Панель Databases
На панели DATABASES в интерактивном виде выводится информация о базах данных и таблицах ADQM. Если в конфигурации ADQM не описан ни один логический кластер, на панели выводятся базы данных, расположенные на текущем хосте ADQM.
Если в конфигурации есть описание одного или нескольких кластеров, панель содержит две вкладки:
-
LOCAL — показывает базы данных на текущем хосте ADQM (без базы данных
information_schema); -
CLUSTER — показывает иерархическое дерево баз данных и таблиц кластера (также без
information_schema). Если в конфигурации описан один кластер, он будет отображаться на вкладке по умолчанию. Если сконфигурировано несколько кластеров ADQM, кластер для отображения на панели DATABASES можно выбрать из выпадающего списка.
Когда ADQM Notebook работает через Chproxy, переключатель LOCAL/CLUSTER отсутствует — на панели всегда показывается дерево баз данных и таблиц выбранного кластера.
Клик по иконке ![]()
![]() Refresh обновляет информацию по базам данным и таблицам.
Refresh обновляет информацию по базам данным и таблицам.
В списке баз данных/таблиц/столбцов доступно поле для фильтрации данных — при вводе любой подстроки выполняется фильтрация одновременно на уровне всех объектов.
Таблицы
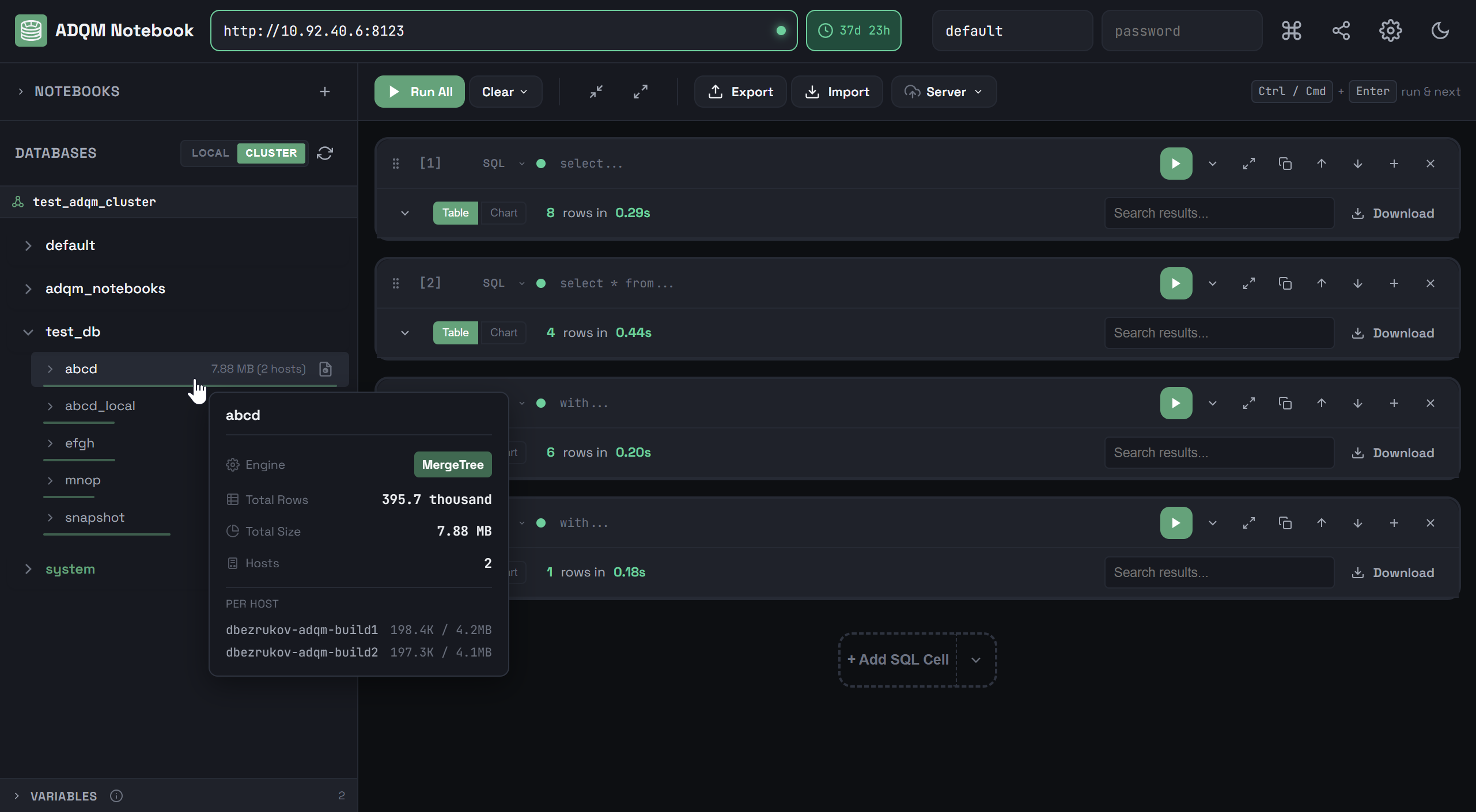
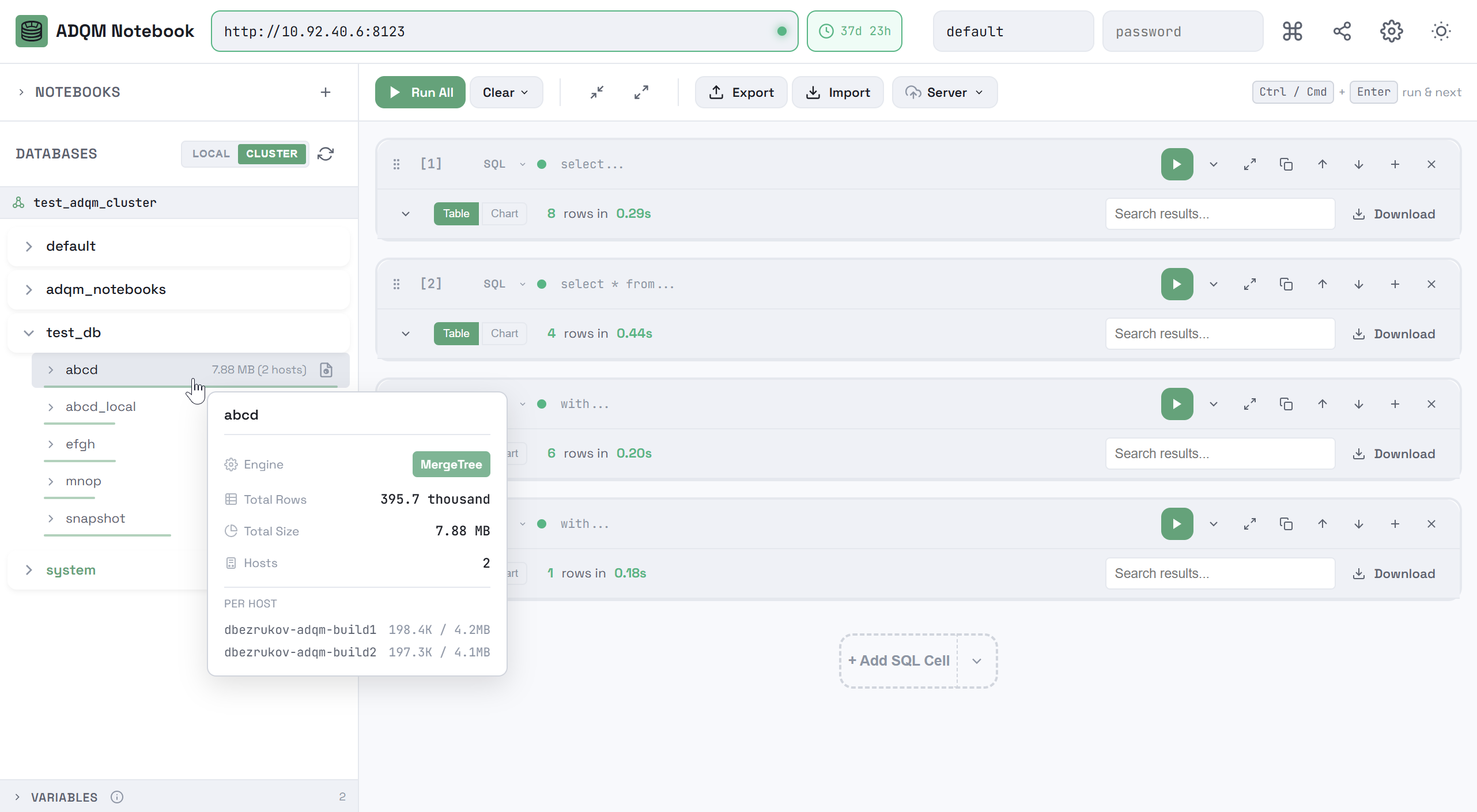
Чтобы развернуть базу данных и посмотреть таблицы, которые в ней находятся, кликните по строке базы данных. В строке каждой таблицы указывается ее размер, а по цветовому индикатору можно визуально оценить размер таблицы относительно самой большой таблицы в базе данных. На вкладке CLUSTER для таблиц также указывается количество шардов и реплик, на которых располагаются табличные данные.
При наведении курсора мыши на строку таблицы во всплывающем окне (tooltip) можно посмотреть дополнительную информацию о таблице: табличный движок, общее количество строк, общий размер и распределение данных по хостам (на вкладке CLUSTER).
При нажатии правой кнопкой мыши на строку таблицы открывается контекстное меню, которое можно использовать, чтобы автоматически вставить в выбранную SQL-ячейку (или в новую, если ни одна ячейка не выбрана) запрос к данной таблице для выполнения на одном хосте или на кластере в зависимости от выбранной на панели DATABASES вкладки (LOCAL или CLUSTER).
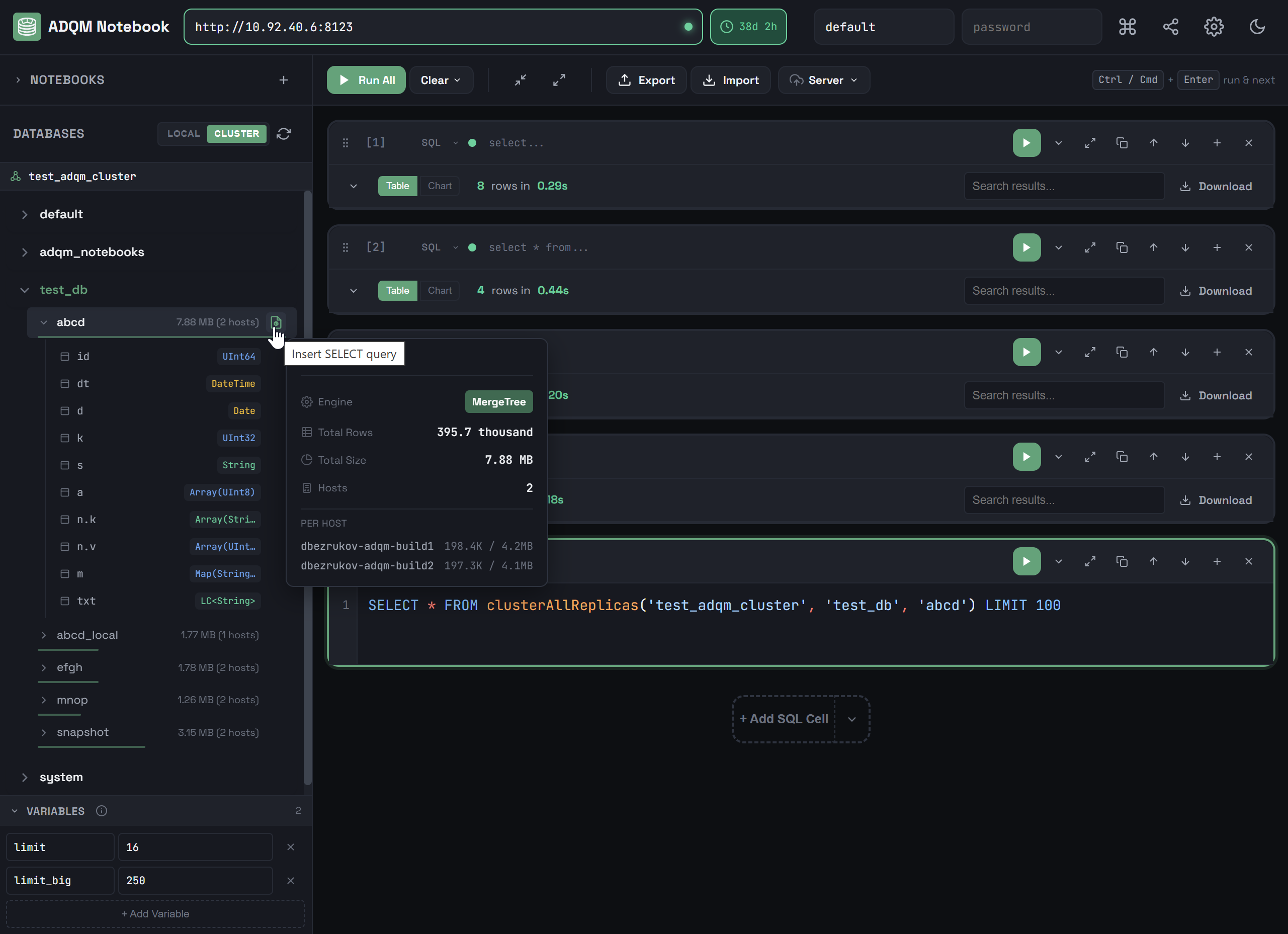
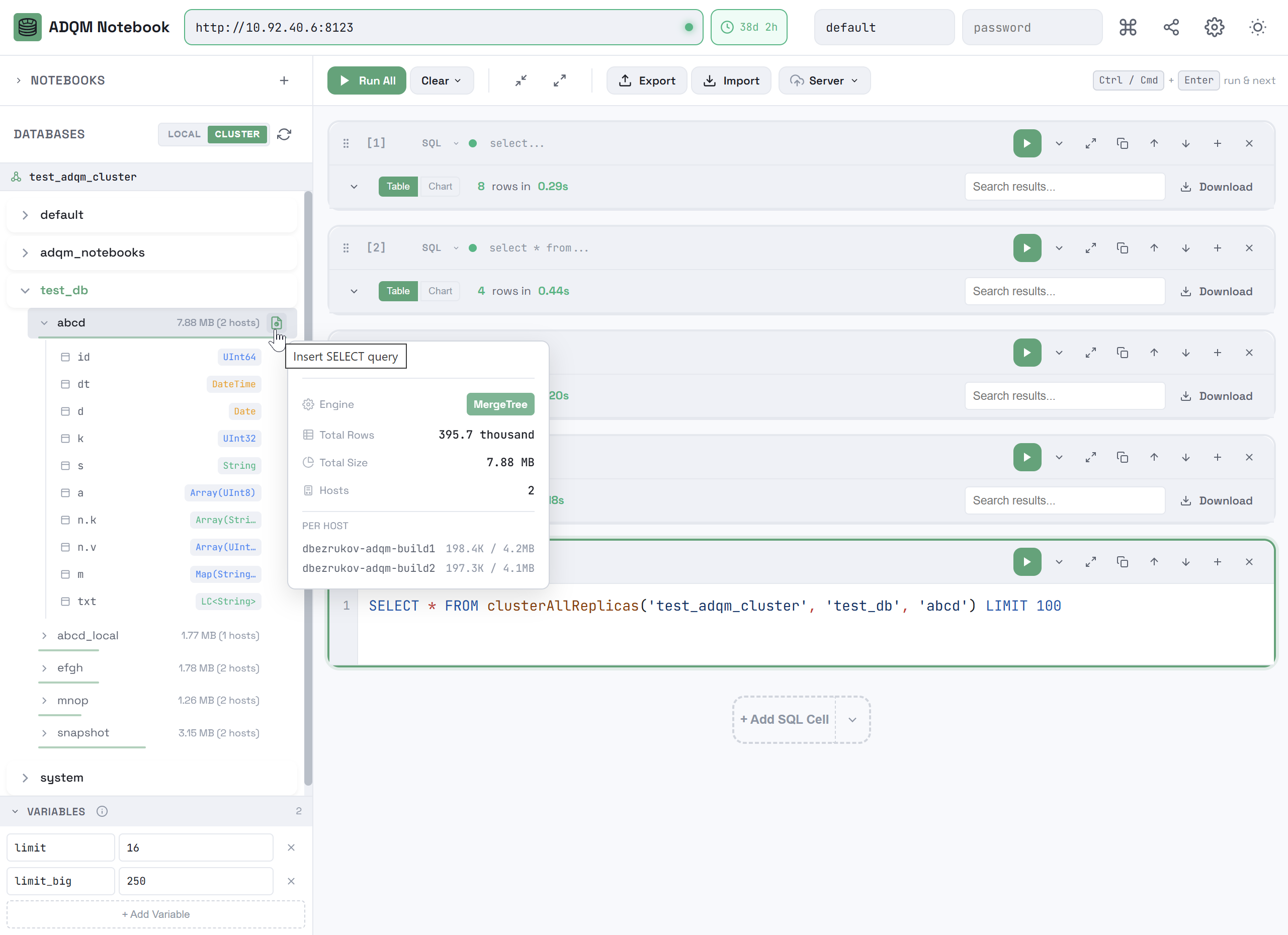
Из контекстного меню можно вставлять следующие запросы:
-
SELECT * … LIMIT 100 — запрос на чтение 100 строк таблицы.
LOCALSELECT * FROM "<database_name>"."<table_name>" LIMIT 100CLUSTERSELECT * FROM clusterAllReplicas('<cluster_name>', '<database_name>', '<table_name>') LIMIT 100 -
SELECT count(*) — запрос для получения общего количества строк в таблице.
LOCALSELECT count(*) FROM "<database_name>"."<table_name>"CLUSTERSELECT count(*) FROM clusterAllReplicas('<cluster_name>', '<database_name>', '<table_name>') -
DESCRIBE TABLE — запрос для получения детальной информации о структуре таблицы.
LOCAL и CLUSTERDESCRIBE TABLE "<database_name>"."<table_name>" -
SHOW CREATE TABLE — запрос для получения команды, с помощью которой была создана таблица.
LOCAL и CLUSTERSHOW CREATE TABLE "<database_name>"."<table_name>"
В каждом из приведенных выше примеров запросов имя таблицы, для которой вызывается контекстное меню, а также имя базы данных и кластера обозначаются как <table_name>, <database_name> и <cluster_name> соответственно — при вставке запроса в ячейку вместо этих обозначений будут автоматически подставляться фактические имена соответствующих объектов.
Столбцы таблиц
Чтобы развернуть таблицу и посмотреть ее столбцы, кликните по строке таблицы. Для каждого столбца показывается его имя и тип данных.
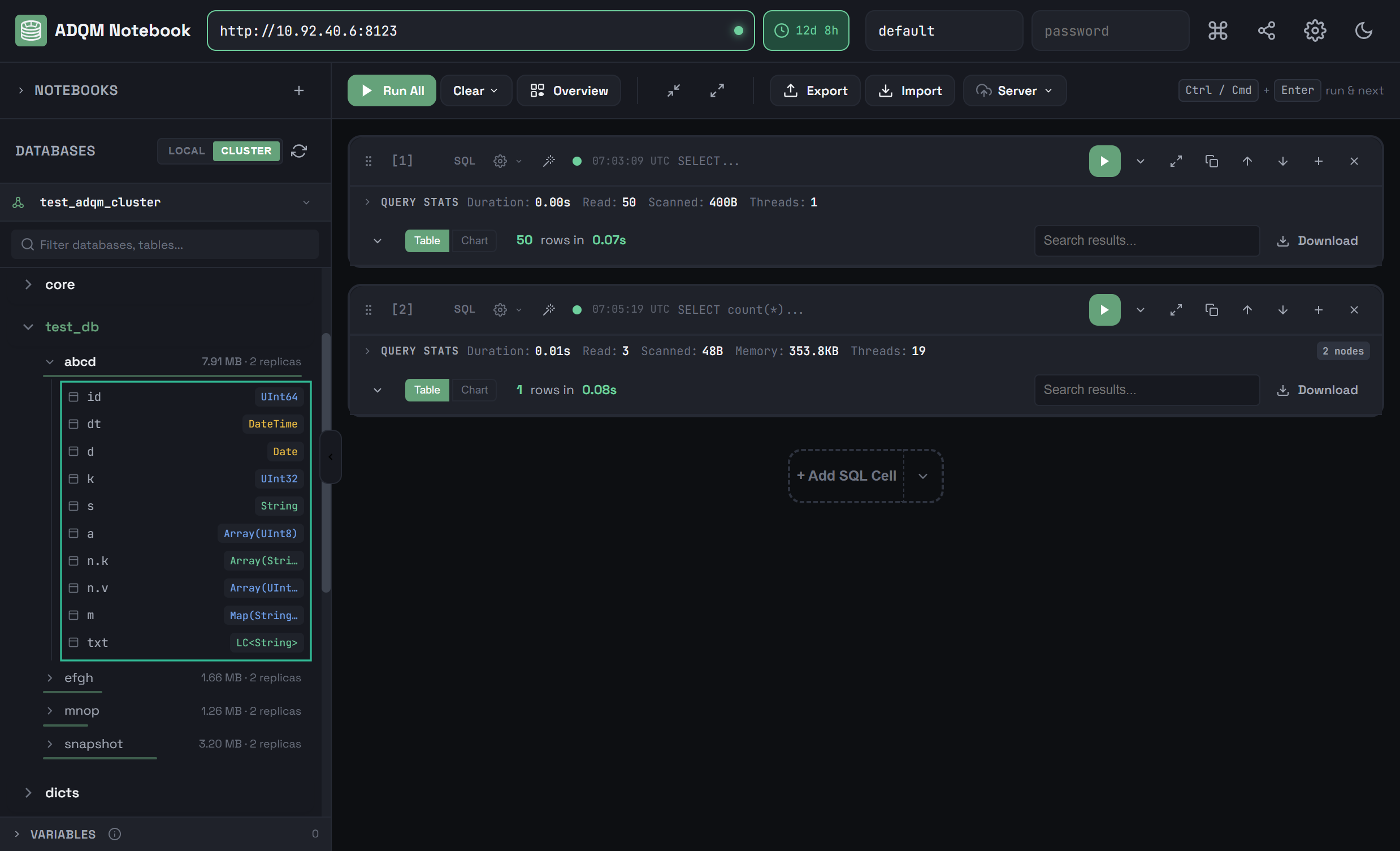
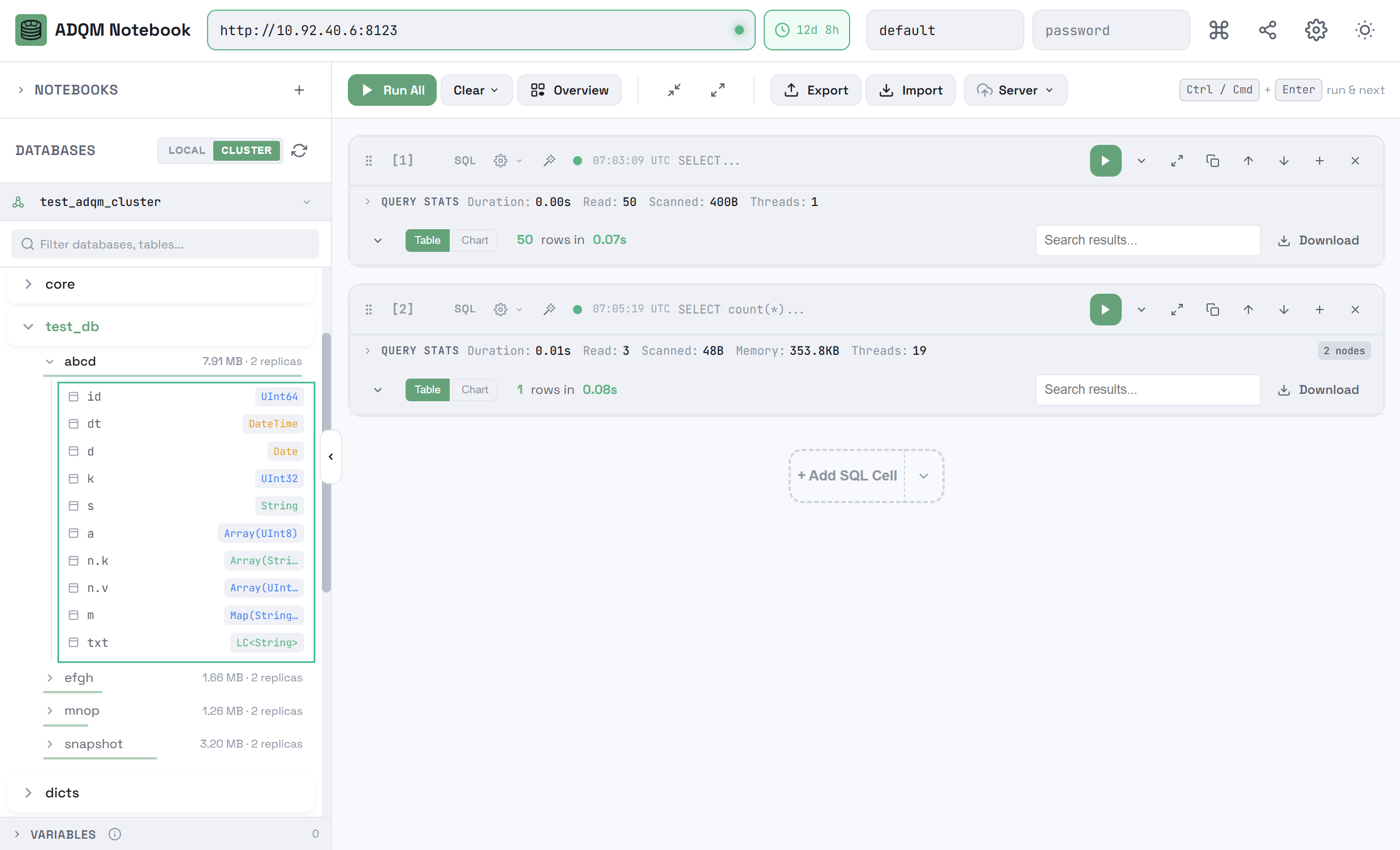
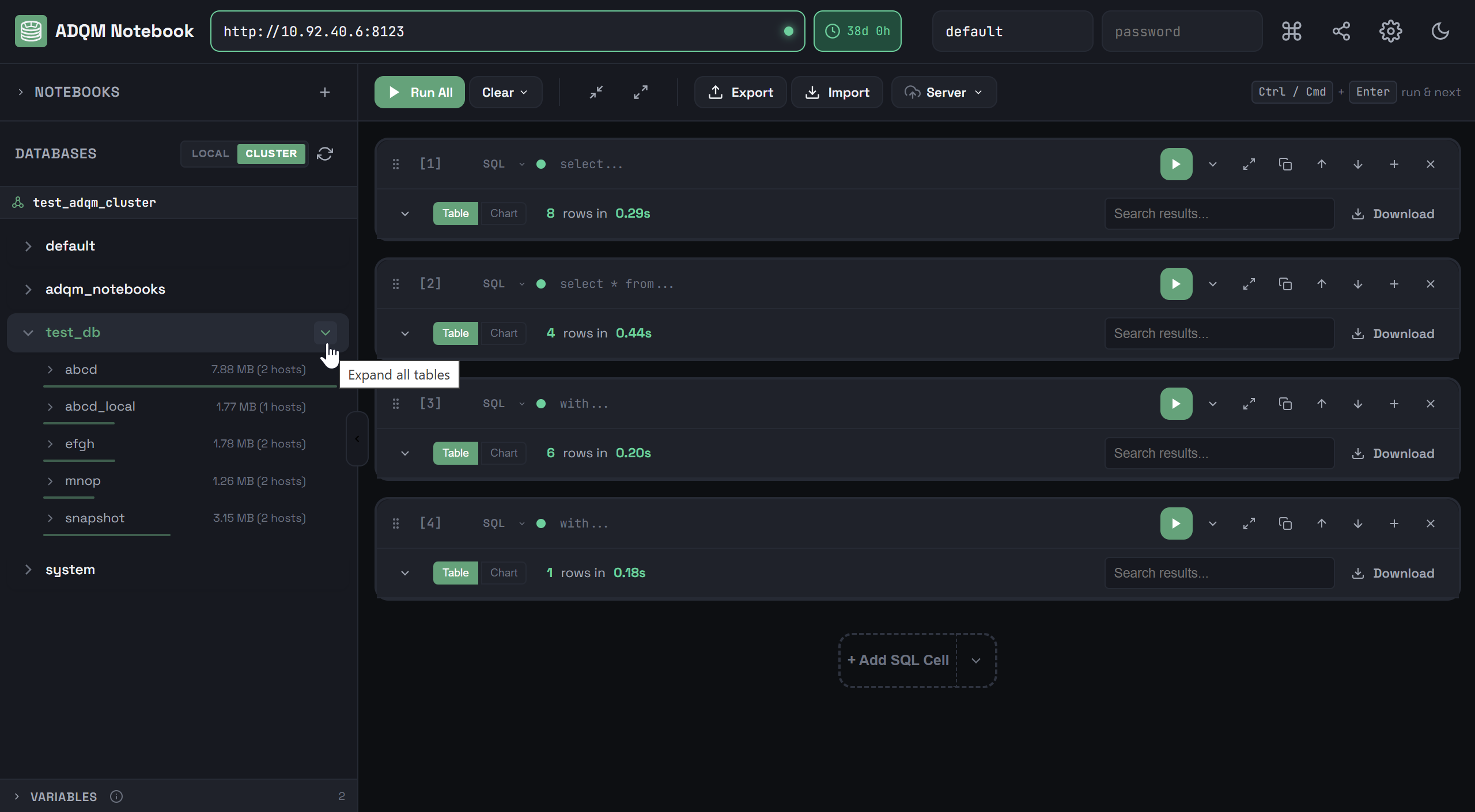
Чтобы развернуть структуру всех таблиц в рамках одной базы данных, в строке базы данных кликните по иконке ![]()
![]() Expand all tables, которая становится видимой при наведении курсора мыши на базу данных в панели DATABASES (если все таблицы уже развернуты, иконка
Expand all tables, которая становится видимой при наведении курсора мыши на базу данных в панели DATABASES (если все таблицы уже развернуты, иконка ![]()
![]() Collapse all tables в строке базы данных позволяет их свернуть).
Collapse all tables в строке базы данных позволяет их свернуть).
Контекстное меню
При нажатии правой кнопкой мыши на строку, соответствующую столбцу таблицы, открывается контекстное меню, с помощью которого можно быстро вставить имя столбца или один из предопределенных запросов с обращением к данному столбцу в поле редактирования запроса выбранной SQL-ячейки (или в новую ячейку, если ни одна не выбрана) для выполнения на одном хосте или кластере ADQM в зависимости от выбранной на панели DATABASES вкладки (LOCAL или CLUSTER).
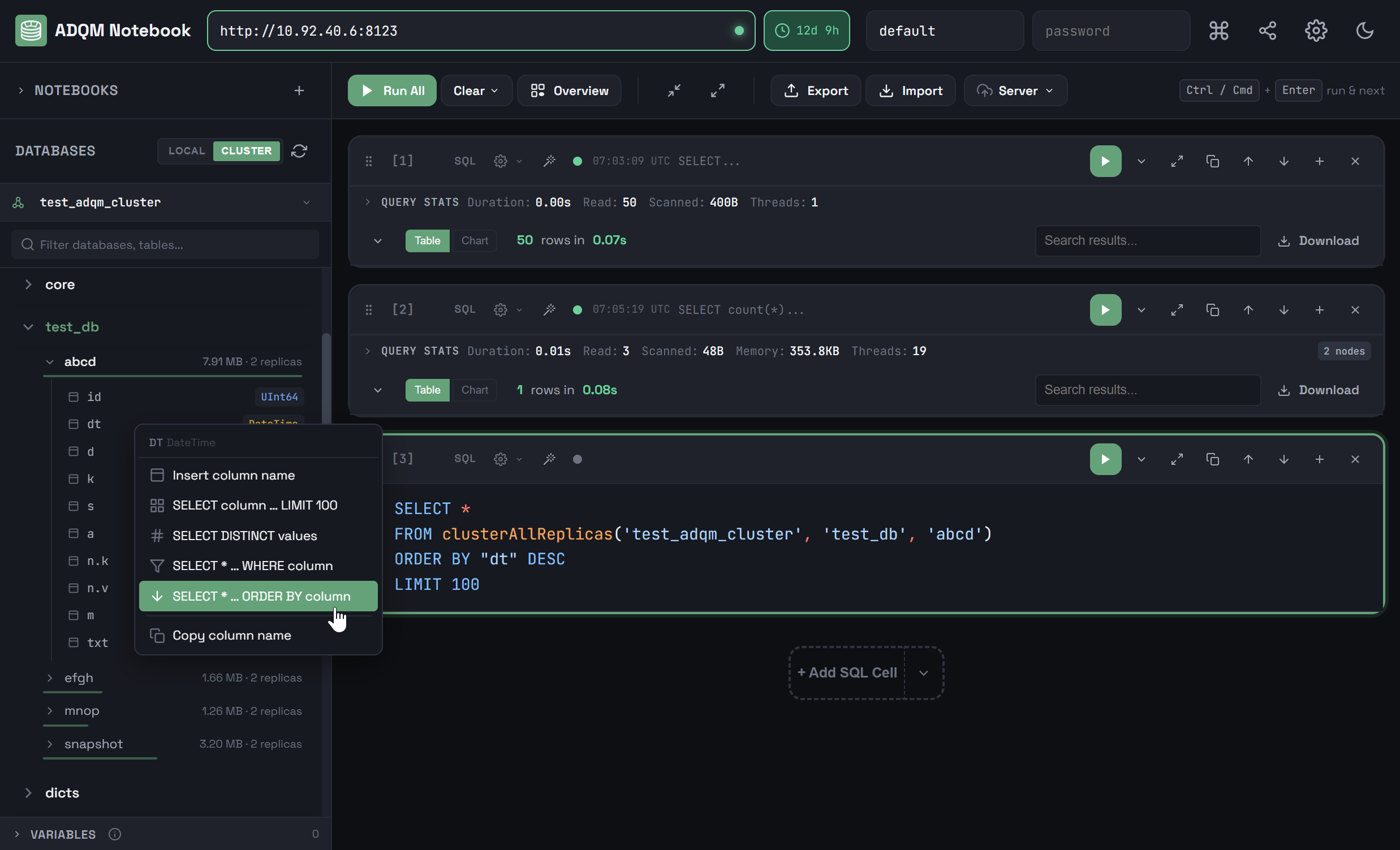
В контекстном меню доступны следующие действия:
-
Insert column name — вставить имя столбца таблицы. То же самое можно сделать, кликнув по строке, соответствующей столбцу таблицы, на панели DATABASES.
-
SELECT column … LIMIT 100 — вставить запрос, который считывает значения данного столбца из 100 первых строк таблицы.
LOCALSELECT "<column_name>" FROM "<database_name>"."<table_name>" LIMIT 100CLUSTERSELECT "<column_name>" FROM clusterAllReplicas('<cluster_name>', '<database_name>', '<table_name>') LIMIT 100 -
SELECT DISTINCT values — вставить запрос, который выбирает уникальные значения (не более 100) в данном столбце таблицы и вычисляет их количество.
LOCALSELECT "<column_name>", count(*) AS cnt FROM "<database_name>"."<table_name>" GROUP BY "<column_name>" ORDER BY cnt DESC LIMIT 100CLUSTERSELECT "<column_name>", count(*) AS cnt FROM clusterAllReplicas('<cluster_name>', '<database_name>', '<table_name>') GROUP BY "<column_name>" ORDER BY cnt DESC LIMIT 100 -
SELECT * … WHERE column — вставить шаблон запроса для чтения данных из таблицы с фильтром по значению данного столбца, которое необходимо дописать в тексте запроса в выражении
WHERE "<column_name>" =после знака=.LOCALSELECT * FROM "<database_name>"."<table_name>" WHERE "<column_name>" = LIMIT 100CLUSTERSELECT * FROM clusterAllReplicas('<cluster_name>', '<database_name>', '<table_name>') WHERE "<column_name>" = LIMIT 100 -
SELECT * … ORDER BY column — вставить запрос на выборку данных из таблицы с сортировкой результатов по данному столбцу в порядке убывания.
LOCALSELECT * FROM "<database_name>"."<table_name>" ORDER BY "<column_name>" DESC LIMIT 100CLUSTERSELECT * FROM clusterAllReplicas('<cluster_name>', '<database_name>', '<table_name>') ORDER BY "<column_name>" DESC LIMIT 100 -
Copy column name — скопировать имя столбца в буфер обмена.
В каждом из приведенных выше запросов имя столбца, для которого вызывается контекстное меню, а также имя таблицы, базы данных и кластера обозначаются как <column_name>, <table_name>, <database_name> и <cluster_name> соответственно — при вставке запроса в ячейку вместо этих обозначений будут автоматически подставляться фактические имена соответствующих объектов.
Схема зависимостей объектов
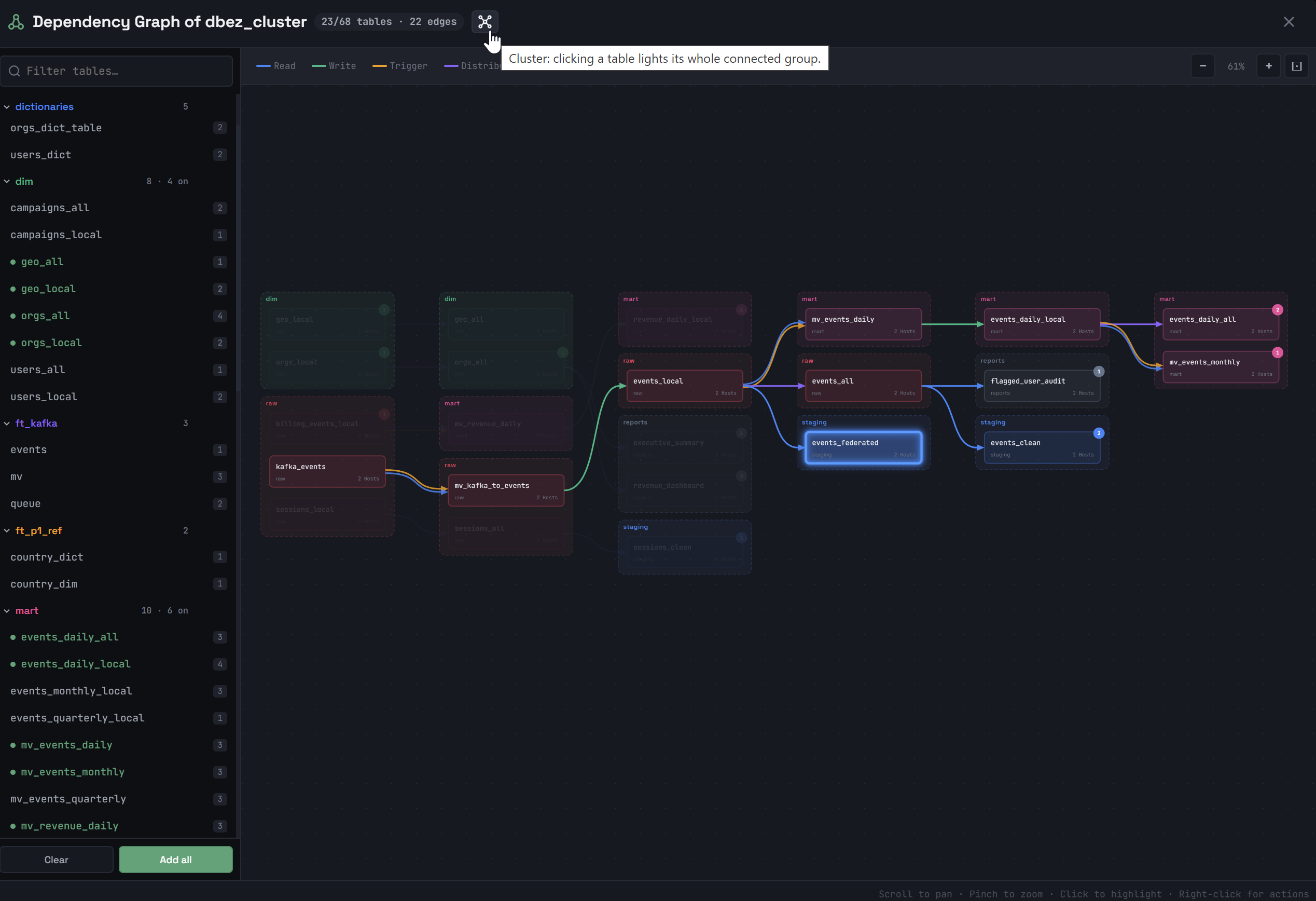
Кликните по иконке ![]() Show dependency graph слева от названия кластера, чтобы посмотреть зависимости между объектами баз данных ADQM.
Show dependency graph слева от названия кластера, чтобы посмотреть зависимости между объектами баз данных ADQM.
В открывшемся окне Dependency Graph of <cluster_name> в списке слева выберите объекты (кликая по именам), зависимости которых нужно посмотреть. Поддерживаемые типы объектов: таблицы (движки семейства MergeTree, Merge, Set, Join, Kafka, Distributed), представления, материализованные представления, словари, проекции.
Справа от имени объекта показывается общее количество его зависимостей. Чтобы выбрать все объекты, кликните Add all ниже списка. Кнопка Clear удаляет все объекты из схемы.
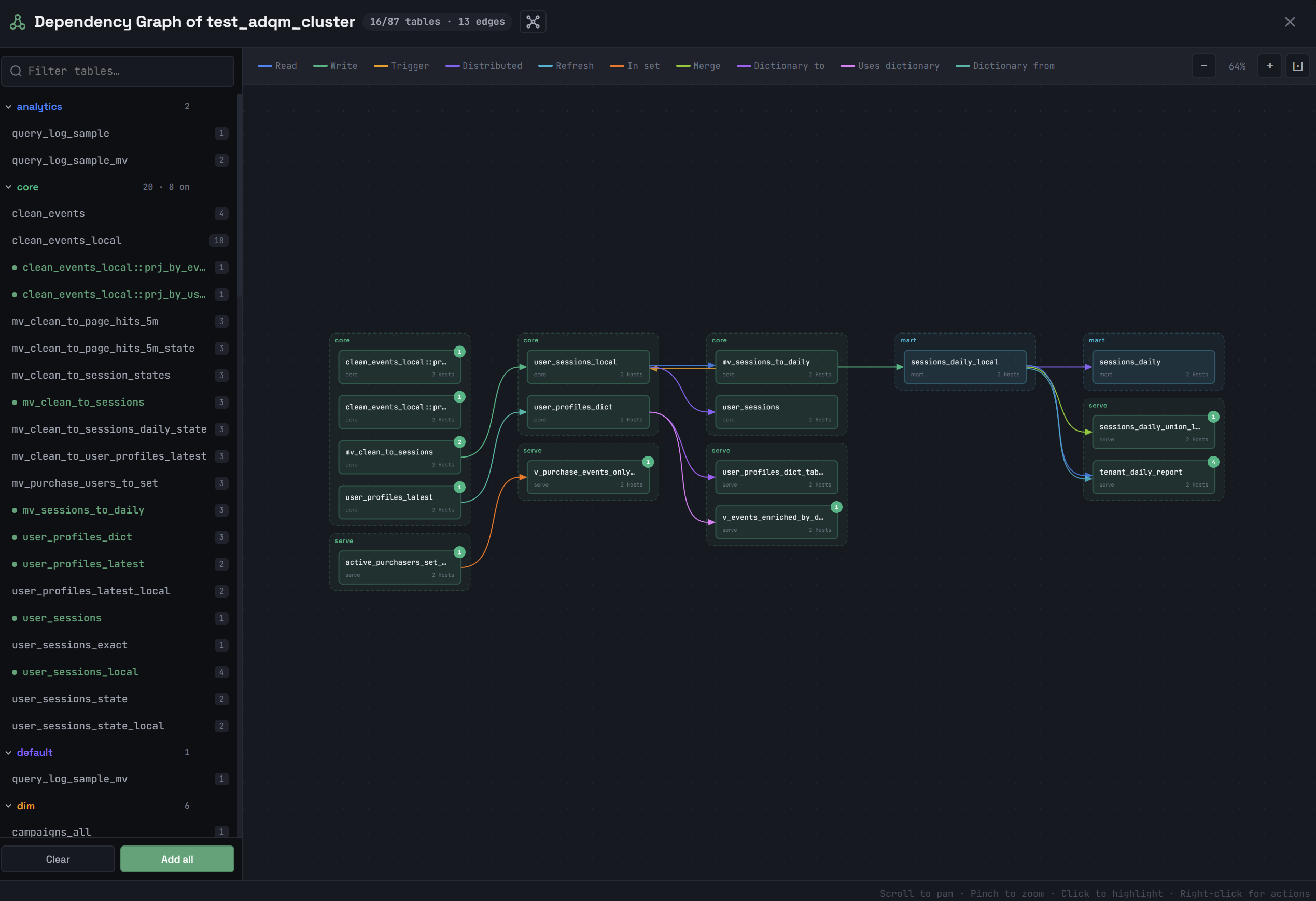
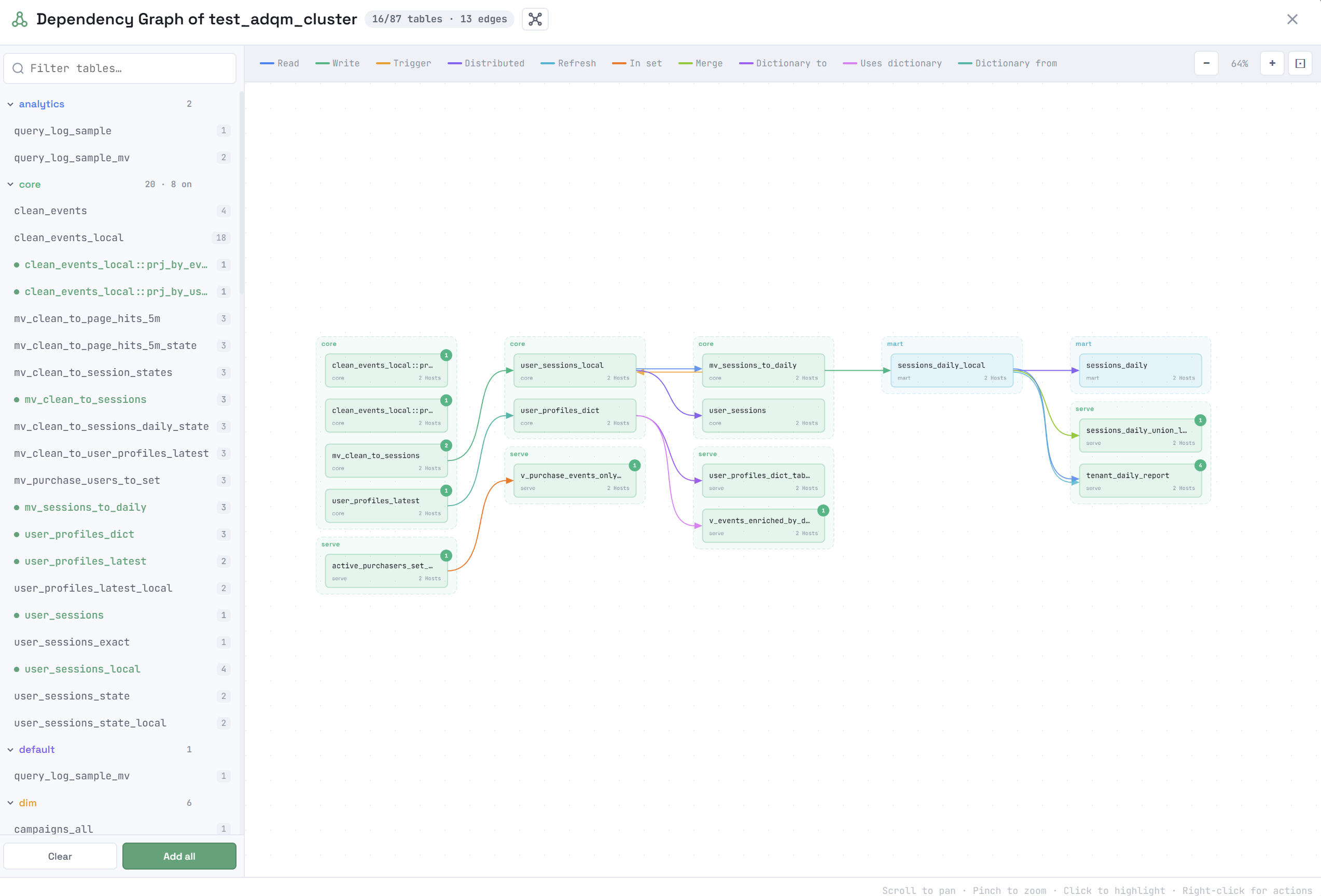
Выбранные объекты будут отрисованы в основной области окна и соединены стрелками. Цвет стрелки обозначает тип зависимости. Типы присутствующих на схеме зависимостей между объектами и соответствующие им цвета перечисляются в легенде в верхней части окна. Если кликнуть по типу зависимости в легенде, соответствующие связи (стрелки) между объектами будут удалены со схемы.
Возможные типы зависимостей:
-
Read — таблица и объект, из которого она читает данные;
-
Write — материализованное представление и целевая таблица, в которую будут сохраняться данные из него;
-
Trigger — таблица и материализованное представление, которое срабатывает при вставке данных в эту таблицу;
-
Distributed — Distributed-таблица и локальная таблица, на которую она ссылается;
-
Projection — проекция и ее исходная таблица;
-
Refresh — обновляемое материализованное представление и его явная зависимость (
DEPENDS ON); -
In set — таблица на основе движка Set и объект, который ее использует;
-
Merge — таблица на основе движка Merge и таблица, из которой она читает данные;
-
Dictionary to — таблица на движке Dictionary и словарь, на основе которого она создана;
-
Uses dictionary — таблица, использующая данные словаря через функцию
dictGet, и словарь; -
Dictionary from — словарь и его источник данных.
При наведении курсора мыши на объект во всплывающем окне показывается более подробная информация о нем и его зависимостях: на каких хостах располагается объект, какие объекты являются источником данных для него (зависимости receives from) и для каких объектов он сам является источником данных (зависимости used by).
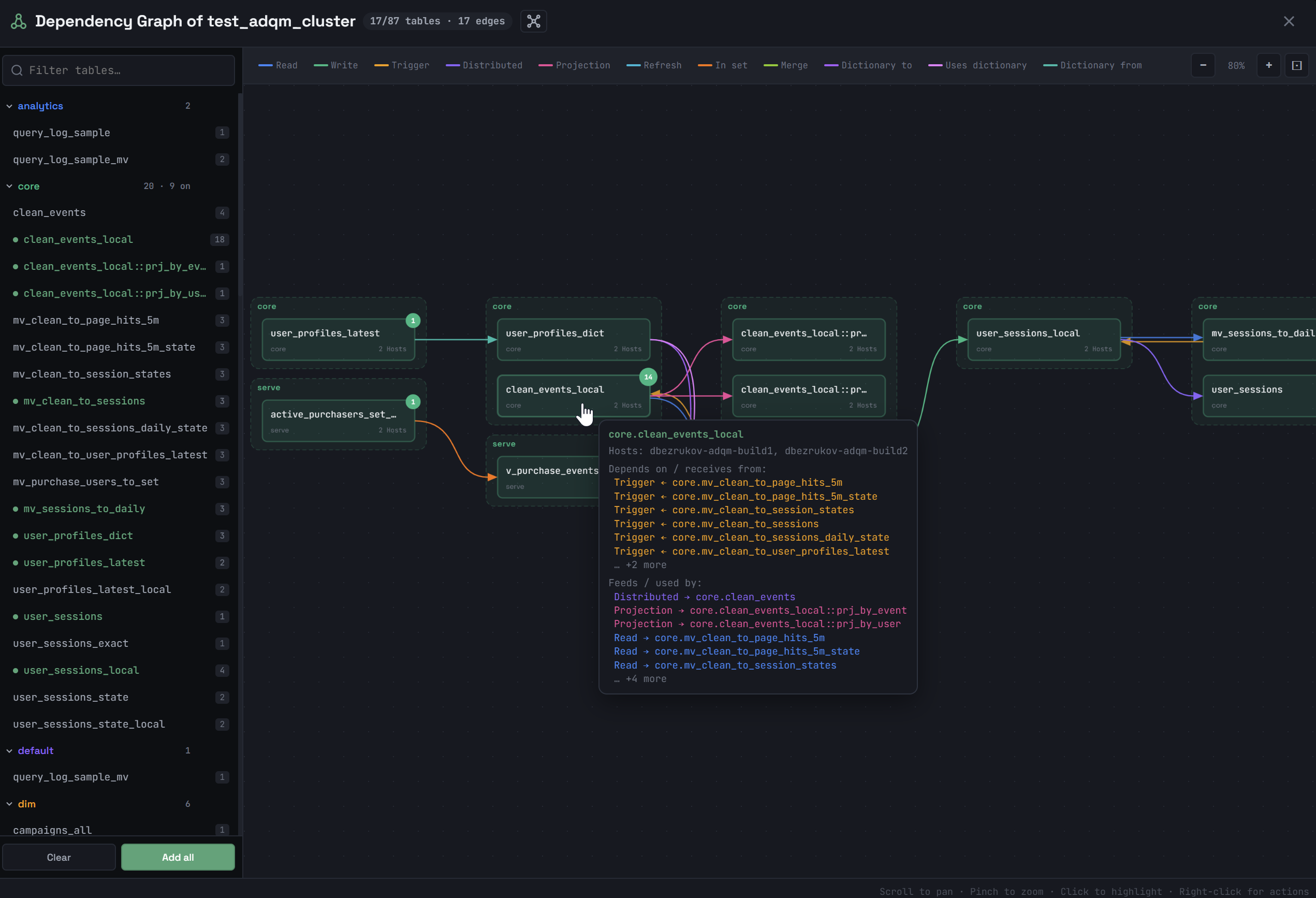
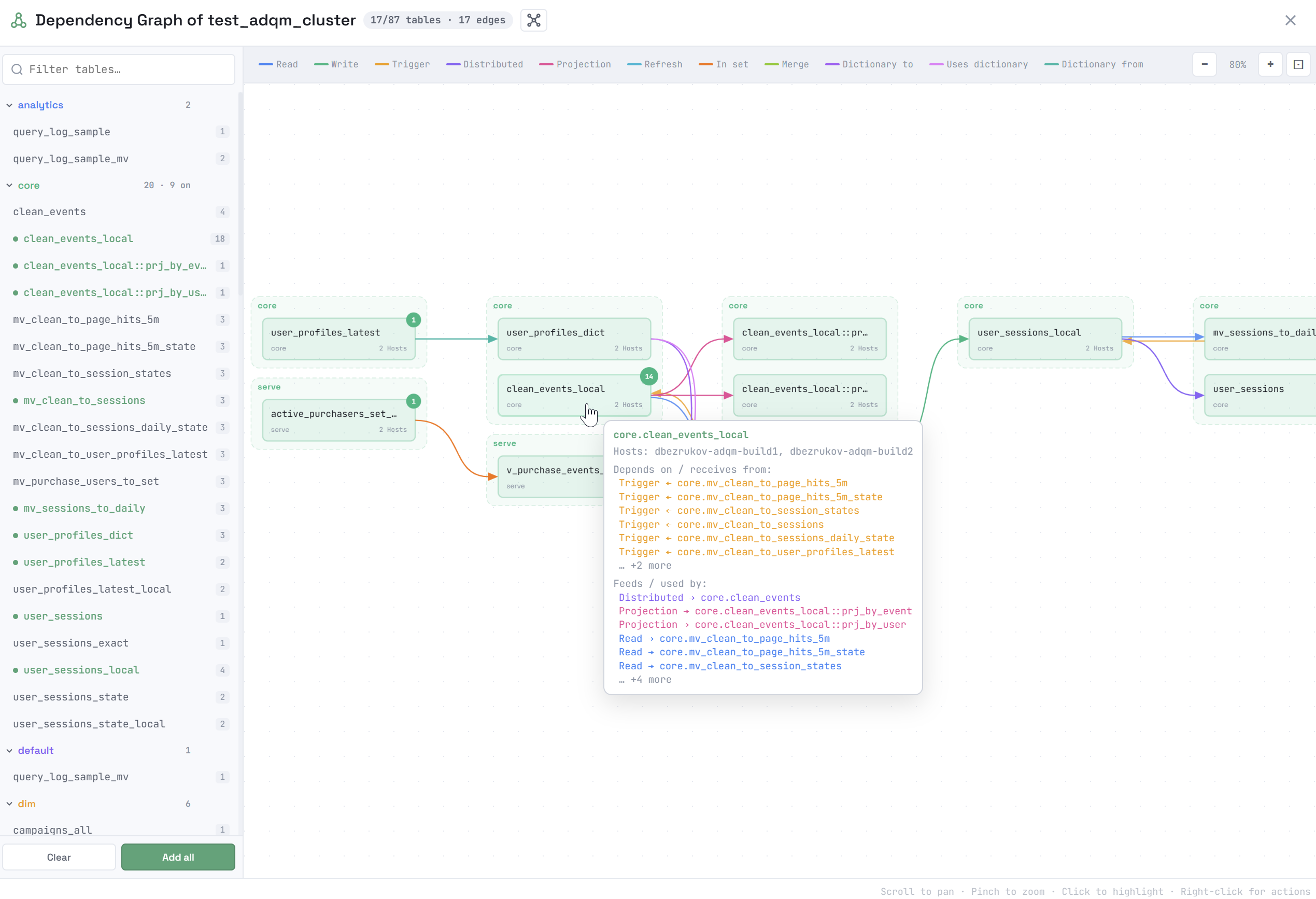
В правом верхнем углу объекта показано число его зависимостей, которые еще не показаны на схеме. Чтобы построить все зависимости объекта, добавленного на схему, нажмите на него правой кнопкой мыши и выберите из контекстного меню Upstream (зависимости receives from), Downstream (зависимости used by) или Expand all (все зависимости объекта). Команда Remove удаляет объект со схемы.
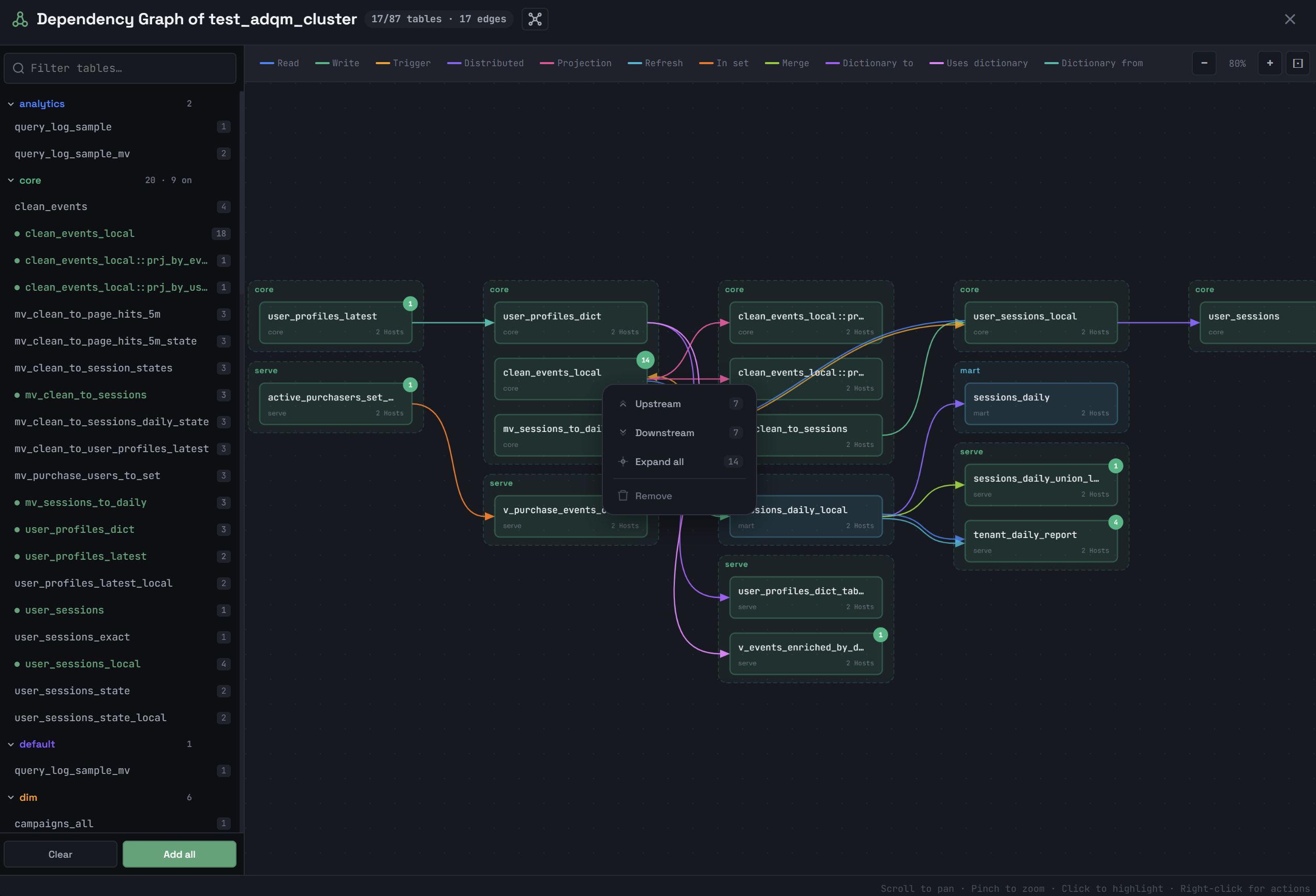
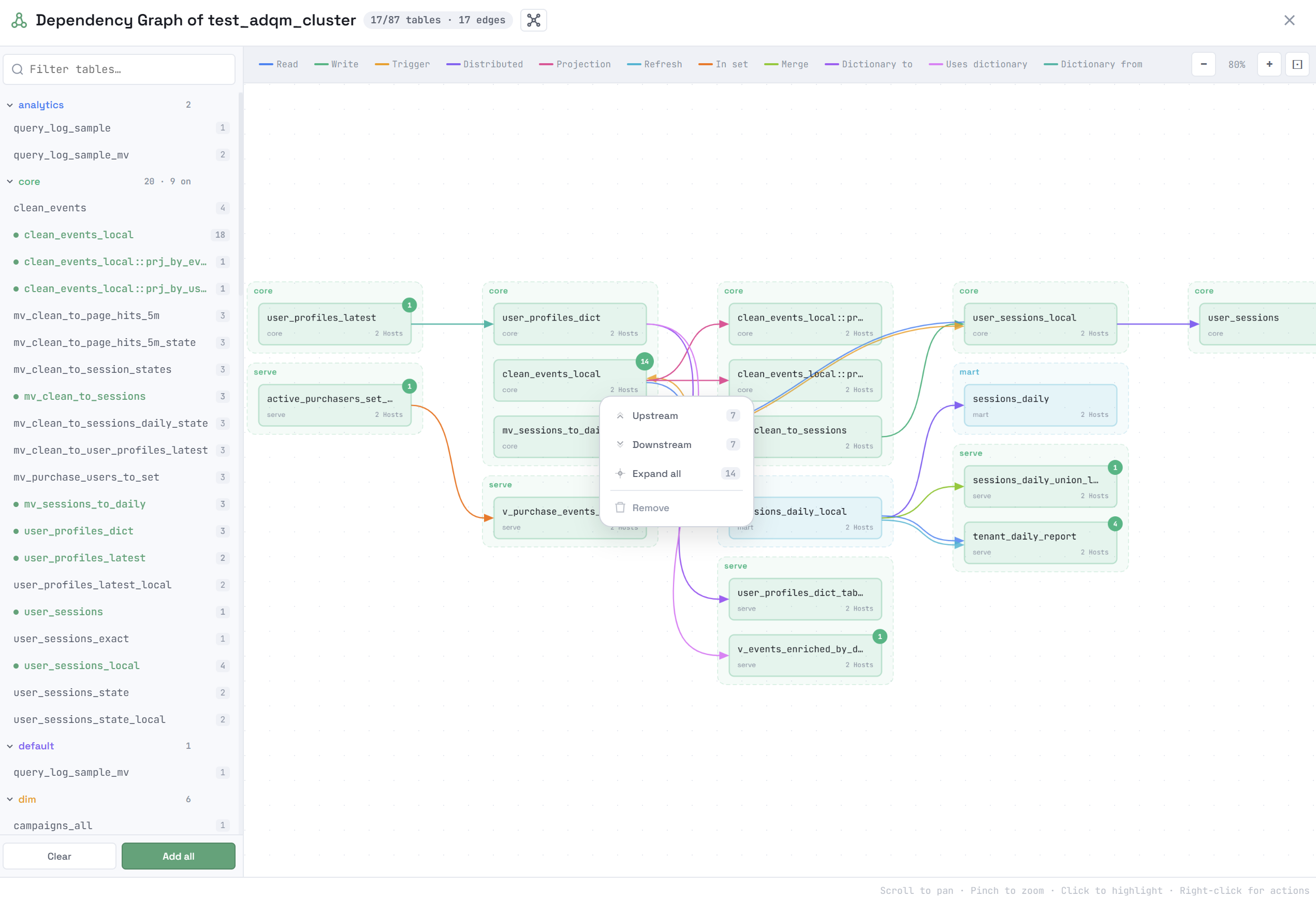
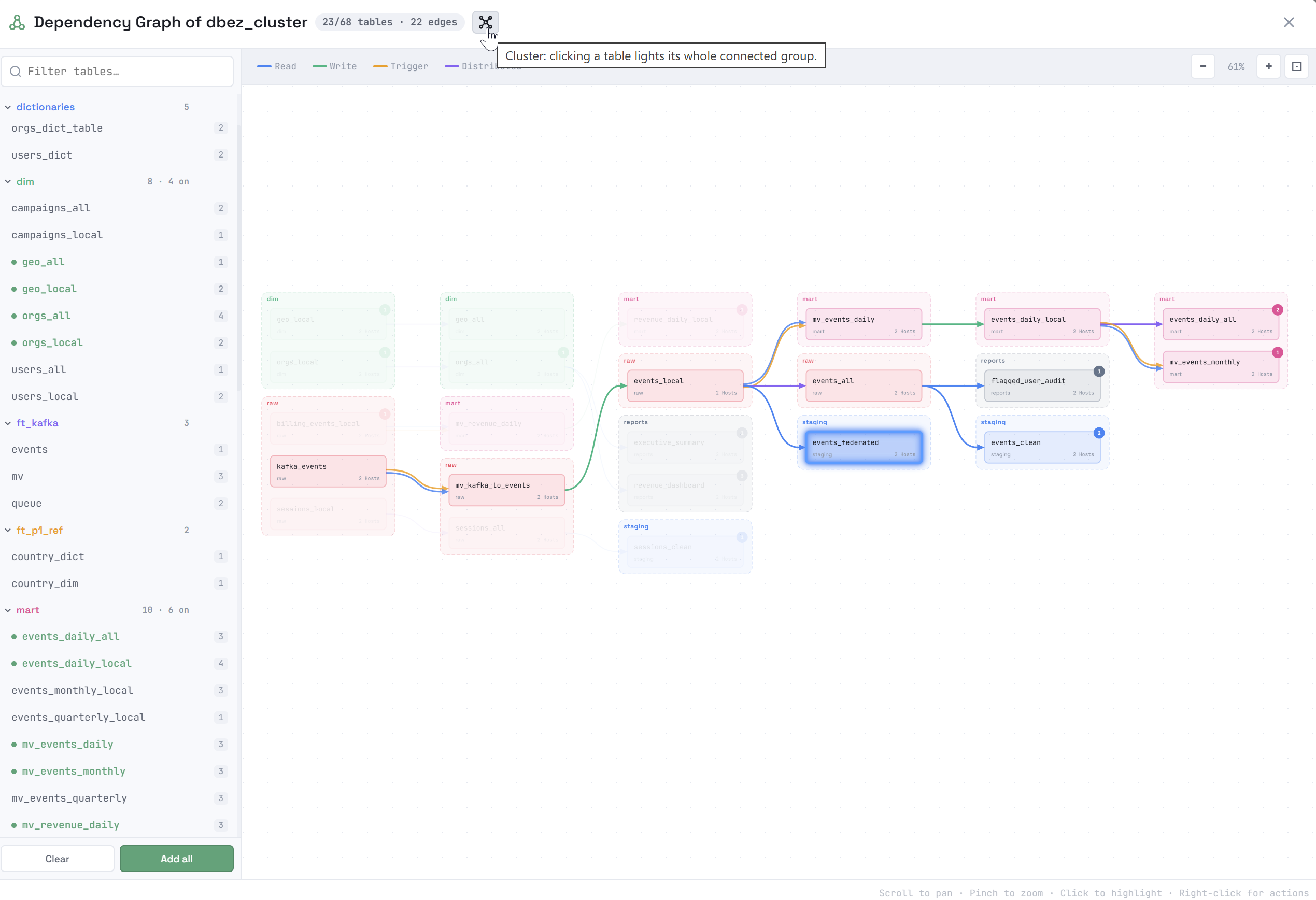
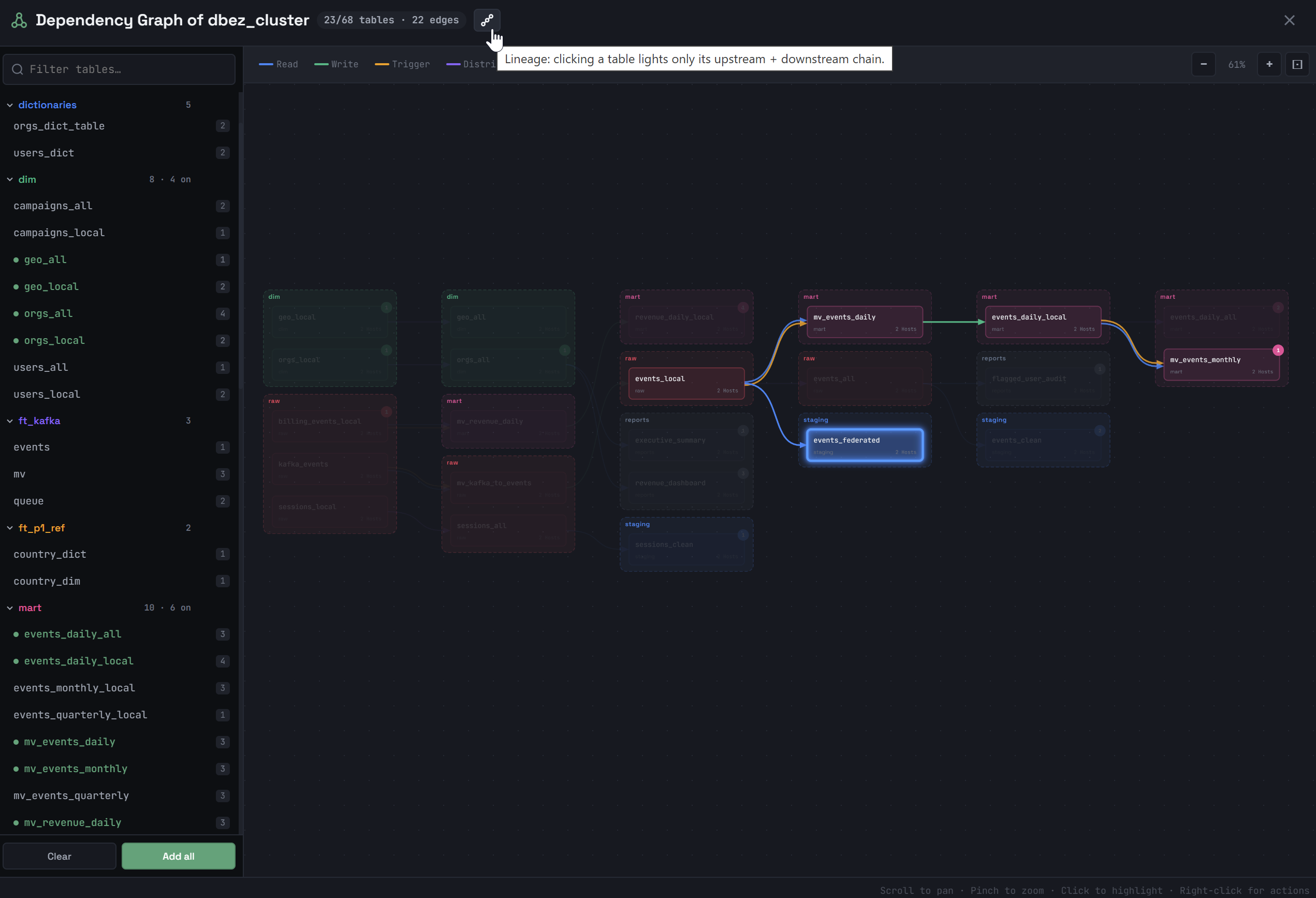
Если кликнуть по объекту на схеме зависимостей, подсвечивается подграф, в который включаются объекты в соответствии с опцией, выбранной в заголовке окна:
-

 Cluster — все объекты, связанные с выбранным объектом. При клике по другому объекту в этом подграфе подсвечиваемый подграф не меняется.
Cluster — все объекты, связанные с выбранным объектом. При клике по другому объекту в этом подграфе подсвечиваемый подграф не меняется. -

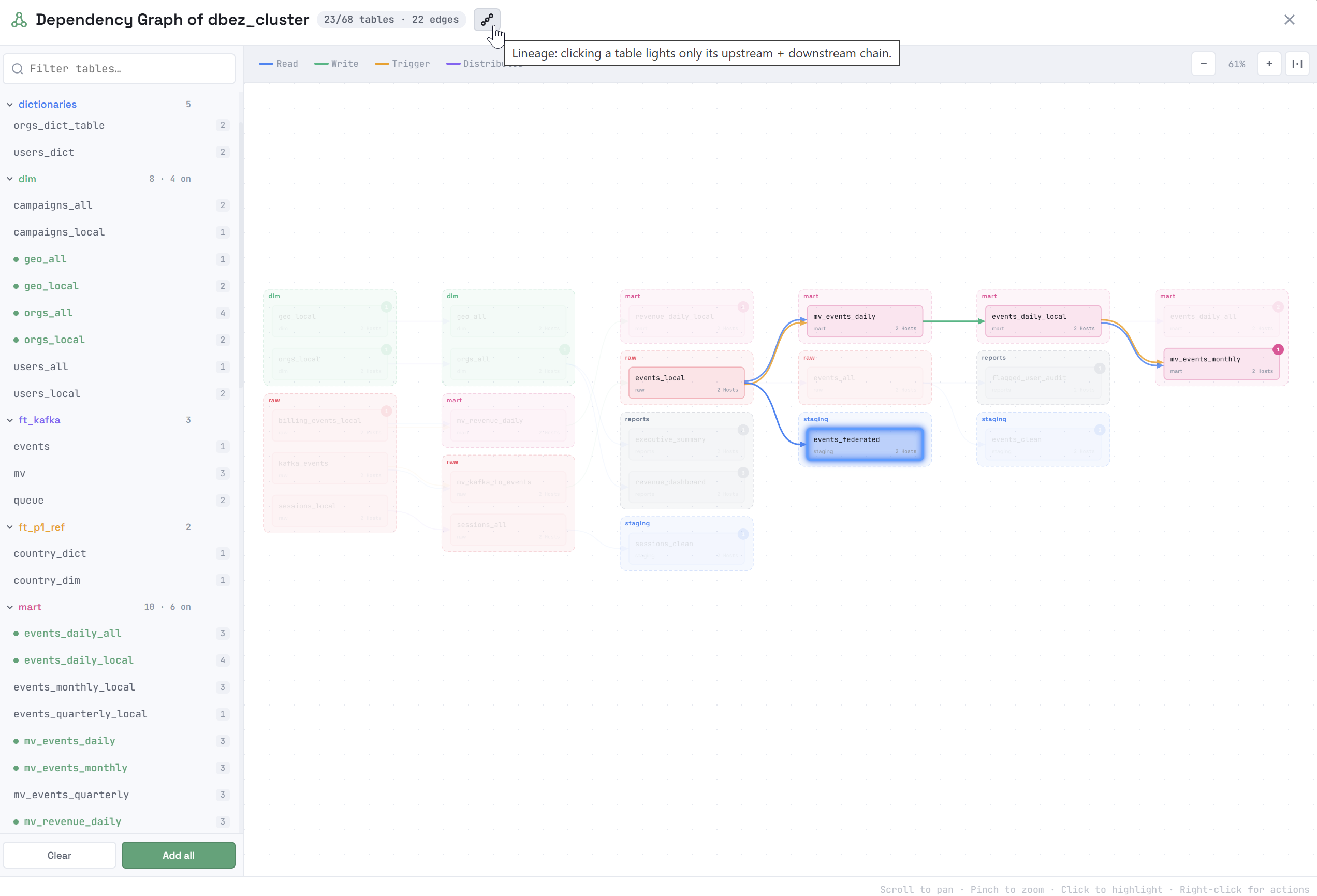
 Lineage — только предки и потомки объекта (то есть "соседний" объект, который имеет тот же источник, что и выбранный объект, но не принадлежит directed-пути, в подсвечиваемый подграф не включается). Если кликнуть по другому объекту в этом подграфе, будет подсвечен другой подграф — lineage этого объекта.
Lineage — только предки и потомки объекта (то есть "соседний" объект, который имеет тот же источник, что и выбранный объект, но не принадлежит directed-пути, в подсвечиваемый подграф не включается). Если кликнуть по другому объекту в этом подграфе, будет подсвечен другой подграф — lineage этого объекта.