Оценка подхода lock-free списков


Введение
Привет от команды Greengage DB Core!
Позвольте начать с краткой исторической справки: Greengage DB был запущен в 2024 году как open-source форк Greenplum — Massively Parallel Processing (MPP) аналитической системы управления базами данных, основанной на PostgreSQL. Мы начали этот проект, чтобы поддержать open-source сообщество Greenplum, который неожиданно стал проприетарным продуктом в мае 2024 года. Мы гарантируем дальнейшее развитие Greengage DB, следуя принципам открытости и прозрачности.
Так как Greengage DB основан на PostgreSQL, он унаследовал некоторые его известные особенности и проблемы. Одна из таких проблем, особенно актуальная в распределенных средах — это проблема "брошенных файлов" (orphaned files).
Эта проблема возникает, когда таблица создается и данные загружаются в рамках активной транзакции. Если происходит критический сбой до того, как транзакция будет закоммичена или отменена (например, внезапное отключение питания или неожиданное завершение работы узла базы данных), система проходит процесс восстановления после падения (crash recovery). При этом логическая таблица откатится, но физические файлы данных, связанные с этой незакоммиченной таблицей, могут остаться в файловой системе. Со временем такие брошенные файлы могут накапливаться, занимая место и приводя к ненужному расходу ресурсов. В настоящее время их удаление происходит вручную.
Недавно мы представили новый функционал, который позволяет автоматически удалять такие брошенные файлы. Полная информация об этой возможности доступна в статье Удаление брошенных файлов.
Если кратко, основная идея нашего подхода такова:
-
Каждый backend-процесс хранит информацию о файлах, созданных для новых отношений (именуемых
relfilenodeв терминах PostgreSQL), вместе с текущим ID транзакции в собственном внутреннем списке. После коммита (commit) или отката (abort) транзакции все записиrelfilenodeдля этой транзакции удаляются из списка. -
Процесс
checkpointerагрегирует информацию из всех таких списков всех backend-процессов и сохраняет собранные данные в новой, отдельной записи Write-Ahead Log (WAL). -
Во время восстановления процесс
Startup, который воспроизводит WAL, получает информацию о созданныхrelfilenodesи впоследствии удаляет физические файлы для всех транзакций, которые помечены как все еще не завершенные, в конце процесса восстановления.
Таким образом, одной из ключевых частей этой новой функциональности является эффективная и надежная передача информации о relfilenodes от множества backend-процессов к центральному процессу checkpointer. Так как все они — независимые процессы Linux, любые общие данные, такие как списки relfilenode, должны храниться в shared memory. Естественно, эти общие данные требуют надежной защиты от одновременного доступа для обеспечения целостности и согласованности.
Прямолинейный и распространенный подход к защите общих данных — это реализация классического механизма блокировок, например, с использованием мьютекса или спинлока для каждого отдельного списка. Однако важнейшей характеристикой любой высокопроизводительной OLAP СУБД является способность быстро обрабатывать огромные объемы данных. Введение частых блокировок, особенно в системе с множеством параллельных backend-процессов, может привести к значительной конкуренции, что вызывает ухудшение производительности из-за последовательной обработки и снижения параллелизма.
Поэтому мы поставили перед собой вопрос: возможно ли вообще разработать этот механизм межпроцессного взаимодействия так, чтобы избежать традиционного использования явных блокировок, и если да, даст ли такой подход реальный прирост производительности?
Описание подхода
Ответ — "да", это возможно, но у такого lock-free подхода будут определенные конструктивные ограничения:
-
Выделенный доступ
Для каждого списка
relfilenodeсуществует строго один выделенный процесс записи (backend-процесс) и один выделенный процесс чтения (checkpointer). Такая модель "один писатель — один список" в паре с единым центральным процессом чтения существенно упрощает управление конкурентным доступом. -
Вставки только в начало
Каждый процесс записи добавляет новые узлы только в свой список. Все вставки выполняются только в начало списка. Этот выбор критически важен для lock-free стратегии, так как он позволяет добавлять новые записи без конфликта с чтением или другими операциями записи в существующие элементы списка.
-
Логическое удаление (пометка)
Когда процесс записи должен удалить узел из списка (например, после коммита или отката транзакции), он не удаляет узел физически. Вместо этого он логически помечает узел как удаленный. Это позволяет избежать сложного управления памятью и состояния гонки, которые могли бы возникнуть при физическом удалении в конкурентной lock-free среде.
-
Физическое удаление выполняется процессом чтения
Фактическое физическое удаление таких помеченных узлов выполняется исключительно процессом чтения. Очистка происходит сразу после того, как процесс успешно прочитал и обработал текущие данные списка, гарантируя, что ни один активный процесс записи больше не ссылается на удаляемые узлы. Периодически создавая контрольные точки, мы гарантируем, что очистка списка проходит своевременно и его размер не раздувается.
-
Конкурентные операции во время чтения
Пока процесс чтения проходит список, процесс записи может выполнять операции параллельно. Новые вставки, сделанные процессом записи, во время чтения разрешены, но они не будут видны текущему процессу чтения. Логическое удаление (пометка узлов как удаленных) также может выполняться параллельно с процессами записи. Это означает, что процесс чтения может встретить и обработать узел, который уже был логически помечен как удаленный. Это приемлемо в нашем случае. Причина в том, что добавление нового узла происходит при создании хранилища для нового отношения, что также создает собственную WAL-запись. При воспроизведении WAL мы увидим либо эту запись, либо следующую checkpoint-запись, которая будет содержать новый узел. А удаление происходит при коммите или откате транзакции, что также создает WAL-запись. Поэтому информация об удаленном
relfilenodeбудет получена из нее. Более подробно об этом можно почитать в статье Удаление брошенных файлов.
Lock-free подход вдохновлен статьей A Pragmatic Implementation of Non-Blocking Linked Lists. Из нее мы взяли идею логического удаления узла с помощью Compare-and-Swap. Мы переосмыслили подход и упростили его для модели с одним процессом записи (оригинал описывает алгоритм для нескольких) и сосредоточились на управлении удаленными узлами.
Вставка (процесс записи)
Вставка проста: мы перемещаем указатель next нового узла на первый узел в списке, а затем устанавливаем HEAD, указывающий на новый узел.


Удаление (процесс записи)
Как мы упомянули, удаление из списка процессом записи является логическим, то есть узел остается в списке, но помечается как deleted. Чтобы не добавлять дополнительных полей для хранения этой метки, мы используем младший значащий бит (LSB) поля указателя next узла списка. LSB гарантированно равен 0 из-за требований выравнивания памяти.
Важно отметить, что все эти узлы списка должны находиться в shared memory. Это не позволяет выделять их с помощью стандартных функций управления памятью в рамках одного процесса, таких как malloc (или palloc, который распространен в PostgreSQL). Вместо этого используется специализированный механизм Dynamic Shared Memory Areas (DSA). По сути, он предоставляет объект dsa_area, который может использоваться несколькими backend-процессами для совместного доступа к данным. Для клиентского кода это выглядит как единый heap общей памяти с простым allocate/free интерфейсом. Так как память отображается по разным адресам в разных бэкендах, используется совместно используемый относительный указатель и операция для преобразования его в локальный для бэкенда указатель. Таким образом, говоря об указателях, мы имеем в виду dsa_pointer, который под капотом реализован как uint64 или uint32.
Итак, чтобы логически удалить узел, процессу записи достаточно установить младший бит поля next в 1. Но, как мы уже сказали, фактическая очистка списка выполняется параллельно процессом чтения. Это создает потенциальную гонку: процесс чтения может попытаться освободить следующий узел в тот самый момент, когда процесс записи пытается пометить указатель next текущего узла. Чтобы избежать конфликтов и обеспечить атомарность, операция установки метки в LSB указателя next должна выполняться атомарно — именно поэтому используется инструкция Compare-and-Swap (CAS). CAS позволяет писателю убедиться, что значение указателя next не изменилось неожиданно, прежде чем применить метку удаления.


Обход списка (процесс чтения)
Для обхода списка процесс чтения использует две основные операции:
-
get_first() -
get_next()
Во время этих операций процесс чтения активно выполняет очистку: он пропускает все узлы, помеченные как логически удаленные, физически удаляет их из структуры списка и освобождает связанную с ними память.
Однако есть критический нюанс относительно самого первого узла списка: мы не удаляем физически и не освобождаем узел, на который сейчас указывает HEAD, даже если он помечен как deleted. Этот момент важен, так как указатель HEAD — это непосредственная цель атомарных обновлений процессами записи при вставке новых узлов. Попытка физически удалить узел HEAD параллельно с операциями записи над ним может привести к сложному состоянию гонки. Узел HEAD, помеченный как deleted, будет пропущен при обходе, но его физическое удаление будет отложено до тех пор, пока новый узел не обновит HEAD, и он будет удален в следующем цикле чтения.
Давайте проиллюстрируем проход по списку на примере: рассмотрим список из шести узлов. Предположим, что Node 1, Node 2 и Node 5 в данный момент помечены как логически удаленные, и Node 1 является текущим HEAD списка.


Первый шаг: выполнение операции get_first()
-
Процесс чтения начинает с
Node 1(HEAD). Так какNode 1помечен как удаленный и являетсяHEAD-узлом, он пропускается, но не освобождается физически. -
Далее процесс чтения переходит к
Node 2.Node 2помеченdeleted, поэтомуget_first()физически удаляетNode 2из списка и освобождает этот узел. -
Процесс чтения продолжается, пока не находит
Node 3, который не помечен какdeleted. -
get_first()возвращает указатель наNode 3как текущую позицию итерации.


Второй шаг: выполнение операции get_next() (от Node 3)
-
Процесс чтения проверяет
Node 4, который не помечен какdeleted. -
get_next()возвращает указатель наNode 4как текущую позицию итерации.


Третий шаг: выполнение операции get_next() (от Node 4)
-
Процесс чтения проверяет
Node 5.Node 5помечен какdeleted, поэтомуget_next()физически удаляет и освобождаетNode 5из списка. Ключевой момент: на этом этапе указательnextузлаNode 4(который ранее указывал наNode 5) должен быть обновлен так, чтобы теперь указывать наNode 6. -
Чтобы гарантировать атомарность обновления этого указателя
nextузлаNode 4, особенно учитывая, что процесс записи может одновременно попытаться пометить самNode 4, снова используется операция Compare-and-Swap (CAS). Это гарантирует, что обновление указателяnextузлаNode 4произойдет, только если его значение все еще ожидаемое, предотвращая состояние гонки. -
В итоге
get_next()возвращает указатель наNode 6как текущую позицию итерации.


Концепция, при которой процесс чтения (checkpointer) отвечает за физическую очистку удаленных узлов, подразумевает, что операции чтения при проходе по списку могут быть не всегда максимально быстрыми с точки зрения чистой производительности. Это связано с тем, что читатель совмещает извлечение данных с освобождением памяти и перестройкой списка.
Однако в нашем конкретном случае эта особенность не представляет серьезной проблемы. Процесс checkpointer уже изначально спроектирован для выполнения множества ресурсоемких фоновых операций, таких как сброс модифицированных блоков данных на диск, управление логами транзакций и обновление различной системной метаинформации. Это важные, трудоемкие задачи, которые по своей природе выполняются асинхронно в фоновом режиме и специально спроектированы так, чтобы не блокировать и не оказывать прямого влияния на выполнение пользовательских запросов.
Таким образом, пока операции, выполняемые checkpointer, не блокируют backend-процессы, менее критичная по скорости работа процесса чтения вполне допустима. Все операции записи (вставка и логическое удаление) выполняются backend-процессами, которые напрямую обслуживают пользовательские запросы, поэтому критически важно, чтобы эти операции записи были максимально быстрыми и неблокирующими. Это позволит нам обеспечить оптимальную производительность пользовательских запросов.
Итак, подытожим: данный подход основывается на выделенном доступе (один писатель, один читатель на список), вставках только в HEAD списка со стороны процессов записи и логическом удалении (пометка узлов младшим битом в указателе next, использование CAS для атомарности). Процесс чтения выполняет всю физическую очистку помеченных узлов во время прохода по списку.
Описание процедуры тестирования
После завершения реализации следующим важным шагом стало тщательное тестирование и оценка производительности.
Процедура тестирования была спроектирована с учетом следующих ключевых требований:
-
Она должна была точно оценивать производительность в сценариях, максимально приближенных к реальным условиям. Это предполагало тестирование с большим количеством параллельных процессов записи и одним процессом чтения, все это — в рабочем окружении кластера Greengage.
-
Одновременно тестовое окружение должно было быть достаточно изолированным, чтобы исключить возможное влияние других, не связанных подсистем. Такие внешние воздействия могли бы привести к нестабильности и исказить результаты теста (например, использование реального процесса
checkpointerбыло бы непрактично, так как его другие многочисленные операции неизбежно повлияли бы на точность измерения). -
Процедура должна была быть гибкой, позволяя варьировать ключевые параметры, которые могут влиять на производительность, такие как общее количество вставляемых и удаляемых элементов, степень параллелизма (т.е. количество одновременно работающих процессов записи) и другие релевантные факторы.
С учетом этих соображений была разработана следующая синтетическая схема тестирования:
-
Эмуляция писателя
Код процесса записи был инкапсулирован в PostgreSQL-функцию, возвращающую множество (SRF), с сигнатурой
Datum lfl_test(PG_FUNCTION_ARGS). Это позволило легко выполнять операции записи, просто вызываяSELECT lfl_test(params)из любого удобного клиентского инструмента, такого какpsql. В сочетании с инструментом параллельного выполнения (например, кастомный скрипт с использованиемGNU parallelдля параллельных сессийpsql), можно было эффективно запускать сколько угодно параллельных сессий записи. Внутри функция отправляет запросы на все рабочие сегменты Greengage. На каждом сегменте функция выполняет цикл операций записи и удаления заданное количество итераций, согласно переданным параметрам. Результаты с сегментов возвращаются диспетчеру и затем возвращаются из функции пользователю. Результатом является время, затраченное процессом записи на вставку и удаление запрошенного числа элементов. -
Эмуляция читателя
Для чтения был создан выделенный фоновый процесс. Этот процесс периодически опрашивает все активные backend-сессии, а затем проходит по их lock-free спискам. Его основная задача — читать содержимое этих списков, выполнять необходимую очистку узлов, помеченных как
deleted, и затем для проверки выгружать данные на диск.
Другим важным аспектом было то, как эффективно интерпретировать результаты, полученные с помощью нашей методологии тестирования. Прямой анализ абсолютных значений времени дал бы ограниченную информацию, так как такие цифры зависят от характеристик аппаратного обеспечения и условий окружения тестового кластера.
Следовательно, истинной целью и точкой интереса было провести сравнительный анализ, а именно: сравнить ключевые параметры lock-free реализации списка с традиционным списком на блокировках. Это сравнение проводилось на одном и том же кластере Greengage и идентичном аппаратном обеспечении, что позволило изолированно выполнить замеры производительности нашего lock-free решения по сравнению с его аналогом на блокировках. Такой подход позволяет сделать осмысленные выводы об относительной эффективности нашего решения.
Результаты тестирования
Мы провели тесты производительности с разным количеством вставляемых и удаляемых элементов: 100, 1000, 5000 и 10000 записей. Для статистической надежности каждая конфигурация тестов была повторена 10 раз. Усредненные значения производительности этих запусков представлены на следующих графиках.
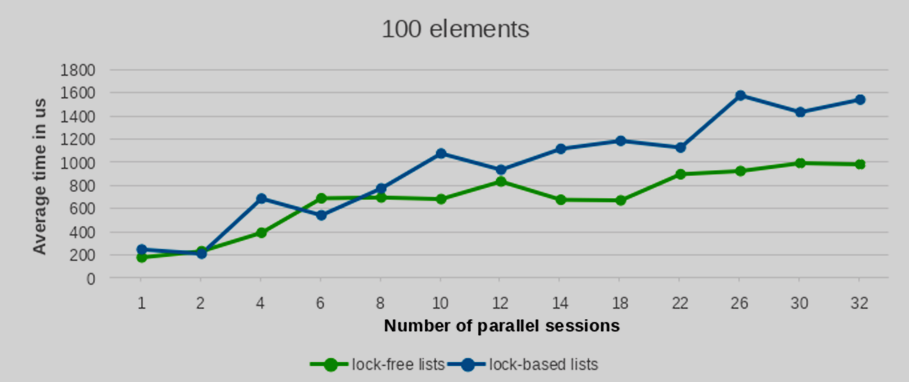
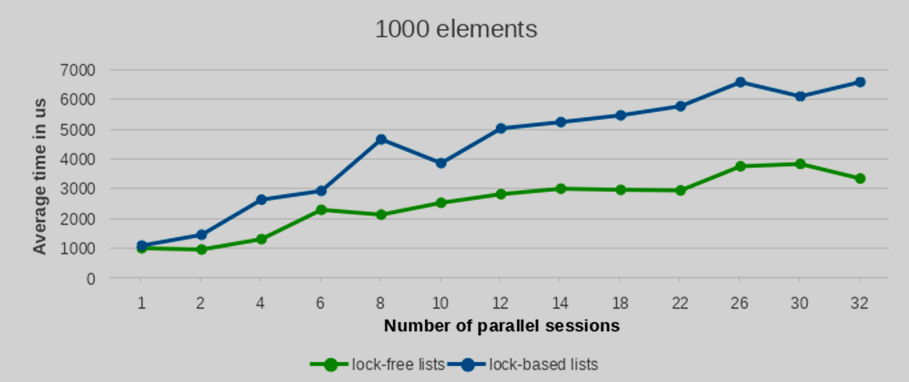
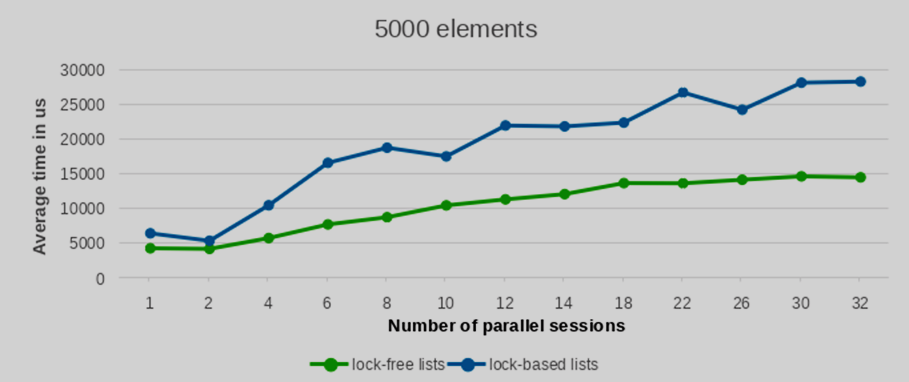
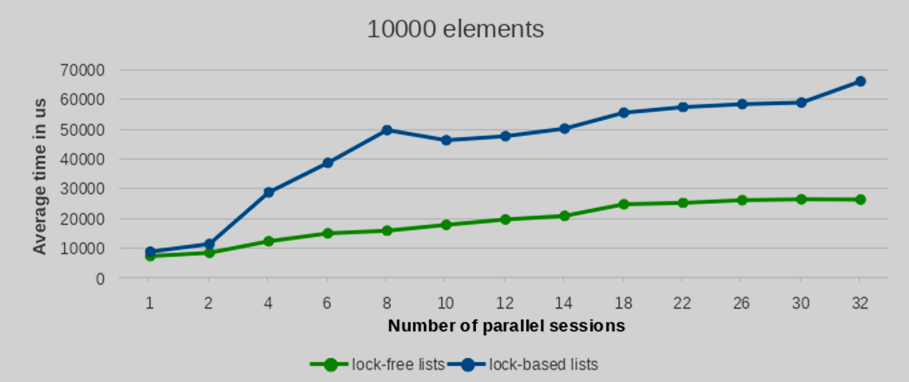
Как видно из приведенных графиков, с увеличением количества параллельных сессий (и, следовательно, одновременно запущенных backend-процессов) время выполнения реализации lock-free списка растет значительно более плавно по сравнению со списками, построенными на per-backend блокировках. Это указывает на лучшую масштабируемость при взаимных блокировках.
Разница в производительности между lock-free списком и обычным списком с блокировками значительно увеличивается с ростом количества параллельных записей. Более того, это преимущество становится все более очевидным при большем числе элементов. В то время как результаты для небольшого числа элементов показывают в целом сопоставимую производительность обоих подходов, преимущество lock-free списков четко проявляется при обработке значительных объемов элементов.
Заключение
Описанный lock-free подход доказал свою эффективность, показав обнадеживающие результаты производительности при высоких нагрузках. Однако, учитывая, что ожидаемая нагрузка для нашей целевой функциональности невелика (как правило, хранение десятков или сотен relfilenodes, но обычно не более), мы приняли стратегическое решение по реализации этого функционала. Мы решили использовать традиционные списки с блокировками, так как они показывают сопоставимую производительность при малом количестве элементов. Этот выбор существенно повышает удобство сопровождения и снижает риск случайных поломок или неожиданных регрессий при будущих изменениях, благодаря простоте, присущей традиционному подходу.
Тем не менее, сама lock-free методология доказала свои отличные характеристики производительности, особенно при высокой конкуренции за ресурсы и больших объемах данных. Следовательно, этот подход остается сильным кандидатом для использования в будущих новых функциональных возможностях Greengage DB, где необходимо эффективно и параллельно передавать или обмениваться значительными объемами данных между различными процессами внутри сегмента, обеспечивая надежную масштабируемость и минимальные накладные расходы.
Источник: Оценка подхода lock-free списков