Три способа отследить запросы Greenplum, которые "отъедают" слишком много ресурсов


Привет! Меня зовут Роман, я работаю разработчиком в компании Arenadata, где мы решаем много задач, связанных с Greenplum. Как-то мне представился случай разобраться с одним непростым, но вполне типичным для этой СУБД кейсом. Необходимо было выяснить, на обработку каких запросов уходит неадекватно много системных ресурсов. В этой статье мне бы хотелось поделиться своими наработками и рассказать о трех проверенных мной способах мониторинга утилизации системных ресурсов, потребляемых запросами в Greenplum.
Способ 1. Запрос с помощью EXPLAIN ANALYZE
Первый способ, который можно использовать, — это выполнить запрос с помощью EXPLAIN ANALYZE и разобрать план запроса. Так можно получить разнообразную информацию по памяти, например:
-
Количество памяти, выделенное запросу.
-
Количество выполненных слайсов. Слайс — это независимая часть плана. Может выполняться как параллельно, так и последовательно с остальными частями. Каждый слайс может состоять из нескольких операторов.
-
Выделенное количество памяти под каждый слайс и другие параметры.
Если включить дополнительные конфигурационные параметры, например, explain_memory_verbosity и gp_enable_explain_allstat, а вместо EXPLAIN ANALYZE выполнить EXPLAIN (ANALYZE, VERBOSE), можно получить еще больше данных о состоянии памяти:
-
Сколько потребовалось памяти для выполнения всех слайсов и каждого слайса по отдельности.
-
Сколько памяти было задействовано для выполнения запроса в разрезе каждого слайса.
-
Информация по памяти в разрезе операций внутри запроса.
-
Подробная информация по использованию памяти в разрезе каждого сегмента и другие параметры.
Тем, кто силен духом, можно попробовать выполнить еще и EXPLAIN (ANALYZE, VERBOSE) SELECT к небольшой таблице с включенными параметрами explain_memory_verbosity и gp_enable_explain_allstat. Результатом команды должен быть план запроса с подробными данными по операциям, которые выполняли сегменты при выполнении этого запроса с расширенной информацией по памяти. Разобраться в таком плане будет достаточно непросто, и сложность заключается в том, что этот план можно получить только после завершения выполнения запроса. А что, если запрос не выполняется и падает по памяти? Или необходимо посмотреть текущее потребление памяти? Или нужна информация по другим метрикам? Увы, но в этом случае EXPLAIN ANALYZE не помощник.
Способ 2. Использование системных представлений
Существует несколько системных представлений, которые можно использовать для анализа потребляемых ресурсов, таких как память и CPU.
Cхема gp_toolkit
Если в качестве контроля ресурсов используется механизм ресурсных групп, то любой запрос, который работает внутри Greenplum, всегда работает в рамках определенной ресурсной группы. Выбор ресурсной группы зависит от юзера, запустившего запрос, так как именно пользователи привязаны к конкретной ресурсной группе. Информацию о принадлежности запроса к конкретной ресурсной группе можно найти в системном представлении pg_stat_activity в поле rsgname. В случае, если необходимо понять, к какой ресурсной группе привязан пользователь, можно воспользоваться следующим запросом:
SELECT rolname, rsgname FROM pg_roles, pg_resgroup WHERE pg_roles.rolresgroup = pg_resgroup.oid;В сборке от Arenadata Greenplum использует механизм ресурсных групп по умолчанию. В "ванильном" Greenplum по умолчанию используются ресурсные очереди.
При использовании механизма ресурсных групп для мониторинга памяти и CPU можно задействовать представления из схемы gp_toolkit.
В Greenplum 5 и Greenplum 6 эти представления реализованы по-разному, поэтому расскажу про каждый отдельно.
Greenplum 5 (GP5)
В версии GP5 доступно только одно представление gp_toolkit.gp_resgroup_status, в котором есть поля cpu_usage и memory_usage. Данные представлены в JSON-формате и показывают утилизацию ресурсов в соответствующих ресурсных группах по каждому сегменту.
Есть небольшая особенность отображения утилизации по CPU: если сегменты расположены на одном сегмент-хосте, то они будут показывать одинаковое значение CPU, а именно утилизацию самого сегмент-хоста, на котором расположены данные сегменты.
Поле cpu_usage показывает текущую утилизацию CPU:
{"-1":0.02, "0":86.96, "1":87.14, "2":87.15, "3":87.10}
Поле memory_usage показывает текущую утилизацию по памяти:
{"-1":{"used":11, "available":2534, "quota_used":508, "quota_available":0, "quota_granted":508, "quota_proposed":508, "shared_used":0, "shared_available":2037, "shared_granted":2037, "shared_proposed":2037},
"0":{"used":164, "available":472, "quota_used":126, "quota_available":0, "quota_granted":126, "quota_proposed":126, "shared_used":38, "shared_available":472, "shared_granted":510, "shared_proposed":510},
"1":{"used":0, "available":636, "quota_used":126, "quota_available":0, "quota_granted":126, "quota_proposed":126, "shared_used":0, "shared_available":510, "shared_granted":510, "shared_proposed":510},
"2":{"used":171, "available":465, "quota_used":126, "quota_available":0, "quota_granted":126, "quota_proposed":126, "shared_used":45, "shared_available":465, "shared_granted":510, "shared_proposed":510},
"3":{"used":0, "available":636, "quota_used":126, "quota_available":0, "quota_granted":126, "quota_proposed":126, "shared_used":0, "shared_available":510, "shared_granted":510, "shared_proposed":510}
}
Поле memory_usage имеет более сложную структуру, поэтому привожу расшифровку ключей данного поля. Все значения указываются в мегабайтах:
-
used— количество памяти, используемой запросом (quota_used+shared_used). -
available— количество доступной памяти для ресурсной группы (quota_available+shared_available). Может быть отрицательным значением, если запрос вышел за рамки потребления памяти ресурсной группы и начал потреблять глобальную память. -
quota_used— количество используемой фиксированной памяти. -
quota_available— количество свободной фиксированной памяти. -
quota_granted— количество фиксированной памяти, которая выделяется с помощью параметраmemory_limitдля ресурсной группы. Значение равноquota_used+quota_available. -
shared_used— количество используемой разделяемой памяти. -
shared_available— количество свободной разделяемой памяти. Тоже может быть отрицательным значением, если запрос вышел за рамки потребления памяти ресурсной группы и начал потреблять глобальную память. -
shared_granted— количество разделяемой памяти, которая выделяется с помощью параметраmemory_shared_quotaдля ресурсной группы. Значение равноshared_used+shared_available.
Greenplum 6 (GP 6)
В GP6, помимо gp_resgroup_status, присутствуют еще два представления:
-
gp_resgroup_status_per_segment -
gp_resgroup_status_per_host
Они работают поверх представления gp_resgroup_status и выдают данные по используемым ресурсам и в разрезе сегментов (gp_resgroup_status_per_segment), и в разрезе сегмент-хостов (gp_resgroup_status_per_host).
Стоит отметить, что в работе с этими представлениями есть ряд ограничений. Во-первых, они показывают данные только в онлайн-режиме, и, к сожалению, нет возможности посмотреть исторические данные. Во-вторых, нельзя сегментировать потребление ресурсов в рамках сессии и в рамках запросов. Поскольку в ресурсной группе одновременно может работать несколько запросов от разных пользователей, нет никакой возможности понять, какой из запросов какую часть ресурсов использует.
Расширение gp_internal_tools
Есть еще одно интересное представление, которое позволяет контролировать ресурсы по памяти в рамках сессии. Оно уже не зависит от того, используете ли вы в качестве контроля ресурсов ресурсные очереди или ресурсные группы. Представление находится в расширении gp_internal_tools и называется session_state.session_level_memory_consumption. Для его использования достаточно установить расширение с помощью команды CREATE EXTENSION gp_internal_tools. Подробное описание полей данного представления можно посмотреть в документации Greenplum.
Результат выполнения запроса к этому представлению будет выглядеть приблизительно так, как показано на рисунке ниже.
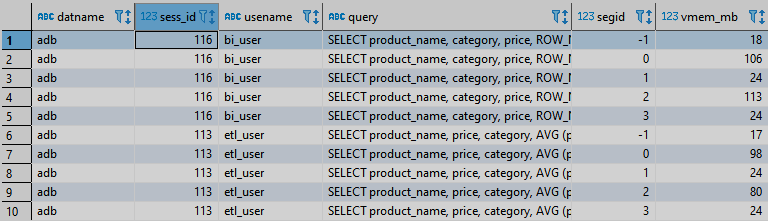
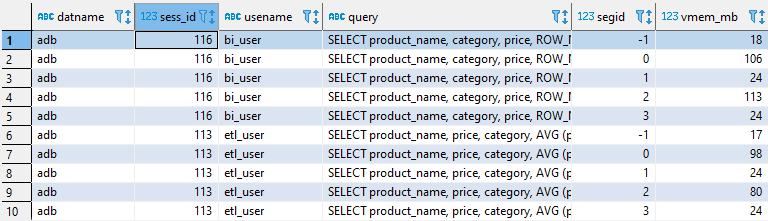
Для контроля памяти нас больше всего интересует поле vmem_mb. Оно отображает, сколько памяти используют запросы в рамках определенной сессии. С помощью данного представления уже можно выделить запросы, которые работают в рамках определенной сессии, а также понять, сколько памяти расходуется в рамках сессии.
Поле sess_id — это номер сессии, в рамках которой осуществляется запрос. По нему можно объединиться с системным представлением pg_stat_activity и получить из него больше информации по текущему запросу. Так как данные представлены для каждого сегмента, потребление памяти можно отследить в разрезе сегментов. А благодаря этому можно увидеть некоторые перекосы по использованию памяти при выполнении запросов, если таковые имеются.
Так же, как и предыдущие представления по ресурсным группам, это представление показывает данные только на момент запроса, т.е. исторических данных нет. Если они необходимы для последующего анализа выполнения запросов, можно сохранять данные во внутреннюю таблицу. Для этого:
-
Создаем внутреннюю таблицу.
-
Добавляем в нее колонку со временем вставки данных.
-
С помощью планировщика задач (например, cron) запускаем
SELECT+INSERTиз представленияsession_state.session_level_memory_consumptionво внутреннюю таблицу.
Такой подход позволяет в динамике отследить, какие запросы работали в системе и сколько памяти было выделено для их выполнения.
Это представление обладает следующей особенностью: для одной и той же сессии оно несколько раз может отображать данные по одному и тому же сегменту (в зависимости от конкретного запроса). Примечательно, что это вовсе не означает, что данный запрос потребляет памяти во столько же раз больше, просто следует иметь это в виду.
Способ 3. Отслеживание метрик процессов
Третий способ, и, как мне видится, он является самым любопытным, — это отслеживание метрик процессов запроса в операционной системе. Каждый запрос, который стартует внутри Greenplum, генерирует процессы на мастер-сервере и сегмент-хостах. Стоит отметить, что этих процессов может быть довольно много, а их количество зависит от сложности запроса и от количества сегментов на сегмент-хосте.
Такие процессы обладают определенными маркерами в аргументах запуска, по которым можно идентифицировать номер сессии, номер сегмента, номер запроса внутри сессии и даже номер слайса.
Например, если запустить SELECT * FROM <table_name> и во время его выполнения обратить внимание на процессы мастер-сервера и сегмент-хоста, то на мастере мы увидим примерно следующий процесс:
gpadmin 15322 0.3 0.5 645872 47192 ? Ssl 07:49 0:00 postgres: 5432, gpadmin adb [local] con9 cmd8 SELECT
На сегмент-сервере этот же запрос будет порождать следующие процессы:
gpadmin 12020 2.4 0.5 870812 40096 ? Dsl 07:50 0:00 postgres: 10000, gpadmin adb 10.92.8.40(40642) con9 seg1 cmd9 slice1 MPPEXEC SELECT gpadmin 12021 2.6 0.5 870892 41404 ? Dsl 07:50 0:00 postgres: 10001, gpadmin adb 10.92.8.40(54924) con9 seg3 cmd9 slice1 MPPEXEC SELECT
В этом способе мониторинга важно понимать также значения аргументов запуска процессов на мастер-сервере и сегмент-хосте. Расскажу о них кратко.
-
Номер сессии. Речь про параметр
con9. Он отвечает за номер сессии, в рамках которой осуществляется запрос. По этому номеру можно связать все процессы на мастер-сервере и на сегмент-хостах, которые порождаются запросами, работающими в рамках данной сессии. И этот же номер сессии присутствует в полеsess_idсистемного представленияpg_stat_activity, откуда можно получить дополнительную информацию о запросе. -
Идентификатор сегмента. В аргументах процесса присутствует также номер сегмента. В приведенном примере на сегмент-хостах он представлен в виде параметров
seg3иseg1. В процессе на мастер-сервере он может отсутствовать, но на мастер-сервере всегда один сегмент, и его номер равен -1. Номер сегмента важен в том случае, если вам необходимо определять неравномерность потребления ресурсов разными сегментами. -
Номер команды. Есть еще параметр
cmd(command count), который отвечает за номер команды внутри данной сессии. В рамках одного запроса он может различаться на мастер-сервере и на сегментах. Более того, даже в рамках одного запросаcmdможет быть разным на одном и том же сегменте. Например, это происходит, когда мы используем функции, а внутри этих функций есть набор команд и запросов, которые выполняются в рамках данной функции. Таким образом, выходит, что при выполнении определенной функции каждая команда внутри нее будет иметь разный command count, но с точки зрения пользователя это будет выглядеть, как один запрос. -
Номер слайса. Еще из аргументов процесса можно получить номер слайса. В приведенном примере на сегмент-хостах слайс представлен параметром
slice1. На мастер-сервере, в аргументах процесса, упоминание о слайсе отсутствует. Однако в некоторых случаях этот параметр может присутствовать и в процессе на мастер-сервере. Это означает, что данная часть запроса выполнялась непосредственно на мастер-сервере. Так мы можем получить данные по выполняемому запросу в разрезе слайсов и посмотреть, какой из слайсов требует больше всего памяти или больше всего использует CPU.
Когда разобрались с аргументами процессов, дальше уже дело техники. По каждому процессу собираем необходимые метрики, агрегируем данные со всех сегментов по номеру сессии (он же con в аргументах процесса и он же sess_id в системном представлении pg_stat_activity) и получаем метрики по запросу, который выполнялся внутри Greenplum в рамках определенной сессии на момент сбора метрики.
Сбор и агрегация — это уже процесс творческий. Можно, например, использовать популярные системы мониторинга, которые включают в себя как агентов мониторинга, которые умеют собирать необходимые метрики по процессам, так и централизованную базу данных, в которой можно агрегировать данные. Также можно использовать свои собственные скрипты и свою базу данных.
Какие метрики по процессам можно собирать?
Утилизация CPU
Здесь есть свои нюансы. Например, утилита ps показывает среднее значение с момента появления процесса в системе. Это не очень удобно, когда нужно отслеживать пиковые нагрузки в определенный момент времени. Допустим, запрос продолжительное время работал над каким-то слайсом и не требовал особых ресурсов, но в какой-то момент времени слайс отработал, и в дело вступил очередной слайс, которому необходимы большие ресурсы CPU. При этом среднее значение использования CPU будет небольшим, так как процесс данного слайса никаких активных действий не выполнял до текущего момента.
Следовательно, лучше мониторить текущую загрузку CPU и уже на основе этих данных рассчитывать среднее значение за определенный период времени, если это необходимо.
Текущую утилизацию CPU можно получить с помощью утилит top или htop. Можно воспользоваться данными из файлов /proc/uptime и /proc/[pid]/stat. Если используем данные из файлов, то алгоритм вычисления будет следующий:
-
Получаем количество тиков в секунду (
clk_tck) с помощью командыgetconf CLK_TCK. -
Получаем время безотказной работы (
cputime), используя первый параметр файла /proc/uptime. -
Получаем общее время (
proctime), затраченное процессом (utime(14) + stime(15)) из /proc/[pid]/stat. -
Ожидаем 1 секунду и повторяем шаги 2 и 3.
-
Рассчитываем процент использования CPU по формуле:
Нагрузка на дисковую подсистему
Здесь тоже есть ряд утилит, которые отображают данные в разрезе процессов, например, iotop или pidstat, либо можно получать данные из файла процесса /proc/[pid]/io.
Важно понимать, что это только часть нагрузки на дисковую подсистему, которая генерируется именно этим процессом. Не стоит забывать о фоновых служебных процессах, которые синхронизируют данные между основным сегментом и его зеркалом, пишут данные в журнал транзакций и так далее. В зависимости от типа запроса эти служебные процессы могут генерировать дополнительную нагрузку на дисковую подсистему.
Память
Это самая интересная метрика. Напомню, что в Greenplum существует два основных системных представления, которые показывают данные по памяти:
-
Представление
session_state.session_level_memory_consumption(полеvmem_mb), которое показывает общий объем используемой памяти в рамках сессии. -
Представление по ресурсным группам, отображающее данные по памяти (используется запросами, работающими в рамках конкретной ресурсной группы).
В зависимости от сложности запроса данные по памяти в этих системных представлениях могут значительно различаться. Это связано с некоторыми тонкостями учета предоставленной памяти процессу, за который отвечает внутренний механизм Greenplum. Обычно цифры в представлении session_level_memory_consumption больше, чем в представлении по ресурсным группам.
На самом деле это не так критично, так как существует корреляция между значениями в двух представлениях.
Ниже представлены графики потребления памяти из двух представлений по 97 запросам с небольшим объемом данных стандартного теста TPC-DS.
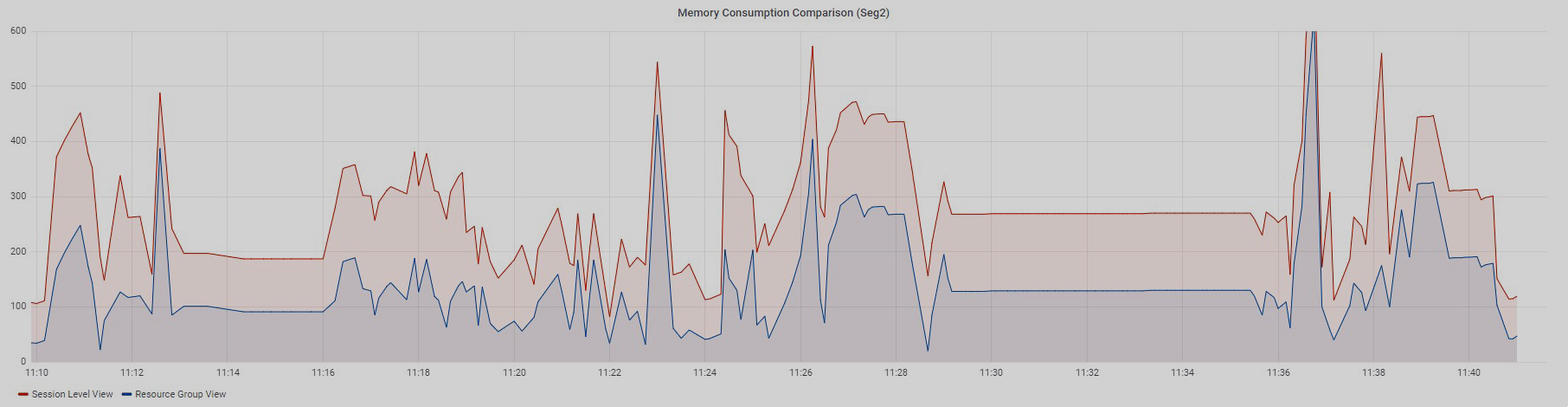
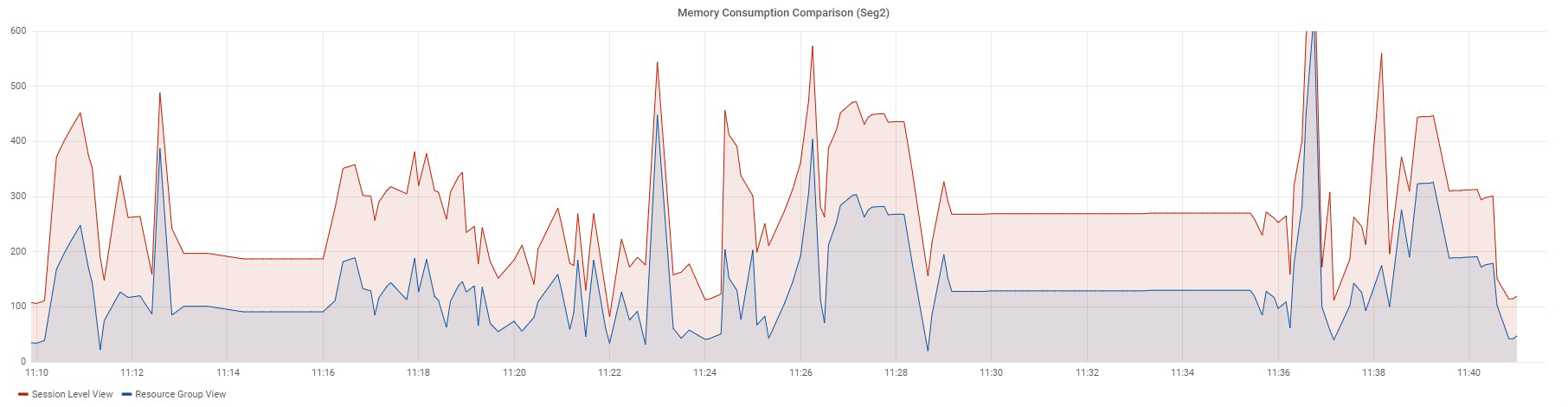
Запросы выполнялись последовательно.
График Resource Group View построен по данным из колонки memory_used представления gp_toolkit.gp_resgroup_status_per_segment. А график Session Level View построен на основе данных из колонки vmem_mb из представления session_state.session_level_memory_consumption.
Оба графика отображают данные по одному сегменту. По графикам видно, что если потребление памяти в ресурсной группе увеличивается, то увеличивается и значение из представления session_level_memory_consumption и наоборот.
Таким образом, с помощью представления session_level_memory_consumption можно отслеживать тренд потребления памяти запросом, работающим в рамках определенной сессии.
Но вернемся к нашим процессам, которые порождаются запросами внутри Greenplum. Попробуем выяснить, какое количество памяти потребляется процессами, и сравнить полученные цифры с памятью из системных представлений.
С помощью команды ps -eo pid, rss, command мы можем получить данные о выделенной процессу оперативной памяти, которая называется Resident Set Size.
Алгоритм расчета будет следующим:
-
Получаем PID всех процессов на мастер-сервере и сегмент-хостах, которые относятся к запросам. Чуть выше я уже показал, как выглядят эти процессы. Исключаем процессы, которые перешли в состояние
idle(если процесс перешел в состояниеidle, это значит, что данный процесс уже отработал или находится в ожидании). -
Для каждого процесса получаем данные по Resident Set Size.
-
Суммируем полученные значения от процессов и группируем их по
session_id(этоcmdв аргументах процесса) иseg_id(это значениеsegв аргументах процесса). Получаем результат, который представлен на графике.
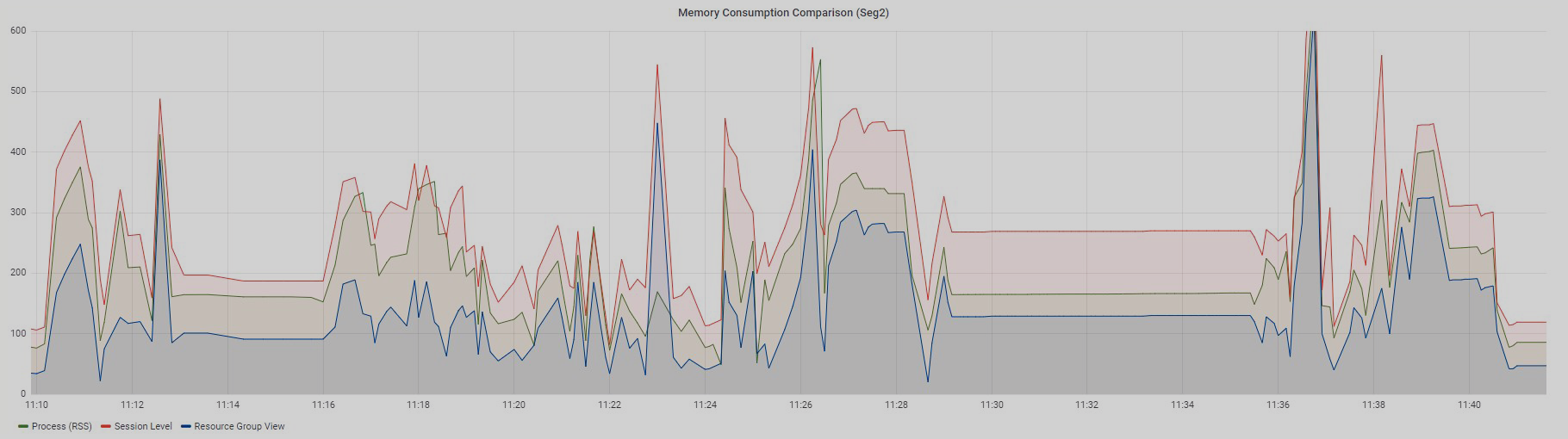
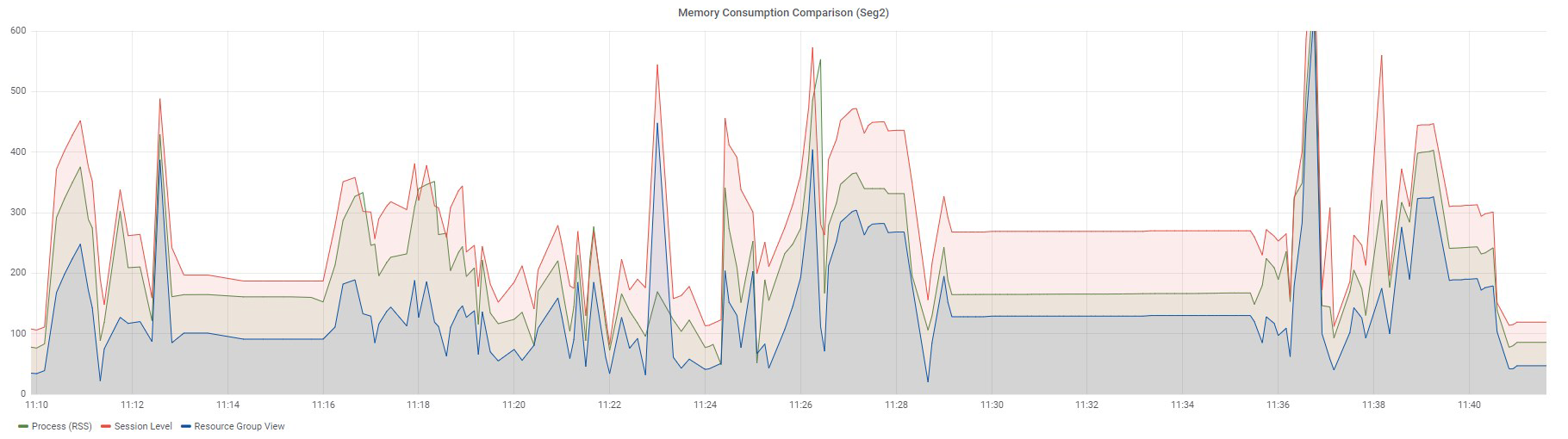
График Process (RSS), который отображает сумму RSS по всем процессам определенного запроса, находится где-то посередине между графиками Session Level View и Resource Group View и повторяет тренд двух сопутствующих графиков.
Помимо Resident Set Size у процессов есть еще 2 вида памяти, которые называются Unique set size и Proportional set size. Результаты экспериментов показали, что если нам необходимо приблизиться к данным, которые отображаются в представлении по ресурсным группам, то ближе всего к этому значению — Unique set size.
Алгоритм расчета применяем такой же, как и при использовании данных по RSS, но только теперь нам нужны данные по памяти USS. Можно воспользоваться утилитой smem или получить данные из файла /proc/[pid]/smaps. Если использовать файл smaps, то значение USS можно получить, просуммировав все значения для полей Private_Clean и Private_Dirty. Значение будет в килобайтах.
Если проделаем все операции алгоритма, то получим значение, близкое к значению memory_used из представления gp_resgroup_status_per_segment, полученного в тот же самый момент времени.
Ниже представлены графики все тех же 97 запросов по двум сегментам: Seg1 и Seg2.
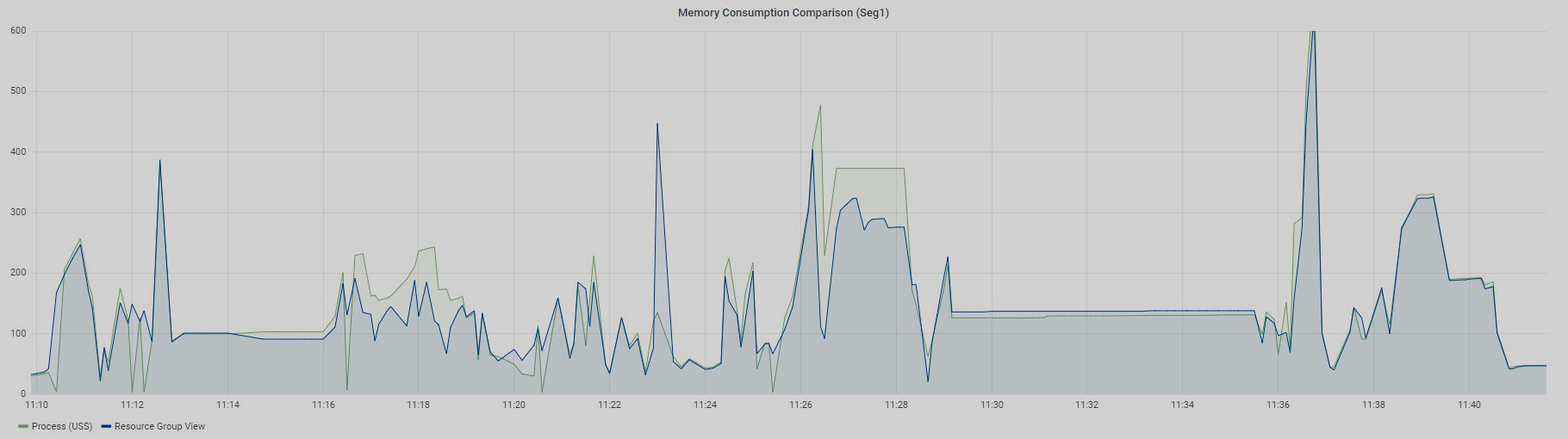
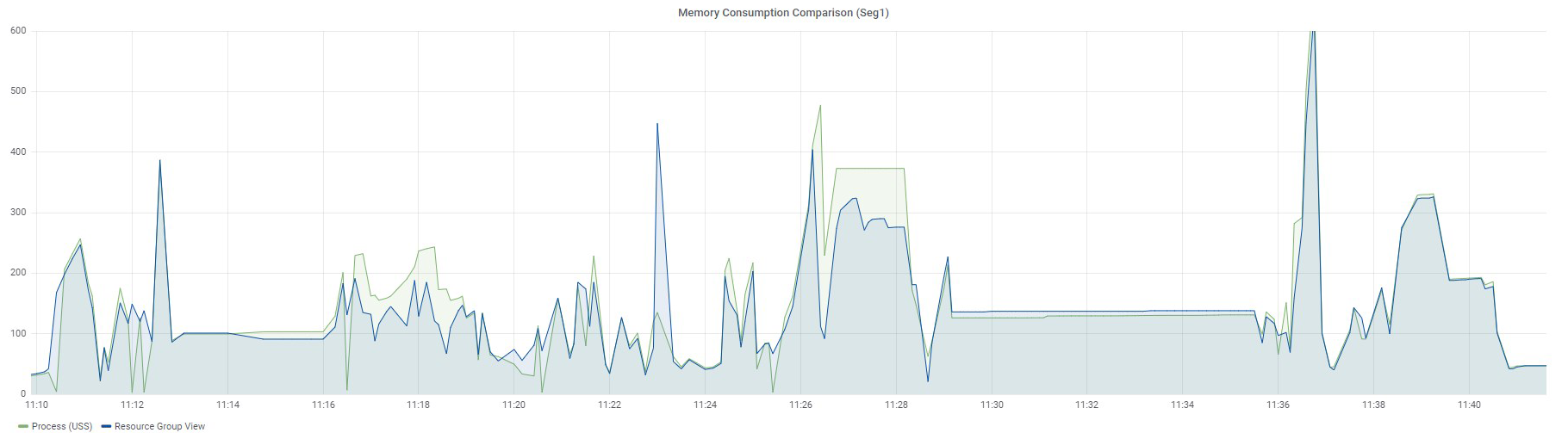
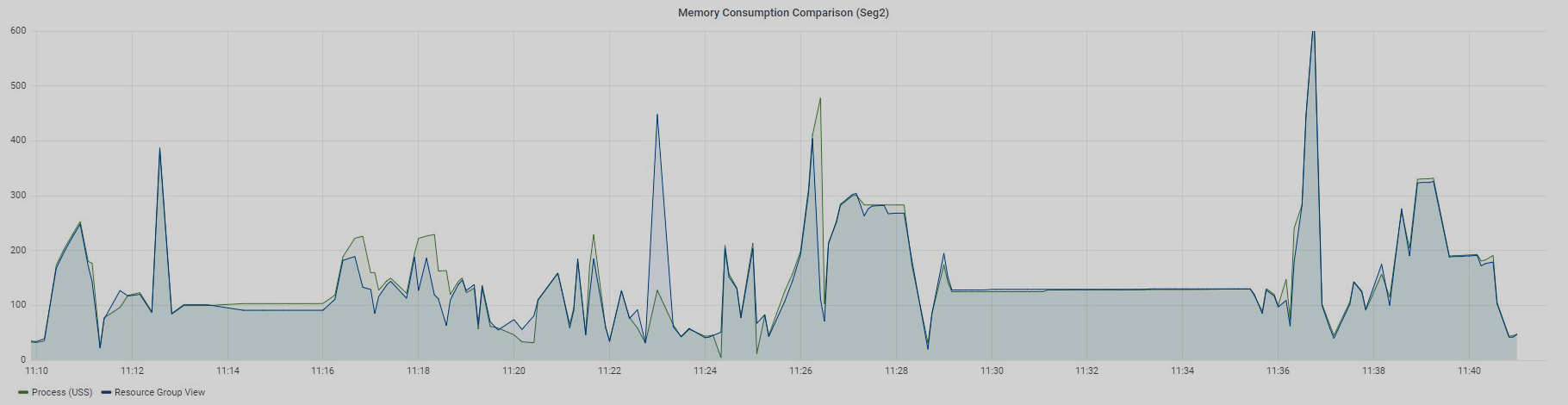
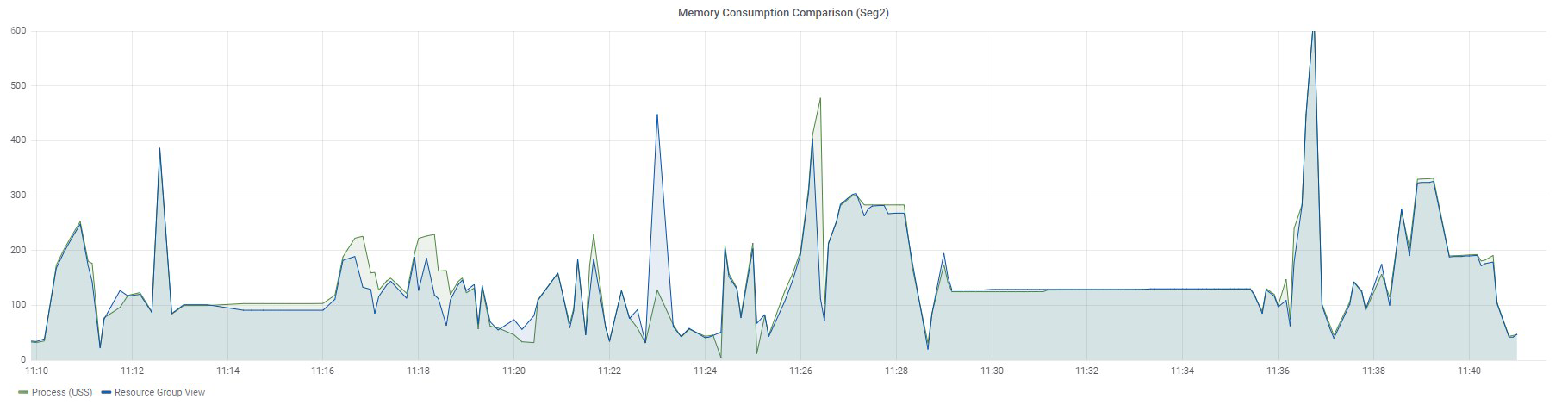
Запросы выполнялись последовательно, и это значит, что в конкретный момент времени в измеряемой ресурсной группе работал только один запрос. Напомню, что в представлениях по ресурсным группам нет возможности разделить использование памяти по каждому запросу. Можно увидеть только общее значение для всех запросов, работающих в конкретной ресурсной группе.
График Resource Group View отображает данные из представления gp_resgroup_status_per_segment по значениям в колонке memory_used, а график Process (USS) демонстрирует сумму USS по всем процессам определенного запроса.
Четкого совпадения тоже нет, но уже очень близкие значения, особенно для Seg2. Почему я говорю "близкие"? Дело в том, что Greenplum имеет свой внутренний механизм учета виртуальной памяти vmtracker, который отвечает за то, сколько выделить памяти запросу, сколько памяти осталось свободной, можно ли выдать дополнительную память запросу, или же свободной памяти нет. Как эта виртуальная память соотносится с памятью, потребляемой процессами запросов, — это вопрос отдельного изучения, который мне еще предстоит когда-нибудь выяснить. Результаты, о которых я рассказал, были получены экспериментальным путем.
Разумеется, у вас может возникнуть резонный вопрос: зачем нам метрики от процессов, если есть системные представления и не надо заморачиваться сбором, агрегацией и хранением этих метрик?
Отвечу следующее.
Во-первых, если мы используем данные из представлений по ресурсным группам, то выделить конкретный запрос в этой группе можно только в том случае, если он работает один в рамках этой ресурсной группы. Если параллельно работающих процессов два и более, то разделить данные ресурсы невозможно.
Во-вторых, это дает возможность увидеть потребление ресурсов в разрезе слайсов. Мы почти на уровне операторов внутри слайсов можем узнать потребление памяти. Какие операторы выполняются внутри слайса, можно посмотреть с помощью команды EXPLAIN. Эта команда отобразит план выполнения запроса, но физически не будет выполнять запрос.
В-третьих, можно собирать любые метрики процессов, которые необходимы для статистики, но которых нет в системных представлениях.
Это, пожалуй, все, что я хотел рассказать о системных метриках, которые можно собирать и контролировать в рамках работы запросов внутри Greenplum.