Work with a cluster topology
Overview
|
NOTE
Click the |
The cluster topology is displayed on the Topology page of the ADP Control web interface. You can select the cluster for which the topology should be provided from the Cluster combo box at the top of the page. After selecting a cluster, the Postgres and Patroni fields located next to the Cluster field will display the ADP/PostgreSQL and patroni versions, respectively. The topology diagram shows all cluster nodes with a PostgreSQL/ADPG service. The nodes are connected to each other by arrows indicating the direction of replication streams.
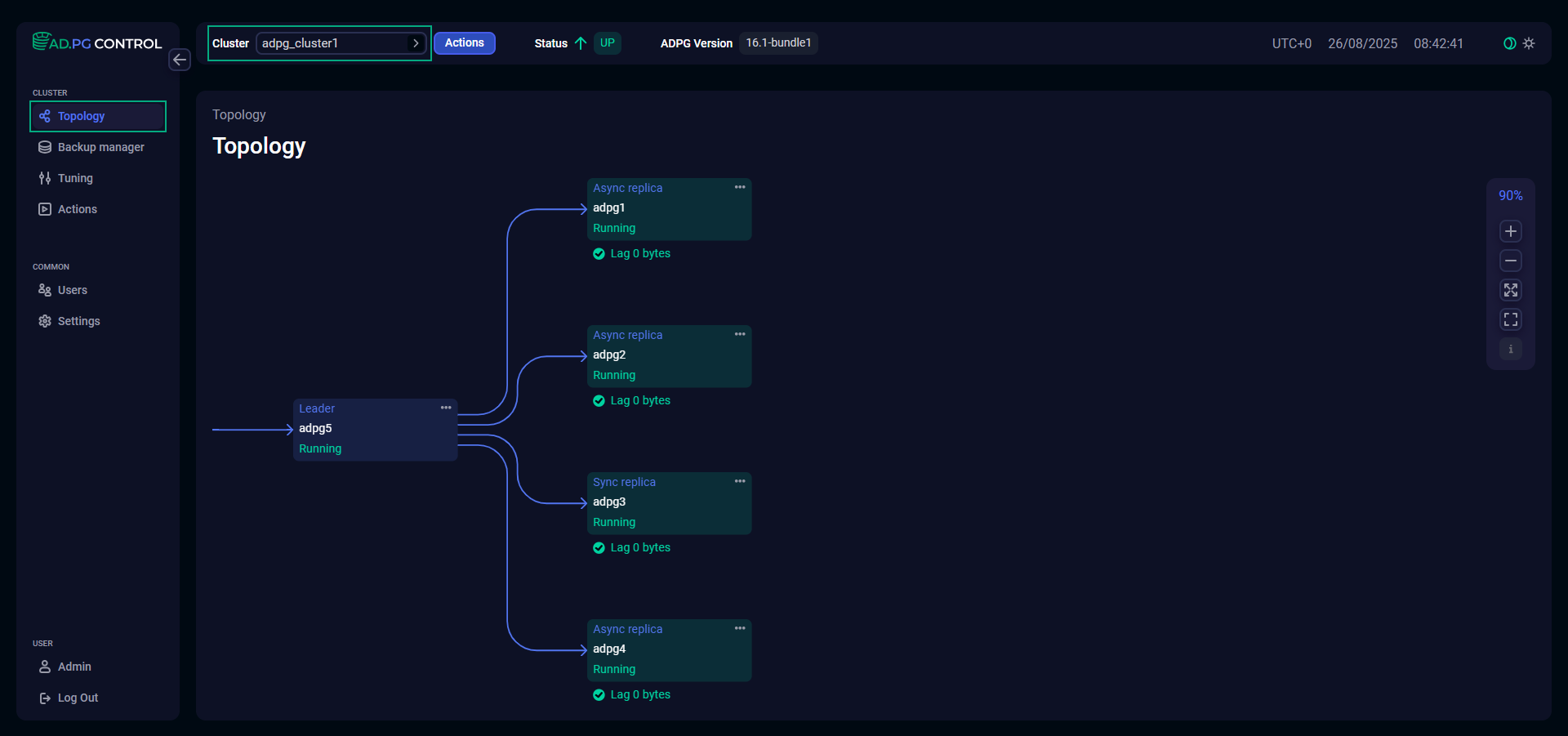
The topology diagram displays the following information for each node:
-
Role in the cluster:
Leader,Async replica,Sync replica. -
Node name.
-
Status:
Running,Stopping,Initializing,Stopped,Failed,Unknown,Out of patroni.
For replica nodes, the topology diagram shows lag (in bytes) — the number of bytes by which the replica’s state lags behind the leader state.
The table below shows mapping patroni node statuses to node statuses on the diagram.
| Status on the topology diagram | Patroni status |
|---|---|
Running |
running, streaming |
Stopping |
stopping |
Initializing |
|
Stopped |
stopped |
Failed |
|
Unknown |
An instance with unknown status |
Out of patroni |
A node is not in a cluster, for example, if the patroni service is stopped on the node |
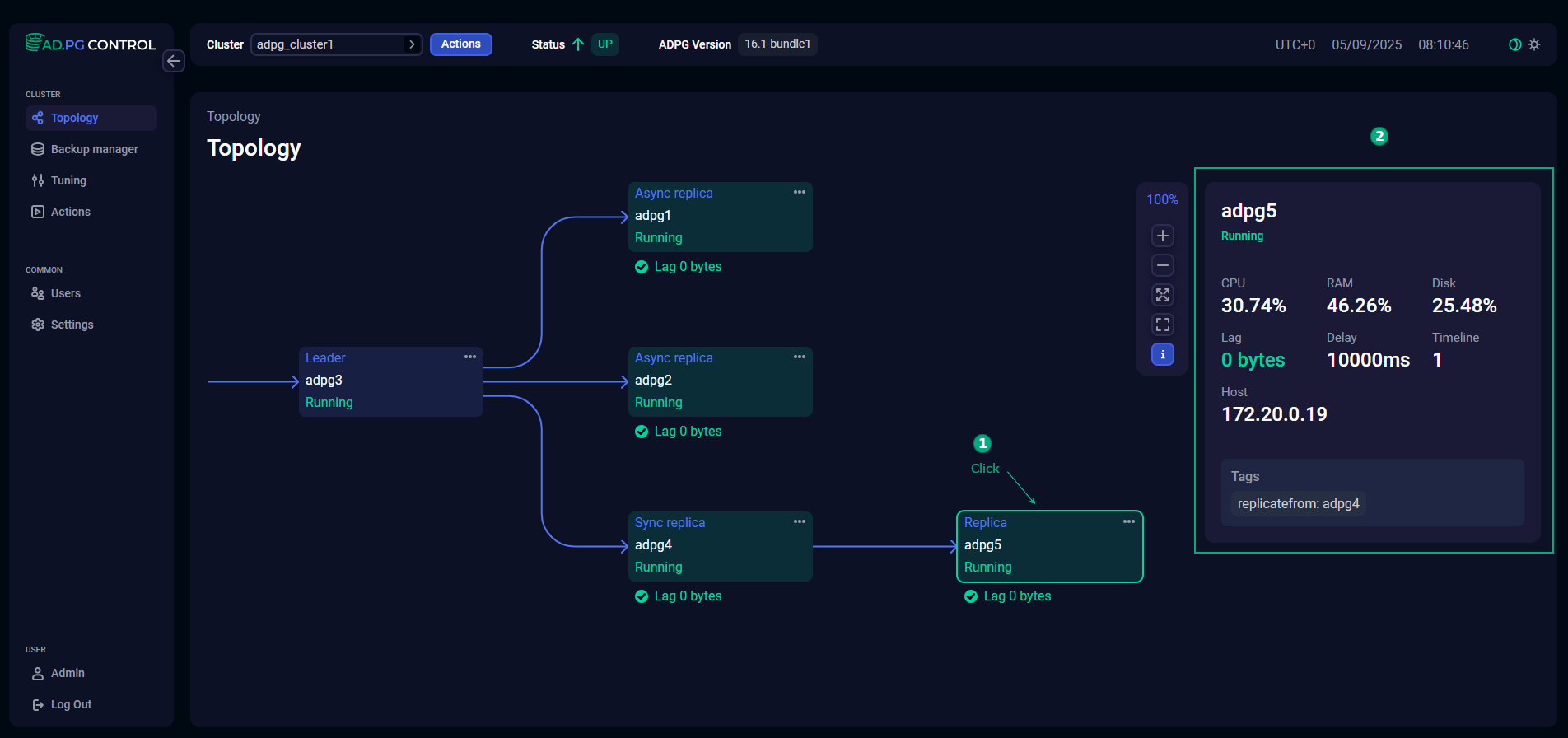
Display node details
You can click a node on the diagram to display the following node details:
-
CPU — percentage of CPU usage;
-
RAM — percentage of RAM usage;
-
Disk — percentage of disk usage;
-
Lag — number of bytes by which the replica’s state lags behind the leader state;
-
Delay — time delay between the creation of a WAL record on the leader and its replay on the replica that is set via the recovery_min_apply_delay parameter;
-
Timeline — PostgreSQL timeline;
-
Host — host IP address;
-
Tags — patroni tags.
The Topology page displays a toolbar that allows you to close a window with node details and zoom the topology diagram. The toolbar also shows a zoom factor as a percentage value.
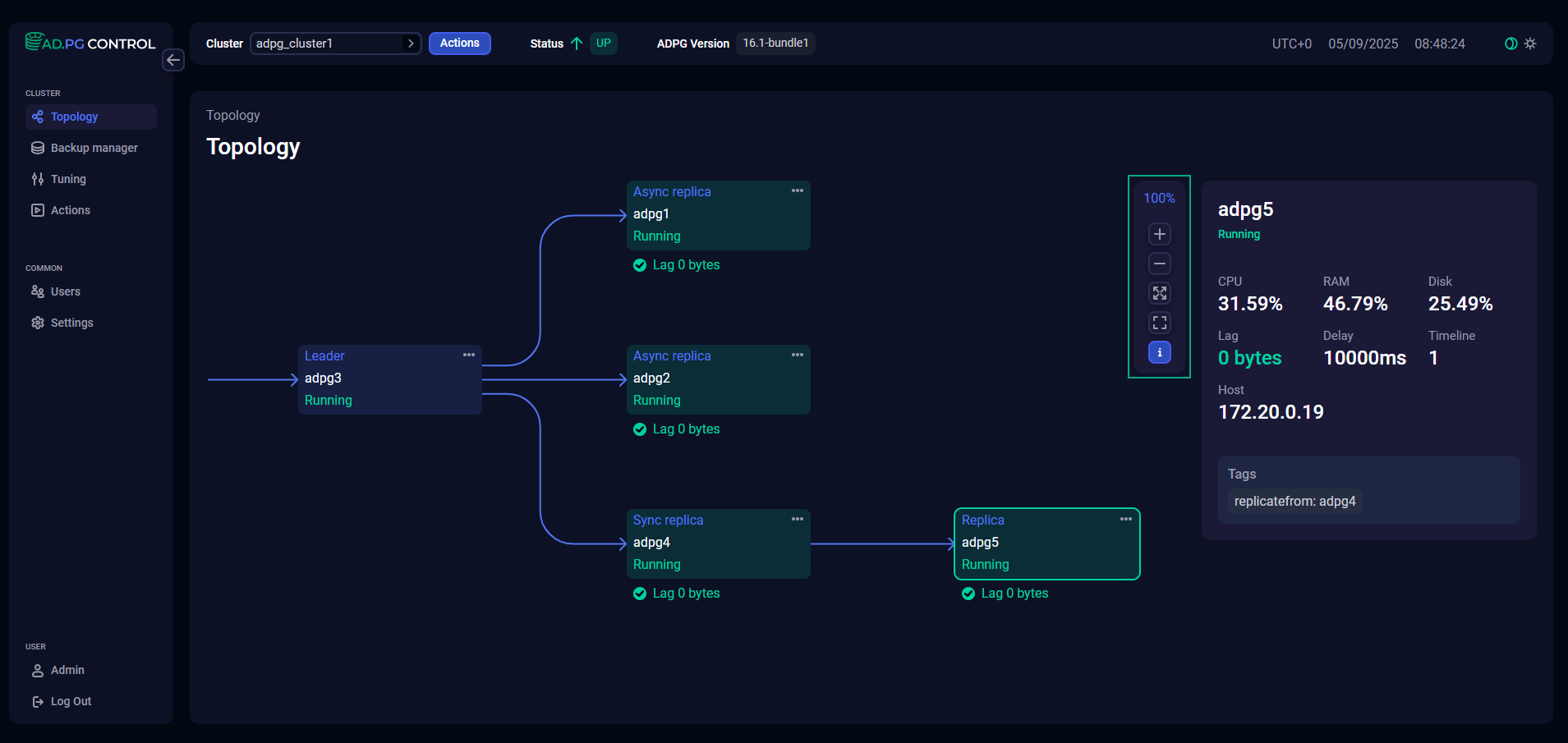
It includes the following buttons:
-

 — zoom in;
— zoom in; -

 — zoom out;
— zoom out; -

 — maximize the diagram to fill the entire screen;
— maximize the diagram to fill the entire screen; -

 — reduce the diagram size to 100%;
— reduce the diagram size to 100%; -

 — hide node details window.
— hide node details window.
Run actions
On the Topology page, you can execute the following actions:
To execute actions, click Actions at the top of the page.
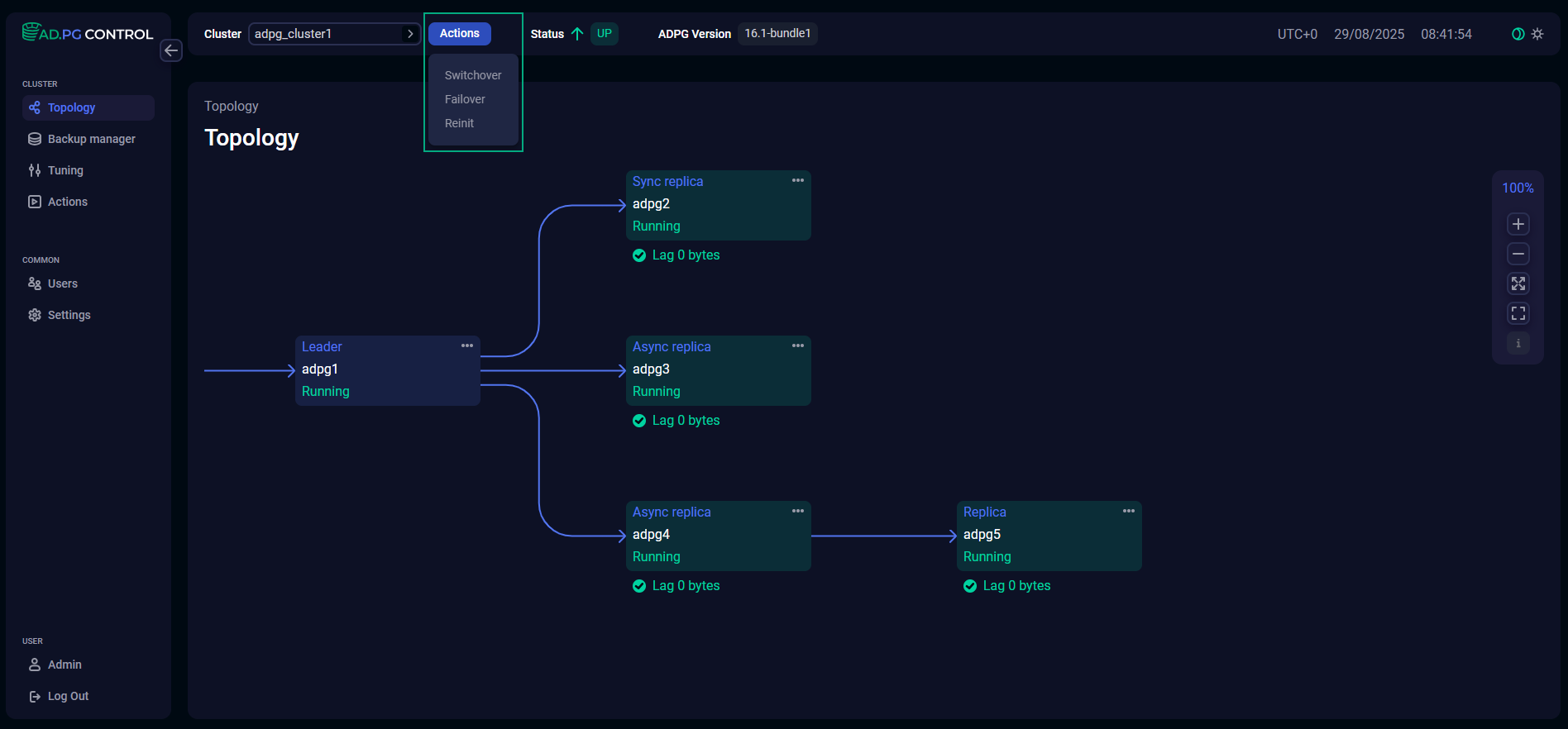
Alternatively, you can run actions related to the current node from the node menu.
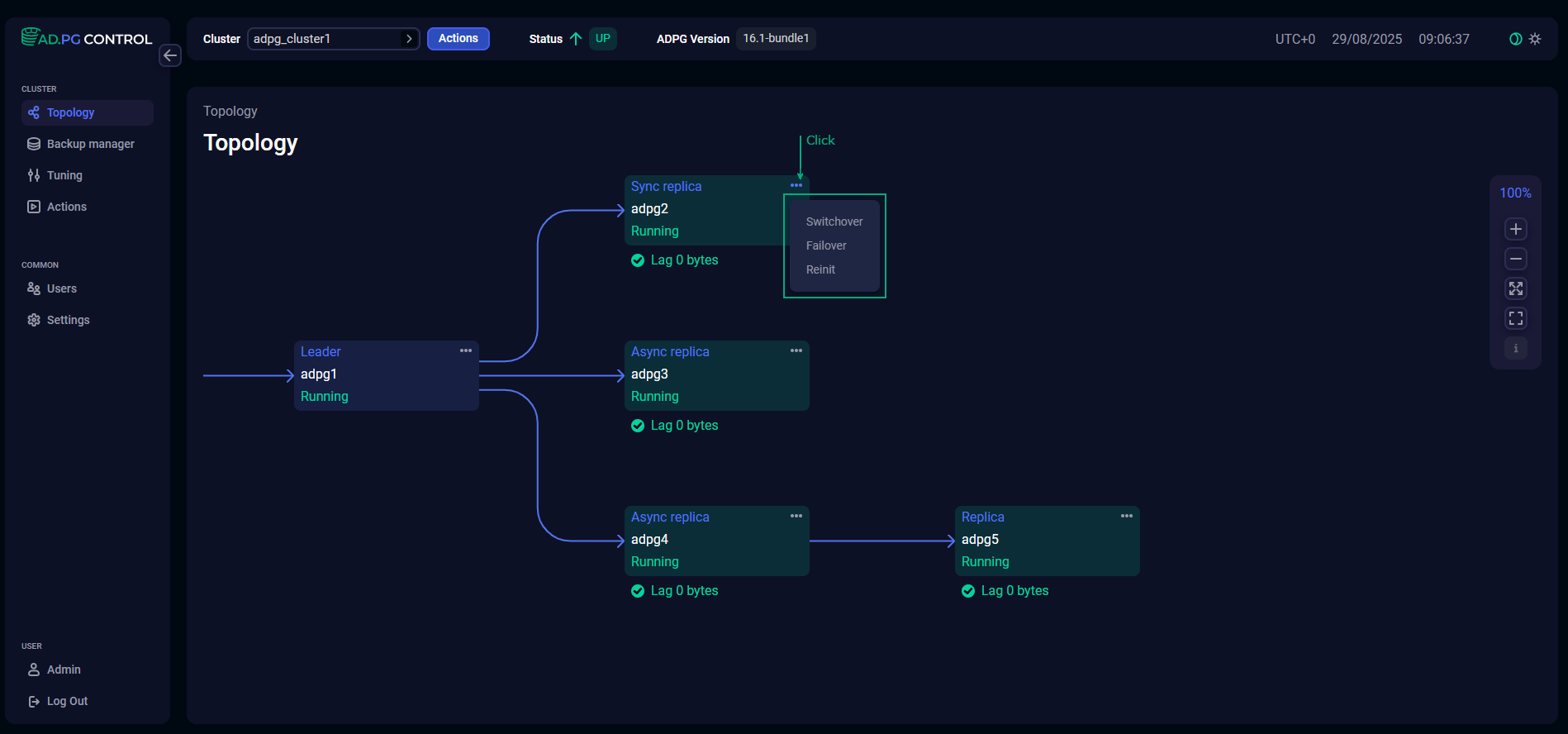
In this case, the node for which an action is executed cannot be changed from the action window — the Candidate field for Switchover, Failover and the Instance field for Reinit are filled automatically.
Once an action is launched, an indicator appears at the top of the page.
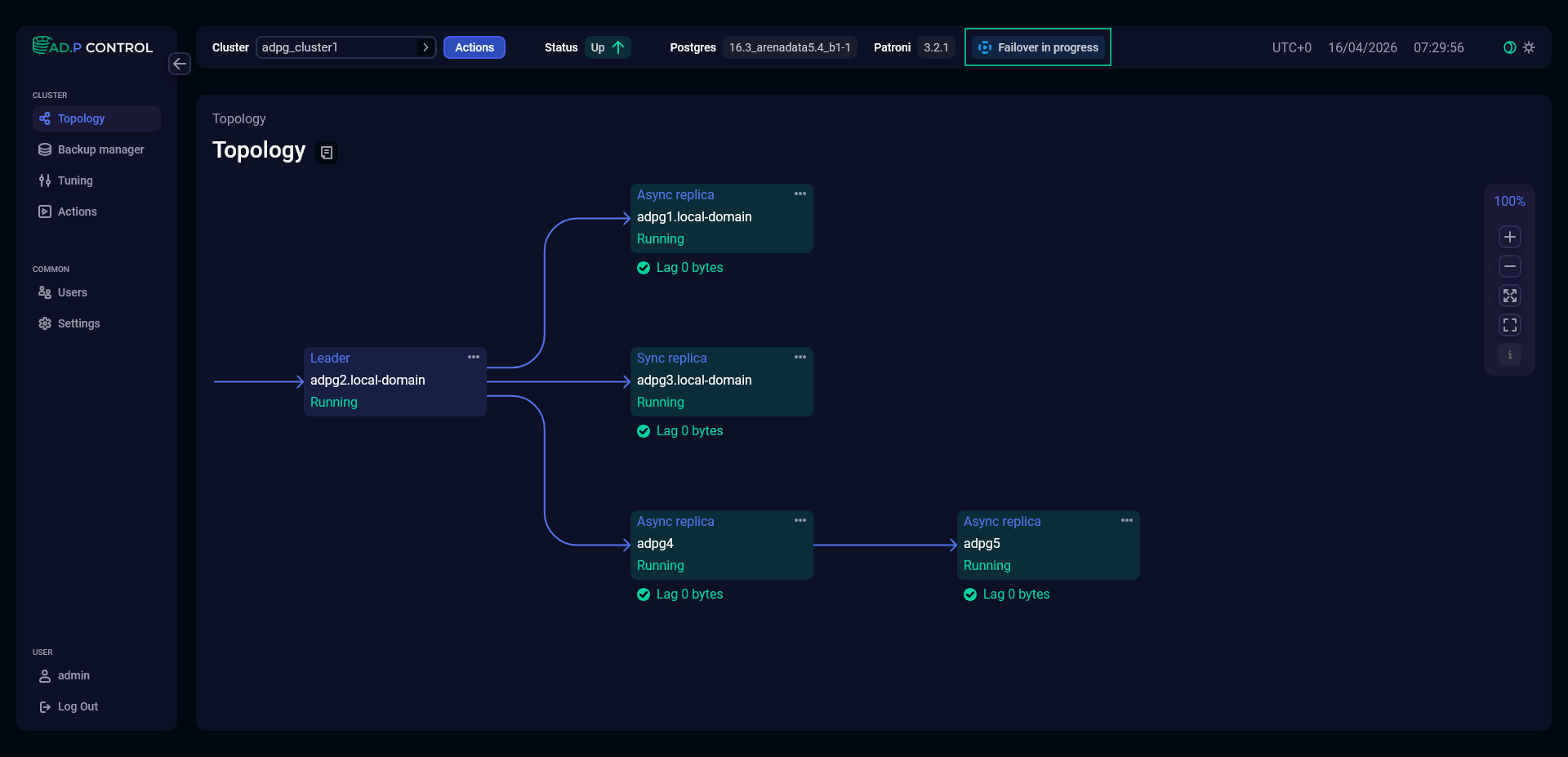
All ADP Control actions are logged on the Actions page. On this page, you can obtain information about successful actions and errors that occur if actions fail.
|
IMPORTANT
Note that the Failover and Switchover actions can cause data loss. It depends on how up-to-date the promoted replica is in comparison to the leader. Both actions also interrupt ongoing transactions and sessions on the leader. |
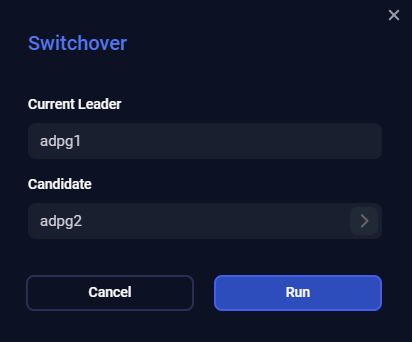
Switchover
The Switchover action moves the leader role to a specified replica node. A former leader becomes a replica. If a cluster contains any synchronous replicas, you should select a synchronous replica as a switchover candidate. The Switchover action is not available for asynchronous replicas if the replication synchronous mode is enabled in the cluster.
You can use this action when the cluster is healthy:
-
The cluster has a leader.
-
In a cluster with the synchronous replication, synchronous replicas are available.
If the cluster is unhealthy, use Failover instead.
To run the action, click Switchover in the action list, specify a node candidate (if not set) that should be promoted to the leader, and click Run.
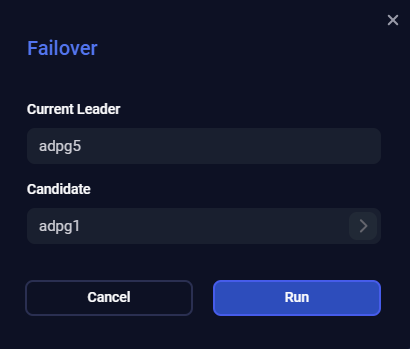
Failover
The Failover action can move the leader role to an asynchronous or synchronous replica. The previous leader turns into a replica.
You can use this action when the cluster is not healthy, for example, there is no leader in a cluster, or there is no synchronous replica available in a synchronous cluster.
Nothing prevents you from running Failover in a healthy cluster. However, it is recommended to utilize the Switchover action in this case.
To run the action, click Failover in the action list, specify a node candidate (if not set) that should be promoted to the leader, and click Run. Also, when choosing a node, you can select the Autoselect option from the combo box values — the node candidate will be determined automatically.
|
NOTE
If an automatic failover action occurs in a cluster, it is not displayed on the Actions page. This page logs actions initiated only manually.
|
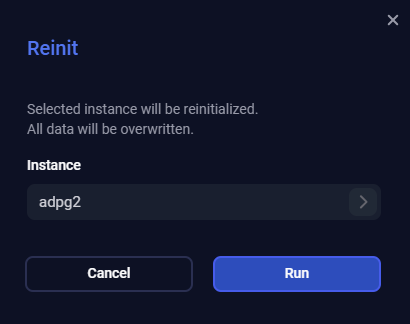
Reinit
The Reinit action reinitializes a cluster node. All data on this node will be overwritten.
You can perform the Reinit action when the PostgreSQL instance on a replica is unable to catch up with the primary database, and patroni cannot automatically recover it. Reinit removes the existing data directory and creates a new replica from the current leader.
To run the action, click Reinit in the action list, specify an instance (if not set) that should be reinitialized, and click Run.
Pause cluster
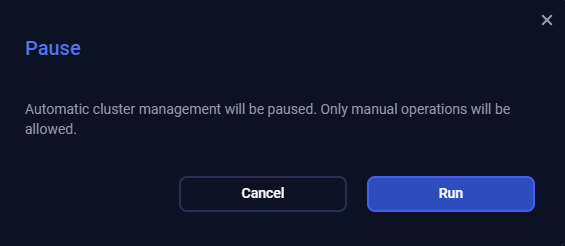
The Pause cluster action switches patroni to the pause mode. In the pause mode, patroni does not manage the cluster, but still saves the cluster state in DCS. The pause mode can be helpful during major version upgrades or corruption recovery. Such operations often start and stop nodes for reasons unknown to patroni. Some nodes can be even temporary promoted, breaking the assumption of running only one leader. Therefore, patroni needs to be able to stop controlling a running cluster.
To run the action, click Pause cluster in the action list and click Run in the window that opens.
Once the action is completed, ADP Control displays an indicator of the pause mode in the Status field at the top of the page.
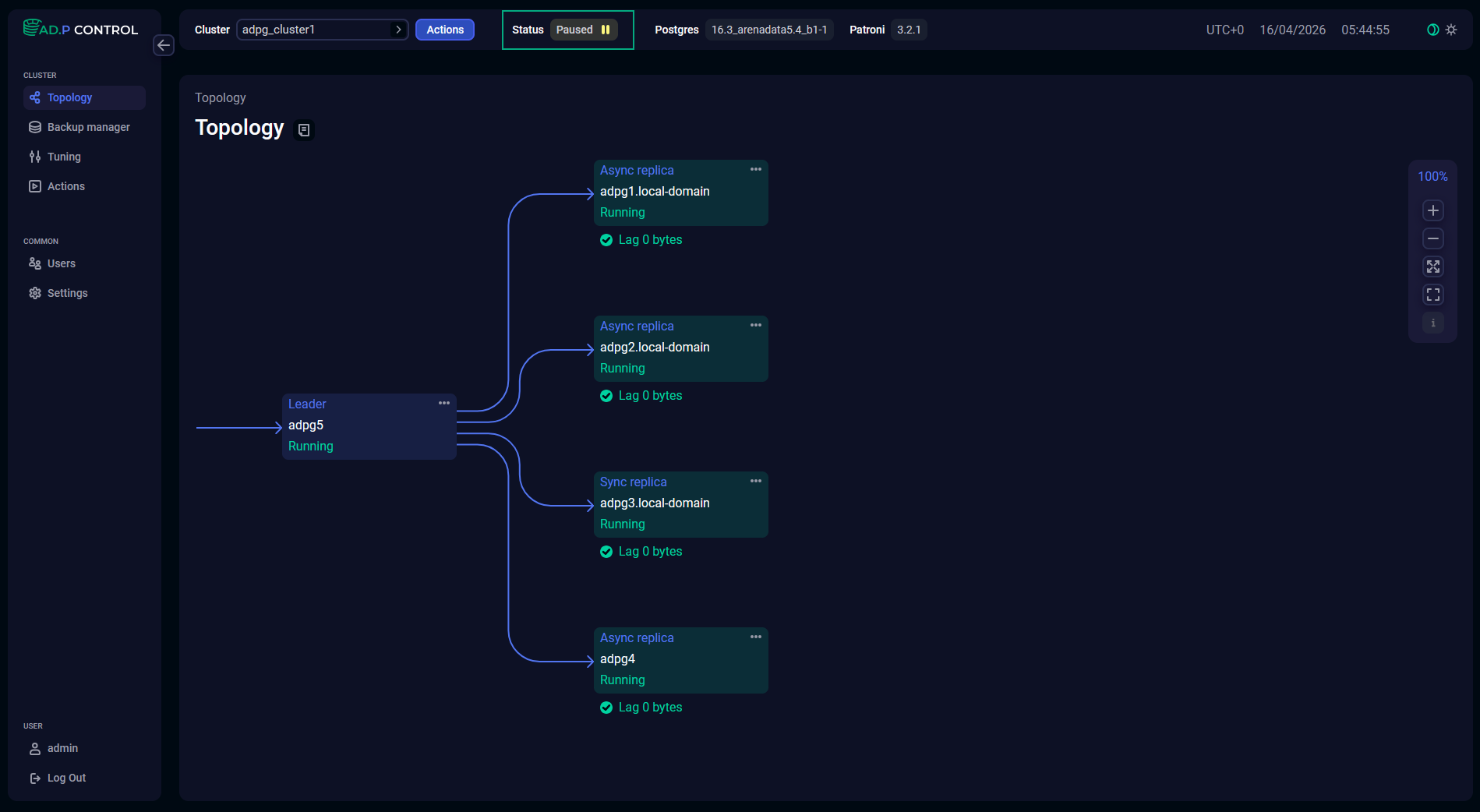
Use the Resume cluster action to switch off the pause mode.
Resume cluster
The Resume cluster action switches patroni from the pause mode, brings the cluster to the working state, returns the control over the cluster to patroni. The action also resolves situations with several leaders if it occurs.
To run the action, click Resume cluster in the action list and click Run in the window that opens.