Как ускорить бэкап и сэкономить место на сторадже: на примере ArenadataDB ddboost и СХД Dell EMC Data Domain

Всем привет, меня зовут Андрей, я системный архитектор Arenadata, и в этой статье мы рассмотрим интеграцию решения логического резервного копирования и восстановления gpbackup/gprestore с программно-аппаратным комплексом Dell EMC Data Domain — задача, которой наша команда разработки занималась в 2022 году.
Итогом этой разработки стал плагин-коннектор для нативного использования этой системы хранения данных в задачах резервного копирования и восстановления данных. С декабря 2022 года мы поставляем его в Enterprise Edition нашего продукта Arenadata DB.
Логический VS физический бэкап
Варианты подхода к реализации резервного копирования БД можно разделить на логическое и физическое создание резервных копий. При логическом резервном копировании состояние БД представляется в виде набора DDL/DML-команд, которые можно применить для восстановления этого состояния. При физическом — процесс оперирует уже физическим представлением данных, как они сохраняются в БД (файлы данных, индексов, WAL-логов и др.).
Логическое резервное копирование при всех его плюсах, а это и возможность восстановления на кластер с другой топологией и (или) другой версией СУБД, гибкими настройками фильтрации по схемам и таблицам и другими полезными возможностями, как правило, медленнее физического варианта реализации. Также из-за необходимости преобразования в текстовый формат представления он предъявляет большие требования к свободному месту в системах хранения данных. Вариант с использованием, например, COPY FROM SEGMENT в комбинации с бинарным форматом передачи данных оставим за границами этой статьи.
Однако влияние этих минусов можно частично нивелировать использованием специализированных программно-аппаратных комплексов, которые предлагают возможность дедупликации, то есть распознавания и исключения повторяющихся копий данных с сохранением на диск только уникальных блоков. Это может значительно экономить объем пространства для хранения данных, а также, если система поддерживает дедупликацию "на лету", это уменьшает и трафик.
Решение Dell EMC Data Domain предоставляет много полезных возможностей, среди которых поддержка шифрования, сжатия, файловой репликации, работа как по TCP/IP, так и по Fibre Channel (DD Boost-over-Fibre Channel Transport), поддержка HA и автоматического failover. С подробным описанием можно ознакомиться на соответствующих ресурсах.
Для нашей же задачи важно, что система обеспечивает дедупликацию данных "на лету". Эта возможность предоставляется библиотекой DD Boost. Библиотека увеличивает производительность процесса резервного копирования за счет использования возможности откинуть дублирующийся блок уже на стороне клиента, не передавая его на сервер. При этом переданные блоки сохраняются в системе хранения вне зависимости от того, завершилось ли резервное копирование успешно или нет, что опять-таки экономит время при повторном резервном копировании в случае ошибки.
Рассмотрим этот процесс более подробно.
DD Boost: дедупликация данных
На рисунке ниже представлена общая схема потока данных при выполнении операции записи данных в систему хранения данных.
Входящий поток (1) разбивается на отдельные блоки (2), этим блокам сопоставляется (3) набор данных (отпечаток), который позволяет определить наличие этого сегмента в системе хранения (4), далее в случае принятия решения об отправке блока он сжимается (5), отправляется в систему хранения (6) и записывается на устройство (7).


Архитектура решения
Архитектура нашего решения предполагает наличие плагина-коннектора, использующего DD Boost SDK. Плагин-коннектор встраивается в процесс резервного копирования и восстановления. За эти процессы отвечают специализированные утилиты gpbackup и gprestore.
На следующем рисунке представлена общая схема вызовов при выполнении операции резервного копирования.


В общей схеме работы компонентов gpbackup отвечает за:
-
подготовку (1) служебных файлов с метаданными, файлов-смещений, файлов конфигурации, итогового отчета и др.;
-
подготовку к резервному копированию (2) данных таблиц с помощью операции
COPY FROM SEGMENT; -
запуск процесса(ов) плагина (3) с последующей передачей в процесс плагина либо полного пути копируемого файла, либо данных таблицы в виде потока байт. Этот же полный путь к файлу будет использоваться и для восстановления утилитой gprestore.
В задачи плагина входит:
-
подготовка системы хранения (4) к выполнению задачи резервного копирования (проверка доступности системы хранения, создание каталогов на файловой системе и тому подобное);
-
сохранение (5) как отдельных файлов, так и потока данных таблиц в файлах в системе хранения в процессе выполнения задачи резервного копирования.
Процесс дедупликации, сжатия и передачи данных в систему хранения библиотека DD Boost берет на себя.
Нагрузочные тесты
Нагрузочные тесты проводились согласно следующему плану:
-
Определить целевые показатели производительности решения теми средствами/утилитами, которые предлагаются вендором (синтетический тест пропускной способности канала).
-
Провести изолированные тесты плагина для определения "чистой" производительности, без потенциального влияния утилит gpbackup и gprestore с учетом разного количества соединений (потоков) с одного или нескольких серверов (синтетические изолированные тесты плагина).
-
Провести итоговые тесты плагина в составе gpbackup и gprestore с различными опциями (итоговые тесты плагина в составе gpbackup и gprestore).
Синтетический тест пропускной способности канала
Для получения целевых показателей на тестовой среде использовалась специализированная утилита ddpconnchk. Данная утилита позволяет провести нагрузочный тест канала до системы хранения данных и получить, по сути, ожидаемые показатели скорости записи и чтения данных. Запуск параметризуется числом потоков, осуществляющих чтение/запись, итоговым размером данных для записи и рядом других параметров.
Несколько запусков этой утилиты на тестовой среде позволили определить целевые показатели по скорости записи (см. таблицу ниже).
| Число потоков | Скорость записи в среднем, МБ/сек |
|---|---|
1 |
204 |
5 |
1280 |
10 |
2560 |
20 |
3413 |
30 |
2560 |
Результаты синтетических тестов показали, что наибольшая скорость достигалась при определенной комбинации параметров: тестовый файл в 1 ГБ и 20 потоков. В 30 потоков скорость уже ощутимо меньше — на уровне 10 потоков.
Стоит отметить, что данный тест с точки зрения скорости записи не отражает картину, которая характерна для процесса передачи данных с учетом их дедупликации. Также в реальной конфигурации скорость может быть ограничена сверху и другими подсистемами, например дисковой.
Таким образом, можно считать эти показатели ориентировочными для случая с уникальным набором данных при отсутствии ограничений производительности дисковой подсистемы клиента.
Синтетические изолированные тесты
Изолированный тест — это тестовая передача данных напрямую в систему хранения данных через плагин без обработки и передачи данных со стороны gpbackup (таких как подготовка данных таблиц с последующей передачей через стандартный ввод/вывод в плагин и тому подобное).
Идея теста заключается в проверке "чистой" производительности с исключением потенциального влияния операций, производимых утилитой gpbackup. Тестовый поток для данного теста представляет собой сгенерированные случайным образом двоичные данные (итоговый объем данных для записи — 200 ГБ одним файлом или разделенным на отдельные части, но таким же объемом). Эти данные перенаправляются напрямую через стандартный ввод/вывод в плагин. Схожим образом с плагинами работают gpbackup и gprestore.
Несколько запусков этого теста позволили определить следующие показатели скорости записи.
| Число потоков | Скорость записи в среднем, МБ/сек |
|---|---|
1 |
150 |
10 |
1110 |
20 |
1100 |
Один сервер — один поток
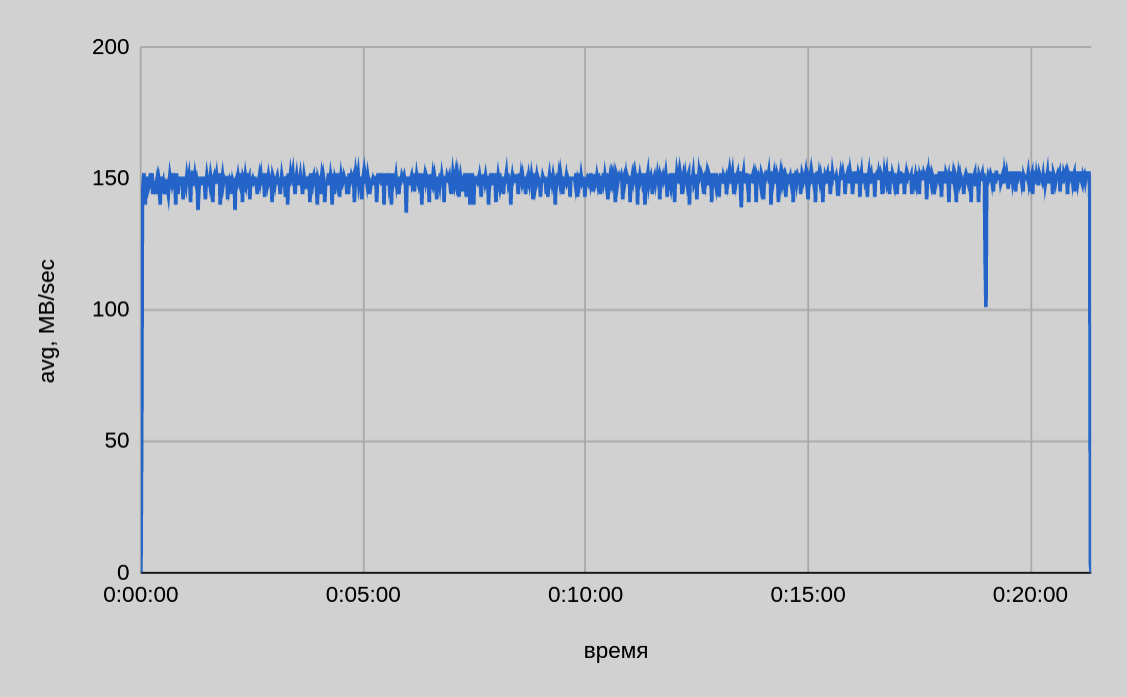
Показатель скорости записи в один поток в среднем составляет ~150 МБ/сек, итоговое время передачи 200 ГБ — ~22 минуты.
Один сервер — десять потоков
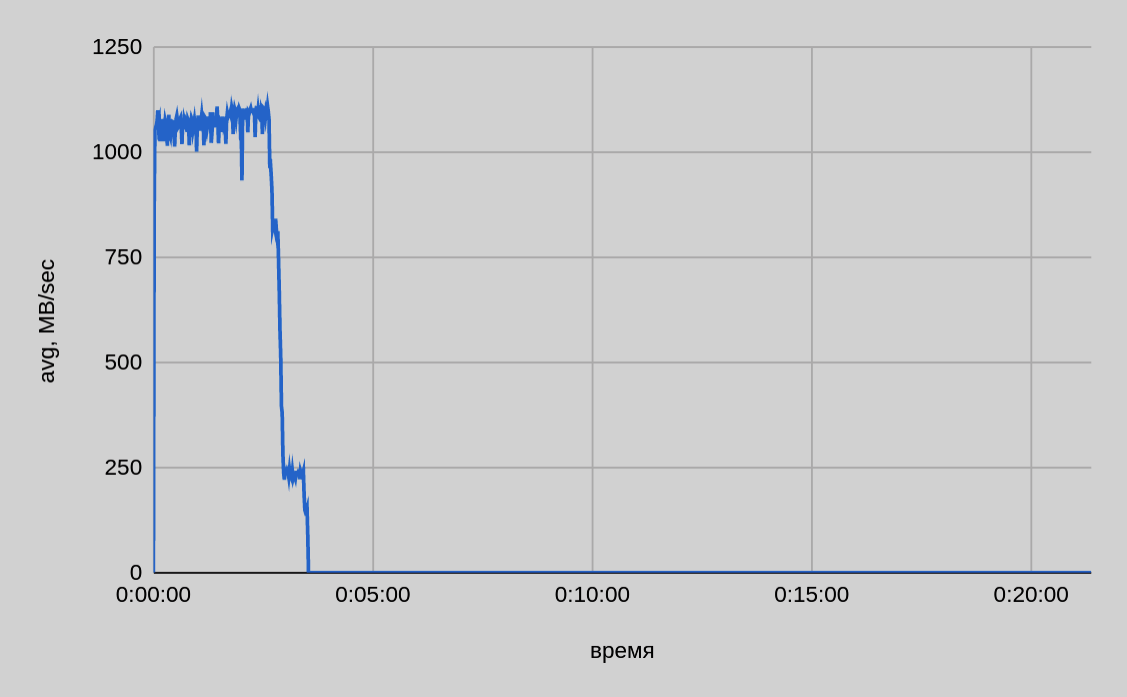
Из графика на приведенном выше рисунке видно, что при параллельной передаче с одного хоста десяти файлов скорость в среднем была чуть выше 1 ГБ/сек и по мере завершения отправки отдельных частей она снижалась. Итоговое время передачи 200 ГБ составило ~3.5 минуты.
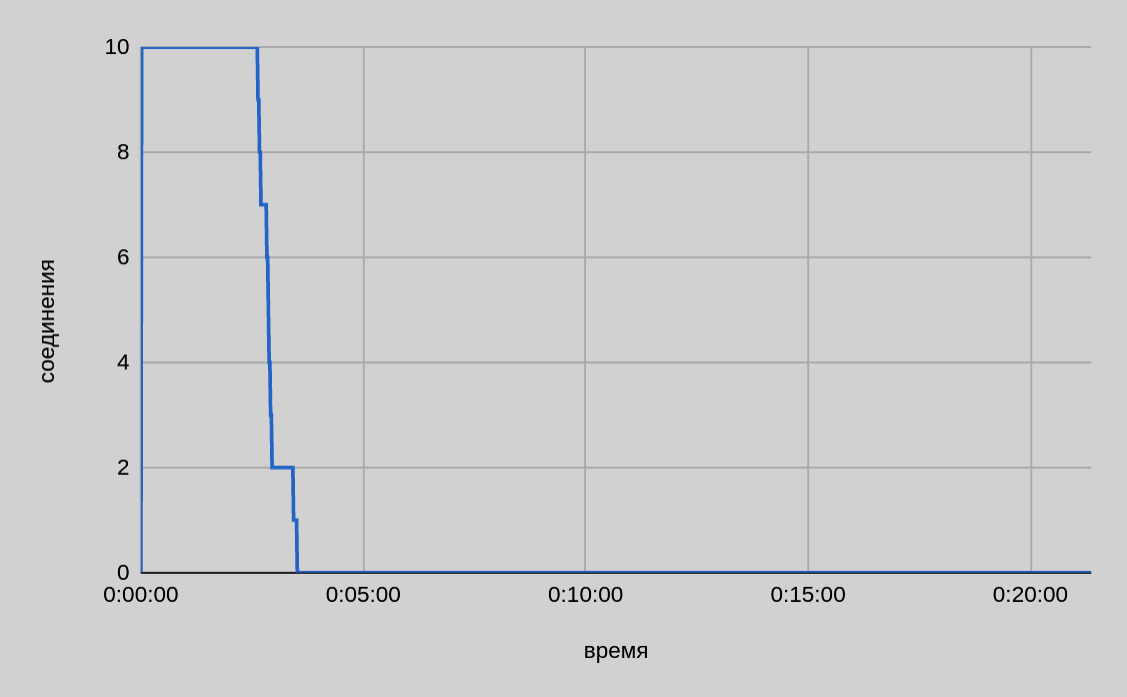
В целом по мере завершения отправки отдельных частей падение общей скорости отправки чуть больше, чем обеспечивало одно соединение в единичном тесте. Например, для двух файлов можно было бы ожидать скорость порядка 300 МБ/сек, по факту видим ~235 МБ/сек. Возможно, это связано с пулом внутренних потоков библиотеки DD Boost и тем, как происходит распределение полосы пропускания между потоками внутри библиотеки.
Один сервер — двадцать потоков
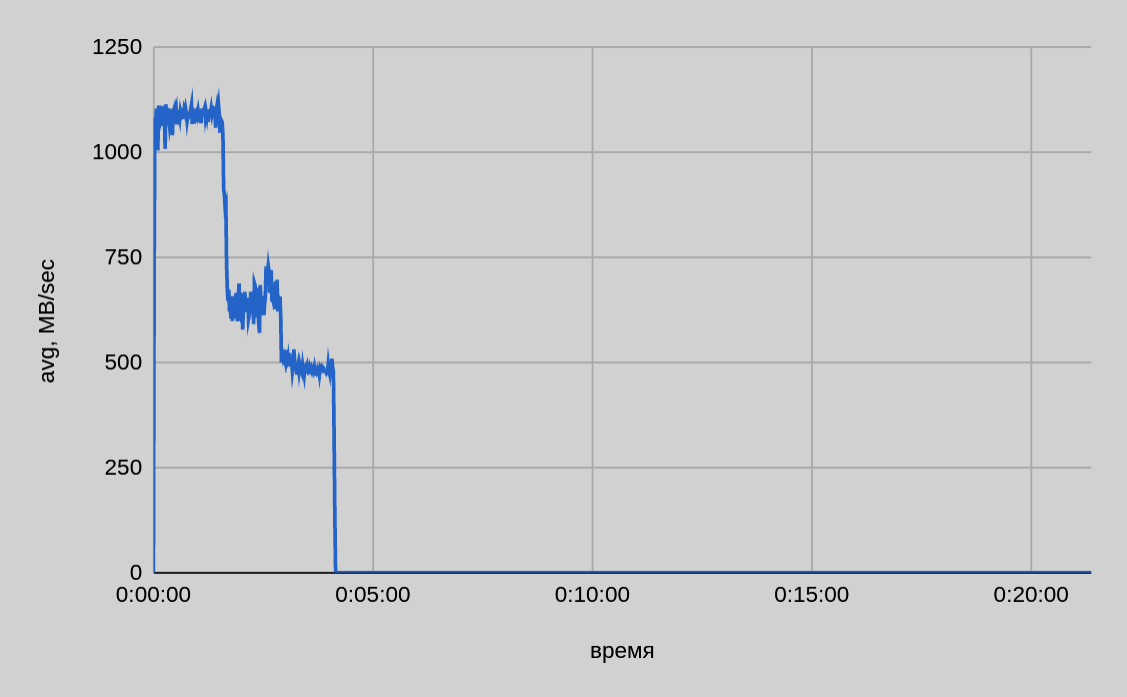
Из изображенного выше графика видно, что при параллельной передаче двадцати файлов общее время в итоге вышло даже чуть большим, чем было при десяти потоках.
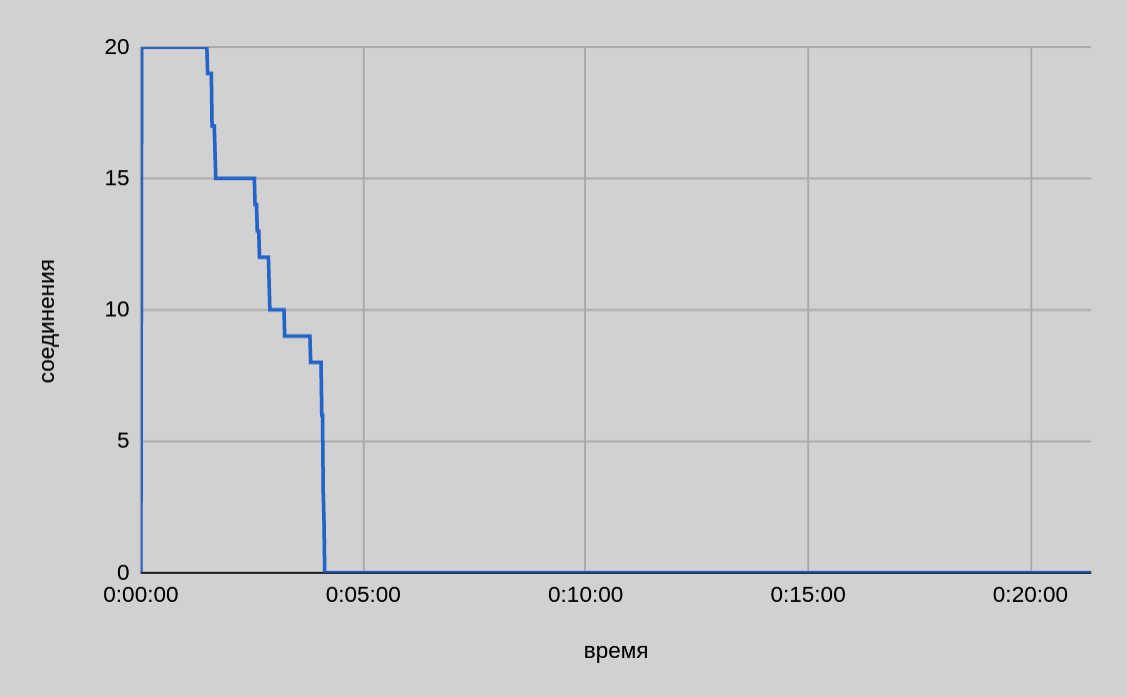
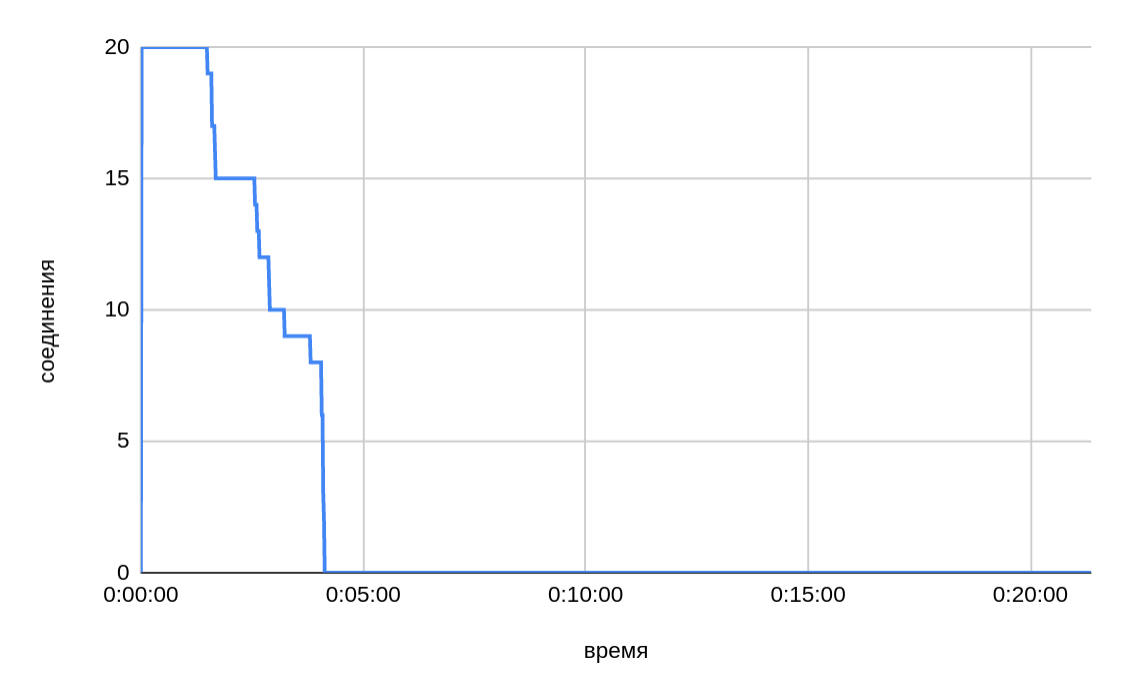
Судя по замедлению скорости в конце, также актуален вопрос разделения пропускной полосы между открытыми соединениями. По мере завершения отправки отдельных частей файла и высвобождения соединений можно было бы ожидать для десяти активных соединений (из двадцати на момент старта) такую же скорость, как и для десяти. Однако, судя по графикам, падение скорости было пропорционально начальному пулу активных соединений.
| Хост | В среднем, МБ/сек | В среднем, МБ/сек | В среднем, МБ/сек |
|---|---|---|---|
host1 |
1096 |
552 |
278 |
host2 |
998 |
556 |
279 |
host3 |
— |
552 |
278 |
host4 |
— |
548 |
279 |
host5 |
— |
— |
280 |
host6 |
— |
— |
279 |
host7 |
— |
— |
278 |
host8 |
— |
— |
280 |
2040 |
2160 |
2180 |
Скорость записи в целом совпадает со скоростью в десять потоков с одного сервера, которую мы увидели в результатах на предыдущих тестах (~1.1 ГБ/сек). С двух серверов в среднем получили ~2 ГБ/сек на запись.
Суммарное значение скорости 2.2 ГБ/сек чуть выше, чем на двадцати соединениях с двух серверов, но уже можно предположить, что, начиная с четырех серверов, виден максимум на запись со стороны системы хранения и дедупликации. Скорость в пиках примерно соответствует максимуму, который достигается с 1-2 серверов, но в среднем видно, что полоса пропускания уже разделяется между всеми сорока соединениями с четырех серверов — по ~550 МБ/сек с сервера.
Дальнейшее падение скорости на запись с одного сервера при аналогичной общей скорости на запись (2.2 ГБ/сек) косвенно подтверждает гипотезу о максимуме на запись со стороны системы хранения и дедупликации. В подтверждение этой гипотезы говорит тот факт, что на синтетических тестах утилитой ddpconnchk со схожими параметрами (30 соединений/потоков) получен в целом аналогичный результат по максимальной скорости на запись (2560.00 МБ/сек).
Таким образом, можно сделать вывод, что практический максимум, достигнутый в изолированных тестах в конфигурации с восемью серверами, сопоставим с результатами синтетических тестов пропускной способности канала.
|
ПРИМЕЧАНИЕ
Проведение отдельной серии тестов дисковой подсистемы показало, что именно производительность дисковой подсистемы ограничивала скорость операции чтения в ~1.1 ГБ/сек в рамках одного хоста. |
Итоговые тесты плагина в составе gpbackup и gprestore
Для серии итоговых тестов конфигурация тестового окружения была следующей:
-
Объем данных: 3.1 ТБ; 2 ТБ; 0.6 ТБ.
-
Число таблиц в базе данных: 31200 (5% таблиц размером >= 500 МБ; 28% — пустые таблицы; размер остальных таблиц < 500 МБ).
-
Число серверов в кластере: 22 сегмент-хоста + 2 мастер/standby.
Серия тестов производительности включала в себя:
-
Тест полного резервного копирования в режиме параллельного копирования (jobs) на очищенный Dell EMC Data Domain.
-
Тест повторного полного резервного копирования в режиме параллельного копирования (jobs) на Dell EMC Data Domain с данными от предыдущего резервного копирования.
-
Тест полного резервного копирования в режиме копирования одного файла для всех таблиц сегмента (single-data-file) на очищенный Dell EMC Data Domain.
-
Повторный тест полного резервного копирования в режиме копирования одного файла для всех таблиц сегмента (single-data-file) на Dell EMC Data Domain с данными от предыдущего резервного копирования.
-
Тест резервного копирования больших таблиц (~1500 таблиц, суммарный объем — ~2 ТБ) на очищенный Dell EMC Data Domain.
-
Повторный тест резервного копирования больших таблиц (~1500 таблиц, суммарный объем — ~2 ТБ) на Dell EMC Data Domain с данными от предыдущего резервного копирования.
-
Тест резервного копирования малых таблиц (~20800 таблиц, суммарный объем — ~0.6 ТБ) на очищенный Dell EMC Data Domain.
| № теста | single-data-file | jobs count | copy-queue-size | Исходный объем данных в таблице* | Полное время резервного копирования, минуты | Оценочная скорость резервного копирования в среднем, МБ/сек** |
|---|---|---|---|---|---|---|
1 |
— |
15 |
— |
3 ТБ |
720 |
72 |
2 |
— |
15 |
— |
3 ТБ |
630 |
82 |
3 |
+ |
— |
20 |
3 ТБ |
58 |
889 |
4 |
+ |
— |
20 |
3 ТБ |
38 |
1334 |
5 |
+ |
— |
20 |
2 ТБ |
13 |
2640 |
6 |
+ |
— |
20 |
2 ТБ |
2 |
14186 |
7 |
+ |
— |
20 |
0.6 ТБ |
33 |
300 |
* Объем фактически передаваемых данных на 30-40% больше из-за необходимости преобразования в CSV-формат.
** Оценочная скорость рассчитывалась на базе исходного размера БД, а не фактически копируемых данных.
Также были проведены несколько референсных тестов резервного копирования на локальную файловую систему с использованием плагина (8) и без (9), а также серия тестов локальных бэкапов (10-17) с различными настройками длины очереди подготовки таблиц к резервному копированию (copy-queue-size).
| № теста | single-data-file | jobs count | copy-queue-size | Исходный объем данных в таблице | Полное время резервного копирования, минуты | Оценочная скорость резервного копирования в среднем, МБ/сек |
|---|---|---|---|---|---|---|
8 |
— |
15 |
— |
3 ТБ |
14 |
3829 |
9 |
— |
15 |
— |
3 ТБ |
15 |
3557 |
10 |
+ |
— |
60 |
3 ТБ |
35 |
1498 |
11 |
+ |
— |
50 |
3 ТБ |
35 |
1485 |
12 |
+ |
— |
40 |
3 ТБ |
30 |
1709 |
13 |
+ |
— |
30 |
3 ТБ |
36 |
1421 |
14 |
+ |
— |
25 |
3 ТБ |
37 |
1416 |
15 |
+ |
— |
20 |
3 ТБ |
38 |
1365 |
16 |
+ |
— |
10 |
3 ТБ |
39 |
1325 |
17 |
+ |
— |
5 |
3 ТБ |
46 |
1137 |
| № теста | single-data-file | jobs count | copy-queue-size | Исходный объем данных в таблице | Полное время восстановления, минуты | Оценочная скорость восстановления в среднем, МБ/сек |
|---|---|---|---|---|---|---|
18 |
+ |
— |
5 |
2 ТБ |
47 |
715 |
Выводы по проведенным тестам:
-
Вариант параллельного копирования данных таблиц с опцией jobs фактически несовместим с данной системой хранения и не рекомендуется к использованию. Можно предположить, что это связано с существенно большим числом копируемых файлов по сравнению с опцией single-data-file. При этом из тестов (8) и (9) видно, что скорость при копировании на локальную файловую систему была на два порядка выше. Также стоит отметить отсутствие видимых накладных расходов при копировании через плагин в локальную файловую систему — тесты (8) и (9).
-
Данная система хранения лучше справляется с копированием больших файлов (5). Фактически с учетом результатов синтетических тестов ddpconnchk подобный профиль нагрузки занимает всю доступную полосу пропускания (~2500 МБ/сек при 30 потоках). С небольшими таблицами скорость на порядок ниже — (7).
-
Наибольшая скорость получена при повторном копировании больших таблиц — (6). Это можно связать с процессом дедупликации, который в этом варианте задействован на полную.
Детализация прогонов полного теста резервного копирования БД представляет наибольший интерес, так как она отражает наиболее близкий к реальности сценарий с различными по размеру таблицами.
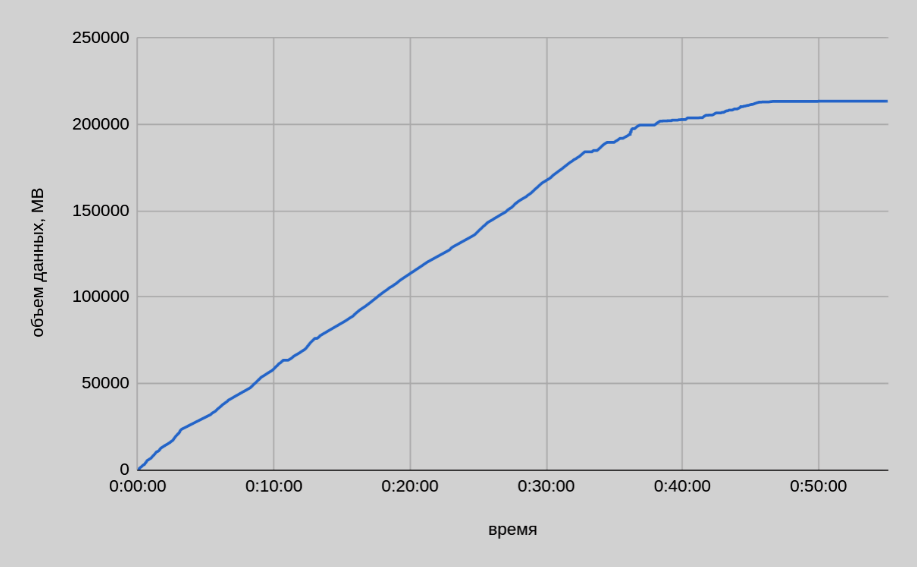
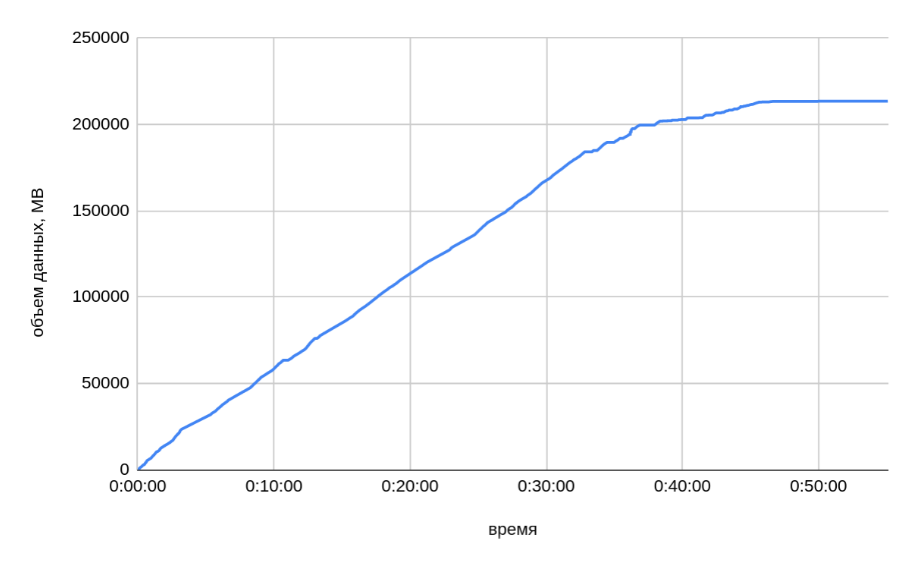
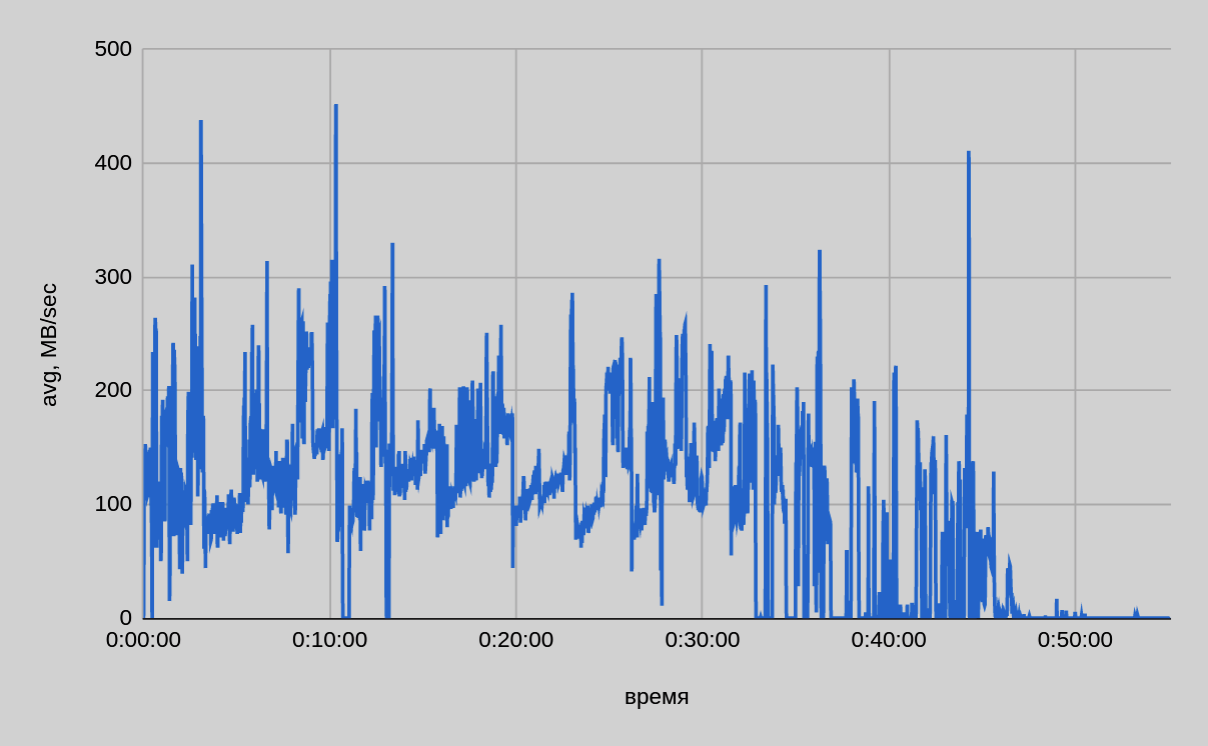
На рисунке ниже представлен график копирования данных одним из сегмент-хостов.
-
По данным мониторинга с каждого сегмент-хоста было записано примерно одинаковое количество данных — ~213 ГБ. Таким образом, реальный размер передаваемых данных со всех 22 сегмент-хостов составил ~4.4 ТБ.
-
По графику подтверждается, что скорость копирования зависит от размера копируемых таблиц: gpbackup создает резервные копии в порядке убывания по размеру таблиц. В первые 30-35 минут резервного копирования средняя скорость составляла ~140 МБ/сек (с одного хоста). В оставшейся части скорость в среднем составляет ~40 МБ/сек, что косвенно подтверждается тестом резервного копирования малых таблиц — (7). В целом скорость копирования варьируется в широком диапазоне. На следующем рисунке представлен сводный график скорости копирования.
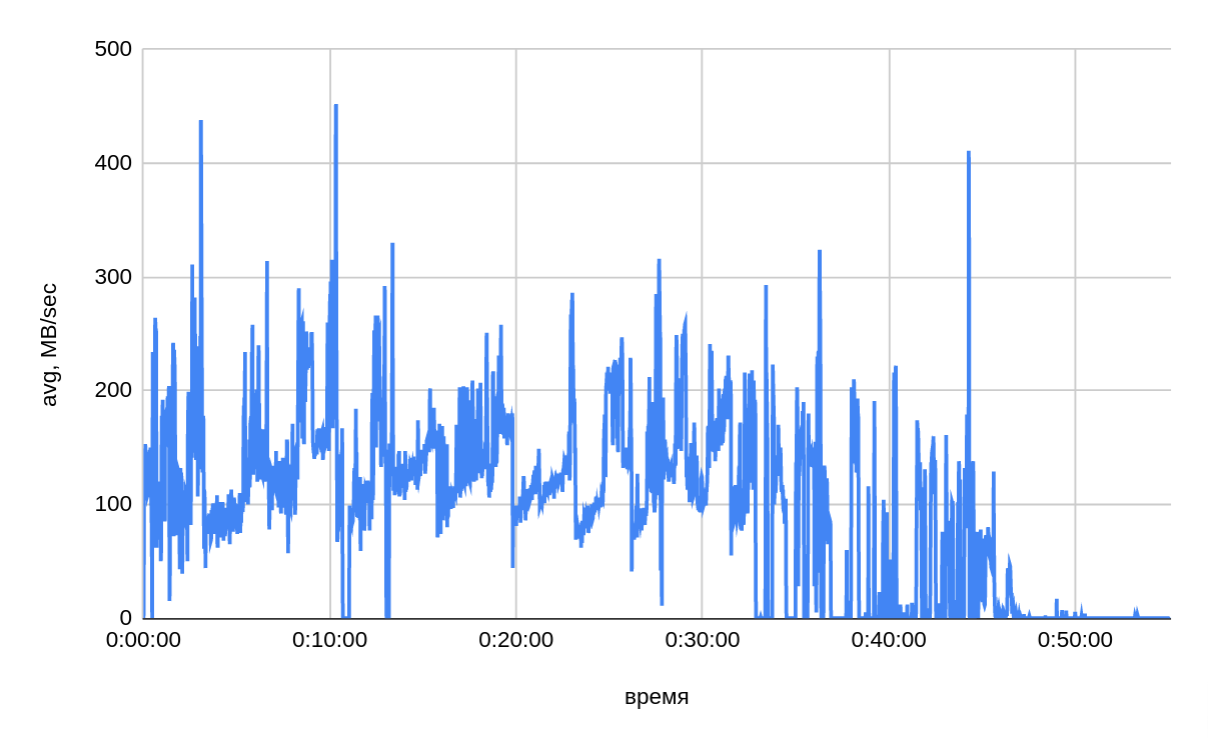
Заключение
По итогам тестирования можно сделать следующие выводы:
-
Дедупликация может значительно увеличить скорость создания резервной копии БД (до пяти раз быстрее по результатам наших тестов).
-
Связка gpbackup, DD Boost и Dell EMC Data Domain показывает лучшую производительность при использовании режима копирования "все таблицы сегмента — один файл" (single-data-file). Режим параллельного копирования (jobs) не рекомендуется к использованию из-за своей крайне низкой производительности записи.
-
Как следствие из предыдущего пункта: производительность выше при записи больших блоков данных (в тестах использовались таблицы свыше 500 МБ на таблицу). Возможно, такой профиль позволяет системе хранения эффективнее выполнять дедупликацию данных, в том числе и "на лету", а также сократить число служебных операций открытия/закрытия файлов, управления соединениями.
-
Остальные подсистемы также могут ограничивать общую производительность решения. В ходе конфигурации, тестирования и эксплуатации нужно уделять внимание всем аспектам.