

Мониторинг команд
Страница Monitoring → Commands в web-интерфейсе ADB Control предназначена для вывода SQL-команд, которые выполняются в кластерах ADB, подключенных для мониторинга. Страница состоит из двух вкладок:
Queries
Вкладка Queries показывает SQL-команды. Она состоит из двух вкладок: Online и History, которые подробно описаны ниже.
Online
На вкладке Monitoring → Commands → Queries → Online выводятся команды в следующих статусах:
-
Queued— команды, по которым еще не пришла информация о фактическом начале выполнения. -
Running— команды, выполняющиеся в текущий момент времени. -
Cancelling— команды, для которых осуществляется отмена (в рамках отмены либо прерывания соответствующей транзакции).
В верхней части вкладки содержится поле Current count, показывающее общее число команд в различных статусах во всех кластерах ADB, подключенных для мониторинга.
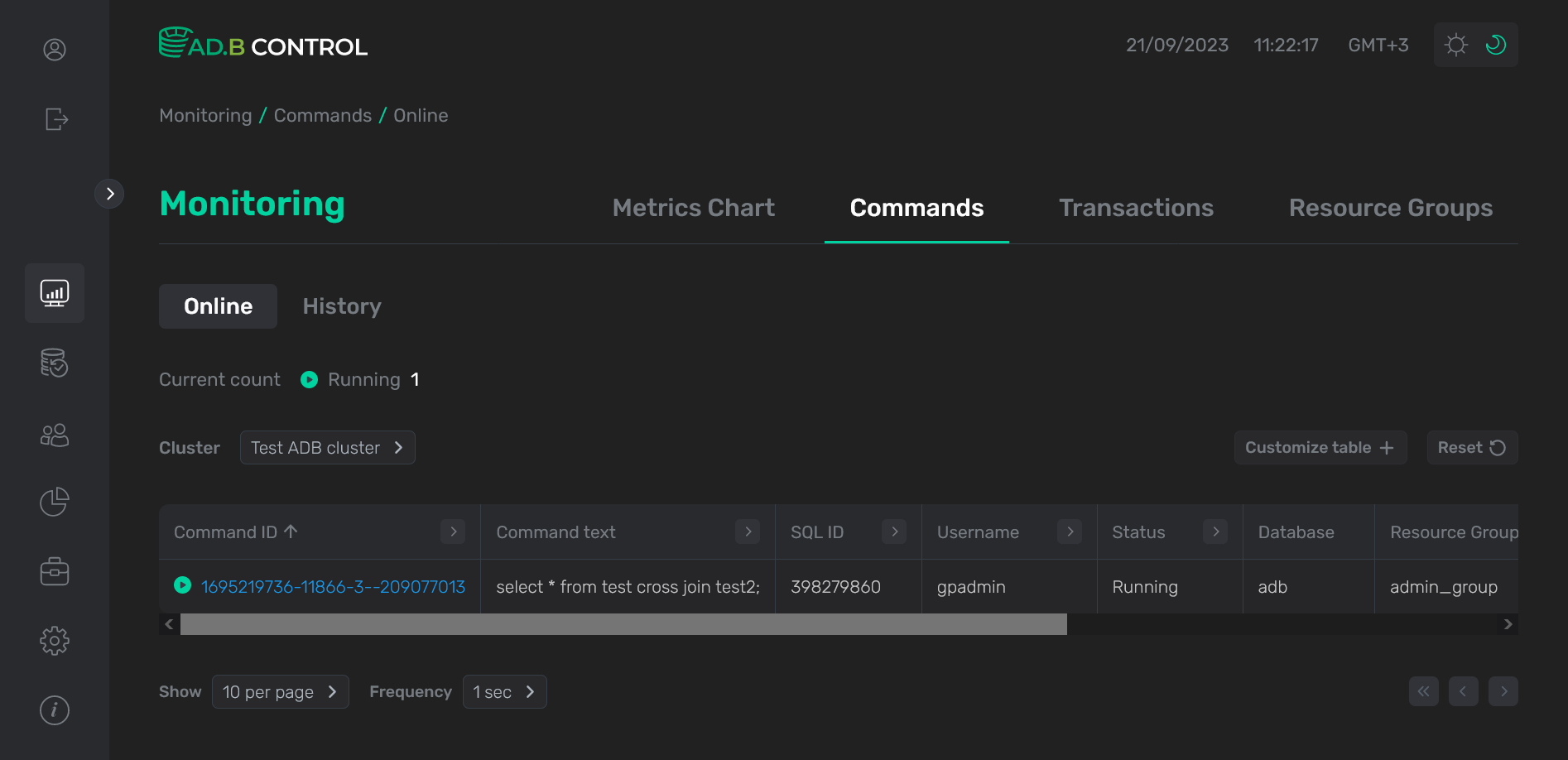
Таблица, расположенная на вкладке Monitoring → Commands → Queries → Online, выводит следующую информацию о командах.
| Поле | Описание |
|---|---|
Command ID |
Уникальный идентификатор команды, включающий:
|
Command text |
Первые символы текста команды. Для вывода текста полностью (в случае длинных запросов) наведите курсор мыши на ячейку таблицы со значением |
SQL ID |
Идентификатор, являющийся общим для SQL-команд с одинаковой структурой |
Username |
Имя пользователя, запустившего команду |
Status |
Статус команды. Возможные значения см. выше |
Database |
Название базы данных, в которой запущена команда |
Resource group |
Название ресурсной группы, которая используется для команды |
Cluster |
Название кластера, в котором запущена команда |
Planner |
Название оптимизатора запросов, используемого для построения плана выполнения команды. Возможные значения:
|
Submitted |
Дата и время отправки команды пользователем в формате |
Tags |
Теги команды |
Run time |
Общее время выполнения команды в часах, минутах и секундах |
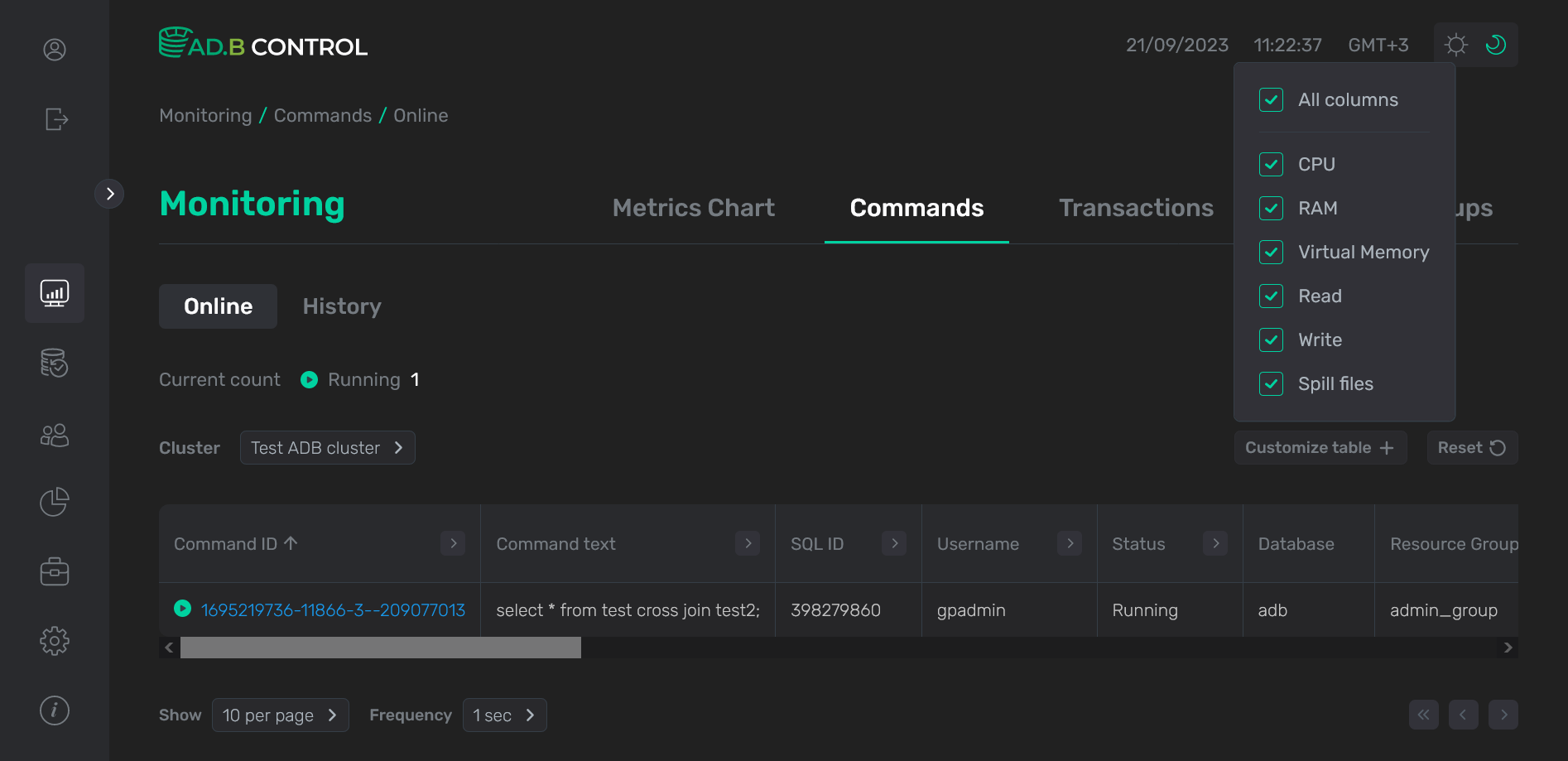
Возможно добавление дополнительных столбцов в таблицу с командами для отображения метрик, описание которых представлено ниже. Для добавления новых столбцов нажмите Customize table и отметьте столбцы в выпадающем списке.
Над таблицей со списком команд расположен фильтр Cluster, в котором можно выбрать кластер ADB и его базы данных, для которых требуется вывести данные в таблице. По умолчанию выбраны все БД кластера, отмеченного как дефолтный в настройках ADB Control.
В заголовках столбцов таблицы со списком команд
расположены фильтры, которые можно использовать для отбора необходимых данных. Для открытия фильтра необходимо нажать на иконку ![]()
![]() . Для тех столбцов, где набор возможных значений ограничен (например, Status), в фильтре можно выбрать значение из выпадающего списка.
Для некоторых столбцов (например, Username) требуется ввести искомое значение.
Для столбцов, показывающих дату и время (например, Submitted), временной диапазон можно выбрать из календаря.
. Для тех столбцов, где набор возможных значений ограничен (например, Status), в фильтре можно выбрать значение из выпадающего списка.
Для некоторых столбцов (например, Username) требуется ввести искомое значение.
Для столбцов, показывающих дату и время (например, Submitted), временной диапазон можно выбрать из календаря.
Иконка ![]()
![]() означает, что для столбца определен фильтр. Для сброса всех фильтров нажмите Reset.
означает, что для столбца определен фильтр. Для сброса всех фильтров нажмите Reset.
History
На вкладке Monitoring → Commands → Queries → History выводятся команды в следующих статусах:
-
Done— успешно завершенные команды. -
Cancelled— отмененные команды (в рамках отмены либо прерывания соответствующей транзакции). -
Error— команды, во время выполнения которых произошла ошибка. -
Unknown— команды, итоговый статус которых не был получен. Устанавливается по тайм-ауту для запросов в статусахQueued,Running,Cancelling, по которым не оказалось соответствующих записей в системном представленииpg_stat_activity.
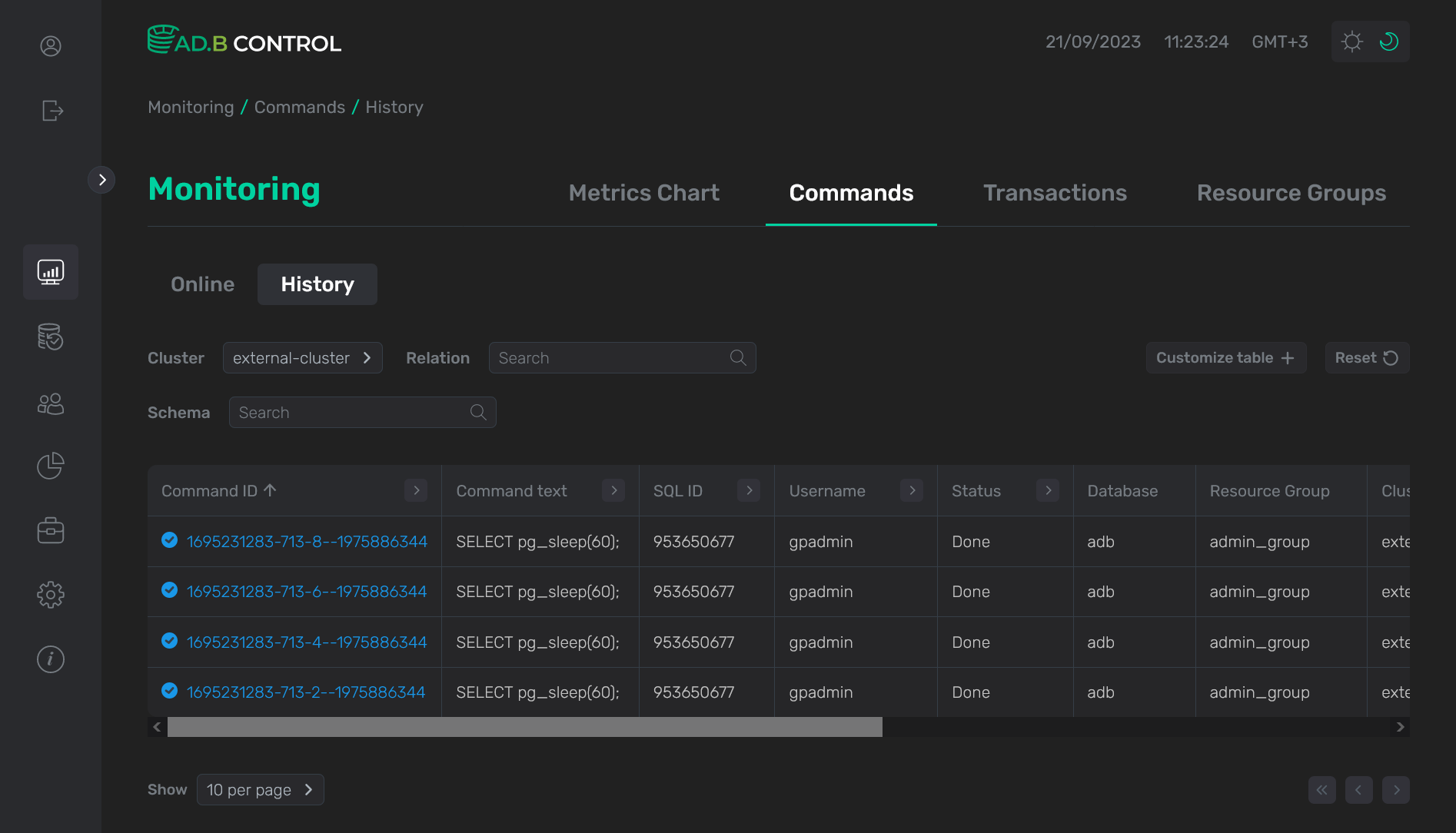
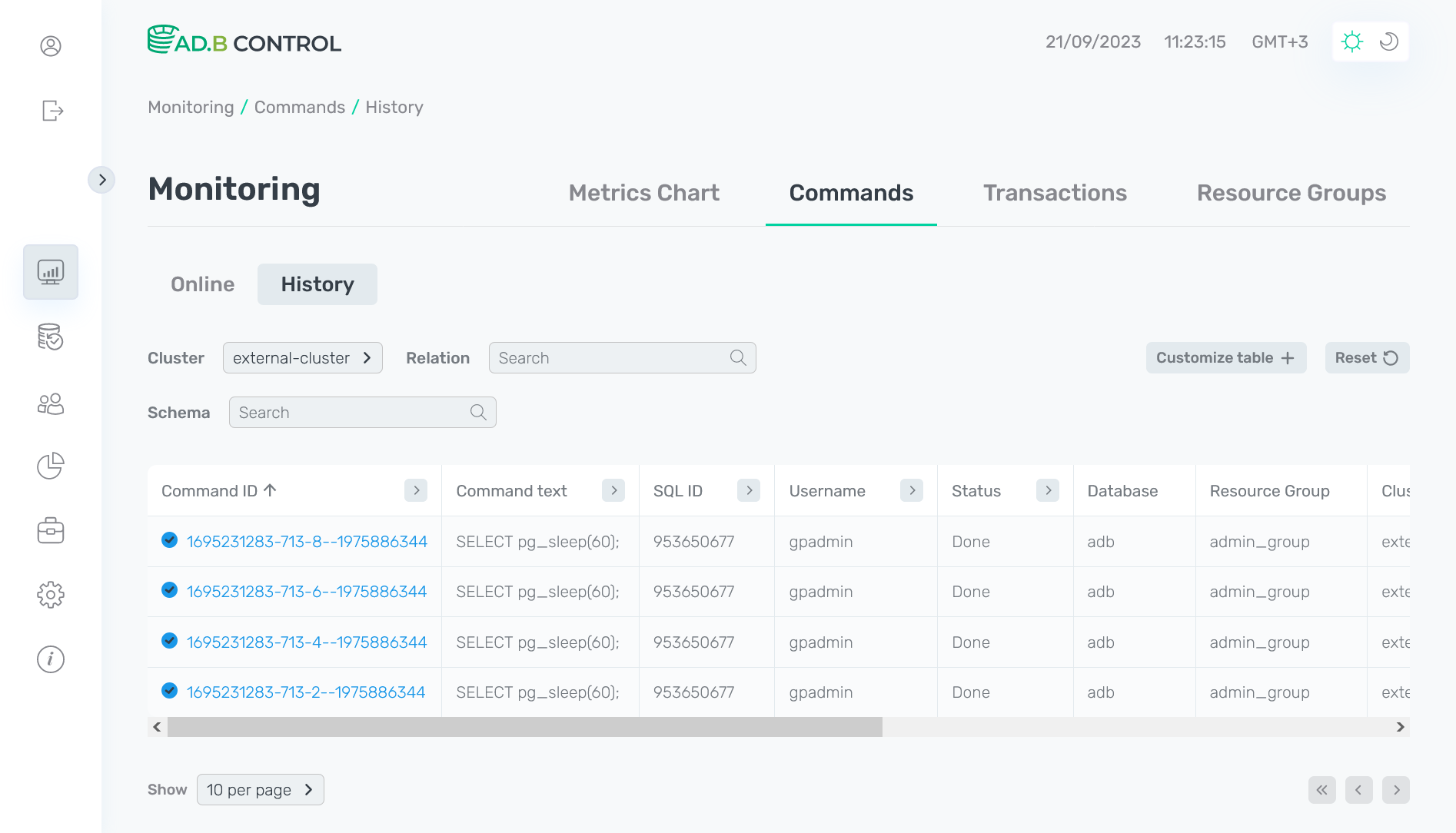
Большая часть полей в таблице со списком команд на вкладке History совпадает с полями, описанными выше для вкладки Online. Добавляется только следующее поле:
-
Ended — дата и время завершения команды в формате
DD/MM/YYYY HH:mm:ss. Поле заполняется как в результате успешного выполнения, так и в случае ошибки или отмены выполнения.
Как и на вкладке Online, есть возможность добавления дополнительных столбцов в таблицу с командами — путем нажатия на кнопку Customize table.
Над таблицей со списком команд расположены фильтры, которые можно использовать для отбора необходимых данных. Наряду с описанным выше фильтром Cluster, на вкладке History доступны еще два фильтра:
-
Relation — фильтрация по названию используемого в запросе отношения. Искомое значение вводится полностью.
-
Schema — фильтрация по названию схемы БД, которой принадлежит используемое в запросе отношение. Искомое значение вводится полностью.


Детали команды
Чтобы просмотреть детальную информацию о команде, нажмите на ее идентификатор (Command ID) в таблице на вкладке Monitoring → Commands → Queries → Online либо Monitoring → Commands → Queries → History.
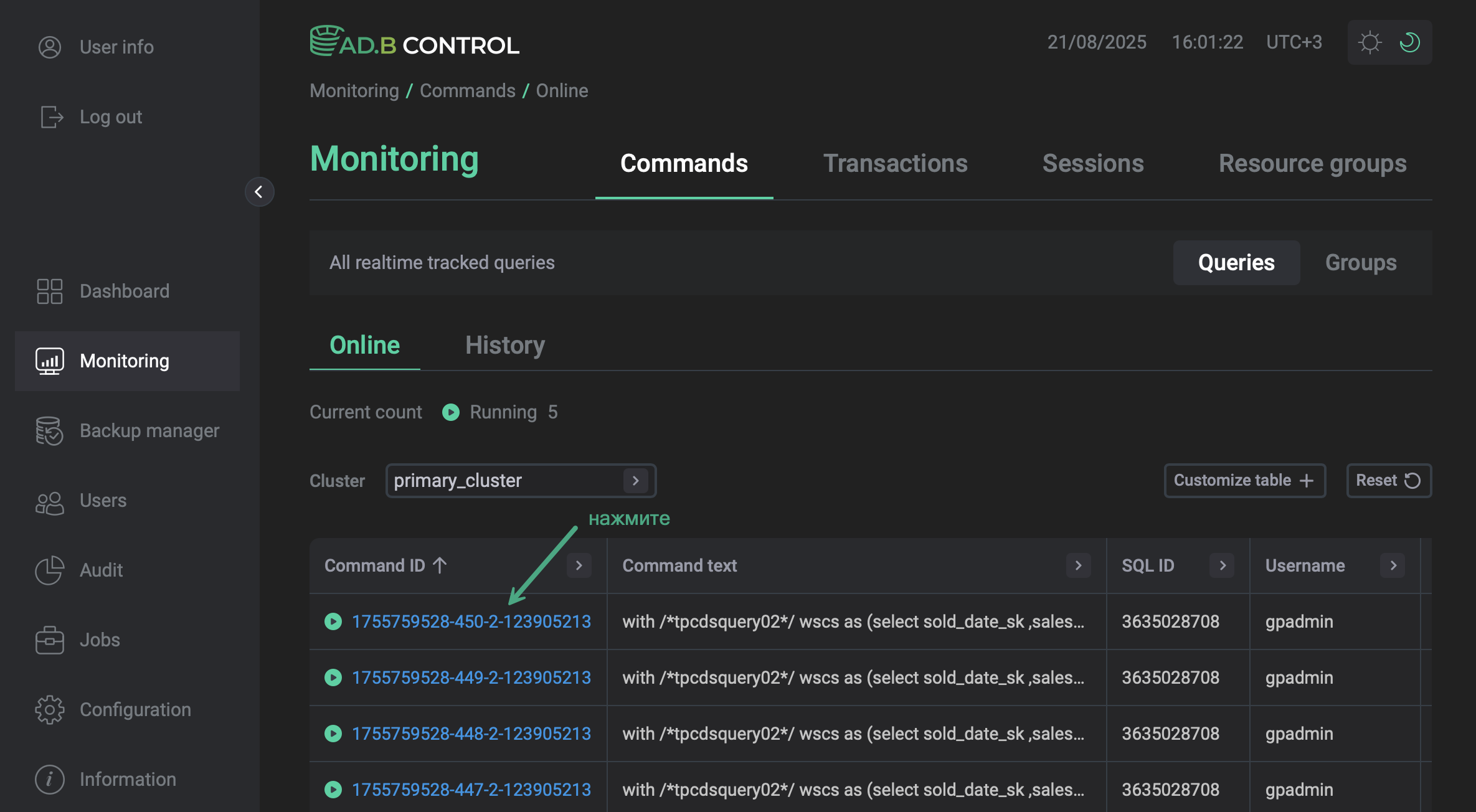
Следующая страница содержит несколько секций, описанных ниже.
Заголовок
В верхней части страницы выводится следующая информация о команде:
-
Уникальный идентификатор (см. Command ID выше). В примере ниже —
1695219736-11866-3—209077013. -
Статус (см. Status выше). В примере ниже —
Running. -
Порядковый номер в ADB Control (начиная с
1). Ведется сквозная нумерация по всем кластерам с самой первой зафиксированной команды. В примере ниже —2683. -
Transaction ID — идентификатор транзакции, при нажатии на который можно перейти к просмотру деталей транзакции.
-
Run time — время выполнения команды в часах, минутах, секундах.


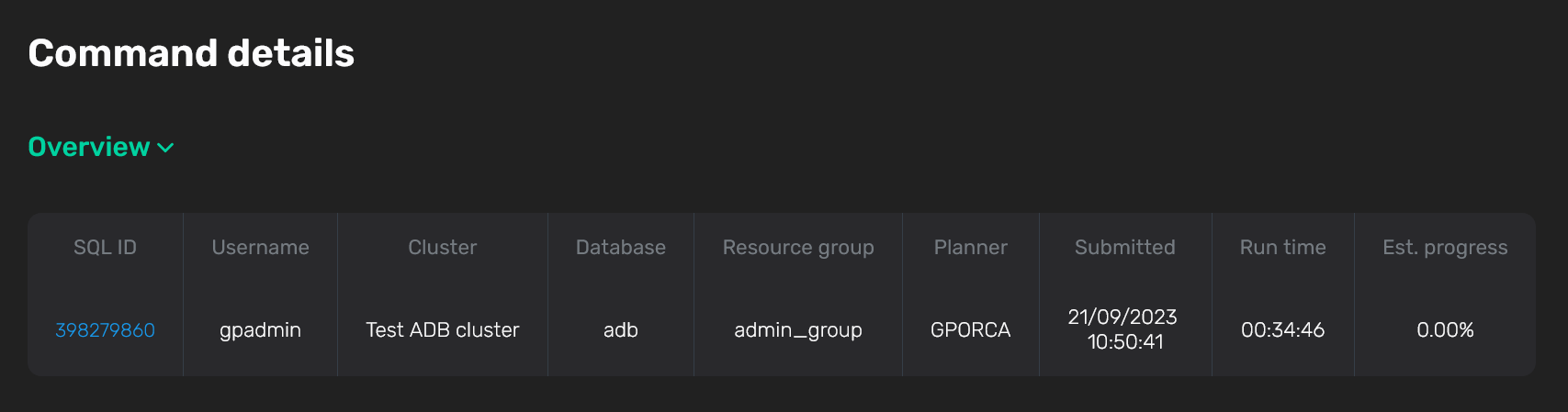
Overview
Секция Overview показывает базовую информацию о команде. В дополнение к полям, описанным выше, выводятся:
-
Run time — длительность выполнения команды в часах, минутах, секундах.
-
Est. progress — прогресс выполнения команды в процентах от спрогнозированного времени, рассчитываемый по формуле:
где:
-
Est.Cost(x)— оценка стоимости узла плана запроса, сделанная планировщиком. -
NodeProgress(x)— прогресс для каждого узла плана запроса, рассчитываемый по следующей формуле:где:
-
ActualRows— реальное количество извлеченных строк (кортежей). -
EstimatedRows— предположение планировщика о количестве строк (кортежей), которое будет извлечено для текущего узла плана.
-
-
Если команда завершается с ошибкой (в статусе Error), информация об ошибке выводится под таблицей в секции Overview.
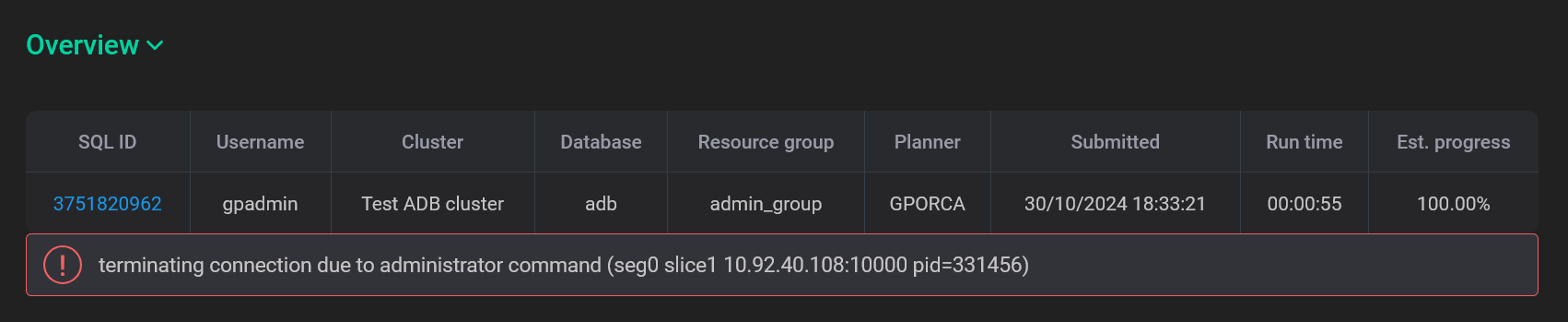
Performance
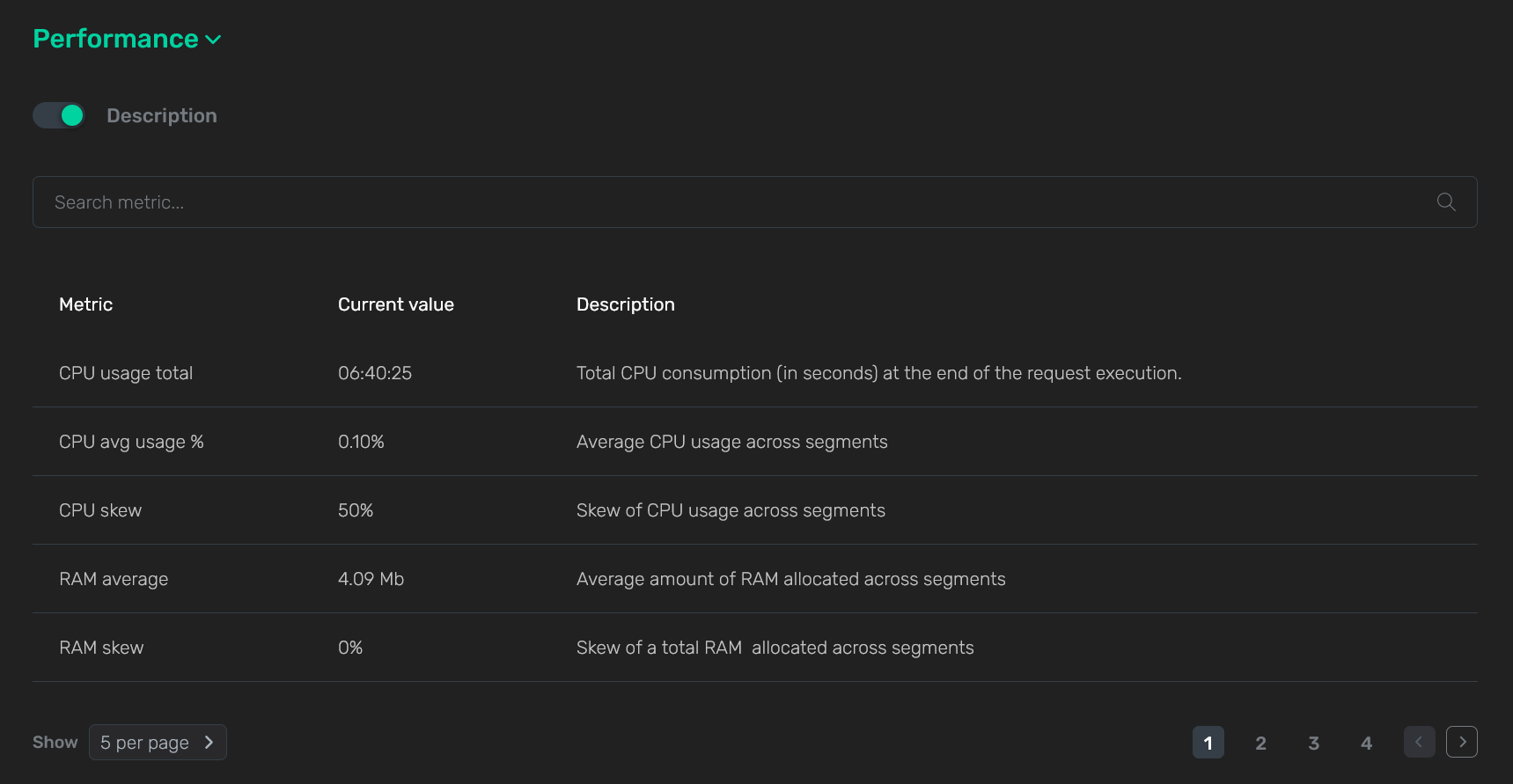
Секция Performance показывает статистику потребления системных ресурсов выбранной командой. Метрики, используемые для мониторинга, приведены в разделе Метрики, собираемые для команд.
В верхней части секции Performance показываются усредненные значения по всем сегментам кластера с выводом "перекосов" (skew).
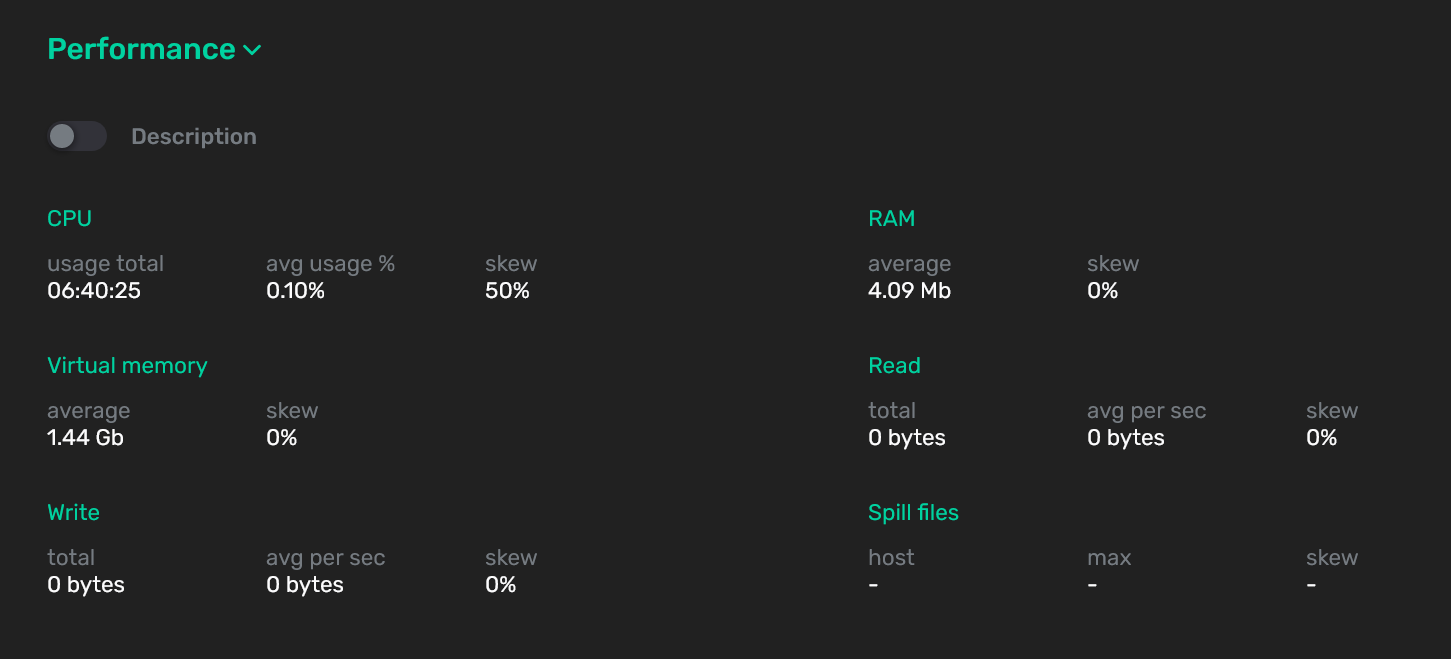
Можно перейти к альтернативному варианту показа метрик, переведя переключатель под названием секции Performance в активное состояние. В результате отобразится таблица, где по каждой метрике выводится не только текущее значение, но и подробное описание.
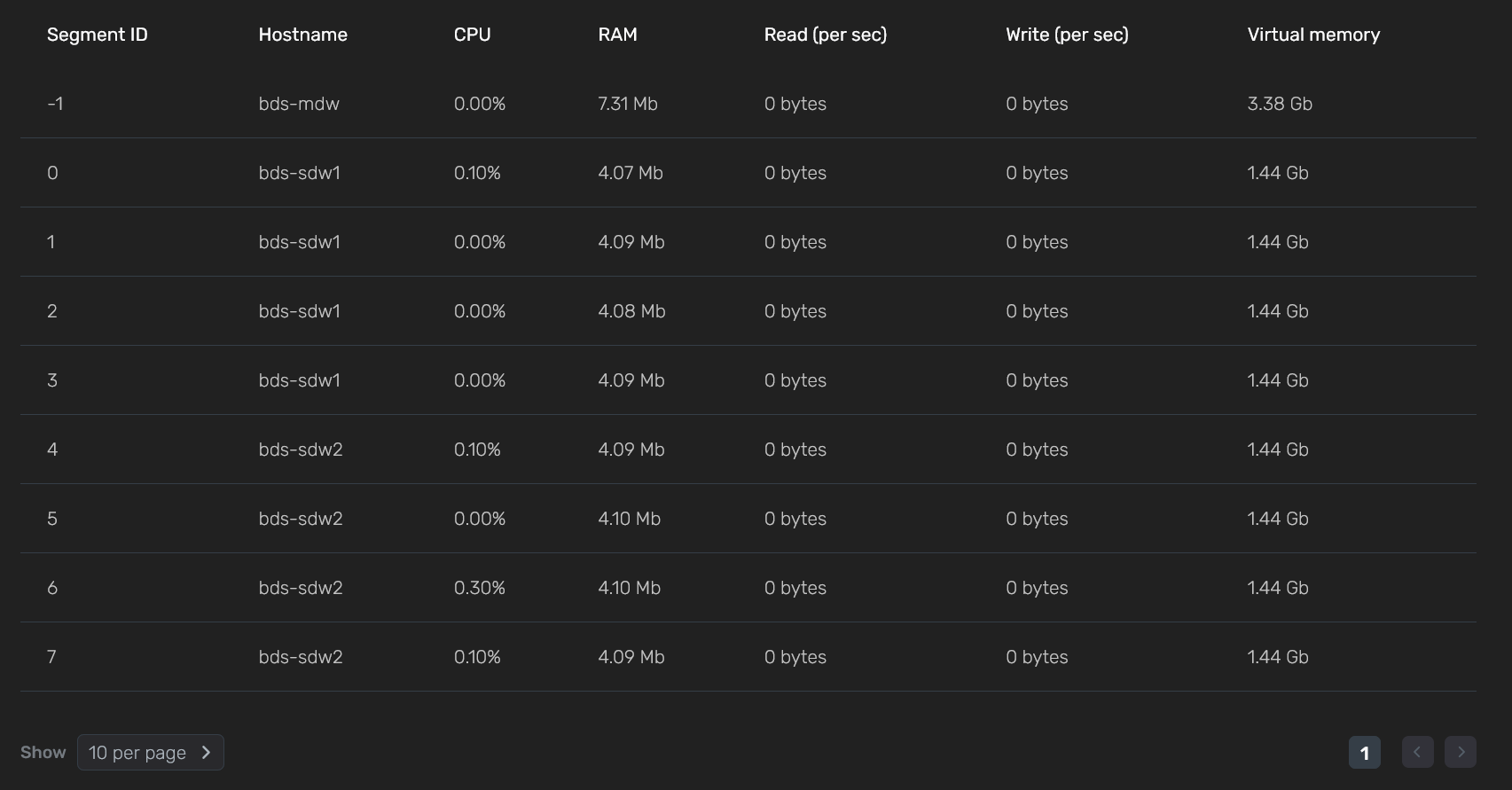
В нижней части секции Performance показываются значения метрик отдельно для каждого сегмента кластера, включая координатор-сегмент seg-1 (где Segment ID равен -1).
| Поле | Описание |
|---|---|
Segment ID |
Уникальный идентификатор сегмента данных. Ссылается на |
Hostname |
Название хоста |
CPU |
Объем потребляемого CPU в сегменте (в процентах). На основе значений метрики для всех сегментов рассчитывается средняя величина CPU avg usage % |
RAM |
Объем потребляемой памяти RAM в сегменте (в байтах). На основе значений метрики для всех сегментов рассчитывается средняя величина RAM average |
Read (per sec) |
Скорость чтения данных в секунду в сегменте (в байтах). На основе значений метрики для всех сегментов рассчитывается средняя величина Read avg per sec |
Write (per sec) |
Скорость записи данных в секунду в сегменте (в байтах). На основе значений метрики для всех сегментов рассчитывается средняя величина Write avg per sec |
Virtual memory |
Объем выделенной виртуальной памяти в сегменте (в байтах). На основе значений метрики для всех сегментов рассчитывается средняя величина Virtual memory average |
Spill size |
Размер spill-файлов (в байтах). Поле заполняется, если на вкладке Configuration → General → Metrics параметру Spill metrics collection mode присвоено значение |
Spill files number |
Количество spill-файлов. Поле заполняется, если на вкладке Configuration → General → Metrics параметру Spill metrics collection mode присвоено значение |
Начиная с версии ADBM 2.1.2 для таблицы, изображенной выше, доступны фильтрация и сортировка данных:
-
Фильтры предусмотрены для столбцов Segment ID и Hostname. Для применения фильтра нажмите на иконку

 в заголовке столбца и введите искомое значение. Иконка
в заголовке столбца и введите искомое значение. Иконка 
 означает, что для столбца определен фильтр. Для сброса всех фильтров нажмите Reset.
означает, что для столбца определен фильтр. Для сброса всех фильтров нажмите Reset. -
Сортировка данных возможна во всех столбцах, кроме Hostname. Для изменения порядка сортировки данных в выбранном столбце нажмите на иконку

 или
или 
 в его заголовке.
в его заголовке.
|
ВАЖНО
Запрос системных метрик на сегментах ADB производится агентами ADB Control только для команд с продолжительностью дольше 15 секунд. Поэтому для команд, которые успевают завершиться быстрее этого времени, секция с метриками будет пустой. |
Command text
Секция Command text показывает текст запроса, который можно скопировать нажав на иконку 
 в верхнем правом углу фрагмента с кодом.
в верхнем правом углу фрагмента с кодом.


Секции с планом выполнения
Под секцией Command text расположены несколько вкладок, показывающих детали выполнения запроса:
-
Plan & progress
-
Text
-
Relations
Первая вкладка Plan & progress содержит графическое представление плана запроса в виде дерева. Выполнение производится снизу вверх — от дочерних узлов к корневому. В каждом узле плана отображается тип выполняемой операции, а также следующая информация:
-
Если запрос к БД выполняется:
-
Фактическое число извлеченных кортежей на текущий момент. Параметр обновляется в процессе выполнения.
-
Фактическое время выполнения слайса (группы узлов плана) на текущий момент. Параметр обновляется в процессе выполнения и отображается на всех узлах, принадлежащих одному слайсу.
-
-
Если запрос к БД завершен:
-
Общее фактическое время выполнения узла плана.
-
Общее фактическое число извлеченных кортежей.
-
Отношение времени обработки узла плана к общему времени выполнения запроса (в процентах).
-
В верхнем правом углу каждого узла плана выводится иконка, соответствующая его статусу:
-
 — узел плана выполняется.
— узел плана выполняется. -
 — узел плана завершен.
— узел плана завершен. -
 — при выполнении слайса, в который входит узел плана, зафиксирована ошибка. Статус доступен начиная с версии ADB Control 4.10.3. Узлы слайсов с ошибками выделяются красным цветом.
— при выполнении слайса, в который входит узел плана, зафиксирована ошибка. Статус доступен начиная с версии ADB Control 4.10.3. Узлы слайсов с ошибками выделяются красным цветом. -
 — узел плана недостижим. В этот статус переводятся узлы, находящиеся по дереву выше ошибочного слайса, а также те, чей родительский узел попал в ошибочный слайс, находясь в статусе инициализации (до начала выполнения). Статус доступен начиная с версии ADB Control 4.10.3.
— узел плана недостижим. В этот статус переводятся узлы, находящиеся по дереву выше ошибочного слайса, а также те, чей родительский узел попал в ошибочный слайс, находясь в статусе инициализации (до начала выполнения). Статус доступен начиная с версии ADB Control 4.10.3.
Узлы плана, относящиеся к одному слайсу, выделяются одинаковым цветом, а также имеют одинаковый статус.
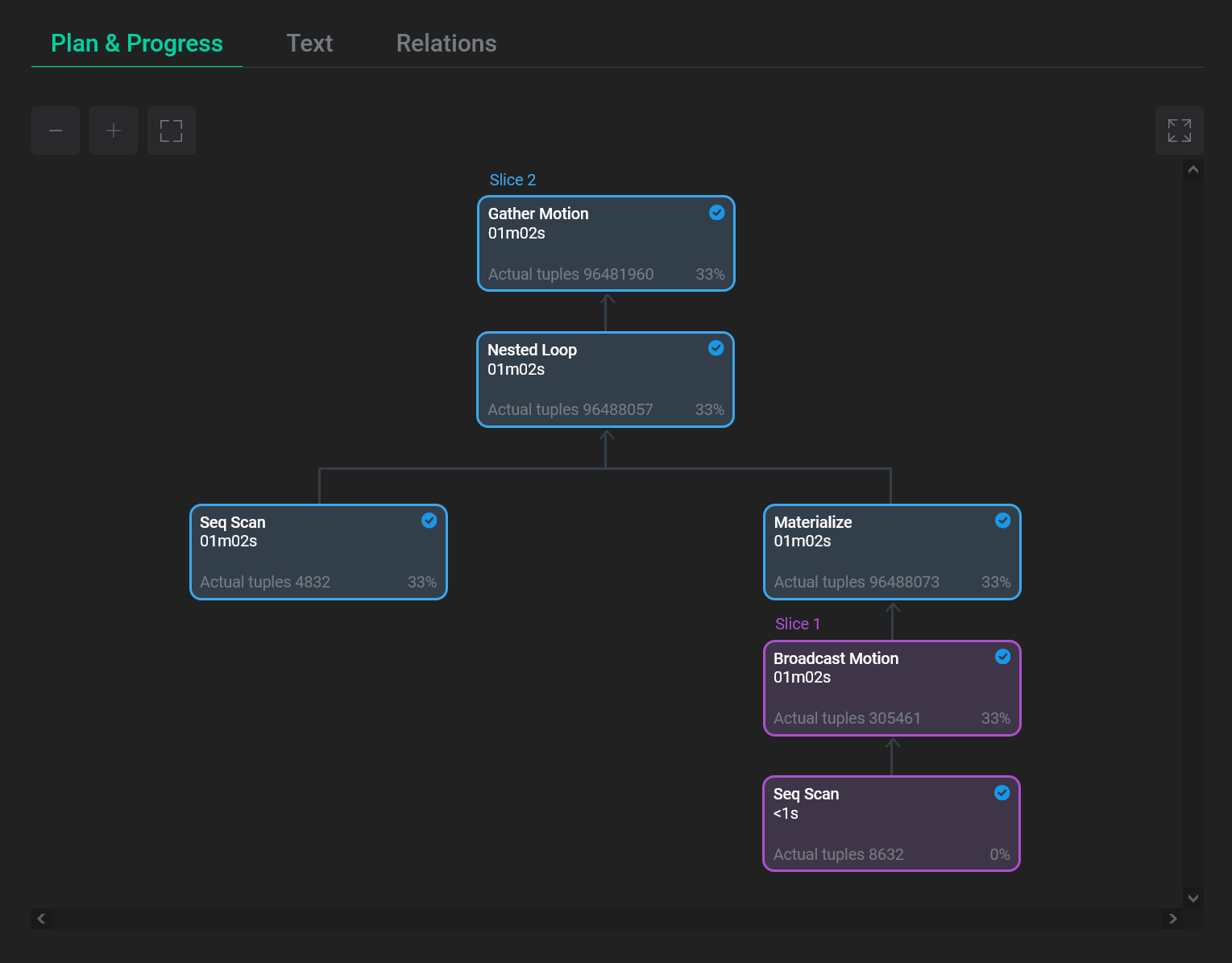
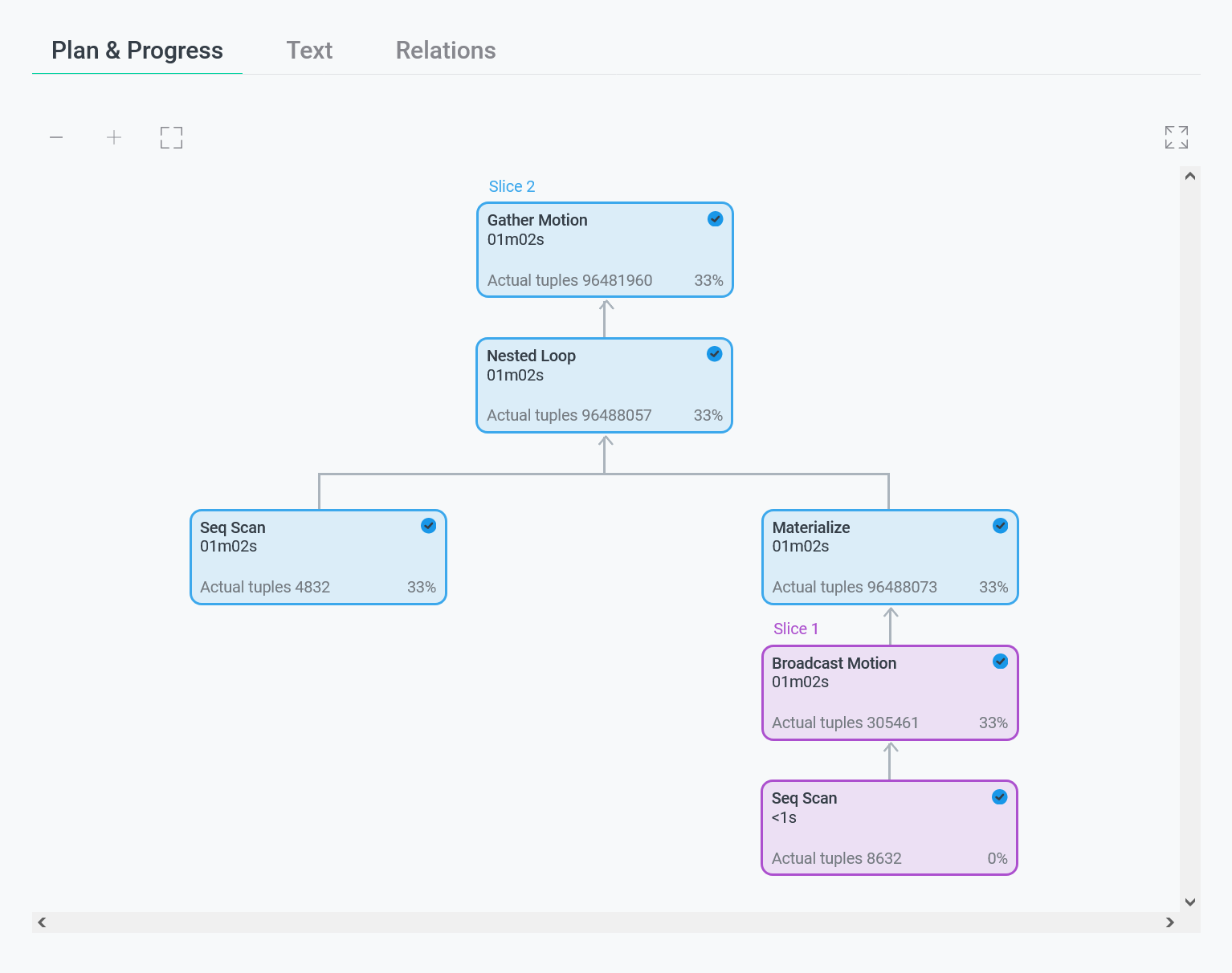
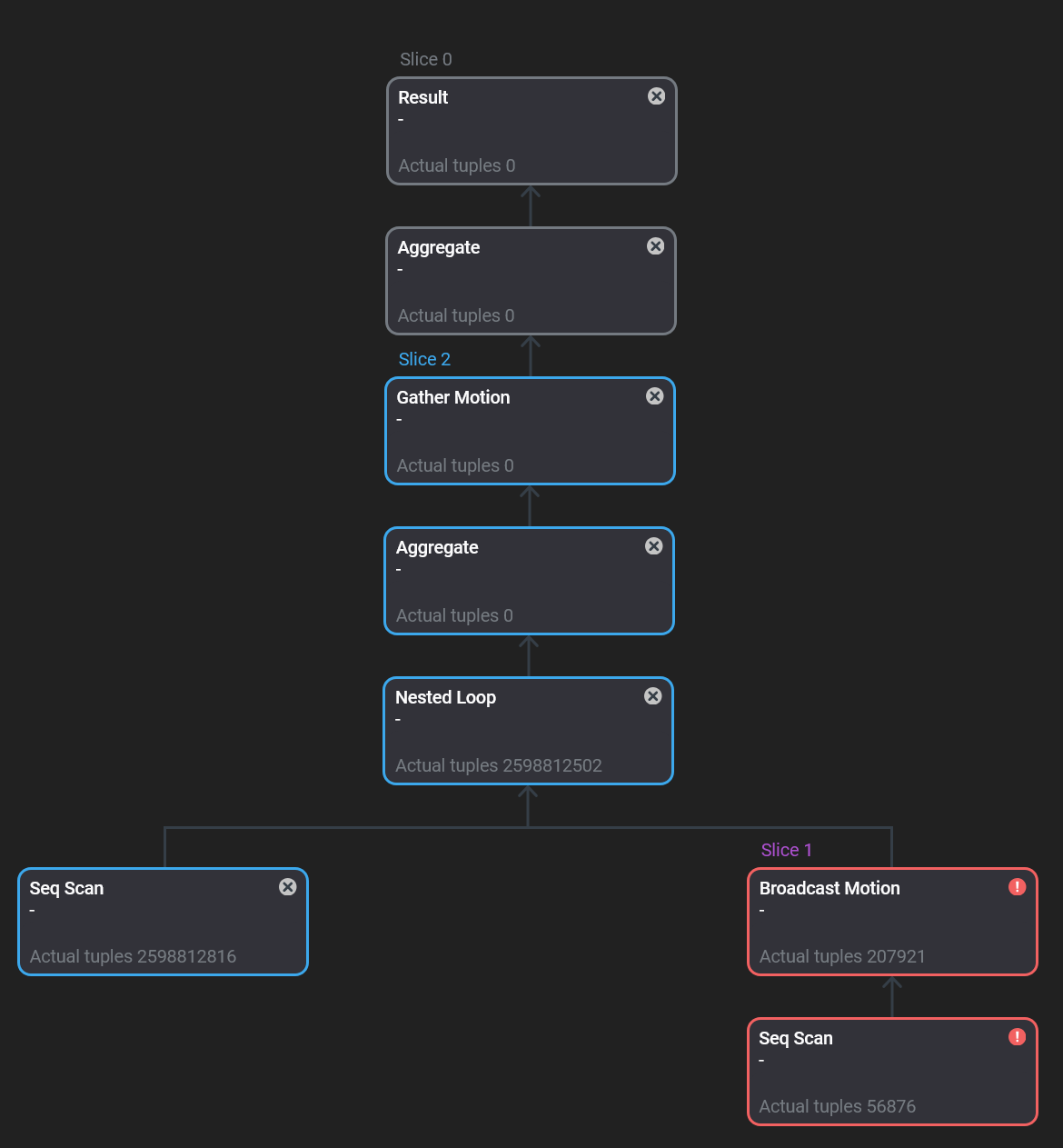
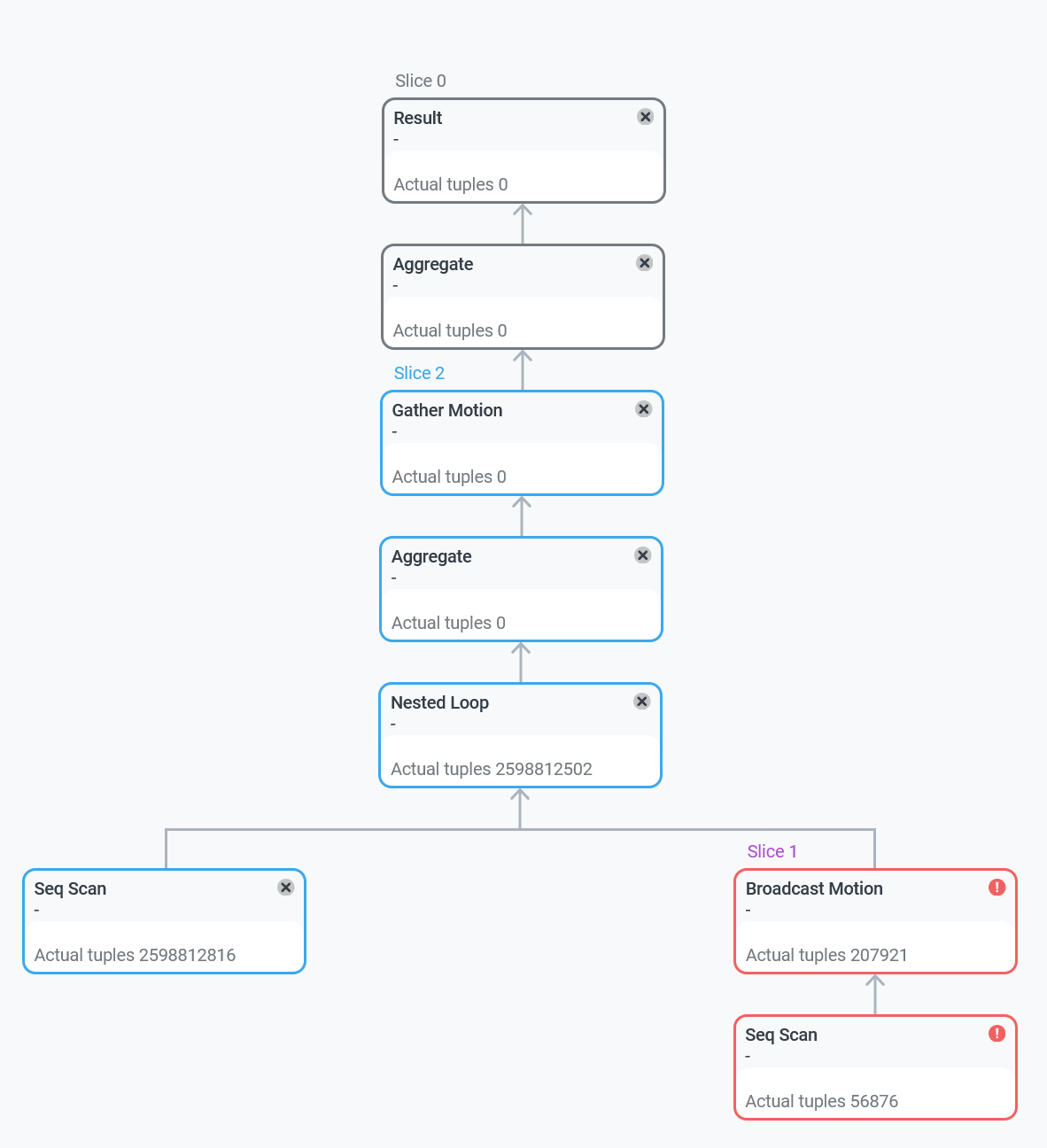
При нажатии на узел плана в правой части экрана открывается панель с дополнительной информацией.
| Поле | Описание |
|---|---|
Cost |
Коэффициент трудоемкости выполнения узла плана |
Schema |
Имя схемы. Используется, чтобы отличать одноименные таблицы, принадлежащие различным схемам |
Relation |
Используемое отношение |
Row skew |
"Перекос" в данных (skew). Разность между единицей и отношением среднего значения количества кортежей, полученных с сегментов, к максимальному: |
Est.tuples |
Прогнозируемое количество кортежей, которое потребуется извлечь на текущем этапе выполнения плана |
Actual tuples |
Реальное количество извлеченных кортежей |
Prediction accuracy |
Отношение реального количества извлеченных кортежей к спрогнозированному (в процентах). Значение, превышающее 100%, указывает на то, что планировщик сделал неправильное предположение о количестве кортежей, которое потребуется извлечь при выполнении узла плана (их оказалось больше) |
Operation keys |
Дополнительные условия, используемые при выполнении некоторых операций. Например, |
Execution time |
Время выполнения узла плана в часах, минутах, секундах |
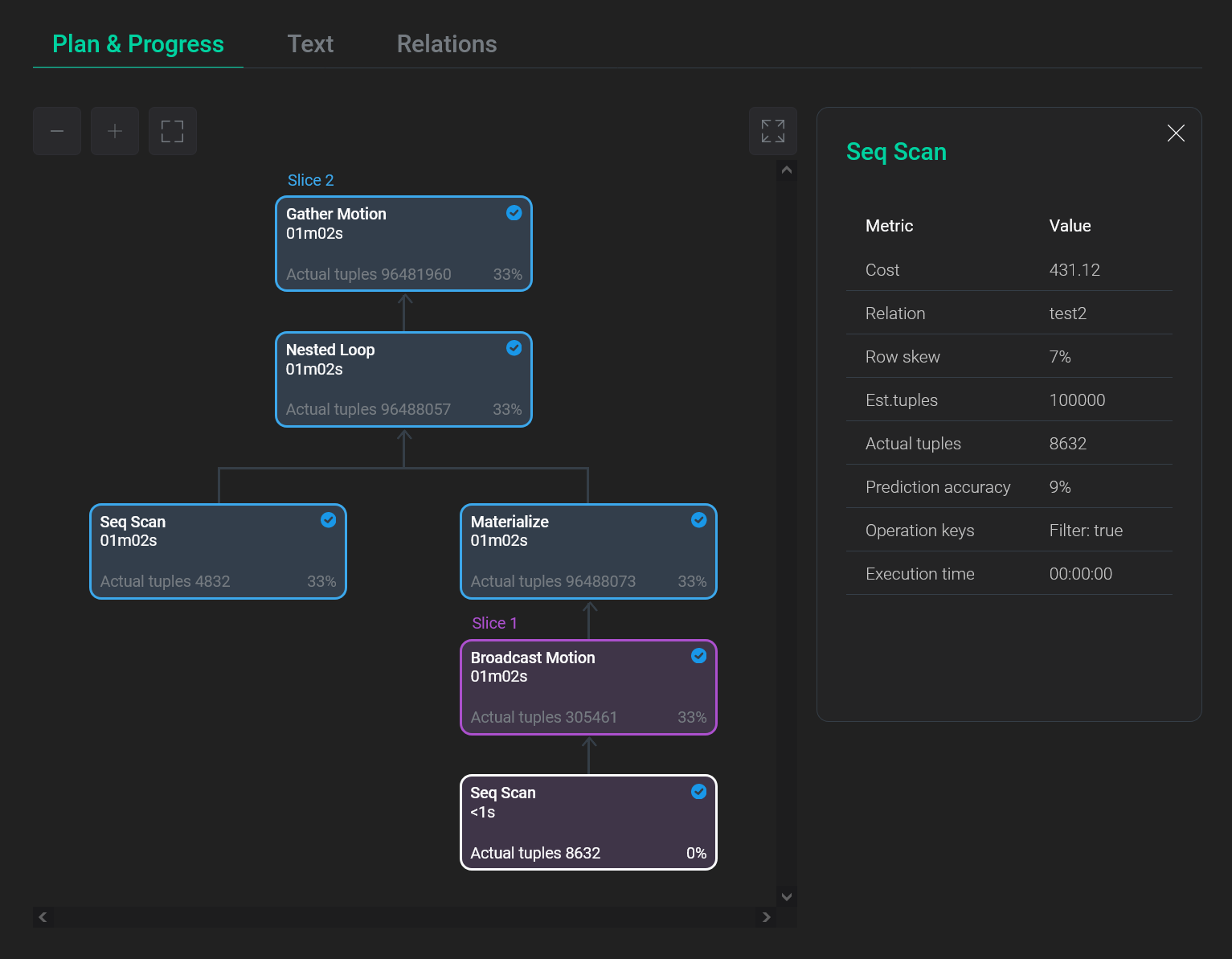
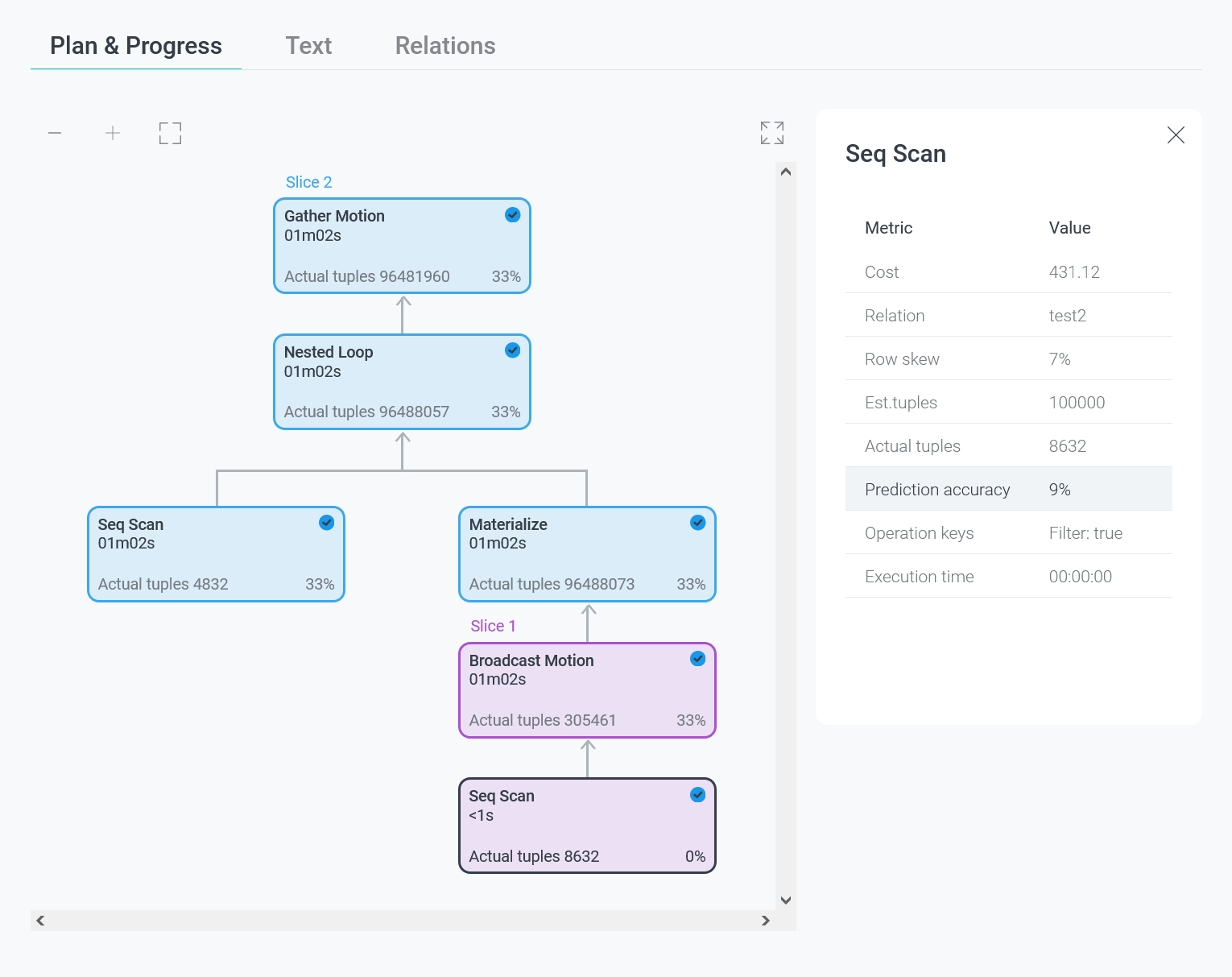
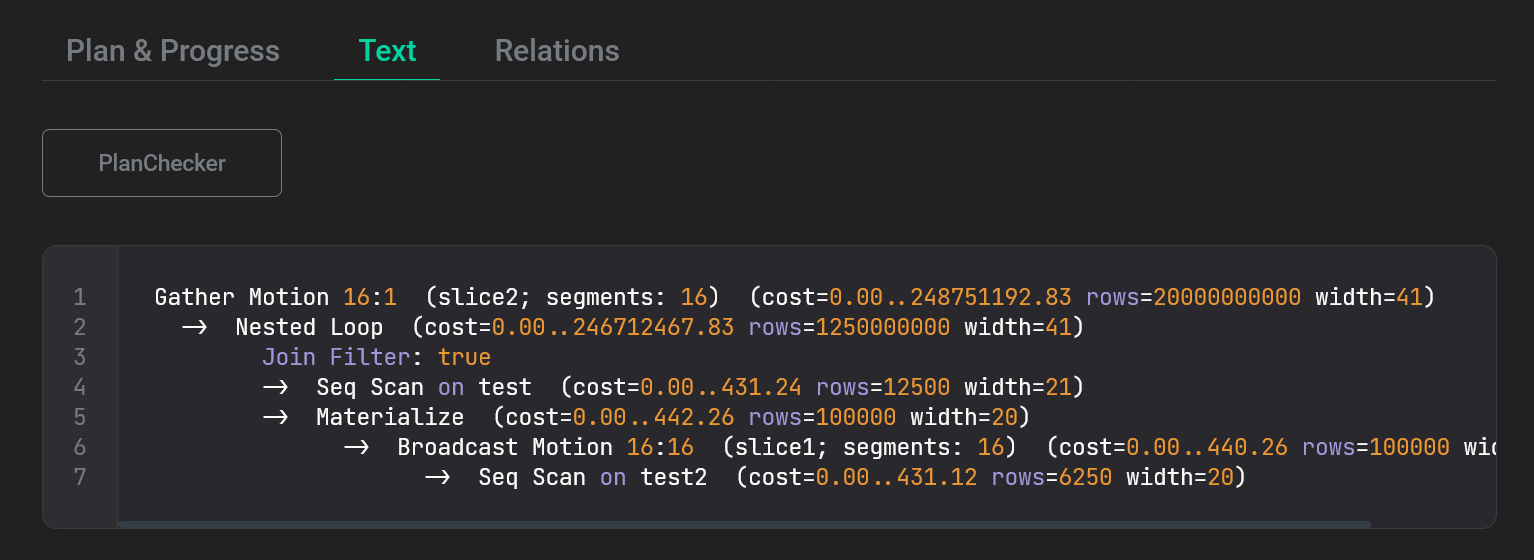
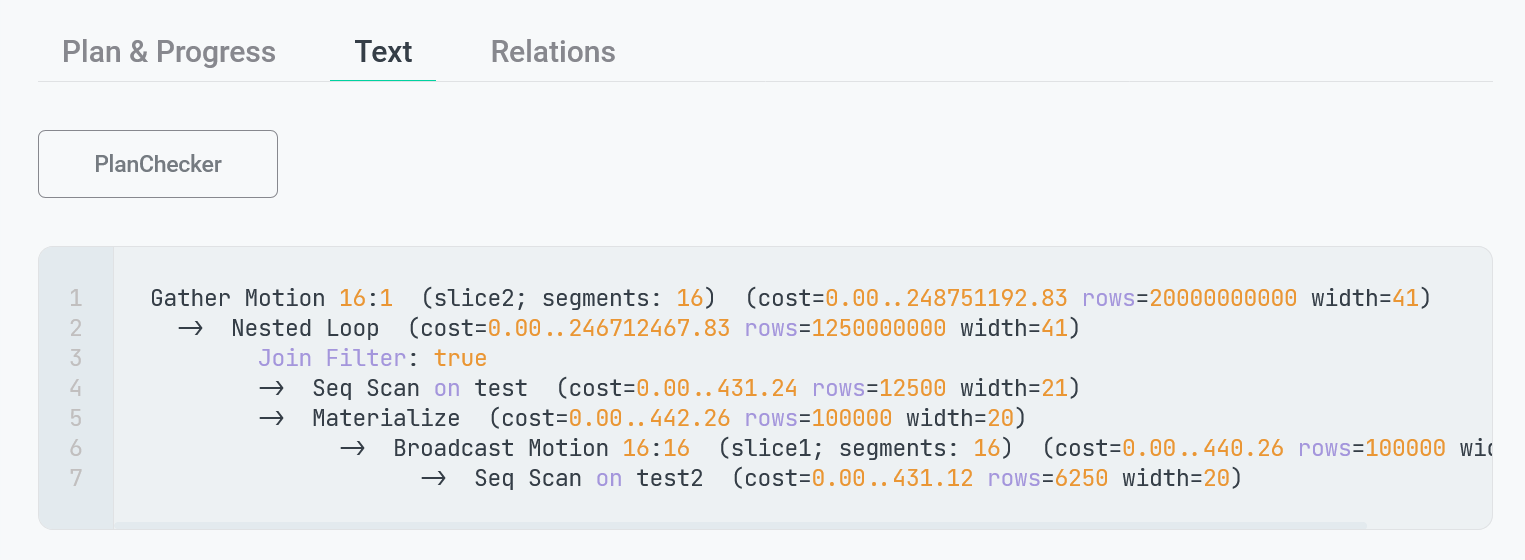
Следующая вкладка Text выводит текстовое представление плана запроса, которое является результатом выполнения команды EXPLAIN. Текст можно скопировать нажав на иконку в верхнем правом углу фрагмента с кодом.
Последняя вкладка Relations выводит список отношений, используемых в запросе. Для каждого отношения наряду с именем отображается название соответствующей схемы БД.
|
ПРИМЕЧАНИЕ
Нажав на конкретную строку в таблице со списком отношений, можно перейти к просмотру деталей аудита обращений к выбранному отношению. Этот функционал доступен для пользователей ADB Control с соответствующими разрешениями (см. |
Метрики, собираемые для команд
Обе рассмотренные выше вкладки Online и History позволяют посмотреть статистику потребления системных ресурсов запущенными командами (на вкладке Performance в деталях команды). Доступные для команд метрики описаны ниже.
|
ПРИМЕЧАНИЕ
|
| Группа | Метрика | Описание |
|---|---|---|
CPU |
CPU usage total |
Общее время потребления CPU по сегментам кластера (в секундах) |
CPU avg usage % |
Среднее потребление CPU (в процентах) процессами, участвующими в выполнении запроса на сегментах кластера. Рассчитывается как результат деления суммарного потребления CPU на всех сегментах кластера (исключая координатор и standby) на общее число процессов, обрабатывающих запрос на сегмент-хостах (исключая координатор и standby) |
|
CPU skew |
Показатель, отражающий "перекос" (skew) в потреблении CPU по сегментам кластера (в процентах). Значение, отличное от нуля, говорит о том, что один из сегментов использует больший объем CPU, чем остальные |
|
RAM |
RAM average |
Средний объем потребляемой памяти RAM по сегментам кластера (в байтах). Потребление RAM в каждый конкретный момент рассчитывается на основе метрики rss (Resident Set Size) из операционной системы |
RAM skew |
Показатель, отражающий "перекос" (skew) в потреблении RAM по сегментам кластера (в процентах). Значение, отличное от нуля, говорит о том, что один из сегментов использует больший объем RAM, чем остальные |
|
Virtual memory |
Virtual memory average |
Средний объем выделенной виртуальной памяти по сегментам кластера (в байтах). Потребление виртуальной памяти в каждый конкретный момент рассчитывается на основе метрики vsize (Virtual Memory Size) из операционной системы |
Virtual memory skew |
Показатель, отражающий "перекос" (skew) в выделении виртуальной памяти по сегментам кластера (в процентах). Значение, отличное от нуля, говорит о том, что один из сегментов использует больший объем виртуальной памяти, чем остальные |
|
Read |
Read total |
Общий объем прочитанных данных по сегментам кластера (в байтах). Для расчета используется следующая формула: |
Read avg per sec |
Усредненный показатель скорости чтения данных в секунду по сегментам кластера (в байтах). Скорость чтения в каждый конкретный момент рассчитывается на основе информации об I/O Read из /proc/[pid]/stat операционной системы как дельта между текущим и предыдущим значением |
|
Read skew |
Показатель, отражающий "перекос" в чтении данных по сегментам кластера (в процентах). Значение, отличное от нуля, говорит о том, что один из сегментов считывает больший объем с диска, чем остальные |
|
Write |
Write total |
Общий объем записанных данных по сегментам кластера (в байтах). Для расчета используется следующая формула: |
Write avg per sec |
Усредненный показатель скорости записи данных в секунду по сегментам кластера (в байтах). Скорость записи в каждый конкретный момент рассчитывается на основе информации об I/O Write из /proc/[pid]/stat операционной системы как дельта между текущим и предыдущим значением |
|
Write skew |
Показатель, отражающий "перекос" (skew) в записи данных по сегментам кластера (в процентах). Значение, отличное от нуля, говорит о том, что один из сегментов записывает на диск больший объем, чем остальные |
|
Spill files |
Spill files host |
Общий объем spill-файлов на хостах кластера на текущий момент времени (в байтах) |
Spill files abs host |
Максимальная величина Spill files host, зафиксированная на хостах кластера за время выполнения команды (в байтах) |
|
Spill files abs seg |
Максимальный объем использованных spill-файлов одним сегментом кластера за время выполнения команды (в байтах) |
|
Spill files skew |
Показатель, отражающий "перекос" (skew) в объеме использованных spill-файлов (в процентах) на текущий момент времени. Значение, отличное от нуля, говорит о том, что один из сегментов использует больший объем spill-файлов, чем остальные |
|
Spill files abs seg skew |
Показатель, отражающий "перекос" (skew) в объеме использованных spill-файлов (в процентах) на момент времени, в который наблюдалась величина Spill files abs seg. Вычисление производится на основе следующей формулы: |
Groups
Группа запросов (query group) — это набор SQL-запросов, сгруппированных по SQL ID, номеру узла (node number) и типу узла (node type) в плане выполнения запроса.
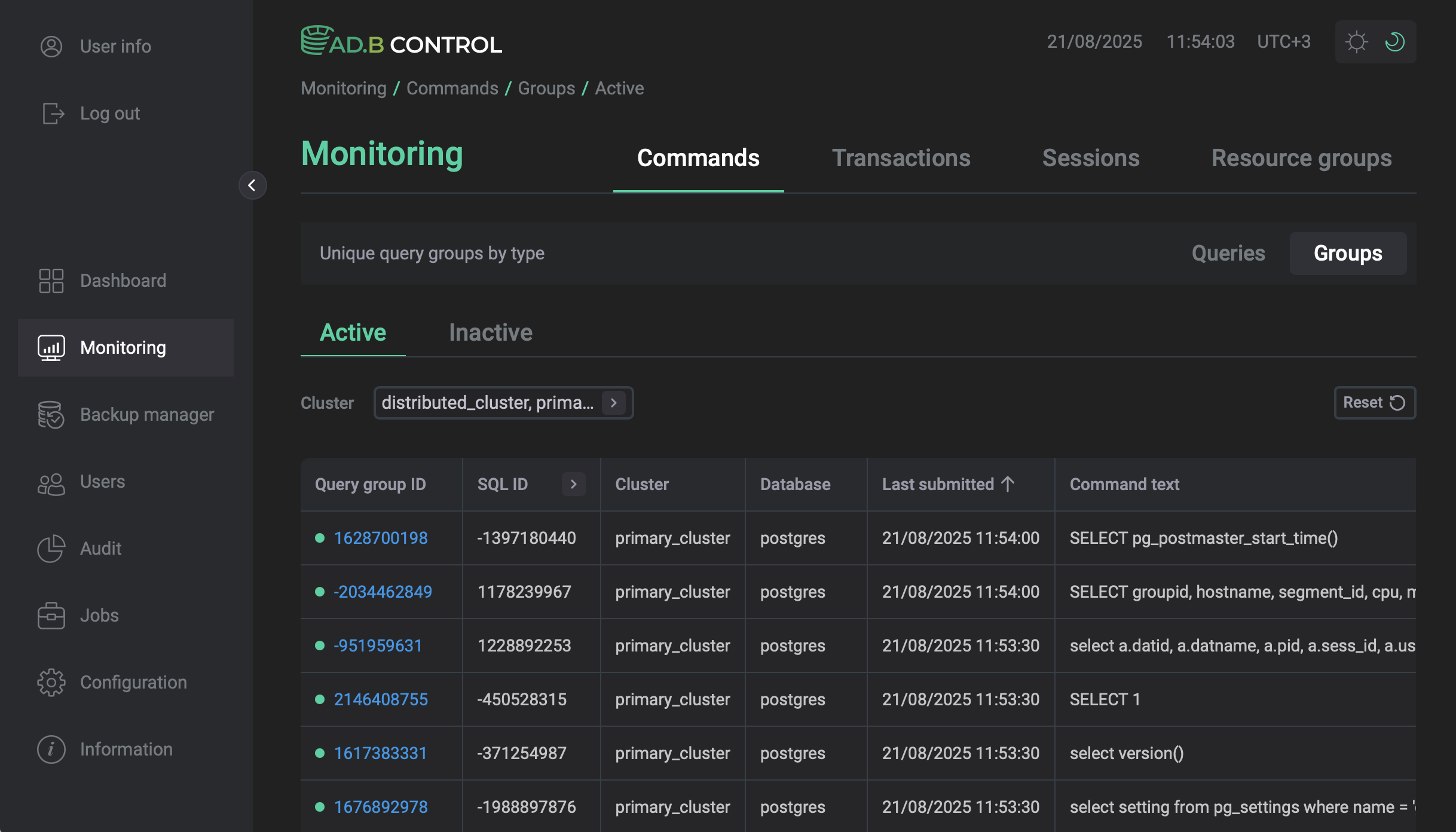
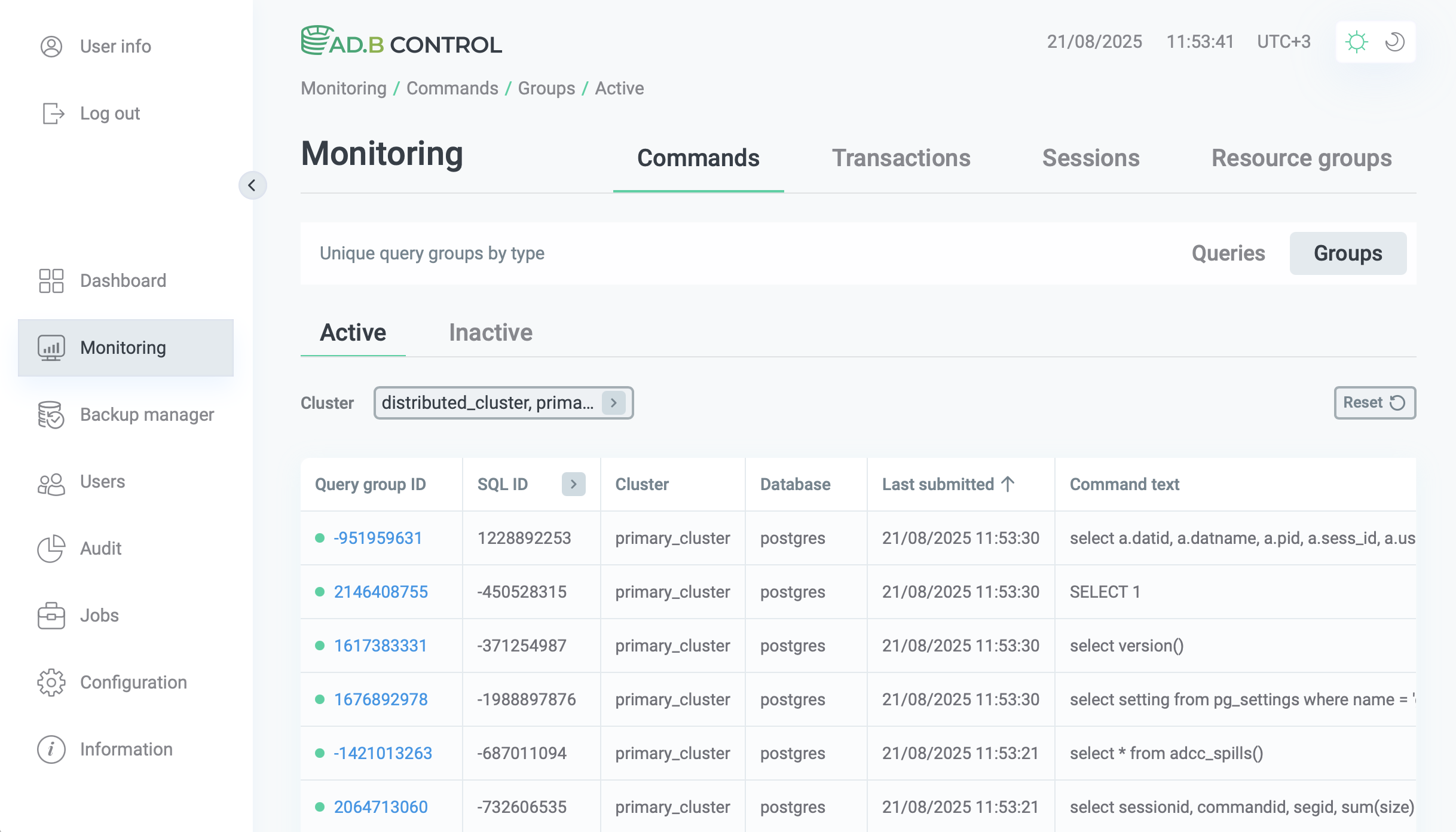
При получении SQL-запроса ADB Control создает группу для каждой новой комбинации SQL ID, номера узла и типа узла. Если следующий запрос совпадает с существующей группой по этим параметрам, он считается принадлежащим к этой группе, при этом у группы обновляется параметр Last submitted. Если запрос не совпадает ни с одной группой, создается новая группа.
|
ПРИМЕЧАНИЕ
В данный момент то, на какой вкладке будет отображен SQL-запрос, зависит от его длительности:
|
Группы запросов могут быть активными (active) и неактивными (inactive) в зависимости от времени последнего запроса в группе. Если время последнего запроса приходится на последние 5 минут, группа считается активной и отображается на вкладке Active. Если с момента последнего запроса в группе прошло больше 5 минут, она считается неактивной и отображается на вкладке Inactive.
Таблица, расположенная на вкладке Monitoring → Commands → Groups, выводит следующую информацию о группах.
| Поле | Описание |
|---|---|
Query group ID |
Идентификатор группы, рассчитываемый как хеш от SQL ID, номера узла и типа узла |
SQL ID |
Идентификатор, являющийся общим для SQL-команд с одинаковой структурой |
Cluster |
Название кластера, в котором запущены запросы группы |
Database |
Название базы данных, в которой запущены запросы группы |
Last submitted |
Время последнего запроса в группе |
Command text |
Текст первого запроса в группе |
Type |
Тип группы. В данный момент поддерживается только тип |
Над таблицей со списком групп расположен фильтр Cluster, в котором можно выбрать кластер ADB и его базы данных, для которых требуется вывести данные в таблице. По умолчанию выбраны все БД кластера, отмеченного как дефолтный в настройках ADB Control.
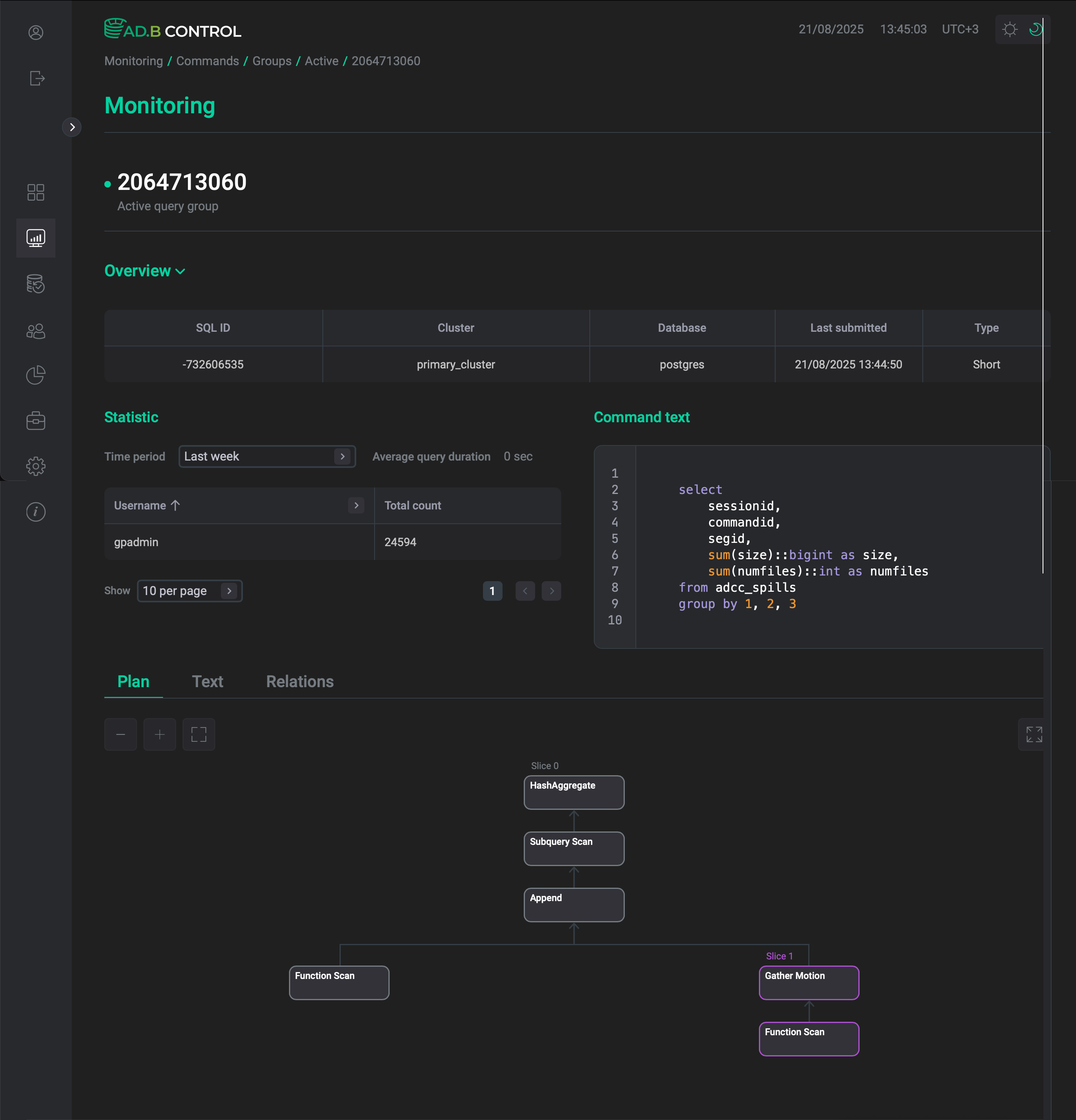
Детали группы
Чтобы просмотреть детальную информацию о группе, нажмите на ее идентификатор в столбце Query group ID.
Открывшаяся страница содержит следующие секции:
-
Overview показывает основные параметры группы, описанные в таблице выше.
-
Statistic показывает среднее время выполнения команды и количество команд по каждому пользователю. С помощью фильтра Time period вы можете просмотреть данные за последний час, последний день или последнюю неделю.
-
Command text показывает текст первого запроса в группе.
-
Plan, Text и Relations — описание вкладок приводится в разделе Детали команды → Секции с планом выполнения.
|
ПРИМЕЧАНИЕ
В отличие от вкладки Queries, группы запросов не показывают прогресс выполнения и статусы узлов плана. |
SQL ID
SQL ID — это идентификатор структуры SQL-команды.
Он используется в ADB Control для идентификации команд с одинаковой структурой и для объединения их в группы.
SQL ID в ADB Control соответствует значению queryid из таблицы pg_stat_statements в ADB.
Семантически эквивалентные SQL-команды имеют один и тот же SQL ID. На практике это означает, что свойства команд, описанные ниже, будут совпадать.
Подзапросы анализируются рекурсивно в соответствии с теми же принципами.
Факторы, влияющие на SQL ID
Если следующие свойства SQL-команд различаются, командам будут присвоены разные SQL ID.
| Свойство | Примеры команд с разными SQL ID |
|---|---|
Тип операции: |
|
Отношения (relation), над которыми производится действие |
|
Затронутые столбцы, в том числе их порядок в запросе |
|
Функции. Независимо от аргументов разные функции приводят к присвоению разных SQL ID |
|
Общие табличные выражения (Common table expression, CTE). Структура CTE и порядок (если их несколько). Отличия в названиях CTE также приведут к присвоению отдельных SQL ID, даже если их содержимое совпадает |
|
Условие |
|
|
|
|
|
|
|
Оконные функции — присваиваются отдельные SQL ID при разнице в столбцах, функциях и операторах |
|
Присваиваются отдельные SQL ID при использовании |
|
Факторы, не влияющие на SQL ID
Если тексты SQL-команд отличаются только следующими свойствами, такие команды будут иметь одинаковый SQL ID.
| Свойство | Примеры команд с одинаковым SQL ID |
|---|---|
Алиасы |
|
Константы в операторах и функциях |
|
Переводы строк, пробелы и табуляция |
|
Блокировки |
|
Все служебные (utility) команды (то есть команды, отличные от Если служебная команда имеет подзапрос, который не является служебной командой, то такой подзапрос будет иметь отдельный SQL ID |
|