

Iceberg connector
Iceberg Sink Connector overview
Apache Iceberg Sink Connector — sink connector for writing data from Kafka to Iceberg tables.
Using Iceberg Sink Connector provides the following benefits:
-
Message coordination for centralized Iceberg commits.
-
Ensuring exactly once delivery semantic.
-
Ability to fork across multiple tables.
-
Automatic table creation and schema evolution.
-
Field name mapping using Iceberg column mapping functionality.
To illustrate the benefits of the connector, the article shows an implementation of a full pipeline using Kafka Connect — capturing change data (CDC) in PostgreSQL database tables with writing changes to an Iceberg table.
Prerequisites for the ADH and ADS clusters and the description of the Iceberg Sink Connector configuration are provided below separately for each available storage: Hadoop Distributed File System (HDFS) and Apache Ozone (O3).
Prerequisites
The environment used to create a complete CDC pipeline is described below.
ADH
-
The ADH cluster is installed according to the Online installation guide. The minimum ADH version is 3.3.6.2.b1.
-
The Core configuration, Zookeeper, HDFS, ADPG, Hive, HUE, and Impala services are added and installed in the ADH cluster.
-
In ADH, the
kafka-connectuser is created on each host and has rights to create tables in the HDFS storage (as a member of thehadoopgroup), for example, as shown below:$ sudo adduser kafka-connect $ sudo usermod -aG hadoop kafka-connect
-
The ADH cluster is installed according to the Online installation guide. The minimum ADH version is 3.3.6.2.b1.
-
The Core configuration, Zookeeper, HDFS, ADPG, Hive, Ozone, HUE, and Impala services are added and installed in the ADH cluster.
-
In ADH, the
kafka-connectuser is created on each host and has rights to create tables in the HDFS storage (as a member of thehadoopgroup), for example, as shown below:$ sudo adduser kafka-connect $ sudo usermod -aG hadoop kafka-connect -
For the described example, on the host where Ozone is installed, a volume and a bucket are created:
$ ozone sh volume create volumetest $ sudo ozone sh bucket create /volumetest/testbucket -
The configuration of ADH services for integration with Ozone is completed as described below. In all specified configurations,
<ozone.om.service.ids>is used — the value of the corresponding parameter of the Ozone Manager component (ozone-site.xml parameter group) of the Ozone service in the ADH cluster, configured during cluster installation.-
Core configuration
Set the
ofs://<ozone.om.service.ids>/value for the fs.defaultFS parameter in the core-site.xml group to define the default filesystem name. -
YARN
Set the
ofs://<ozone.om.service.ids>/system/yarn/node-labelsvalue for the yarn.node-labels.fs-store.root-dir parameter in the yarn-site group to define the NodeLabelManager URI. -
Hive
Set the
ofs://<ozone.om.service.ids>/volumetest/testbucketvalue for the hive.metastore.warehouse.dir parameter in the hive-site.xml group to define the location of the default database for the storage, where/volumetest/testbucketis an Ozone volume and bucket, existing in Ozone or created specifically above.
-
It is recommended to configure ADH cluster services during the cluster installation (before executing the Install action). Changing configuration for the installed services does not guarantee stable operation of Iceberg Sink Connector when using the Ozone storage.
ADS and ADS Control
-
The ADS cluster is installed according to the Online installation guide. The minimum ADS version is 3.7.2.1.b1.
-
Kafka, Kafka Connect, and Schema-Registry services are added and installed in the ADS cluster.
-
To automatically create a Kafka topic, the auto.create.topics.enable parameter is enabled in the server.properties group when configuring the Kafka service.
-
When configuring the Kafka Connect service, a new value
/usr/lib/kafka-connect/pluginshas been added to the plugin.path parameter group in the connect-distributed.properties parameter as shown below.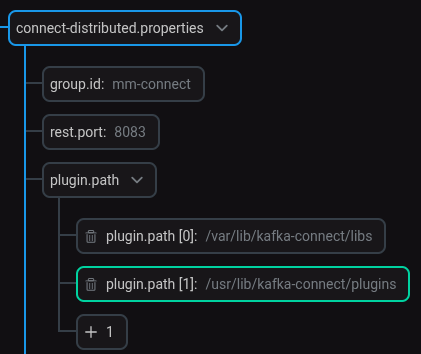 Configuring the path to the Iceberg Sink Connector plugin
Configuring the path to the Iceberg Sink Connector pluginSetting the plugin path is required only for ADS 3.7.2.1.b1.
-
The configuration of the ADH cluster used in the pipeline is imported into the ADS cluster.
To enable import, on the Import tab of the ADS cluster, select Cluster configuration next to the name of the ADH cluster and click Import.
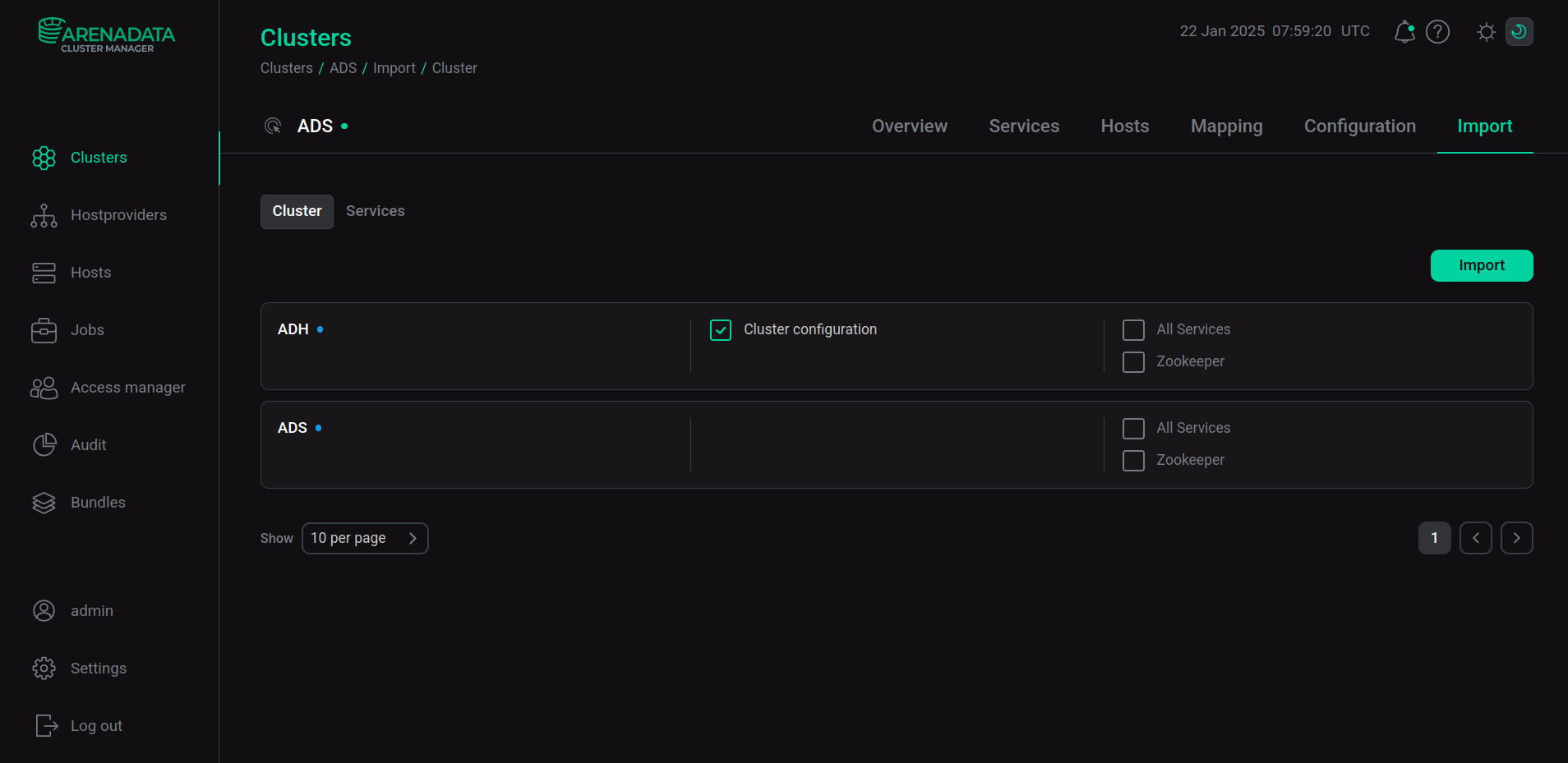 Import of ADH data
Import of ADH dataAs a result of the import, the /usr/lib/kafka/config/ folder should contain the ADH configuration files: core-site-xml and hdfs-site-xml.
-
The ADS Control cluster is installed according to the Installation guide and integrated with the ADS cluster being used.
-
The ADS cluster is installed according to the Online installation guide. The minimum ADS version is 3.9.1.2.b1.
-
The Zookeeper, Kafka, Kafka Connect, and Schema-Registry services are added and installed in the ADS cluster.
-
To automatically create a Kafka topic, the auto.create.topics.enable parameter is enabled in the server.properties group when configuring the Kafka service.
-
The configuration of the ADH cluster used in the pipeline is imported into the ADS cluster.
To enable import, on the Import tab of the ADS cluster, select Cluster configuration next to the name of the ADH cluster and click Import.
Import of ADH dataAs a result of the import, the /usr/lib/kafka/config/ folder should contain the ADH configuration files: core-site-xml and hdfs-site-xml.
The import of the ADH cluster configuration should be performed after configuring ADH services for integration with Ozone.
-
The ADS Control cluster is installed according to the Installation guide and integrated with the ADS cluster being used.
ADPG
-
The ADPG cluster is installed according to the Online installation guide.
-
PostgreSQL server IP address (a host with the ADPG service) is
10.92.43.42. For incoming connections, the default port number is5432. -
To create a Debezium connector, similar to the one described in the Debezium Connector for PostgreSQL server article, the ADPG cluster settings are set via ADCM UI (configuring access to the database from the Kafka Connect host in the pg_hba.conf file and the wal_level parameter in the postgresql.conf file).
Below is an example of creating and configuring a PostgreSQL database (in the ADPG cluster).
Create a database:
CREATE DATABASE my_database;Connect to the database:
\c my_databaseCreate a user with the SUPERUSER role:
CREATE USER my_user WITH SUPERUSER PASSWORD 'P@ssword';|
CAUTION
The SUPERUSER user role is used for testing purposes only. For more information, see Configuring permissions for the Debezium connector.
|
Create a test table:
CREATE TABLE my_table (
id BIGSERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
country VARCHAR(100),
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);Configure replica identification for a table to enable the use of BIGSERIAL PRIMARY KEY indexes on the subscriber side for row lookups:
ALTER TABLE my_table REPLICA IDENTITY FULL;Fill the table with data (given as an example, several lines are needed for clarity):
INSERT INTO my_table(name, country) VALUES ('John Jones','USA');|
NOTE
|
Create a Debezium connector for PostgreSQL server
To capture row-level data changes in PostgreSQL database tables using ADS Control, create a Debezium connector similar to the one described in the article Debezium connector for PostgreSQL server.
Below is an example Debezium connector configuration with a description of the new parameters used in the data pipeline.
{
"name": "cdc-my-adpg",
"topic.prefix": "cdc__demo",
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"publication.autocreate.mode": "filtered",
"database.user": "my_user",
"database.dbname": "my_database",
"tasks.max": 1,
"database.port": 5432,
"plugin.name": "pgoutput",
"database.hostname": "10.92.43.42",
"database.password": "P@ssword",
"table.include.list": ["public.my_table"],
"value.converter.schema.registry.url": "http://10.92.42.130:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://10.92.42.130:8081",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"transforms": ["unwrap"],
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.add.fields": "op,source.schema,source.table,source.ts_ms,ts_ms",
"transforms.unwrap.add.headers": "db",
"transforms.unwrap.delete.handling.mode": "rewrite",
"slot.name": "cdc__my_database",
"schema.evolution": "basic"
}| Attribute | Description |
|---|---|
value.converter.schema.registry.url |
Schema-Registry server address |
key.converter.schema.registry.url |
Schema-Registry server address |
transforms.unwrap.type |
Specifies the class used for the |
transforms.unwrap.add.fields |
Additional fields to add to the data |
transforms.unwrap.add.headers |
Defines whether to add metadata to the Kafka message header |
transforms.unwrap.delete.handling.mode |
Defines how to handle deletion events. |
table.include.list |
Optional list of comma-separated regular expressions that match the table IDs of the tables whose changes are to be captured. If this property is set, the connector captures changes only from the specified tables. Each ID must be of the form
|
slot.name |
Name of the PostgreSQL logical decoding slot created for streaming. The server uses this slot to stream events to the Debezium connector. Must be unique for each connector connecting to the database |
schema.evolution |
Specifies the schema evolution mode. When set to |
Create an Iceberg connector
To create an Iceberg connector via ADS Control, the connector plugin IcebergSinkConnector is used.
To create connectors using the ADS Control, you need to:
-
Go to the Kafka Connects page in the ADS Control web interface. The Kafka Connects page becomes available after selecting a cluster in the cluster management section and going to the desired tab on the General page.
-
Select the desired cluster and go to the Kafka Connect instance overview page.
-
Click Create Connector on the Kafka Connect instance overview page. After clicking Create Connector, the window for selecting the connector plugin Clusters → <cluster name> → Kafka Connects → <cluster name> connector → Kafka connector plugins opens.
-
Select the desired connector to create.
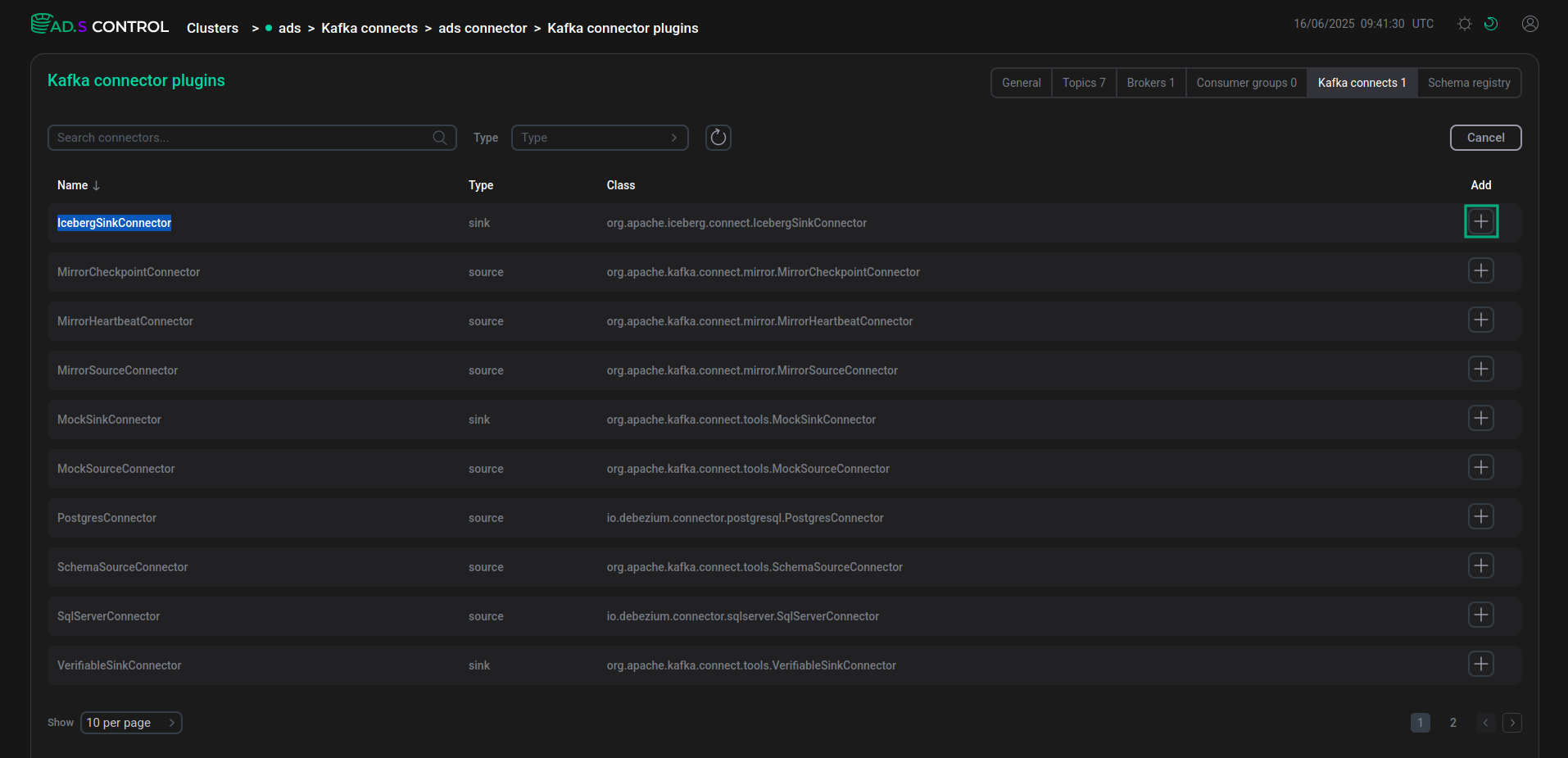 Selecting a plugin to create a connector
Selecting a plugin to create a connector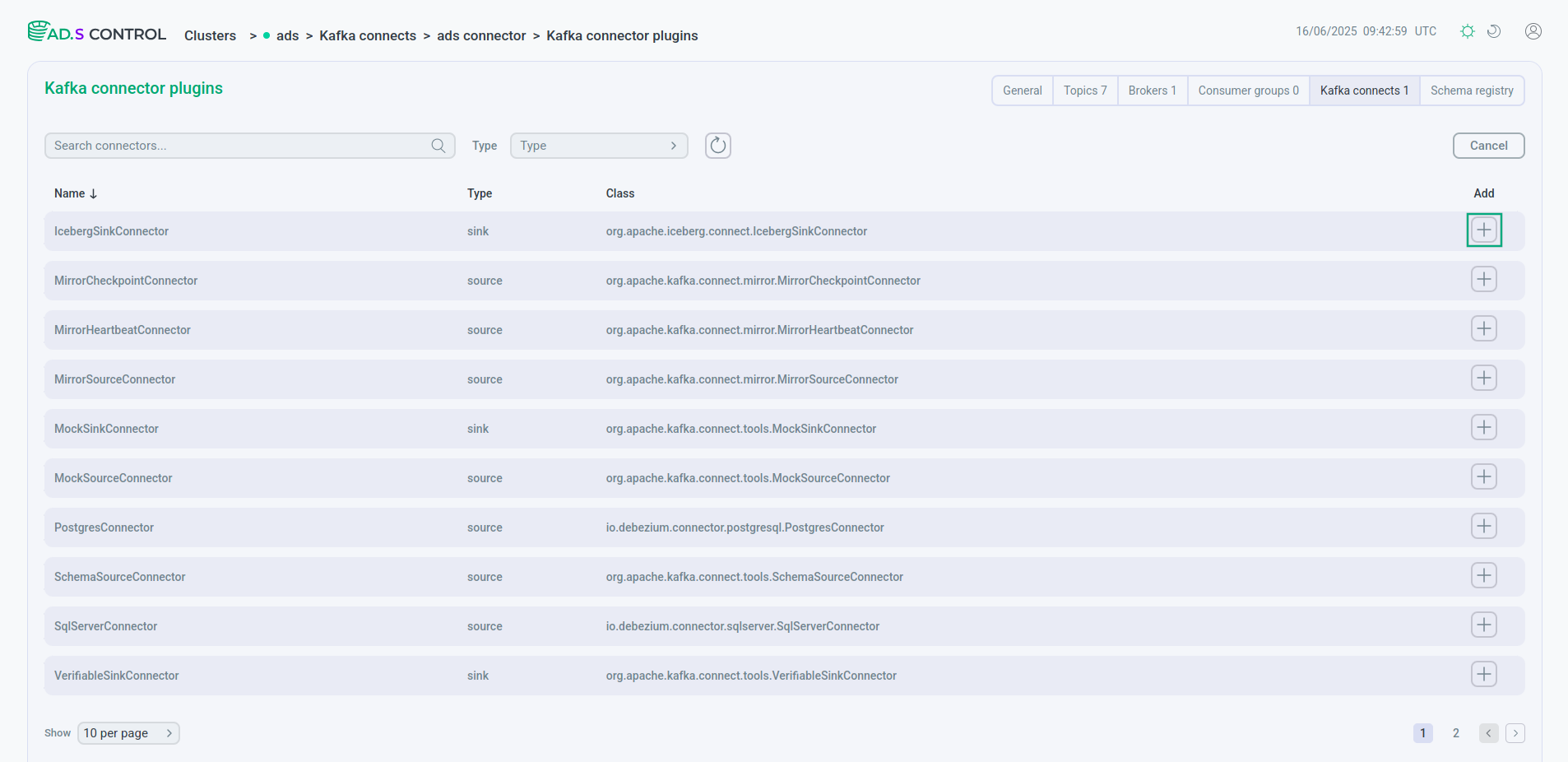 Selecting a plugin to create a connector
Selecting a plugin to create a connector -
Fill in the connector configuration parameters. If necessary, use the parameter information:
-
in the Kafka Connect configuration parameters article;
-
in the Iceberg connector configuration.
You can fill in the configuration in the form of a JSON file. To do this, enable the JSON view switch.
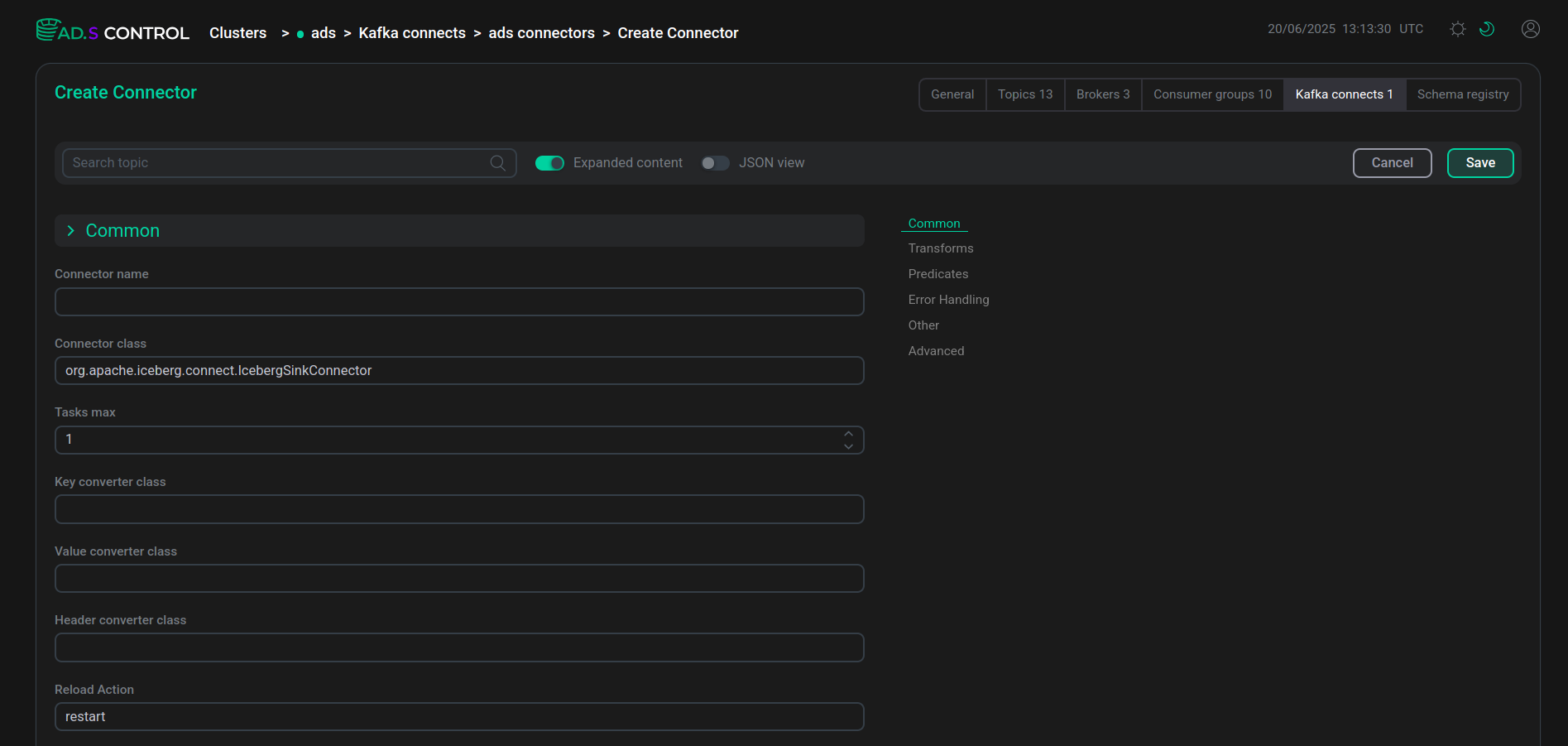 Connector configuration
Connector configuration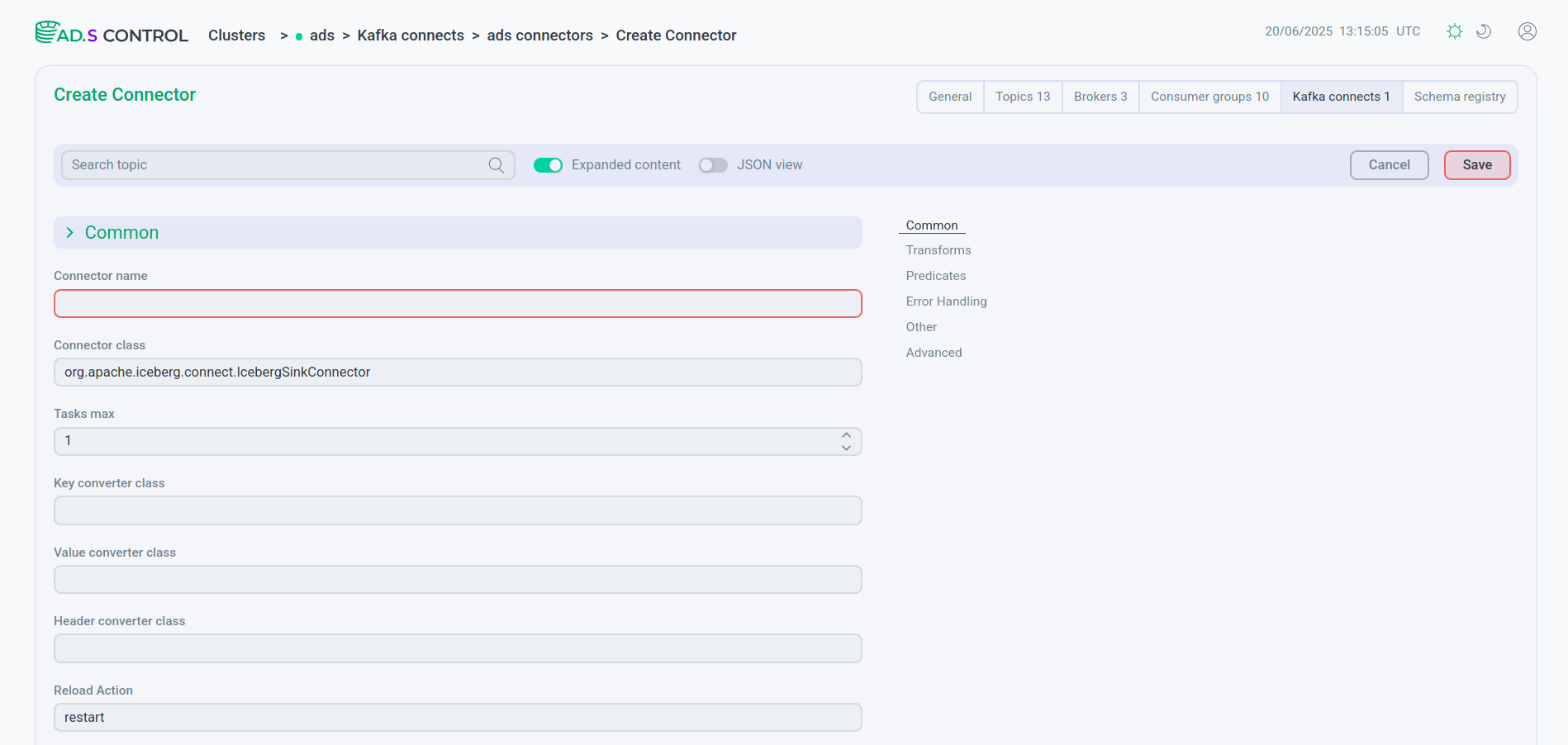 Connector configuration
Connector configuration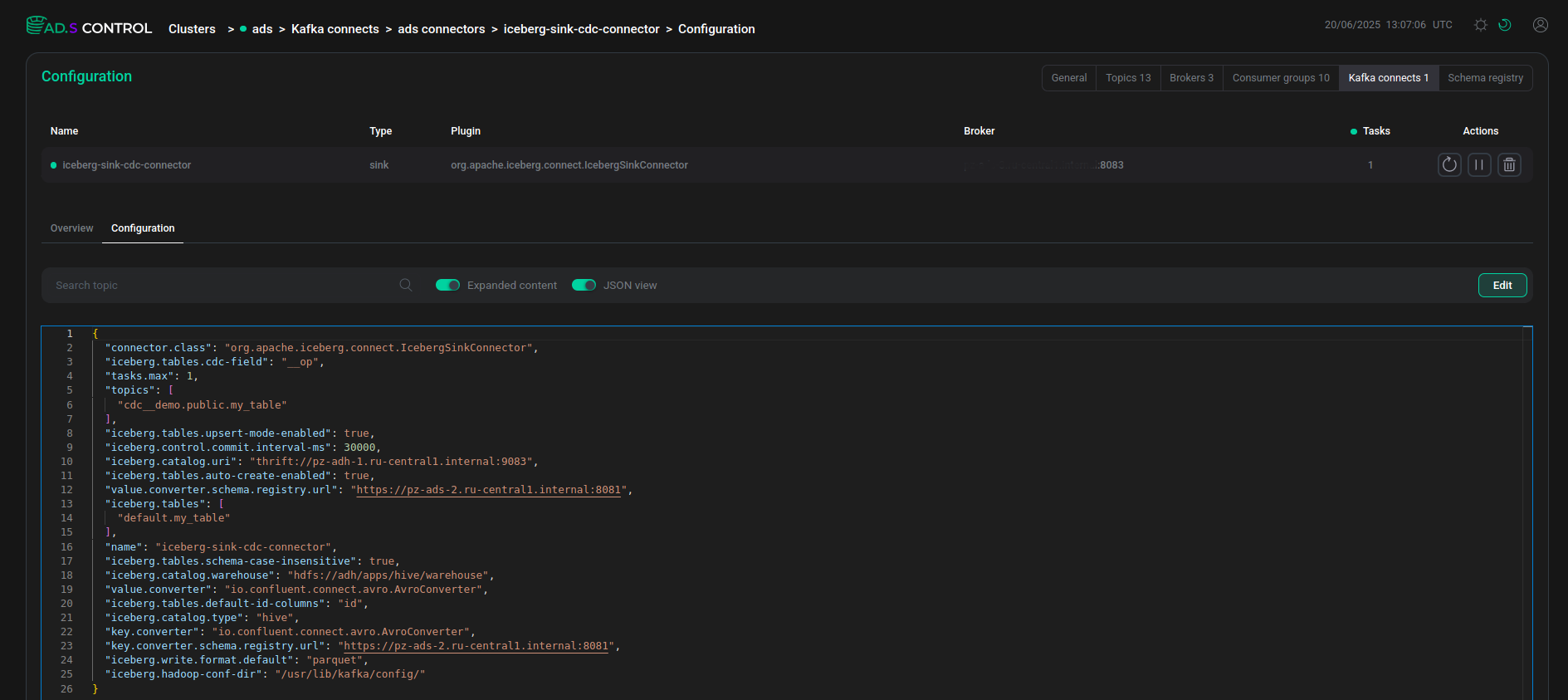 Connector configuration JSON file
Connector configuration JSON file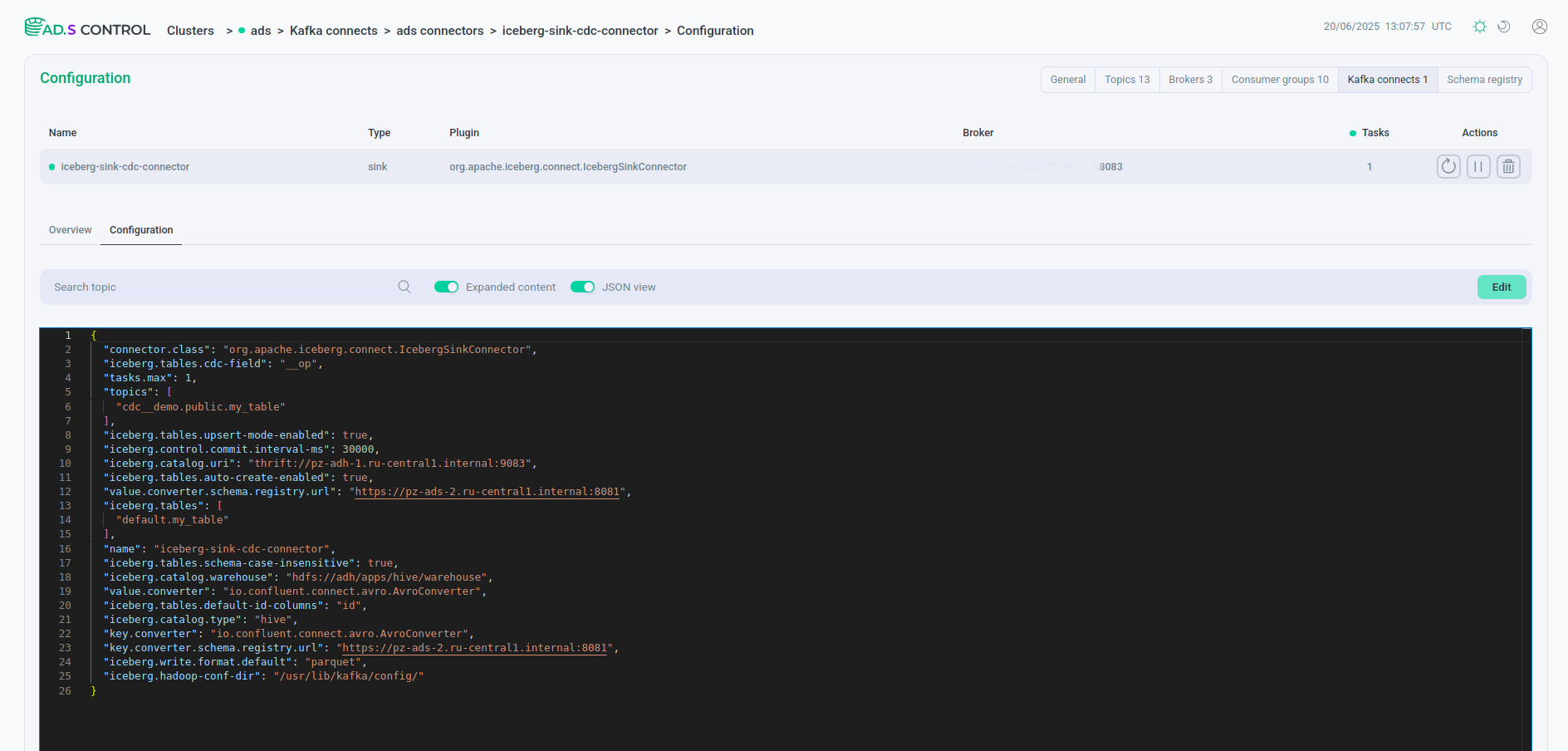 Connector configuration JSON fileExample contents of a JSON file with an Iceberg connector configuration with HDFS
Connector configuration JSON fileExample contents of a JSON file with an Iceberg connector configuration with HDFS{ "connector.class": "org.apache.iceberg.connect.IcebergSinkConnector", "iceberg.tables.cdc-field": "__op", "tasks.max": 1, "topics": [ "cdc__demo.public.my_table" ], "iceberg.tables.upsert-mode-enabled": true, "iceberg.control.commit.interval-ms": 30000, "iceberg.catalog.uri": "thrift://10.92.43.153:9083", "iceberg.connect.hdfs.keytab": "/etc/security/keytabs/kafka-connect.service.keytab", "iceberg.tables.auto-create-enabled": true, "value.converter.schema.registry.url": "http://10.92.42.130:8081", "iceberg.connect.hdfs.principal": "kafka-connect/sov-ads-6.ru-central1.internal@ADS-KAFKA.LOCAL", "iceberg.tables": [ "default.my_table" ], "name": "iceberg-sink-cdc-connector", "iceberg.tables.schema-case-insensitive": true, "iceberg.catalog.warehouse": "hdfs://adh/apps/hive/warehouse", "value.converter": "io.confluent.connect.avro.AvroConverter", "iceberg.tables.default-id-columns": "id", "iceberg.hdfs.authentication.kerberos": true, "iceberg.catalog.type": "hive", "key.converter": "io.confluent.connect.avro.AvroConverter", "key.converter.schema.registry.url": "http://10.92.42.130:8081", "iceberg.write.format.default": "parquet", "iceberg.hadoop-conf-dir": "/usr/lib/kafka/config/" }Example contents of a JSON file with an Iceberg connector configuration with Ozone{ "connector.class": "org.apache.iceberg.connect.IcebergSinkConnector", "iceberg.tables.cdc-field": "__op", "tasks.max": 1, "topics": [ "cdc__demo.public.my_table" ], "iceberg.tables.upsert-mode-enabled": true, "iceberg.control.commit.interval-ms": 30000, "iceberg.catalog.uri": "thrift://10.92.38.137:9083", "iceberg.connect.hdfs.keytab": "/etc/security/keytabs/kafka-connect.service.keytab", "iceberg.tables.auto-create-enabled": true, "value.converter.schema.registry.url": "http://10.92.38.143:8081", "iceberg.connect.hdfs.principal": "kafka-connect/sov-ads-6.ru-central1.internal@ADS-KAFKA.LOCAL", "iceberg.tables": [ "default.my_table" ], "name": "iceberg-sink-cdc-connector", "iceberg.tables.schema-case-insensitive": true, "iceberg.catalog.warehouse": "ofs://adh2/volumetest/testbucket", "value.converter": "io.confluent.connect.avro.AvroConverter", "iceberg.tables.default-id-columns": "id", "iceberg.hdfs.authentication.kerberos": true, "iceberg.catalog.type": "hive", "key.converter": "io.confluent.connect.avro.AvroConverter", "key.converter.schema.registry.url": "http://10.92.38.143:8081", "iceberg.write.format.default": "parquet", "iceberg.hadoop-conf-dir": "/usr/lib/kafka/config/" }The description of the Iceberg Sink Connector parameters used in the examples is given below.
Description of parameters for configuring the Iceberg Sink ConnectorAttribute Description name
Name of the connector that will be used in the Kafka Connect service
connector.class
Class name for the connector
tasks.max
Maximum number of tasks to create
topics
Name of the topic whose data should be passed to the Iceberg tables. For the CDC pipeline implementation, the topic name has the form
<topic.prefix>.<table.include.list>, consisting of the parameters of the Debezium connector created aboveiceberg.tables
Comma-separated list of target tables
iceberg.write.format.default
Default file format for a table:
parquet,avro, ororciceberg.tables.auto-create-enabled
Set to
trueto automatically create target tablesiceberg.tables.schema-case-insensitive
Set to
trueto search for table columns by name in a case-insensitive mannericeberg.tables.upsert-mode-enabled
Set the value to
trueto enable UPSERT modeiceberg.tables.cdc-field
The field of the source record that identifies the type of operation (
INSERT,UPDATE, orDELETE) when UPSERT mode is enablediceberg.tables.default-id-columns
A list of default comma-separated columns that define the identifier row in tables (primary key). Is a mandatory parameter when UPSERT mode is enabled
iceberg.catalog.type
Type of a catalog for storing Iceberg tables
iceberg.catalog.uri
Address to connect to the catalog with Iceberg tables (address of the host with the Hive Metastore component installed)
iceberg.hdfs.authentication.kerberos
Flag for enabling/disabling HDFS Kerberos authentication (disabled by default). Used when Kerberos authentication is enabled in ADS and ADH. Available starting from ADS 3.9.0.1.b1
iceberg.connect.hdfs.principal
The name of the Kerberos principal to be used in authentication. It is a mandatory parameter if Kerberos authentication is enabled. Available starting from ADS 3.9.0.1.b1
iceberg.connect.hdfs.keytab
The path to the keytab file for Kerberos, which contains the key for the principal. It is a mandatory parameter if Kerberos authentication is enabled. Available starting from ADS 3.9.0.1.b1
iceberg.hadoop-conf-dir
Path to Kafka broker configuration files
iceberg.catalog.warehouse
Path to metadata storage. Must match the value of the hive.metastore.warehouse.dir parameter in the hive-site.xml group for Hive
key.converter
Converter type for message key
key.converter.schema.registry.url
Schema-Registry server address
value.converter
Converter type for message value
value.converter.schema.registry.url
Schema-Registry server address
iceberg.control.commit.interval-ms
Interval between commits in ms
-
-
After filling, click Save and get a message about the successful creation of the connector.
 Message about the successful creation of the connector
Message about the successful creation of the connector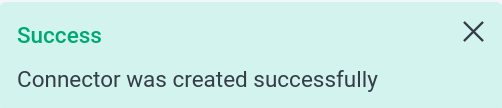 Message about the successful creation of the connector
Message about the successful creation of the connector -
On the opened page, launch the connector using the

 icon .
icon . -
Check that the launched connector is in a working status.
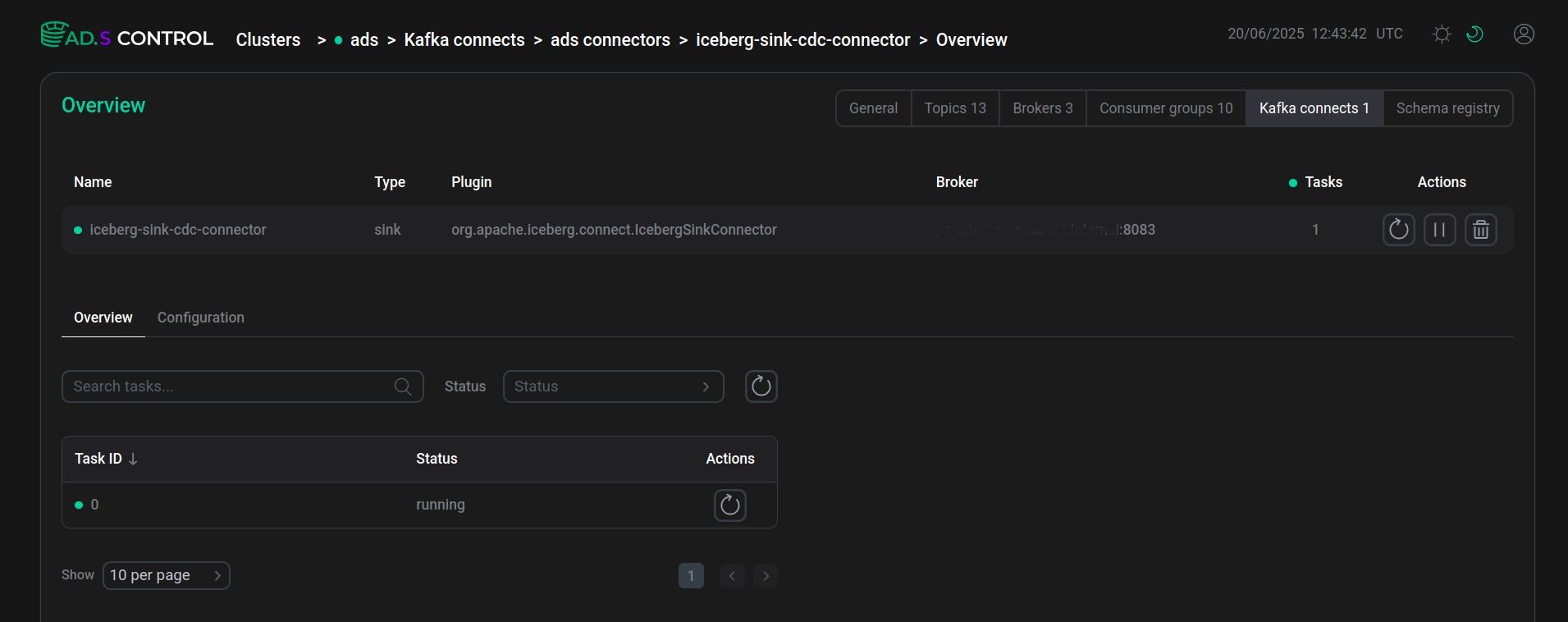 Created and launched connector
Created and launched connector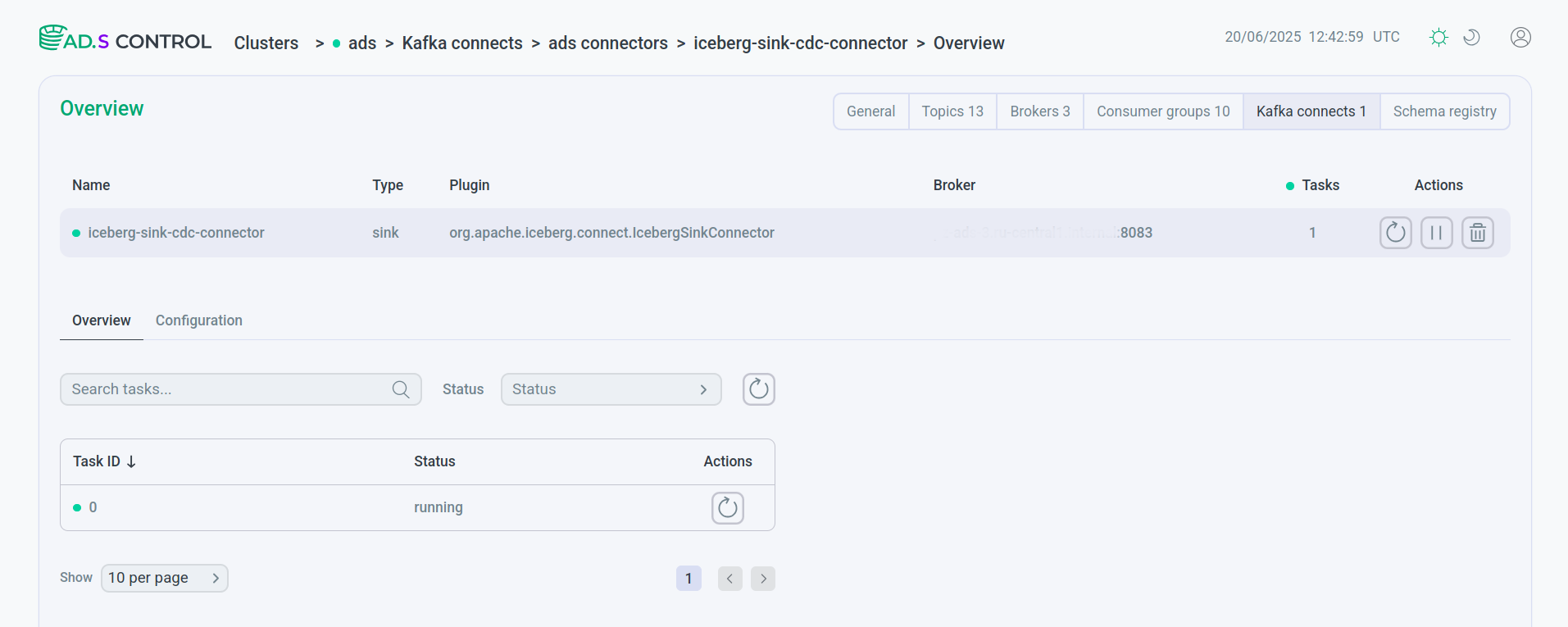 Created and launched connector
Created and launched connectorIf after creating the connector the task is created with an error, the contents of the error can be seen after clicking
 located in the Status field of the task.
located in the Status field of the task.
PostgreSQL database table data in ADS Control
The Topics page of the ADS Control user interface displays a topic with all PostgreSQL table fields and their contents created by the Debezium connector.
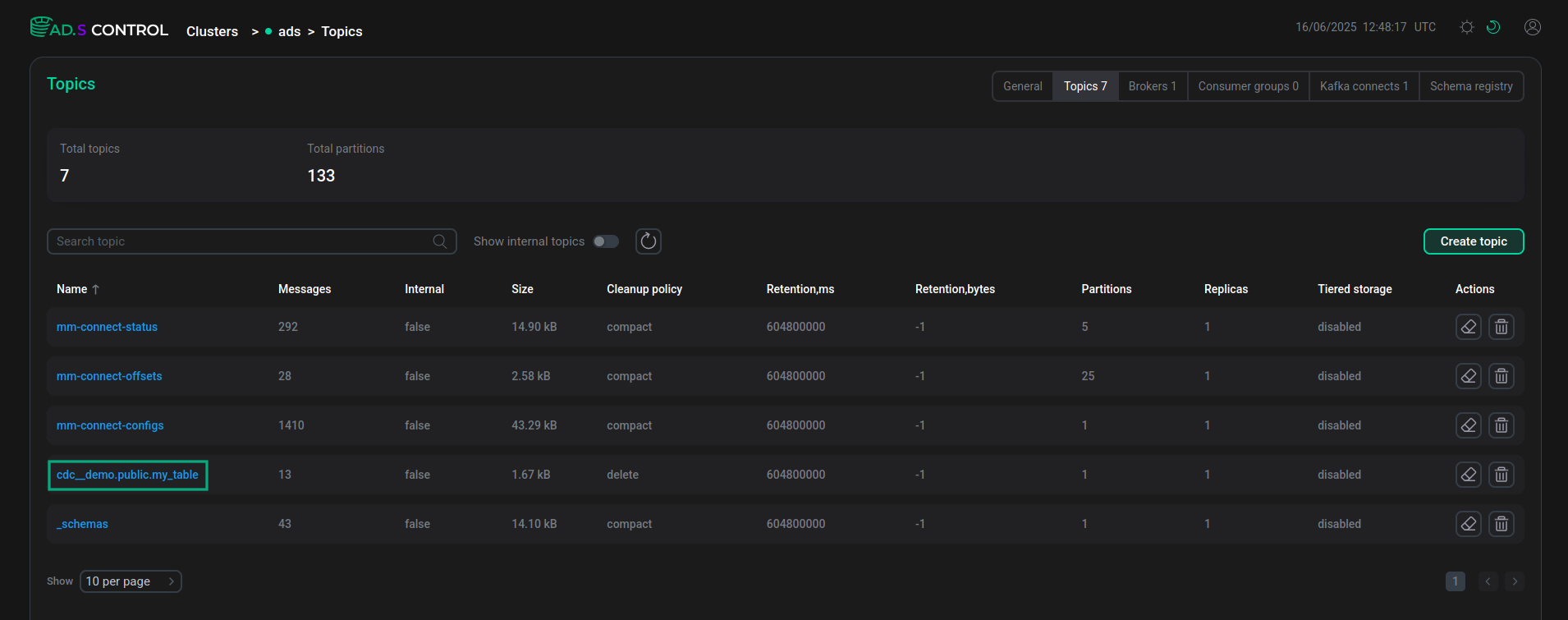
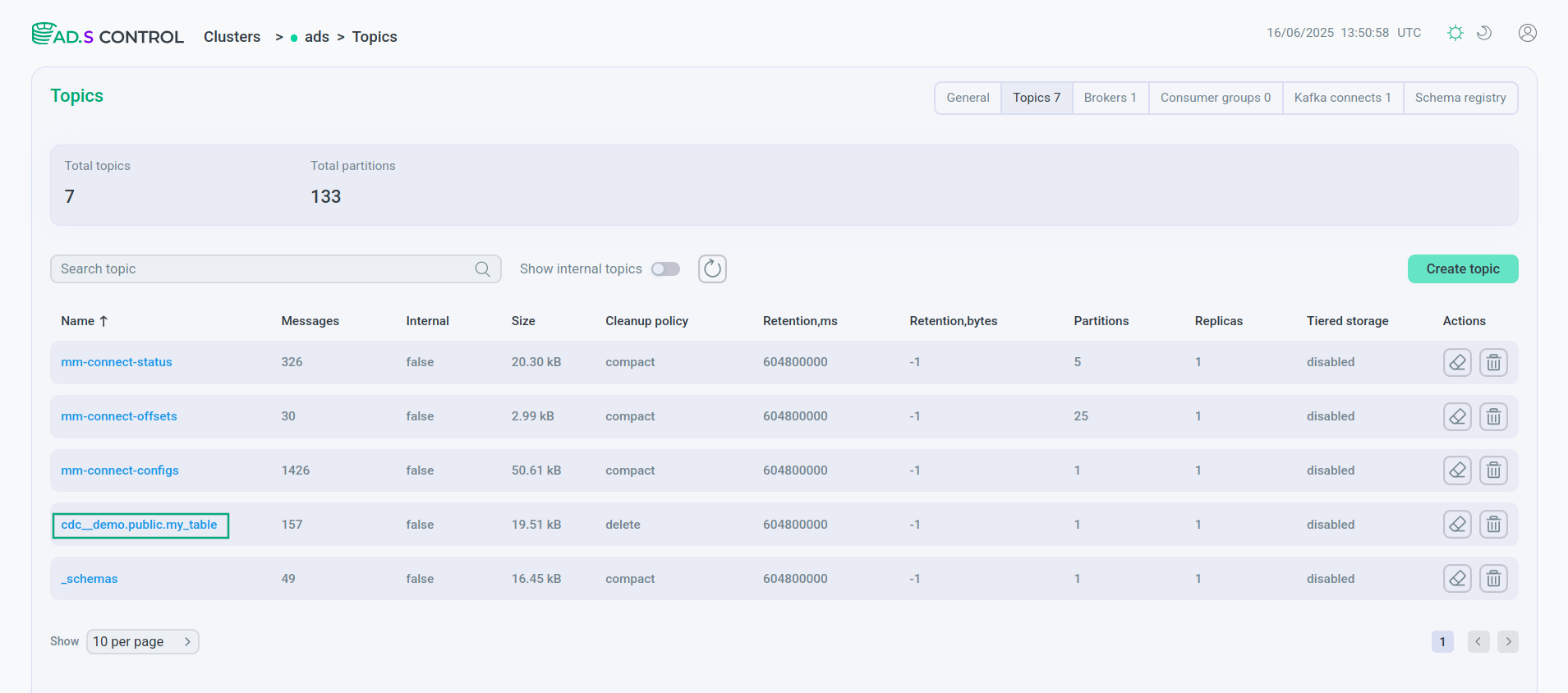
The ADS Control user interface page Schema-Registry displays the schemas created in Schema-Registry for table keys and values.
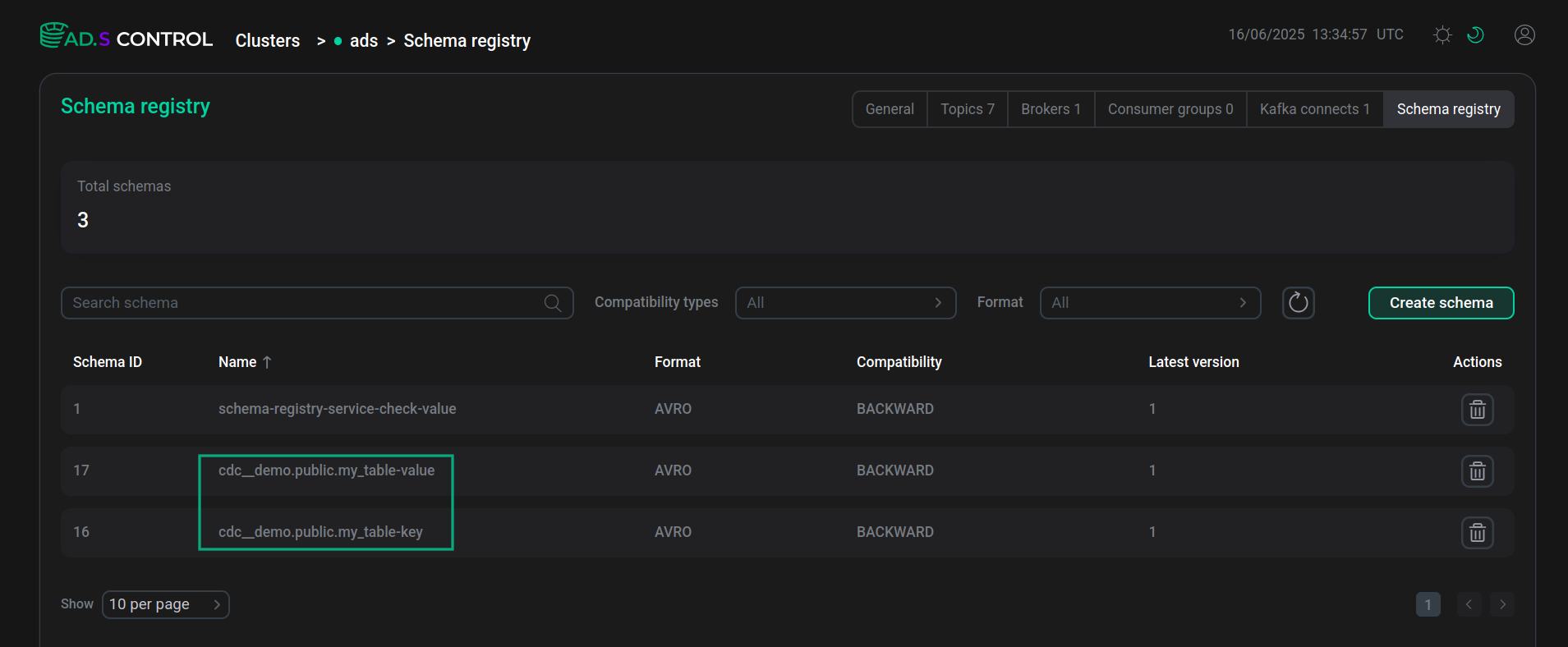
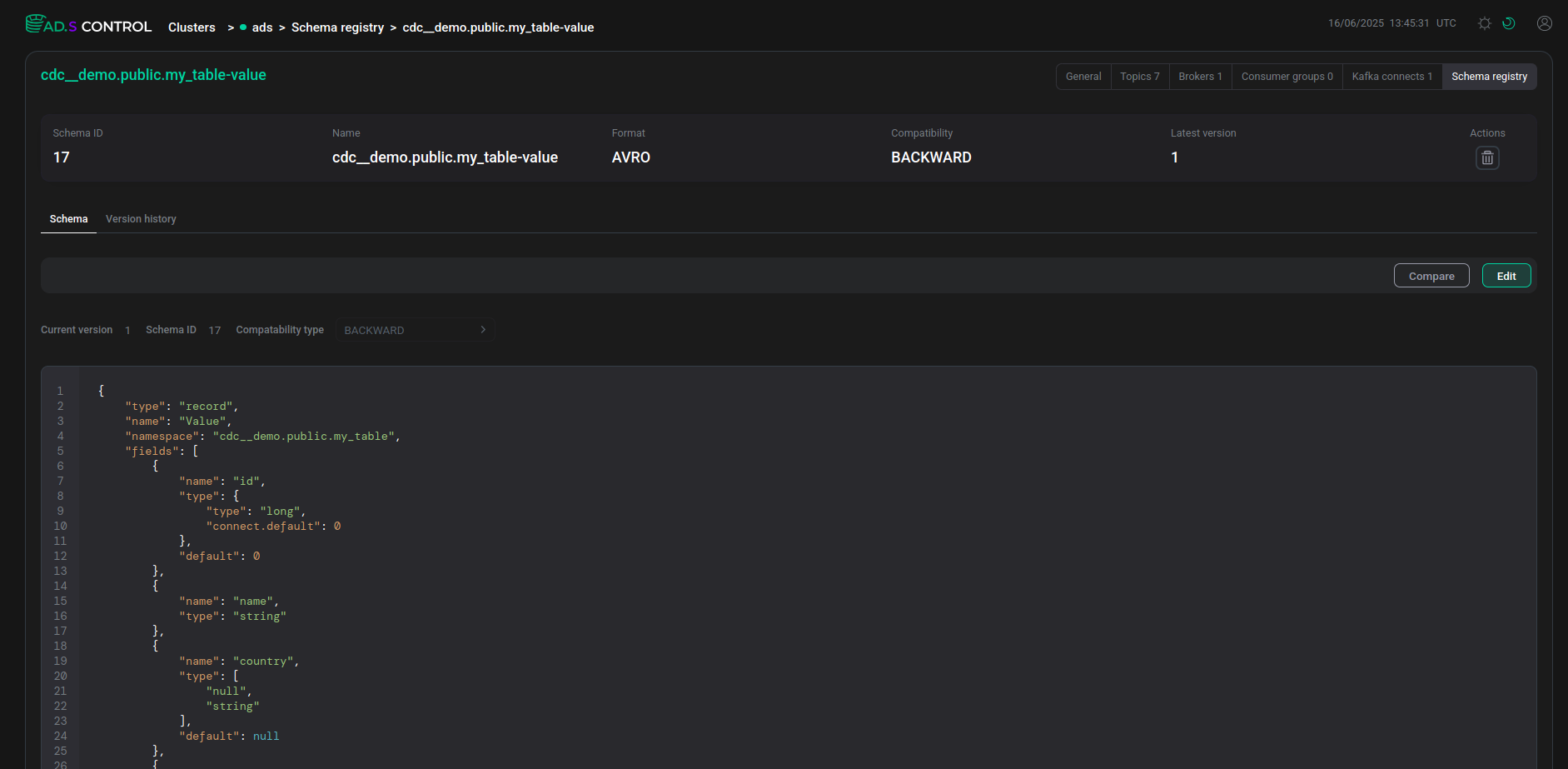
The schemas tab displays a description of all table fields, including fields added using the transforms.unwrap.add.fields parameter when creating the Debezium connector.
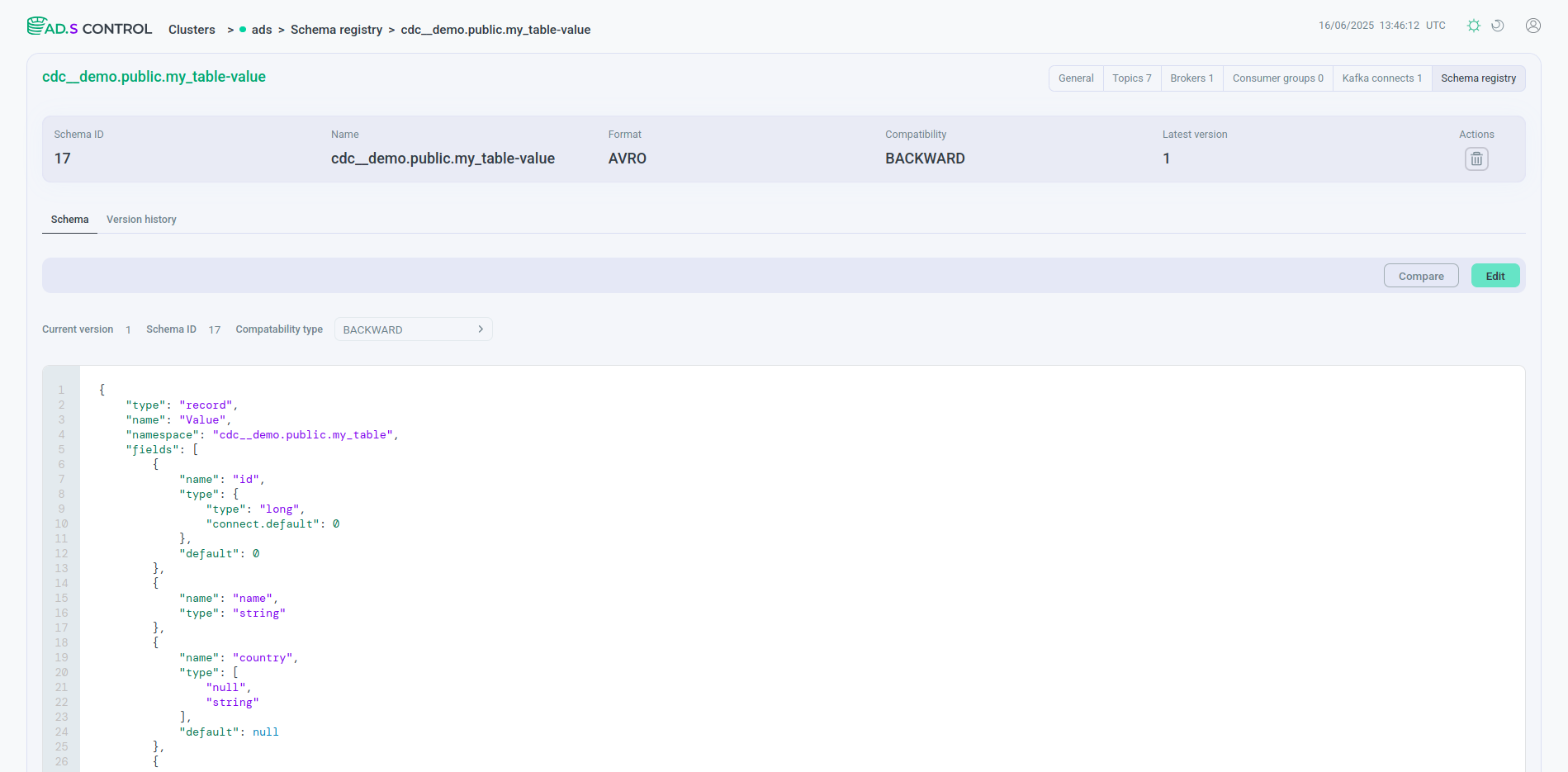
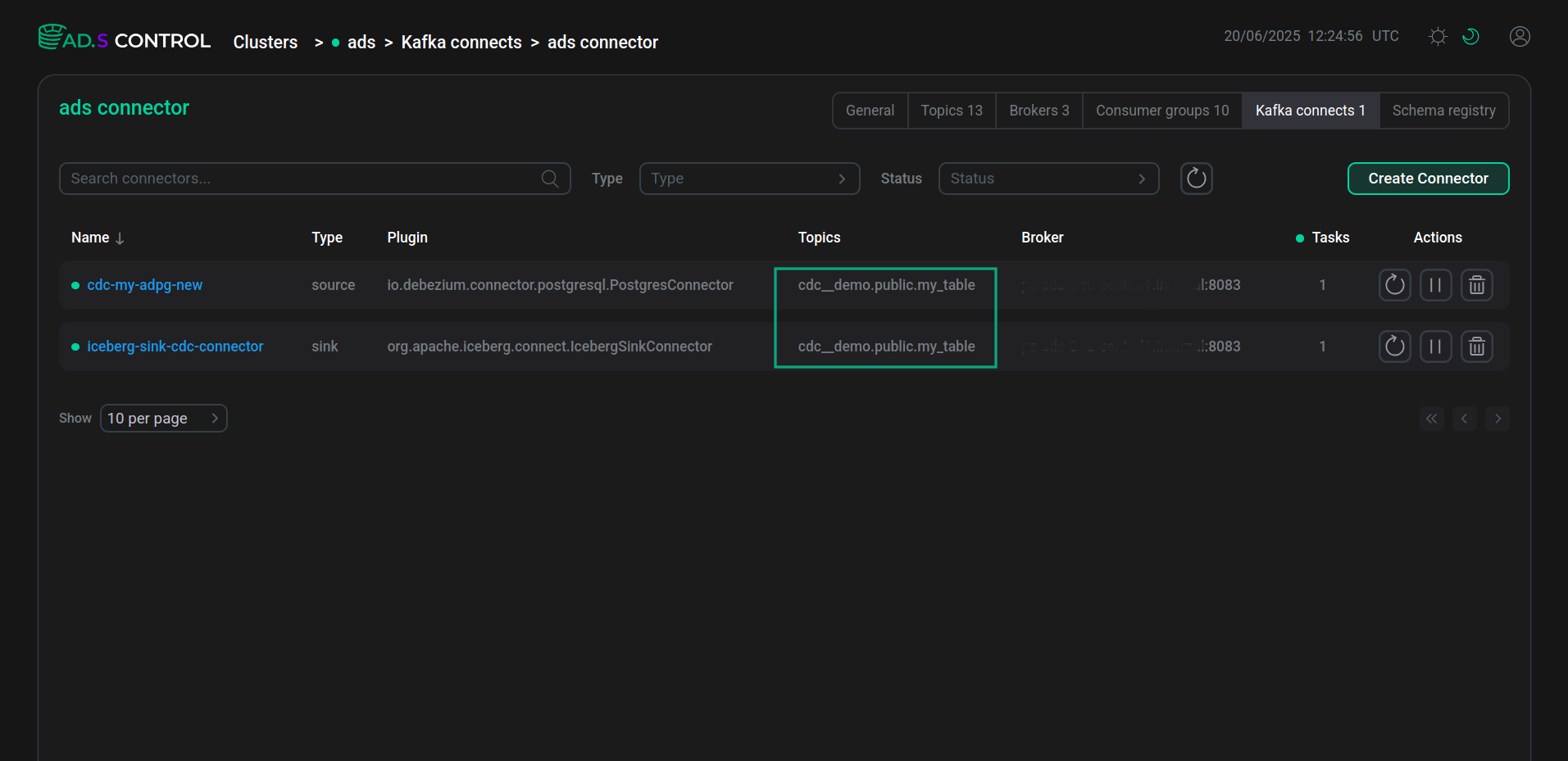
As a result of creating the data pipeline, in the connectors table on the Kafka Connect instance overview page, both connectors created have the same topic name in the Topic column.
Iceberg tables
To test change collection using the Debezium connector, make changes to the PostgreSQL table:
INSERT INTO my_table(name, country) VALUES ('NAME','COUNTRY');After connecting to the user interface of the HUE service from the ADH cluster, you can view Iceberg tables created by the connector.
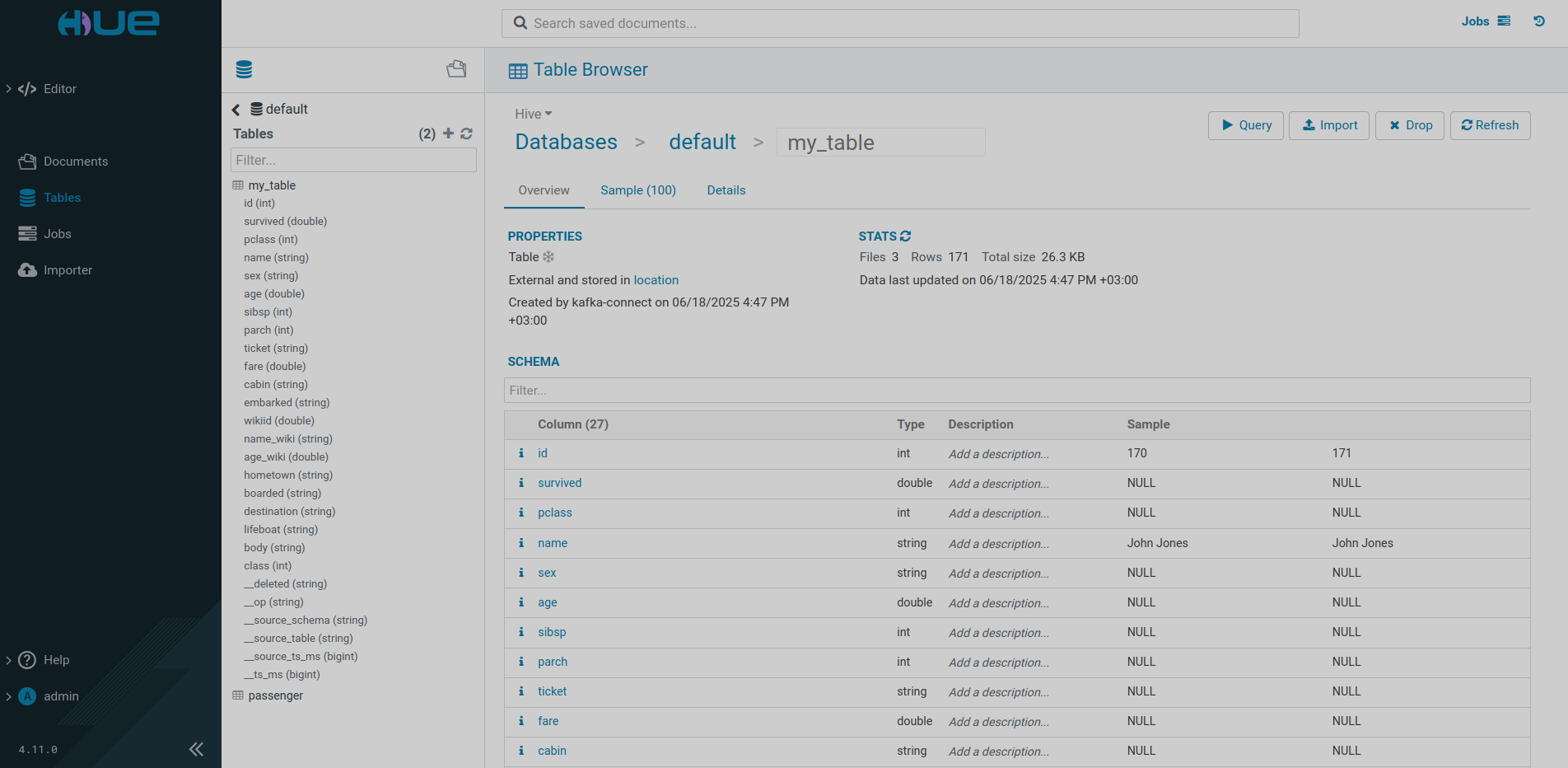
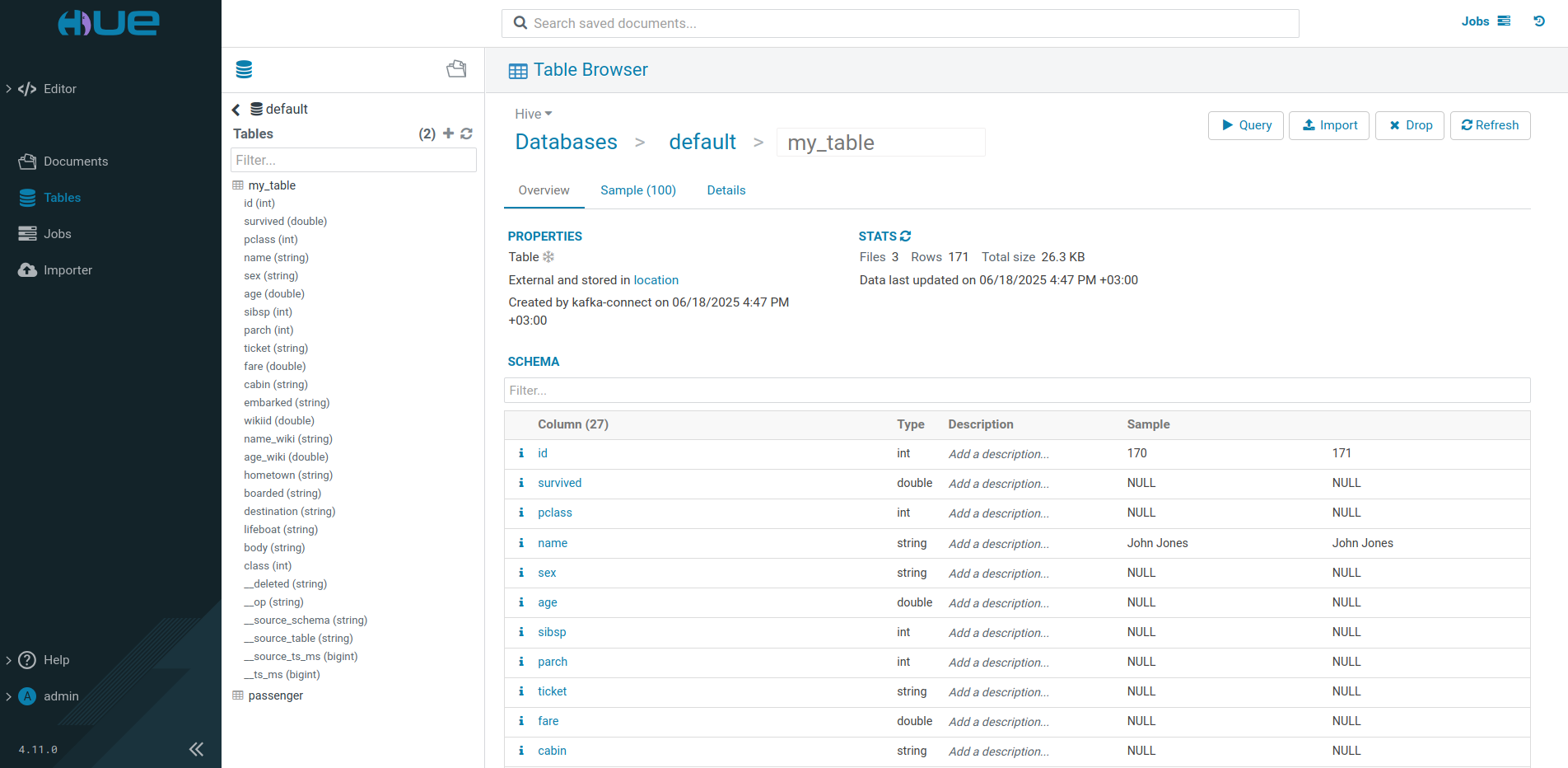
The path to the directory where the table is located is specified on the Databases → default → my_table → Details tab as the Location parameter and matches the value of the hive.metastore.warehouse.dir parameter in the hive-site.xml group of the Hive ADH service parameters.
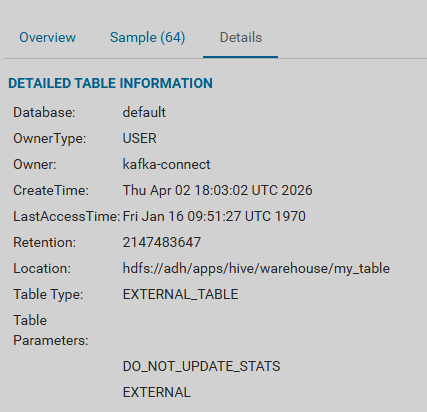
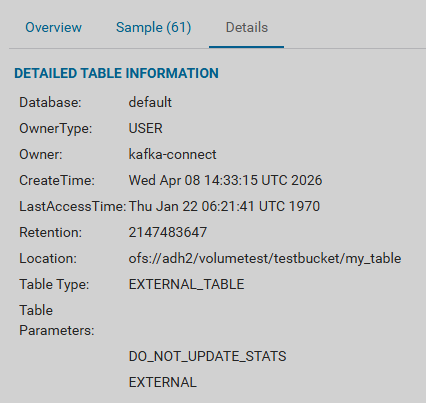
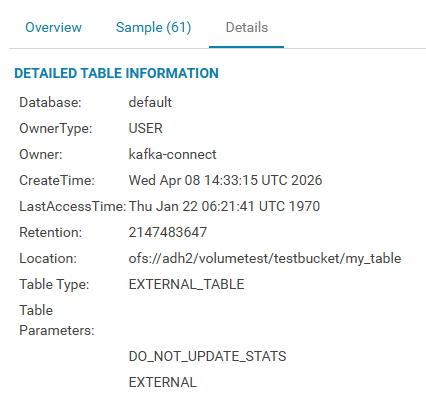
For a table placed in Ozone, messages and metadata can be viewed on the Ozone page in the HUE UI in the corresponding volume and bucket.
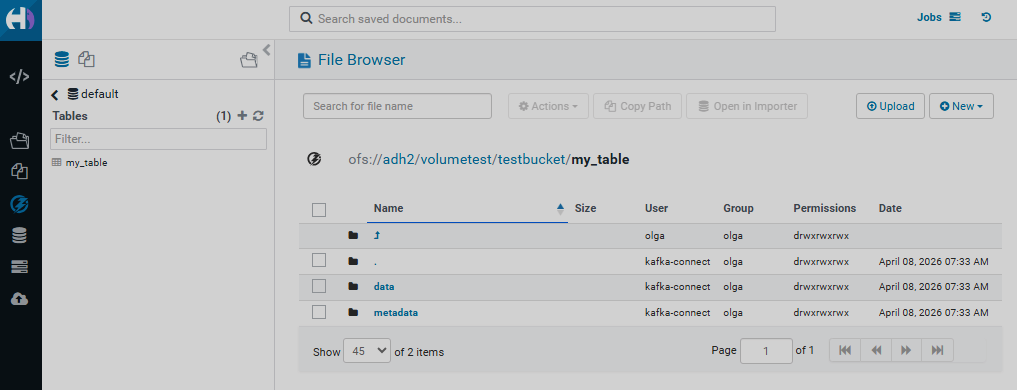
UPSERT mode
Starting from ADS 3.9.0.1.b1, there is an option to specify parameters to enable and configure the UPSERT mode in the Iceberg Sink Connector configuration.
After enabling the UPSERT mode (using the connector parameter iceberg.tables.upsert-mode-enabled), any changes to the Iceberg tables are made in accordance with the following rules:
-
Each operation is an
UPSERT— a combination ofDELETEandINSERToperations. The row is updated in the Iceberg table with the same identifier as in the incoming record. If the row is not found, a record is simply added. This allows for inserting, updating, or deleting records in a single operation without overwriting data. -
If there is a field in the Kafka record indicating the type of operation being performed (
INSERT,UPDATE, orDELETE) and this operation type is specified as the value of the connector parametericeberg.tables.cdc-field, then these operations are executed independently of each other (as they would have been performed without enabling the UPSERT mode). When a new record is attempted, the connector will match the value of the Kafka record operation field with the value of theiceberg.tables.cdc-fieldparameter, and if they match, it will apply this operation to the incoming row. The function for specifying the type of operation can be used when retrieving data from CDC platforms.Users can also configure the values of the
iceberg.tables.cdc-fieldparameter, corresponding to various operations, by applying the following options:-
iceberg.tables.cdc.ops.insert -
iceberg.tables.cdc.ops.update -
iceberg.tables.cdc.ops.delete
Example of specifying options in the connector configuration:
{ "iceberg.tables.cdc-field": "__op", "iceberg.tables.cdc.ops.insert": "c,r", "iceberg.tables.cdc.ops.update": "u", "iceberg.tables.cdc.ops.delete": "d", "iceberg.tables.upsert-mode-enabled": "true", "iceberg.tables.default-id-columns": "id" } -
-
If a Kafka record contains a field specifying the type of operation being performed (
INSERT,UPDATE, orDELETE), and this operation type is listed as the value for the connector parametericeberg.tables.cdc.ops.ignored, then the connector will simply ignore the incoming record.
|
NOTE
Currently, the |
The parameters of the UPSERT mode are described below, as well as the version of ADS starting from which these parameters can be applied.
| Parameter | Description | Default value | ADS version |
|---|---|---|---|
iceberg.tables.upsert-mode-enabled |
Set the value to |
false |
|
iceberg.tables.cdc-field |
The field of the source record that identifies the type of operation ( |
__op |
|
iceberg.tables.default-id-columns |
A list of default comma-separated columns that define the identifier row in tables (primary key). Is a mandatory parameter |
— |
|
iceberg.tables.cdc.ops.insert |
Comma-separated values of the CDC operation field that correspond to |
r,c |
|
iceberg.tables.cdc.ops.update |
Comma-separated values of the CDC operation field that correspond to |
u |
|
iceberg.tables.cdc.ops.delete |
Comma-separated values of the CDC operation field that correspond to |
d |
|
iceberg.tables.cdc.ops.ignored |
Comma-separated values of the CDC operation field that should be ignored by the connector |
t,m |
Deletion vectors
Starting with ADS 4.0.0.b1, deletion vectors are supported for Iceberg v3 tables.
Deletion vectors (DVs) — the row deletion mechanism introduced in Apache Iceberg Spec v3, which uses a Roaring Bitmap attached directly to data files for data deletion, reducing redundant reading and metadata overhead for tables with frequent updates.
For Iceberg v3 tables, setting the write.delete.mode and write.update.mode parameters to merge-on-read enables deletion vectors when deleting and updating records.
Table metadata encryption
Starting with ADS 4.0.0.b1, Iceberg table encryption is supported, including:
-
Encryption of manifest list key metadata when using StandardEncryptionManager.
-
Caching of encryption keys (1-hour TTL) to reduce load on Key Management Service (KMS).
-
AES GCM streaming encryption; the encrypted file length is recorded in the key metadata to protect against attacks.
To support encryption functionality for an Iceberg table/catalog, the Iceberg catalog/table parameters should be configured:
-
encryption.type = standard— enables the standard encryption type. -
encryption.kms-impl— specifies the path to KMS client custom classes. -
encryption.key-id— specifies the identifier of the master key used to encrypt and decrypt the table. Master keys are stored and managed in the KMS.