Метрики мониторинга кластера ADB
- Обзор
- Просмотр метрик в Prometheus
- Дашборды Grafana
- Доступ к Grafana
- Greengage - Backup Monitoring (gpbackup)
- Greengage - Cluster Overview
- Greengage - Database Health
- Greengage - Exporter Monitoring
- Greengage - Host & Resource Group Resources
- Greengage - Query Performance
- Greengage - Replication & Segments
- Node Exporter statistics
- Process exporter metrics
- PXF Service Dashboard
В статье описываются метрики мониторинга кластера ADB. Для получения информации об установке мониторинга обратитесь к разделу Установка мониторинга.
Обзор
Сервис мониторинга состоит из следующих компонентов:
-
Node Exporter — предоставляет метрики, связанные с аппаратным обеспечением и операционной системой хостов: использование памяти, CPU и дискового пространства. Метрики доступны на порте и эндпойнте, заданных в секции Node Exporter settings конфигурации сервиса мониторинга (по умолчанию —
11203/metrics). -
Process Exporter — предоставляет метрики по выбранным процессам. В ADB отслеживаемые процессы — это агенты ADB и ADB Control. Метрики Process Exporter доступны на порте, заданном в секции Process exporter settings конфигурации сервиса мониторинга (по умолчанию —
9256). Компонент Process Exporter доступен только в Enterprise-версии ADB. -
Greengage Exporter — собирает метрики кластера и базы данных, такие как состояние сегментов и активные подключения. Метрики доступны на порте и эндпойнте, заданных в секции Greengage Exporter settings конфигурации сервиса мониторинга (по умолчанию —
9080/metrics). -
Prometheus — собирает и хранит метрики из настроенных источников данных: Node Exporter, Process Exporter и Greengage Exporter. Метрики доступны в веб-интерфейсе Prometheus на порте, заданном в секции Prometheus settings конфигурации сервиса мониторинга (по умолчанию —
11200). -
Grafana — использует Prometheus в качестве источника данных и отображает метрики в виде графиков и диаграмм, организованных в дашборды. Дашборды доступны в веб-интерфейсе Grafana на порте, заданном в секции Grafana settings конфигурации сервиса мониторинга (по умолчанию —
11210).
Кроме того, сервис PXF предоставляет встроенные метрики в формате Prometheus.
Эти метрики содержат информацию об активных операциях чтения и записи, обработке фрагментов, количестве переданных записей и байт, а также метрики JVM и Tomcat.
На каждом хосте, где установлен PXF, эти метрики доступны на порту 5888 по эндпойнту /actuator/prometheus, например 192.0.2.5:5888/actuator/prometheus.
ADB настраивает сервер Prometheus для сбора этих метрик и предоставляет их в виде дашборда PXF Service Dashboard в Grafana.
Просмотр метрик в Prometheus
Prometheus — это система для мониторинга и оповещений. Prometheus собирает метрики от экспортеров, а затем Grafana собирает данные для графиков, отправляя запросы в Prometheus. Если панели в дашбордах Grafana пустые или показывают некорректные значения, можно проверить данные в Prometheus, чтобы определить, связана ли проблема со сбором метрик или с конфигурацией дашборда:
-
В браузере введите
<IP-адрес сервера мониторинга>:<порт>. Порт по умолчанию —11200, его можно изменить в секции Prometheus settings в конфигурации сервиса Monitoring.IP-адрес, порт и имя хоста Prometheus также доступны на вкладке Info сервиса Monitoring.
-
В открывшемся окне введите имя пользователя и пароль, указанные в поле Prometheus users to login/logout to Prometheus конфигурации сервиса мониторинга.
В веб-интерфейсе Prometheus можно проверить его конфигурацию и состояние экспортеров (на странице Targets). Также можно использовать Prometheus Query Language (PromQL) для проверки конкретных метрик.
Дашборды Grafana
Grafana позволяет визуализировать метрики, хранящиеся в Prometheus, создавать собственные дашборды или изменять существующие.
Доступ к Grafana
-
В браузере введите
<IP-адрес сервера мониторинга>:<порт>. Порт по умолчанию —11210, его можно изменить в секции Grafana settings в конфигурации сервиса Monitoring.IP-адрес, порт и имя хоста Grafana также доступны на вкладке Info сервиса Monitoring.
-
В открывшемся окне в поле Email or username введите
admin, а в поле Password — пароль, указанный в поле Grafana administrator’s password конфигурации сервиса мониторинга.
По умолчанию в Grafana доступны следующие дашборды:
|
ПРИМЕЧАНИЕ
Если в кластере есть резервный мастер, к его метрикам применимо следующее:
|
Greengage - Backup Monitoring (gpbackup)
Этот дашборд предназначен для мониторинга операций резервного копирования базы данных ADB с помощью gpbackup. Greengage Exporter получает информацию о выполненных бэкапах из базы данных SQLite, расположенной по пути $MASTER_DATA_DIRECTORY/gpbackup_history.db.
|
ПРИМЕЧАНИЕ
По умолчанию база данных gpbackup_history.db отсутствует.
Она автоматически создается при первом использовании gpbackup.
|
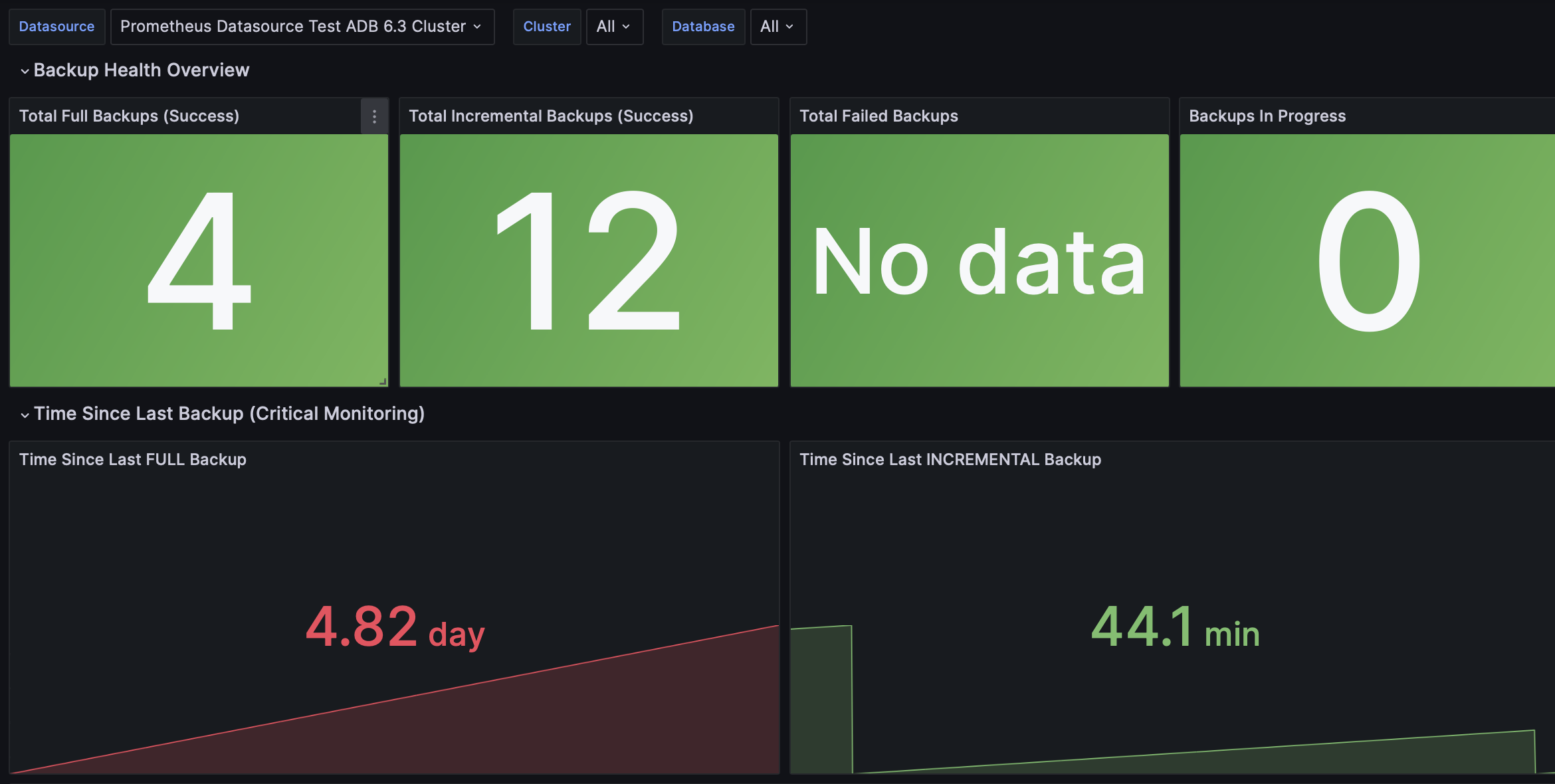
| Название панели | Описание |
|---|---|
Total Full Backups (Success) |
Общее количество успешных полных бэкапов по выбранным кластерам и базам данных |
Total Incremental Backups (Success) |
Общее количество успешных инкрементальных бэкапов по выбранным кластерам и базам данных |
Total Failed Backups |
Общее количество неудачных бэкапов по выбранным кластерам и базам данных |
Backups In Progress |
Текущее количество бэкапов, выполняющихся в данный момент |
Time Since Last FULL Backup |
Время, прошедшее с момента завершения последнего успешного полного бэкапа |
Time Since Last INCREMENTAL Backup |
Время, прошедшее с момента завершения последнего успешного инкрементального бэкапа |
Time Since Last Backup Over Time |
Время, прошедшее с момента последнего завершенного бэкапа (полного и инкрементального) по каждой базе данных |
Last Full Backup Duration |
Длительность последнего успешного полного бэкапа в секундах |
Last Incremental Backup Duration |
Длительность последнего успешного инкрементального бэкапа в секундах |
Incremental vs Full Backup Time Ratio |
Отношение длительности последнего инкрементального бэкапа к длительности последнего полного. Инкрементальные бэкапы, как правило, создаются быстрее полных, поэтому значение обычно должно быть ниже 100% |
Backup Duration Over Time |
График длительности бэкапов (полных и инкрементальных) по каждой базе данных |
Backup Type Distribution (Success) |
Соотношение успешных полных и инкрементальных бэкапов |
Backup Count Over Time (Stacked) |
График, показывающий количество успешных полных, успешных инкрементальных и неудачных бэкапов за период |
Backup Details Table |
Таблица с количеством бэкапов по базам данных, типу (полный или инкрементальный) и статусу ( |
Greengage - Cluster Overview
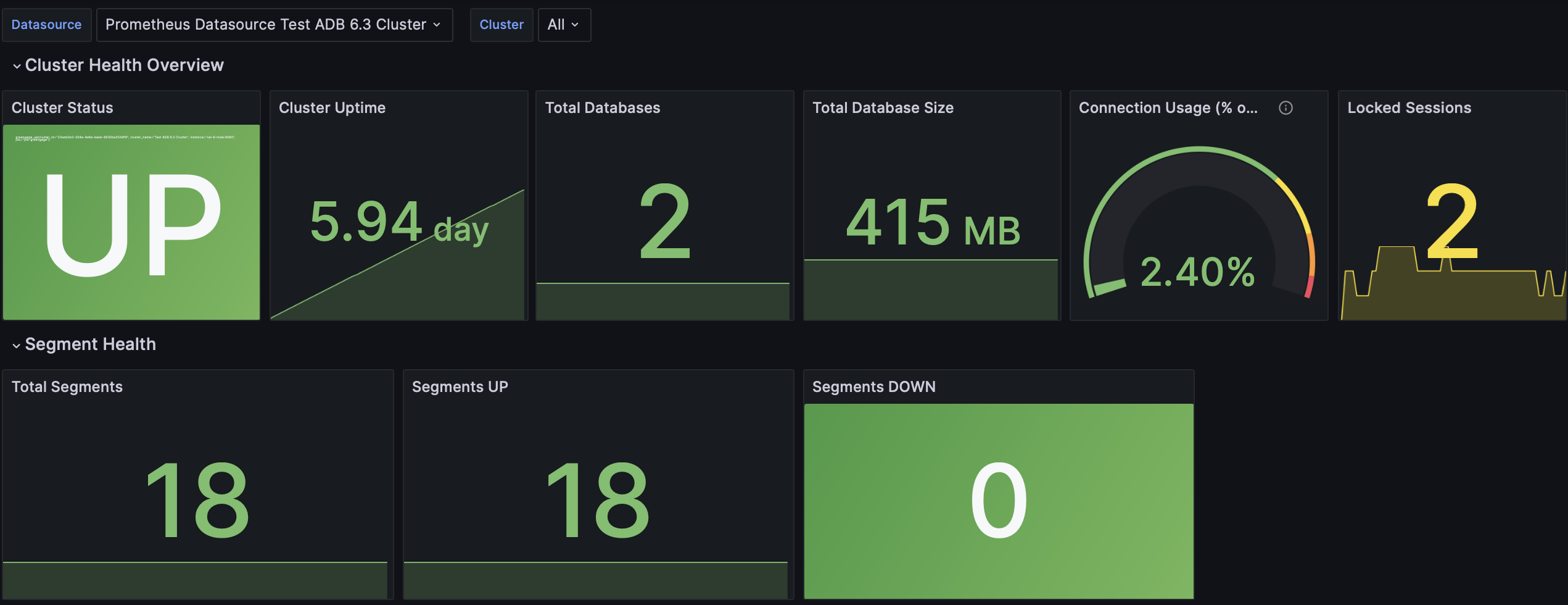
Дашборд показывает общее состояние и производительность кластера ADB: статус кластера, состояние сегментов и активность подключений.
| Название панели | Описание |
|---|---|
Cluster Status |
Показывает, работает ли кластер и доступен ли он ( |
Cluster Uptime |
Общее время непрерывной работы кластера с момента последнего перезапуска |
Total Databases |
Общее количество баз данных в кластере |
Total Database Size |
Суммарный размер всех баз данных в кластере |
Connection Usage (% of Max) |
Текущие подключения в виде процента от лимита подключений (задается параметром конфигурации сервера max_connections). Показывает, насколько кластер близок к исчерпанию лимита подключений |
Locked Sessions |
Количество сессий, заблокированных в данный момент, что может указывать на проблемы с конкуренцией за ресурсы. Для более подробного анализа блокировок см. дашборд Query Performance |
Total Segments |
Общее количество сегментов (основных и зеркальных), настроенных в кластере |
Segments UP |
Количество сегментов, работающих в данный момент |
Segments DOWN |
Количество сегментов, недоступных в данный момент |
Segment Status by Host |
График, показывающий статус каждого сегмента ( |
Connections by State |
График, показывающий количество подключений, сгруппированных по состоянию (активное, простаивающее, простаивающее в транзакции) |
Query Activity |
Распределение запросов по состоянию
|
Active Queries by Duration Bucket |
Распределение активных запросов по интервалам длительности. Запросы распределены по следующим интервалам: 0–10 секунд, 10–60 секунд, 60–180 секунд, 180–600 секунд и более 600 секунд |
Replication Lag (Replay) |
Задержка репликации в байтах для каждого сегмента — объем данных WAL, ожидающих воспроизведения на зеркалах |
Max Replication Lag |
Максимальная задержка репликации среди всех сегментов, отображаемая как единственное значение с пороговыми уровнями предупреждений и критического состояния |
Greengage - Database Health
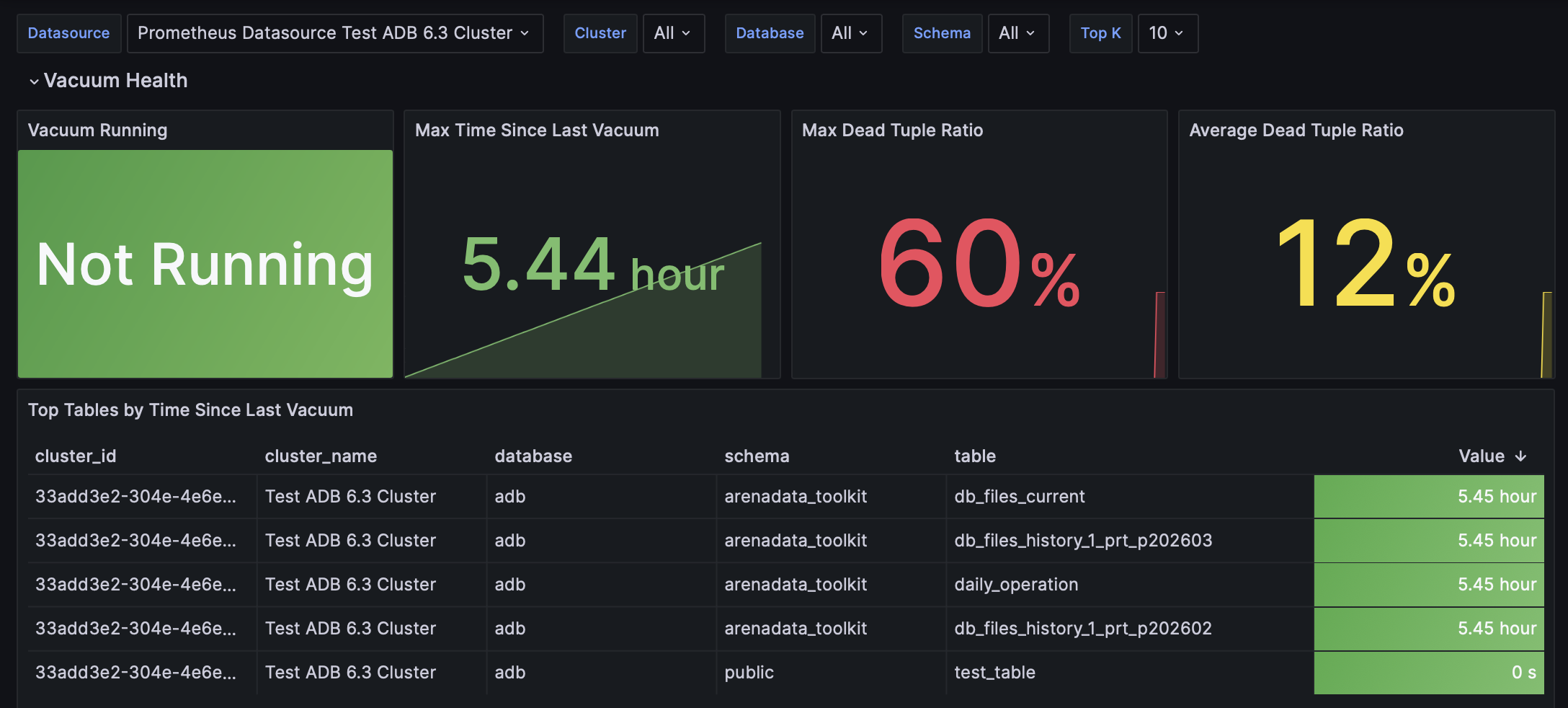
Дашборд отображает метрики работоспособности базы данных: операции vacuum, степень раздувания таблиц (bloat) и перекос распределения данных (skew).
| Название панели | Описание |
|---|---|
Vacuum Running |
Показывает, выполняется ли в данный момент операция |
Max Time Since Last Vacuum |
Максимальное время, прошедшее с момента последней операции |
Max Dead Tuple Ratio |
Максимальное отношение "мертвых" строк к "живым" по всем таблицам, указывающее на возможную необходимость |
Average Dead Tuple Ratio |
Среднее отношение "мертвых" строк по всем таблицам, отражающее общий уровень bloat таблиц |
Top Tables by Time Since Last Vacuum |
Список таблиц с наибольшим временем, прошедшим с момента последней операции При каждом сборе метрики учитываются только те таблицы, в которых сумма "мертвых" и живых строк превышает заданный порог (COLLECTOR_TABLE_VACUUM_TUPLE_THRESHOLD).
Таким образом, после успешной операции |
Vacuum & Autovacuum Count |
График накопленного количества ручных операций При каждом сборе метрики учитываются только те таблицы, в которых сумма "мертвых" и живых строк превышает заданный порог (COLLECTOR_TABLE_VACUUM_TUPLE_THRESHOLD).
Таким образом, после успешной операции |
Top Tables by Dead Tuple Ratio |
График таблиц с наибольшим отношением "мертвых" строк с изменением во времени |
Table Bloat State (0=none, 1=moderate, 2=severe) |
График, отображающий состояние bloat таблиц с изменением во времени |
Top Tables by Skew Factor (>1.5 is significant) |
График, показывающий изменение коэффициента перекоса со временем для таблиц, превышающих порог 1.5 |
Tables with Bloat |
Таблицы с признаком bloat с указанием его состояния (1 — умеренное, 2 — значительное) |
Tables with High Skew Factor |
Таблицы с наибольшим текущим коэффициентом перекоса |
Greengage - Exporter Monitoring
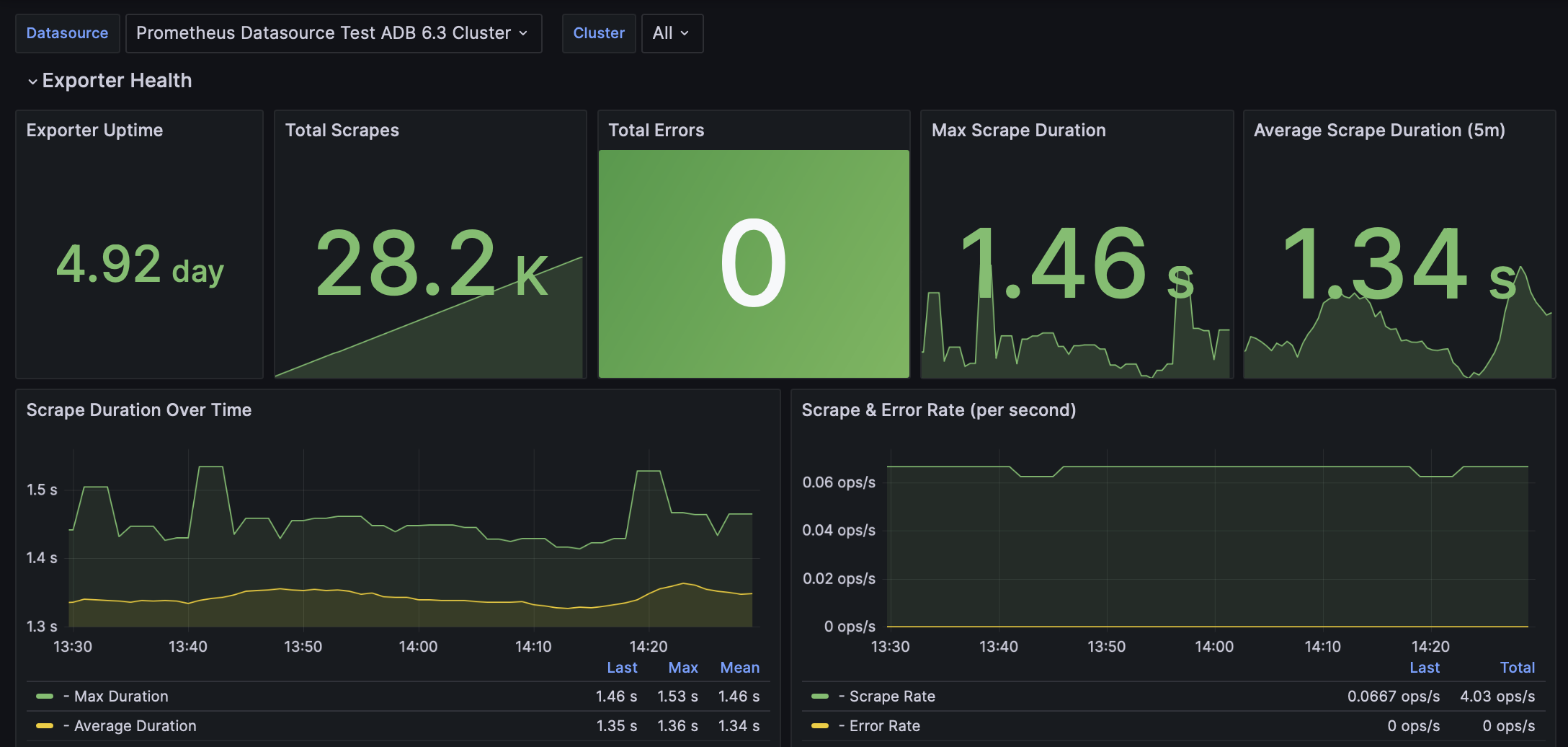
Дашборд показывает работоспособность и производительность самого Greengage Exporter.
| Название панели | Описание |
|---|---|
Exporter Uptime |
Общее время непрерывной работы процесса Greengage Exporter |
Total Scrapes |
Общее количество сборов метрик (scrape), то есть количество раз, когда Prometheus успешно собрал метрики из Greengage Exporter |
Total Errors |
Общее количество ошибок, возникших в ходе сборов метрик |
Max Scrape Duration |
Максимальная длительность одной операции сбора метрик в секундах, с пороговыми значениями |
Average Scrape Duration (5m) |
Средняя длительность сбора метрик за последние 5 минут |
Scrape Duration Over Time |
График максимальной и средней длительности сборов метрик с течением времени |
Scrape & Error Rate (per second) |
Скорость операций сбора метрик и ошибок в секунду за 5-минутные периоды |
Collector Durations |
Изменение длительности выполнения каждого коллектора во времени.
В Greengage Exporter коллекторы — это компоненты, отвечающие за сбор определенных типов метрик, например коллектор статистики |
Circuit Breaker State |
Текущее состояние внутренних автоматических выключателей (circuit breaker):
|
Circuit Breaker Opened Count (5m increase) |
Количество раз, когда автоматические выключатели переходили в состояние |
Circuit Breaker Calls Rate (per second) |
Скорость обращений к автоматическим выключателям в секунду |
Timeout Calls Rate (per second) |
Скорость вызовов методов с защитой по тайм-ауту в секунду, разбитая по признаку наступления тайм-аута |
Timeout Execution Duration (Average) |
Средняя длительность выполнения методов |
Retry Calls Rate (per second) |
Скорость вызовов методов с повторными попытками в секунду, разбитая по статусу повтора и результату |
Total Retry Attempts (5m increase) |
Общее количество повторных попыток по всем методам за последние 5 минут |
Method Invocation Rate (per second) |
Скорость всех вызовов методов в секунду.
Вызовы разделены по результату, например |
Greengage - Host & Resource Group Resources
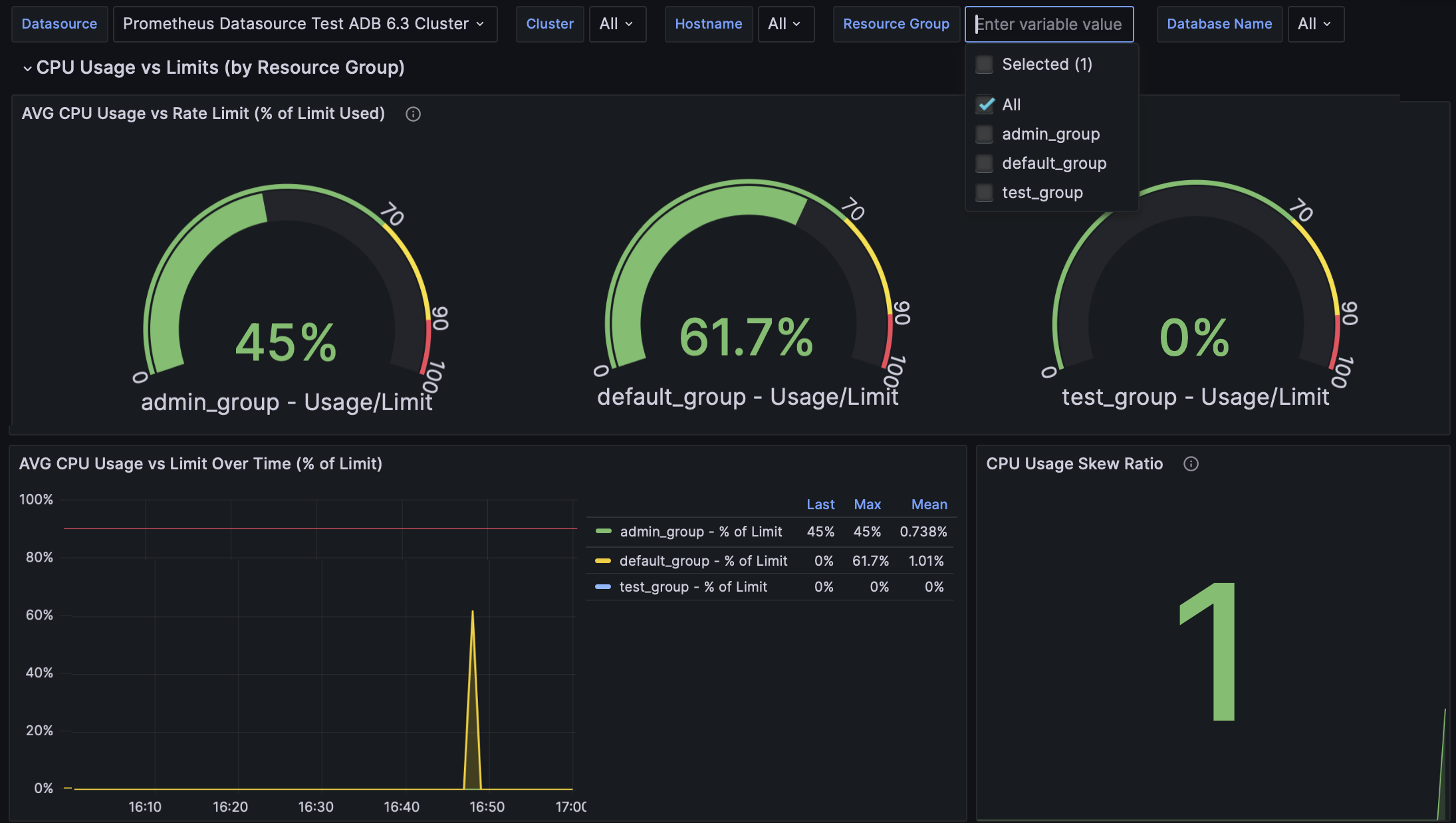
Дашборд предоставляет обзор потребления ресурсов в кластере ADB на уровне хостов и ресурсных групп.
Для просмотра данных по конкретному хосту или группе ресурсов используйте фильтры Hostname и Resource Group в верхней части дашборда.
| Название панели | Описание |
|---|---|
AVG CPU Usage vs Rate Limit (% of Limit Used) |
Среднее использование CPU каждой ресурсной группой, выраженное в процентах от установленного для нее лимита |
AVG CPU Usage vs Limit Over Time (% of Limit) |
График изменения во времени среднего использования CPU относительно лимита, выраженного в процентах от лимита |
CPU Usage Skew Ratio |
Отношение максимального использования CPU к среднему по хостам; значения больше 1.3 указывают на неравномерное распределение нагрузки по CPU |
Absolute CPU Usage by Host and Resource Group |
График абсолютного использования CPU (в процентах) по хостам и ресурсным группам с аннотацией лимита |
Memory Usage vs Limit (% of Limit Used) - LIMITED GROUPS ONLY |
Использование памяти в виде процента от лимита памяти для ресурсных групп с конечными лимитами (группы без лимита исключены) |
Memory Usage Skew Ratio |
Отношение максимального использования памяти к среднему по хостам; значения больше 1.3 указывают на неравномерное распределение памяти |
Average Memory Usage |
Среднее использование памяти по всем хостам кластера |
Max Memory Usage |
Максимальное использование памяти, зафиксированное на любом хосте кластера |
Memory Usage by Host and Resource Group (with Limits) |
График абсолютного использования памяти по хостам и ресурсным группам с отображением настроенных лимитов |
Running Sessions by Resource Group |
Количество текущих активных сессий по каждой группе ресурсов; высокие значения указывают на высокую нагрузку |
Queueing Sessions by Resource Group (Resource Saturation Indicator) |
Количество сессий, ожидающих постановки в очередь из-за достижения ограничений ресурсов в ресурсной группе |
Running vs Queueing Sessions Over Time |
График, показывающий, как со временем распределялись активные и ожидающие постановки в очередь сессии по ресурсным группам |
Average Disk Total |
Средний объем дискового пространства по всем хостам |
Average Disk Used |
Среднее использование дискового пространства по всем хостам |
Disk Usage Skew Ratio |
Отношение максимального использования дискового пространства к среднему по хостам; значения > 1.3 указывают на неравномерное распределение дискового пространства |
Max Disk Usage Percent |
Максимальный процент использования дискового пространства, зафиксированный на любом хосте |
Disk Usage Percent by Host |
Процент использования дискового пространства по хостам |
Disk Usage by Host (Total/Used/Available) |
График, отображающий общее, используемое и доступное дисковое пространство по хостам |
Database Size by Name |
Размеры выбранных баз данных в МБ |
Max Spill Usage |
Максимальное использование дискового пространства spill-файлами, зафиксированное на любом хосте |
Average Spill Usage |
Среднее использование дискового пространства spill-файлами по всем хостам |
Spill Usage Skew Ratio |
Отношение максимального использования spill-файлов к среднему |
Spill Usage by Host |
Использование дискового пространства spill-файлами по хостам |
Greengage - Query Performance
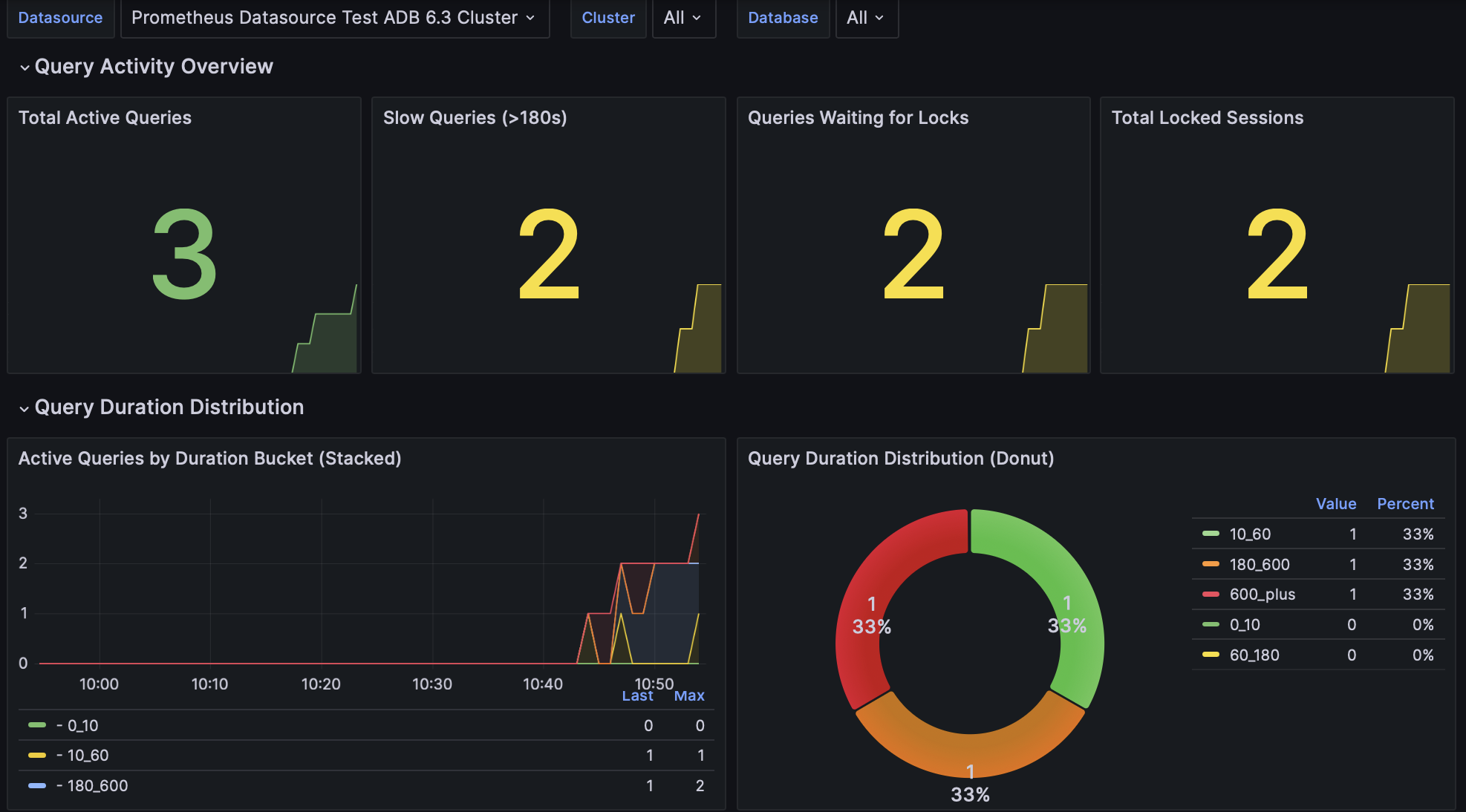
Дашборд предназначен для мониторинга производительности запросов — он показывает число активных запросов, медленных запросов, конкуренцию за доступ к заблокированным объектам и статистику подключений.
| Название панели | Описание |
|---|---|
Total Active Queries |
Текущее количество активных запросов в кластере с пороговыми значениями для нормального, повышенного и высокого уровня активности |
Slow Queries (>180s) |
Количество активных запросов, превысивших 180 секунд (3 минуты), что может свидетельствовать о проблемах с производительностью |
Queries Waiting for Locks |
Количество активных запросов, заблокированных в ожидании получения блокировки.
Соответствует строкам со значением |
Total Locked Sessions |
Общее количество сессий, ожидающих блокировок в данный момент |
Query Activity Over Time |
Распределение запросов по состоянию за выбранный период:
|
Active Queries by Duration Bucket (Stacked) |
Распределение активных запросов по предопределенным интервалам длительности. Интервалы классифицируют запросы по времени выполнения: 0–10 секунд, 10–60 секунд, 60–180 секунд, 180–600 секунд и более 600 секунд |
Query Duration Distribution (Donut) |
Текущее распределение активных запросов по интервалам длительности с абсолютными значениями и процентами |
Total Connections (All States) |
Общее количество подключений к базе данных во всех состояниях |
Active Connections |
Количество подключений, активно выполняющих запросы |
Idle Connections |
Количество подключений в состоянии простоя (ожидание активности со стороны клиента) |
Connections by State Over Time |
Подключения, сгруппированные по состоянию ( |
Queries Waiting for Locks Over Time |
Количество запросов, заблокированных в ожидании блокировок, с пороговыми значениями предупреждения и критического состояния |
Locked Sessions Over Time |
Общее количество заблокированных сессий с изменением во времени |
Max Lock Wait Time by Type and Mode |
Максимальное время ожидания для блокировок, сгруппированных по типу и режиму. После снятия блокировок метрики исчезают с панели (неактуальные данные не отображаются) |
Waiting Queries by Lock Type and Mode |
Количество запросов, ожидающих блокировок, сгруппированных по типу и режиму. После снятия блокировок метрики исчезают с панели (неактуальные данные не отображаются) |
Greengage - Replication & Segments
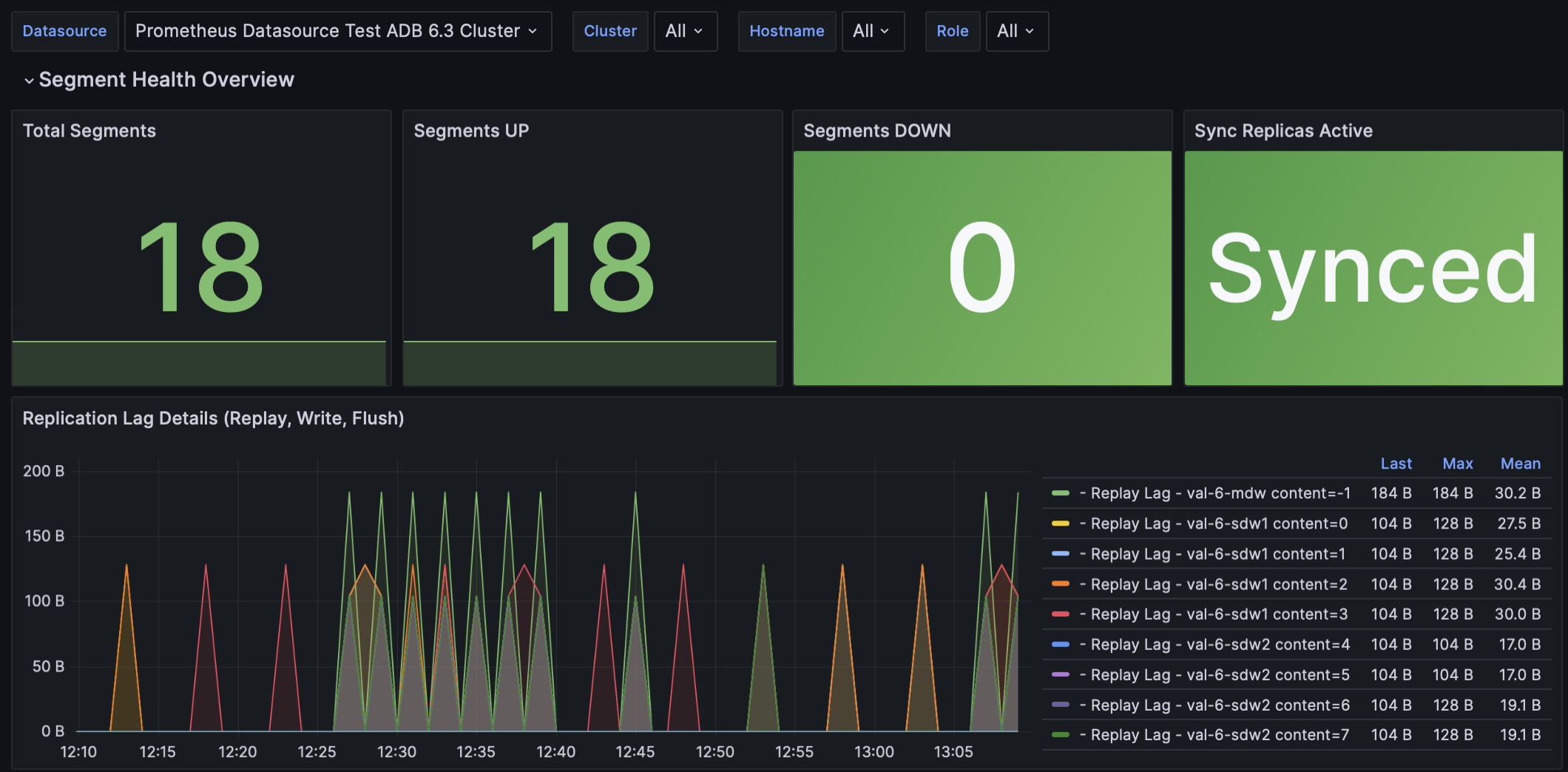
Дашборд предназначен для мониторинга состояния сегментов и репликации.
| Название панели | Описание |
|---|---|
Total Segments |
Общее количество сегментов (основных и зеркальных), настроенных в кластере |
Segments UP |
Количество сегментов, работающих в данный момент |
Segments DOWN |
Количество сегментов, недоступных в данный момент |
Sync Replicas Active |
Показывает, активна ли синхронная репликация |
Segment Status |
График, показывающий статус сегментов с изменением во времени с указанием имени хоста, порта, идентификатора содержимого (content ID) и роли |
Segment Role (1=Primary, 2=Mirror) |
График, отображающий роль сегмента (основной или зеркальный) с изменением во времени |
Segment Mode (1=Sync, 2=Resync, 3=Change Track, 4=Not Sync) |
График режима репликации сегментов с изменением во времени |
Max Replication Lag |
Максимальная задержка репликации в байтах по всем сегментам, с пороговыми значениями |
Average Replication Lag |
Средняя задержка репликации в байтах по всем сегментам, с пороговыми значениями |
Minimum Sync State (2=sync, 1=async, 0.5=potential, 0=unknown) |
Минимальное состояние синхронизации среди всех соединений репликации — отражает наихудший случай синхронизации в кластере |
Replication Lag Details (Replay, Write, Flush) |
График задержки репликации в байтах для каждого сегмента с разбивкой по задержкам воспроизведения (replay), записи (write) и сброса (flush) |
Replication State (1=streaming, 2=catchup, 3=backup, 0=unknown) |
График состояния репликации для каждого зеркала |
Replication Sync State (2=sync, 1=async, 0.5=potential, 0=unknown) |
График, отображающий политику синхронизации с изменением во времени:
|
Segment Details Table |
Таблица со списком всех сегментов и их текущим статусом, именем хоста, портом, идентификатором содержимого (content ID), ролью и изначальной ролью |
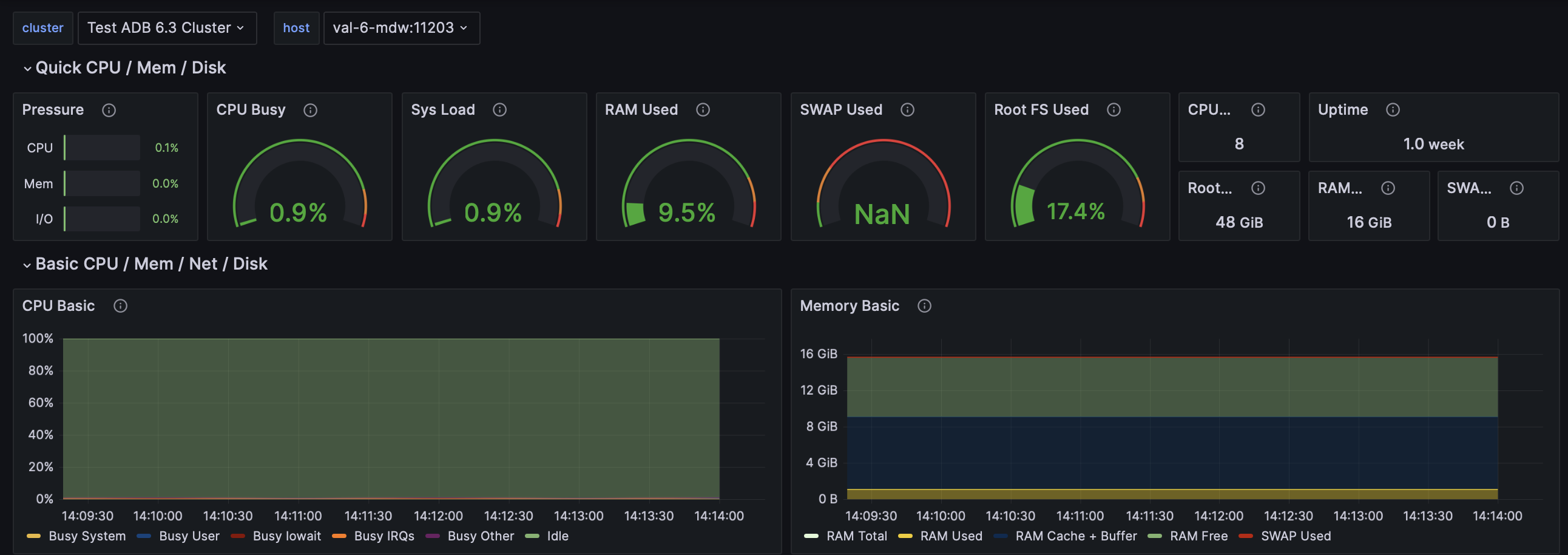
Node Exporter statistics
Дашборд статистики Node Exporter предоставляет системные метрики для каждого хоста кластера, на котором установлен Node Exporter. Выбрать хост можно с помощью фильтра host в верхней части страницы.
Process exporter metrics
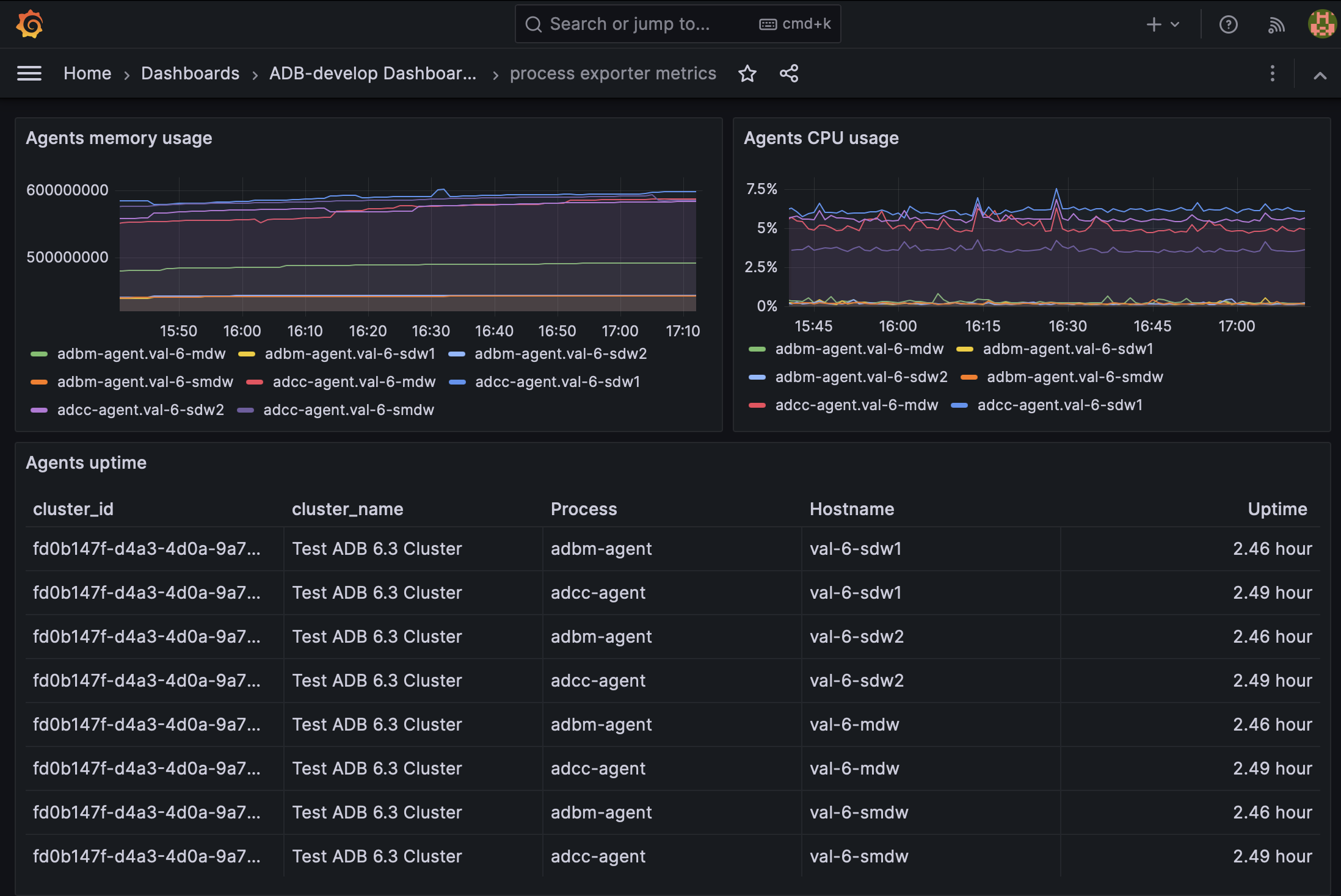
Дашборд предназначен для мониторинга агентов ADB Control и ADBM (процессов adcc-agent и adbm-agent) на основе метрик, собираемых Process Exporter.
| Название панели | Описание |
|---|---|
Agents uptime |
Время непрерывной работы каждого экземпляра агента |
Agents memory usage |
Использование памяти каждым агентом в динамике |
Agents CPU usage |
Использование CPU (в процентах) каждым агентом в динамике |
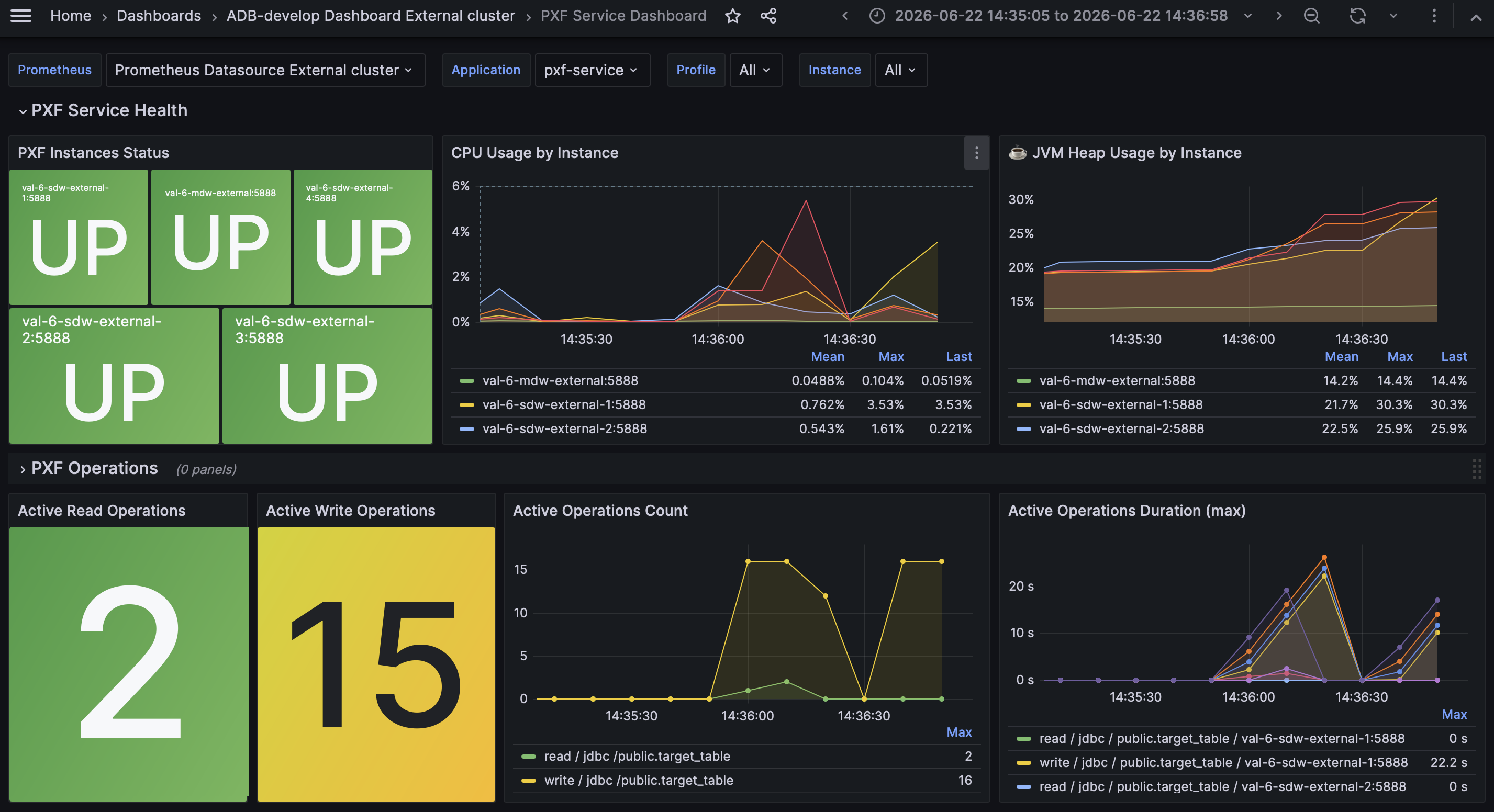
PXF Service Dashboard
Дашборд предоставляет информацию о состоянии экземпляров PXF, метриках работы PXF, потреблении памяти JVM, потоках и соединениях Tomcat, а также частоте HTTP-запросов и ошибок. Полный список всех доступных панелей приведен в документации PXF Grafana Dashboards.
В верхней части дашборда доступны следующие фильтры:
-
Application — название сервиса PXF, задаваемое параметром
management.metrics.tags.applicationв файле $PXF_BASE/conf/pxf-application.properties. Если не задано, по умолчанию используетсяpxf-service. -
Profile — используемые профили PXF.
-
Instance — хосты, на которых установлены экземпляры PXF (соответствует настройке
targetsв файле /etc/admprom/prometheus/prometheus.yml).