Greenplum vs Citus. Часть 2


В предыдущей статье мы обсудили основные архитектурные особенности Citus. Также довольно глубоко рассмотрели некоторые особенности планирования и выполнения запросов.
Во второй части мы затронем тему ребаланса шардов — эта часть представляет для нас особый интерес в связи с нашими планами по проекту Greengage, где мы будем заниматься задачей масштабирования кластера в меньшую сторону (задача также известная как ggshrink, проще говоря сокращение числа сегментов и перераспределение данных на меньшее количество сегментов).
В заключительной части этой статьи мы рассмотрим результаты прогонов сравнительных TPC-DS тестов Citus и Greenplum.
Ребаланс
Архитектура Citus позволяет использовать различные подходы с точки зрения реализации механизма распределения данных и балансировки нагрузки при доступе к этим данным.
Сценарии использования Citus таковы, что наличие возможного перекоса по данным (data skew) не является чем-то необычным. Например, в случае тривиального примера, когда шардам соответствуют данные определенных пользователей (мы упоминали подход с multi-tenant архитектурой в первой части), добиться равномерности распределения в том виде, как это более привычно для Greenplum, будет проблематично. Какие-то шарды будут априори занимать больше места, так как принимают больший объем данных и, возможно, большую нагрузку. Создателям Citus очевидно пришлось учитывать эти особенности и в подходе к решению задачи балансировки нагрузки при таких исходных условиях.
На мой взгляд, подобные требования привели к тому, что Citus предлагает довольно интересные возможности конфигурации распределения данных:
-
базовые алгоритмы балансировки оперируют понятиями
costиcapacity, что позволяет реализовать различные стратегии балансировки; -
встроенные стратегии балансировки
by_shard_countиby_disk_size, вероятно, позволяют покрыть большинство сценариев обычных пользователей; -
тем, кому нужно что-то выходящее за рамки встроенных алгоритмов, предлагается вариант описать свои функции расчёта
costиcapacity, тем самым настроив алгоритм таким образом, чтобы закрыть свои потребности по распределению данных и/или нагрузки.
Основные понятия ребаланса — это рассмотренные нами в первой статье шарды (shard), группа шардов (shard group), размещение группы шардов (shard group placement) и группа узлов (node group).
Группа шардов содержит множество шардов с одинаковыми диапазонами ключей.
Размещение группы шардов — это соответствие группы шардов группе узлов, где группа узлов идентифицируется по некоторому целочисленному идентификатору groupid (идентификатор можно узнать из таблицы pg_dist_node).
Говоря про перенос шардов между узлами, имеется ввиду перемещение всей группы шардов. Такая необходимость становится очевидной, если мы вспомним про свойство co-location шардов, чтобы Citus имел возможность эффективного соединения таблиц.
Прежде чем описать алгоритм ребаланса предлагаю рассмотреть:
-
понятие стоимости (
cost) и емкости (capacity) в терминах групп шардов и узлов для их размещения; -
понятие утилизации (
utilization) узла при размещении групп шардов; -
понятие допустимости размещения группы шардов на узле (так называемый
disallowedPlacementList); -
допущения и ограничения, которые учитывались разработчиками при решении задачи ребаланса.
Стоимость — это оценочная характеристика группы шардов, позволяющая сравнивать группы шардов между собой для решения задачи балансировки.
Например, для стратегии by_disk_size это значение принимается равным занимаемому объему данных на диске, однако пользователь может сопоставить этому значению свою характеристику (реализовав свою пользовательскую функцию и сопоставив её с пользовательской стратегией).
Емкость, в свою очередь, является характеристикой узла, который принимает эту группу шардов. Семантика значения по умолчанию весовая, равна 1, так как вклад каждого узла кластера считается равноценным. При желании пользователь может переопределить это значение, если какие-то узлы кластера вносят больший вклад (например, расширили кластер какими-то более производительными узлами).
Утилизация связывает стоимость и емкость следующим образом:
где — утилизация i-ого узла, — стоимость j-ой группы, — емкость i-ого узла.
Понятие допустимости размещения группы необходимо для реализации стратегий закрепления группы шардов за определенными узлами.
Первое и главное допущение, что алгоритм не ищет "идеального" решения задачи балансировки, а довольствуется некоторым "локально-оптимальным" положением групп шардов. Основная архитектурная документация даёт ссылку на теоретические основы этой и подобных ей задач, но в данном случае нас интересует практическая сторона. Что означает это "локально-оптимальное" положение? Допустим, в нашем кластере такие группы шардов:
SELECT
shardid,
table_name,
shard_size,
shard_size >> 20 AS "shard_size_in_MiB",
nodename,
nodeport
FROM citus_shards as s
WHERE table_name = 'dist_table'::regclass
ORDER BY nodename, nodeport;shardid | table_name | shard_size | shard_size_in_MiB | nodename | nodeport ---------+------------+------------+-------------------+-----------+---------- 102490 | dist_table | 253837312 | 242 | citus-db1 | 8002 102492 | dist_table | 417579008 | 398 | citus-db1 | 8002 102491 | dist_table | 491520 | 0 | citus-db2 | 8003 102493 | dist_table | 73728 | 0 | citus-db2 | 8003 (4 rows)
Как видно из таблицы, утилизация нод citus-db1 и citus-db2 отличается на 3 порядка:
SELECT
nodename,
nodeport,
norm_node_utilization_for_table('dist_table'::regclass) as node_utilization
FROM citus_shards AS s
WHERE table_name = 'dist_table'::regclass
GROUP BY nodename, nodeport;nodename | nodeport | node_utilization -----------+----------+------------------ citus-db1 | 8002 | 1.998 citus-db2 | 8003 | 0.001 (2 rows)
Так как стратегия по умолчанию by_disk_size значением стоимости считает размер шарда на диске в байтах, что может быть не очень удобным для восприятия при значимом перекосе, для иллюстрации этого перекоса я использовал самописную функцию norm_node_utilization_for_table для некоторого нормирования значения.
Это значение рассчитывается как "во сколько раз объем данных на шардах больше/меньше, чем некоторое идеальное среднее значение, исходя из числа нод и общего объема данных".
Также нужно добавить, что стоимость для каждого шарда инкрементируется на значение citus.rebalancer_by_disk_size_base_cost, равное по умолчанию 104857600 байт. Это делается для того, чтобы избежать ситуации неправильной балансировки для шардов с малым количеством данных либо пустых. Для теста и наглядности я выставил это значение в 0.
Таким образом, для моего тестового кластера из 2 нод и 4 шардов общая стоимость (total cost) будет равна 671981568 байт, общая ёмкость (total capacity) будет равна 2.
Важный момент для корректной работы алгоритма ребаланса — это пороговые значения, которые позволяют не делать избыточные перемещения, так как алгоритм не учитывает стоимость самого перемещения. То есть, если для достижения балансировки, которая возникла из-за дисбаланса в 10 ГБ, ему необходимо переместить несколько ТБ данных, то он с радостью запланирует такое перемещение. Можно сказать, что без этих настроек цель сбалансировать кластер любой ценой оправдывает средства. По сути, эти значения представляют собой диапазон утилизации ноды, внутри которого нода считается сбалансированной (threshold). Для данного случая диапазон такой: (369589856, 302391712), что равно плюс-минус 10% от средней утилизации на 2 нодах. Таким образом, если значение попадает в этот интервал, то нода считается достаточно сбалансированной.
Также используется и второе пороговое значение improvement_threshold. Чтобы проиллюстрировать необходимость такого порога, в документации приводится следующий пример: допустим, имеются две ноды с такими стоимостями шардов A=200 GB и B=99 GB. Перемещение 100 GB данных шарда с ноды A на ноду B улучшит их положение с точки зрения баланса (A=100 GB, B=199 GB), но выгода от такого перемещения крайне сомнительная, учитывая требуемые на такое перемещение ресурсы (как мы помним, алгоритм не оценивает стоимость перемещений!). Значение этого порога для стратегии by_disk_size задаётся равным 50%. Смысл таков: при оценке целесообразности перемещений учитывается насколько улучшится утилизация ноды, если такое перемещение выполнить. Если показатель утилизации улучшится более чем на 50%, то перемещение планируется к выполнению.
Алгоритм ребаланса
Citus предоставляет возможность получить план без фактического перераспределения шардов, вызвав функцию get_rebalance_table_shards_plan. Эта функция опирается на реализацию алгоритма ребаланса, что даёт возможность поисследовать его на примере вызова для моего тестового кластера из 2 узлов и таблицы на 4 шарда.
Начальное состояние шардов:
shardid | table_name | shard_size | shard_size_in_MiB | nodename | nodeport ---------+------------+------------+-------------------+-----------+---------- 102490 | dist_table | 253837312 | 242 | citus-db1 | 8002 102492 | dist_table | 417579008 | 398 | citus-db1 | 8002 102491 | dist_table | 491520 | 0 | citus-db2 | 8003 102493 | dist_table | 73728 | 0 | citus-db2 | 8003
Итак, как выглядит на практике сам алгоритм:
-
Определяет тип стратегии ребаланса и другие входные параметры (пороговые значения, флаг высвобождения ноды
drainOnly). В моём случае это пороговое значениеthresholdдля вычисления, насколько узел загружен или наоборот свободен — значение по умолчанию, равное 0,1 (т.е. 10%); значениеimprovement_thresholdравно 0.5 (т.е. 50%). -
Составляет список всех активных узлов (рабочие узлы, которые могут принимать
SELECT-запросы, исключая координатор) и сортирует их по имени хоста и порту. В моём случае это 3 активных узла (2 рабочих узла и координатор) и 4 возможных размещения шардов. -
Проходит по списку таблиц, для которых требуется осуществить балансировку, где для каждой таблицы получает список доступных размещений шардов. Я выбрал одну таблицу для балансировки
dist_table. Специальных ограничений на размещение шардов нет, все узлы активны — таким образом, число доступных размещений для шардов равно 4. -
Для полученного списка активных узлов, списка возможных размещений групп шардов и параметров на 1-ом шаге, составляет список шагов по перемещению групп шардов между узлами, которые приводят кластер к сбалансированному состоянию:
-
Инициализируется начальный список размещений шардов с точки зрения последующего планирования переноса шардов (
shardPlacementList):-
Вычисляются значения емкости узлов (
capacity). Для координатора емкость, по умолчанию, считается равной 0, для узлов равна 1. -
Вычисляется общая емкость всех узлов (
totalCapacity). Для моего случая это значение равно 2. -
Вычисляется значение стоимости шардов (
costисходя из их текущего размещения). Значение колонкиshard_size. -
Вычисляется значение утилизации шардов (
utilization) для данного размещения на узле. Для функции вычисленияcapacityиcostпо умолчанию значение для всех шардов будет равно стоимости, то есть размеру шарда, так какcapacityравно 1. -
Вычисляется значение общей стоимости по всем шардам (
totalCost). РавноеSUM(shard_size) = 671981568. -
Список узлов сортируется по возрастанию и убыванию утилизации или емкости узла. .
-
-
Осуществляется планирование переноса шардов с тех узлов, на которых шардам находиться нельзя (
disallowedPlacementList). В моём случае таких шардов нет. -
С учетом полученного на шаге 1 списка
shardPlacementList(в моём случае таблица однаdist_table, список состоит из одного элемента):-
Вычисляется утилизация в среднем (
totalCost/totalCapacity). Для тестового примера это значение равно671981568 / 2 = 335990784байт. -
Исходя из значения порога
thresholdсчитается пограничный диапазон, внутри которого узел считается сбалансированным. В моём случае это(302391712, 369589856)в байтах. -
Ищутся возможные варианты размещения шарда. Это ключевая часть алгоритма ребаланса. Основная идея заключается в переносе шардов с наиболее загруженных узлов на менее нагруженные. Тут нам и пригодятся оба списка, полученные на шаге сортировки списка по утилизации/емкости узлов. Алгоритм устраивает первый подходящий вариант переноса, который улучшает баланс кластера, то есть он не ищет наилучший вариант (таким образом являясь жадным алгоритмом). Если текущий наименее нагруженный узел не подходит, то алгоритм переходит к следующему. Алгоритм завершает свою работу, как только не будет найдено варианта улучшения балансировки кластера. Пороговые значение при этом используются для достижения приемлемого баланса и позволяют избегать ситуаций, которые я описывал выше. Таким образом:
-
Из полученного отсортированого списка узлов по убыванию утилизации получаем первый элемент. Это будет узел, с которого будет планироваться перенос, то есть узел-источник. В моём случае на первом шаге это будет узел
citus-db1с двумя шардами 102490 и 102492 (это идентификаторы их колонкиshardid). -
Если утилизация узла-источника меньше левой границы диапазона (302391712, 369589856), то алгоритм считает свою задачу выполненной, так как не имеет смысла переносить шарды с уже незагруженных узлов.
utilizationноды в данном случае 671416320 байт, что больше нижней границы диапазона, идём дальше. -
Иначе, начинаем со второго списка нод по возрастанию утилизации. Это будут кандидаты на узлы, на которые может рассматриваться перенос, то есть узел-приёмник. В моём случае это нода
citus-db2с утилизацией 565248 байт. -
Если утилизация возможного узла-приёмника больше правой границы диапазона (302391712, 369589856), то дальнейший поиск узлов не имеет смысла, так как дальше будут узлы либо с такой же, либо с большей утилизацией. Также не имеет смысла ряд других сценариев с порогами, которые при рассмотрении опустим. В данном случае утилизация узла 565248 < 369589856 байт.
-
Для выбранных источника и возможного приёмника рассчитываются их утилизации после возможного переноса (на узле-источника уменьшается, на узле-приёмнике увеличивается). Сначала рассматривается шард 102492 со стоимостью 417579008 байт. Если перенос осуществляется, то новые вес и утилизация на узле-приёмнике будут равны 418144256 байт. На узле источнике скорректируется до 253837312 байт.
-
Если утилизация узла-приёмника стала выше, чем источника после возможного переноса, то это перемещение считается полезным с точки зрения приведения кластера в сбалансированное состояние и общее состояние кластера можно обновить (пока в памяти). В моём случае утилизация на приёмнике стала бы выше (418144256 > 253837312), так что алгоритм действует дальше.
-
Если утилизация узла-приёмника после возможного переноса становится больше утилизации узла-источника (до возможного переноса), то нужно принять решение, насколько это перемещение имеет смысл с точки зрения улучшения общего баланса. Также алгоритм проверяет возможное улучшение утилизации по пороговому ограничению
improvement_threshold— если выгоды от перемещения нет, то рассматриваются другие варианты переноса. -
Если возможный перенос улучшает баланс кластера, то этот шаг планируется, в состоянии в памяти обновляется состояние стоимости и утилизации, а алгоритм продолжает свою работу. Так как возможный шаг улучшает ребаланс и шаг переноса шарда 102492 со стоимостью 417579008 байт на ноде
citus-db1планируется к переносу на нодуcitus-db2. Это первый шаг, который мы видим в плане выше. Далее алгоритм уже рассматривает обновленную картину после возможного переноса шарда и при планировании шагов учитывает утилизацию узлаcitus-db2как 418144256 байт и исходит из этого. -
Если возможных шагов по улучшению баланса не будет найдено, то алгоритм завершает свою работу.
-
-
-
По итогу работы алгоритм в моём случае выбрал следующие шаги для ребаланса dist_table:
select * from get_rebalance_table_shards_plan('dist_table'::regclass::oid);table_name | shardid | shard_size | sourcename | sourceport | targetname | targetport ------------+---------+------------+------------+------------+------------+------------ dist_table | 102492 | 417579008 | localhost | 8002 | localhost | 8003 dist_table | 102491 | 491520 | localhost | 8003 | localhost | 8002 dist_table | 102493 | 73728 | localhost | 8003 | localhost | 8002 (3 rows)
Таким образом, после перемещения групп шардов кластер бы сбалансировался следующий образом:
shardid | table_name | shard_size | shard_size_in_MiB | nodename | nodeport ---------+------------+------------+-------------------+-----------+---------- 102490 | dist_table | 253837312 | 242 | citus-db2 | 8003 102492 | dist_table | 417579008 | 398 | citus-db1 | 8002 102491 | dist_table | 491520 | 0 | citus-db1 | 8002 102493 | dist_table | 73728 | 0 | citus-db1 | 8002
Перемещение шардов
Высокоуровнево перемещение шардов выглядит следующим образом: есть два варианта переноса — блокирующий, который, как следует из названия, приостанавливает операции с шардом, пока перенос не будет осуществлён, и неблокирующий (по большей части, так как во время обновления метаданных блокировка всё-таки берётся на некоторый промежуток времени) на базе использования логической репликации.
Оба варианта опираются на создание новых таблиц перед переносом данных.
После успешного завершения перемещения шардов таблицы-источники будут удалены.
Если где-то возникнет ошибка, то уже проделанные изменения остаются как есть.
У неблокирующего переноса также есть важная деталь, что если у распределенной таблицы отсутствует первичный ключ (или уникальный индекс), то UPDATE- и DELETE-выражения будут завершаться с ошибками. Что в некотором смысле приближает его к блокирующему.
Описание деталей переноса потянет на полную статью, так что я обозначу основные особенности:
-
При начальном создании таблиц на приёмнике индексы и ограничения не создаются. Создание этих и ряда других объектов происходит после завершения копирования и когда будет завершен накат свежих записей.
-
Слот репликации создаётся отдельно, при создании подписки (
CREATE SUBSCRIPTION) слот репликации не создаётся (create_slot = false). При этом копирование данных осуществляется вне созданной подписки с использованиемCOPY. Хотя это можно делать в рамках подписки (параметрcopy_data), однако заявляется, что это делается из соображений производительности, так как можно в том числе воспользоваться binary-копированием (также, судя по всему, задействуется внутрянка Adaptive Executor, который обсуждался в первой части). -
Изначально подписка создаётся в
disabled-режиме, включается она после копирования данных. -
Перед и после создания индексов, ограничений и т.п. происходит ожидание, пока новый шард догонит LSN источника.
-
Чтобы обновить метаданные таблиц, необходимо дождаться завершения текущих DML-операций (ожидается для взятия глобальной блокировки).
-
После получения блокировки опять приходится ждать наката свежих данных.
-
Как только это произошло, происходит обновление метаданных (
pg_dist_placement). -
Также, на мой взгляд, важное замечание, что "… final commit happens in a 2PC, with all the characteristics of a 2PC. If the commit phase fails on one of the nodes, writes on the shell table remain blocked on that node until the prepared transaction is recovered, after which they will see the updated placement. The data movement generally happens outside of the 2PC, so the 2PC failing on the target node does not necessarily prevent access to the shard".
Если сравнивать эту часть Citus с Greenplum, то различия принципиальные — для Greenplum сценарии использования с перекосом данных между сегментами возможны (препятствовать он этому не может), но являются скорее исключением и показателем "плохого" распределения данных. Для равномерного распределения данных рекомендуется использовать определенные практики. Выражение "скорость каравана равна скорости самого медленного верблюда" хорошо отражает возможные проблемы, которые возникают в случае перекоса данных. Для контроля за этими параметрами системы есть специальные представления.
Число сегментов в общем случае на всех узлах одинаково. В случае использования зеркалирования (а для продакшен это является обязательным) в Greenplum реализованы 2 стратегии размещения зеркал: group- и spread-зеркалирования.
Таким образом, как таковой задачи ребаланса данных таблиц в понимании Citus в Greenplum нет, так как единицей масштабирования выступает отдельный экземпляр PostgreSQL (то есть сегмент), который содержит порции данных всех таблиц. Однако кластер Greenplum в силу объективных причин (например, ручной перенос зеркал, переключение на зеркала, вывод или ввод в строй новых узлов) может прийти в несбалансированное состояние именно по числу сегментов на узлах (как primary-, так и mirror-сегментам). И тогда кластер нужно приводить в сбалансированное состояние.
И тут время для небольшого спойлера: мы планируем решать эту задачу в рамках Greengage и, конкретнее, в задаче ggshrink кластера (вернее, как части ggshrink).
Контроль за потреблением ресурсов
Как известно, в Greenplum контроль за потреблением ресурсов реализован на базе ресурсных групп (и в более ранних версиях — слотов). Без этого механизма задача распределения ресурсов между множеством потребителей с разными уровнями критичности выполнения задач представляется тpyднopeшaeмой. Очевидно, что эта функциональность must-have для корпоративных пользователей.
С одной стороны, Citus за счёт параллелизации запросов в виде разбиения на подзадачи, которые обращаются к отдельным физическим шардам, выглядит выигрышно в плане утилизации имеющихся ресурсов, но бесконтрольность этого процесса может сыграть злую шутку в случае высоконагруженных кластеров.
Сравнение по результатам TPC-DS тестов
Формально, для Citus готовых реализаций тестов TPC-DS нет (по крайней мере, мне их найти не удалось). Разработчики рекомендуют к использованию HammerDB. Однако для OLAP это реализация TPC-H спецификации, кроме того, в HammerDB нет реализации для Greenplum.
В рамках данного исследования было интересно сравнить производительность с Greenplum по TPC-DS тестам.
Пришлось частично адаптировать тест, который подходит и для Postgres.
Небольшими доработками удалось адаптировать его для Citus. В частности, под Citus нужно создать distributed- и reference-таблицы.
Создания индексов, которые в этой реализации под PostgreSQL объявляеются для колонок, я оставил как есть, хотя это существенно замедлило загрузку данных, по сравнению с Greenplum, где схема задаёт только ключи распределения и индексы отсутствуют.
Я исходил из следующей идеи — раз Citus заявляется как способ масштабирования PostgreSQL, то и подход с поднятием нескольких экземпляров и организация кластера Citus должна соотвествовать этому видению. Наличие существующих индексов также соответствует этой идее. Осталось только разобраться с разделением на distributed- и reference-таблицы и решить, какие ключи использовать для распределения данных по шардам. Я взял разбиение на эти типы таблиц и колонки распределения из предлагаемого разработчиками самого Citus варианта под TPC-DS (это не готовая реализация, а скорее набор скриптов).
Однако при запуске тестов приключилась занятная история. Пристрелочный тест с набором данных около 10 ГБ (в терминах используемой реализации — scaling factor равен 10) для Citus в ряде тестов либо не завершился в разумный интервал времени, либо показал настолько медленное время, что прогон на каком-то весомом объеме данных не имел никакого смысла. Ради интереса я запустил эти тесты отдельно, но отменил их примерно через 3 часа ожидания.
Создателями реализации теста рекомендуется использовать scaling factor равным 3000 (т.е. около 3 ТБ), но с учетом времени выполнения даже сравнительно быстрых тестов я такой набор решил не использовать даже для относительно быстрых тестов. Для анализа показателей времени с точки зрения разницы и для разбора причин этой разницы во времени достаточно и этого набора. Также пришлось исключить 18 запросов из 99, которые с таким вариантом колонок распределения не выполнились из-за ошибки. Подбирать другие колонки и затачивать запросы под конкретные тесты, скорее всего, могло бы нарушить работоспособность других тестов, а исправлять по кругу другие тесты у меня не было никакого желания.
Конфигурация тестового стенда
Citus
| Node | Configuration |
|---|---|
citus coordinator node |
CPU(s): 32 |
citus worker node #1 |
CPU: 32 |
citus worker node #2 |
CPU: 32 |
Greenplum
| Node | Configuration |
|---|---|
master node |
CPU: 32 |
segment node #1 |
|
segment node #2 |
Набор данных TPC-DS
Со схемой данных и, в целом, со спецификацией TPC-DS тестов можно ознакомиться тут.
| Tablename | Citus table size (scale factor 100) | Citus table size (scale factor 10) | Citus table size (scale factor 1) | Greenplum table size (scale factor 100) |
|---|---|---|---|---|
call_center |
49 КБ |
72 КБ |
16 КБ |
3,2 МБ |
catalog_page |
10 МБ |
6048 КБ |
2 МБ |
9 МБ |
catalog_returns |
2,5 ГБ |
235 МБ |
24 МБ |
3,7 ГБ |
catalog_sales |
32 ГБ |
3 ГБ |
318 МБ |
12,8 ГБ |
customer |
0,9 ГБ |
226 МБ |
15 МБ |
0,2 ГБ |
customer_address |
0,4 ГБ |
102 МБ |
7 МБ |
116 МБ |
customer_demographics |
0,4 ГБ |
415 МБ |
144 МБ |
88 МБ |
date_dim |
34 МБ |
32 МБ |
11 МБ |
15 МБ |
household_demographics |
1,22 МБ |
1296 КБ |
442 КБ |
6,6 МБ |
income_band |
24 КБ |
24 КБ |
8 КБ |
6,5 МБ |
inventory |
17 ГБ |
5,6 ГБ |
520 МБ |
1,6 ГБ |
item |
0,2 ГБ |
95 МБ |
6 МБ |
63 МБ |
promotion |
467 КБ |
240 КБ |
74 КБ |
6,6 МБ |
reason |
24 КБ |
24 КБ |
8 КБ |
6,4 МБ |
ship_mode |
24 КБ |
24 КБ |
8 КБ |
6,4 МБ |
store |
393 КБ |
120 КБ |
16 КБ |
6,6 МБ |
store_returns |
4,1 ГБ |
398 МБ |
42 МБ |
3,2 ГБ |
store_sales |
45 ГБ |
4,4 ГБ |
446 МБ |
17,8 ГБ |
time_dim |
33 МБ |
33 МБ |
11 МБ |
14 МБ |
warehouse |
24 КБ |
24 КБ |
8 КБ |
6,4 МБ |
web_page |
762 КБ |
96 КБ |
8 КБ |
6,6 МБ |
web_returns |
1,1 ГБ |
105 МБ |
11 МБ |
0,9 ГБ |
web_sales |
15 ГБ |
1,4 ГБ |
153 МБ |
6,6 ГБ |
web_site |
24 КБ |
72 КБ |
49 КБ |
6,5 МБ |
Сравнительные тесты основного набора (scaling factor 100)
С содержанием каждого запроса можно ознакомиться тут. Постфикс в имени теста соотвествует постфиксу имени шаблона. Например, tpcds.01 соответствует шаблон query1.tpl.
| Test | Greenplum (scale factor 100) | Citus (scale factor 100) | Citus (scale factor 10) | Citus (scale factor 1) |
|---|---|---|---|---|
tpcds.01 |
00:00:01.131 |
— |
2h timeout |
00:02:38.158 |
tpcds.02 |
00:00:09.918 |
00:02:02.122 |
00:01:54.114 |
00:00:13.139 |
tpcds.03 |
00:00:00.864 |
00:00:00.433 |
00:00:00.605 |
00:00:00.125 |
tpcds.04 |
00:00:20.202 |
— |
2h timeout |
00:20:20.122 |
tpcds.05 |
00:00:02.258 |
— |
00:06:12.372 |
00:00:41.412 |
tpcds.06 |
00:00:00.561 |
00:00:11.119 |
00:00:13.130 |
00:00:01.104 |
tpcds.07 |
00:00:01.125 |
00:00:01.139 |
00:00:01.134 |
00:00:00.277 |
tpcds.08 |
00:00:00.739 |
00:00:00.591 |
00:00:00.526 |
00:00:00.628 |
tpcds.09 |
00:00:15.154 |
00:00:02.251 |
00:00:02.229 |
00:00:00.829 |
tpcds.10 |
00:00:01.128 |
not supported |
not supported |
not supported |
tpcds.11 |
00:00:10.101 |
— |
2h timeout |
00:05:09.309 |
tpcds.12 |
00:00:00.304 |
00:00:00.202 |
00:00:00.192 |
00:00:00.137 |
tpcds.13 |
00:00:02.241 |
00:00:00.466 |
00:00:00.476 |
00:00:00.164 |
tpcds.14 |
00:00:28.280 |
— |
00:07:13.433 |
00:00:48.485 |
tpcds.15 |
00:00:00.607 |
00:00:00.263 |
00:00:00.307 |
00:00:00.148 |
tpcds.16 |
00:00:07.734 |
not supported |
not supported |
not supported |
tpcds.17 |
00:00:02.221 |
00:00:00.380 |
00:00:00.360 |
00:00:00.202 |
tpcds.18 |
00:00:01.188 |
not supported |
not supported |
not supported |
tpcds.19 |
00:00:00.792 |
00:00:00.502 |
00:00:00.427 |
00:00:00.162 |
tpcds.20 |
00:00:00.362 |
00:00:00.223 |
00:00:00.245 |
00:00:00.125 |
tpcds.21 |
00:00:00.614 |
00:00:00.954 |
00:00:00.862 |
00:00:00.176 |
tpcds.22 |
00:00:06.633 |
not supported |
not supported |
not supported |
tpcds.23 |
00:01:10.702 |
— |
00:03:10.190 |
00:00:25.257 |
tpcds.24 |
00:00:18.185 |
00:00:13.137 |
00:00:12.127 |
00:00:00.19 |
tpcds.25 |
00:00:01.179 |
00:00:00.365 |
00:00:00.359 |
00:00:00.285 |
tpcds.26 |
00:00:01.102 |
00:00:00.944 |
00:00:00.764 |
00:00:00.232 |
tpcds.27 |
00:00:01.167 |
not supported |
not supported |
not supported |
tpcds.28 |
00:00:10.106 |
00:00:01.193 |
00:00:01.190 |
00:00:00.626 |
tpcds.29 |
00:00:03.336 |
00:00:00.295 |
00:00:00.295 |
00:00:00.236 |
tpcds.30 |
00:00:00.678 |
— |
00:26:48.160 |
00:00:09.911 |
tpcds.31 |
00:00:02.276 |
00:00:11.115 |
00:00:11.118 |
00:00:02.232 |
tpcds.32 |
00:00:00.776 |
not supported |
not supported |
not supported |
tpcds.33 |
00:00:01.137 |
00:00:00.57 |
00:00:00.549 |
00:00:00.303 |
tpcds.34 |
00:00:01.193 |
00:00:00.523 |
00:00:00.479 |
00:00:00.22 |
tpcds.35 |
00:00:02.245 |
not supported |
not supported |
not supported |
tpcds.36 |
00:00:04.428 |
not supported |
not supported |
not supported |
tpcds.37 |
00:00:02.236 |
not supported |
not supported |
not supported |
tpcds.38 |
00:00:05.526 |
00:00:14.146 |
00:00:14.146 |
00:00:02.207 |
tpcds.39 |
00:00:06.600 |
— |
00:02:31.151 |
00:00:16.167 |
tpcds.40 |
00:00:00.844 |
00:00:00.181 |
00:00:00.181 |
00:00:00.121 |
tpcds.41 |
00:00:00.161 |
00:00:09.989 |
00:00:10.103 |
00:00:00.527 |
tpcds.42 |
00:00:00.376 |
00:00:00.437 |
00:00:00.436 |
00:00:00.134 |
tpcds.43 |
00:00:02.219 |
00:00:00.477 |
00:00:00.434 |
00:00:00.165 |
tpcds.44 |
00:00:04.436 |
00:00:00.100 |
00:00:00.108 |
00:00:00.082 |
tpcds.45 |
00:00:00.721 |
00:00:00.288 |
00:00:00.272 |
00:00:00.142 |
tpcds.46 |
00:00:03.398 |
00:00:01.179 |
00:00:01.166 |
00:00:00.496 |
tpcds.47 |
00:00:05.524 |
— |
2h timeout |
00:37:12.223 |
tpcds.48 |
00:00:02.202 |
00:00:00.654 |
00:00:00.615 |
00:00:00.212 |
tpcds.49 |
00:00:01.140 |
00:00:00.311 |
00:00:00.284 |
00:00:00.178 |
tpcds.50 |
00:00:04.430 |
00:00:00.179 |
00:00:00.179 |
00:00:00.123 |
tpcds.51 |
00:00:08.894 |
00:00:25.256 |
00:00:26.261 |
00:00:03.339 |
tpcds.52 |
00:00:00.365 |
00:00:00.481 |
00:00:00.447 |
00:00:00.121 |
tpcds.53 |
00:00:01.132 |
00:00:01.108 |
00:00:01.105 |
00:00:00.174 |
tpcds.54 |
00:00:01.118 |
00:00:00.709 |
00:00:00.606 |
00:00:00.21 |
tpcds.55 |
00:00:00.414 |
00:00:00.411 |
00:00:00.377 |
00:00:00.134 |
tpcds.56 |
00:00:01.167 |
00:00:00.56 |
00:00:00.615 |
00:00:00.248 |
tpcds.57 |
00:00:03.300 |
— |
00:35:26.212 |
00:00:01.120 |
tpcds.58 |
00:00:01.104 |
00:00:00.839 |
00:00:00.848 |
00:00:00.326 |
tpcds.59 |
00:00:12.126 |
00:01:20.803 |
00:01:21.819 |
00:00:02.224 |
tpcds.60 |
00:00:01.192 |
00:00:00.847 |
00:00:00.761 |
00:00:00.349 |
tpcds.61 |
00:00:01.144 |
00:00:00.74 |
00:00:00.726 |
00:00:00.131 |
tpcds.62 |
00:00:02.273 |
00:00:00.352 |
00:00:00.32 |
00:00:00.197 |
tpcds.63 |
00:00:01.106 |
00:00:01.122 |
00:00:01.121 |
00:00:00.195 |
tpcds.64 |
00:00:11.116 |
00:01:11.712 |
00:01:16.766 |
00:00:01.125 |
tpcds.65 |
00:00:09.958 |
00:00:07.780 |
00:00:08.850 |
00:00:01.100 |
tpcds.66 |
00:00:01.160 |
00:00:00.438 |
00:00:00.497 |
00:00:00.291 |
tpcds.67 |
00:01:41.101 |
not supported |
not supported |
not supported |
tpcds.68 |
00:00:02.230 |
00:00:00.664 |
00:00:00.651 |
00:00:00.245 |
tpcds.69 |
00:00:01.161 |
not supported |
not supported |
not supported |
tpcds.70 |
00:00:04.495 |
not supported |
not supported |
not supported |
tpcds.71 |
00:00:01.105 |
00:00:00.647 |
00:00:00.644 |
00:00:00.218 |
tpcds.72 |
00:00:26.267 |
00:00:00.766 |
00:00:00.790 |
00:00:00.972 |
tpcds.73 |
00:00:01.107 |
00:00:00.351 |
00:00:00.371 |
00:00:00.208 |
tpcds.74 |
00:00:06.679 |
— |
2h timeout |
00:01:54.114 |
tpcds.75 |
00:00:05.583 |
00:00:39.398 |
00:00:39.399 |
00:00:04.477 |
tpcds.76 |
00:00:03.351 |
00:00:04.490 |
00:00:05.534 |
00:00:00.815 |
tpcds.77 |
00:00:01.145 |
not supported |
not supported |
not supported |
tpcds.78 |
00:00:18.180 |
00:01:18.786 |
00:01:17.777 |
00:00:08.890 |
tpcds.79 |
00:00:05.523 |
00:00:01.188 |
00:00:01.182 |
00:00:00.449 |
tpcds.80 |
00:00:02.244 |
00:00:01.177 |
00:00:01.155 |
00:00:00.738 |
tpcds.81 |
00:00:00.977 |
— |
01:50:21.662 |
00:00:07.747 |
tpcds.82 |
00:00:09.908 |
not supported |
not supported |
not supported |
tpcds.83 |
00:00:01.106 |
00:00:00.576 |
00:00:00.606 |
00:00:00.338 |
tpcds.84 |
00:00:00.619 |
00:00:00.188 |
00:00:00.199 |
00:00:00.122 |
tpcds.85 |
00:00:02.208 |
00:00:00.279 |
00:00:00.298 |
00:00:00.191 |
tpcds.86 |
00:00:01.112 |
not supported |
not supported |
not supported |
tpcds.87 |
00:00:05.542 |
00:00:15.151 |
00:00:15.154 |
00:00:02.211 |
tpcds.88 |
00:00:14.144 |
00:00:01.191 |
00:00:02.209 |
00:00:00.606 |
tpcds.89 |
00:00:01.114 |
00:00:01.120 |
00:00:01.120 |
00:00:00.197 |
tpcds.90 |
00:00:01.167 |
00:00:00.289 |
00:00:00.289 |
00:00:00.112 |
tpcds.91 |
00:00:00.698 |
00:00:00.159 |
00:00:00.151 |
00:00:00.127 |
tpcds.92 |
00:00:00.611 |
not supported |
not supported |
not supported |
tpcds.93 |
00:00:04.465 |
00:00:00.197 |
00:00:00.220 |
00:00:00.102 |
tpcds.94 |
00:00:03.314 |
not supported |
not supported |
not supported |
tpcds.95 |
00:00:23.236 |
not supported |
not supported |
not supported |
tpcds.96 |
00:00:03.327 |
00:00:00.352 |
00:00:00.341 |
00:00:00.131 |
tpcds.97 |
00:00:07.708 |
00:00:00.825 |
00:00:00.638 |
00:00:00.195 |
tpcds.98 |
00:00:00.673 |
00:00:00.472 |
00:00:00.417 |
00:00:00.168 |
tpcds.99 |
00:00:03.344 |
00:00:00.764 |
00:00:00.476 |
00:00:00.178 |
Предлагаю детальнее рассмотреть один из тестов, в которых разница производительности была наибольшей и выполнение которых я остановил по тайм-ауту:
| Test | Greenplum (scale factor 100) | Citus (scale factor 100) | Citus (scale factor 10) | Citus (scale factor 1) |
|---|---|---|---|---|
tpcds.01 |
00:00:01.131 |
— |
2h timeout |
00:02:38.158 |
Сам запрос:
WITH customer_total_return AS
(
SELECT
sr_customer_sk AS ctr_customer_sk,
sr_store_sk AS ctr_store_sk,
SUM(SR_RETURN_AMT_INC_TAX) AS ctr_total_return
FROM store_returns, date_dim
WHERE
sr_returned_date_sk = d_date_sk AND d_year = 1999
GROUP BY sr_customer_sk, sr_store_sk
)
SELECT c_customer_id
FROM customer_total_return ctr1, store, customer
WHERE ctr1.ctr_total_return > (SELECT avg(ctr_total_return) * 1.2
FROM customer_total_return ctr2
WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk)
AND s_store_sk = ctr1.ctr_store_sk
AND s_state = 'TN'
AND ctr1.ctr_customer_sk = c_customer_sk
ORDER BY c_customer_id
LIMIT 100;Особенность данного запроса во вложенном связанном подзапросе.
Для каждой строки из табличного выражения customer_total_return нужно определить, является ли значение ctr_total_return для пары покупатель-магазин (sr_customer_sk и sr_store_sk) больше, чем среднее значение для магазина, плюс 20% к этому среднему.
Таким образом, в лоб эта задача решается перебором всего множества вычисленного табличного выражения ctr_total_return и сравнением значение атрибута ctr_total_return с результатом агрегирующей функции SUM для данного магазина.
Судя по плану, который выдаёт Citus, он именно так и делает.
План EXPLAIN для Citus:
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
Custom Scan (Citus Adaptive)
-> Distributed Subplan 62_1 (1)
-> HashAggregate
Group Key: remote_scan.ctr_customer_sk, remote_scan.ctr_store_sk
-> Custom Scan (Citus Adaptive)
Task Count: 32 (2)
Tasks Shown: One of 32
-> Task
Node: host=localhost port=8002 dbname=postgres
-> GroupAggregate
Group Key: store_returns.sr_customer_sk, store_returns.sr_store_sk
-> Sort
Sort Key: store_returns.sr_customer_sk, store_returns.sr_store_sk
-> Nested Loop (3)
-> Seq Scan on store_returns_102358 store_returns
-> Memoize
Cache Key: store_returns.sr_returned_date_sk
Cache Mode: logical
-> Index Scan using date_dim_pkey_102318 on date_dim_102318 date_dim (4)
Index Cond: (d_date_sk = store_returns.sr_returned_date_sk)
Filter: (d_year = 1999)
Task Count: 1
Tasks Shown: All
-> Task
Node: host=localhost port=8000 dbname=postgres
-> Limit
-> Sort
Sort Key: customer.c_customer_id
-> Nested Loop
-> Nested Loop
Join Filter: (intermediate_result.ctr_store_sk = store.s_store_sk)
-> Function Scan on read_intermediate_result intermediate_result
Filter: (ctr_total_return > (SubPlan 1))
SubPlan 1
-> Aggregate
-> Function Scan on read_intermediate_result intermediate_result_1
Filter: (intermediate_result.ctr_store_sk = ctr_store_sk)
-> Materialize
-> Seq Scan on store_102357 store
Filter: ((s_state)::text = 'TN'::text)
-> Index Scan using customer_pkey_102315 on customer_102315 customer
Index Cond: (c_customer_sk = intermediate_result.ctr_customer_sk)Как видно из плана, Citus принял решение оформить табличное выражение customer_total_return как распределенный подплан (маркер 1).
Внутри план был распределён по 32 таскам исходя из числа шардов таблицы store_returns по умолчанию равным 32 (маркер 2).
Выбор соединения Nested Loop (маркер 3), видимо, справедлив для данного случая, так как текущая TPC-DS реализация строит индексы по некоторым полям и такой индекс и был выбран для соединения с таблицей date_dim (маркер 4).
Выполнение этого подплана привело с созданию промежуточного файла, который уже использовался в основном запросе, выполнявшемся на координаторе. Для этого запроса приходится выполнять коррелированный вложенный запрос:
where ctr1.ctr_total_return > (select avg(ctr_total_return) * 1.2
from customer_total_return ctr2
where ctr1.ctr_store_sk = ctr2.ctr_store_sk)Этой части соответствует такой EXPLAIN-план выполнения:
-> Nested Loop (cost=0.29..12733.24 rows=20 width=17)
-> Nested Loop (cost=0.00..12603.32 rows=20 width=4) (1)
Join Filter: (intermediate_result.ctr_store_sk = store.s_store_sk)
-> Function Scan on read_intermediate_result intermediate_result (cost=0.00..12542.50 rows=333 width=8) (2)
Filter: (ctr_total_return > (SubPlan 1))
SubPlan 1
-> Aggregate (cost=12.52..12.53 rows=1 width=32)
-> Function Scan on read_intermediate_result intermediate_result_1 (cost=0.00..12.50 rows=5 width=32)
Filter: (intermediate_result.ctr_store_sk = ctr_store_sk)и фактический EXPLAIN ANALYZE:
-> Materialize (cost=0.00..50601517.68 rows=20 width=4) (actual time=0.031..154.745 rows=12734 loops=665)
-> Nested Loop (cost=0.00..50601517.58 rows=20 width=4) (actual time=20.473..102683.089 rows=12753 loops=1) (1)
Join Filter: (intermediate_result.ctr_store_sk = store.s_store_sk)
Rows Removed by Join Filter: 55645
-> Function Scan on read_intermediate_result intermediate_result (cost=0.00..50587820.49 rows=76412 width=8) (actual time=20.458..102674
.660 rows=12753 loops=1)
Filter: (ctr_total_return > (SubPlan 1))
Rows Removed by Filter: 37009
SubPlan 1
-> Aggregate (cost=662.02..662.03 rows=1 width=32) (actual time=2.063..2.063 rows=1 loops=49762) (2)
-> Function Scan on read_intermediate_result intermediate_result_1 (cost=0.00..570.65 rows=36545 width=32) (actual time=0.013..1.566 rows=8123 loops=49762) (3)
Filter: (intermediate_result.ctr_store_sk = ctr_store_sk) (4)
Rows Removed by Filter: 41639
-> Materialize (cost=0.00..1.21 rows=12 width=4) (actual time=0.000..0.000 rows=5 loops=12753)
-> Seq Scan on store_102357 store (cost=0.00..1.15 rows=12 width=4) (actual time=0.009..0.012 rows=10 loops=1)
Filter: ((s_state)::text = 'TN'::text)Как видно, планировщику пришлось принимать решение на некорректных входных данных.
В отсутствии других вариантов (так как используется оценка для функции read_intermediate_result) данный узел Function Scan on read_intermediate_result intermediate_result оценил, что вернёт rows=333 строк (маркер 2 в выводе EXPLAIN).
На самом деле, судя по EXPLAIN ANALYZE, строк на один порядок больше (маркер 3 в выводе EXPLAIN ANALYZE). Для другого scale factor ошибка будет больше.
Самая медленная часть плана — это как раз Nested Loop (маркер 1) по результатам выполнения подплана. Для каждой строки из промежуточного результата вызывается подсчёт агрегирующей функции (маркер 2), чтобы рассчитать значение SUM для данного ctr_store_sk (маркер 4). Выглядит не слишком оптимальным.
Greenplum и GPORCA, как мне представляется, строят более продвинутый план, который и приводит к такой существенной разнице во времени:
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------
Gather Motion 2:1 (slice9; segments: 2)
Merge Key: customer.c_customer_id
-> Sort
Sort Key: customer.c_customer_id
-> Sequence
-> Shared Scan (share slice:id 9:0) (1)
-> Materialize
-> HashAggregate
Group Key: store_returns.sr_customer_sk, store_returns.sr_store_sk
-> Redistribute Motion 2:2 (slice8; segments: 2) (2)
Hash Key: store_returns.sr_customer_sk, store_returns.sr_store_sk
-> Hash Join
Hash Cond: (store_returns.sr_returned_date_sk = date_dim.d_date_sk)
-> Dynamic Seq Scan on store_returns (dynamic scan id: 1)
-> Hash
-> Partition Selector for store_returns (dynamic scan id: 1)
-> Broadcast Motion 2:2 (slice7; segments: 2) (3)
-> Seq Scan on date_dim
Filter: (d_year = 1999)
-> Redistribute Motion 1:2 (slice6)
-> Limit
-> Gather Motion 2:1 (slice5; segments: 2)
Merge Key: customer.c_customer_id
-> Limit
-> Sort
Sort Key: customer.c_customer_id
-> Hash Join
Hash Cond: (customer.c_customer_sk = share0_ref3.sr_customer_sk)
-> Seq Scan on customer
-> Hash
-> Redistribute Motion 2:2 (slice4; segments: 2)
Hash Key: share0_ref3.sr_customer_sk
-> Hash Join
Hash Cond: (share0_ref3.sr_store_sk = store.s_store_sk)
-> Hash Join
Hash Cond: (share0_ref3.sr_store_sk = share0_ref2.sr_store_sk)
Join Filter: (share0_ref3.ctr_total_return > (((pg_catalog.avg((avg(share0_ref2.ctr_total_return
)))) * 1.2))) (4)
-> Shared Scan (share slice:id 4:0)
-> Hash
-> Broadcast Motion 2:2 (slice2; segments: 2) (5)
-> Result
-> Result
-> HashAggregate
Group Key: hare0_ref2.sr_store_sk
-> Redistribute Motion 2:2 (slice1; segments: 2)
Hash Key: share0_ref2.sr_store_sk
-> Result
-> HashAggregate (6)
Group Key: share0_ref2.sr_store_sk
-> Shared Scan (share slice:id 1:0)
-> Hash
-> Broadcast Motion 2:2 (slice3; segments: 2)
-> Seq Scan on store
Filter: ((s_state)::text = 'TN'::text)
Optimizer: Pivotal Optimizer (GPORCA)С точки зрения близких частей плана, можно отметить, что распределенной, параллельной части плана Citus можно поставить соответствие Shared Scan (маркер 1).
По факту, это то же самое действие и результат с точки зрения данных.
У Greenplum в данной реализации TPC-DS в распоряжении какие-либо индексы отсутствуют, все таблицы DISTRIBUTED BY, поэтому таблицу date_dim приходится перераспределять через Broadcast Motion на все сегменты (маркер 2). Затем таблица store_returns соединяется с date_dim, агрегируется по столбцам sr_customer_sk и sr_store_sk и перераспределяется по сегментам по этим двум столбцам (маркер 3).
Ключевое отличие заключается в том, как Greenplum обрабатывает вложенный коррелированный подзапрос.
Во-первых, осуществляется группировка по полю sr_store_sk и предрасчет фукнции SUM (маркер 6).
Во-вторых, это множество строк перераспределяется Broadcast Motion опять-таки по атрибуту sr_store_sk (маркер 5).
Это позволит сделать локальный Hash Join исходного множества из Shared Scan с уже предрассчитанным множеством по колонке sr_store_sk и таким образом просто применить условие Join Filter по ctr_total_return с учетом выражения avg(ctr_total_return) * 1.2 (маркер 4).
Этот шаг позволяет выполнить запрос на несколько порядков быстрее. Citus вычисляет агрегат в рамках вложенного корреллированного запроса для каждой строки из inner-множества для соединения Nested Loop.
Greenplum все рассчитал и просто осуществляет Hash Join с тем же условием.
Ради интереса я сделал детализацию первого запроса. Тут четко видно, где Citus проводит больше всего времени.
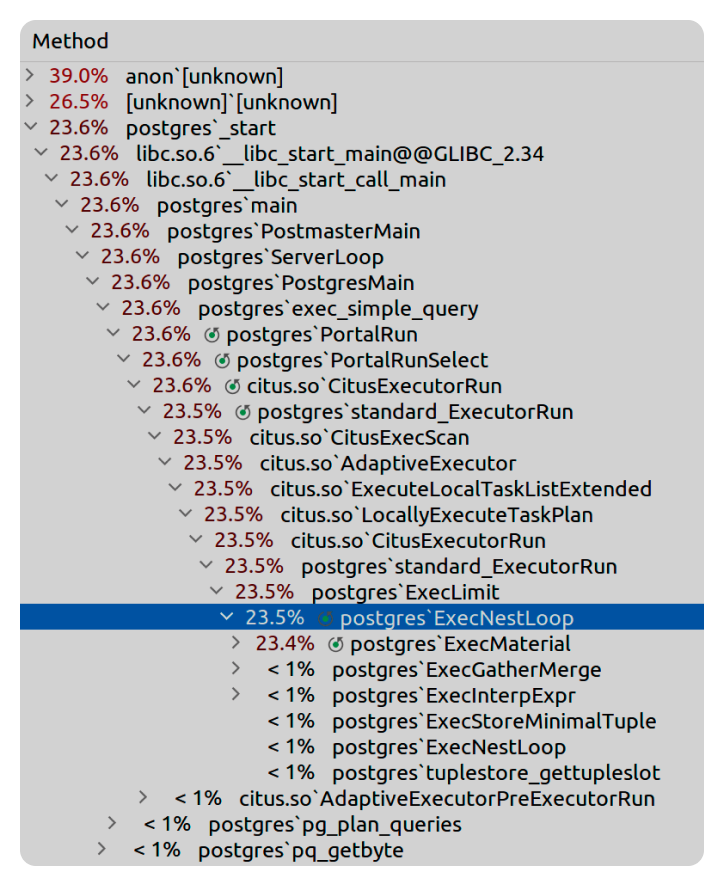
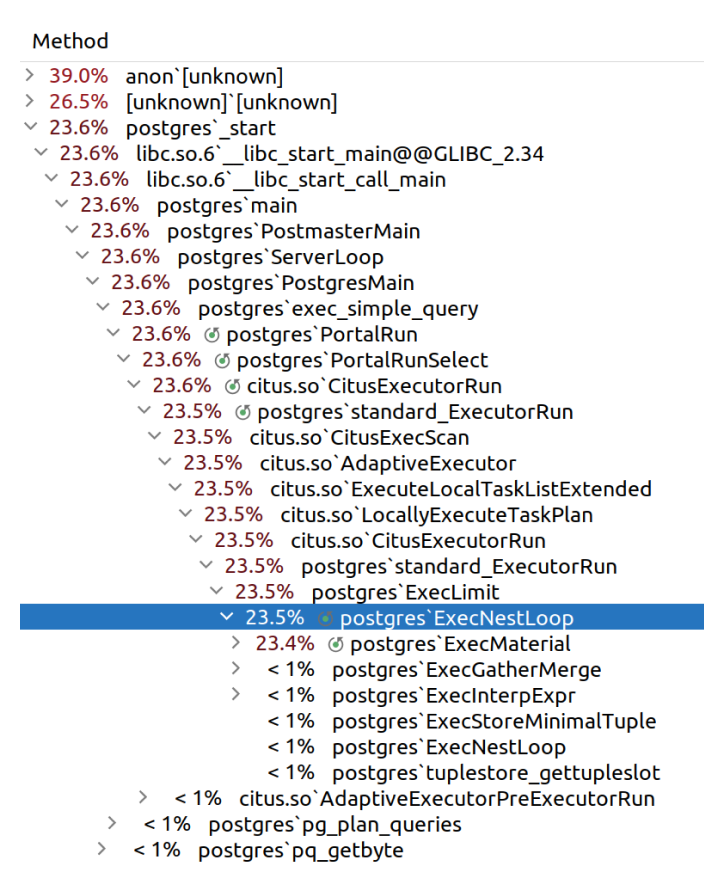
Итоги
Для себя я сделал следующие выводы:
-
Использование Citus для OLAP для ad-hoc запросов будет вызывать затруднения. Подгонять co-located колонки под запросы при наличии значимых запросов данных будет крайне затруднительно, вопрос удобства оставим за скобками. Кто-то скажет, что выполнение подобных запросов — не целевая задача Citus и прилагается бонусом, однако возможности представляются, в планировщике есть поддержка, и авторы, судя по всему, работали в этом направлении.
-
Планировщик Greenplum со сложными OLAP-запросами справляется лучше.
-
Использование сильно партицированных таблиц с Citus — это, по моему мнению, "бомба", которая может рвануть по мере роста количества таблиц в базе данных. Повторюсь, что на каждую листовую партицию создаётся в общем по умолчанию по 32 таблицы-шарда. Кто-то будет создавать больше, что может еще больше усугубить ситуацию с количеством таблиц.
-
Citus проще масштабировать, есть возможности вывести ноду из кластера одним API-вызовом.
-
Для задач быстро горизонтально отмасштабировать имеющийся PostgreSQL кластер — отличное средство.
-
Особых сложностей вручную развернуть небольшой Citus-кластер нет, однако для больших установок уже не хватает доступных возможностей автоматизированного деплоя кластера. У Greenplum для ручных деплоев по крайней мере есть
gpinitsystem. -
Рассмотренные стратегии ребаланса позволяют поддерживать более широкий круг сценариев использования решения, на которые Greenplum не ориентирован.
-
Интересной особенностью Citus является возможность соединяться с рабочими узлами и запускать запросы с этих узлов напрямую. Таким образом, любой узел может выступать координатором запросов. На данный момент в исключениях запросы, которые меняют состояние кластера с точки зрения метаданных (DDL-запросы,
create_distributed_tableи т.д.). В этих случаях потребуется запускать запрос выделенного координатора. -
При работе с Citus нужно учитывать, что распределенные снимки в этом решении не поддерживаются, так что нужно помнить про отсутствие гарантий соблюдения правил видимости для закоммиченных транзакций в рамках всего кластера.