How to speed up backup and save storage space: on the example of ArenadataDB ddboost and Dell EMC Data Domain

Hello everyone! My name is Andrey, I am a system architect at Arenadata. In this article, we will look at the integration of the gpbackup/gprestore logical backup and recovery utilities with the Dell EMC Data Domain software and hardware solution — a task, on which our development team worked in 2022.
The result of this development was a connector plugin for the native use of this data storage system in tasks of data backup and recovery. Since December 2022, we are delivering it in the Enterprise Edition of our Arenadata DB product.
Logical vs physical backup
Approaches for implementing database backup can be divided into logical and physical backup. With a logical backup, a database state is represented as a set of DDL/DML commands that can be used to restore this state. With a physical backup, the process operates with a physical representation of data — as it is stored in a database (data files, indexes, WAL logs, etc.).
Logical backup with all its advantages (including the possibility of recovery to a cluster with a different topology and (or) a different version of the DBMS, flexible settings for filtering by schemes and tables, and other useful features) is generally slower than the physical backup implementation. It also places great demands on free space in data storage systems as the representation should be converted to text format. The option of using COPY FROM SEGMENT (as an example) in combination with a binary data transfer format is outside the scope of this article.
However, the impact of these disadvantages can be partially mitigated by the use of specialized software and hardware solutions that offer the possibility of deduplication (i.e. they can recognize and exclude repeated copies of data saving only unique blocks to disk). It can significantly save storage space and if the system supports on-the-fly deduplication, it also reduces traffic.
The Dell EMC Data Domain solution provides many useful features, including support for encryption, compression, file replication, work over both TCP/IP and Fiber Channel (DD Boost-over-Fiber Channel Transport), support for HA and automatic failover. A detailed description can be found on the relevant resources.
For our task, it is important that the system supports on-the-fly data deduplication. The DD Boost library provides this functionality. The library increases the performance of the backup process by using the ability to discard a duplicate block on the client side, without transferring it to the server. In this case, the transferred blocks are stored in the storage system regardless of whether the backup was completed successfully or not, which again saves time when re-backing up in case of an error.
Let’s look at this process in more detail.
DD Boost: data deduplication
The image below shows a general diagram of the data flow when writing data to a data storage system.
The incoming flow (1) is divided into separate blocks (2). These blocks are mapped (3) to a set of data (fingerprint), which allows determining the presence of this block in the storage system (4). Then, if a decision to send a block is made, it is compressed (5), sent to the storage system (6), and written to the device (7).


Solution architecture
The architecture of our solution assumes the presence of a connector plugin that uses the DD Boost SDK. The connector plugin is built into the backup and restore process. The gpbackup and gprestore specialized utilities are responsible for these processes.
The following image shows the general scheme of calls when performing a backup operation.


In the general scheme of the components' work, gpbackup is responsible to:
-
prepare (1) service files with metadata, offset files, configuration files, final report, etc.;
-
prepare for backup (2) table data with the
COPY FROM SEGMENToperation; -
launch the plugin process(es) (3) with subsequent transfer of the full path to the copied file or table data as a byte stream to the plugin process. The same full path to the file will be used for recovery with the gprestore utility.
The plugin tasks include:
-
prepare the storage system (4) to perform the backup task (check the availability of the storage system, create directories on the file system, etc.);
-
save (5) both individual files and a stream of table data to files of the storage system while a backup task is running.
The DD Boost library takes over the process of deduplication, compression, and transfer of data to the storage system.
Load tests
Load tests were performed according to the following plan:
-
Identify the target performance metrics of the solution using the tools/utilities the vendor offers (synthetic bandwidth test).
-
Perform isolated tests of the plugin to determine "pure" performance, without the potential influence of the gpbackup and gprestore utilities, with different numbers of connections (threads) from one or multiple servers (synthetic isolated tests of the plugin).
-
Perform final tests of the plugin as a part of gpbackup and gprestore with various options (final tests of the plugin as a part of gpbackup and gprestore).
Synthetic bandwidth test
To obtain target metrics in the test environment, the ddpconnchk specialized utility was used. This utility allows performing a load test of the channel to the data storage system and, in fact, obtaining the expected speed of writing and reading data. The launch is parameterized by the number of threads that perform reading/writing, the final size of the data to be written, and a number of other parameters.
Several runs of this utility in the test environment allowed us to determine the target metrics of the write speed (see the table below).
| Number of threads | Average write speed, MB/sec |
|---|---|
1 |
204 |
5 |
1280 |
10 |
2560 |
20 |
3413 |
30 |
2560 |
The results of synthetic tests showed that the highest speed was achieved with a certain combination of parameters: a test file of 1 GB and 20 threads. With 30 threads, the speed is noticeably lower — at the level of 10 threads.
It is worth noting that this test, in terms of the write speed, does not present the picture that is typical for the process of transferring data with its deduplication. Also, in a real configuration, the speed can be limited from above by other subsystems, such as disk.
Thus, these metrics can be considered indicative for the case with a unique set of data in the absence of performance limitations of the client’s disk subsystem.
Synthetic isolated tests
An isolated test is a test transfer of data directly to the data storage system through the plugin without processing and transferring data from gpbackup (such as preparing table data and then transferring it through standard I/O to the plugin, etc.).
The idea of the test is to check "pure" performance without the potential impact of operations performed by the gpbackup utility. The test stream for this test is randomly generated binary data (the total amount of data to be written is 200 GB in one file or the same size but divided into separate parts). This data is routed to the plugin directly via standard I/O. gpbackup and gprestore work with plugins in a similar way.
Several runs of this test allowed us to determine the following write speed metrics.
| Number of threads | Average write speed, MB/sec |
|---|---|
1 |
150 |
10 |
1110 |
20 |
1100 |
One server — one thread
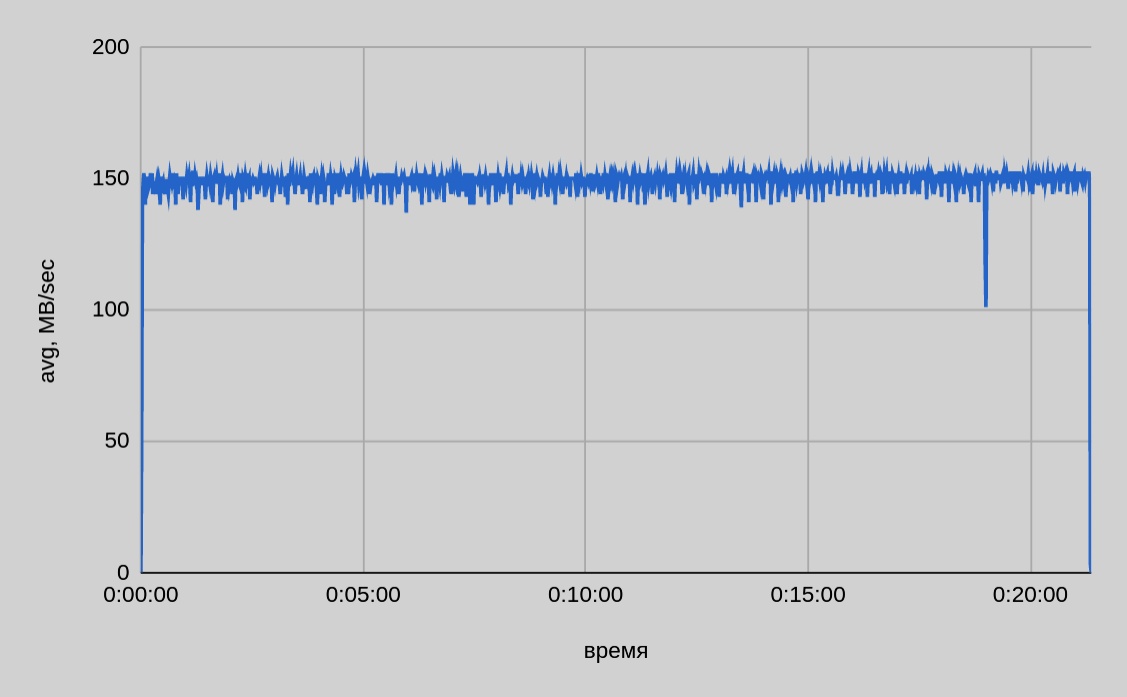

The average speed of writing to one thread is ~150 MB/sec, the total time of transferring 200 GB is ~22 minutes.
One server — ten threads
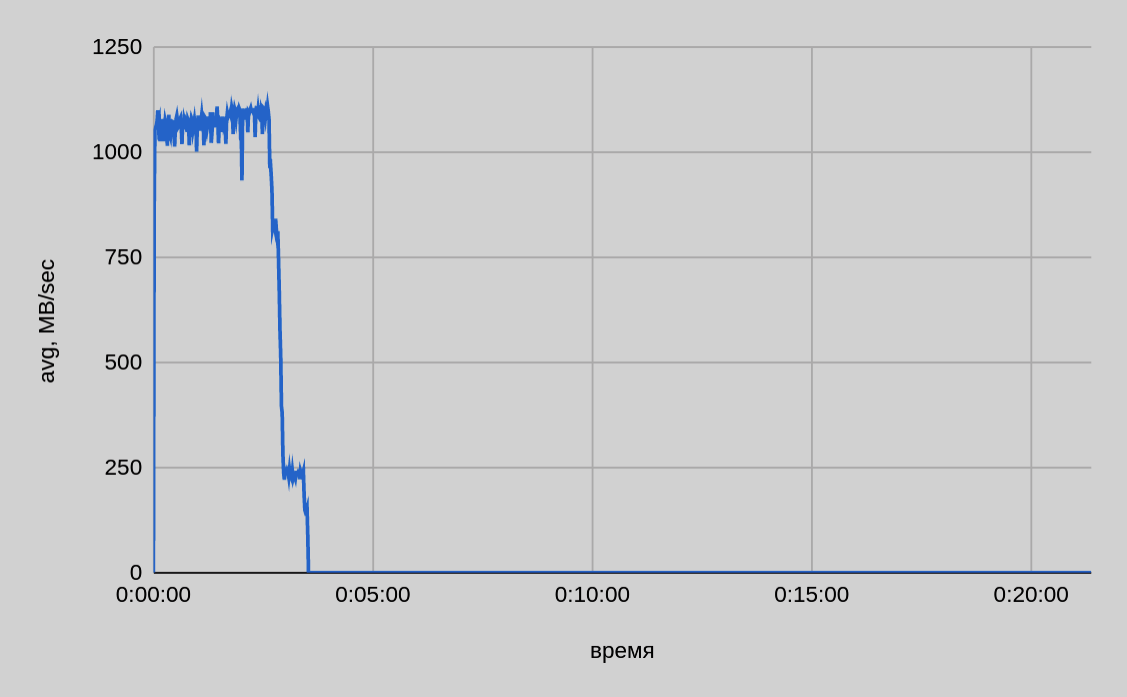
From the graph above, we can see that when ten files were transferred in parallel from one host, the speed was on average slightly above 1 GB/sec and it decreased as individual parts were sent. The total time of transferring 200 GB was ~3.5 minutes.
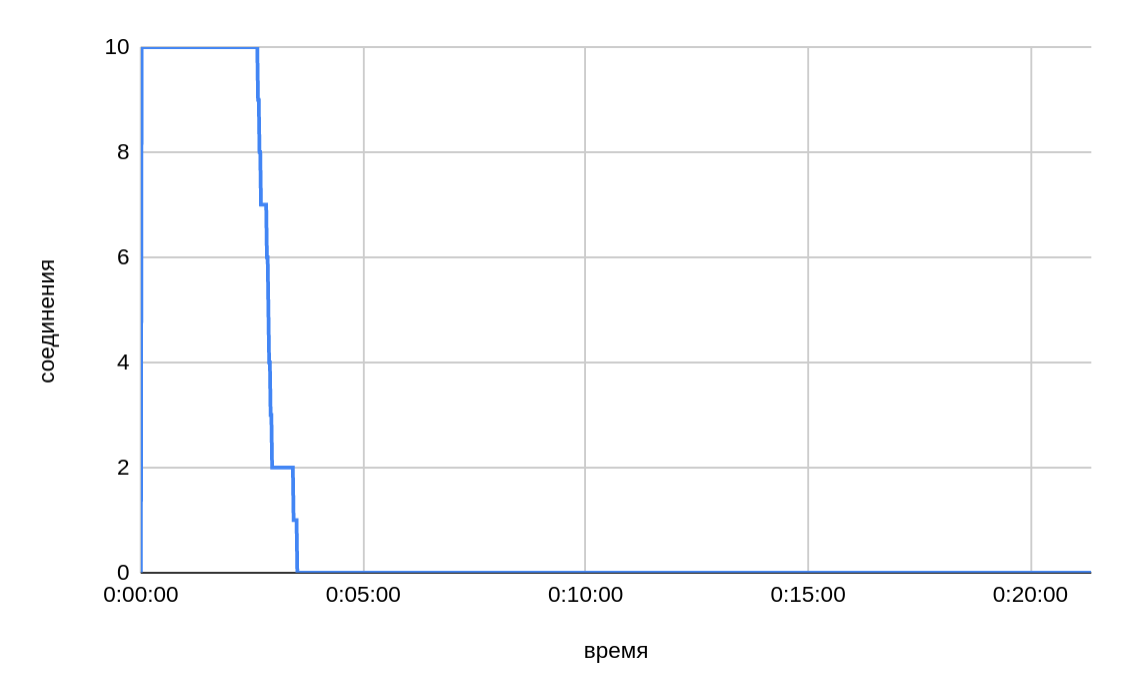
In general, as sending of individual parts completes, the drop in the overall speed of sending is slightly greater than one connection in a single test provided. For example — for two files, one would expect a speed of about 300 MB/sec, but in fact we see ~235 MB/sec. Perhaps this is due to the internal thread pool of the DD Boost library and how bandwidth is shared between threads within the library.
One server — twenty threads
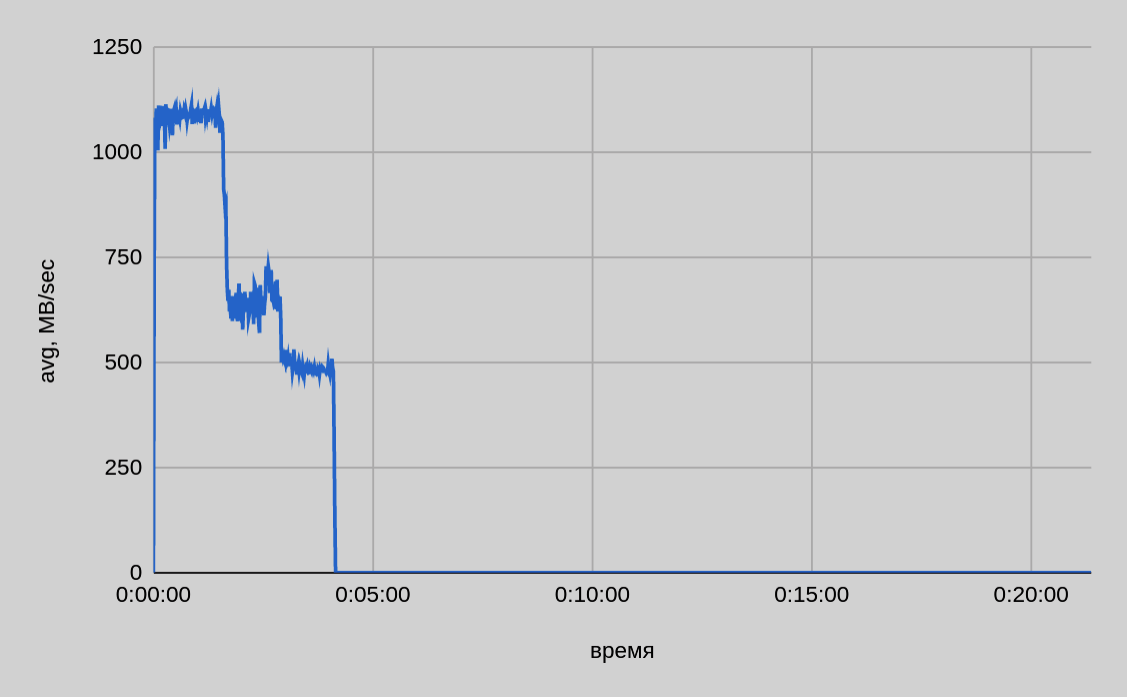
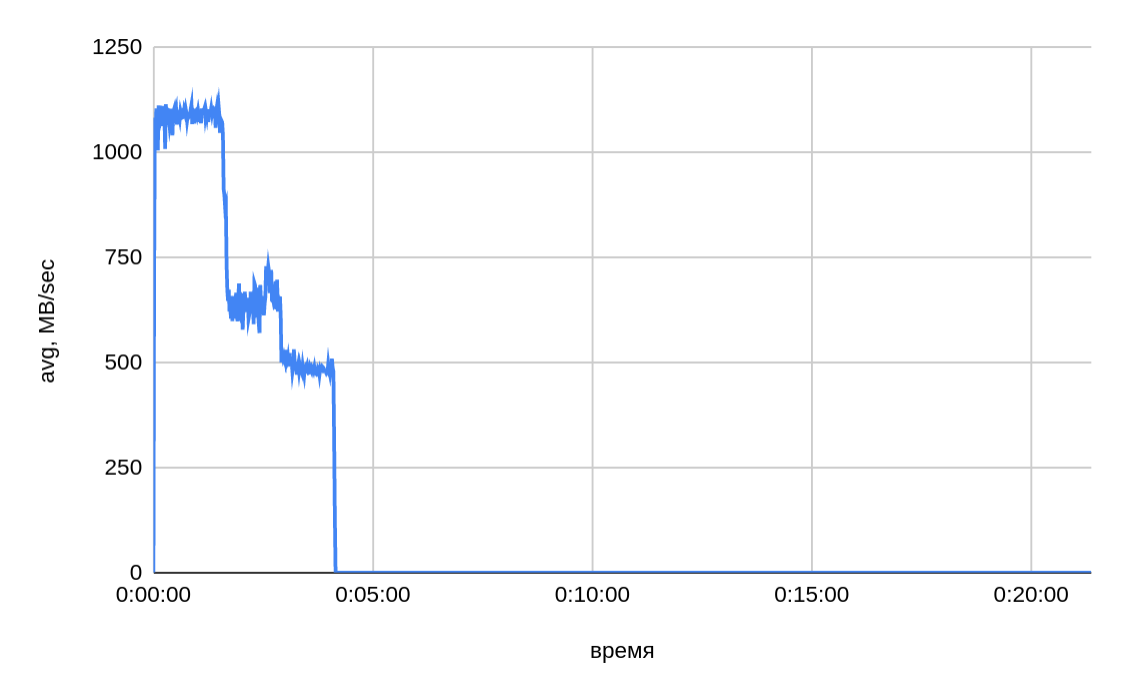
From the graph above, we can see that when transferring twenty files in parallel, the total time is even slightly longer than it was with ten threads.
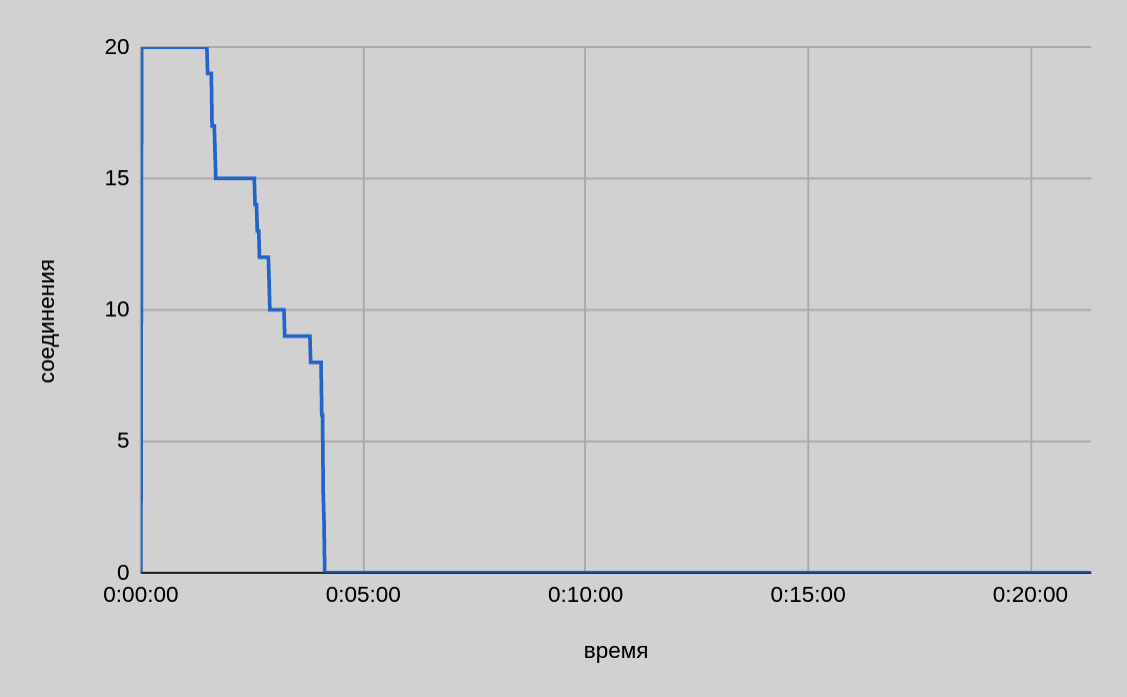
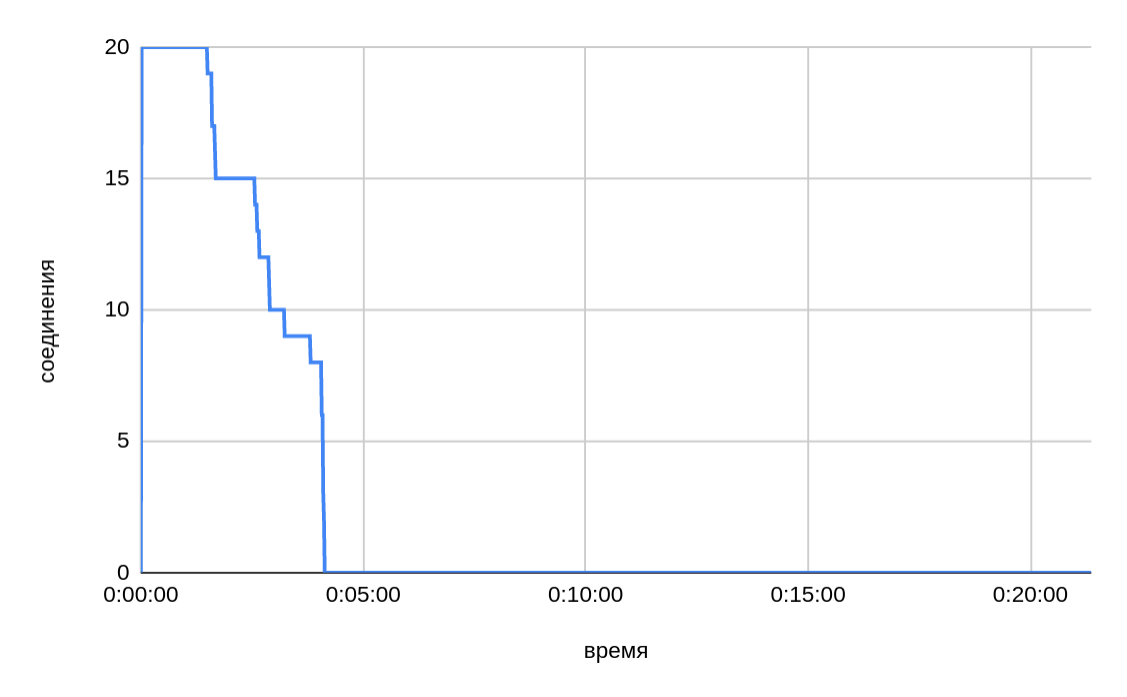
As the speed slows down at the end, the issue of sharing bandwidth between open connections is also relevant. As sending individual parts of a file is completed and connections are released, one would expect to have the same speed for ten active connections (out of twenty at the start) as for ten ones. However, as graphs show, the drop in speed was proportional to the initial pool of active connections.
| Host | Average, MB/sec | Average, MB/sec | Average, MB/sec |
|---|---|---|---|
host1 |
1096 |
552 |
278 |
host2 |
998 |
556 |
279 |
host3 |
— |
552 |
278 |
host4 |
— |
548 |
279 |
host5 |
— |
— |
280 |
host6 |
— |
— |
279 |
host7 |
— |
— |
278 |
host8 |
— |
— |
280 |
2040 |
2160 |
2180 |
The write speed generally matches the speed to ten threads from one server that we saw in the results of previous tests (~1.1 GB/sec). On average, we received ~2 GB/sec for writing from two servers.
The total speed of 2.2 GB/sec is slightly higher than the speed for twenty connections from two servers, but it is already possible to assume that, starting with four servers, the maximum for writing from the storage and deduplication system is visible. The speed in peaks approximately corresponds to the maximum that is achieved from 1-2 servers, but on average it can be seen that the bandwidth is already shared between all forty connections from four servers — ~550 MB/sec per server.
A further drop in the write speed from one server with a similar overall write speed (2.2 GB/sec) indirectly confirms the hypothesis about the maximum write speed on the part of the storage and deduplication system. This hypothesis is confirmed by the fact that synthetic tests by the ddpconnchk utility with similar parameters (30 connections/threads) showed a generally similar result in terms of maximum write speed (2560.00 MB/sec).
Thus, we can conclude that the practical maximum achieved in isolated tests in a configuration with eight servers is comparable to the results of synthetic bandwidth tests.
|
NOTE
A separate series of tests of the disk subsystem showed that it was the disk subsystem performance that limited the speed of the read operation to ~1.1 GB/sec within a single host. |
Final tests of the plugin as a part of gpbackup and gprestore
For a series of final tests, the test environment configuration was the following:
-
Amount of data: 3.1 TB; 2 TB; 0.6 TB.
-
Number of tables in a database: 31200 (5% of tables are >= 500 MB in size; 28% — empty tables; size of remaining tables — < 500 MB).
-
Number of servers in a cluster: 22 segment hosts + 2 master/standby.
A series of performance tests included:
-
Test of full backup in a mode of copying in parallel (jobs) to formatted Dell EMC Data Domain.
-
Test of repeated full backup in a mode of copying in parallel (jobs) to Dell EMC Data Domain with data from the previous backup.
-
Test of full backup in a mode of copying a single file for all tables in a segment (single-data-file) to formatted Dell EMC Data Domain.
-
Repeated test of full backup in a mode of copying a single file for all tables in a segment (single-data-file) to Dell EMC Data Domain with data from the previous backup.
-
Test of backing up large tables (~1500 tables, total amount — ~2 TB) to formatted Dell EMC Data Domain.
-
Repeated test of backing up large tables (~1500 tables, total amount — ~2 TB) to Dell EMC Data Domain with data from the previous backup.
-
Test of backing up small tables (~20800 tables, total amount — ~0.6 TB) to formatted Dell EMC Data Domain.
| Test № | single-data-file | jobs count | copy-queue-size | Initial amount of data in a table* | Total backup time, minutes | Estimated average backup speed, MB/sec** |
|---|---|---|---|---|---|---|
1 |
— |
15 |
— |
3 TB |
720 |
72 |
2 |
— |
15 |
— |
3 TB |
630 |
82 |
3 |
+ |
— |
20 |
3 TB |
58 |
889 |
4 |
+ |
— |
20 |
3 TB |
38 |
1334 |
5 |
+ |
— |
20 |
2 TB |
13 |
2640 |
6 |
+ |
— |
20 |
2 TB |
2 |
14186 |
7 |
+ |
— |
20 |
0.6 TB |
33 |
300 |
* The amount of data actually transferred is 30-40% larger due to the need to convert to CSV format.
** The estimated speed was calculated based on the original size of the database, not data being actually copied.
We also performed several reference tests of backup to a local file system using the plugin (8) and without it (9), as well as a series of tests of local backups (10-17) with different settings of the queue length to prepare tables for backup (copy-queue-size).
| Test № | single-data-file | jobs count | copy-queue-size | Initial amount of data in a table | Total backup time, minutes | Estimated average backup speed, MB/sec |
|---|---|---|---|---|---|---|
8 |
— |
15 |
— |
3 TB |
14 |
3829 |
9 |
— |
15 |
— |
3 TB |
15 |
3557 |
10 |
+ |
— |
60 |
3 TB |
35 |
1498 |
11 |
+ |
— |
50 |
3 TB |
35 |
1485 |
12 |
+ |
— |
40 |
3 TB |
30 |
1709 |
13 |
+ |
— |
30 |
3 TB |
36 |
1421 |
14 |
+ |
— |
25 |
3 TB |
37 |
1416 |
15 |
+ |
— |
20 |
3 TB |
38 |
1365 |
16 |
+ |
— |
10 |
3 TB |
39 |
1325 |
17 |
+ |
— |
5 |
3 TB |
46 |
1137 |
| Test № | single-data-file | jobs count | copy-queue-size | Initial amount of data in a table | Total backup time, minutes | Estimated average backup speed, MB/sec |
|---|---|---|---|---|---|---|
18 |
+ |
— |
5 |
2 TB |
47 |
715 |
Conclusions from the performed tests:
-
Parallel copying table data with the jobs option is much slower and not recommended for use. We can assume that this is due to a significantly larger number of files being copied compared to the single-data-file option. Moreover, it is clear from tests (8) and (9) that the speed when copying to the local file system was two orders of magnitude higher. It is also worth noting the absence of visible overhead when copying through the plugin to the local file system — tests (8) and (9).
-
This storage system is better at copying large files (5). In fact, taking into account the results of synthetic ddpconnchk tests, such load profile takes up the entire available bandwidth (~2500 MB/sec with 30 threads). With small tables, the speed is an order of magnitude lower — (7).
-
The highest speed was obtained when copying large tables repeatedly — (6). This can be associated with the deduplication process, which is fully involved in this option.
The detail of the full DB backup test runs is of the greatest interest, since it reflects the scenario that is closest to reality with tables of different sizes.
The image below shows a graph of copying data by one of the segment hosts.
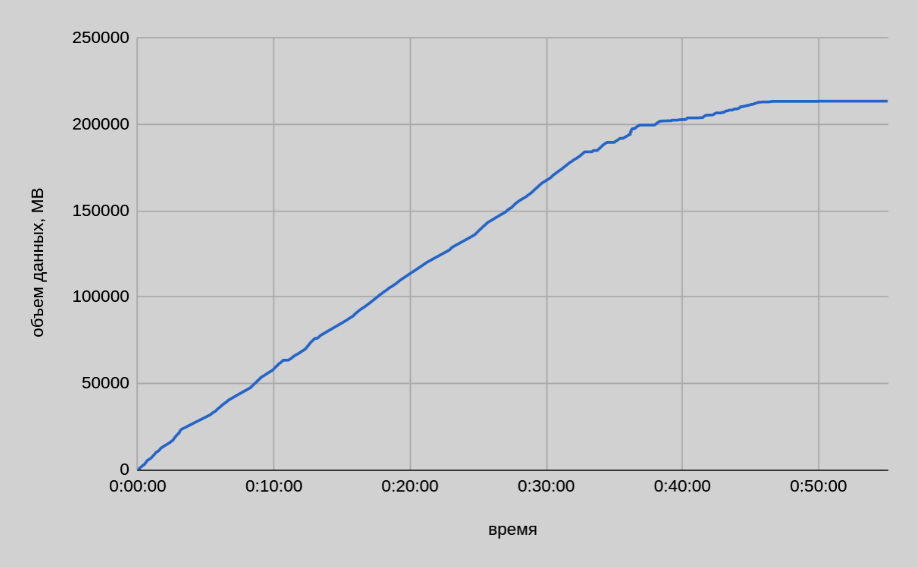
-
According to monitoring data, about the same amount of data was written from each segment host — ~213 GB. Thus, the actual size of transferred data from all 22 segment hosts was ~4.4 TB.
-
The graph confirms that copy speed depends on the size of the tables being copied: gpbackup creates backup copies in descending order by table size. In the first 30-35 minutes of backup, the average speed was ~140 MB/sec (from one host). In the remaining part, the average speed is ~40 MB/sec, which is indirectly confirmed by the small table backup test — (7). In general, copy speed varies widely. The following image shows a summary graph of copy speed.
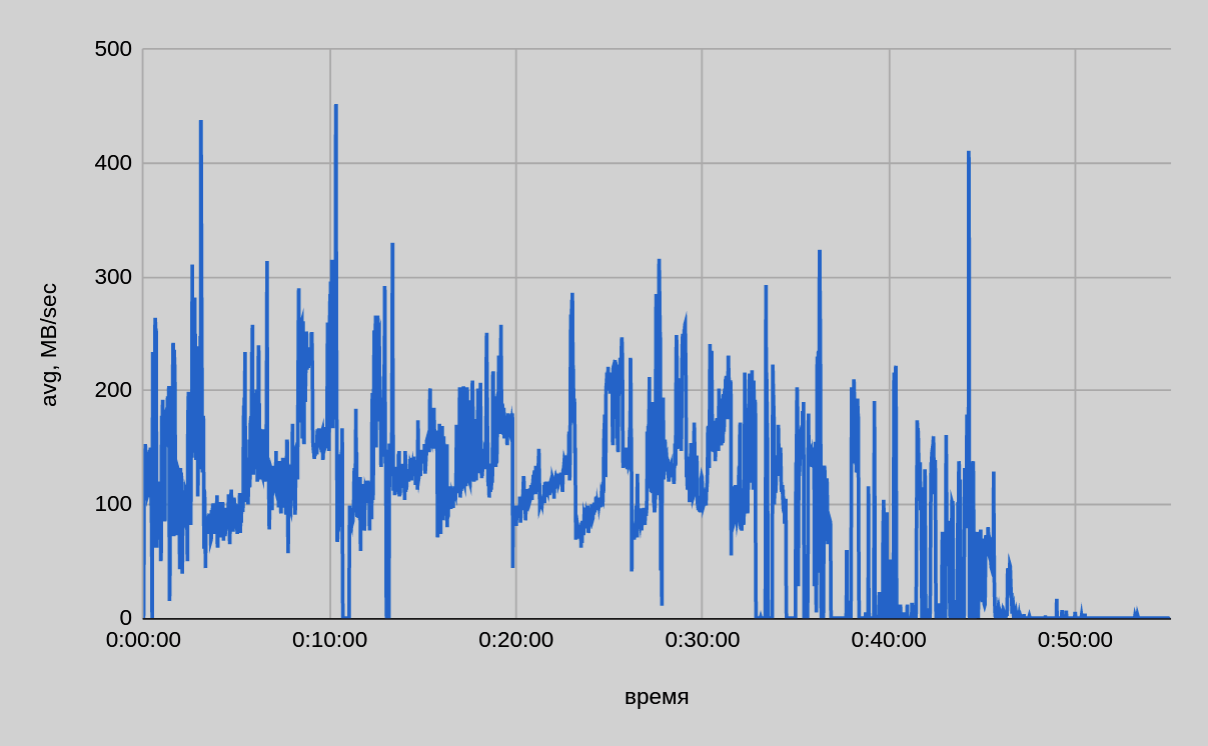
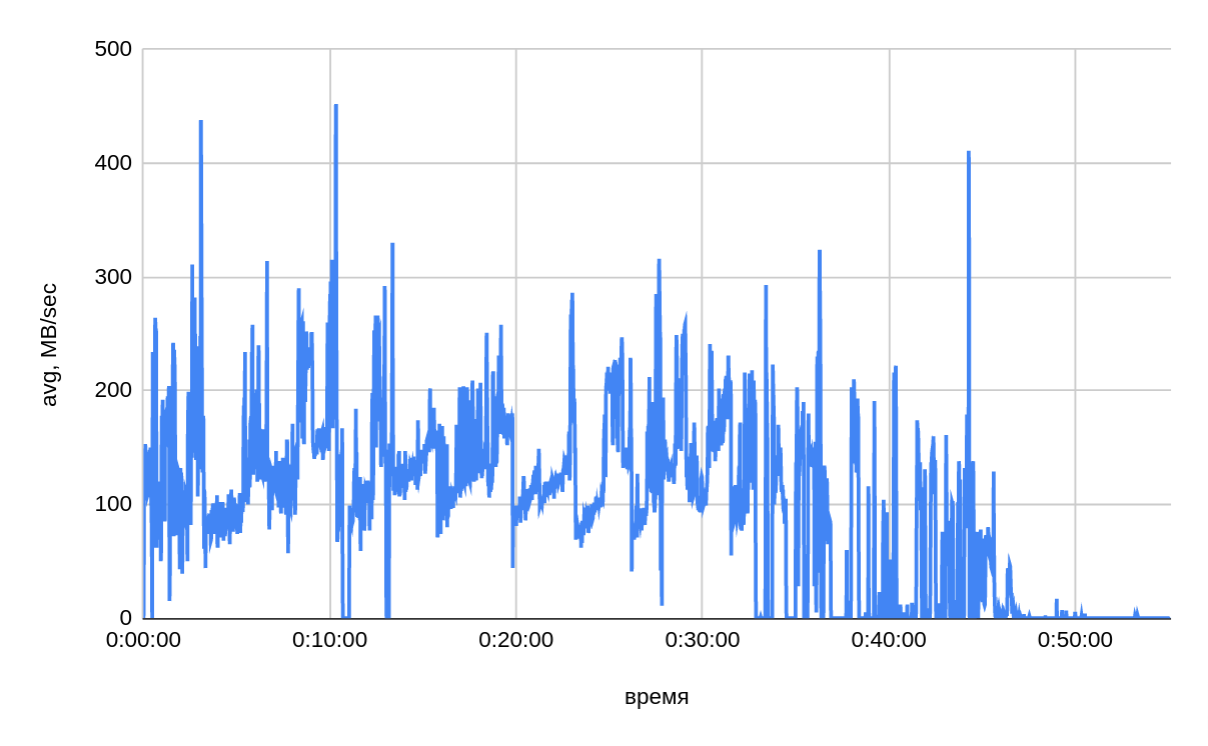
Conclusion
Testing results leads to the following conclusions:
-
Deduplication can significantly increase the speed of creating a database backup (up to five times faster in our tests).
-
A combination of gpbackup, DD Boost, and Dell EMC Data Domain shows better performance when using the copy mode "all tables on a segment — one file" (single-data-file). The parallel copy mode (jobs) is not recommended for use due to its extremely low performance of writing.
-
As a consequence of the previous point: performance is higher when writing large blocks of data (in the tests, tables over 500 MB per table were used). Perhaps this profile allows the storage system to perform data deduplication more efficiently (including on the fly) and also reduce the number of service operations for opening/closing files and managing connections.
-
Other subsystems may also limit the overall performance of the solution. You need to pay attention to all aspects during configuration, testing, and operation.