

Просмотр дашборда
На странице Dashboard web-интерфейса ADQM Control выводится общая информация о состоянии кластера ADQM в виде:
-
Heat map — визуальное представление состояния хостов кластера ADQM.
-
Recent alerts — список последних оповещений о потенциальных и критических проблемах, обнаруженных на хостах кластера ADQM.
-
Top 10 tables — 10 самых больших по объему данных таблиц в кластере ADQM и 10 таблиц, в которые направлено наибольшее количество запросов.
-
Top 10 queries — 10 самых долгих по времени выполнения запросов и 10 запросов, использовавших наибольшее количество памяти.
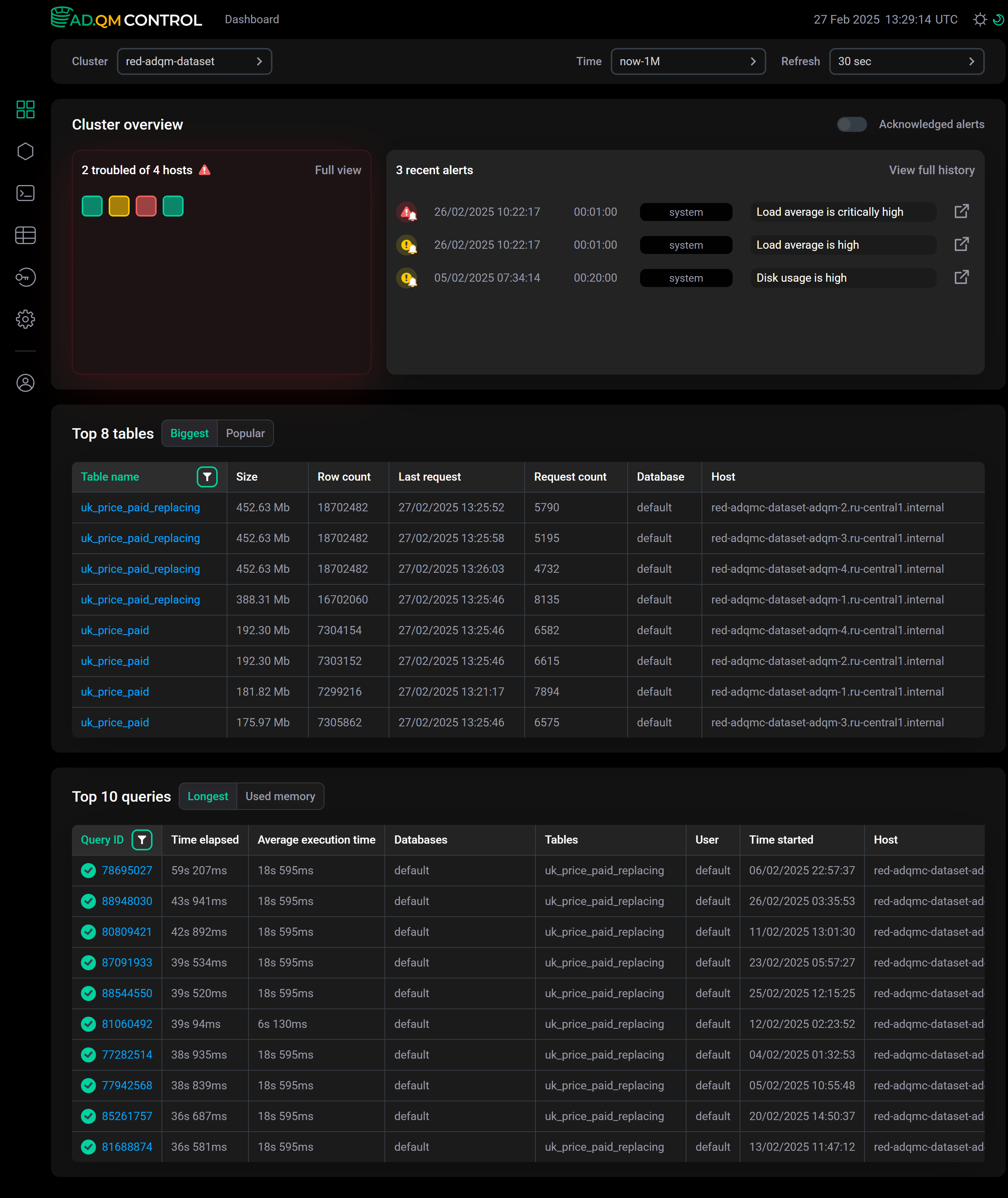
В верхней части экрана можно настроить следующие фильтры отбора данных для построения дашборда:
-
Cluster — кластер ADQM, для которого выводится информация.
-
Time — временной период, за который требуется вывести информацию. При нажатии на поле открывается окно, в котором можно выбрать интервал из предложенных вариантов на вкладке Range либо самостоятельно установить границы временного диапазона (не менее 1 часа) на вкладке Calendar.
-
Refresh — частота обновления данных.
Cluster overview
Heat map
Heat map — это графическое представление данных о состоянии всех хостов кластера ADQM, где каждый хост изображается в виде квадрата, цвет которого обозначает состояние системы в выбранный интервал времени.
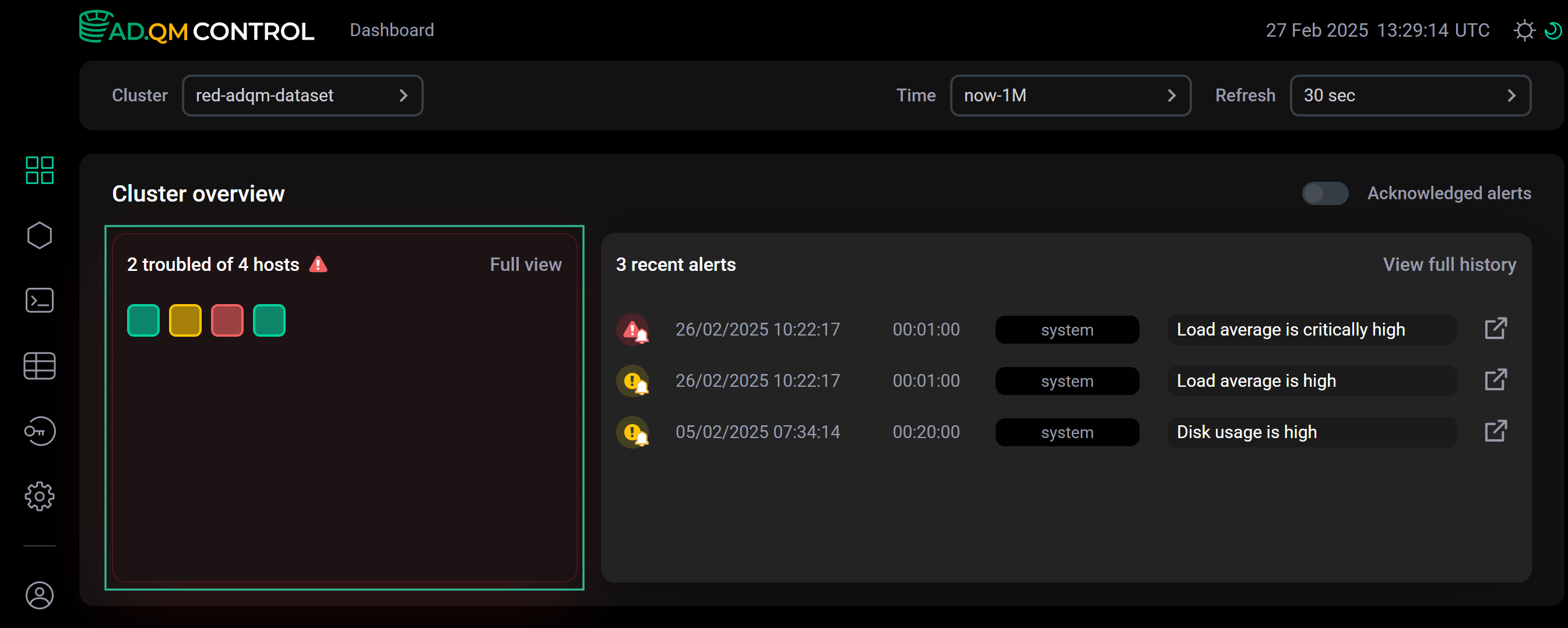
Состояние хоста и соответствующий ему цвет в матрице heat map определяется по наличию оповещений о проблемах на хосте:
 — в ADQM Control нет оповещений о каких-либо проблемах на хосте (healthy host).
— в ADQM Control нет оповещений о каких-либо проблемах на хосте (healthy host).
 — на хосте обнаружены только потенциальные проблемы (например, связанные с увеличением значений каких-либо системных метрик), которые пока не являются критическими. В ADQM Control сгенерированы соответствующие сообщения об этих проблемах — оповещения среднего уровня важности (warning alerts).
— на хосте обнаружены только потенциальные проблемы (например, связанные с увеличением значений каких-либо системных метрик), которые пока не являются критическими. В ADQM Control сгенерированы соответствующие сообщения об этих проблемах — оповещения среднего уровня важности (warning alerts).
 — на хосте обнаружена как минимум одна критическая проблема, оповещение о которой есть в ADQM Control (critical alert).
— на хосте обнаружена как минимум одна критическая проблема, оповещение о которой есть в ADQM Control (critical alert).
 — хост или сервис ADQMDB недоступен, оповещение об этом сгенерировано в ADQM Control (условия генерации этих оповещений настраиваются в Internal alerts).
— хост или сервис ADQMDB недоступен, оповещение об этом сгенерировано в ADQM Control (условия генерации этих оповещений настраиваются в Internal alerts).
|
РЕКОМЕНДАЦИЯ
Из ADQM Control можно перейти к интерфейсу ADQM Notebook (поддерживается в ADQM начиная с версии 25.8.16.34), который предоставляет различные функциональные возможности для работы с базами данных и таблицами ADQM. Чтобы это сделать, наведите курсор мыши на хост в Heat map и во всплывающем окне нажмите ADQM Notebook. |
Recent alerts
На странице Dashboard также выводится список последних оповещений (максимальное количество — 5) о проблемах на хостах кластера ADQM, отсортированных в порядке убывания по времени, когда оповещения были сгенерированы, а не по важности.
| Уровень важности оповещения | Описание | Условие генерации оповещения |
|---|---|---|
|
На хосте найдена потенциальная проблема |
Значение системной метрики превышает пороговое значение, установленное через параметр Warning в настройках System alerts |
|
На хосте найдена критическая проблема |
Значение системной метрики превышает пороговое значение, установленное через параметр Critical в настройках System alerts |


В Heat map можно выбрать один или несколько хостов (по клику) — тогда в списке Recent alerts будут показаны последние оповещения только для выбранных хостов.
При клике по View full history открывается вкладка Alerts history на странице Cluster metrics, где выводится полный список (история) оповещений за указанный период времени по всем хостам кластера, независимо от выбора хостов в Heat map на странице Dashboard.
Acknowledged alerts
С помощью опции Acknowledged alerts можно указать, какие оповещения о проблемах на хостах кластера должны учитываться при формировании heat map и списка recent alerts в ADQM Control:
![]()
![]() Acknowledged alerts — все оповещения, сгенерированные за выбранный период времени;
Acknowledged alerts — все оповещения, сгенерированные за выбранный период времени;
![]()
![]() Acknowledged alerts — только актуальные оповещения, т.е. не отмеченные как "известные/решенные" (acknowledged). Актуальные, требующие внимания оповещения в ADQM Control отмечаются значком "колокольчик":
Acknowledged alerts — только актуальные оповещения, т.е. не отмеченные как "известные/решенные" (acknowledged). Актуальные, требующие внимания оповещения в ADQM Control отмечаются значком "колокольчик":  или
или  .
.
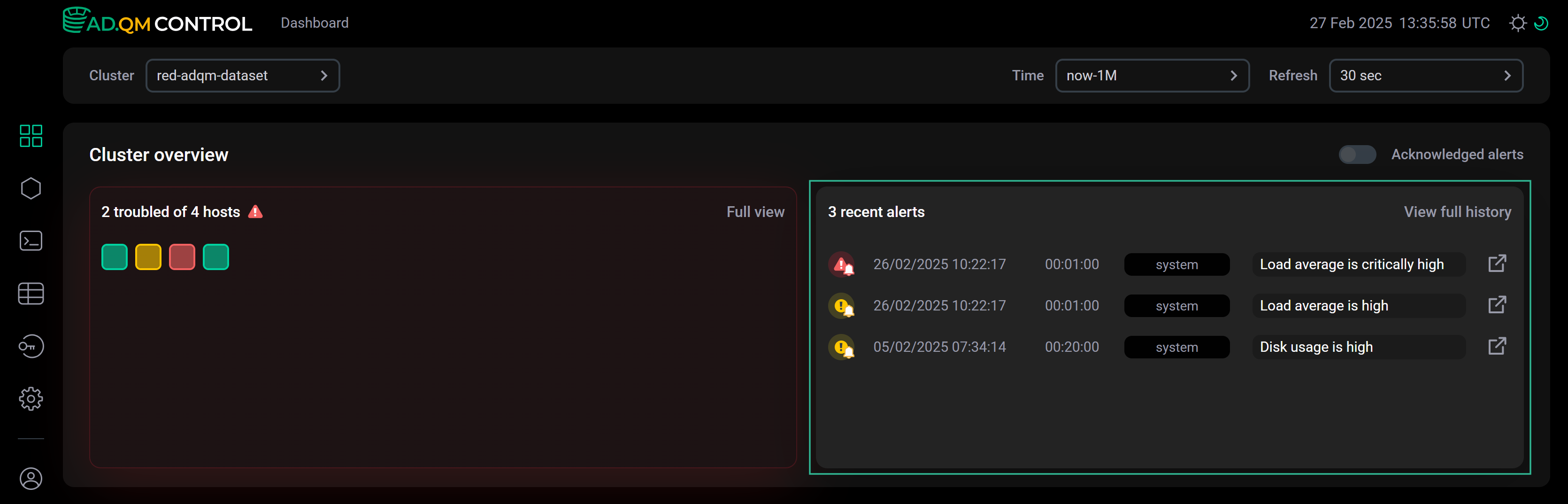
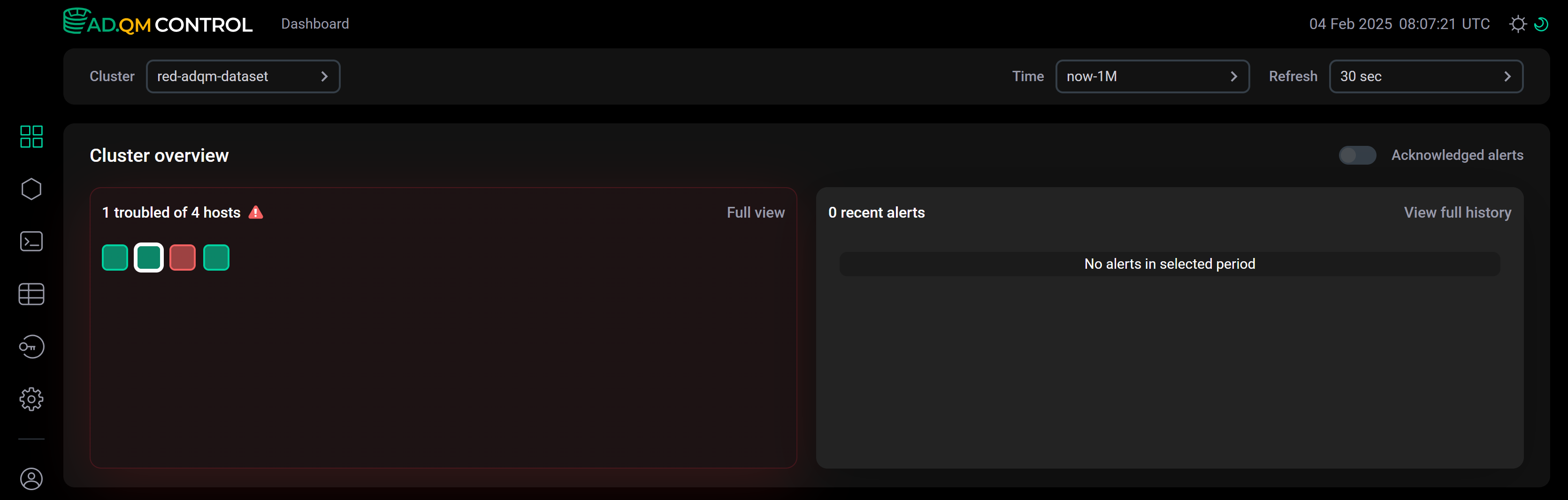
Например, на втором хосте кластера (выбран на рисунке ниже) не обнаружено каких-либо проблем за указанный промежуток времени или все оповещения о проблемах добавлены в acknowledged alerts — в этом случае при выключенной опции ![]()
![]() Acknowledged alerts этот хост в Heat map отмечается зеленым цветом, а список Recent alerts пустой.
Acknowledged alerts этот хост в Heat map отмечается зеленым цветом, а список Recent alerts пустой.
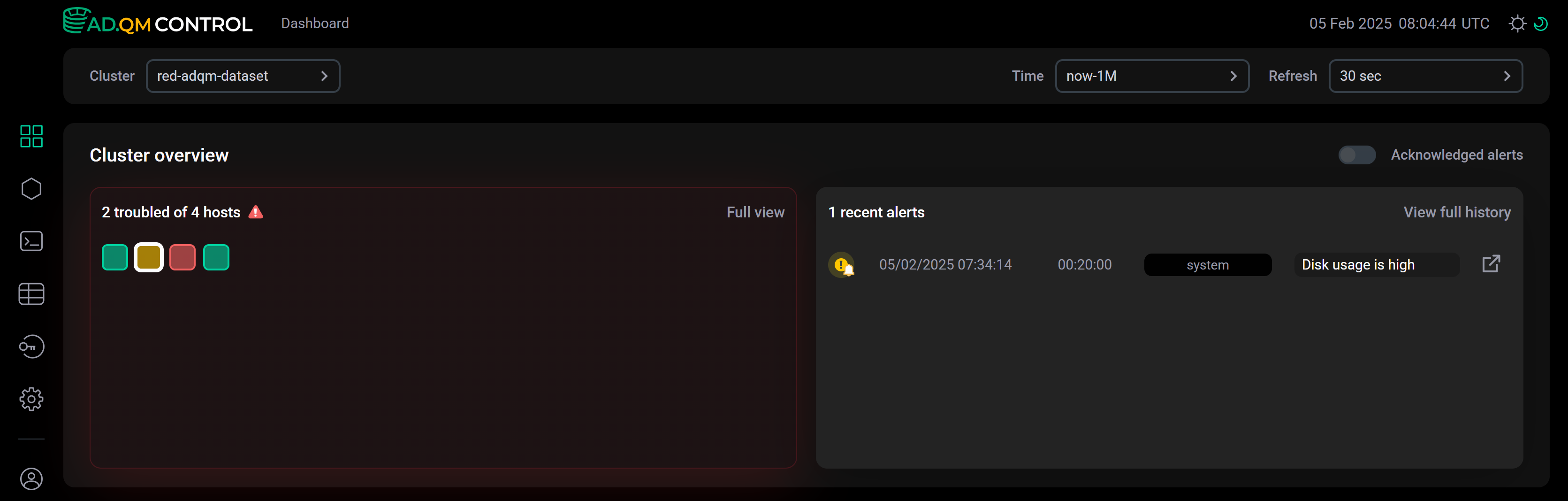
Затем на этом хосте возникла проблема Disk usage is high, о которой ADQM Control сгенерировал соответствующее оповещение-предупреждение. Это оповещение отображается в списке Recent alerts, а цвет хоста в Heat map меняется на желтый как показано на следующем рисунке.
Если проблема с использованием диска проанализирована и найдены способы ее решения, оповещение можно добавить в список acknowledged alerts (на странице с деталями оповещения — см. следующий раздел), так как эта проблема больше не требует внимания. После этого данное оповещение перестанет учитываться при мониторинге состояния кластера — в Heat map хост снова будет отображен зеленым цветом, а оповещение исчезнет из списка Recent alerts для этого хоста.
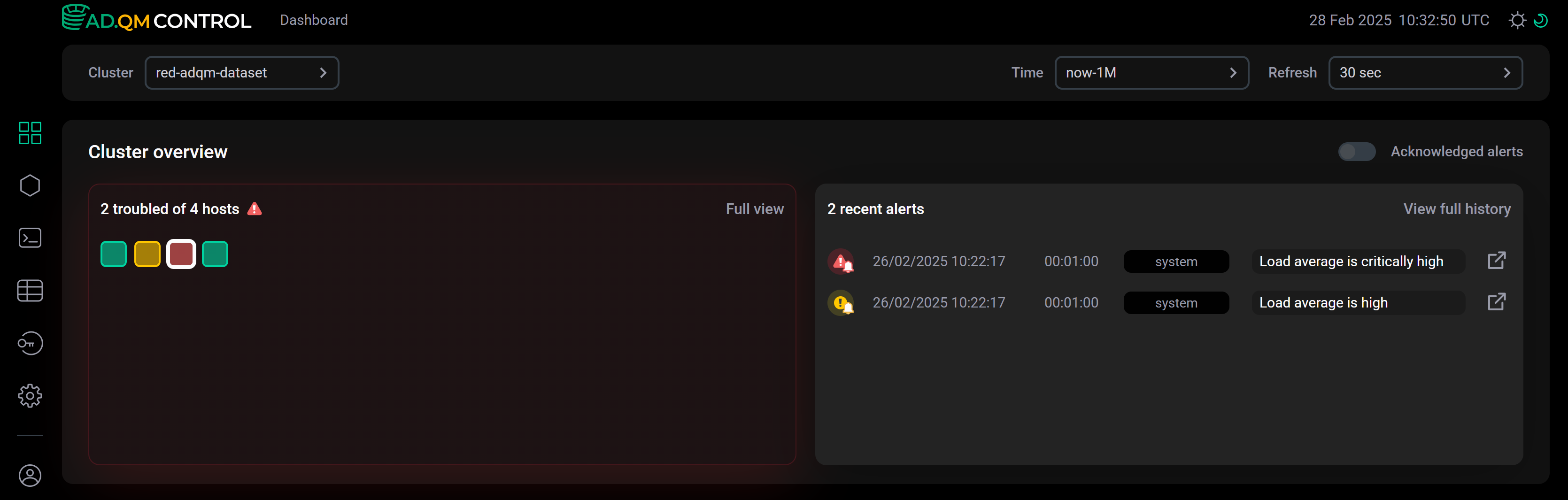
Если опция ![]()
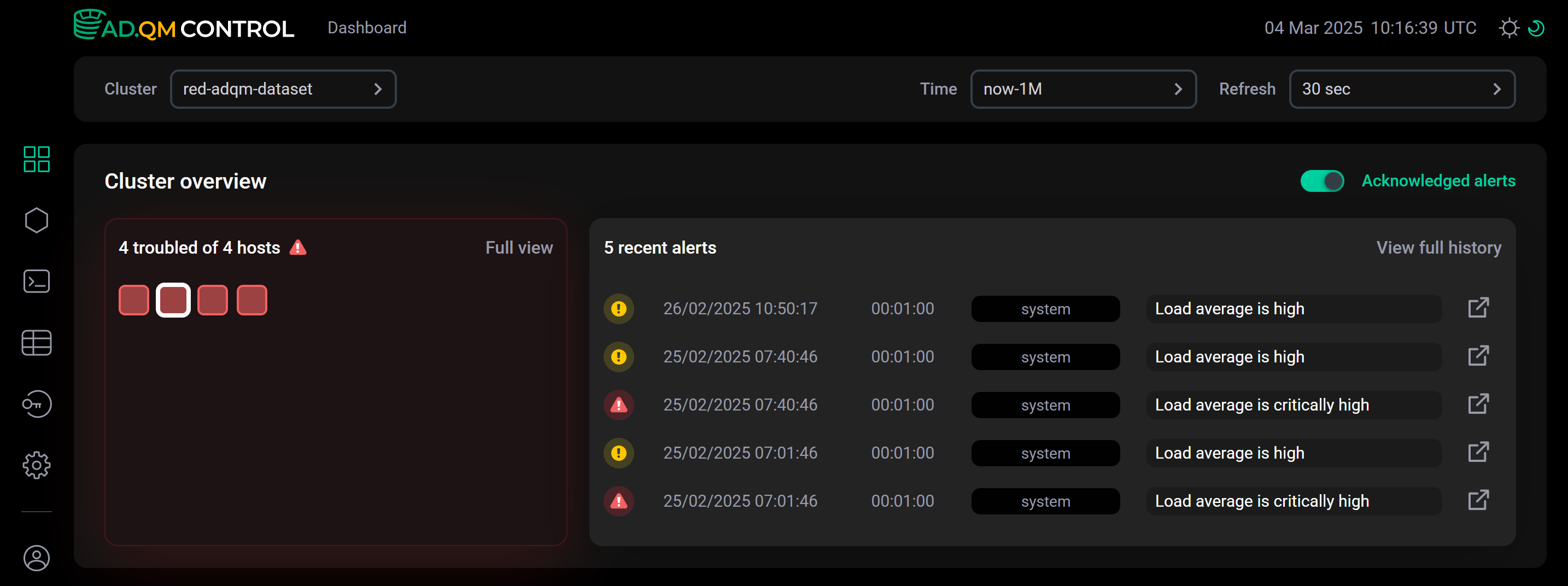
![]() Acknowledged alerts включена, в списке Recent alerts будут показаны последние оповещения, выбранные из всех сгенерированных за указанный период времени (активных и "закрытых"), и все оповещения будут учитываться при формировании матрицы состояния хостов. Например, на рисунке ниже все хосты кластера в Heat map обозначены красным цветом — это значит, что в течение выбранного периода времени (в данном примере — за последний месяц) на каждом из этих хостов была обнаружена хотя бы она критическая проблема. В списке Recent alerts видно, что среди последних по времени оповещений на выбранном хосте нет актуальных проблем (иконки оповещений без значка "колокольчик").
Acknowledged alerts включена, в списке Recent alerts будут показаны последние оповещения, выбранные из всех сгенерированных за указанный период времени (активных и "закрытых"), и все оповещения будут учитываться при формировании матрицы состояния хостов. Например, на рисунке ниже все хосты кластера в Heat map обозначены красным цветом — это значит, что в течение выбранного периода времени (в данном примере — за последний месяц) на каждом из этих хостов была обнаружена хотя бы она критическая проблема. В списке Recent alerts видно, что среди последних по времени оповещений на выбранном хосте нет актуальных проблем (иконки оповещений без значка "колокольчик").
Переход к деталям оповещения
Со страницы Dashboard можно перейти к просмотру детальной информации о конкретной проблеме на хосте одним из следующих способов:
-
В Heat map наведите курсор мыши на хост — во всплывающем окне будет показано два последних оповещения о проблемах, найденных на этом хосте. Нажмите Open alert для оповещения о проблеме, информацию по которой необходимо получить.
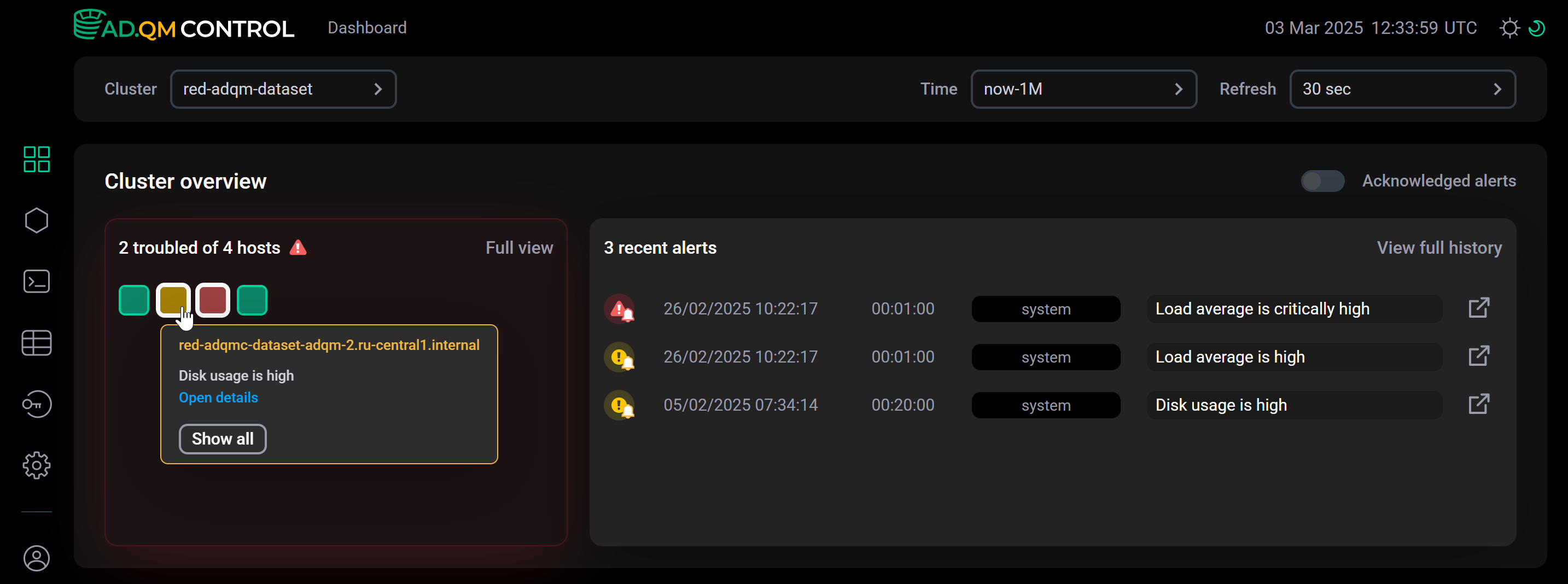 Краткая информация о проблемах, обнаруженных на хосте
Краткая информация о проблемах, обнаруженных на хосте -
В списке Recent alerts нажмите на иконку

 в строке оповещения.
в строке оповещения.
Каждое из этих действий открывает отдельную страницу с детальным описанием соответствующей проблемы. Например, в деталях оповещения Disk usage is high указывается, на каком диске превышен допустимый уровень заполнения. В поле threshold показывается пороговое значение метрики, установленное в Settings → Alerts, на основе которого было сгенерировано оповещение.
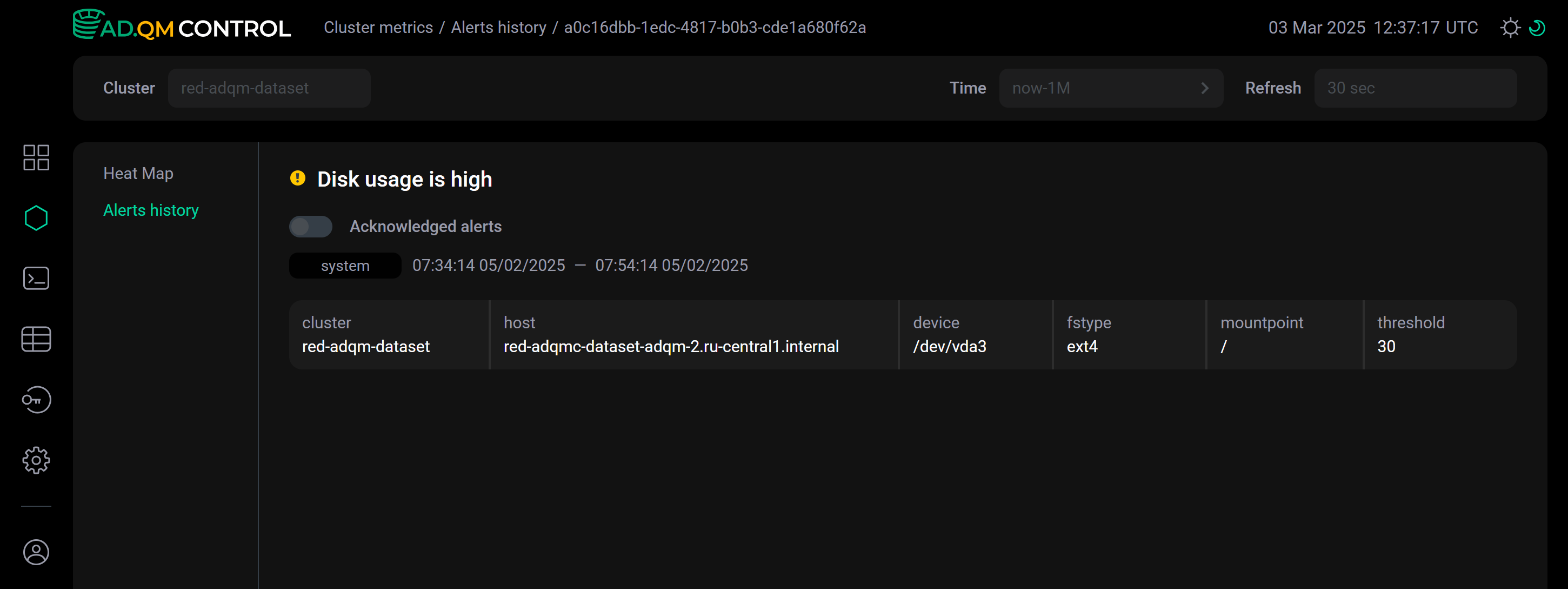
На этой странице с помощью опции Acknowledged alerts можно изменить статус оповещения — добавить соответствующую проблему в список известных/решенных (acknowledged).
Переход на страницу Cluster metrics
Из Heat map на странице Dashboard можно перейти на вкладку Heat map на странице Cluster metrics, где также показывается матрица heat map, а для выбранных хостов справа выводятся общая информация о серверах ClickHouse и таблица со списком всех оповещений (не только последних). Получить больше информации о конкретном оповещении можно кликнув по соответствующей строке в таблице — под строкой появятся детали оповещения.
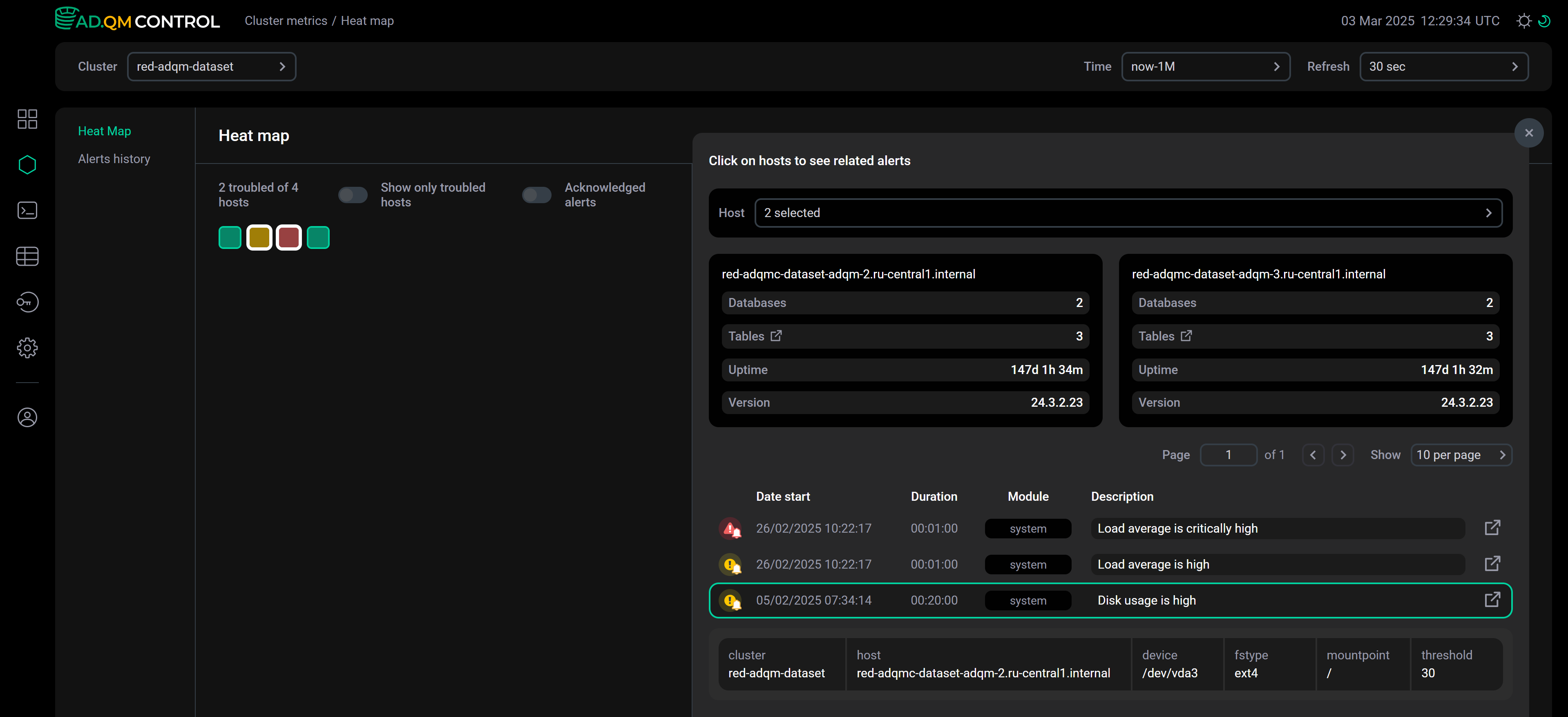
Чтобы перейти на страницу Cluster metrics → Heat map, выполните одно из действий в Heat map на странице Dashboard:
-
Нажмите Details во всплывающем окне, которое показывается при наведении курсора мыши на выбранный (по клику) хост.
-
Нажмите Full view в правом верхнем углу Heat map.
Набор выбранных хостов и настройка Acknowledged alerts синхронизируются между страницами Dashboard и Cluster metrics — при изменении настроек на одной странице соответствующие настройки автоматически изменятся на другой странице.
Top 10 tables
Секция Top 10 tables содержит две вкладки с информацией о таблицах кластера за указанный интервал времени:
-
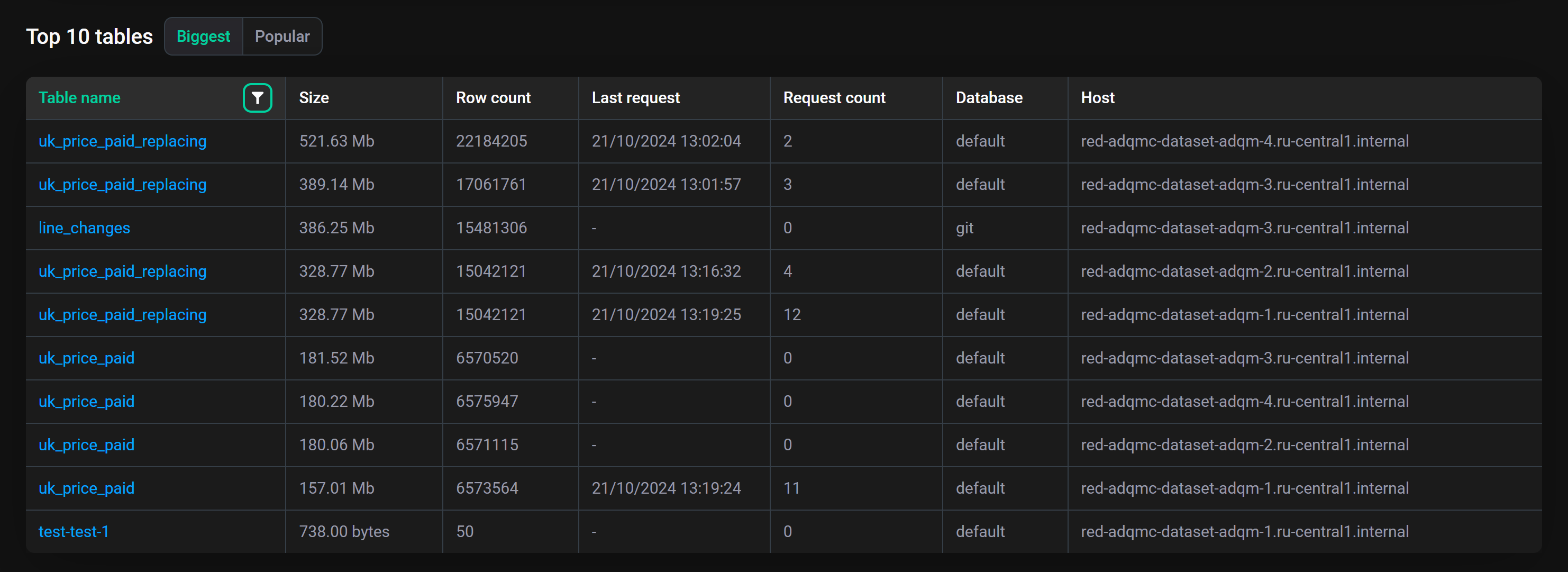
Biggest — 10 самых больших по размеру таблиц (в порядке убывания по Size — размер данных таблицы в сжатом виде в конце выбранного интервала времени).
-
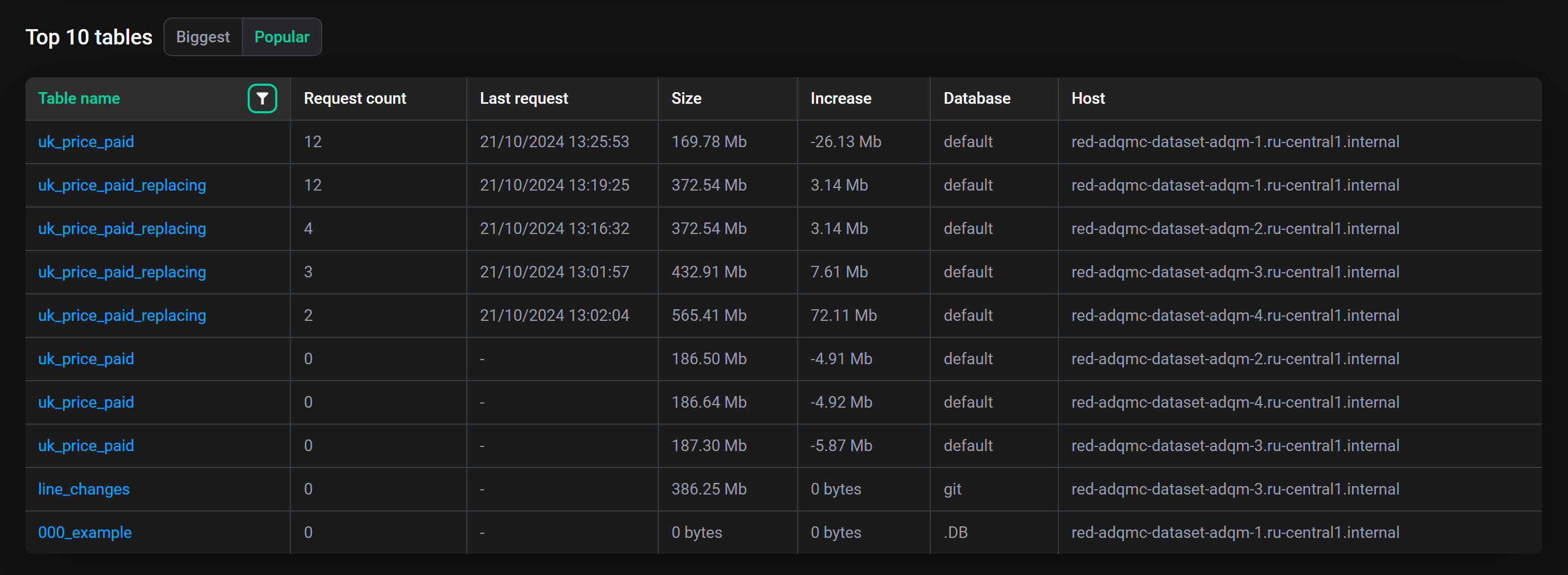
Popular — 10 таблиц, в которые было отправлено больше всего запросов (в порядке убывания по Request count — количество запросов к таблице за выбранный интервал времени).
Справа вверху расположены опции, с помощью которых можно выбрать как должны вычисляться метрики по таблицам ADQM для формирования списка Top 10 tables:
-
Separated — каждая таблица, расположенная на отдельном хосте кластера ADQM, учитывается отдельно;
-
Aggregated — метрики вычисляются для таблиц, сгруппированных по имени, имени базы данных и движку (то есть таблица, данные которой хранятся на нескольких хостах кластера ADQM, считается одной агрегированной таблицей).
В зависимости от выбранного варианта, Separated или Aggregated, для таблиц ADQM в этой секции выводится следующая информация (помимо Size и Request count):
-
Table name — название таблицы (клик по названию таблицы открывает страницу с детальной информацией по столбцам таблицы);
-
Row count (на вкладке Biggest) — количество строк данных в таблице в конце выбранного интервала времени;
-
Exist — время существования таблицы (с момента подключения кластера ADQM к ADQM Control для мониторинга);
-
Last request — время запуска последнего запроса к таблице в выбранном интервале времени;
-
Increase (на вкладке Popular) — изменение размера таблицы за выбранный интервал времени (отрицательное значение означает уменьшение объема данных в таблице);
-
Database — база данных, которой принадлежит таблица;
-
Host — хост, на котором расположена таблица (клик по иконке
открывает интерфейс ADQM Notebook или встроенный web-интерфейс ClickHouse для этого хоста в зависимости от версии ADQM — ADQM Notebook поддерживается начиная с версии 25.8.16.34).
-
Table name — название таблицы (клик по названию агрегированной таблицы открывает страницу со списком таблиц группы, с которой можно перейти к детальной информации по столбцам таблицы, расположенной на конкретном хосте);
-
Row count (на вкладке Biggest) — общее количество строк данных в таблице на всех хостах в конце выбранного интервала времени;
-
Exist — время существования таблицы (с момента подключения кластера ADQM к ADQM Control для мониторинга);
-
Last request — время запуска последнего запроса к таблице в выбранном интервале времени;
-
Increase (на вкладке Popular) — изменение общего размера таблицы за выбранный интервал времени (отрицательное значение означает уменьшение объема данных в таблице);
-
Database — база данных, которой принадлежит таблица;
-
Hosts — число хостов, на которых расположена таблица;
-
Size imbalance (на вкладке Biggest) — неравномерность распределения данных таблицы по размеру между хостами;
-
Requests imbalance (на вкладке Popular) — неравномерность распределения запросов к таблице, выполняемых на разных хостах.
В заголовке поля Table name расположена иконка ![]()
![]() , кликнув по которой можно посмотреть или изменить фильтр, определяющий среди каких таблиц ADQM выбираются самые большие или самые популярные таблицы. Доступны следующие предопределенные фильтры:
, кликнув по которой можно посмотреть или изменить фильтр, определяющий среди каких таблиц ADQM выбираются самые большие или самые популярные таблицы. Доступны следующие предопределенные фильтры:
-
Existing (фильтр по умолчанию) — выбираются топ-10 таблиц из существующих в кластере на последний момент времени указанного интервала (существующими считаются таблицы, метрики которых продолжали поступать в ADQM Control в конце временного интервала). При вычислении значений метрик агрегированных таблиц учитываются только данные таблиц, существующих в группе в конце выбранного интервала времени.
-
Historical — выбираются топ-10 таблиц из всех существовавших в кластере в указанном временном диапазоне (в том числе учитываются таблицы, которые были удалены). Значения метрик агрегированных таблиц вычисляются с учетом данных всех таблиц, существовавших в группе в течение выбранного интервала времени.
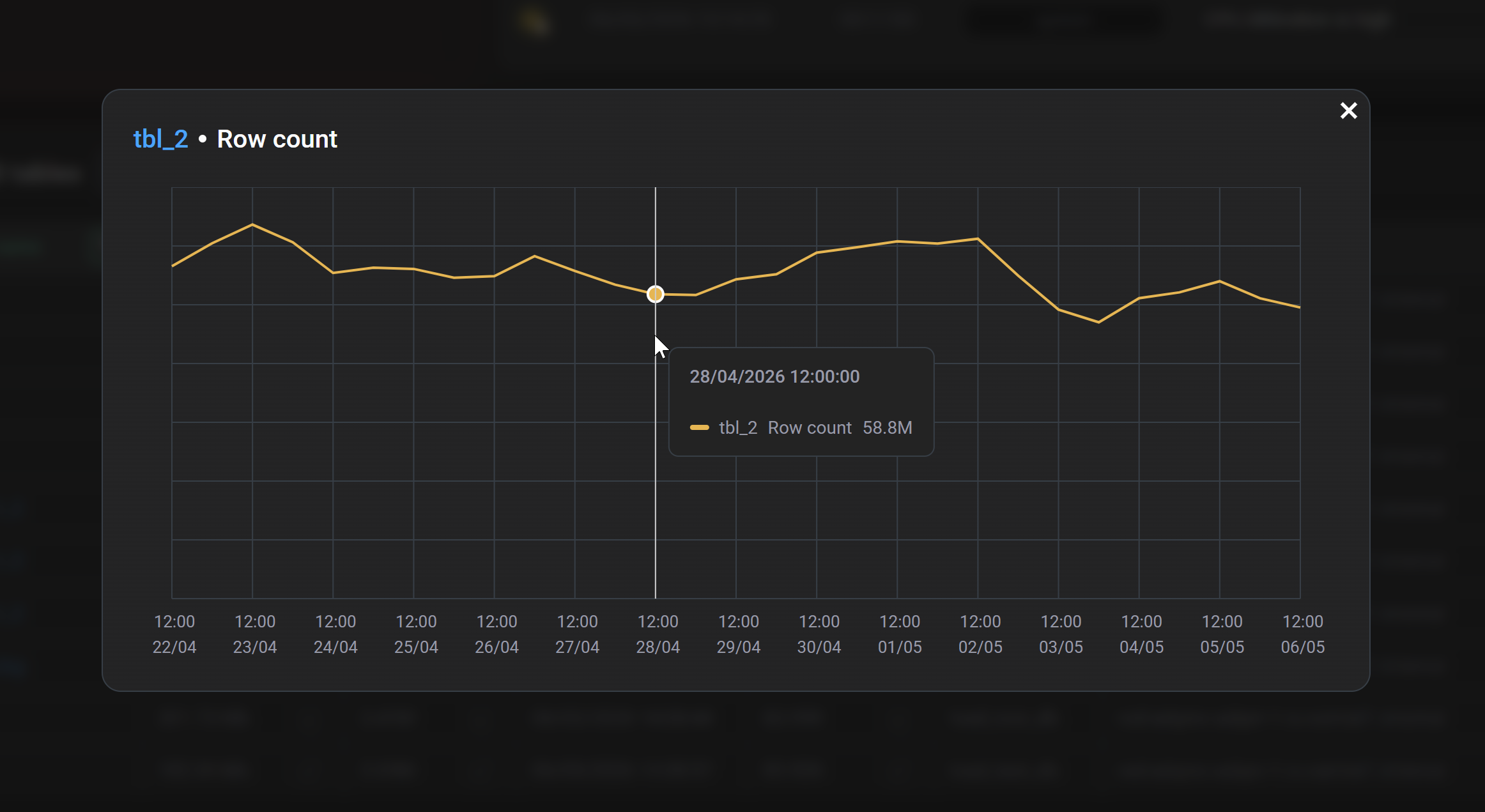
В столбцах Size, Row count, Request count, Size imbalance и Requests imbalance в каждой строке расположена иконка ![]()
![]() , клик по которой открывает модальное окно с графиком изменения соответствующей метрики таблицы ADQM. Из этого окна можно перейти на страницу с детальной информацией о таблице — для этого кликните по названию таблицы в левом верхнем углу окна.
, клик по которой открывает модальное окно с графиком изменения соответствующей метрики таблицы ADQM. Из этого окна можно перейти на страницу с детальной информацией о таблице — для этого кликните по названию таблицы в левом верхнем углу окна.
|
ПРИМЕЧАНИЕ
Посмотреть информацию по всем таблицам кластера, актуальную в указанный период времени, можно на странице Tables. |
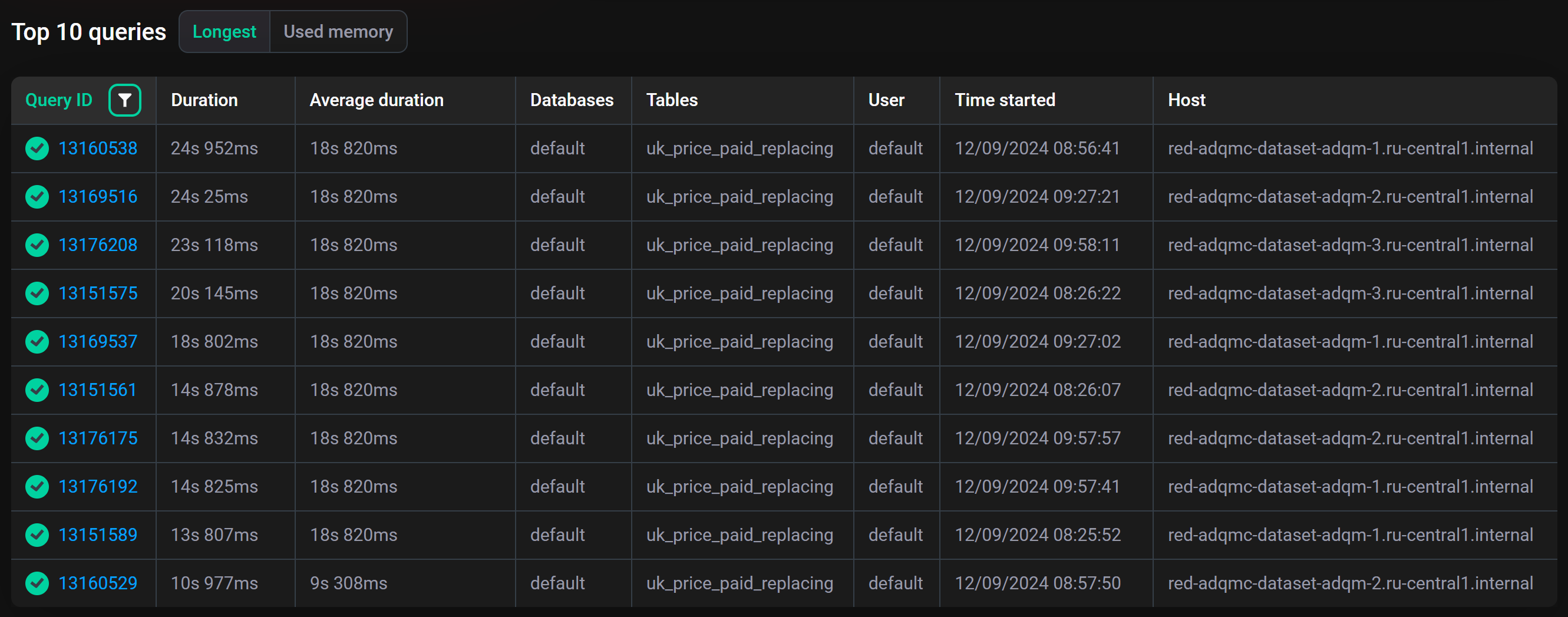
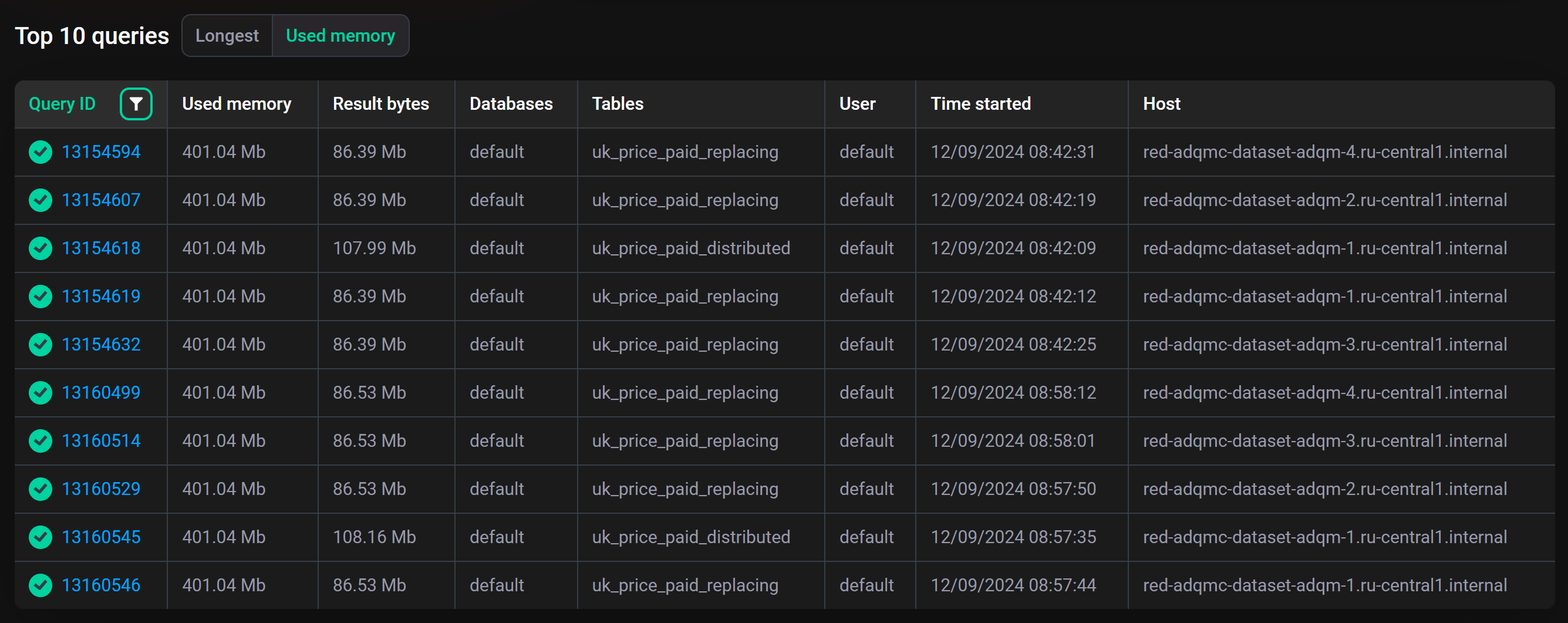
Top 10 queries
Секция Top 10 queries содержит две вкладки с информацией о запросах, направленных в базы данных кластера ADQM за указанный интервал времени:
-
Longest — 10 завершенных запросов, на обработку которых потребовалось наибольшее количество времени (в порядке убывания по Duration — длительность выполнения запроса).
-
Used memory — 10 запросов, для выполнения которых потребовалось наибольшее количество памяти (в порядке убывания по Used memory — объем используемой запросом памяти).
Для запросов также выводится следующая информация:
-
Query ID — идентификатор запроса (клик по идентификатору открывает страницу Query details, где можно посмотреть текст запроса);
-
Average duration (на вкладке Longest) — среднее время выполнения запроса (статистика считается по запросам, текст которых полностью совпадает, то есть для параметризованных запросов учитываются конкретные значения параметров);
-
Result bytes (на вкладке Used memory) — объем памяти для хранения результата запроса;
-
Databases — названия баз данных, в которые направлялся запрос;
-
Tables — названия таблиц, в которые направлялся запрос;
-
User — имя пользователя ADQM, запустившего выполнение запроса;
-
Time started — время начала выполнения запроса;
-
Host — хост, где выполнялся запрос.
В заголовке поля Query ID расположена иконка ![]()
![]() , кликнув по которой можно посмотреть или изменить фильтр, определяющий, среди каких запросов выбираются самые долгие или самые затратные по памяти запросы. Доступны следующие предопределенные фильтры:
, кликнув по которой можно посмотреть или изменить фильтр, определяющий, среди каких запросов выбираются самые долгие или самые затратные по памяти запросы. Доступны следующие предопределенные фильтры:
-
Completed (на вкладке Longest) — выбираются топ-10 самых долгих запросов из всех завершившихся (то есть из всех запросов за исключением активных);
-
All (на вкладке Used memory) — выбираются топ-10 самых затратных по памяти запросов из всех;
-
Successful (фильтр по умолчанию) — выбираются топ-10 запросов из завершившихся успешно.
|
ПРИМЕЧАНИЕ
Посмотреть всю историю запросов за нужный период времени можно на странице Queries. |