Evaluating lock-free list approach


Introduction
Hello from the Greengage DB Core Team!
Let me start with a brief historical reference — Greengage DB was launched in 2024 as an open-source fork of Greenplum, a Massively Parallel Processing (MPP) analytical database management system based on PostgreSQL. We started this project to accommodate the open-source community of Greenplum, which was unexpectedly turned into a proprietary product in May 2024. We ensure further development of Greengage DB following the principles of openness and transparency.
As Greengage DB is derived from PostgreSQL, it inherently carries some of its well-known characteristics and challenges. One such issue, particularly relevant in distributed environments, is the problem of "orphaned files".
This issue arises when a table is created and data is loaded within an active transaction. If a critical failure occurs before the transaction can be committed or aborted (for example, a sudden system power loss or an unexpected shutdown of a database node), the system undergoes a crash recovery process. While the logical table will be rolled back, the physical data files associated with that uncommitted table may persist on the underlying file system. Over time, these orphaned files can accumulate, cluttering storage space and leading to unnecessary resource consumption. Currently, addressing this requires manual intervention for cleanup.
Recently, we have introduced a new feature that allows for the automatic removal of such orphaned files. Full information about this feature is available in the Deleting orphaned files article.
In a nutshell, the core idea behind our approach is as follows:
-
Each backend process stores information about files created for new relations (referred to as
relfilenodein PostgreSQL terms), along with their current transaction ID, in its own internal list. Once the transaction is committed or aborted, allrelfilenodeentries for that transaction are removed from the list. -
The
checkpointerprocess aggregates information from all such lists across all backends and stores the accumulated data in a new, dedicated Write-Ahead Log (WAL) record. -
During crash recovery, the
Startupprocess, which replays the WAL, obtains the information about created relfilenodes and subsequently deletes the physical files for all transactions that are marked as still in-progress at the end of the recovery process.
So, one of the crucial parts of this new feature is the efficient and reliable transfer of information about relfilenodes from the numerous backend processes to the central checkpointer process. Given that all of these are independent Linux processes, any shared data, such as the relfilenode lists, must reside in shared memory. Naturally, this shared data requires robust protection from concurrent access to ensure data integrity and consistency.
A straightforward and common approach to protect shared data would be to implement a conventional locking mechanism, such as mutexes or spinlocks, for each individual list. However, a paramount characteristic of any high-performance Online Analytical Processing (OLAP) database management system is its ability to process vast amounts of data quickly. Introducing frequent locking, especially in a system with many concurrent backend processes, could potentially introduce significant contention, leading to performance degradation due to increased serialization and reduced parallelism.
Therefore, we posed a critical question to ourselves: is it possible, or even feasible, to design this inter-process communication mechanism in a way that avoids the traditional use of explicit locks, and if so, would such an approach genuinely yield a performance benefit for our system?
Approach description
The answer is indeed "yes", it is feasible, but this lock-free approach comes with specific design constraints and trade-offs:
-
Dedicated Access
For any given
relfilenodelist, there is strictly only one dedicated writer process (a backend process) and one dedicated reader process (thecheckpointerprocess). This one-to-one writer-to-list relationship, coupled with a single central reader, simplifies concurrency management significantly. -
Head-Only Insertions
Each writer process exclusively adds new nodes to its respective list. Crucially, all insertions are performed at the head of the list. This design choice is fundamental to a lock-free strategy, as it allows writers to add new entries without contending with reads or other writes on existing list elements.
-
Logical Deletion (Marking)
When a writer process needs to "remove" a node from its list (for example, after a transaction commits or aborts), it does not physically delete the node from the list structure. Instead, it logically "marks" the node as deleted. This avoids complex memory management and race conditions that would arise from physical deletions in a concurrent, lock-free environment.
-
Reader-Driven Physical Cleanup
The actual physical removal of these "marked as deleted" nodes from the list structure is deferred and performed exclusively by the reader process. This cleanup occurs immediately after the reader has successfully read and processed the current contents of the list, ensuring that no active writer is still referencing the nodes being removed. By performing checkpoints periodically, we ensure that the list cleanup occurs in an acceptable manner without blowing up its actual size.
-
Concurrent Operations During Reading
While the reader process traverses a list, the writer process is still permitted to perform operations concurrently. New insertions made by the writer process during the reader’s traversal are allowed, but they will not be visible to the current traversal of the reader. Similarly, logical deletions (marking nodes as deleted) can occur concurrently by writer processes. This implies that the reader might encounter and process a node that has already been logically marked for deletion by a writer. That is acceptable for our use case. The reason is that adding a new node happens when the storage for a new relation is created, which in turn also creates its own dedicated WAL record. So, during replay of the WAL we either would see that WAL record or the next
checkpointrecord, which will contain the new node. And removing is done on commit or abort of the transaction, which also will create a WAL record. Therefore, the information about the removedrelfilenodewill be obtained from that record. For more details, please refer to the Deleting orphaned files article.
The lock-free approach is inspired by the article A Pragmatic Implementation of Non-Blocking Linked Lists. From the article, we took the idea of the node’s logical deletion that relies on Compare-and-Swap operation. We reconsidered the overall approach and simplified it for a single-writer model (the original article describes an algorithm for the multiple-writers model) and focused more on the management of the deleted nodes.
Insertion (by the writer process)
It is straightforward and simple — we set next pointer of the new node to the first node in the list, and then set HEAD to point to the new node.


Deletion (by the writer process)
As we’ve said above, deletion from the list by the writer process is "logical", meaning the node still stays in the list, but it is marked as deleted. In order not to add additional fields to keep this mark, we utilize the least significant bit (LSB) of the next pointer field of a list node. The LSB is guaranteed to be 0 due to memory alignment requirements.
It is crucial to note that all these list nodes must reside within shared memory. This prevents them from being allocated by standard process-local memory management functions like malloc (or palloc, which is common in the PostgreSQL environment) within a single process. Instead, a specialized mechanism known as Dynamic Shared Memory Areas (DSA) is employed. As per its design, "it provides an object called a dsa_area which can be used by multiple backends to share data. It appears to client code as a single shared memory heap with a simple allocate/free interface. Because the memory is mapped at different addresses in different backends, it introduces a kind of sharable relative pointer and an operation to convert it to a backend-local pointer". So, when we are talking about pointers here, actually we are talking about dsa_pointer, which is uint64 or uint32 under the hood.
Thus, to logically remove a node, the writer simply needs to set the least significant bit (bit 0) of its next field to 1. However, as we previously established, the actual physical cleanup of the list is performed concurrently by the reader process. This creates a potential race condition: the reader could attempt to free the next node in the sequence at the very moment a writer tries to mark the current node’s next pointer. To prevent such conflicts and ensure atomicity, the operation of setting this mark in the LSB of the next pointer must be performed atomically, which is precisely why the Compare-and-Swap (CAS) instruction is used. CAS allows the writer to ensure that the next pointer’s value has not changed unexpectedly before applying the deletion mark.


Traversal (by the reader process)
For iterating over the list, the reader process utilizes two primary operations:
-
get_first() -
get_next()
During these iteration operations, the reader actively performs cleanup: it skips over all nodes that are marked as logically deleted, physically removes them from the list structure, and then frees the memory associated with these removed nodes.
However, there’s a critical distinction regarding the very first node in the list: we do not physically remove or free the node currently pointed to by the HEAD pointer, even if it is marked as deleted. This constraint is crucial because the HEAD pointer is the immediate target for atomic updates by writer processes during new node insertions. Attempting to physically remove the HEAD node concurrently with writer operations on it could lead to complex race conditions. While a HEAD node marked as deleted will be skipped during iteration, its physical removal will be delayed until a new node successfully updates the HEAD pointer, and it will be removed on a consequent read cycle.
Let’s illustrate the traversal with an example: consider a list with six nodes. Suppose Node 1, Node 2, and Node 5 are currently marked as logically deleted, and Node 1 is the current HEAD of the list.


First step: Performing get_first() operation
-
The reader starts at
Node 1(theHEAD). SinceNode 1is marked deleted and is theHEADnode, it is skipped but not physically freed by the reader. -
The reader then moves to
Node 2.Node 2is markeddeleted, soget_first()physically removesNode 2from the list and frees the node. -
The reader continues until it finds
Node 3, which is not marked asdeleted. -
get_first()returns a pointer toNode 3as the current iteration position.


Second step: Performing get_next() operation (from Node 3)
-
The reader examines
Node 4, which is not marked asdeleted. -
get_next()returns a pointer toNode 4as the current iteration position.


Third step: Performing get_next() operation (from Node 4)
-
The reader examines
Node 5.Node 5is markeddeleted, soget_next()physically removes and freesNode 5from the list. Crucially, at this point, the next pointer ofNode 4(which previously pointed toNode 5) must be updated to now point toNode 6. -
To ensure the atomicity of this pointer update (
Node 4's next pointer), especially since a writer process could concurrently try to markNode 4itself, we again employ the Compare-and-Swap (CAS) operation. This ensures that the update toNode 4's next pointer occurs only if its value is still as expected, preventing a race condition. -
Finally,
get_next()returns a pointer toNode 6as the "current" iteration position.


The design choice where the reader (checkpointer) process is responsible for the physical cleanup of deleted nodes inherently implies that the read operations for list traversal might not always be exceptionally fast in terms of raw performance. This is because the reader combines data retrieval with memory deallocation and list restructuring.
However, in our specific use case, this characteristic does not pose a significant problem. The checkpointer process is already designed to handle a multitude of intensive background operations — such as flushing modified data blocks to disk, managing transaction logs, and updating various system metadata. These are crucial, heavy-duty tasks that, by their nature, are performed asynchronously in the background and are specifically architected not to block or directly impact the foreground execution of user queries.
Therefore, as long as the list traversal and cleanup operations performed by the checkpointer do not introduce contention or locking that impedes the progress of backend processes, a less performance-critical reading speed is entirely acceptable. The system can tolerate a more "unhurried" pace for these background cleanup activities. Conversely, all write operations (insertions and logical deletions) are executed by backend processes directly serving user queries. For this reason, it is paramount that these write operations are as fast and non-blocking as possible to ensure optimal user experience and query throughput.
So, in summary, the approach relies on the dedicated access (one writer, one reader per list), head-only insertions by writers, and logical deletion (marking nodes with an LSB in their next pointer, using CAS for atomicity). The reader handles all physical cleanup of these marked nodes during its traversal.
Testing procedure description
Once the implementation was complete, our next important step was to rigorously test and evaluate its performance.
Our testing procedure was designed with the following key requirements in mind:
-
It needed to accurately estimate performance in scenarios closely mirroring real-world conditions. This implied testing with numerous concurrent writer processes and a single reader process, all executing within a functional Greengage cluster environment.
-
Simultaneously, the testing environment had to be sufficiently isolated to prevent potential interference from other unrelated subsystems. Such external influences could introduce instability and skew the test results (for instance, it was deemed impractical to utilize the actual
checkpointerprocess, as its many other ongoing operations would inevitably affect the precision of our test timings). -
The procedure needed to offer flexibility, allowing us to vary key parameters that could influence performance, such as the total number of elements inserted and deleted, the degree of parallelism (i.e. the number of concurrent writer processes operating simultaneously), and other relevant factors.
With these considerations, we devised the following synthetic test setup:
-
Writer Emulation
We encapsulated the writer code within a PostgreSQL set-returning function (SRF), with the
Datum lfl_test(PG_FUNCTION_ARGS)signature. This allowed us to easily execute write operations by simply invokingSELECT lfl_test(params); from any convenient client tool, such aspsql. Furthermore, in conjunction with a parallel execution tool (e.g. a custom script leveragingGNU parallelfor concurrentpsqlsessions), we could efficiently spawn as many parallel writer sessions as required. Under the hood, this function dispatches requests to all Greengage executor segments. On each segment, the function then performs a loop of write and delete operations for a specified number of iterations, as defined by the function’s parameters. The results from the segments are returned to the dispatcher, and then returned from the function to the user. The result is the time spent by the writer process to insert and delete the requested number of elements. -
Reader Emulation
For the reader component, a dedicated background process was created. This process periodically polls all active backend sessions and then iterates over their associated lock-free lists. Its primary task is to read the contents of these lists, performing the necessary cleanup of marked-as-deleted nodes, and then, for verification purposes, dump the data to disk.
Another crucial consideration was how to effectively interpret the results generated by our testing methodology. A direct analysis of absolute timing values would provide limited insight, as such figures are inherently dependent on the underlying hardware specifications and environmental conditions of the test cluster.
Therefore, the true objective and point of interest was to perform a comparative analysis: specifically, to conduct an "apples-to-apples" performance comparison between our new lock-free list implementation and a traditional lock-based list. This comparison would be carried out on the same Greengage cluster and identical hardware, thereby isolating the performance impact attributable solely to the lock-free design versus its locked counterpart. This approach allows us to derive meaningful conclusions about the relative efficiency of our solution.
Testing results
We conducted performance tests with varying numbers of inserted and deleted elements, specifically testing with 100, 1000, 5000, and 10000 entries. To ensure statistical robustness, each test configuration was replicated 10 times. The averaged performance values from these runs are presented in the following plots.
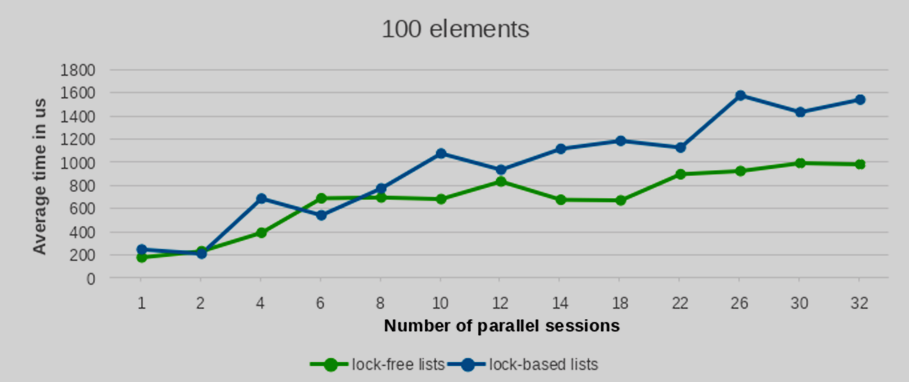
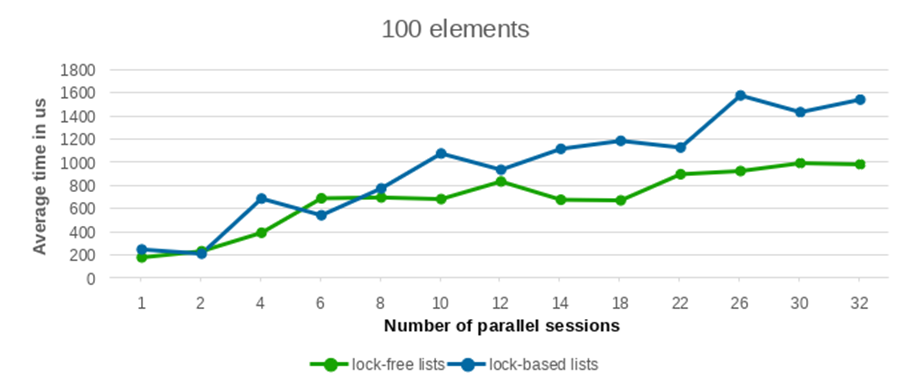
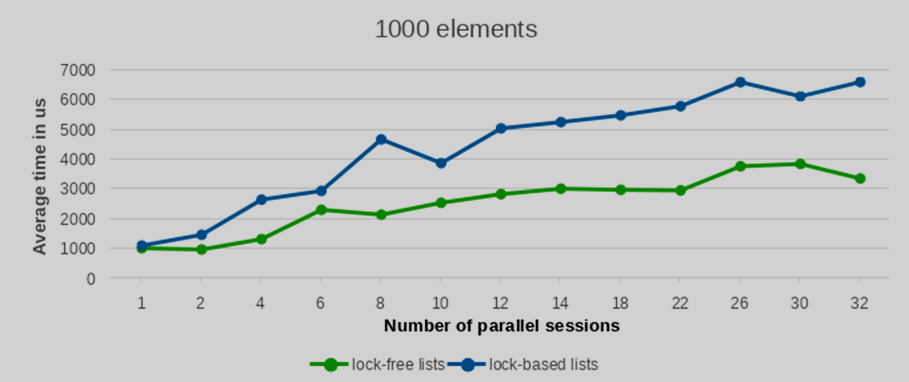
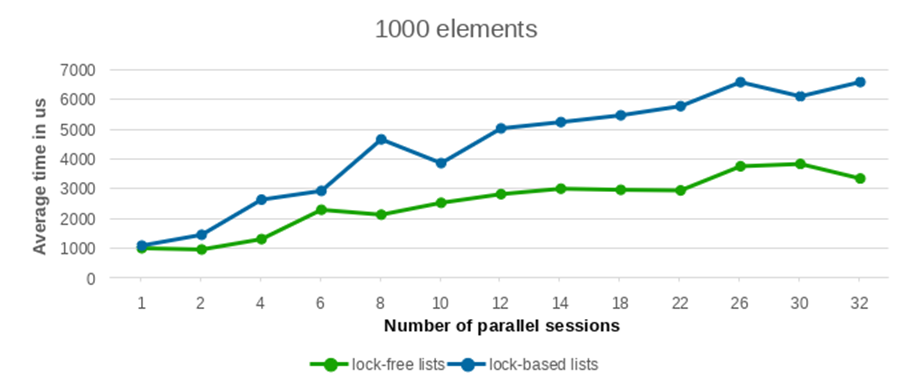
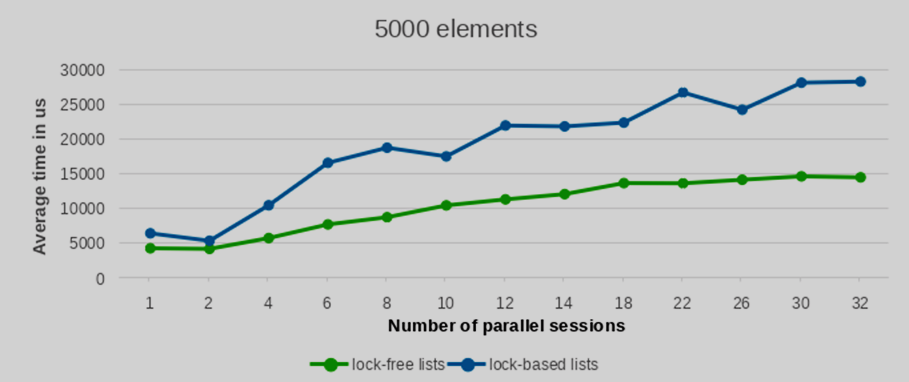
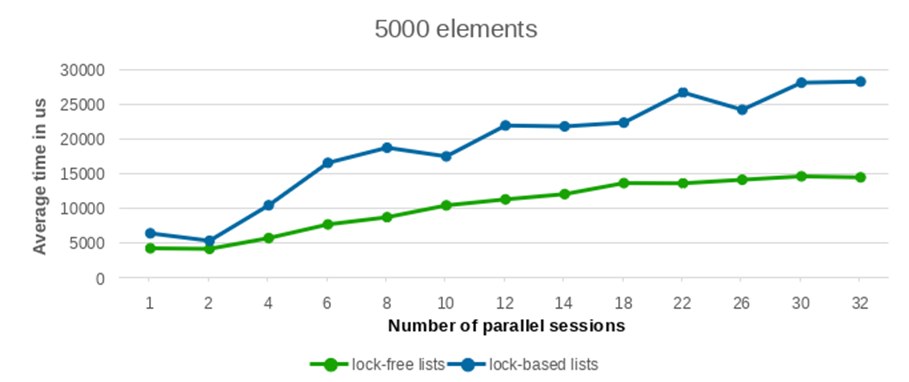
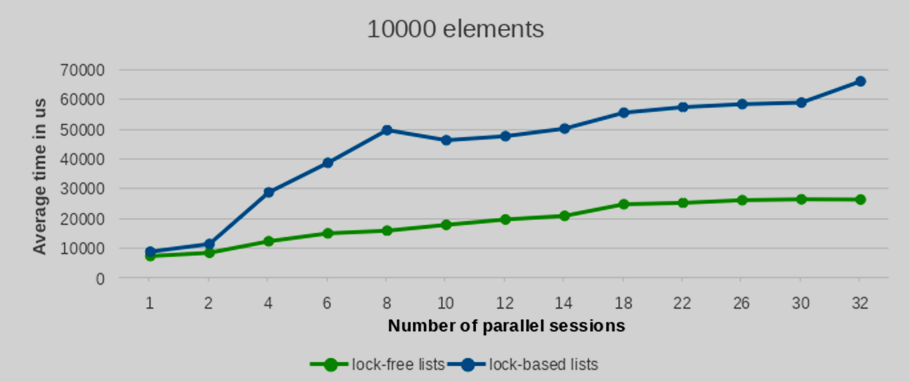
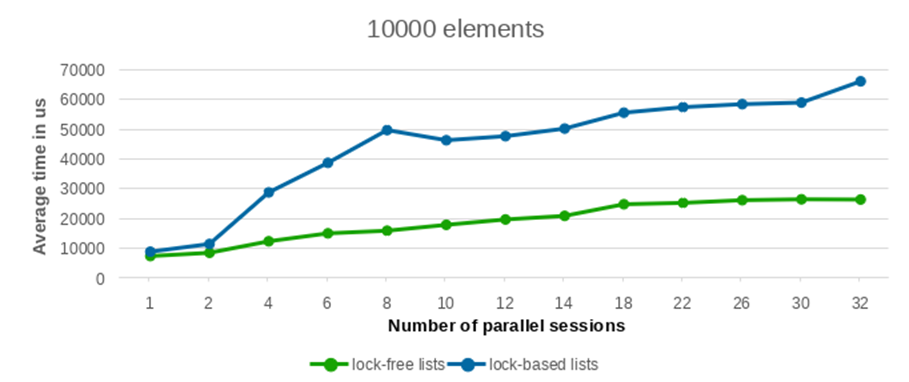
As can be observed from the provided plots, with an increasing number of parallel sessions (and consequently, concurrently launched backend processes), the execution time of the lock-free list implementation exhibits a significantly more gradual increase compared to lists protected by traditional per-backend locks. This indicates better scalability under contention.
The performance differential between the lock-free list and the conventional lock-based list widens considerably as the number of concurrent writers increases. Furthermore, this performance advantage becomes increasingly pronounced with a larger number of elements. While the results for a low element count show largely comparable performance between the two approaches, the benefit of the lock-free lists becomes clearly evident when processing a substantial volume of elements.
Conclusion
The described lock-free approach has demonstrated its effectiveness, yielding promising performance results under heavy workloads. However, given that the expected workload for our current target feature is not particularly high (typically involving the storage of tens or hundreds of relfilenodes, but generally not more), we made a strategic decision for this specific feature’s implementation. We opted to proceed with traditional lock-based lists, as they exhibit comparable performance at these lower element counts. This choice significantly enhances maintainability and reduces the risk of accidental breakage or unintended regressions from future modifications, due to the inherent simplicity of the traditional approach.
Nevertheless, the lock-free methodology itself has proven its excellent performance characteristics, particularly under high contention and with larger data volumes. Consequently, this approach remains a strong candidate for future features within Greengage DB where substantial amounts of data need to be efficiently and concurrently passed or shared among different processes within a segment, ensuring robust scalability and minimal performance overhead.