kafka>Список всех возможных параметров конфигурации можно посмотреть в статье Configuration properties документации библиотеки librdkafka. В ADQM используйте нижнее подчеркивание вместо точки в названии параметра — например, <auto_offset_reset>latest</auto_offset_reset> вместо auto.offset.reset = latest.
Настройки для таблиц Kafka в ADQM можно указать через интерфейс ADCM. Для этого на странице конфигурации сервиса ADQMDB активируйте опцию Kafka engine и в поле Kafka Properties перечислите нужные параметры движка Kafka (соответствующие теги со значениями, без тега <kafka>).
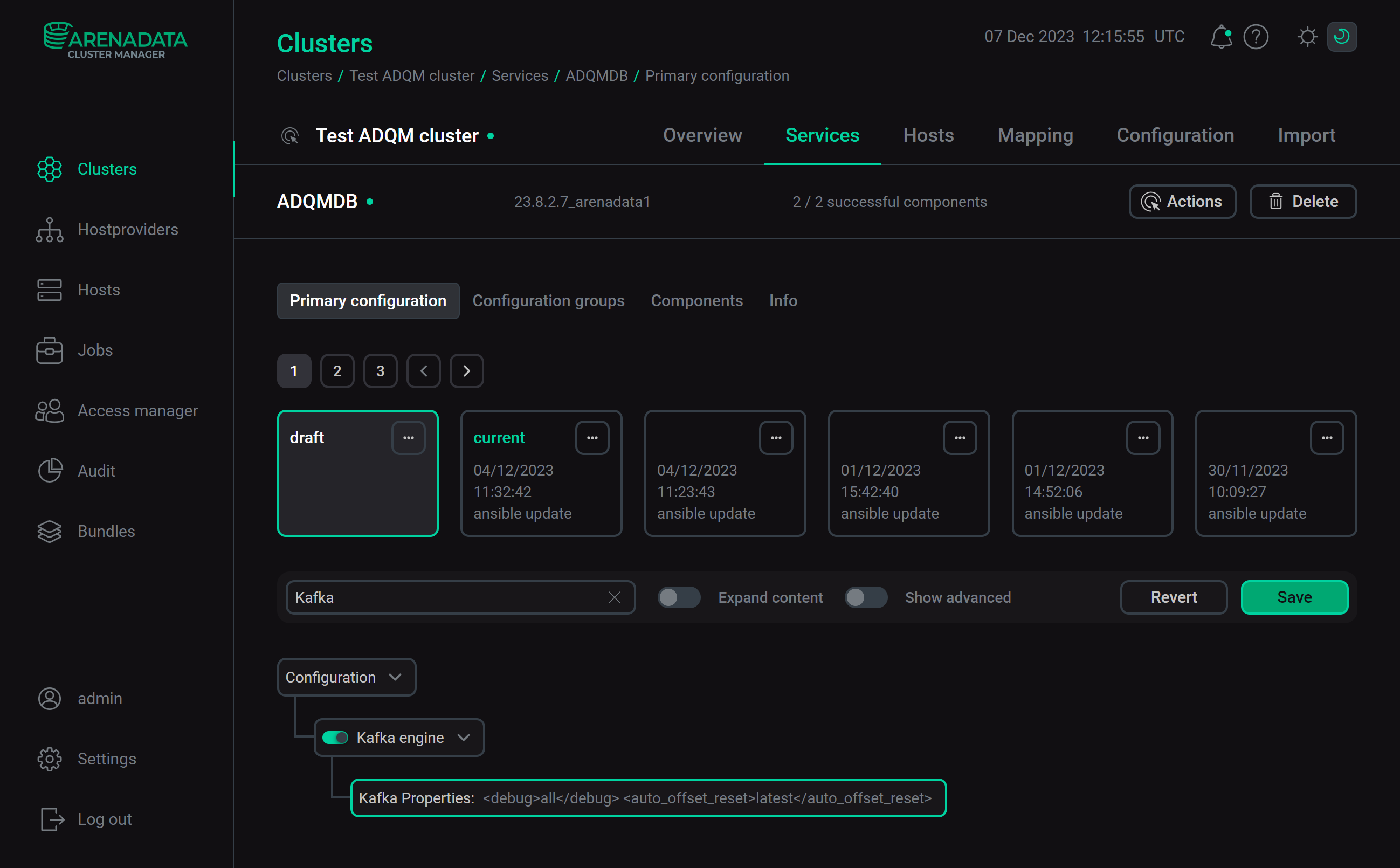
Нажмите Save и выполните действие Reconfig с опцией Restart для сервиса ADQMDB — после того, как выполнение действия завершится, секция <kafka> с указанными параметрами будет добавлена в файл config.xml.
Поддержка Kerberos
Для работы с Kafka с поддержкой Kerberos назначьте параметру security_protocol значение sasl_plaintext. Этого достаточно, если тикет выдачи тикетов Kerberos (ticket-granting ticket) получен и кешируется средствами операционной системы. ClickHouse может поддерживать учетные данные Kerberos с помощью файла keytab. Используйте также параметры sasl_kerberos_service_name, sasl_kerberos_keytab и sasl_kerberos_principal для настройки аутентификации через Kerberos — см. пример ниже.
Виртуальные столбцы
Иногда может быть полезно иметь метаданные сообщений Kafka при их загрузке в ClickHouse. Например, может потребоваться знать координаты потребленного сообщения в топике или сколько сообщений получено из определенного топика или партиции. Для этой цели движок Kafka предоставляет следующие виртуальные столбцы.
| Название столбца | Тип данных | Описание |
|---|---|---|
_topic |
LowCardinality(String) |
Топик Kafka |
_key |
String |
Ключ сообщения |
_offset |
UInt64 |
Смещение (offset) сообщения |
_timestamp |
Nullable(DateTime) |
Временная метка сообщения |
_timestamp_ms |
Nullable(DateTime64(3)) |
Временная метка сообщения в миллисекундах |
_partition |
UInt64 |
Партиция топика Kafka |
_headers.name |
Array(String) |
Массив ключей заголовков сообщений |
_headers.value |
Array(String) |
Массив значений заголовков сообщений |
_error |
String |
Текст исключения, которое было выдано, если сообщение не удалось обработать. Столбец заполняется, если параметр |
_raw_message |
String |
Cообщение, которое не удалось успешно обработать. Столбец заполняется, если параметр |
Чтобы получать значения виртуальных столбцов, необходимо добавить соответствующие столбцы в структуру целевой таблицы и указать их в выражении SELECT материализованного представления — см. пример ниже. Виртуальные столбцы в таблице Kafka создавать не нужно, так как они доступны автоматически.
Общие операции
Остановка и перезапуск потребления сообщений
Чтобы остановить получение сообщений из топика, отсоедините таблицу Kafka:
DETACH TABLE <kafka_engine_table>;Отсоединение таблицы Kafka не влияет на смещение для группы потребителей. Чтобы возобновить чтение данных и продолжить с предыдущего смещения, снова присоедините таблицу:
ATTACH TABLE <kafka_engine_table>;Изменение целевой таблицы
Если необходимо изменить целевую таблицу, рекомендуется следующая последовательность действий:
-
Отключите таблицу Kafka (
DETACH TABLE). -
Измените целевую таблицу (
ALTER TABLE). -
Удалите материализованное представление, чтобы избежать несоответствия между измененной целевой таблицей и данными из представления (
DROP VIEW). -
Снова присоедините таблицу Kafka (
ATTACH TABLE). -
Пересоздайте материализованное представление (
CREATE MATERIALIZED VIEW).
Пример
Создание топика Kafka в ADS
Подключитесь к любому хосту кластера ADS, на котором установлен сервис Kafka. Перейдите в корневую директорию со скриптами для выполнения команд в среде Kafka (файлы c расширением .sh) и следуйте инструкциям ниже.
-
Создайте топик
topic-kafka-to-adqmс помощью следующей команды (замените<kafka_host>на имя хоста ADS, где создается топик):$ bin/kafka-topics.sh --create --topic topic-kafka-to-adqm --bootstrap-server <kafka_host>:9092Результат:
Created topic topic-kafka-to-adqm.
ПРИМЕЧАНИЕДополнительную информацию о создании и чтении топиков в Kafka можно получить в статье документации ADS Начало работы c Kafka.
-
Запишите тестовые сообщения в топик следующим образом.
Выполните команду, которая запускает режим записи сообщений:
$ bin/kafka-console-producer.sh --topic topic-kafka-to-adqm --bootstrap-server <kafka_host>:9092На следующей строке после ввода команды введите сообщения, каждое на новой строке (используйте
Enterдля перехода на новую строку):>1,"one" >2,"two" >3,"three"Чтобы выйти из режима записи сообщений, перейдите на следующую строку после записи последнего сообщения и нажмите
Ctrl+C.
Создание таблиц в ADQM для интеграции с Kafka
На хосте ADQM запустите консольный клиент clickhouse-client и выполните следующие шаги.
-
Создайте таблицу на базе движка Kafka:
CREATE TABLE kafka_table (id Int32, name String) ENGINE = Kafka ('<kafka_host>:9092', 'topic-kafka-to-adqm', 'clickhouse', 'CSV'); -
Создайте целевую таблицу, в которую будут сохраняться данные:
CREATE TABLE kafka_data (id Int32, name String) ENGINE = MergeTree() ORDER BY id; -
Создайте материализованное представление, которое будет получать данные из таблицы Kafka и помещать их в целевую таблицу MergeTree:
CREATE MATERIALIZED VIEW kafka_data_mv TO kafka_data AS SELECT id, name FROM kafka_table;В момент создания материализованное представление подключается к таблице Kafka, начинает чтение данных и вставку строк в целевую таблицу. Этот процесс продолжаться постоянно — все последующие вставки сообщений в топик Kafka будут считываться.
Чтение данных из Kafka
-
Убедитесь, что данные Kafka вставлены в целевую таблицу:
SELECT * FROM kafka_data;┌─id─┬─name──┐ │ 1 │ one │ │ 2 │ two │ │ 3 │ three │ └────┴───────┘
-
Вставьте новые сообщения в топик Kafka (на хосте ADS):
$ bin/kafka-console-producer.sh --topic topic-kafka-to-adqm --bootstrap-server <kafka_host>:9092>4,"four" >5,"five" -
Проверьте, что новые данные попали в таблицу ADQM:
SELECT * FROM kafka_data;┌─id─┬─name──┐ │ 1 │ one │ │ 2 │ two │ │ 3 │ three │ │ 4 │ four │ │ 5 │ five │ └────┴───────┘
Вставка данных из ADQM в Kafka
-
На хосте ADQM вставьте данные в таблицу на базе движка Kafka:
INSERT INTO kafka_table VALUES (6, 'six'); -
На хосте ADS проверьте, что соответствующее сообщение записалось в топик Kafka:
$ bin/kafka-console-consumer.sh --topic topic-kafka-to-adqm --from-beginning --bootstrap-server <kafka_host>:90921,"one" 2,"two" 3,"three" 4,"four" 5,"five" 6,"six"
-
Убедитесь также, что новые данные записались в целевую таблицу ADQM с данными Kafka:
SELECT * FROM kafka_data;┌─id─┬─name──┐ │ 1 │ one │ │ 2 │ two │ │ 3 │ three │ │ 4 │ four │ │ 5 │ five │ │ 6 │ six │ └────┴───────┘
Изменение целевой таблицы
Чтобы целевая таблица включала метаинформацию о сохраняемых в нее сообщениях Kafka (например, название топика и смещение сообщения), сделайте следующие изменения.
-
Отключите таблицу Kafka:
DETACH TABLE kafka_table; -
Добавьте в целевую таблицу столбцы
topicиoffset:ALTER TABLE kafka_data ADD COLUMN topic String, ADD COLUMN offset UInt64; -
Удалите материализованное представление:
DROP VIEW kafka_data_mv; -
Снова подключите таблицу Kafka:
ATTACH TABLE kafka_table; -
Пересоздайте материализованное представление:
CREATE MATERIALIZED VIEW kafka_data_mv TO kafka_data AS SELECT id, name, _topic as topic, _offset as offset FROM kafka_table;
Теперь для новых сообщений, поступающих в целевую таблицу ADQM, в столбцах topic и offset будет показываться название топика Kafka и смещение сообщения в партиции. Чтобы это проверить:
-
Вставьте новое сообщение в топик Kafka на хосте ADS:
$ bin/kafka-console-producer.sh --topic topic-kafka-to-adqm --bootstrap-server <kafka_host>:9092>7,"seven" -
Запросите данные из таблицы
kafka_dataв ADQM:SELECT * FROM kafka_data;┌─id─┬─name──┐ │ 1 │ one │ │ 2 │ two │ │ 3 │ three │ │ 4 │ four │ │ 5 │ five │ │ 6 │ six │ └────┴───────┘ ┌─id─┬─name──┬─topic───────────────┬─offset─┐ │ 7 │ seven │ topic-kafka-to-adqm │ 6 │ └────┴───────┴─────────────────────┴────────┘
Пример подключения ADQM к Kafka с установленным Kerberos SASL
Настройка ADS
-
Выполните настройку MIT Kerberos KDC на отдельном хосте и проведите керберизацию кластера ADS, следуя инструкции MIT Kerberos. В качестве имени realm используйте
ADS-KAFKA.LOCAL. -
Убедитесь в корректной настройке аутентификации для сервиса Kafka, выполнив шаги из раздела Проверка установленного Kerberos SASL.
-
Создайте принципал для аутентификации в Kafka (например,
ads_user). Для этого выполните следующую команду на хосте, где развернут MIT Kerberos KDC:$ sudo kadmin.local -q "add_principal -pw PASSWORD ads_user@ADS-KAFKA.LOCAL" -
На стороне ADS настройте для пользователя JAAS-файл /tmp/client.jaas и файл конфигурации /tmp/client.properties — см. описание в соответствующих разделах статьи Использование MIT Kerberos в Kafka.
Создание топика в ADS
Создайте тестовый топик, к которому будет подключаться ADQM для чтения/записи сообщений. Для этого на хосте ADS последовательно выполните описанные ниже шаги:
-
Создайте тикет на предоставление тикетов (Ticket-Granting Ticket, TGT) для принципала
ads_user:$ kinit -p ads_user@ADS-KAFKA.LOCALВведите пароль, указанный при создании принципала — в данном примере
PASSWORD. -
Экспортируйте созданный файл client.jaas как параметр JVM для данного пользователя с помощью переменной среды
KAFKA_OPTS:$ export KAFKA_OPTS="-Djava.security.auth.login.config=/tmp/client.jaas" -
Создайте топик (например,
topic-adqm-to-kafka-kerberos), указав путь к созданному файлу client.properties:$ /usr/lib/kafka/bin/kafka-topics.sh \ --create --topic topic-adqm-to-kafka-kerberos \ --bootstrap-server <kafka_host1>:9092,<kafka_host2>:9092,<kafka_host3>:9092 \ --command-config /tmp/client.propertiesЗамените
<kafka_host1>,<kafka_host2>,<kafka_host3>на имена хостов ADS, где создается топик. -
Запишите несколько сообщений в топик, также указав путь к файлу client.properties:
$ /usr/lib/kafka/bin/kafka-console-producer.sh \ --topic topic-adqm-to-kafka-kerberos \ --bootstrap-server <kafka_host1>:9092,<kafka_host2>:9092,<kafka_host3>:9092 \ --producer.config /tmp/client.properties>1,"one" >2,"two" >3,"three"Для выхода из режима записи сообщений перейдите на следующую строку после записи последнего сообщения и нажмите
Ctrl+C.
Создание принципала для подключения ADQM к Kafka
-
На хосте, где развернут MIT Kerberos KDC, создайте новый принципал
adqm_user, который будет использовать ADQM для подключения к Kafka:$ sudo kadmin.local -q "add_principal -randkey adqm_user@ADS-KAFKA.LOCAL" -
Создайте для этого принципала keytab-файл:
$ sudo kadmin.local -q "xst -kt /tmp/adqm_user.keytab adqm_user@ADS-KAFKA.LOCAL" -
Скопируйте keytab-файл /tmp/adqm_user.keytab на хосты ADQM (например, в директорию /tmp).
На хосте ADQM назначьте
clickhouseвладельцем keytab-файла и ограничьте доступ к файлу в целях безопасности:$ sudo chown clickhouse:clickhouse /tmp/adqm_user.keytab $ sudo chmod 0600 /tmp/adqm_user.keytab
Настройка ADQM
-
На странице конфигурации сервиса ADQMDB включите Kafka engine и введите в поле Kafka Properties следующие параметры:
<security_protocol>SASL_PLAINTEXT</security_protocol> <sasl_mechanism>GSSAPI</sasl_mechanism> <sasl_kerberos_service_name>kafka</sasl_kerberos_service_name> <sasl_kerberos_keytab>/tmp/adqm_user.keytab</sasl_kerberos_keytab> <sasl_kerberos_principal>adqm_user@ADS-KAFKA.LOCAL</sasl_kerberos_principal>Нажмите Save и выполните действие Reconfig с опцией Restart для сервиса ADQMDB.
-
Установите необходимые пакеты на хосте кластера ADQM:
$ sudo yum install krb5-libs krb5-workstation -
Также на хосте ADQM отредактируйте файл /etc/krb5.conf, изменив его содержимое следующим образом (замените
<kdc_host>на имя хоста с установленным MIT Kerberos KDC):# Configuration snippets may be placed in this directory as well includedir /etc/krb5.conf.d/ [logging] default = FILE:/var/log/krb5libs.log kdc = FILE:/var/log/krb5kdc.log admin_server = FILE:/var/log/kadmind.log [libdefaults] dns_lookup_realm = false ticket_lifetime = 24h forwardable = true rdns = false pkinit_anchors = FILE:/etc/pki/tls/certs/ca-bundle.crt default_realm = ADS-KAFKA.LOCAL [realms] ADS-KAFKA.LOCAL = { admin_server = <kdc_host> kdc = <kdc_host> } [domain_realm] .ads-kafka.local = ADS-KAFKA.LOCAL ads-kafka.local = ADS-KAFKA.LOCAL
Создание таблиц в ADQM
На хосте ADQM в консольном клиенте clickhouse-client создайте таблицы для интеграции с Kafka:
-
Таблица на базе движка Kafka:
CREATE TABLE adqm_to_ads_kerberos_kafka (id Int32, name String) ENGINE = Kafka ('<kafka_host1>:9092,<kafka_host2>:9092,<kafka_host3>:9092', 'topic-adqm-to-kafka-kerberos', 'clickhouse_group', 'CSV'); -
Целевая таблица, в которую будут сохраняться данные:
CREATE TABLE adqm_to_ads_kerberos_data (id Int32, name String) ENGINE = MergeTree() ORDER BY id; -
Материализованное представление, которое будет получать данные из таблицы Kafka и помещать их в целевую таблицу MergeTree:
CREATE MATERIALIZED VIEW adqm_to_ads_kerberos_data_mv TO adqm_to_ads_kerberos_data AS SELECT id, name FROM adqm_to_ads_kerberos_kafka;
Проверка подключения ADQM к Kafka
-
Проверьте, что данные из топика Kafka вставлены в целевую таблицу ADQM:
SELECT * FROM adqm_to_ads_kerberos_data;┌─id─┬─name──┐ 1. │ 1 │ one │ 2. │ 2 │ two │ 3. │ 3 │ three │ └────┴───────┘
-
Вставьте строку данных в таблицу ADQM на движке Kafka:
INSERT INTO adqm_to_ads_kerberos_kafka VALUES (4, 'four'); -
Убедитесь, что соответствующее сообщение успешно получено на стороне кластера ADS:
$ /usr/lib/kafka/bin/kafka-console-consumer.sh \ --topic topic-adqm-to-kafka-kerberos \ --from-beginning \ --bootstrap-server <kafka_host1>:9092,<kafka_host2>:9092,<kafka_host3>:9092 \ --consumer.config /tmp/client.properties1,"one" 2,"two" 3,"three" 4,"four"