

ClickHouse Keeper
Чтобы использовать ClickHouse Keeper для репликации данных и распределения запросов в ADQM, можно:
-
установить ClickHouse Keeper в кластер ADQM как отдельный сервис;
-
использовать ClickHouse Keeper, интегрированный в сервер ClickHouse.
ClickHouse Keeper как сервис ADQM
Если необходимо разместить ClickHouse Keeper на выделенных хостах, установите ClickHouse Keeper как отдельный сервис в кластер ADQM. Для этого выполните следующие шаги в интерфейсе ADCM:
-
Добавьте сервис Clickhouse Keeper в кластер ADQM.
-
Установите компонент Clickhouse Keeper Server на нечетное количество хостов.
-
Настройте параметры сервиса Clickhouse Keeper (см. список и описания доступных параметров сервиса в статье Конфигурационные параметры).
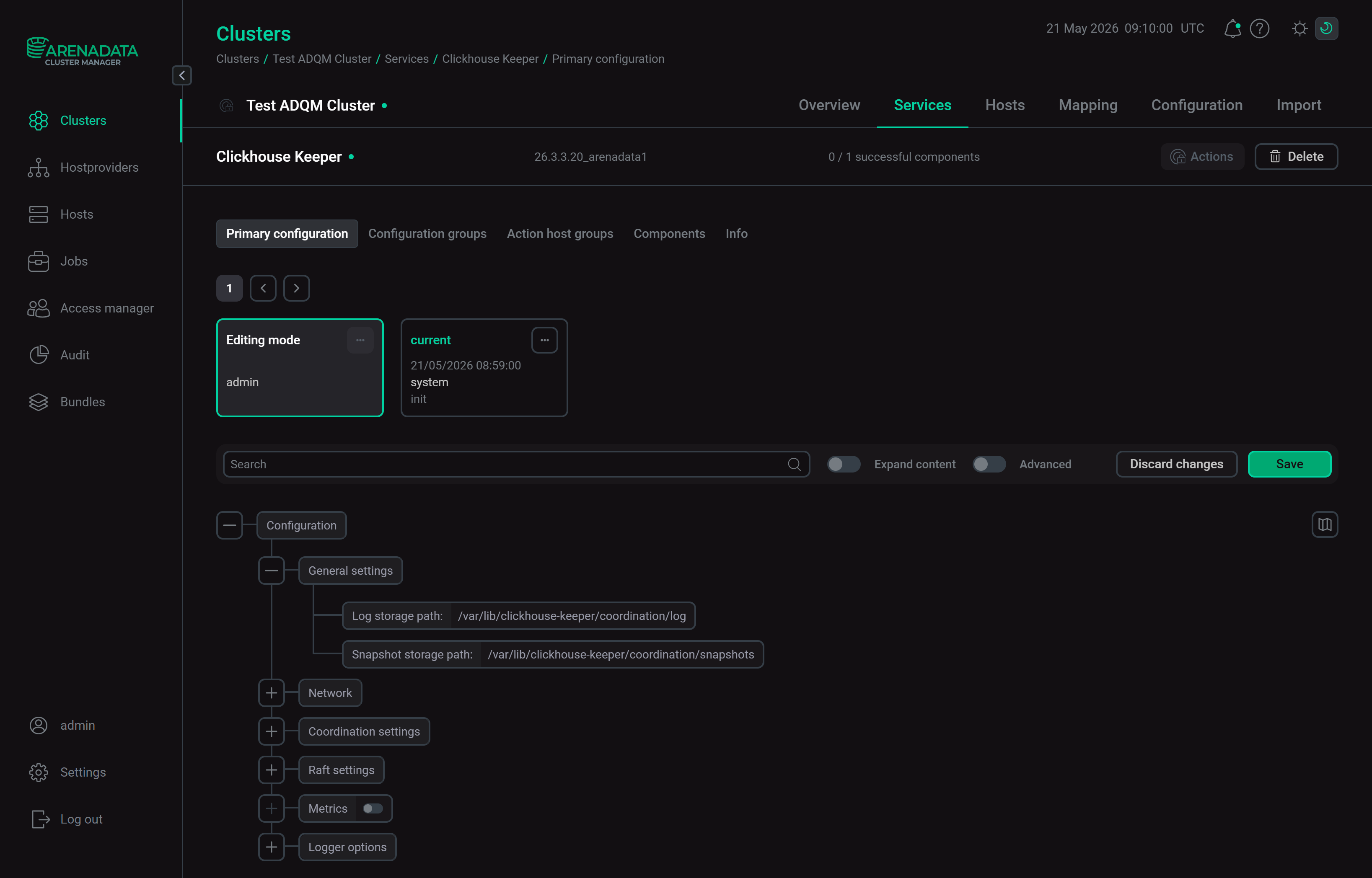 Конфигурационные параметры сервиса Clickhouse Keeper
Конфигурационные параметры сервиса Clickhouse KeeperНажмите Save, чтобы сохранить настройки.
-
Если осуществляется перевод кластера с ZooKeeper, на этом этапе необходимо вручную перенести данные из ZooKeeper в ClickHouse Keeper. Снепшоты и логи в ClickHouse Keeper имеют несовместимые с ZooKeeper форматы, поэтому данные нужно сначала сконвертировать (см. раздел Migration from ZooKeeper в документации ClickHouse).
-
На странице конфигурации сервиса ADQMDB установите значение
chkeeper_allocatedдля параметра Coordination system.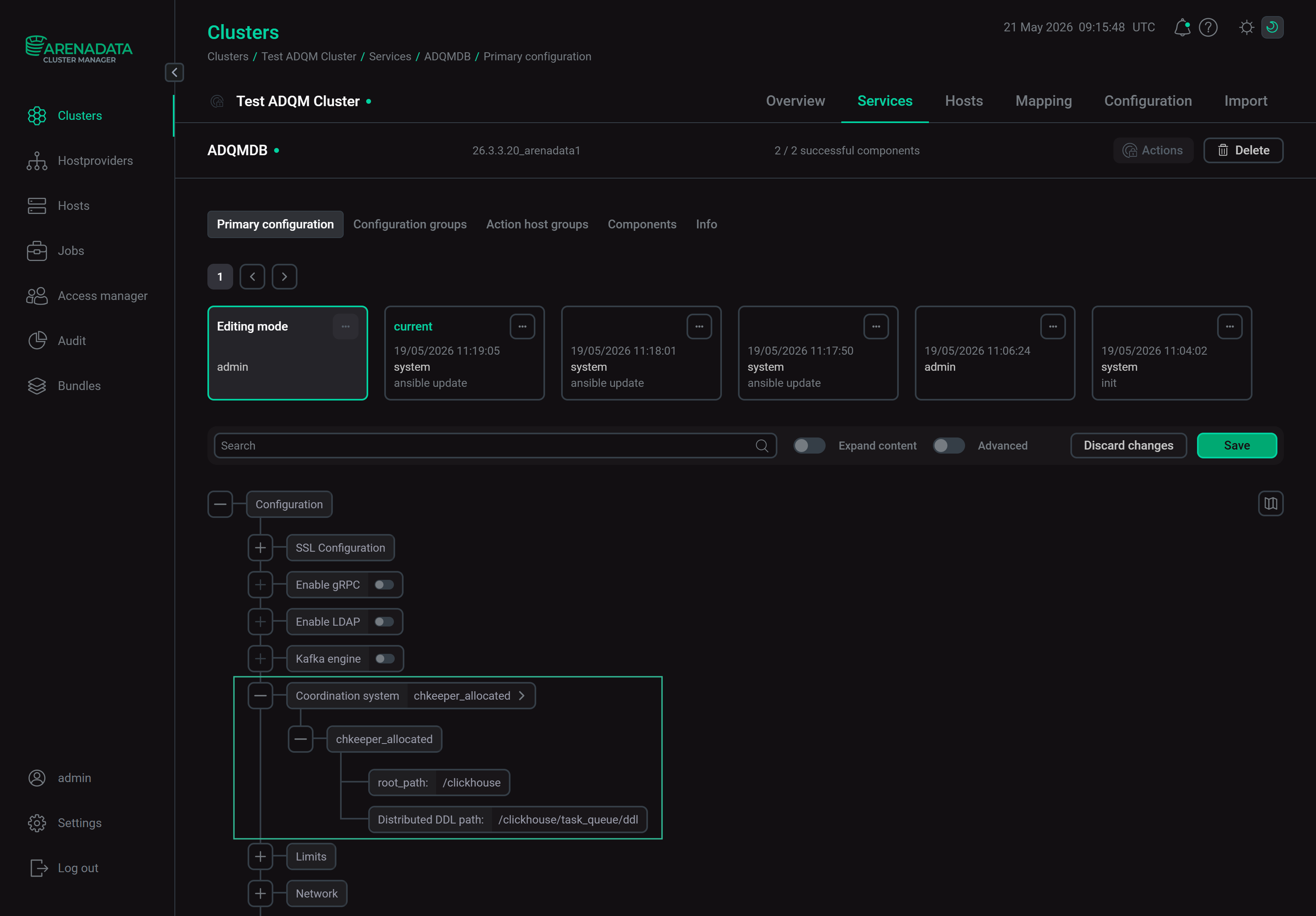 Включение сервиса Clickhouse Keeper
Включение сервиса Clickhouse KeeperВо вложенной группе параметров chkeeper_allocated можно настроить znode-пути.
-
Нажмите Save и выполните действие Reconfig для сервиса ADQMDB, чтобы включить использование установленного ClickHouse Keeper в качестве сервиса координации для кластера ADQM.
|
ПРИМЕЧАНИЕ
Чтобы переустановить ClickHouse Keeper на другие хосты кластера, можно использовать действие сервиса Clickhouse Keeper Add/Remove components. После выполнения этого действия необходимо запустить действие Reconfig для сервиса ADQMDB, чтобы применить изменения. |
Интегрированный ClickHouse Keeper
Если нет требования контролировать, на каких хостах установлен ClickHouse Keeper (например, в тестовых или небольших кластерах), можно использовать внутренний ClickHouse Keeper — ADQM автоматически его сконфигурирует и развернет на хостах, где установлен компонент Clickhouse Server. Для этого в интерфейсе ADCM:
-
Установите значение
chkeeper_integratedдля параметра Coordination system на странице конфигурации сервиса ADQMDB. Настройки во вложенной секции chkeeper_integrated будут заполнены автоматически на основе параметров сервера ClickHouse. При необходимости значения параметров можно изменить (см. описания параметров в статье Конфигурационные параметры).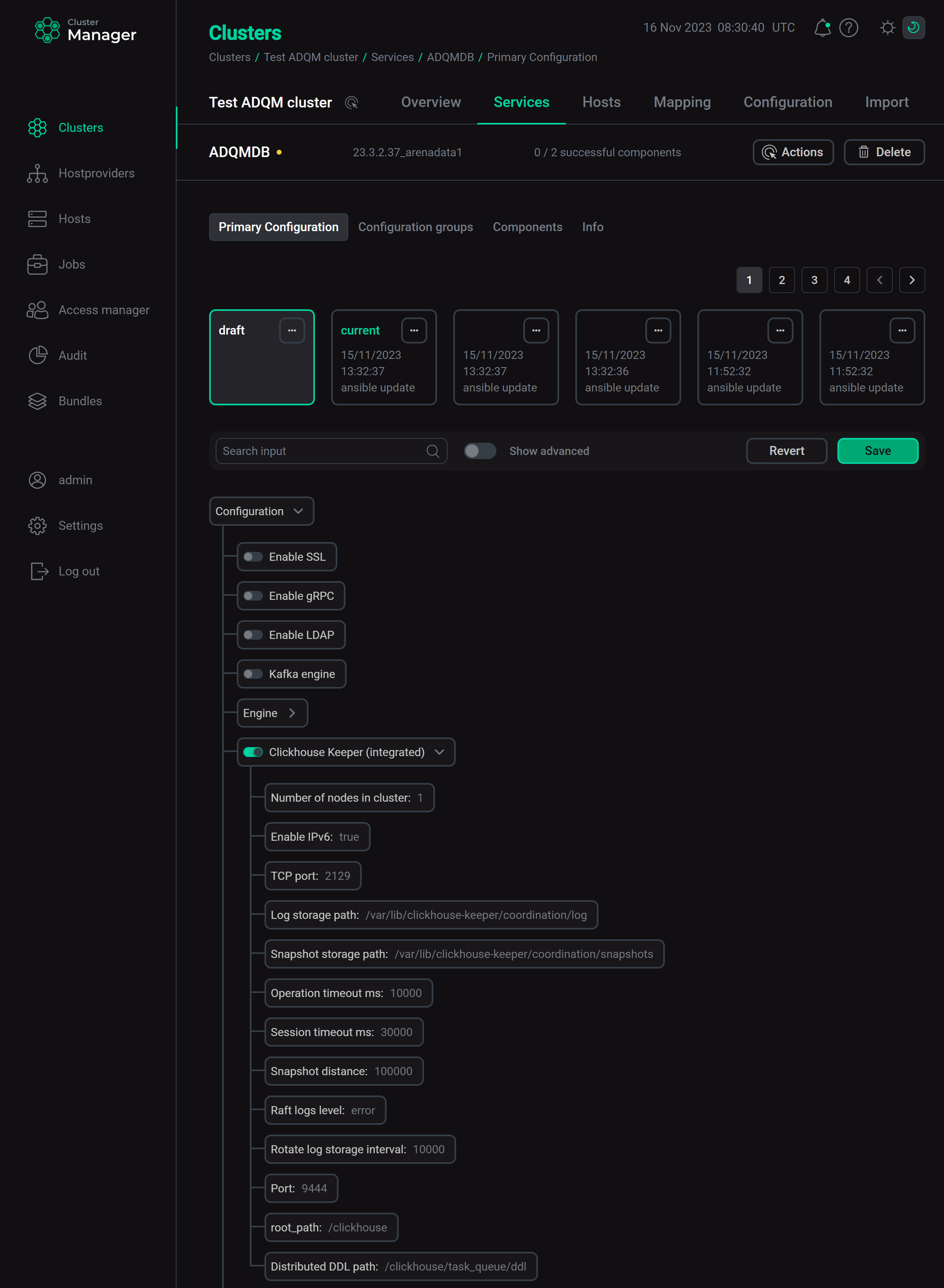 Настройка и включение интегрированного ClickHouse Keeper
Настройка и включение интегрированного ClickHouse Keeper -
Нажмите Save и выполните действие Reconfig для сервиса ADQMDB, чтобы развернуть внутренний ClickHouse Keeper и включить его использование в качестве сервиса координации для кластера ADQM.
Пример тестирования реплицируемых и распределенных таблиц
Конфигурирование кластера ADQM c ClickHouse Keeper
-
Сконфигурируйте тестовый кластер — два шарда, в каждом по две реплики (в данном примере используются хосты host-1, host-2, host-3 и host-4). В статье Конфигурирование логических кластеров в интерфейсе ADCM описано, как это сделать через интерфейс ADCM. В этом случае все необходимые секции (описанные ниже) добавятся в конфигурационный файл каждого сервера автоматически.
-
Конфигурация логического кластера
В файле config.xml конфигурация логического кластера описывается в секции
remote_servers:<remote_servers> <default_cluster> <shard> <internal_replication>true</internal_replication> <weight>1</weight> <replica> <host>host-1</host> <port>9000</port> </replica> <replica> <host>host-2</host> <port>9000</port> </replica> </shard> <shard> <internal_replication>true</internal_replication> <weight>1</weight> <replica> <host>host-3</host> <port>9000</port> </replica> <replica> <host>host-4</host> <port>9000</port> </replica> </shard> </default_cluster> </remote_servers>В данном примере будет использоваться реплицируемая таблица ReplicatedMergeTree, поэтому параметр
internal_replicationдля каждого шарда устанавливается вtrue— в этом случае репликацию данных будет выполнять реплицируемая таблица (то есть данные будут записываться в любую доступную реплику, другая реплика получит данные автоматически). Если бы использовались обычные таблицы, то параметрinternal_replicationнадо было бы установить вfalse, чтобы репликацию данных выполняла таблица Distributed (данные будут записываться на все реплики шарда). -
Макросы
В настройках каждого сервера должна также присутствовать секция
macros, в которой определяются идентификаторы шарда и реплики для автоматической подстановки соответствующих хосту значений при создании реплицируемых таблиц на кластере (ON CLUSTER). Например, макросы для host-1 в кластереdefault_cluster:<macros> <replica>1</replica> <shard>1</shard> </macros>Если вы настраиваете логический кластер в интерфейсе ADCM через параметр Cluster Configuration и указываете имя кластера, например,
abc, то ADQM автоматически пропишет в config.xml макросы следующего вида (для host-1 в составе кластераabc, топология которого аналогична приведенной выше):<macros> <abc_replica>1</abc_replica> <abc_shard>1</abc_shard> </macros>В этом случае при создании реплицируемых таблиц нужно будет использовать переменные
{abc_shard}и{abc_replica}в параметрах ReplicatedMergeTree.
-
-
Установите сервис Clickhouse Keeper на 3 хоста (host-1, host-2, host-3). После этого в конфигурационный файл config.xml добавятся секции:
-
zookeeper— список узлов ClickHouse Keeper; -
distributed_ddl— путь в ClickHouse Keeper для очереди DDL-запросов (если несколько кластеров используют один и тот же ClickHouse Keeper, этот путь должен быть уникальным для каждого кластера).
<zookeeper> <node> <host>host-1</host> <port>2129</port> </node> <node> <host>host-2</host> <port>2129</port> </node> <node> <host>host-3</host> <port>2129</port> </node> <root>/clickhouse</root> </zookeeper> <distributed_ddl> <path>/clickhouse/task_queue/ddl</path> </distributed_ddl> -
Реплицируемые таблицы
-
Создайте реплицируемую таблицу, выполнив следующий запрос на одном из хостов (например, на хосте host-1):
CREATE TABLE test_local ON CLUSTER default_cluster (id Int32, value_string String) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test_local', '{replica}') ORDER BY id;Этот запрос создаст таблицу
test_localна всех хостах кластераdefault_cluster. -
Зайдите на хост host-2 и вставьте данные в таблицу:
INSERT INTO test_local VALUES (1, 'a'); -
Убедитесь, что данные реплицируются. Для этого выполните выборку данных из таблицы
test_localна хосте host-1:SELECT * FROM test_local;Если все работает правильно, в таблицу на хосте host-1 автоматически скопируются данные, которые были записаны в реплику на хосте host-2:
┌─id─┬─value_string─┐ │ 1 │ a │ └────┴──────────────┘
Распределенные таблицы
Обратите внимание, запрос SELECT возвращает данные только из таблицы на том хосте, на котором выполняется запрос.
Вставьте данные в любую реплику на второй шард (например, в таблицу на хосте host-3):
INSERT INTO test_local VALUES (2, 'b');Повторите запрос SELECT на хосте host-1 или host-2 — данные со второго шарда не попадают в выборку:
┌─id─┬─value_string─┐ │ 1 │ a │ └────┴──────────────┘
Чтобы получать данные со всех шардов, можно использовать распределенные таблицы (см. подробную информацию в разделе Распределенные таблицы).
-
Создайте таблицу на движке Distributed:
CREATE TABLE test_distr ON CLUSTER default_cluster AS default.test_local ENGINE = Distributed(default_cluster, default, test_local, rand()); -
Выполните следующий запрос на любом хосте:
SELECT * FROM test_distr;В результирующую выборку включены данные с обоих шардов кластера:
┌─id─┬─value_string─┐ │ 1 │ a │ └────┴──────────────┘ ┌─id─┬─value_string─┐ │ 2 │ b │ └────┴──────────────┘