

Коннектор Iceberg
Обзор Iceberg Sink Connector
Apache Iceberg Sink Connector — коннектор-приемник для записи данных из Kafka в таблицы Iceberg.
Использование Iceberg Sink Connector дает следующие преимущества:
-
Координация сообщений для централизованных коммитов Iceberg.
-
Обеспечение семантики доставки exactly once.
-
Возможность разветвления нескольких таблиц.
-
Автоматическое создание таблиц и эволюция схем.
-
Отображение имени поля с помощью функции сопоставления столбцов Iceberg.
Для иллюстрации преимуществ коннектора в статье показана реализация полного пайплайна с использованием Kafka Connect — захват изменения данных (Change Data Capture, CDC) в таблицах баз данных PostgreSQL с записью изменений в таблицу Iceberg.
Предварительные требования к кластерам ADH и ADS и описание настройки коннектора Iceberg Sink Connector приведены ниже отдельно для каждого доступного хранилища: Hadoop Distributed File System (HDFS) и Apache Ozone (O3).
Предварительные требования
Ниже описано окружение, используемое для создания полного пайплайна CDC.
ADH
-
Кластер ADH развернут согласно руководству Online-установка. Минимальная версия ADH — 3.3.6.2.b1.
-
Сервисы Core configuration, Zookeeper, HDFS, ADPG, Hive, HUE и Impala добавлены и установлены в кластере ADH.
-
В ADH на каждом хосте создан пользователь
kafka-connect, который имеет права на создание таблиц в хранилище HDFS (входит в группуhadoop), например, как показано ниже:$ sudo adduser kafka-connect $ sudo usermod -aG hadoop kafka-connect
-
Кластер ADH развернут согласно руководству Online-установка. Минимальная версия ADH — 3.3.6.2.b1.
-
Сервисы Core configuration, Zookeeper, HDFS, ADPG, Hive, Ozone, HUE и Impala добавлены и установлены в кластере ADH.
-
В ADH на каждом хосте создан пользователь
kafka-connect, который имеет права на создание таблиц в хранилище HDFS (входит в группуhadoop), например, как показано ниже:$ sudo adduser kafka-connect $ sudo usermod -aG hadoop kafka-connect -
Для описываемого примера на хосте, где установлен Ozone, созданы том и бакет:
$ ozone sh volume create volumetest $ sudo ozone sh bucket create /volumetest/testbucket -
Выполнена настройка сервисов ADH для интеграции с Ozone, как описано ниже. Во всех указанных конфигурациях используется
<ozone.om.service.ids>— значение соответствующего параметра компонента Ozone Manager (входящего в группу параметров ozone-site.xml) сервиса Ozone кластера ADH, настроенное во время установки кластера.-
Core configuration
Установите в группе core-site.xml для параметра fs.defaultFS значение
ofs://<ozone.om.service.ids>/для определения имени файловой системы по умолчанию. -
YARN
Установите в группе yarn-site для параметра yarn.node-labels.fs-store.root-dir значение
ofs://<ozone.om.service.ids>/system/yarn/node-labelsдля указания URI для NodeLabelManager. -
Hive
Установите в группе hive-site.xml для параметра hive.metastore.warehouse.dir значение
ofs://<ozone.om.service.ids>/volumetest/testbucketдля указания расположения базы данных по умолчанию для хранилища, где/volumetest/testbucket— том и бакет Ozone, существующие в Ozone или созданные специально ранее.
-
Все настройки для сервисов кластера ADH рекомендуется выполнять во время установки кластера (до запуска действия Install). Изменение настроек для установленных сервисов не гарантирует стабильной работы Iceberg Sink Connector с использованием хранилища Ozone.
ADS и ADS Control
-
Кластер ADS развернут согласно руководству Online-установка. Минимальная версия ADS — 3.7.2.1.b1.
-
Сервисы Zookeeper, Kafka, Kafka Connect и Schema-Registry добавлены и установлены в кластере ADS.
-
Для автоматического создания топика Kafka включен параметр auto.create.topics.enable в группе server.properties при конфигурировании сервиса Kafka.
-
При конфигурировании сервиса Kafka Connect в группе параметров connect-distributed.properties для параметра plugin.path добавлено новое значение
/usr/lib/kafka-connect/plugins, как показано ниже.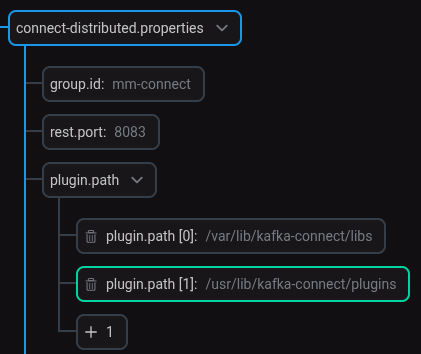 Настройка пути к плагину Iceberg Sink Connector
Настройка пути к плагину Iceberg Sink ConnectorНастройка пути к плагину требуется только для ADS 3.7.2.1.b1.
-
Конфигурация кластера ADH, используемого в пайплайне, импортирована в кластер ADS.
Для включения импорта на вкладке Import кластера ADS выберите Cluster configuration напротив названия кластера ADH и нажмите Import.
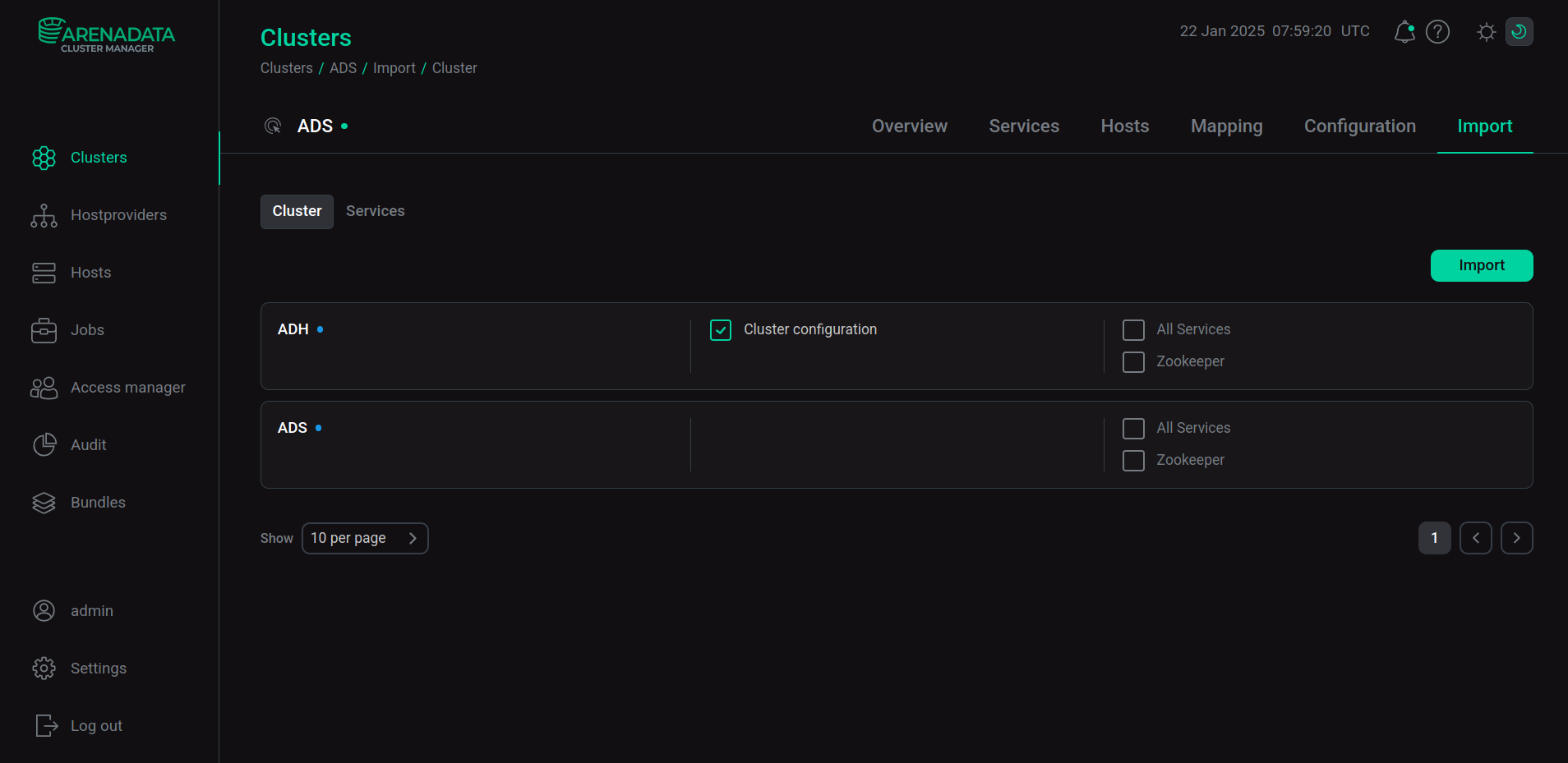 Импорт данных ADH
Импорт данных ADHВ результате импорта в директории /usr/lib/kafka/config/ должны находиться конфигурационные файлы ADH: core-site-xml и hdfs-site-xml.
-
Кластер ADS Control развернут согласно руководству Установка и интегрирован с использующимся кластером ADS.
-
Кластер ADS развернут согласно руководству Online-установка. Минимальная версия ADS — 3.9.1.2.b1.
-
Сервисы Zookeeper, Kafka, Kafka Connect и Schema-Registry добавлены и установлены в кластере ADS.
-
Для автоматического создания топика Kafka включен параметр auto.create.topics.enable в группе server.properties при конфигурировании сервиса Kafka.
-
Конфигурация кластера ADH, используемого в пайплайне, импортирована в кластер ADS.
Для включения импорта на вкладке Import кластера ADS выберите Cluster configuration напротив названия кластера ADH и нажмите Import.
Импорт данных ADHВ результате импорта в директории /usr/lib/kafka/config/ должны находиться конфигурационные файлы ADH: core-site-xml и hdfs-site-xml.
Импорт конфигурации кластера ADH необходимо выполнить после настройки сервисов ADH для интеграции с Ozone.
-
Кластер ADS Control развернут согласно руководству Установка и интегрирован с использующимся кластером ADS.
ADPG
-
Кластер ADPG развернут согласно руководству Online-установка.
-
IP-адрес PostgreSQL server (хост с сервисом ADPG) —
10.92.43.42. Для входящих подключений по умолчанию используется порт с номером5432. -
Для создания коннектора Debezium аналогично описанному в статье Коннектор Debezium для PostgreSQL server установлены настройки кластера ADPG через пользовательский интерфейс ADCM (настройка доступа к базе данных c хоста Kafka Connect в файле pg_hba.conf и параметра wal_level в файле postgresql.conf).
Ниже приведен пример создания и настройки базы данных PostgreSQL (в кластере ADPG).
Создание базы данных:
CREATE DATABASE my_database;Подключение к базе:
\c my_databaseСоздание пользователя с ролью SUPERUSER:
CREATE USER my_user WITH SUPERUSER PASSWORD 'P@ssword';|
ВНИМАНИЕ
Роль пользователя SUPERUSER используются только для тестовых целей. Для получения более подробной информации см. Настройка разрешений для коннектора Debezium.
|
Создание тестовой таблицы:
CREATE TABLE my_table (
id BIGSERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
country VARCHAR(100),
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);Настройка идентификации реплики для таблицы, чтобы включить возможность использования индексов BIGSERIAL PRIMARY KEY на стороне подписчика для поиска строк:
ALTER TABLE my_table REPLICA IDENTITY FULL;Заполнение таблицы данными (приведено как пример, для наглядности необходимо несколько строк):
INSERT INTO my_table(name, country) VALUES ('John Jones','USA');|
ПРИМЕЧАНИЕ
|
Создание коннектора Debezium для PostgreSQL server
Для захвата изменения данных на уровне строк в таблицах баз данных PostgreSQL при помощи ADS Control создайте коннектор Debezium аналогично описанному в статье Коннектор Debezium для PostgreSQL server.
Ниже приведен пример конфигурации Debezium-коннектора с описанием новых параметров, применяющихся в пайплайне данных.
{
"name": "cdc-my-adpg-new",
"topic.prefix": "cdc__demo",
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"publication.autocreate.mode": "filtered",
"database.user": "my_user",
"database.dbname": "my_database",
"tasks.max": 1,
"database.port": 5432,
"plugin.name": "pgoutput",
"database.hostname": "10.92.43.42",
"database.password": "P@ssword",
"table.include.list": ["public.my_table"],
"value.converter.schema.registry.url": "http://10.92.42.130:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://10.92.42.130:8081",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"transforms": ["unwrap"],
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.add.fields": "op,source.schema,source.table,source.ts_ms,ts_ms",
"transforms.unwrap.add.headers": "db",
"transforms.unwrap.delete.handling.mode": "rewrite",
"slot.name": "cdc__my_database",
"schema.evolution": "basic"
}| Атрибут | Описание |
|---|---|
value.converter.schema.registry.url |
Адрес сервера Schema-Registry |
key.converter.schema.registry.url |
Адрес сервера Schema-Registry |
transforms |
Список трансформаций, которые будут применяться к записям |
transforms.unwrap.type |
Класс, используемый для трансформации |
transforms.unwrap.add.fields |
Дополнительные поля, добавляемые к данным |
transforms.unwrap.add.headers |
Добавление метаданных в заголовок сообщения Kafka |
transforms.unwrap.delete.handling.mode |
Определяет, как обрабатывать события удаления. |
table.include.list |
Необязательный список регулярных выражений, разделенных запятыми, соответствующих идентификаторам таблиц, изменения которых необходимо захватить. Если это свойство задано, коннектор захватывает изменения только из указанных таблиц. Каждый идентификатор должен иметь форму
|
slot.name |
Имя логического слота декодирования PostgreSQL, созданного для потоковой передачи. Сервер использует этот слот для потоковой передачи событий на коннектор Debezium. Должен быть уникальным для каждого коннектора, подключаемого к базе |
schema.evolution |
Указывает режим эволюции схемы. При указании значения |
Создание коннектора Iceberg
Для создания коннектора Iceberg через ADS Control используется плагин коннектора IcebergSinkConnector.
Для создания коннекторов при помощи ADS Control:
-
Перейдите на страницу Kafka Connects в web-интерфейсе ADS Control. Страница Kafka Connects становится доступна после выбора кластера в секции управления кластерами и перехода на нужную вкладку на странице General.
-
Выберите нужный кластер и перейдите на страницу обзора экземпляра Kafka Connect.
-
Нажмите кнопку Create Connector на странице обзора экземпляра Kafka Connect. После нажатия кнопки Create Connector открывается окно выбора плагина коннектора Clusters → <cluster name> → Kafka Connects → <cluster name> connector → Kafka connector plugins.
-
Выберите нужный коннектор для создания.
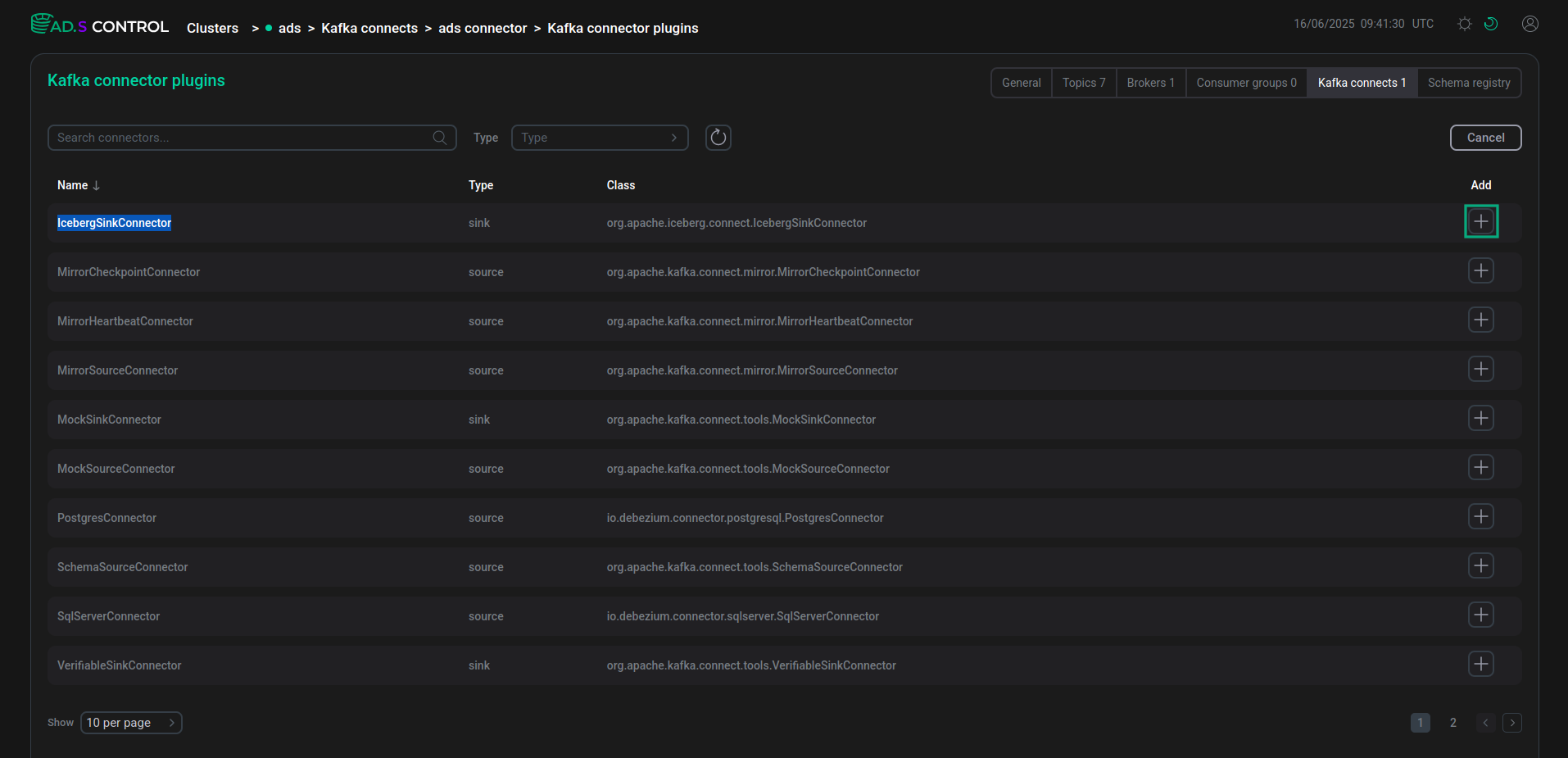 Выбор плагина для создания коннектора
Выбор плагина для создания коннектора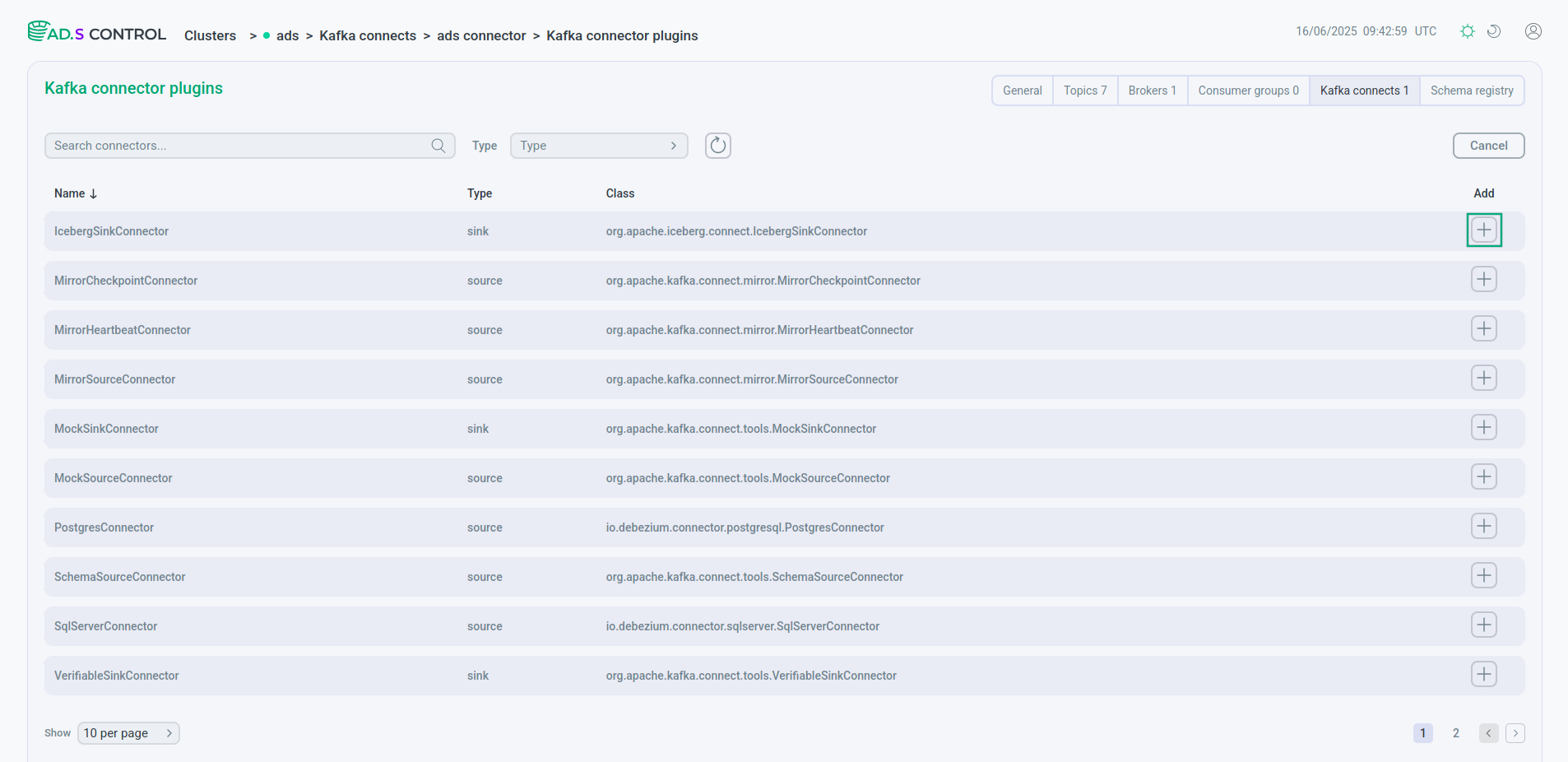 Выбор плагина для создания коннектора
Выбор плагина для создания коннектора -
Заполните параметры конфигурации коннектора. При необходимости воспользуйтесь информацией о параметрах:
-
в статье Конфигурационные параметры Kafka Connect;
-
в описании конфигурации Iceberg-коннектора.
Вы можете использовать заполнение конфигурации в виде файла JSON. Для этого включите переключатель JSON view.
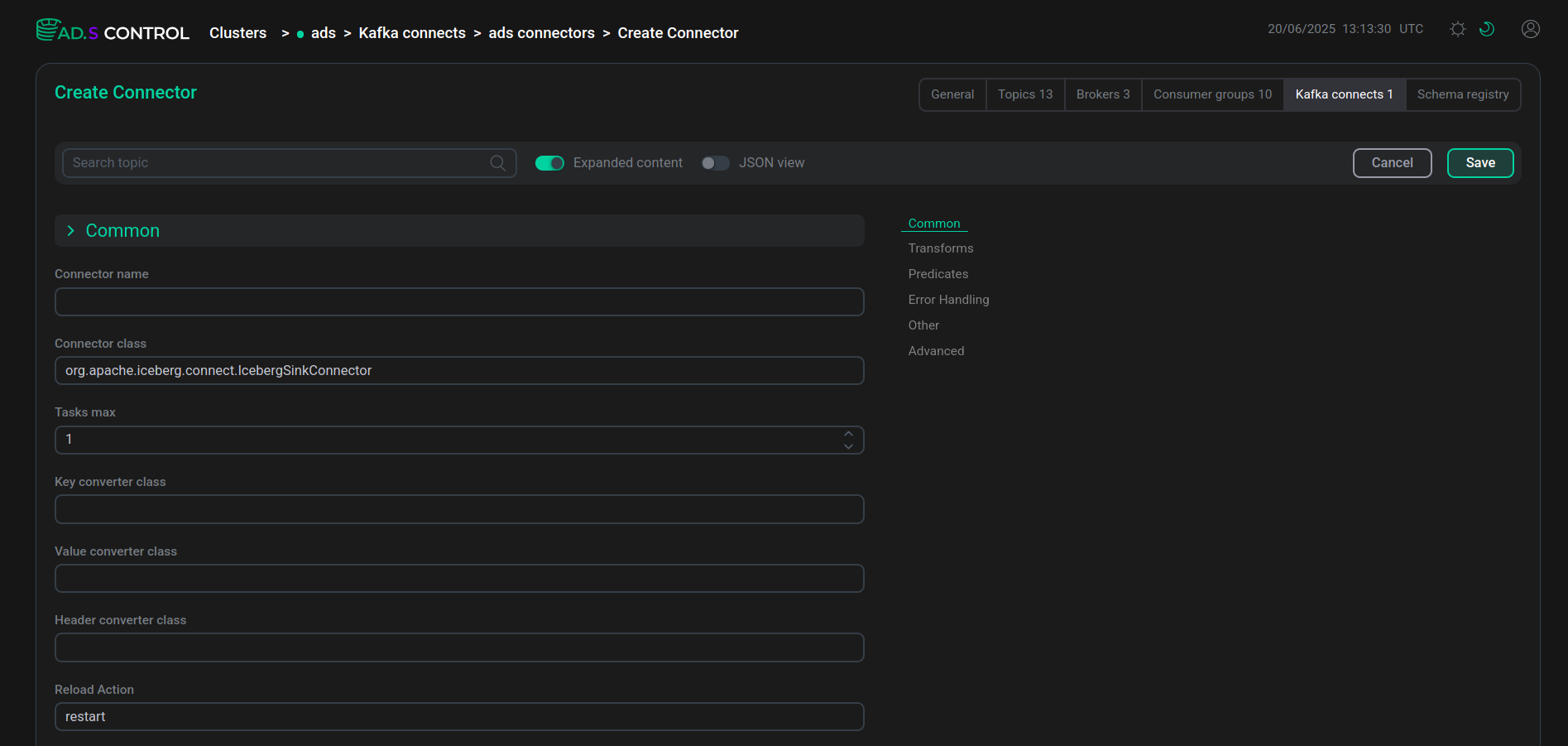 Конфигурация коннектора
Конфигурация коннектора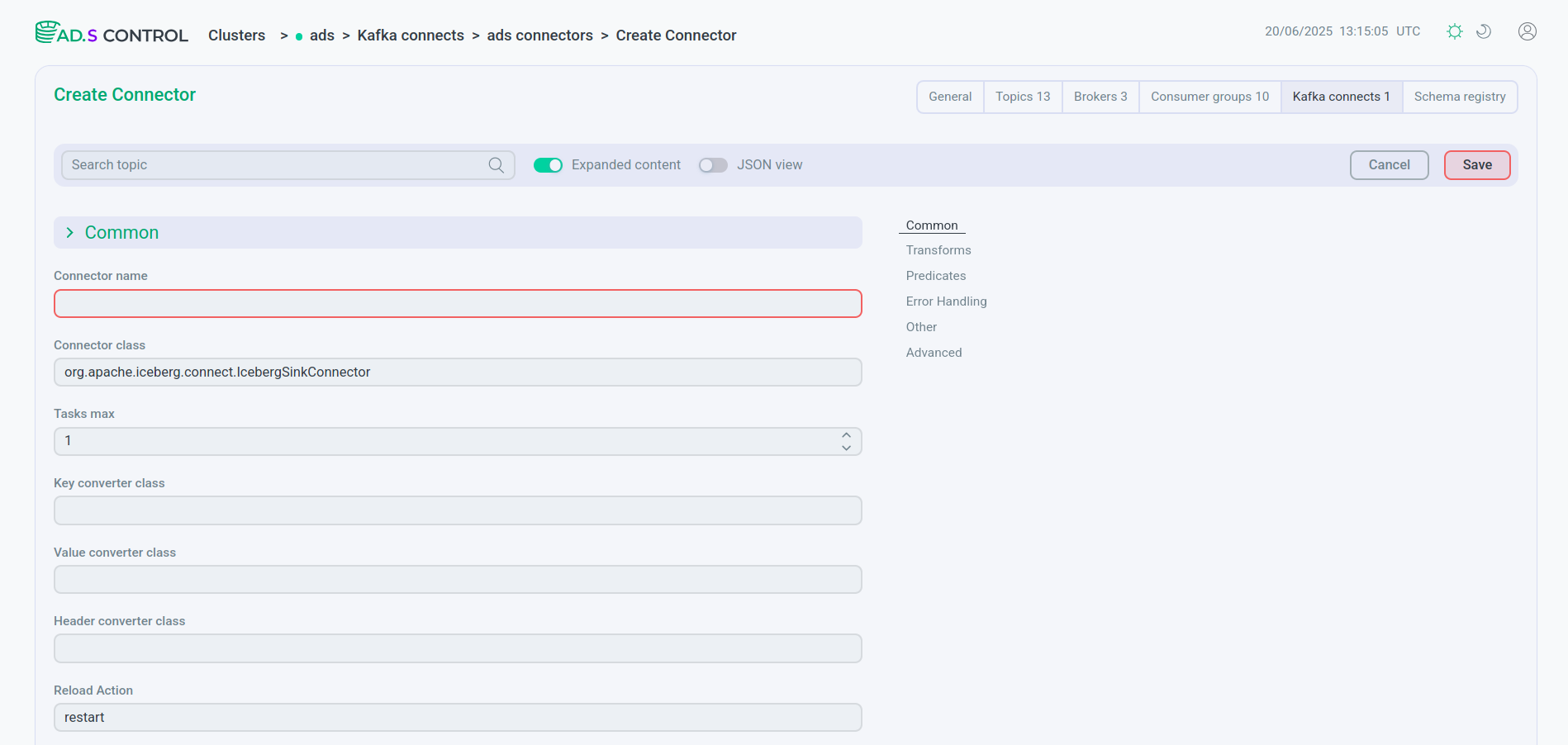 Конфигурация коннектора
Конфигурация коннектора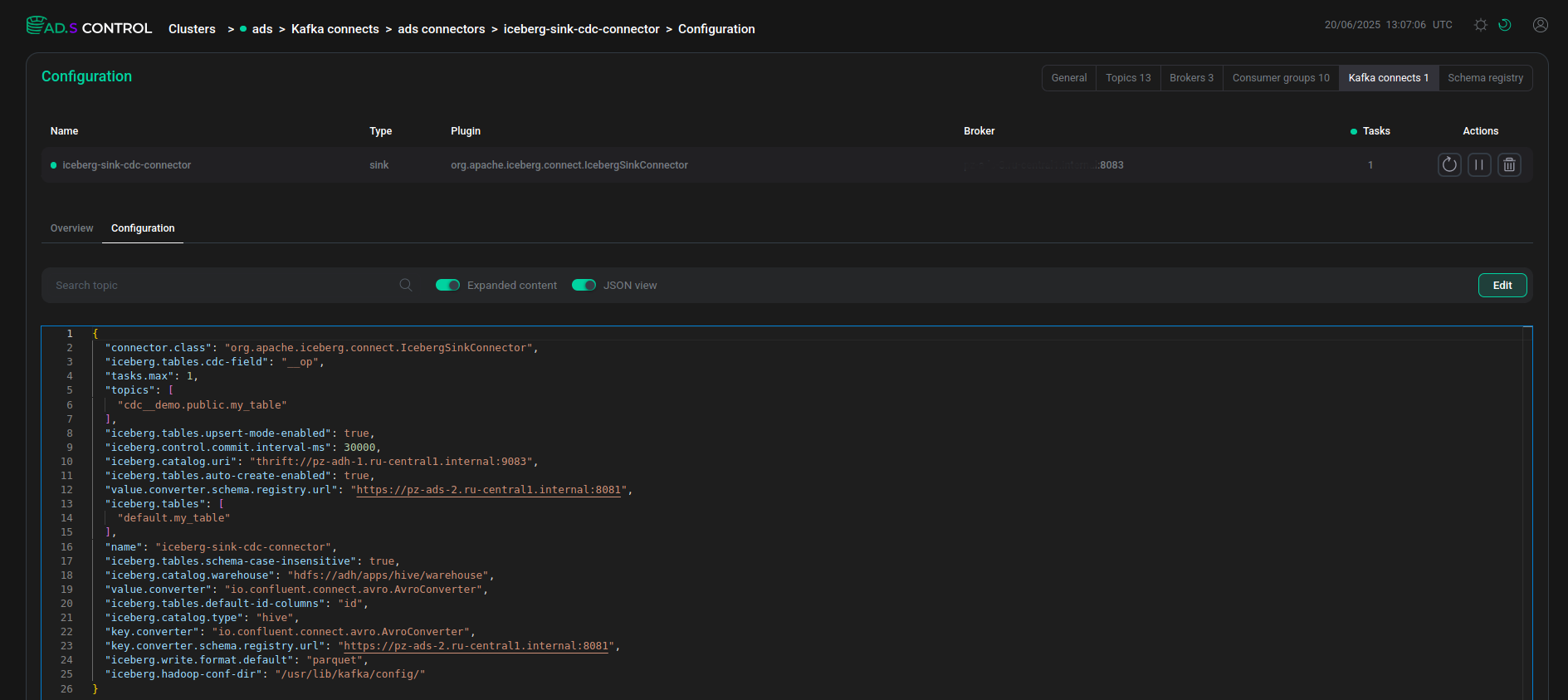 JSON-файл конфигурации коннектора
JSON-файл конфигурации коннектора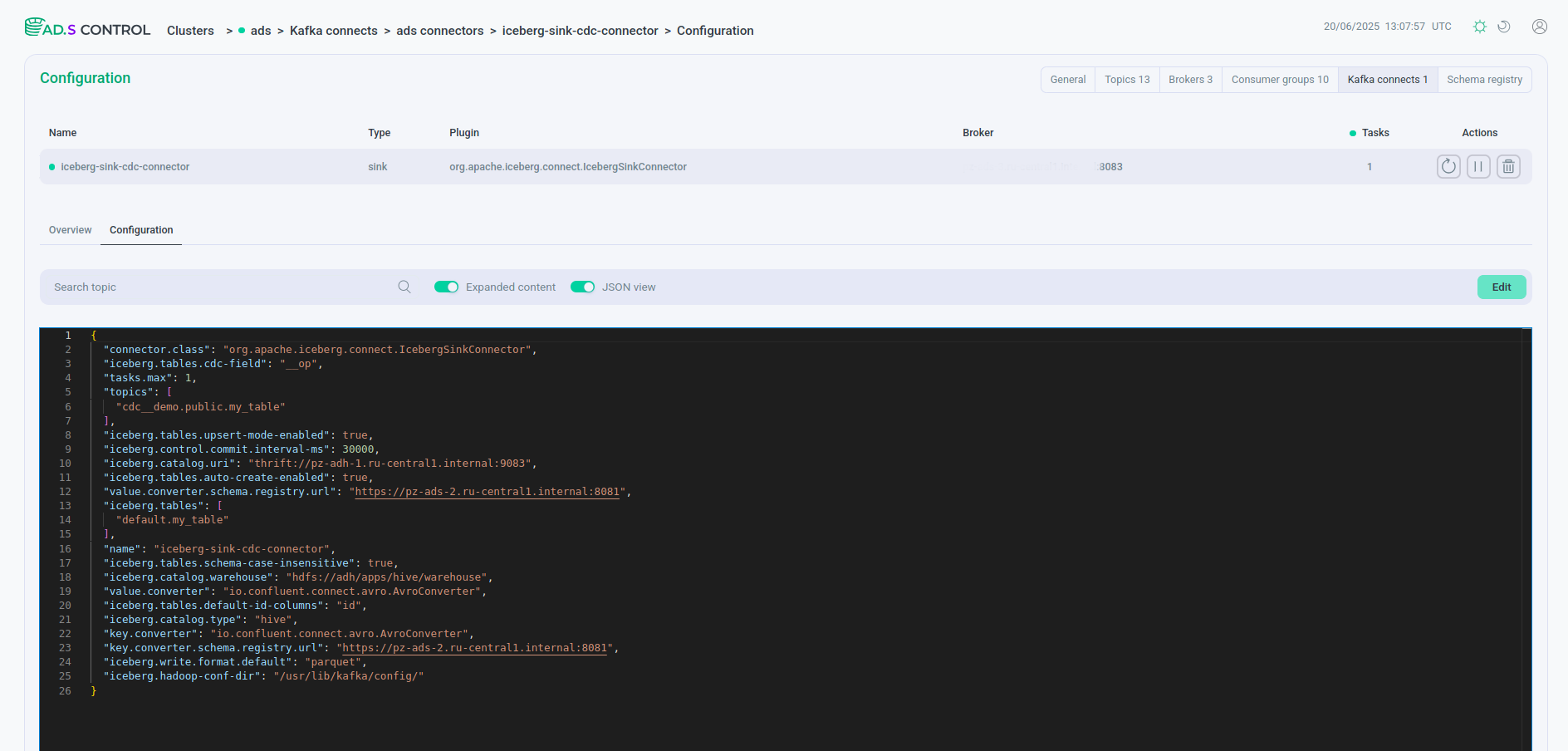 JSON-файл конфигурации коннектораПример содержимого JSON-файла конфигурации коннектора Iceberg Sink Connector с использованием HDFS
JSON-файл конфигурации коннектораПример содержимого JSON-файла конфигурации коннектора Iceberg Sink Connector с использованием HDFS{ "connector.class": "org.apache.iceberg.connect.IcebergSinkConnector", "iceberg.tables.cdc-field": "__op", "tasks.max": 1, "topics": [ "cdc__demo.public.my_table" ], "iceberg.tables.upsert-mode-enabled": true, "iceberg.control.commit.interval-ms": 30000, "iceberg.catalog.uri": "thrift://10.92.43.153:9083", "iceberg.connect.hdfs.keytab": "/etc/security/keytabs/kafka-connect.service.keytab", "iceberg.tables.auto-create-enabled": true, "value.converter.schema.registry.url": "http://10.92.42.130:8081", "iceberg.connect.hdfs.principal": "kafka-connect/sov-ads-6.ru-central1.internal@ADS-KAFKA.LOCAL", "iceberg.tables": [ "default.my_table" ], "name": "iceberg-sink-cdc-connector", "iceberg.tables.schema-case-insensitive": true, "iceberg.catalog.warehouse": "hdfs://adh/apps/hive/warehouse", "value.converter": "io.confluent.connect.avro.AvroConverter", "iceberg.tables.default-id-columns": "id", "iceberg.hdfs.authentication.kerberos": true, "iceberg.catalog.type": "hive", "key.converter": "io.confluent.connect.avro.AvroConverter", "key.converter.schema.registry.url": "http://10.92.42.130:8081", "iceberg.write.format.default": "parquet", "iceberg.hadoop-conf-dir": "/usr/lib/kafka/config/" }Пример содержимого JSON-файла конфигурации Iceberg Sink Connector с использованием Ozone{ "connector.class": "org.apache.iceberg.connect.IcebergSinkConnector", "iceberg.tables.cdc-field": "__op", "tasks.max": 1, "topics": [ "cdc__demo.public.my_table" ], "iceberg.tables.upsert-mode-enabled": true, "iceberg.control.commit.interval-ms": 30000, "iceberg.catalog.uri": "thrift://10.92.38.137:9083", "iceberg.connect.hdfs.keytab": "/etc/security/keytabs/kafka-connect.service.keytab", "iceberg.tables.auto-create-enabled": true, "value.converter.schema.registry.url": "http://10.92.38.143:8081", "iceberg.connect.hdfs.principal": "kafka-connect/sov-ads-6.ru-central1.internal@ADS-KAFKA.LOCAL", "iceberg.tables": [ "default.my_table" ], "name": "iceberg-sink-cdc-connector", "iceberg.tables.schema-case-insensitive": true, "iceberg.catalog.warehouse": "ofs://adh2/volumetest/testbucket", "value.converter": "io.confluent.connect.avro.AvroConverter", "iceberg.tables.default-id-columns": "id", "iceberg.hdfs.authentication.kerberos": true, "iceberg.catalog.type": "hive", "key.converter": "io.confluent.connect.avro.AvroConverter", "key.converter.schema.registry.url": "http://10.92.38.143:8081", "iceberg.write.format.default": "parquet", "iceberg.hadoop-conf-dir": "/usr/lib/kafka/config/" }Описание параметров Iceberg Sink Connector, используемых в примерах, приведено ниже.
Описание параметров для настройки Iceberg Sink ConnectorАтрибут Описание name
Название коннектора, которое будет использоваться в сервисе Kafka Connect
connector.class
Имя класса для коннектора
tasks.max
Максимальное количество создаваемых задач
topics
Имя топика, данные которого должны будут переданы в таблицы Iceberg. Для реализации пайплайна CDC имя топика имеет форму
<topic.prefix>.<table.include.list>, состоящую из параметров Debezium-коннектора, созданного вышеiceberg.tables
Список таблиц назначения, разделенных запятыми
iceberg.write.format.default
Формат файла по умолчанию для таблицы:
parquet,avroилиorciceberg.tables.auto-create-enabled
Установите значение
trueдля автоматического создания целевых таблицiceberg.tables.schema-case-insensitive
Установите значение
trueдля поиска столбцов таблицы по имени без учета регистраiceberg.tables.upsert-mode-enabled
Установите значение
trueдля включения UPSERT-режимаiceberg.tables.cdc-field
Поле исходной записи, которое идентифицирует тип операции (
INSERT,UPDATEилиDELETE) при включенном UPSERT-режимеiceberg.tables.default-id-columns
Список столбцов по умолчанию, разделенных запятыми, которые определяют строку идентификатора в таблицах (primary key). Является обязательным параметром при включенном UPSERT-режиме
iceberg.catalog.type
Тип каталога для хранения таблиц Iceberg
iceberg.catalog.uri
Адрес для подключения к каталогу с таблицами Iceberg (адрес хоста с установленным компонентом Hive Metastore)
iceberg.hdfs.authentication.kerberos
Флаг для включения/выключения аутентификации в HDFS по протоколу Kerberos (по умолчанию выключен). Используется при включенной Kerberos-аутентификации в ADS и ADH. Доступен к использованию начиная с ADS 3.9.0.1.b1
iceberg.connect.hdfs.principal
Имя принципала Kerberos для использования в аутентификации. Является обязательным параметром при включенной Kerberos-аутентификации. Доступен к использованию начиная с ADS 3.9.0.1.b1
iceberg.connect.hdfs.keytab
Путь к keytab-файлу Kerberos, который содержит ключ для принципала. Является обязательным параметром при включенной Kerberos-аутентификации. Доступен к использованию начиная с ADS 3.9.0.1.b1
iceberg.hadoop-conf-dir
Путь к файлам конфигурации брокера Kafka
iceberg.catalog.warehouse
Путь к хранению метаданных. Должен совпадать со значением параметра hive.metastore.warehouse.dir в группе hive-site.xml для Hive
key.converter
Тип конвертера для ключа сообщения
key.converter.schema.registry.url
Адрес сервера Schema-Registry
value.converter
Тип конвертера для значения сообщения
value.converter.schema.registry.url
Адрес сервера Schema-Registry
iceberg.control.commit.interval-ms
Интервал между коммитами в мс
-
-
После заполнения кликните Save и получите сообщение об успешном создании коннектора.
 Сообщение об успешном создании коннектора
Сообщение об успешном создании коннектора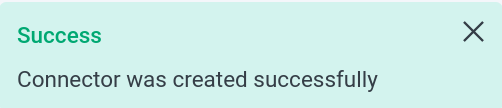 Сообщение об успешном создании коннектора
Сообщение об успешном создании коннектора -
На открывшейся странице запустите коннектор, используя иконку

 .
. -
Проверьте, что запущенный коннектор находится в рабочем статусе.
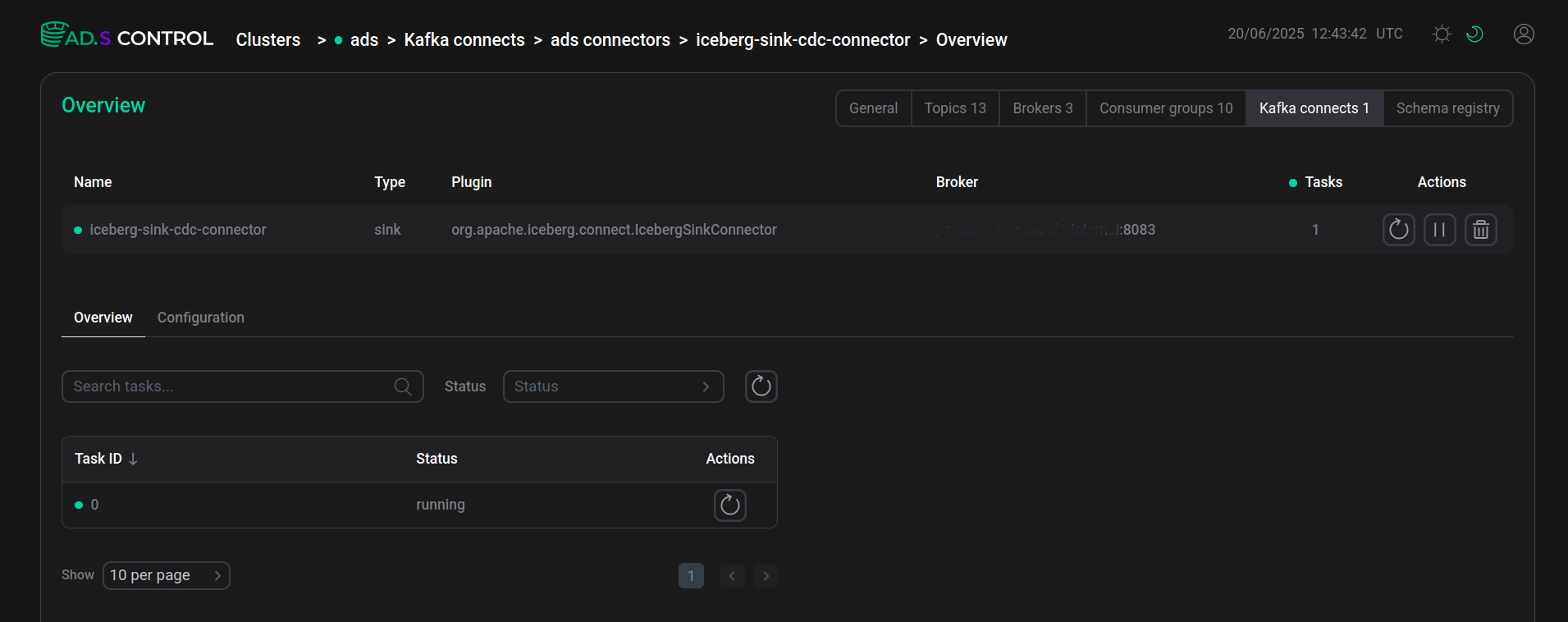 Созданный и запущенный коннектор
Созданный и запущенный коннектор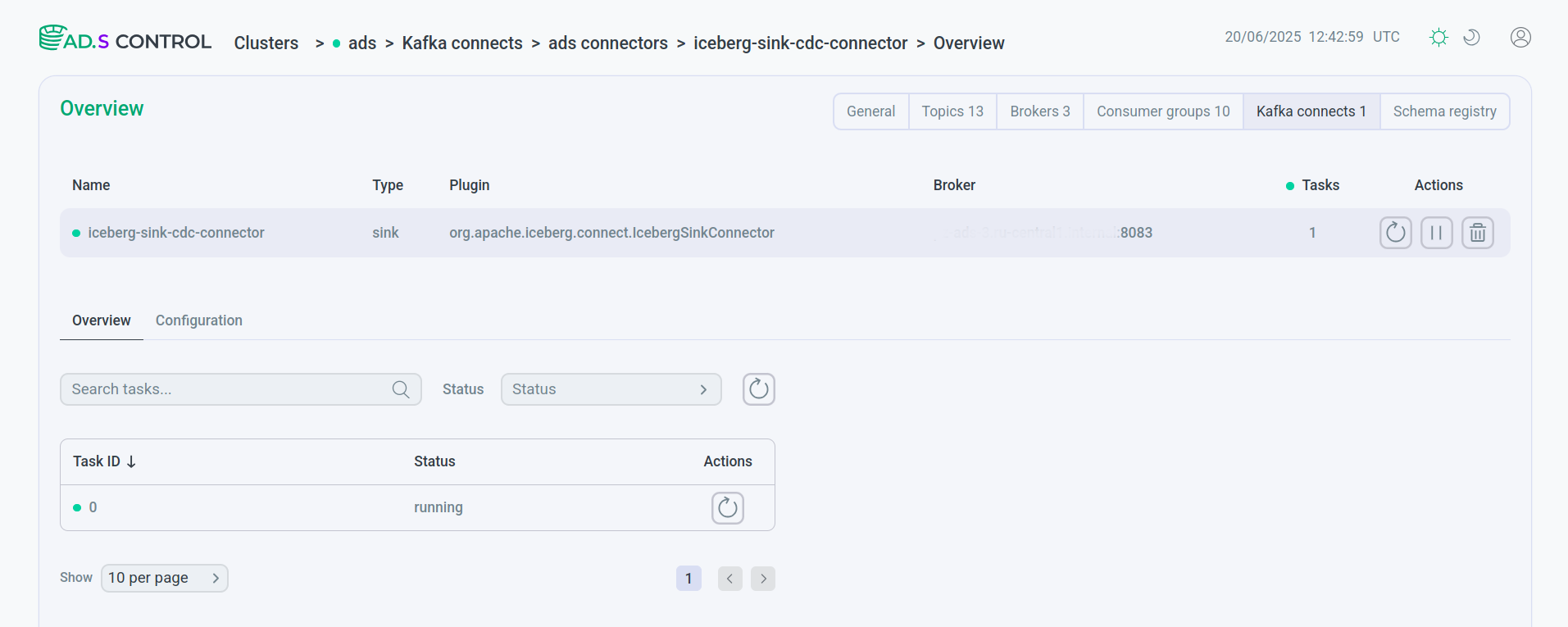 Созданный и запущенный коннектор
Созданный и запущенный коннекторВ случае, если после создания коннектора задача создана с ошибкой, сообщение об ошибке можно увидеть после нажатия иконки
 , расположенной в поле Status задачи.
, расположенной в поле Status задачи.
Данные таблицы PostgreSQL в ADS Control
На странице Topics пользовательского интерфейса ADS Control отображается топик со всеми полями и содержимым таблицы PostgreSQL, созданный коннектором Debezium.
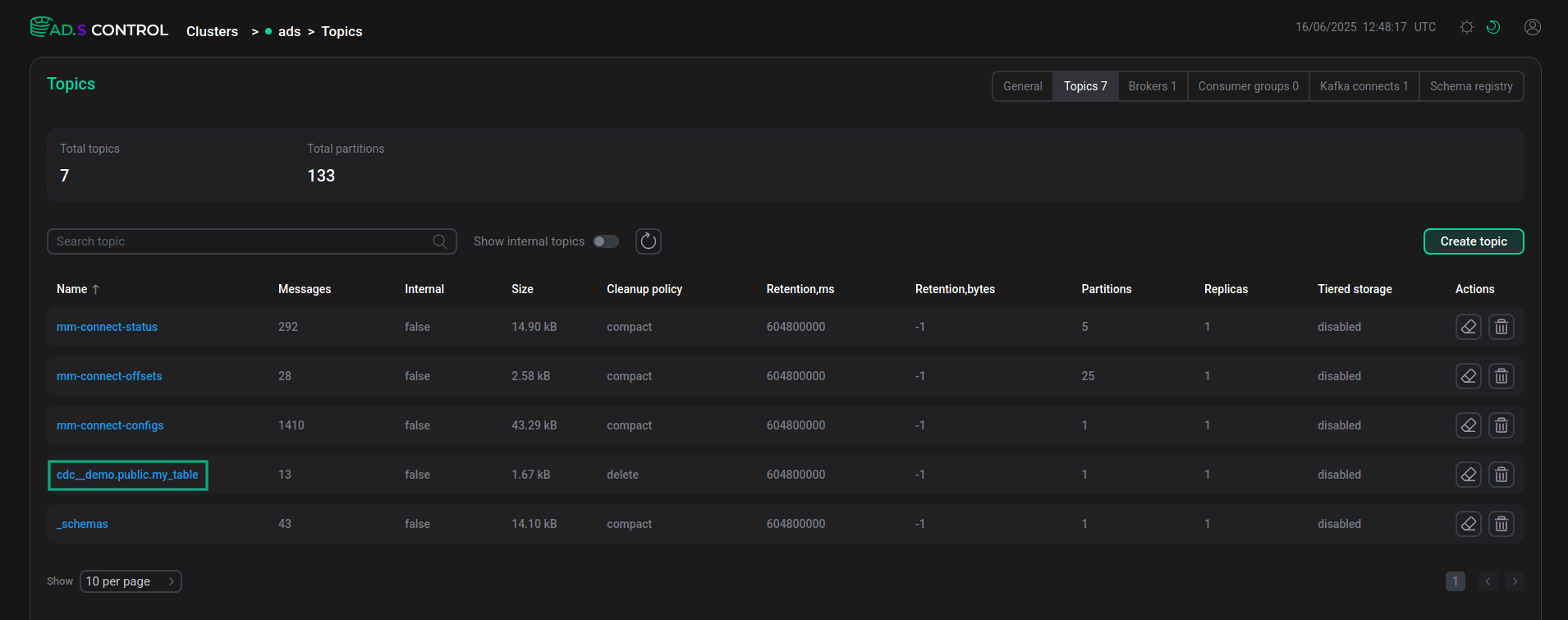
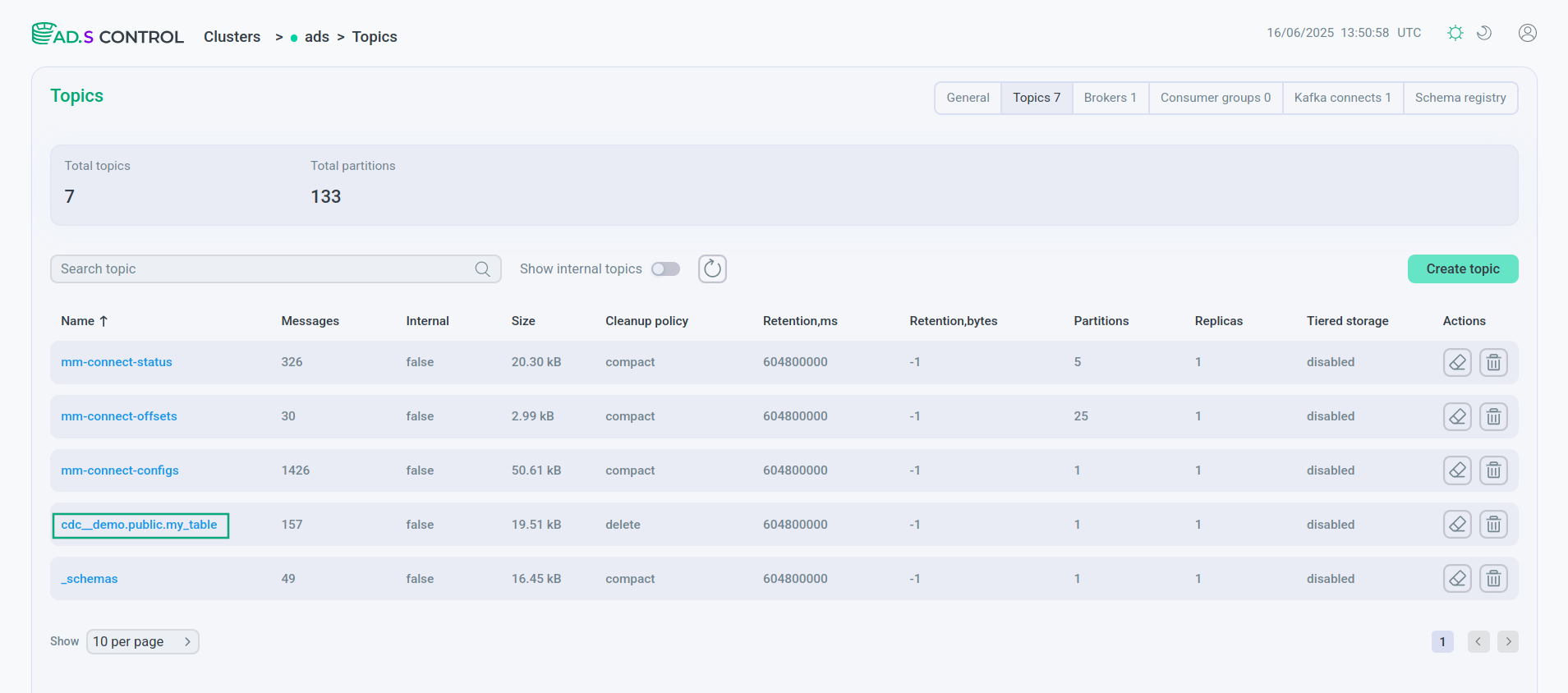
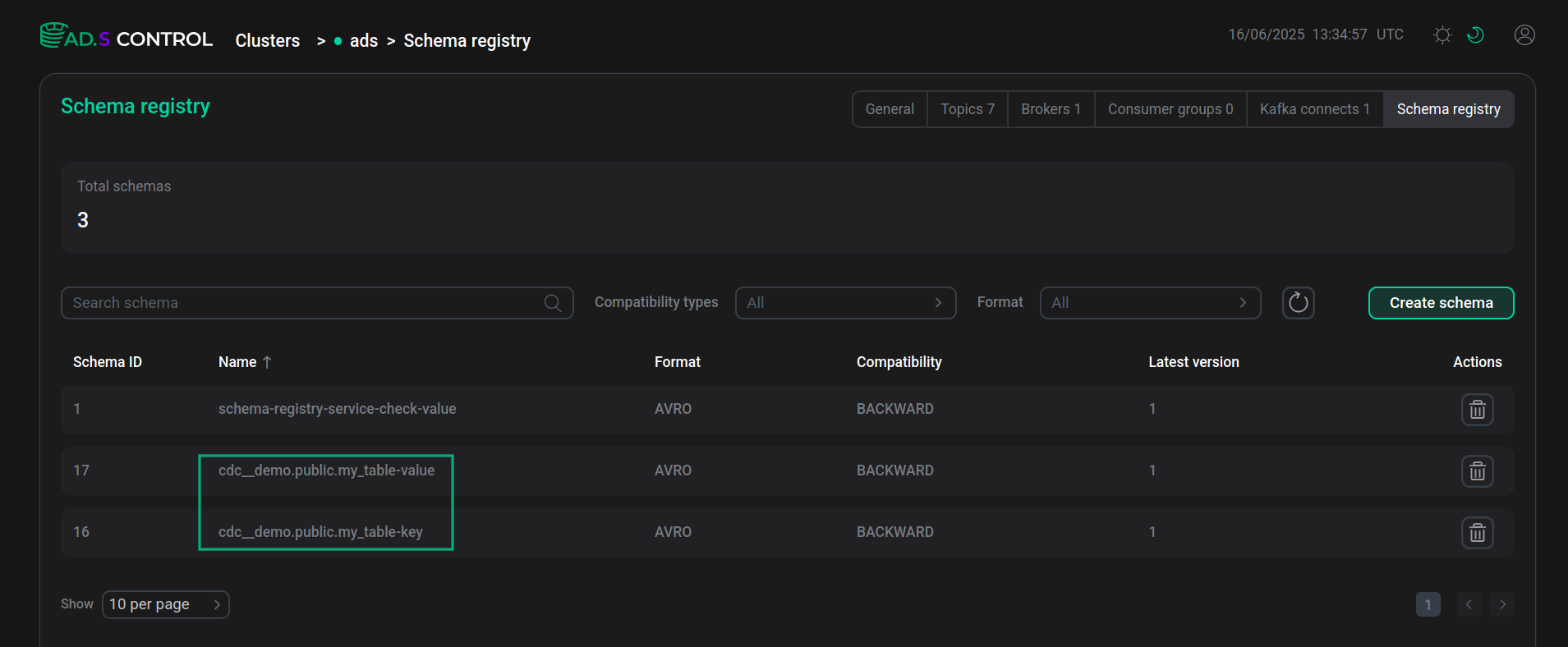
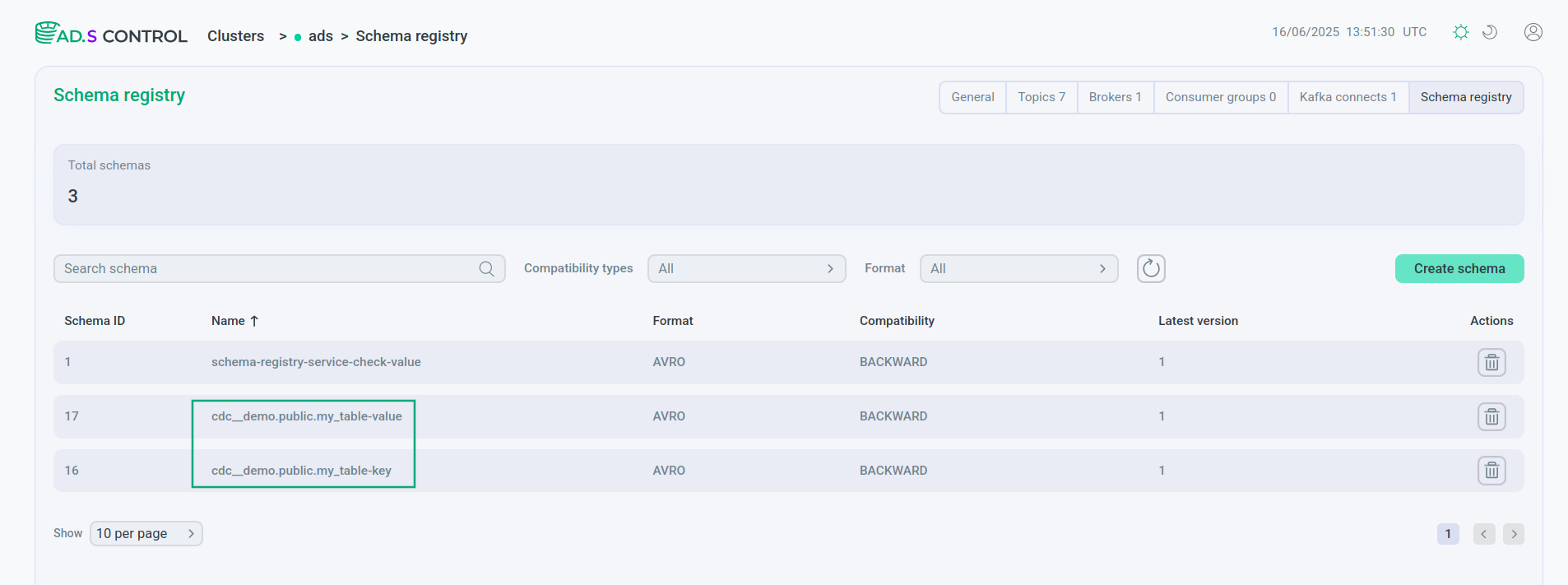
На странице Schema-Registry пользовательского интерфейса ADS Control отображаются созданные в Schema-Registry схемы для ключей и значений таблицы.
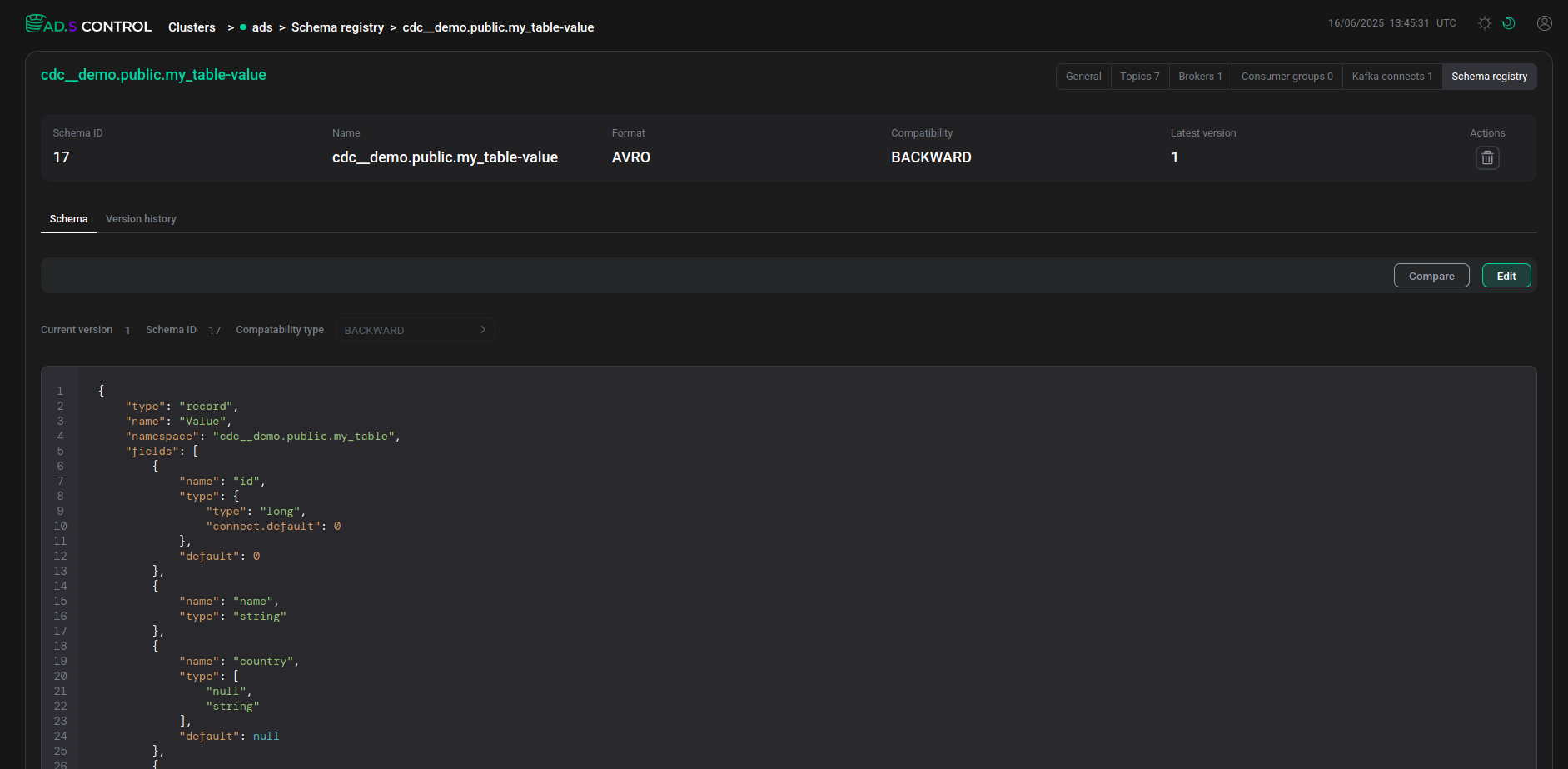
На вкладке схемы отображается описание всех полей таблицы, включая поля, добавленные при помощи параметра transforms.unwrap.add.fields при создании коннектора Debezium.
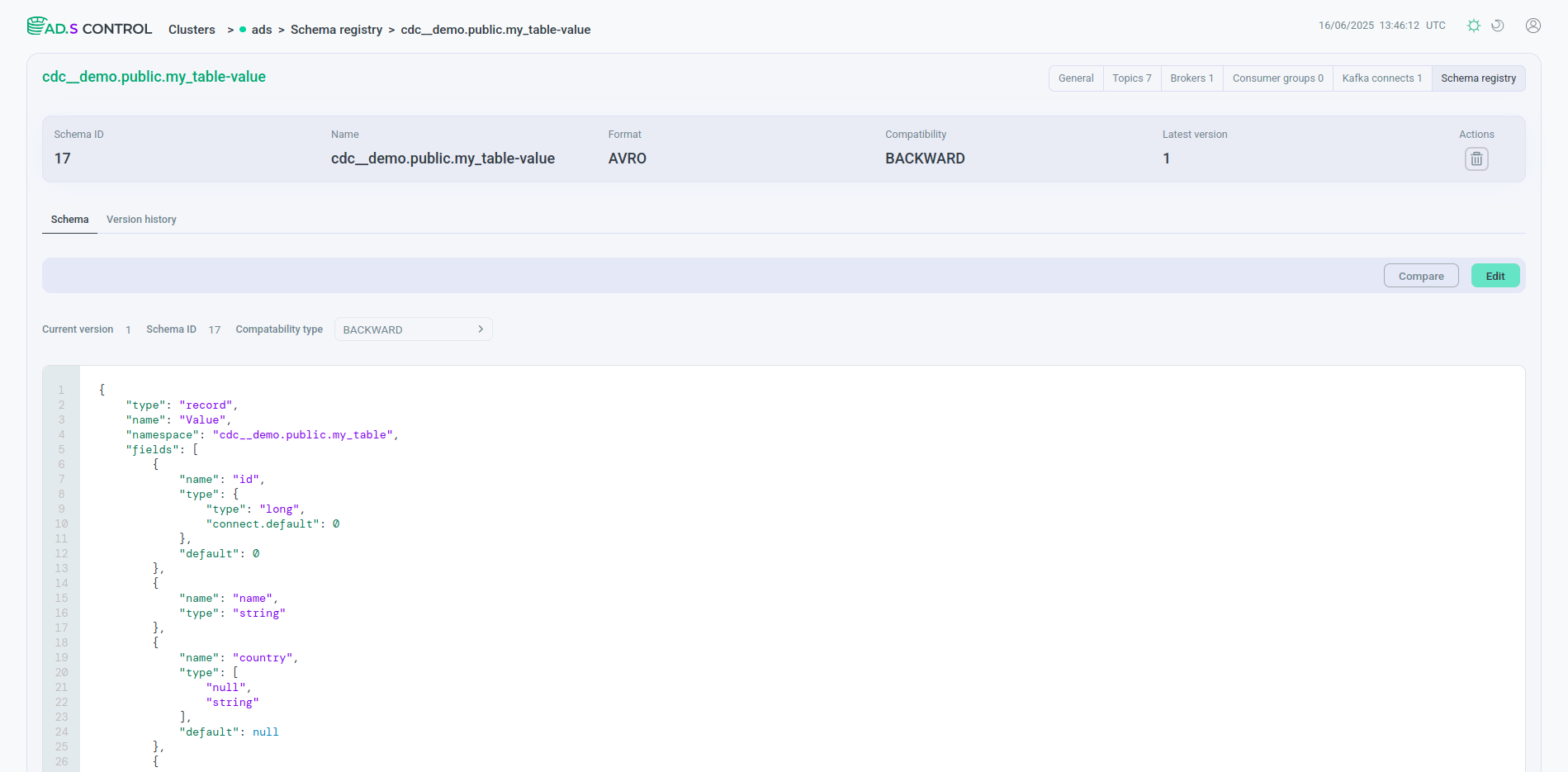
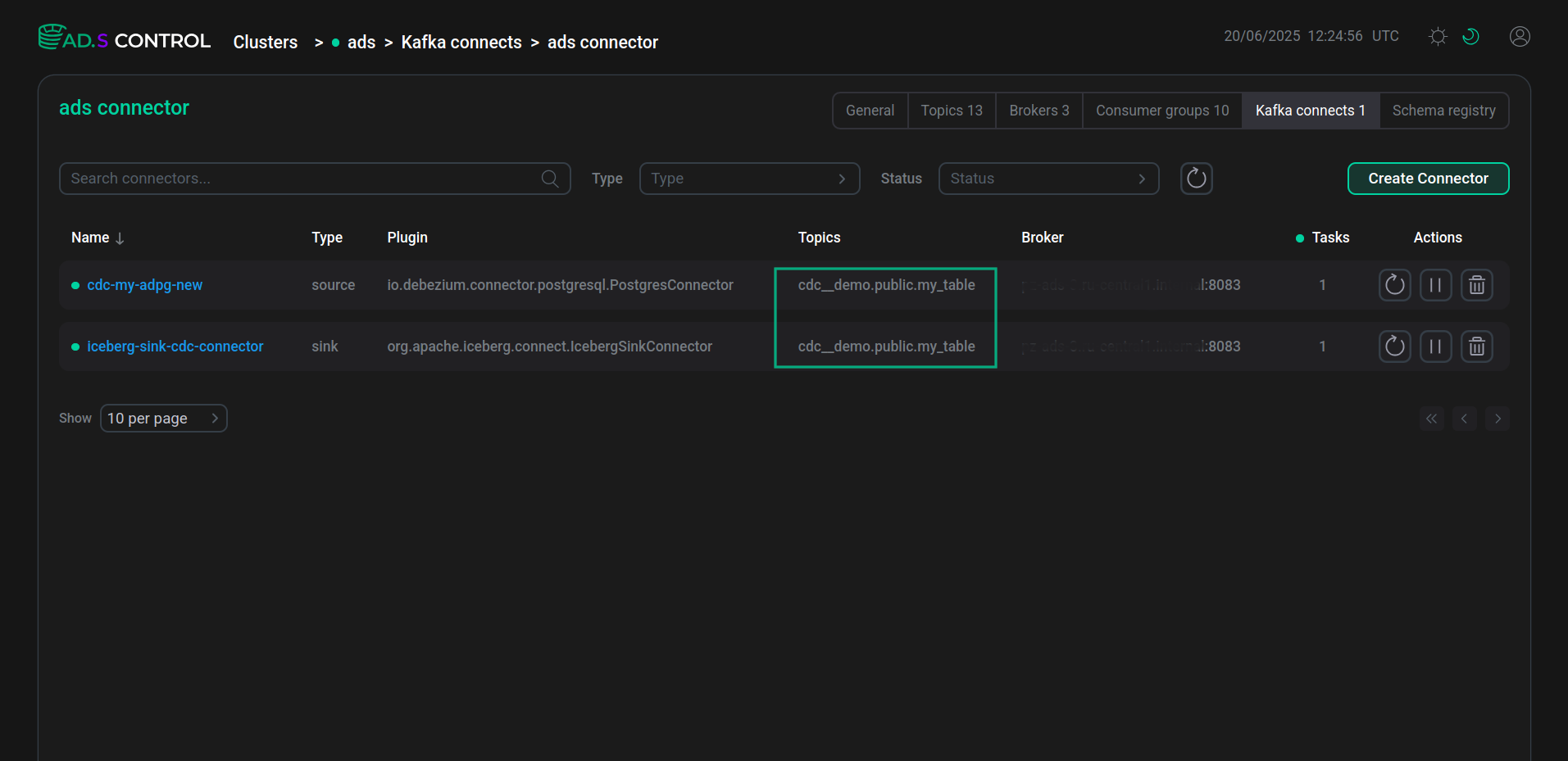
В результате создания пайплайна данных в таблице коннекторов на странице обзора экземпляра Kafka Connect оба созданных коннектора имеют в столбце Topic имя одного и того же обрабатываемого топика.
Таблицы Iceberg
Для проверки сбора изменений коннектором Debezium добавьте запись в таблицу PostgreSQL:
INSERT INTO my_table(name, country) VALUES ('NAME','COUNTRY');После подключения к пользовательскому интерфейсу сервиса HUE из состава кластера ADH можно просматривать таблицы Iceberg, созданные коннектором.
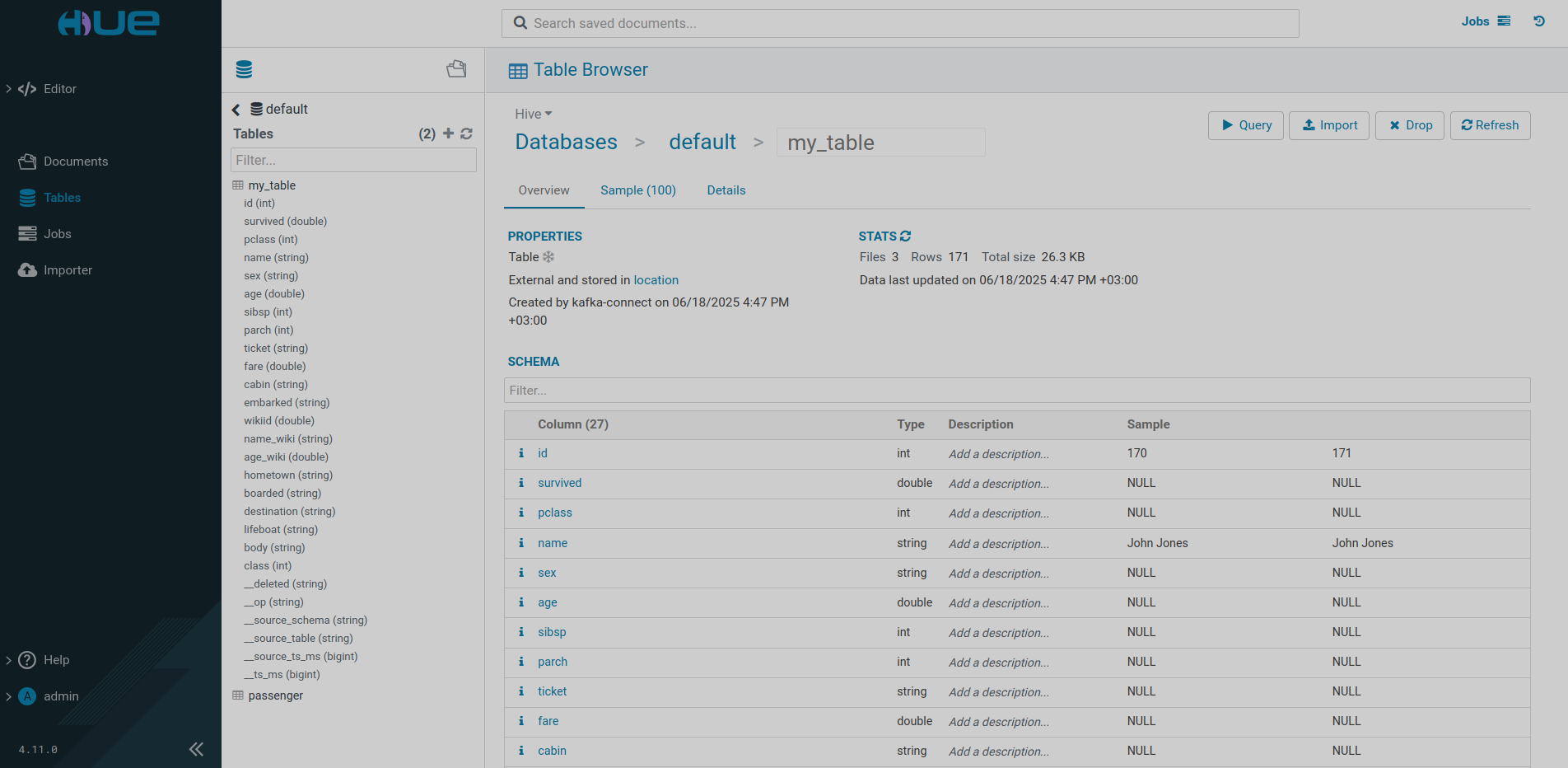
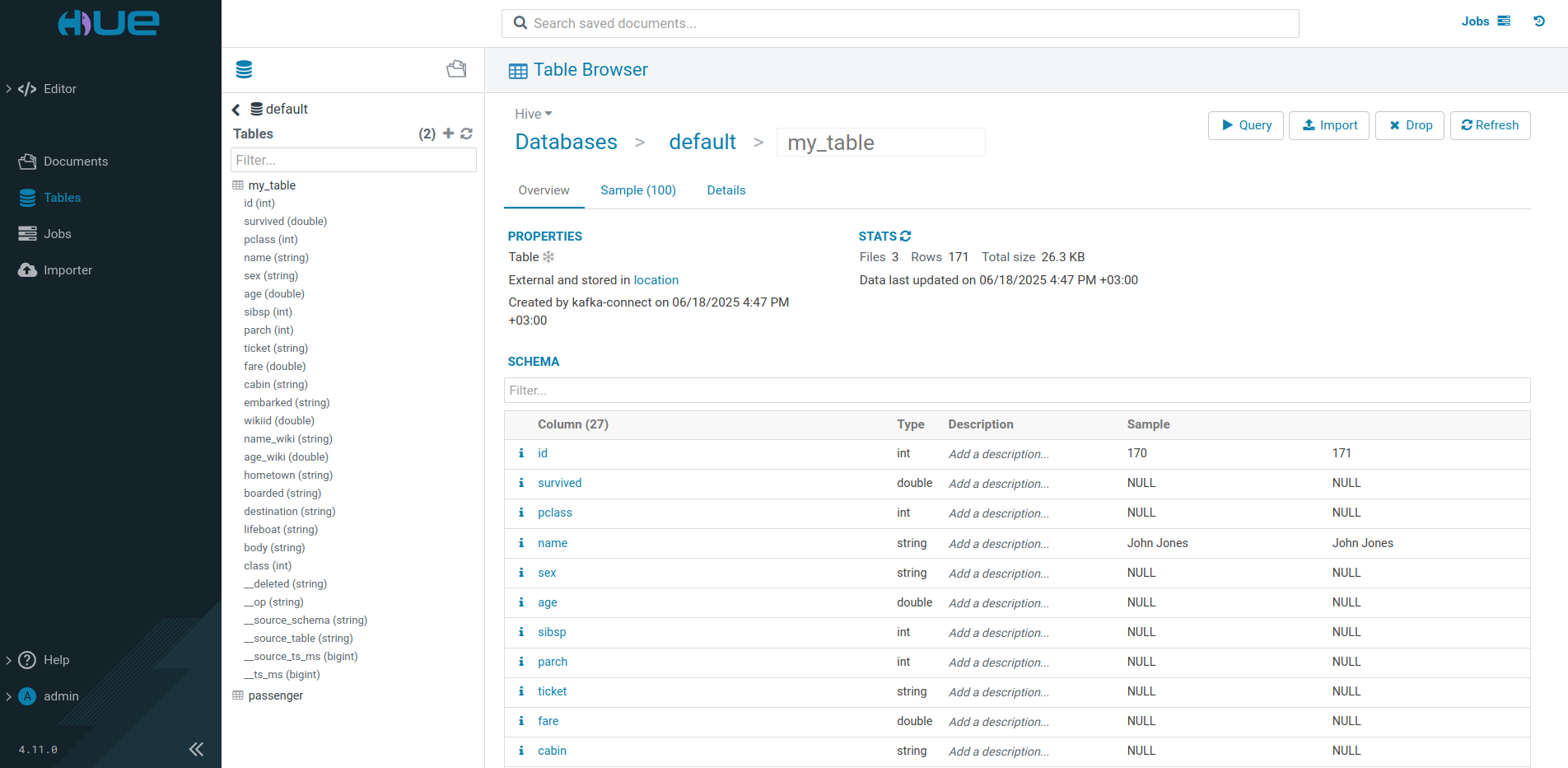
Путь к каталогу, где содержится таблица, указан на вкладке Databases → default → my_table → Details в качестве параметра Location и совпадает со значением параметра hive.metastore.warehouse.dir в hive-site.xml сервиса Hive ADH.
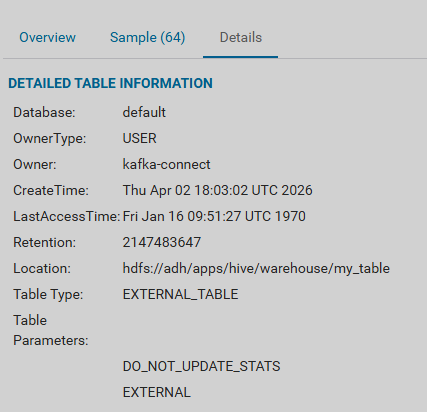
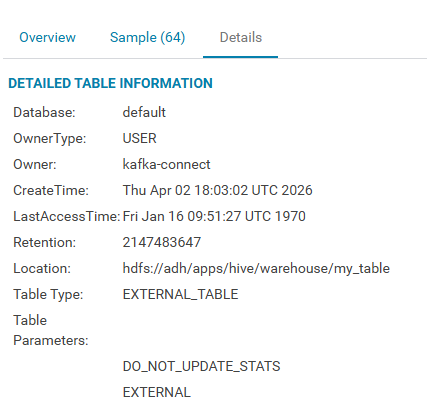
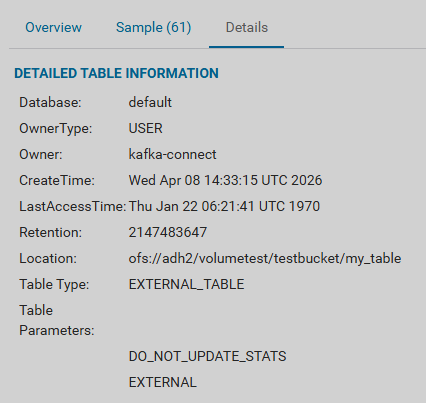
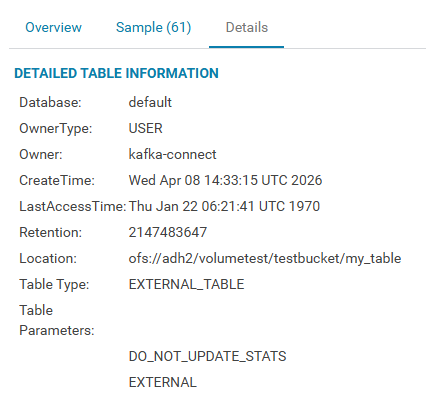
Для таблицы, помещенной в Ozone, могут быть просмотрены сообщения и метаданные на странице Ozone в UI HUE в соответствующем томе и бакете.
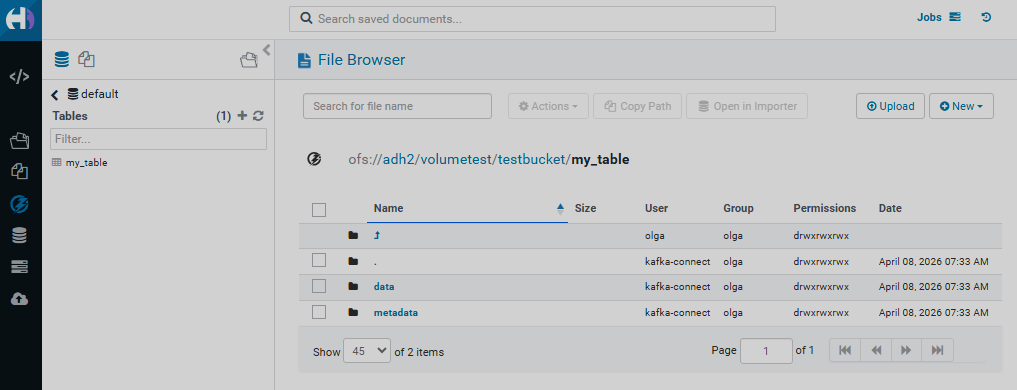
Режим UPSERT
Начиная с ADS 3.9.0.1.b1 существует возможность указания в конфигурации Iceberg Sink Connector параметров для включения и настройки UPSERT-режима.
После включения UPSERT-режима (при помощи параметра коннектора iceberg.tables.upsert-mode-enabled) внесение любого изменения в таблицы Iceberg выполняется согласно следующим правилам:
-
Каждая операция является
UPSERT— комбинацией операцийDELETEиINSERT. Строка обновляется в таблице Iceberg с тем же идентификатором, что и во входящей записи. В случае, если строка не найдена, просто добавляется запись. Это позволяет вставлять, обновлять или удалять записи в одной операции без перезаписи данных. -
Если в записи Kafka присутствует поле, где указан тип выполняемой операции (
INSERT,UPDATEилиDELETE) и этот тип операции указан в качестве значения параметра коннектораiceberg.tables.cdc-field, то эти операции выполняются независимо друг от друга (как они выполнялись бы без включения UPSERT-режима). При попытке новой записи коннектор сопоставит значение поля операции записи Kafka со значением параметраiceberg.tables.cdc-fieldи при совпадении применит данную операцию к поступающей строке. Функция указания типа операции может быть использована при получении данных из CDC-платформ.Пользователи также могут настроить значения параметра
iceberg.tables.cdc-field, соответствующие различным операциям, применив следующие опции:-
iceberg.tables.cdc.ops.insert -
iceberg.tables.cdc.ops.update -
iceberg.tables.cdc.ops.delete
Пример указания опций в конфигурации коннектора:
{ "iceberg.tables.cdc-field": "__op", "iceberg.tables.cdc.ops.insert": "c,r", "iceberg.tables.cdc.ops.update": "u", "iceberg.tables.cdc.ops.delete": "d", "iceberg.tables.upsert-mode-enabled": "true", "iceberg.tables.default-id-columns": "id" } -
-
Если в записи Kafka присутствует поле, где указан тип выполняемой операции (
INSERT,UPDATEилиDELETE) и этот тип операции указан в качестве значения параметра коннектораiceberg.tables.cdc.ops.ignored, то коннектор просто проигнорирует входящую запись.
|
ПРИМЕЧАНИЕ
В настоящее время операция |
Ниже описаны параметры режима UPSERT, а также указана версия ADS, начиная с которой параметры могут быть применены.
| Параметр | Описание | Значение по умолчанию | Версия ADS |
|---|---|---|---|
iceberg.tables.upsert-mode-enabled |
Установите значение |
false |
|
iceberg.tables.cdc-field |
Поле исходной записи, которое идентифицирует тип операции ( |
__op |
|
iceberg.tables.default-id-columns |
Список столбцов по умолчанию, разделенных запятыми, которые определяют строку идентификатора в таблицах (primary key). Является обязательным параметром |
— |
|
iceberg.tables.cdc.ops.insert |
Разделенные запятыми значения поля операции CDC, соответствующие |
r,c |
|
iceberg.tables.cdc.ops.update |
Разделенные запятыми значения поля операции CDC, соответствующие |
u |
|
iceberg.tables.cdc.ops.delete |
Разделенные запятыми значения поля операции CDC, соответствующие |
d |
|
iceberg.tables.cdc.ops.ignored |
Разделенные запятыми значения поля операции CDC, которые должны игнорироваться коннектором |
t,m |
Векторы удаления
Начиная с ADS 4.0.0.b1 поддерживаются векторы удаления, доступные для таблиц версии Iceberg v3.
Векторы удаления (Deletion Vectors, DVs) — механизм удаления строк, введенный в Apache Iceberg Spec v3, который использует для удаления данных карту Roaring Bitmap, прикрепленную непосредственно к файлам данных, что уменьшает избыточное чтение и накладные расходы на метаданные для таблиц с частыми обновлениями.
Для таблиц версии Iceberg v3 установка параметров write.delete.mode, write.update.mode в значение merge-on-read включает векторы удаления при удалении и обновлении записей.
Шифрование метаданных таблицы
Начиная с ADS 4.0.0.b1 поддерживается шифрование таблиц Iceberg, в том числе:
-
Шифрование метаданных ключей списка манифестов при использовании StandardEncryptionManager.
-
Кеширование ключей шифрования (время жизни 1 час) для уменьшения нагрузки на службу управления ключами (Key Management Service, KMS).
-
Поточное шифрование AES GCM; зашифрованная длина файла записывается в метаданные ключа для защиты от атак.
Для поддержки функции шифрования таблицы/каталога Iceberg должны быть настроены параметры каталога/таблицы Iceberg:
-
encryption.type = standard— включает стандартный тип шифрования. -
encryption.kms-impl— указывает путь к пользовательским классам клиентов KMS. -
encryption.key-id— указывает идентификатор мастер-ключа, используемого для шифрования и расшифровки таблицы. Мастер-ключи хранятся и управляются в KMS.