How to create a documentation portal from scratch


"Show us your documentation". This is the first question that our potential customers ask us at any presentation of our software products. And they are right. Documentation is the best way to understand how mature the company is. If the documentation is convenient, well-designed, and contains only actual, well-structured data, it means that most likely software products themselves are at least at the same level, but definitely not worse.
But what if your documentation has been written by developers since ancient times and turned into chaos? What if you have never heard about the role of "Technical Writer"? How to develop your documentation portal and not fail up?
In this article, we — Dmitry (Architecture & Development Director) and Daria (Head of Technical Writing) — will tell you how we created the documentation portal in Arenadata from scratch. We hope that our example will help some of you to take the first steps in this direction.
Why?
For a while, as the main documentation resource, we used a combination of a simple landing made via Bitrix and texts based on Sphinx with default styles and themes. The documentation was written mainly by Software and DevOps engineers.


As we grew, considering that we work with the enterprise market, the documentation quality has become not only a necessity but also an important criterion for the maturity of our products. So, the answer to the fundamental question of any project, namely, "Why?", was on the surface. The state of documentation at that time left much to be desired, so we decided that it was necessary to start over and completely change everything, both landing and content.
Before the start, we had to answer a number of other key questions: "What?", "How?", and "Who?". In this article we offer you our answers to these questions, based on our two years of documentation development.
What?
Our strategy was to replicate the best practices of other companies first, and then develop our own identity and style more suited to our products. So, our journey began with a review of the best practices in documentation.
We looked at documentation of top companies in this area, for example. We also paid attention to the documentation of vendors whose products are close to ours — systems of data storage, management, and processing.
After selecting five suitable examples, we began with a deep analysis of each of them, examining the structure, the engines used, versioning support, and UX/UI.
Based on our analysis, we have selected the following key aspects.
1 — Target audience
First of all, it was necessary to find our target audience, taking into consideration the market segment of Arenadata products.
We have identified three groups of readers that we believe were most relevant:
-
database administrators;
-
data engineers;
-
technical support specialists.
This does not mean that we have ignored other end-user categories, but we have decided to focus on this specific group first.
2 — Content structure
The next step was to determine the content structure of the future documentation portal, which meant deciding whether to include the following sections: User guides, Tutorials, How to, Concepts, References, and others. It was also necessary to take into account different levels of our readers (Junior, Middle, Senior) and adapt the content accordingly.
3 — Content style
Although it may seem that the writing style is not so important, we paid special attention to it. In our opinion, without a uniform style the texts would be vague and difficult to understand. The main goal of our documentation is to present the information in a clear and concise manner so that users could easily find information on our portal.
4 — Approach to writing documentation
It was also important for us to choose the right approach to writing documentation among "docs-as-code", "docs-as-product", "wiki-oriented", and others. We have chosen the "docs-as-code" approach where documentation is reviewed and processed using the same tools and practices as software code. It includes the use of version control systems such as Git, CI/CD automation, document versioning, creating merge requests for reviews, and the use of markup languages to write and format text.
5 — English support
We create solutions based on Open Source, so English language support wasn’t even a question. Rather, we have asked ourselves a different question: "How do we properly organize the process of writing bilingual articles?". Should we first do a release in Russian, and then in English — or vice versa. Either way, both of those options have proven unsuitable for us.
We have decided to release bilingual documentation simultaneously with each new release of our products. It is important to note that we do not translate documentation, but write from scratch in two languages. This approach has proven to be effective in terms of the timing and quality of documentation.
How?
After we answered the question "What?", we faced the next question — "How?".
1 — Engine
Having chosen the docs-as-code approach we started to think about the documentation engine. Documentation engines are specialized tools that facilitate the creation, structuring, and management of documentation. There are many such tools, including Sphinx, Jekyll, Docusaurus, MkDocs, Antora, GitBook, and others.
It was important for us to write the landing of the portal in the same programming language as the engine. This would allow us to customize the engine if its standard capabilities were insufficient to implement our ideas. As a result, this approach has been fully justified and has provided greater flexibility in managing documentation. This narrowed the choice down to the static site generator Antora. If it’s of interest to any of the readers, we will look more closely at the comparison of different analogues in one of our next articles.
However, the engine was not a panacea for us. In our case, only 5% is Antora, the remaining 95% is our own JS customization on top of it. But Antora is a good tool for technical writers because they write in the convenient AsciiDoc format.
2 — Internal search
We have been thinking about the possibility of using ready-made search tools for the portal, as well as our own development on the basis of ElasticSearch. Eventually, we came to the conclusion that the second option would be better for us, because we could improve the search ourselves. It may seem that to expand the functionality of the internal search engine is meaningless, but our experience has shown the opposite.
We realized that users would be less likely to use the website’s built-in documentation search, rather going to Google/Yandex and from there directly to the desired article on our portal. Nevertheless, we pay special attention to the internal search to make it as user-friendly and easy as possible. For this purpose, we have introduced product tags.
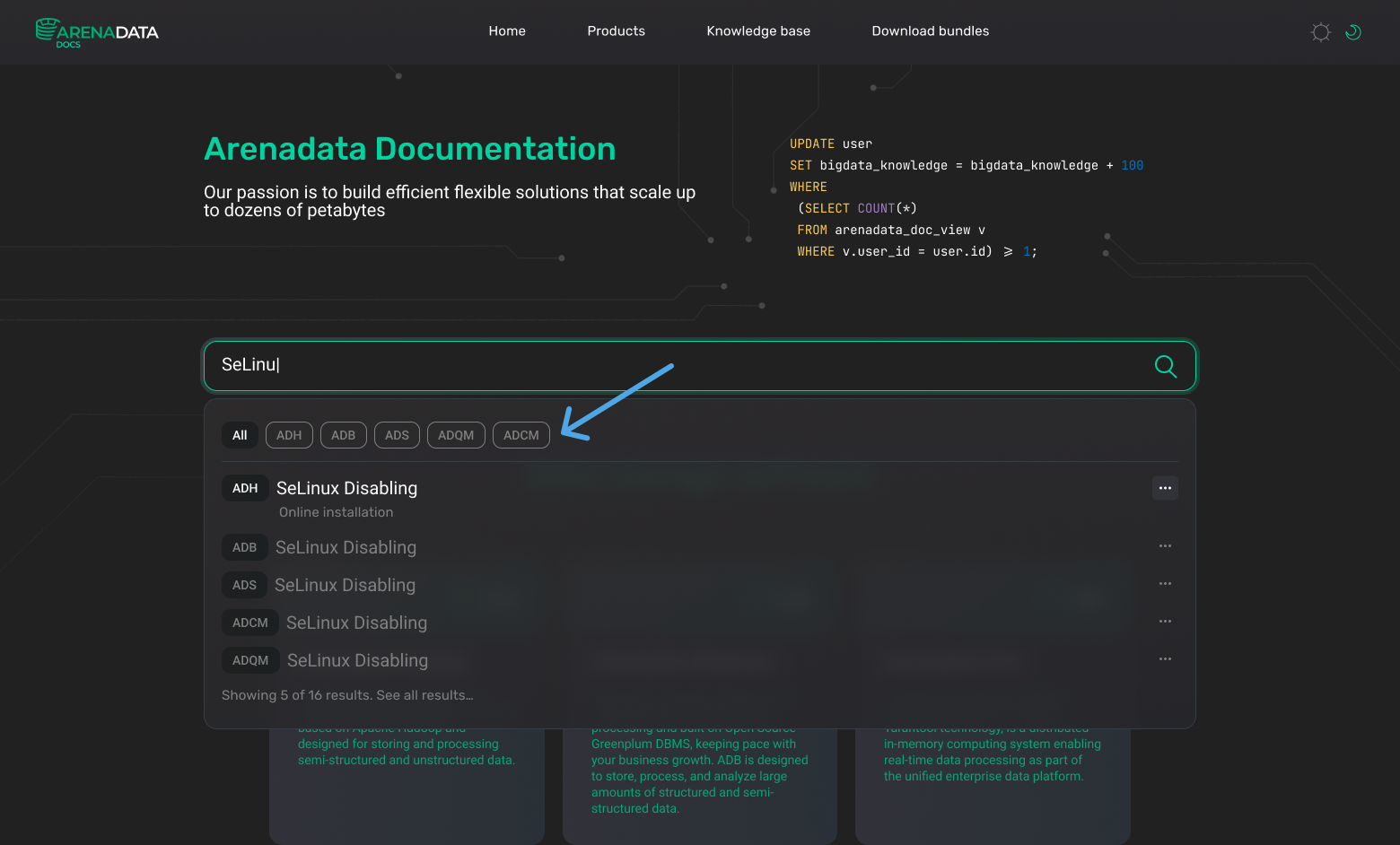
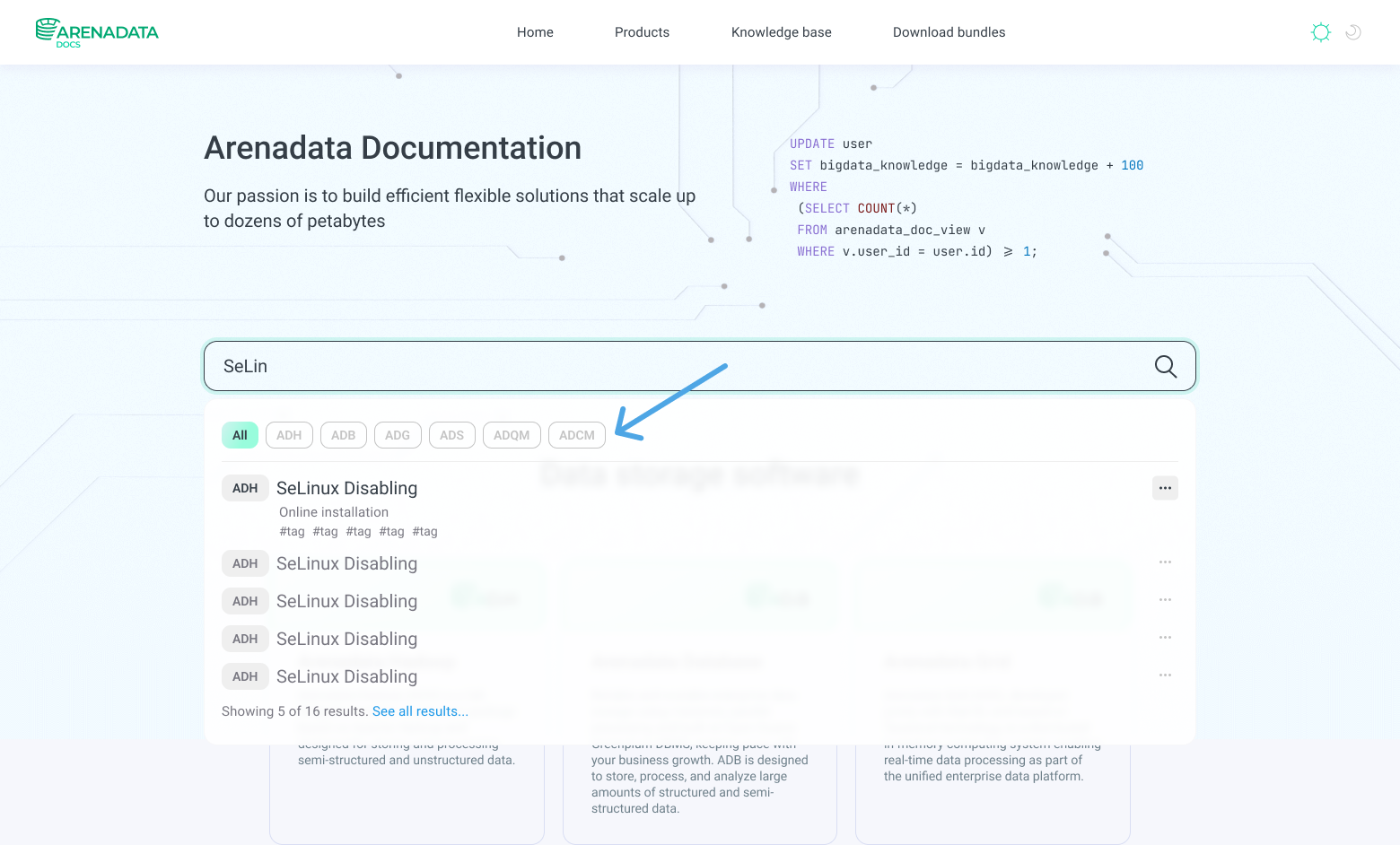
3 — Writing process: assigning tasks, testing, review


For writing documentation we use two-week sprints. They do not coincide with the sprints of development teams, but determine a set of articles that each writer has to write or edit during this time. It can be both descriptions of new features for upcoming product releases (these tasks are usually created by architects, system analysts, and technical program managers — TPM) and articles on basic topics unrelated to any version of the product (such tasks are created by the Head of TW). Sprints are useful to avoid accumulating a large amount of changes in texts and to proofread them in small chunks. Initially, we didn’t do sprints, but as the team grew, they became necessary. For over a year we used one-week sprints, and in 2024 we switched to two-week planning.
Tasks are created in the bug tracking system. While working on the article, a writer is guided by the information from the task (topic, recommendations for structure, links to the Open Source documentation, SEO recommendations), conducts an independent search in open sources, and actively cooperates with colleagues from related departments. Primarily with product architects, system analysts, technical managers, and, if necessary, software developers.
Important point: every writer specializes in a specific product, and also does independent testing of the documentation. In other words, writers perform all the steps mentioned in their articles. This includes deploying and configuring test stands on remote infrastructure in the cloud, installing all required services, writing and running SQL queries, as well as code in other programming languages, and much more. As we mentioned above, from the very beginning, it was important for us that technical writers do not play a purely paperwork role, but deeply immerse themselves in their products and test the processes described — and this approach quickly yielded results: sometimes technical writers are the first to suggest useful improvements or corrections for the products they describe.
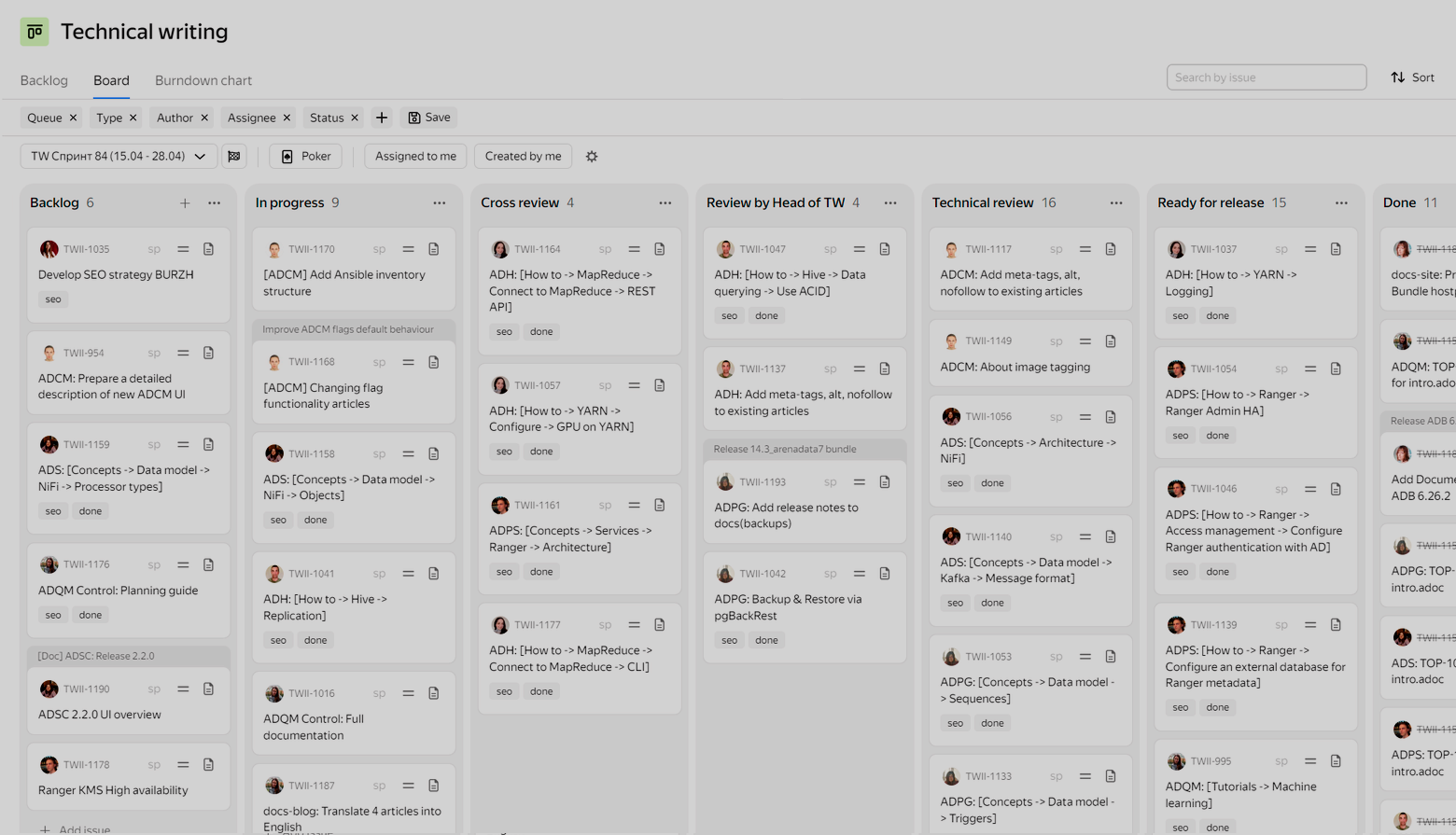
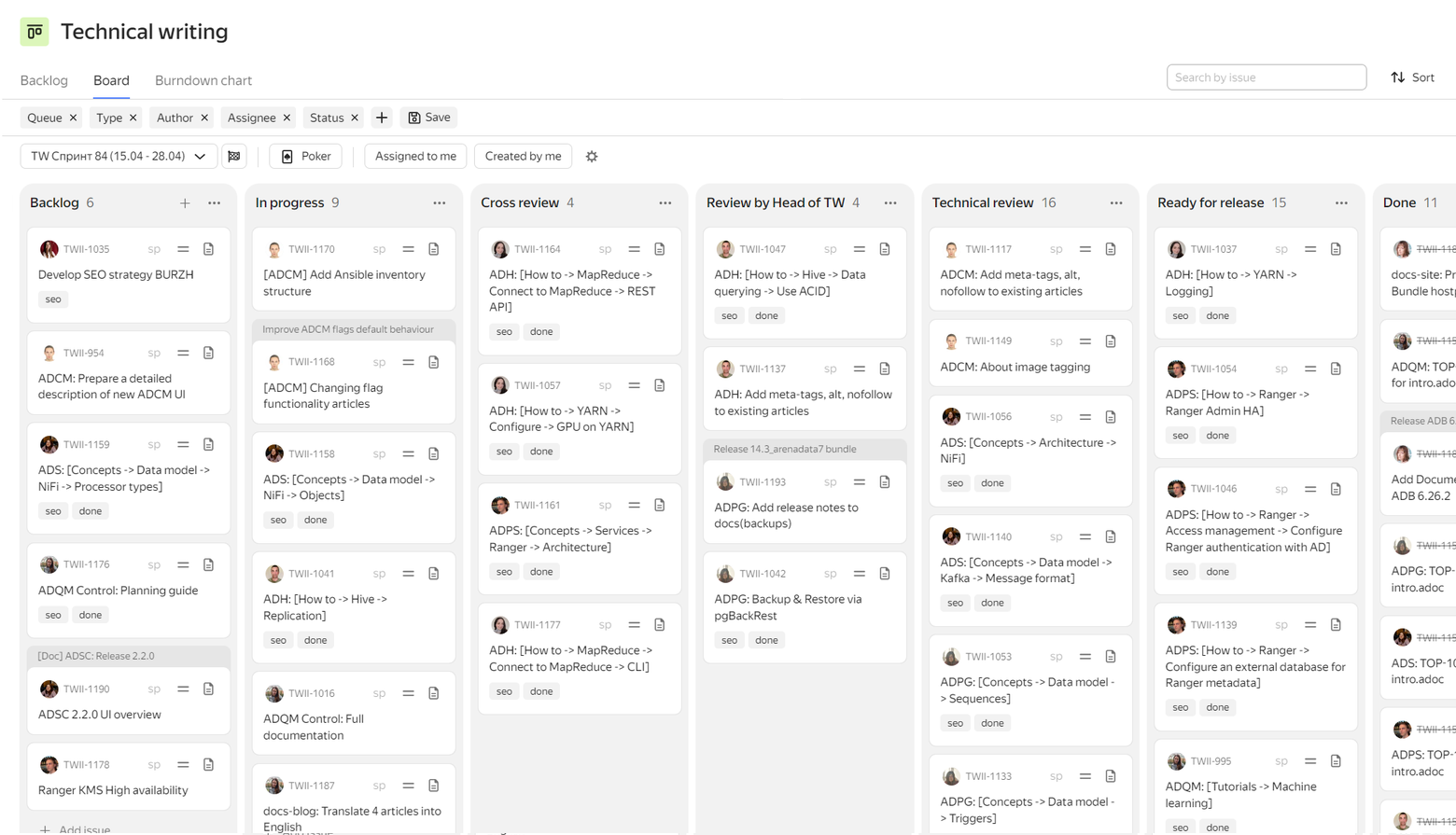
All texts in AsciiDoc format writers create via GitLab — within separate branches in repositories with product documentation (one product = one repository). At the end of the sprint, for each completed task, a MR (merge request) is created, and the task is directed to a review. Currently, we have three types of reviews (following each other):
-
Cross review. All the writers are divided into pairs, and at the end of the sprint each writer reviews his or her partner’s MR — for typos, grammatical errors, as well as compliance with our internal style guides.
-
Review by the Head of TW. After the cross review is done, the Head of TW conducts an additional check of the MR with the mandatory local build under the author’s branch.
-
Technical review. After fixes based on the first two reviews are completed, the author’s branch is merged into the
master, and all changes are automatically built on the Test stand. The web interface of the Test portal is used for final check of actual errors — by our architects, analysts, and TPM. All necessary corrections based on their feedback will be taken into account in the next sprint. As a rule, they are few, because from the beginning of work on the task, the writer interacts with colleagues if necessary.
After all reviews are completed, the sprint ends and the next tasks are taken up. Note that the described workflow was not formed immediately. We changed it repeatedly, adapting it to the size of the team and current goals. For example, the aforementioned cross-review was introduced only in 2024. And since the end of 2023, each task in the backlog is supplemented with recommendations on SEO optimization: values of the title and description meta tags, suitable keywords, structure recommendations based on the analysis of similar materials in the network, etc. Below we’ll tell more about the role of SEO in our team.
4 — Content
As mentioned above, at the beginning of the project, we defined sections for future documentation (Planning guide, How to, etc.). But at the implementation stage we faced additional questions: is it better to convert the old documentation or write a new one from scratch? Which articles should be written first? And, importantly, how long will it take to release a new version of the documentation for each product?
We abandoned the idea of converting the previous documentation on Sphinx, because it was mostly irrelevant and contained both grammatical and factual errors. Like we said before, it was documentation for a startup our company was at that moment. So we decided to write all texts from scratch, although the tools for converting from RST to ADOC exist and have even been tested by us (for example, via the pandoc utility).
To answer the remaining questions, we prepared detailed content maps for each product, which described all future articles and their location in the website navigation menu.


Then, on the basis of content maps we created roadmaps, where the scheduled tasks were distributed among authors on a weekly basis.


The detailed roadmaps allowed us to answer when the first releases of updated documentation for each product would be ready. Of course, there are skeptics who will not believe that with such level of detail it is possible to meet the deadlines — much less those set a year or more in advance. However, practice has shown the opposite. For most products new articles were released as planned.
Currently, 80-90% of the original content maps are implemented for most of the products. When they are fully processed, we will find new topics for the articles. It applies only to scheduled articles. All changes regarding new product releases are processed as a priority as soon as we get the tasks from other departments.
But we no longer update the roadmaps. Now we create tasks in the tracker for 1-2 weeks ahead, because the team has increased significantly, and with the addition of a new role (SEO) more in-depth task descriptions were now required. But in general, roadmaps were quite useful during the first phase to set a certain pace of work, which we maintain to this day.
5 — Details of the documentation building: environments, versioning, multilingualism
In all environments documentation is built automatically according to the pipelines configured by our CI/CD command in GitLab. We use 3 environments:
-
Test. As mentioned above, articles are published to the Test environment at the end of the sprint after going through two reviews and merging the author’s branch into the
master. The stand is mostly intended for technical reviews and shows the most up-to-date version of all articles (master), including those changes that will be published on Prod only in upcoming releases. -
Preprod. Unlike Test, Preprod displays not one but several versions of the documentation for each product — those that have been merged into the release branches. When it’s time for another release, a new release branch is created from the
master. PreProd is updated daily according to the schedule. In fact, it shows us how the documentation will look in Prod. -
Prod. This is the main documentation website available at the address. The Prod update is also done automatically (by running the pipeline) and is mostly an upload of artifacts created during the last PreProd update.
The division into environments was implemented quite quickly thanks to the functionality of Antora. Its playbooks in YAML format allow you to specify from which repositories and branches you need to upload ADOC files to the website build. Thus, in the Test playbook we specified the master branch, and in the PreProd playbook — all release branches (with the release* prefix).
At the moment of the PreProd build, Antora independently extracts the product version number from each release version of the code and saves it in the site structure. Then, this version number is displayed in the web interface — in the version selector. Thanks to this, the portal supports documentation versioning for each product.
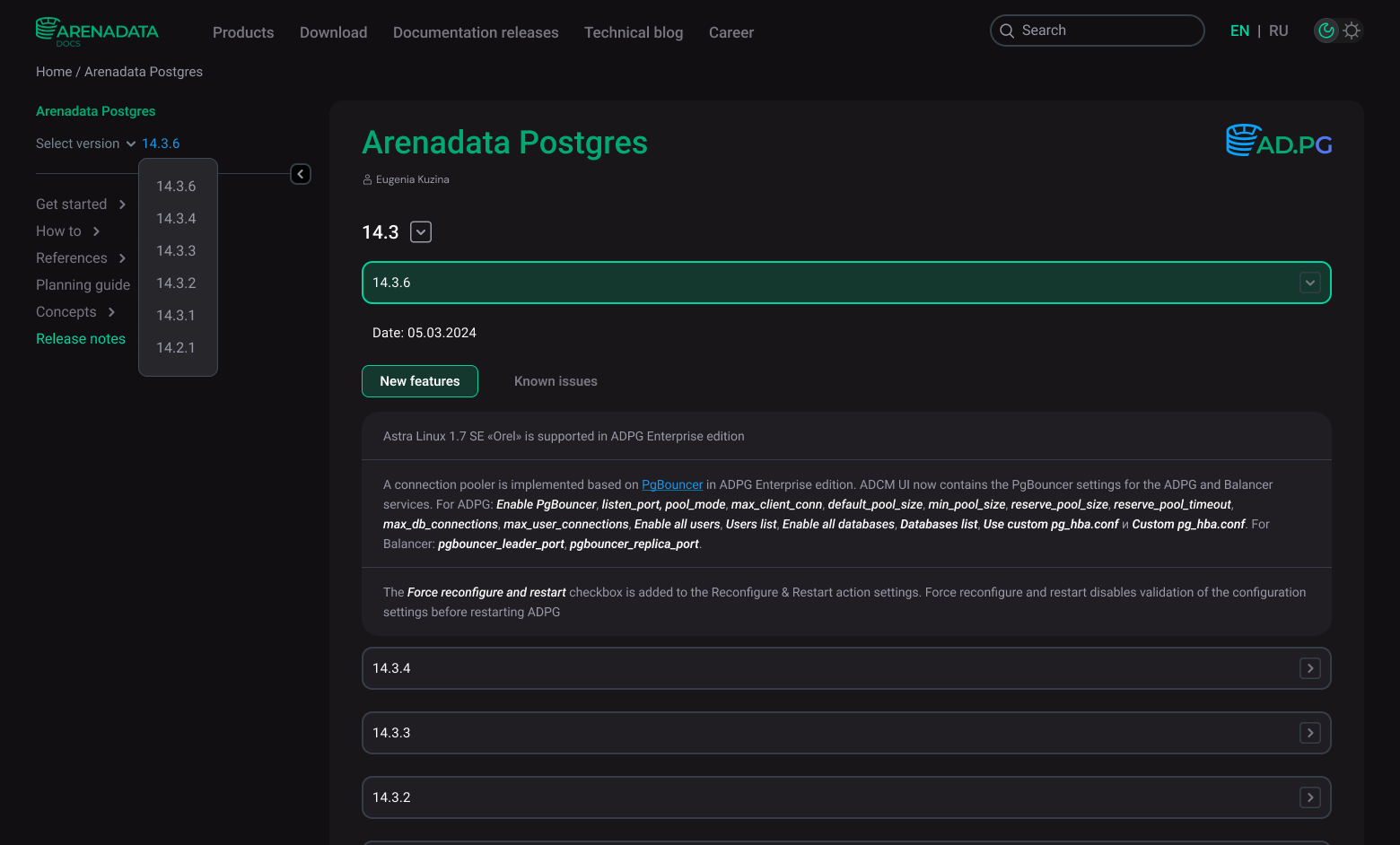
Through the split into playbooks, we implemented another, no less important, function of our portal — multilingualism. Antora does not support the use of several languages "out of the box". It took us several days to figure out how to implement the language switch via a button in the UI. The solution was very simple: instead of one build for each environment, we started to make two builds — based on separate playbooks for Russian and English languages. We created two root directories in all documentation repositories: EN and RU. Accordingly, RU playbooks refer to the RU directories with the code, EN playbooks — to the EN directories. As a result, we now use 4 playbooks: EN/RU for Test and EN/RU for PreProd. And the entire website language is switched, as intended, via one toggle button in the top right corner of the page. This solution, despite its simplicity, is scalable: if necessary, you can always add an additional language without making significant changes to the existing code.
6 — Style guides
At the initial stage of development of the documentation portal, we did not have detailed style guides, since the elements of the web interface were being designed and developed in parallel with writing of the first articles. As a result, a lot of inconsistencies started to appear in the documentation of various products: file names were highlighted both in monospace and italic, different types of tables were used for the same purpose, etc. Therefore, the issue of internal rules for writing documentation became pressing very soon.
When writing style guides, we did not focus on Google, Microsoft, or other well-known styles often used in other companies. We had our own unique design, and, therefore, wanted to adapt our style guides to it as well.
As a result, we formed a set of rules for using the main components of the UI: fonts, tables, lists, code snippets, command output. We described both the standard syntax of AsciiDoc and the additional classes implemented by our frontend developers for the needs of our design: collapsible blocks, tabs, pagination buttons, cards, and more. Finally, on the basis of the most common errors, we developed a checklist for self-testing articles by authors before sending them for review.
In the first months after publication on the internal portal, style guides were actively supplemented, e.g. based on feedback from new employees. If a complicated case was not covered, we discussed it at the daily meeting and fixed in the rules. However, we have never sought to document "everything". We believe that form is important, but it shouldn’t take precedence over content. The currently approved rules are sufficient to make the texts for different products look unified, so the reader can always determine what each color, font, etc. means, regardless of the page it is used on.
7 — Documentation releases
Starting from the very first releases of the documentation, we described every change in detail and notified all interested employees via the company messenger. These messages were subsequently converted into a separate section Documentation releases on our portal. The most important advantage of this section for our clients and employees of other departments is that they no longer need to wait for the next digest in the mailing list or messenger — it is enough to open the page from time to time and independently track updates of the desired products.
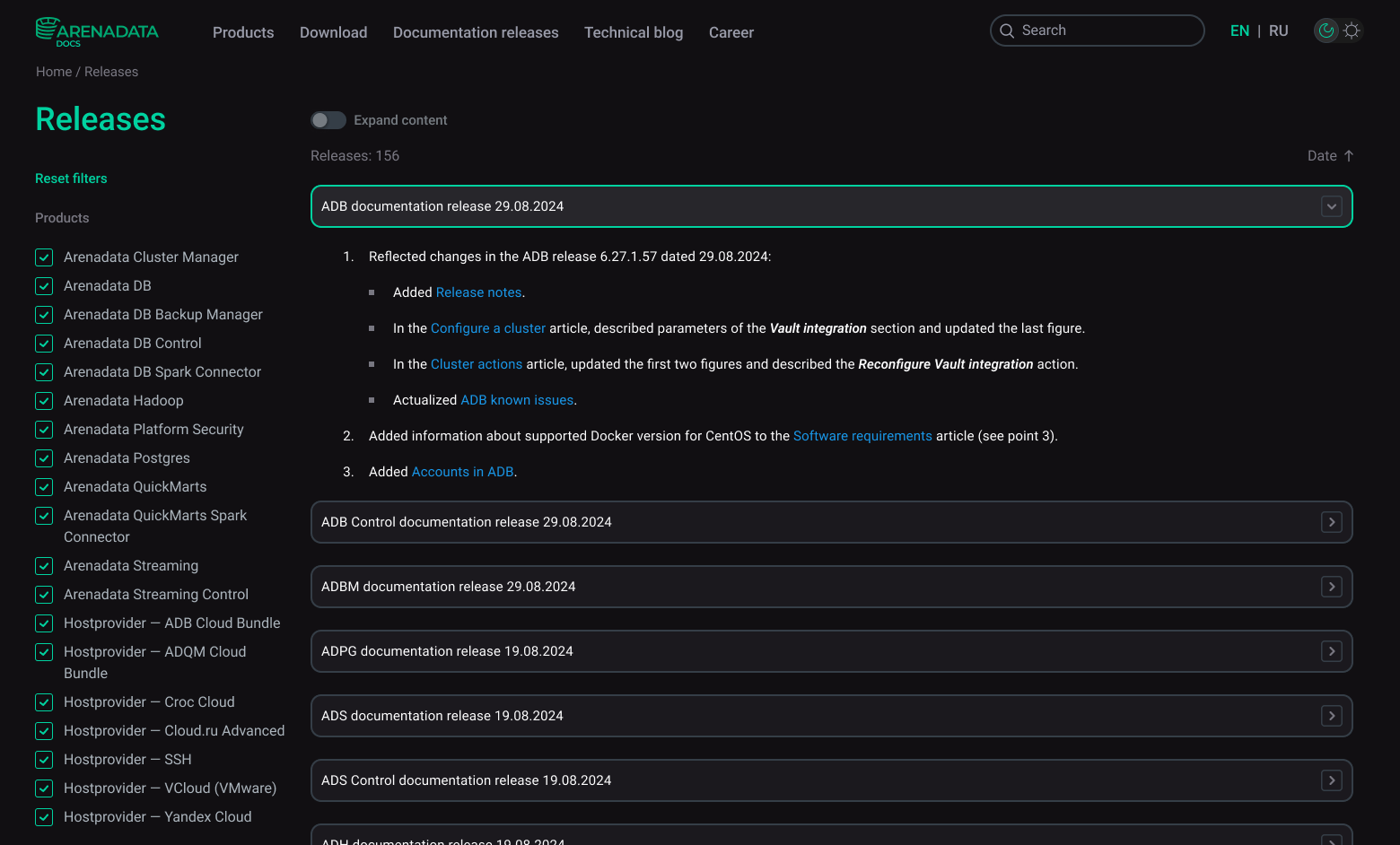
It is important to say that the documentation release in our company is not equal to the product release. Yes, we try to produce documentation in sync with product releases, and most often the documentation release includes articles that describe product changes. However, the concept of the documentation release is broader: it may include other articles on various topics, which are not related to the new product release. Besides that, documentation releases may be published more frequently in comparison with product releases.
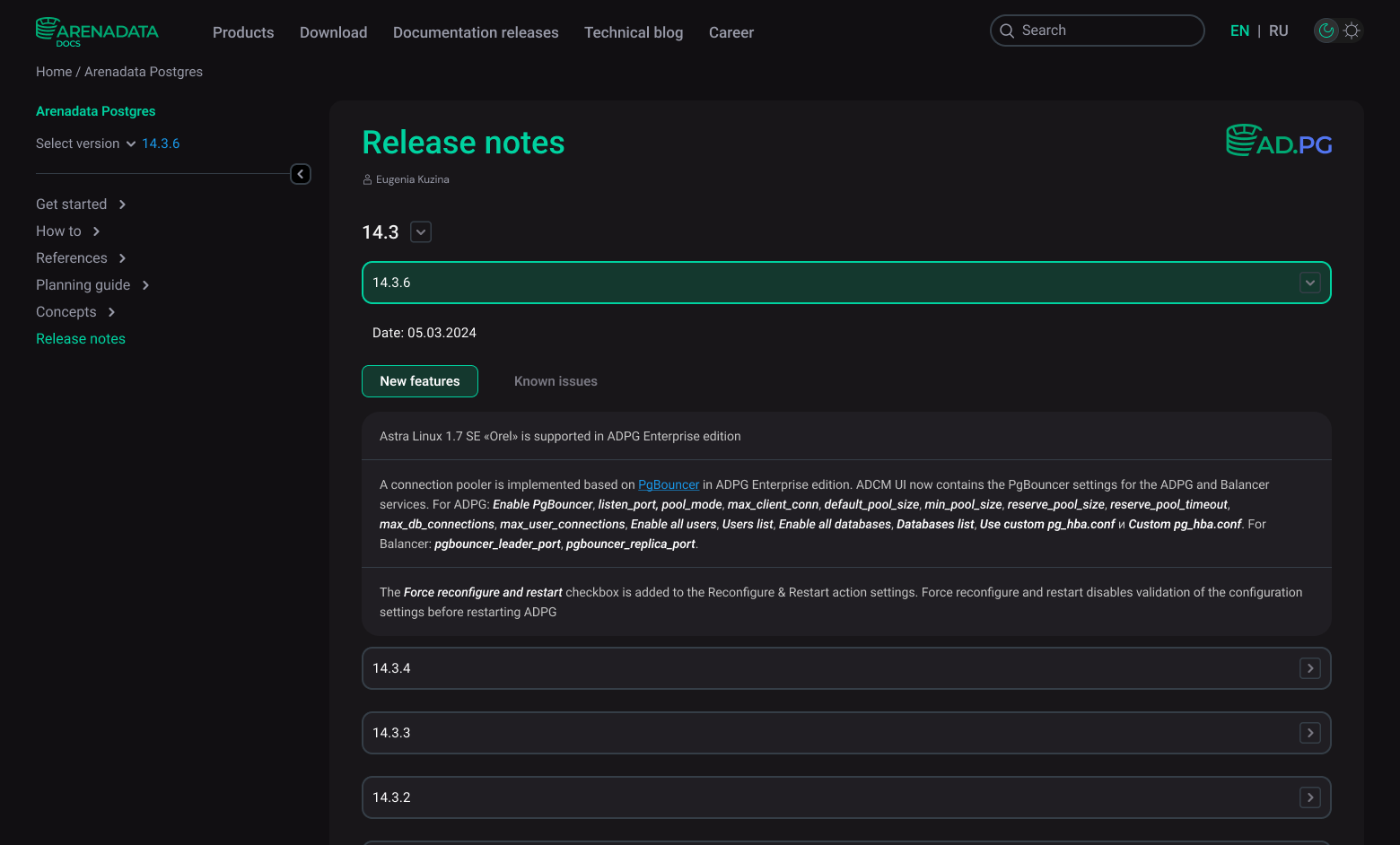
Releases of the products themselves are also described in detail — in the "Release notes" section of the documentation of each product. For easy reading all changes are grouped by version number and type: new features, improvements, bug fixes, misc/internal.
Who?
Let us now turn to a final and equally important issue.
It’s about the team.
At the start, the following team was required:
-
Technical writers: 1 Senior + 2 Middle.
-
DevOps: 1 Middle.
-
JavaScript developers: 1 Senior + 1 Junior.
-
UX/UI designer: 1 Senior.
Overall, 7 people.
We paid special attention to the quality of recruitment. This was incredibly important, especially in the beginning, because the strength of the entire team depended on the caliber of the people we hired at the start. In order to significantly increase our chances of finding the right candidates, we have carefully considered the position requirements. For example, our initial requirements for technical writers included:
-
understanding and practical experience with the "docs-as-code" methodology;
-
readiness for in-depth study of the product;
-
database familiarity;
-
experience or desire to work with Linux;
-
experience of working with Git;
-
readiness for self-testing documentation;
-
written English proficiency at or above С1.
This approach enabled us to build a team of highly skilled, independent technical writers who not only produce documentation in a consistent style but also deeply understand the technical aspects of the product they write about.
The very first version
Five months after the start of work, we have developed the first version of the portal, which you can see below.
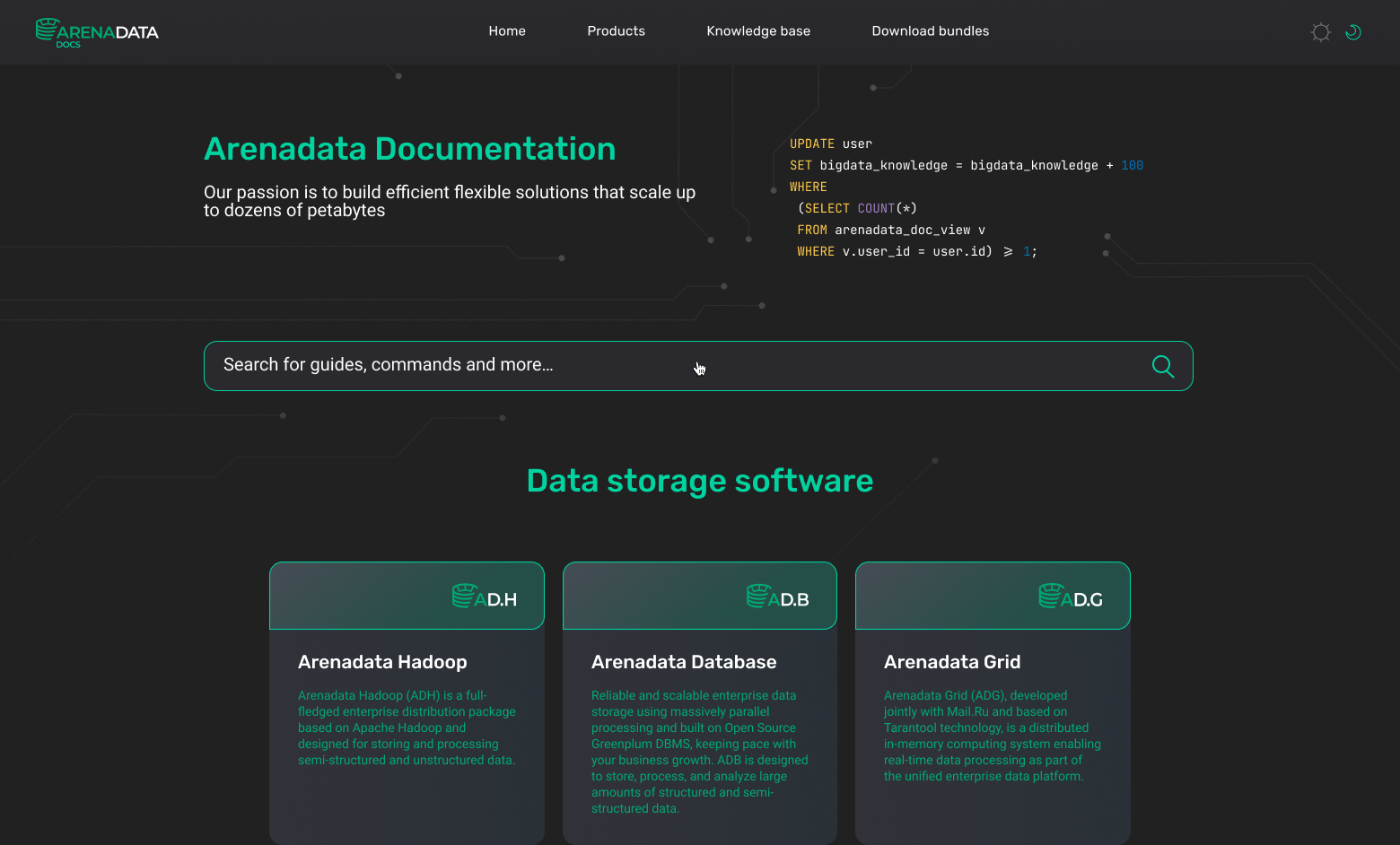
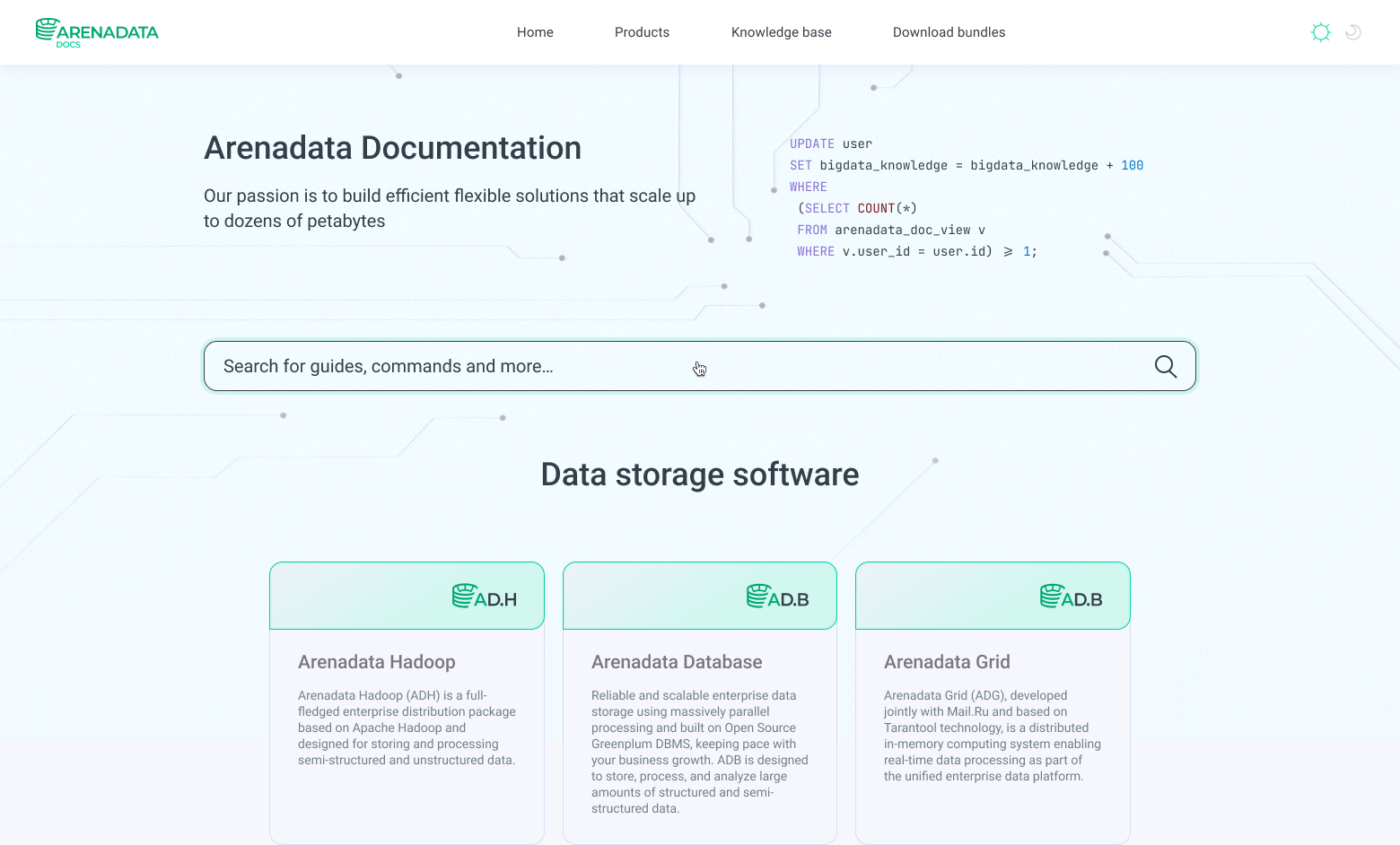
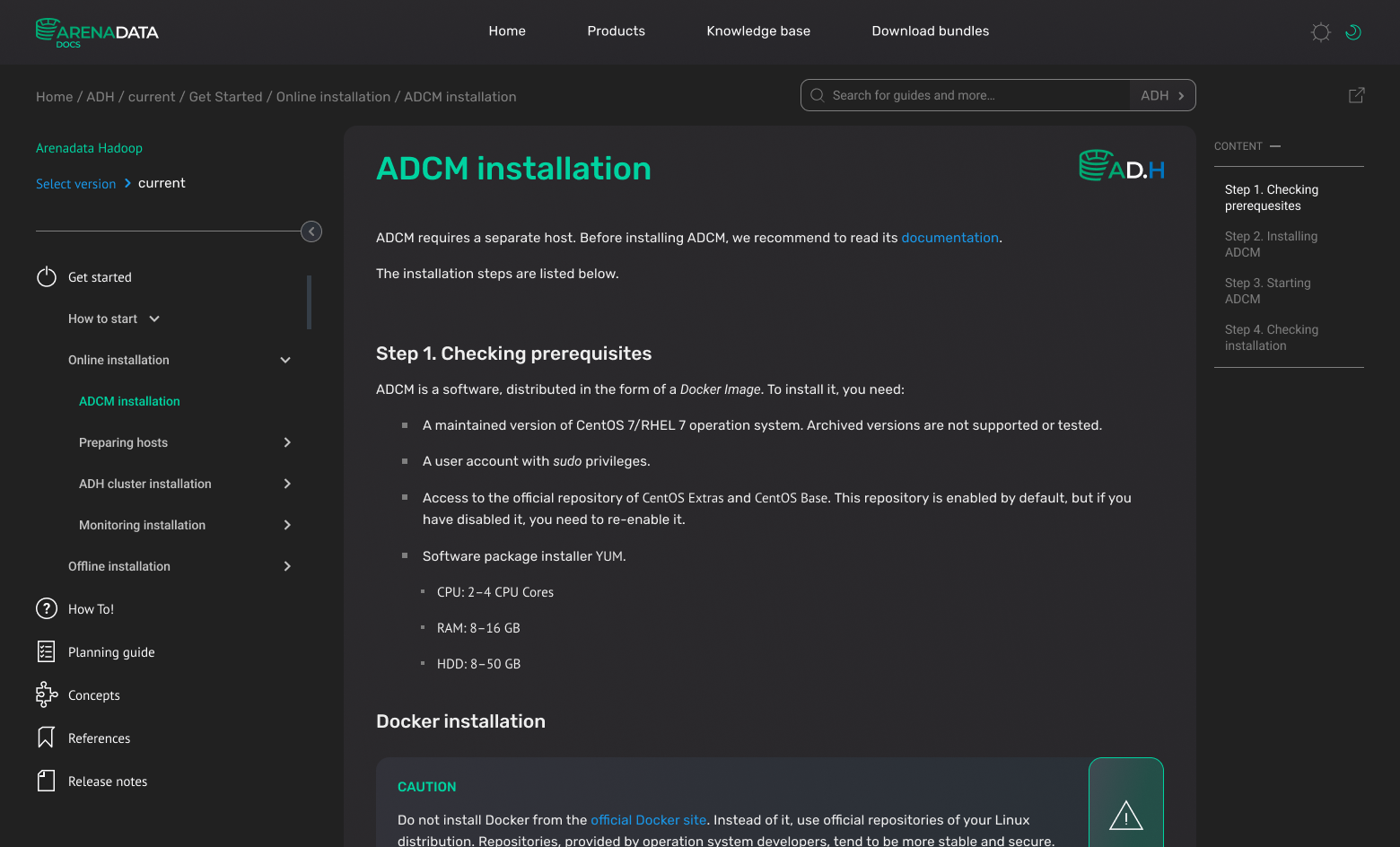
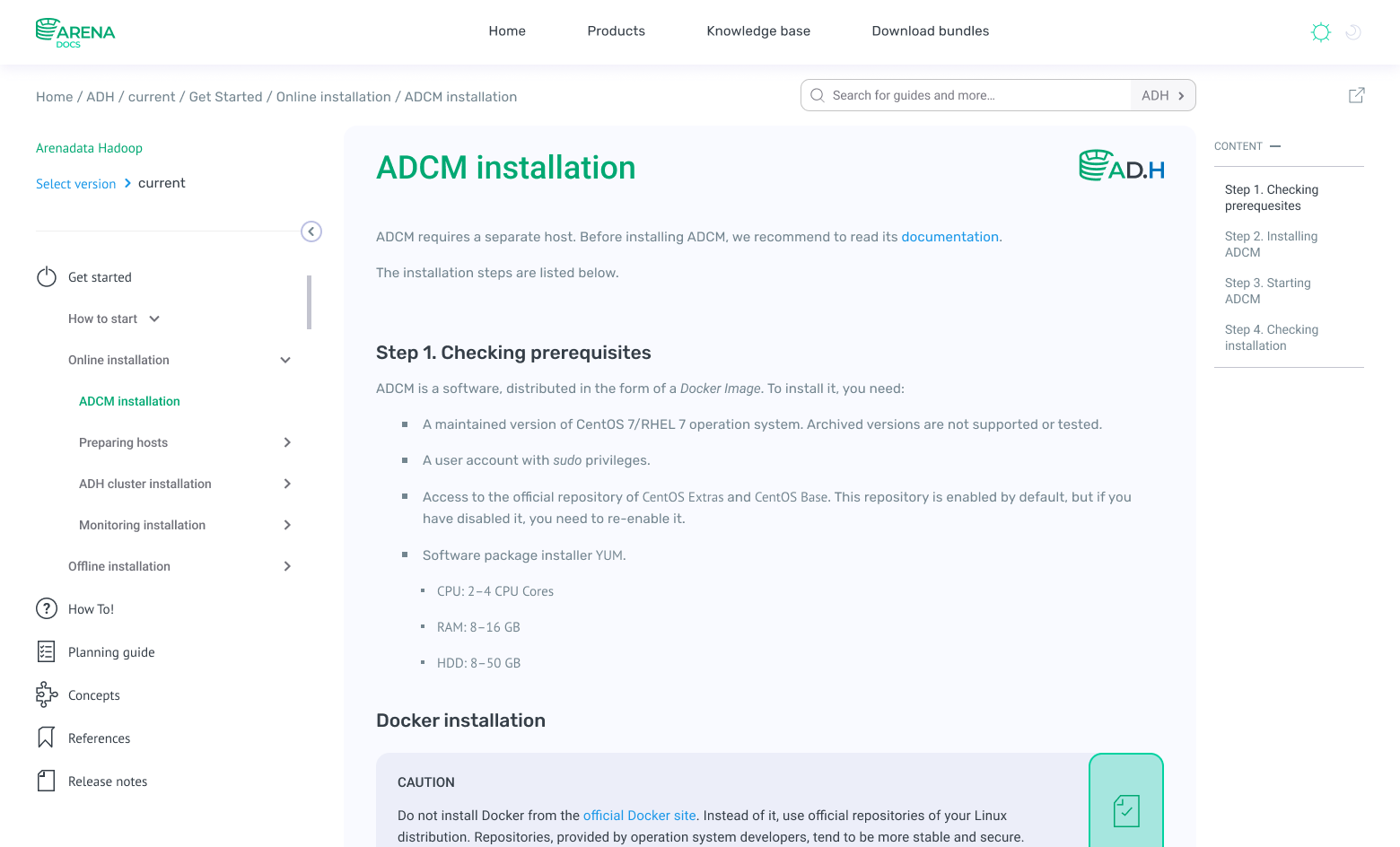
Changes since the first portal version
After a year of intensive work, we finally became close to the desired result and started to think about unique changes in our portal that would define our own direction of development. We decided to exclude standard product cards in favor of our new tabbed system. Although this work required a comprehensive redesign of the portal — which was challenging — it was made possible by the strong foundation laid over the past year. Each tab now provides detailed product information, including product description, usage scenarios, release map, features, competitor comparison, and more.
Our goal was to create the most useful portal for customers, so we removed unnecessary elements from the first version, including a large block about our social networks that took up space but offered little value.
For more comfortable reading, we changed the font style, increased the line spacing, and changed the background color in both schemes. We updated all UI elements used in documentation content, including: navigation menu; tables; collapsible blocks; and elements used for pagination.
We also added a section with information about the documentation releases (as mentioned above), created a technical blog for articles by our architects and developers, and significantly improved the internal search by adding filters for product version numbers and adjusting the search result sorting order.
We have gradually worked out the final process and mechanism for documentation releases. The team of technical writers expanded to nine, with each writer responsible for their own product. It’s worth noting that the number of JS developers working on the portal has remained the same.
Additionally, we expanded the team by adding an SEO specialist, which has significantly improved our operations. We can now track portal traffic and analyze which articles attract the most attention. Based on these statistics, we compile a TOP-10 list of articles for each product.
Final results and our team
The documentation portal is currently supported and developed by the following team:
-
Technical writers: 8, including the Head of TW.
-
DevOps: 1 Middle.
-
JavaScript developers: 1 Senior + 1 Junior.
-
UX/UI designer: 1 Senior + 1 Junior.
-
SEO: 1 Senior.
We encountered many opinions suggesting that a technical writer simply compiles information from a developer or architect. However, that’s not true in our department, and we’re proud to have debunked this myth — at least within our company. So we don’t stop searching for candidates for weeks. The quality is more valuable than the quantity, so we are very careful about the selection: we always ask for bilingual work examples and give a test task to check ability to work with markup languages. The process is not easy, but the results are worth it.
Of course, our responsibility toward our technical writers is also great. We should offer them attractive working conditions, efficient processes, opportunities for development, and various benefits and bonuses. We understand that the high demands we place on our employees also set high expectations for us as a company. It is therefore extremely important for us to demonstrate our achievements and results through the documentation portal and to ensure transparent and efficient work processes. You may have noticed that the title of each article in our documentation includes the author name. We do this intentionally to emphasize the author’s individuality and to show employees that their work is recognized and appreciated. And no, we’re not worried about other companies poaching our writers 🙂
Next steps
-
PDF file generation. Despite the availability of a web-based version of the documentation, many of our customers — primarily from the financial sector — require PDF documents that can be used, for example, in the absence of Internet access. The task of PDF generation is not as simple as it may seem at first sight — due to the customization of AsciiDoc syntax structures used on our portal, as mentioned above. Currently, we are considering the Asciidoctor PDF converter, which allows us to expand its functionality by writing your own classes in Ruby. But we have not made the final decision yet.
-
Further SEO optimization improvements. The main reason we hired an SEO specialist is to improve the ranking of our articles in search engine results. It is significantly important for us that the documentation site is accessed not only through direct links by current clients but also by potential clients through keyword searches on Yandex and Google. We have set a rather ambitious goal: to have our articles rank higher in search engines than those of our competitors (incl. Open Source). Within 6 months after hiring an SEO, we have done a lot of work to achieve this goal: all new articles are written based on SEO recommendations, most of the existing articles were supplemented with meta tags, we implemented micro-markup, robots.txt, and more. We didn’t have to wait long for the results: every week we saw a significant increase in the number of visits to our site from search engines, and within six months the number of visits from search engines tripled.
However, we are not going to be complacent. We plan to boost traffic to all articles and focus on external optimization to improve the site’s ranking (Domain Rating, DR) through crowd and outreach link building.
Instead of conclusion
Thank you for your attention. We hope this article was helpful to you. In conclusion, we’d like to emphasize one important point: when developing a documentation portal from scratch — as well as any other product — the team plays an exceptional role. The results you now see on our documentation portal, were made possible only through the coordinated efforts and professionalism of our team: technical writers, UX/UI designers, developers, architects, technical managers, and SEO. We are truly proud of each one of them.
