

Data compression
Data compression plays an important role in achieving high performance for ADQM. For example, you can use compression to reduce the amount of data to be read when executing a query and speed up this query — see the example in the Improve query performance article.
ADQM supports data compression for the following table engines:
-
MergeTree — you can set a default compression algorithm for tables, as well as specify a compression method (or a combination of them) for an individual column when creating/modifying a table (see Apply compression codecs below).
-
Log — uses the LZ4 compression method by default and supports column-level compression.
Data compression codecs
A codec defines a compression method applied to ADQM data. The following data compression codecs are available in ADQM:
-
General-purpose codecs that allow you to find the optimal balance between the consumption of disk space and CPU resources.
-
Specialized codecs for specific data types. Some of these codecs do not compress data themselves but preprocess it (taking into account data characteristics) for general-purpose codecs, which in turn compress prepared data more efficiently than unprepared data.
General-purpose codecs
| Codec | Compression algorithm | Compression level |
|---|---|---|
NONE |
No compression |
— |
LZ4 |
The LZ4 lossless compression algorithm. Provides both high speed and good compression ratio. Used by default |
— |
LZ4HC[(level)] |
The LZ4 HC (high compression) algorithm with a configurable compression level. In comparison with LZ4, it compresses data better, but slower (decompression is still fast) |
Possible compression levels — |
ZSTD[(level)] |
The ZSTD compression algorithm. Provides both speed and a high compression ratio that can be tuned. ZSTD used without a specialized codec often outperforms other compression methods or at least competitive |
Possible compression levels — Compression levels above |
ZSTD_QAT[(level)] |
The ZSTD compression algorithm with a configurable compression level, implemented by Intel QATlib and Intel QAT ZSTD Plugin. Limitations:
|
Possible compression levels — |
DEFLATE_QPL |
The Deflate compression algorithm implemented by Intel Query Processing Library (Intel QPL). Limitations:
Technical support for this codec in ADQM is limited |
— |
Specialized codecs
| Codec | Description | Parameters |
|---|---|---|
Delta(delta_bytes) |
Replaces raw values with the difference (delta) of two neighboring values (except for the first value that remains unchanged). Works well with monotonically increasing data. Delta is a codec for data preparation, and it cannot be used stand-alone (in other words, it should be followed by some compression codec) |
|
DoubleDelta(bytes_size) |
Calculates the difference between neighboring delta values and stores it in compact binary form. An optimal compression ratio can be achieved for a monotonic sequence with a constant stride (such as time series data). Can be used with any fixed-length data type. Implements the algorithm used in Gorilla TSDB, extending it to support 64-bit data types. Uses 1 extra bit for 32-bit deltas: 5-bit prefixes instead of 4-bit prefixes. For more information, see Compressing Time Stamps in the Gorilla: A Fast, Scalable, In-Memory Time Series Database article. DoubleDelta is a codec for data preparation and it cannot be used stand-alone (in other words, it should be followed by some compression codec) |
Possible values for |
GCD |
Calculates the greatest common denominator (GCD) of the values in a column, then divides each value by the GCD. Can be used with integer, decimal, and date/time columns. The codec is well suited for columns whose values change (increase or decrease) in multiples of GCD — for example, GCD is a codec for data preparation, and it cannot be used stand-alone (in other words, it should be followed by some compression codec) |
— |
Gorilla(bytes_size) |
Calculates XOR between the current and previous floating point value and writes it in compact binary form. The smaller the difference between consecutive values (that is, the slower the values in a series change), the better the compression ratio. Implements the algorithm used in Gorilla TSDB, extending it to support 64-bit types. For more information, see Compressing values in the Gorilla: A Fast, Scalable, In-Memory Time Series Database article |
Possible values for |
FPC(level, float_size) |
Repeatedly predicts the next floating point value in the sequence using the better of two predictors, then calculates the XOR of the actual value with the predicted value, and compresses the result with a leading zero. Similar to Gorilla, FPC efficiently stores series of slowly changing floating point values. For 64-bit values, FPC is faster than Gorilla; for 32-bit values, the estimate may vary. For a detailed description of the algorithm, refer to High Throughput Compression of Double-Precision Floating-Point Data |
Possible values for the Possible values for |
T64 |
Crops unused high bits of integer values (including Enum, Date, and DateTime). At each step of the algorithm, the codec places a block of 64 values into a 64x64 bit matrix, transposes it, crops the unused bits of values, and returns the rest as a sequence. Unused bits are the bits that do not differ between maximum and minimum values in the whole data part for which the compression is used |
— |
The DoubleDelta and Gorilla codecs are used in Gorilla TSDB as components of its compression algorithm. The Gorilla approach is effective in scenarios when data is a sequence of slowly changing values with their timestamps. Timestamps are effectively compressed by the DoubleDelta codec, and values are effectively compressed by the Gorilla codec.
Apply compression codecs
At the server level
By default, ADQM applies the compression method defined in the server configuration to columns of MergeTree tables. You can change the default compression settings in the Data compression section on the configuration page of the ADQMDB service. This section becomes visible when the Show advanced option is enabled. To access and apply configuration parameters, turn on the Data compression switch.
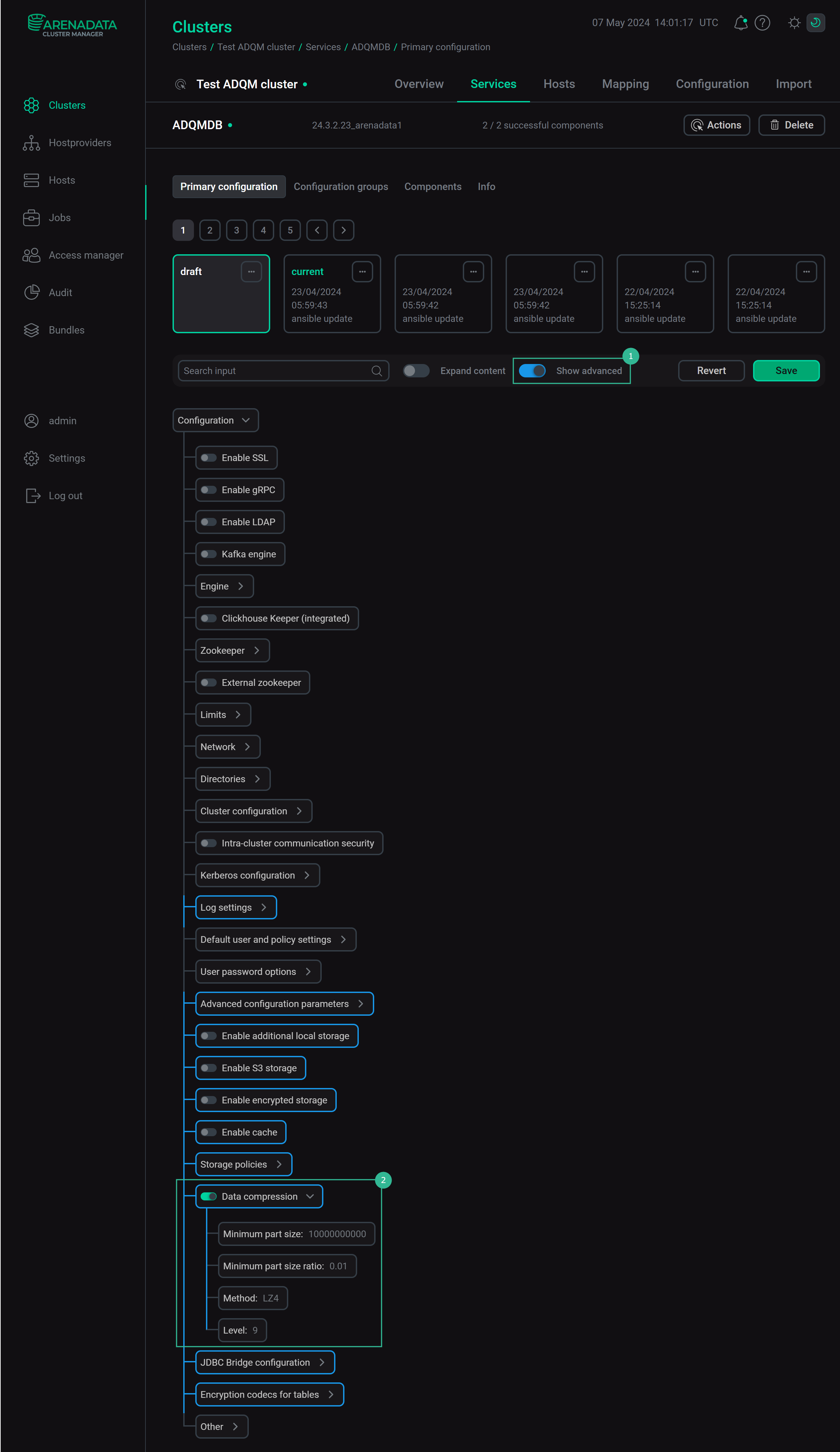
After you have specified the data compression parameters, click Save and run the Reconfig action for the ADQMDB service.
|
NOTE
Changing the default compression settings does not affect existing tables. |
At the column level
You can also set up the compression method for each column separately in the CREATE TABLE query using the CODEC clause:
CREATE TABLE <table_name>
( <column_name1> <data_type1> CODEC(<compression_codec1>) [...],
<column_name2> <data_type2> CODEC(<compression_codec2>) [...],
...)
ENGINE = MergeTree()
...;If the Default codec is assigned to a column (CODEC(Default)) or no codec is specified, the default compression algorithm set at the server level is used.
Codecs can be combined sequentially — for example, when using a specialized codec to prepare data for more efficient compression by a general-purpose codec (CODEC(Delta, ZSTD)).
For an existing table, you can change the compression codec of a column using the following query:
ALTER TABLE <table_name> MODIFY COLUMN <column_name> CODEC(<new_compression_codec>);General recommendations
There are some recommendations on how to get the maximum performance when using data compression:
-
Choose the most suitable compression algorithm for a specific task, taking into account the type and characteristics of your data (if known).
-
When specifying a compression level, remember that the bigger that value is — the more (but slower) the compression is. In fact, data compression allows you to improve I/O performance and reduce data size at the expense of CPU. Try to find the optimal settings — to avoid long compression times or slow scan rates.
-
The final performance of compressed append-optimized tables depends on many factors, such as hardware, query tuning parameters, etc. You should perform comparison testing to determine whether data compression is useful in your environment.
|
TIP
It is recommended to always balance between the available CPU resources and the required compression speed.
|
Example
Create a MergeTree table with Int64 and Float64 columns using the LZ4 and ZSTD data compression codecs in combination with various specialized codecs for preprocessing data:
CREATE TABLE compression_test (
n Int32,
i64 Int64 DEFAULT n CODEC(NONE),
i64_lz4 Int64 DEFAULT n CODEC(LZ4),
i64_delta_lz4 Int64 DEFAULT n CODEC(Delta, LZ4),
i64_doubledelta_lz4 Int64 DEFAULT n CODEC(DoubleDelta, LZ4),
i64_t64_lz4 Int64 DEFAULT n CODEC(T64, LZ4),
i64_zstd Int64 DEFAULT n CODEC(ZSTD),
i64_delta_zstd Int64 DEFAULT n CODEC(Delta, ZSTD),
i64_doubledelta_zstd Int64 DEFAULT n CODEC(DoubleDelta, ZSTD),
i64_t64_zstd Int64 DEFAULT n CODEC(T64, ZSTD),
f64 Float64 DEFAULT n CODEC(NONE),
f64_lz4 Float64 DEFAULT n CODEC(LZ4),
f64_delta_lz4 Float64 DEFAULT n CODEC(Delta, LZ4),
f64_doubledelta_lz4 Float64 DEFAULT n CODEC(DoubleDelta, LZ4),
f64_gorilla_lz4 Float64 DEFAULT n CODEC(Gorilla, LZ4),
f64_fpc_lz4 Float64 DEFAULT n CODEC(FPC, LZ4),
f64_zstd Float64 DEFAULT n CODEC(ZSTD),
f64_delta_zstd Float64 DEFAULT n CODEC(Delta, ZSTD),
f64_doubledelta_zstd Float64 DEFAULT n CODEC(DoubleDelta, ZSTD),
f64_gorilla_zstd Float64 DEFAULT n CODEC(Gorilla, ZSTD),
f64_fpc_zstd Float64 DEFAULT n CODEC(FPC, ZSTD))
Engine = MergeTree()
ORDER BY tuple();Generate test data for the table (1 million rows) so that each column contains a monotonic sequence of values with random increment:
INSERT INTO compression_test (n) SELECT number*1000+(rand()%100) FROM numbers(1000000);Use the system.columns system table to view the size of compressed and uncompressed data in each column and column compression codecs:
SELECT
name,
type,
formatReadableSize(data_uncompressed_bytes) AS uncompressed,
formatReadableSize(data_compressed_bytes) AS compressed,
round(data_uncompressed_bytes / data_compressed_bytes, 2) AS ratio,
compression_codec codec
FROM system.columns
WHERE table = 'compression_test' AND name != 'n';The result of this testing shows that specialized codecs can significantly affect the level of data compression by general-purpose codecs, depending on a column data type. For example, for the Int64 type, both algorithms (LZ4 and ZSTD) provide good compression together with the DoubleDelta codec, and for the Float64 type — ZSTD together with Delta or FPC.
┌─name─────────────────┬─type────┬─uncompressed─┬─compressed─┬─ratio─┬─codec───────────────────────┐
1. │ i64 │ Int64 │ 7.63 MiB │ 7.63 MiB │ 1 │ CODEC(NONE) │
2. │ i64_lz4 │ Int64 │ 7.63 MiB │ 4.78 MiB │ 1.6 │ CODEC(LZ4) │
3. │ i64_delta_lz4 │ Int64 │ 7.63 MiB │ 2.89 MiB │ 2.64 │ CODEC(Delta(8), LZ4) │
4. │ i64_doubledelta_lz4 │ Int64 │ 7.63 MiB │ 1.23 MiB │ 6.21 │ CODEC(DoubleDelta, LZ4) │
5. │ i64_t64_lz4 │ Int64 │ 7.63 MiB │ 1.62 MiB │ 4.72 │ CODEC(T64, LZ4) │
6. │ i64_zstd │ Int64 │ 7.63 MiB │ 1.97 MiB │ 3.87 │ CODEC(ZSTD(1)) │
7. │ i64_delta_zstd │ Int64 │ 7.63 MiB │ 1.36 MiB │ 5.62 │ CODEC(Delta(8), ZSTD(1)) │
8. │ i64_doubledelta_zstd │ Int64 │ 7.63 MiB │ 1.22 MiB │ 6.23 │ CODEC(DoubleDelta, ZSTD(1)) │
9. │ i64_t64_zstd │ Int64 │ 7.63 MiB │ 1.42 MiB │ 5.36 │ CODEC(T64, ZSTD(1)) │
10. │ f64 │ Float64 │ 7.63 MiB │ 7.63 MiB │ 1 │ CODEC(NONE) │
11. │ f64_lz4 │ Float64 │ 7.63 MiB │ 5.01 MiB │ 1.52 │ CODEC(LZ4) │
12. │ f64_delta_lz4 │ Float64 │ 7.63 MiB │ 2.90 MiB │ 2.63 │ CODEC(Delta(8), LZ4) │
13. │ f64_doubledelta_lz4 │ Float64 │ 7.63 MiB │ 3.47 MiB │ 2.2 │ CODEC(DoubleDelta, LZ4) │
14. │ f64_gorilla_lz4 │ Float64 │ 7.63 MiB │ 2.66 MiB │ 2.87 │ CODEC(Gorilla, LZ4) │
15. │ f64_fpc_lz4 │ Float64 │ 7.63 MiB │ 3.11 MiB │ 2.45 │ CODEC(FPC(12), LZ4) │
16. │ f64_zstd │ Float64 │ 7.63 MiB │ 2.22 MiB │ 3.44 │ CODEC(ZSTD(1)) │
17. │ f64_delta_zstd │ Float64 │ 7.63 MiB │ 1.49 MiB │ 5.11 │ CODEC(Delta(8), ZSTD(1)) │
18. │ f64_doubledelta_zstd │ Float64 │ 7.63 MiB │ 2.05 MiB │ 3.72 │ CODEC(DoubleDelta, ZSTD(1)) │
19. │ f64_gorilla_zstd │ Float64 │ 7.63 MiB │ 2.32 MiB │ 3.29 │ CODEC(Gorilla, ZSTD(1)) │
20. │ f64_fpc_zstd │ Float64 │ 7.63 MiB │ 1.87 MiB │ 4.08 │ CODEC(FPC(12), ZSTD(1)) │
└──────────────────────┴─────────┴──────────────┴────────────┴───────┴─────────────────────────────┘
For random data, Delta and DoubleDelta do not work very well, as you can see from the example below. Such data is better compressed with T64 (for integer values) and Gorilla (for floating point numbers) — so these codecs can be recommended for use when the data pattern is unknown.
CREATE TABLE compression_test_rand AS compression_test;INSERT INTO compression_test_rand (n) SELECT rand()%(1000000) FROM numbers(1000000);SELECT
name,
type,
formatReadableSize(data_uncompressed_bytes) AS uncompressed,
formatReadableSize(data_compressed_bytes) AS compressed,
round(data_uncompressed_bytes / data_compressed_bytes, 2) AS ratio,
compression_codec codec
FROM system.columns
WHERE table = 'compression_test_rand' AND name != 'n'; ┌─name─────────────────┬─type────┬─uncompressed─┬─compressed─┬─ratio─┬─codec───────────────────────┐
1. │ i64 │ Int64 │ 7.63 MiB │ 7.63 MiB │ 1 │ CODEC(NONE) │
2. │ i64_lz4 │ Int64 │ 7.63 MiB │ 4.40 MiB │ 1.73 │ CODEC(LZ4) │
3. │ i64_delta_lz4 │ Int64 │ 7.63 MiB │ 4.63 MiB │ 1.65 │ CODEC(Delta(8), LZ4) │
4. │ i64_doubledelta_lz4 │ Int64 │ 7.63 MiB │ 4.43 MiB │ 1.72 │ CODEC(DoubleDelta, LZ4) │
5. │ i64_t64_lz4 │ Int64 │ 7.63 MiB │ 2.40 MiB │ 3.18 │ CODEC(T64, LZ4) │
6. │ i64_zstd │ Int64 │ 7.63 MiB │ 3.32 MiB │ 2.3 │ CODEC(ZSTD(1)) │
7. │ i64_delta_zstd │ Int64 │ 7.63 MiB │ 3.42 MiB │ 2.23 │ CODEC(Delta(8), ZSTD(1)) │
8. │ i64_doubledelta_zstd │ Int64 │ 7.63 MiB │ 3.84 MiB │ 1.99 │ CODEC(DoubleDelta, ZSTD(1)) │
9. │ i64_t64_zstd │ Int64 │ 7.63 MiB │ 2.39 MiB │ 3.19 │ CODEC(T64, ZSTD(1)) │
10. │ f64 │ Float64 │ 7.63 MiB │ 7.63 MiB │ 1 │ CODEC(NONE) │
11. │ f64_lz4 │ Float64 │ 7.63 MiB │ 4.67 MiB │ 1.63 │ CODEC(LZ4) │
12. │ f64_delta_lz4 │ Float64 │ 7.63 MiB │ 4.85 MiB │ 1.57 │ CODEC(Delta(8), LZ4) │
13. │ f64_doubledelta_lz4 │ Float64 │ 7.63 MiB │ 5.94 MiB │ 1.28 │ CODEC(DoubleDelta, LZ4) │
14. │ f64_gorilla_lz4 │ Float64 │ 7.63 MiB │ 3.12 MiB │ 2.44 │ CODEC(Gorilla, LZ4) │
15. │ f64_fpc_lz4 │ Float64 │ 7.63 MiB │ 5.03 MiB │ 1.52 │ CODEC(FPC(12), LZ4) │
16. │ f64_zstd │ Float64 │ 7.63 MiB │ 3.26 MiB │ 2.34 │ CODEC(ZSTD(1)) │
17. │ f64_delta_zstd │ Float64 │ 7.63 MiB │ 3.44 MiB │ 2.22 │ CODEC(Delta(8), ZSTD(1)) │
18. │ f64_doubledelta_zstd │ Float64 │ 7.63 MiB │ 4.07 MiB │ 1.87 │ CODEC(DoubleDelta, ZSTD(1)) │
19. │ f64_gorilla_zstd │ Float64 │ 7.63 MiB │ 3.05 MiB │ 2.5 │ CODEC(Gorilla, ZSTD(1)) │
20. │ f64_fpc_zstd │ Float64 │ 7.63 MiB │ 4.20 MiB │ 1.82 │ CODEC(FPC(12), ZSTD(1)) │
└──────────────────────┴─────────┴──────────────┴────────────┴───────┴─────────────────────────────┘