

Метрики кластера
Страница Cluster metrics web-интерфейса ADQM Control предназначена для вывода информации о состоянии кластера ADQM на основе значений метрик, собираемых с хостов кластера. Страница состоит из трех вкладок Heat map, Incidents и Alerts history, которые подробно описаны ниже.
Для отбора данных, которые должны быть показаны на странице Cluster metrics, можно использовать поля в верхней части экрана:
-
Cluster — кластер ADQM, для которого выводится информация.
-
Time — временной период, за который требуется вывести информацию. При нажатии на поле открывается окно, в котором можно выбрать интервал из предложенных вариантов на вкладке Range либо самостоятельно установить границы временного диапазона на вкладке Calendar.
-
Refresh — частота обновления данных.
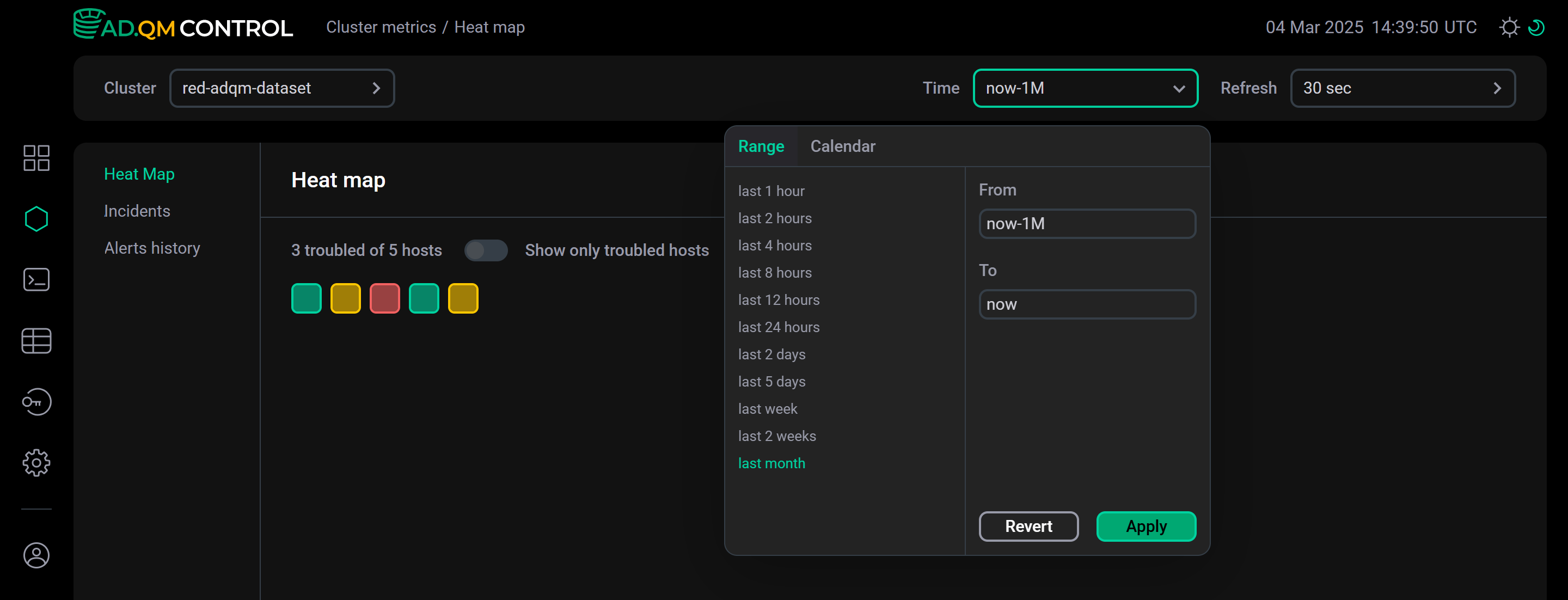
Heat map
Heat map — визуальное представление данных о состоянии всех хостов кластера ADQM, где каждый хост изображается в виде квадрата, цвет которого обозначает состояние системы.
Состояния хоста
Состояние хоста и соответствующий ему цвет в матрице Heat map определяется по наличию оповещений (alerts) о проблемах на хосте:
 — в ADQM Control нет оповещений о каких-либо проблемах на хосте (healthy host).
— в ADQM Control нет оповещений о каких-либо проблемах на хосте (healthy host).
 — на хосте обнаружены только потенциальные проблемы (например, связанные с увеличением значений каких-либо системных метрик), которые пока не являются критическими. В ADQM Control сгенерированы и остаются актуальными соответствующие сообщения об этих проблемах — оповещения среднего уровня важности (warning alerts).
— на хосте обнаружены только потенциальные проблемы (например, связанные с увеличением значений каких-либо системных метрик), которые пока не являются критическими. В ADQM Control сгенерированы и остаются актуальными соответствующие сообщения об этих проблемах — оповещения среднего уровня важности (warning alerts).
 — на хосте обнаружена как минимум одна критическая проблема, оповещение о которой есть в ADQM Control (critical alert).
— на хосте обнаружена как минимум одна критическая проблема, оповещение о которой есть в ADQM Control (critical alert).
Переключатель Show only troubled hosts в верхней части вкладки Heat map позволяет настроить heat map так, чтобы в нем показывались только проблемные хосты.
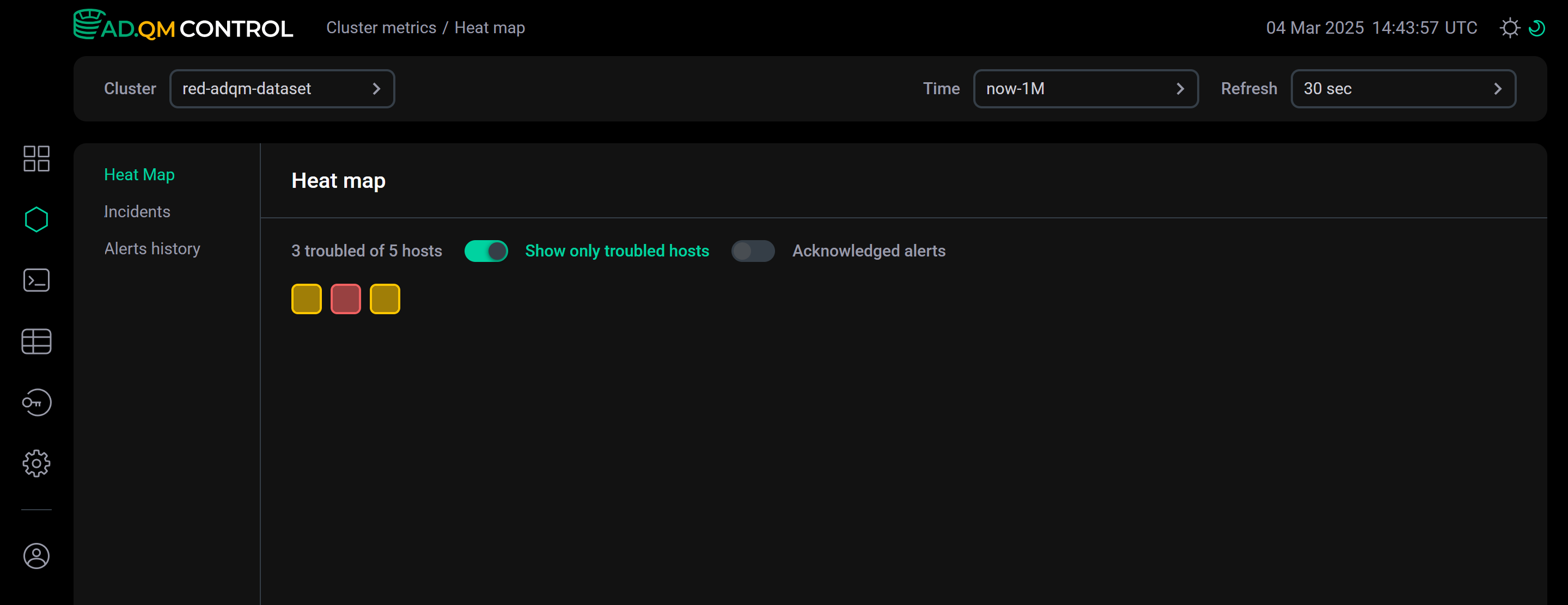
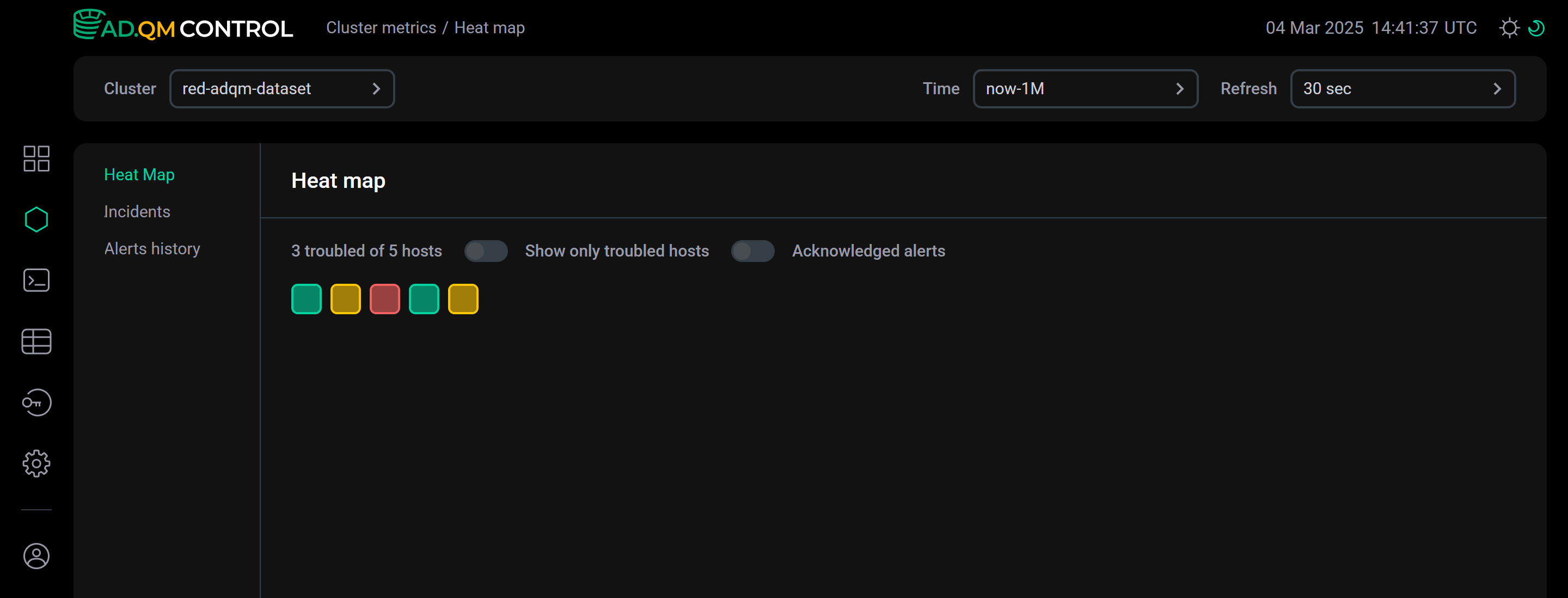
Опция Acknowledged alerts указывает какие оповещения о проблемах на хостах должны учитываться при формировании heat map кластера — все оповещения, сгенерированные за выбранный период времени, или только те, что не отмечены как известные/решенные (acknowledged). См. пример в разделе Acknowledged alerts.
Оповещения о проблемах на хосте
При выборе одного или нескольких хостов (по клику в heat map) справа показывается таблица со списком соответствующих этим хостам оповещений о проблемах, выявленных за указанный период времени. В зависимости от настройки Acknowledged alerts в список включаются все оповещения или только требующие анализа — см. Acknowledged alerts. Над таблицей находится поле Host, где можно изменить набор хостов, для которых выводятся оповещения. Здесь также показывается общая информация по каждому выбранному хосту, где установлен ClickHouse: количество баз данных, количество таблиц, время работы сервера и версия ClickHouse.
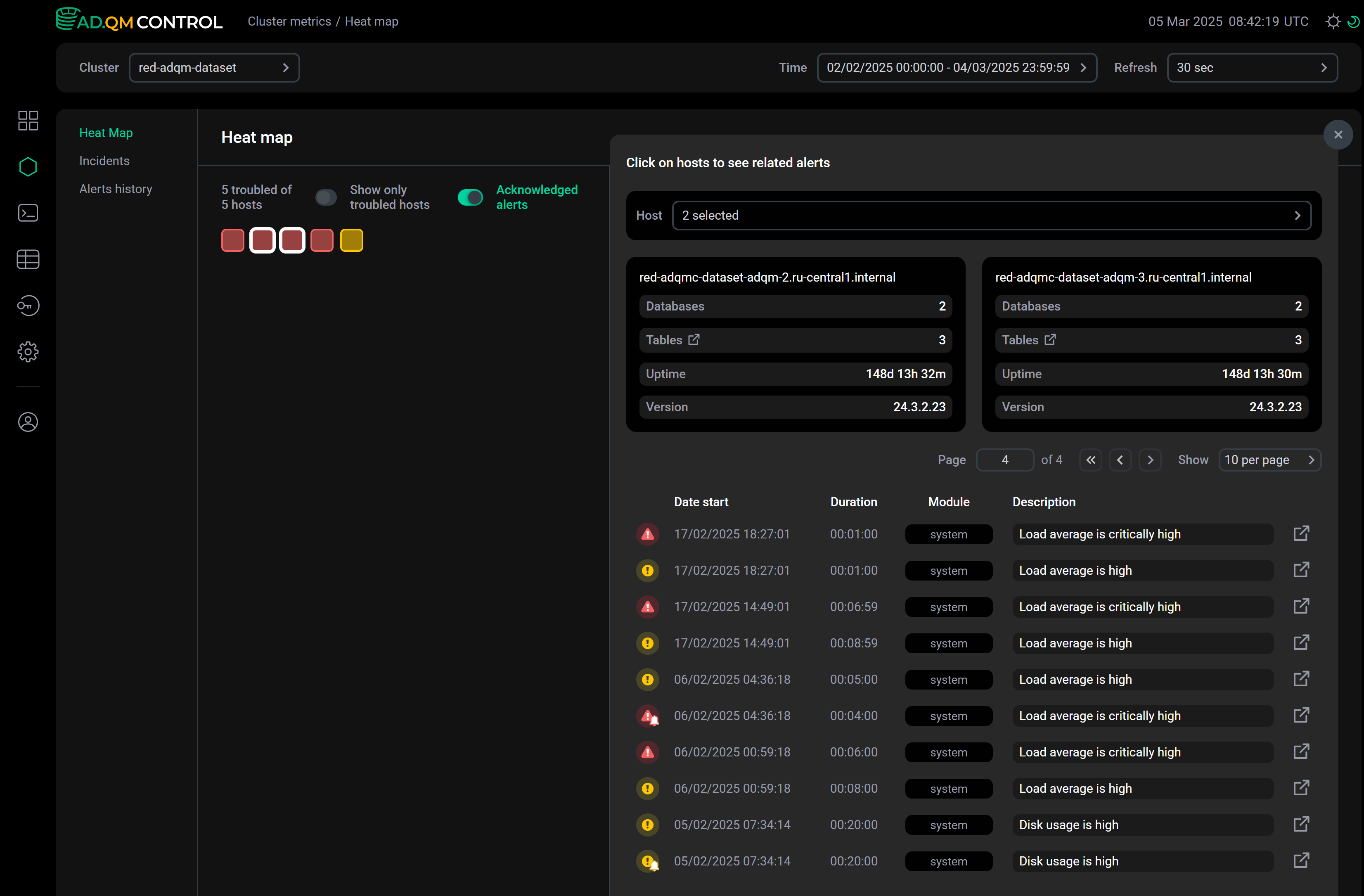
Для каждого оповещения выводится следующая информация.
| Поле | Описание |
|---|---|
Date start |
Дата и время (в формате |
Duration |
Общее время, в течение которого оповещение о проблеме на хосте оставалось актуальным |
Module |
Модуль, в состав которого входит оповещение. В настоящее время в ADQM Control генерируются только оповещения модуля |
Description |
Описание проблемы, обнаруженной на хосте |
В первом столбце таблицы со списком оповещений содержится иконка, которая обозначает уровень важности оповещения:
 ,
,  — оповещение среднего уровня важности (warning) о потенциальной проблеме, которая еще не является критической. Генерируется, если значение системной метрики на хосте превышает пороговое значение, установленное через параметр Warning в настройках System alerts.
— оповещение среднего уровня важности (warning) о потенциальной проблеме, которая еще не является критической. Генерируется, если значение системной метрики на хосте превышает пороговое значение, установленное через параметр Warning в настройках System alerts.
 ,
,  — оповещение высокого уровня важности (critical) о критической проблеме на хосте. Генерируется, если значение системной метрики превышает пороговое значение, установленное через параметр Critical в настройках System alerts.
— оповещение высокого уровня важности (critical) о критической проблеме на хосте. Генерируется, если значение системной метрики превышает пороговое значение, установленное через параметр Critical в настройках System alerts.
Иконками без значка "колокольчик" обозначаются оповещения о проблемах, которые считаются известными/решенными (acknowledged). Этот статус можно установить на странице с деталями оповещения. Иконки , назначаются новым и требующим внимания оповещениям, которые еще не отмечены как acknowledged alerts.
Чтобы получить более подробную информацию по отдельному оповещению, выполните одно из действий:
-
Кликните по строке оповещения в списке — детали оповещения появятся под строкой. В поле threshold показывается пороговое значение метрики, на основе которого было сгенерировано оповещение.
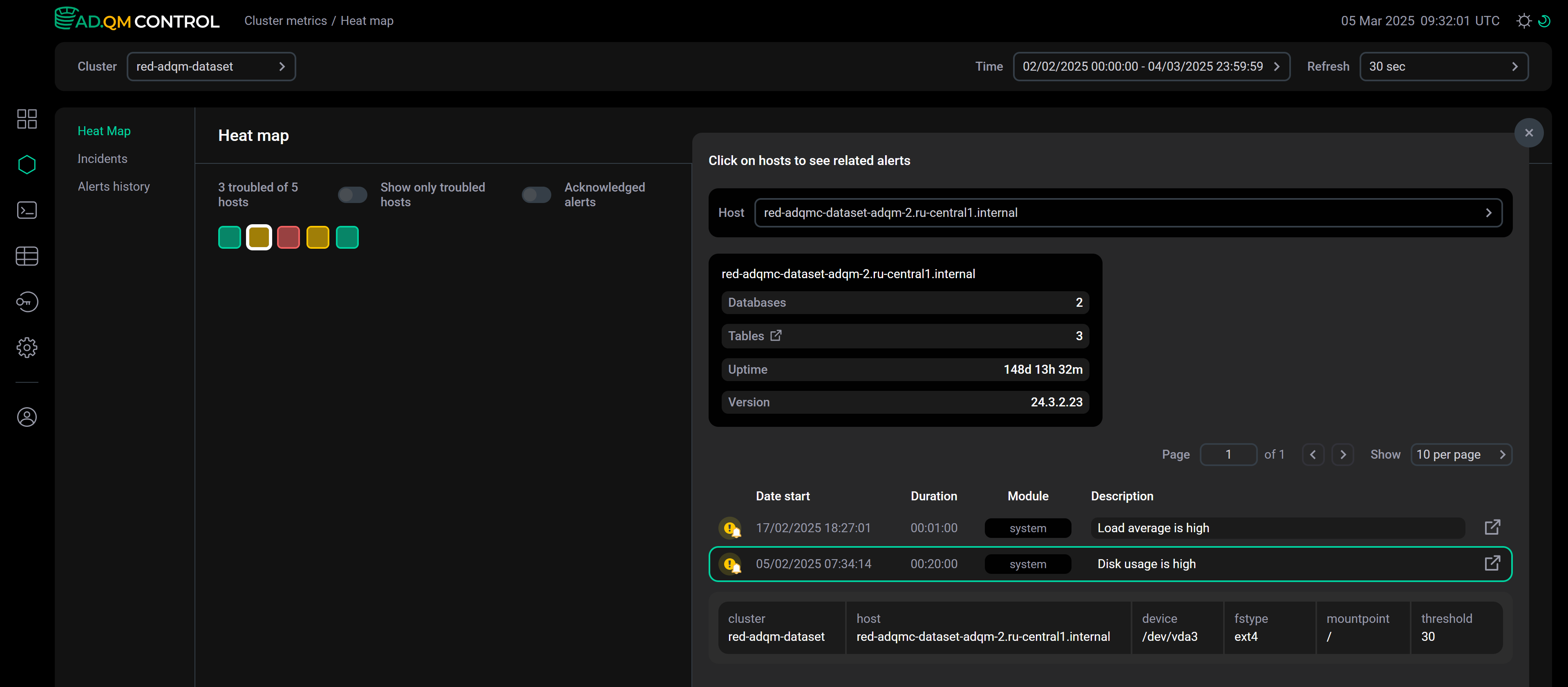 Детали оповещения в списке
Детали оповещения в списке -
Кликните по иконке

 в строке оповещения — будет выполнен переход на отдельную страницу с деталями оповещения (эта страница имеет уникальный адрес, которым можно делиться). С помощью опции Acknowledged alerts можно изменить статус оповещения — добавить соответствующую проблему в список известных/решенных (acknowledged) и не учитывать ее больше при формировании heat map кластера.
в строке оповещения — будет выполнен переход на отдельную страницу с деталями оповещения (эта страница имеет уникальный адрес, которым можно делиться). С помощью опции Acknowledged alerts можно изменить статус оповещения — добавить соответствующую проблему в список известных/решенных (acknowledged) и не учитывать ее больше при формировании heat map кластера.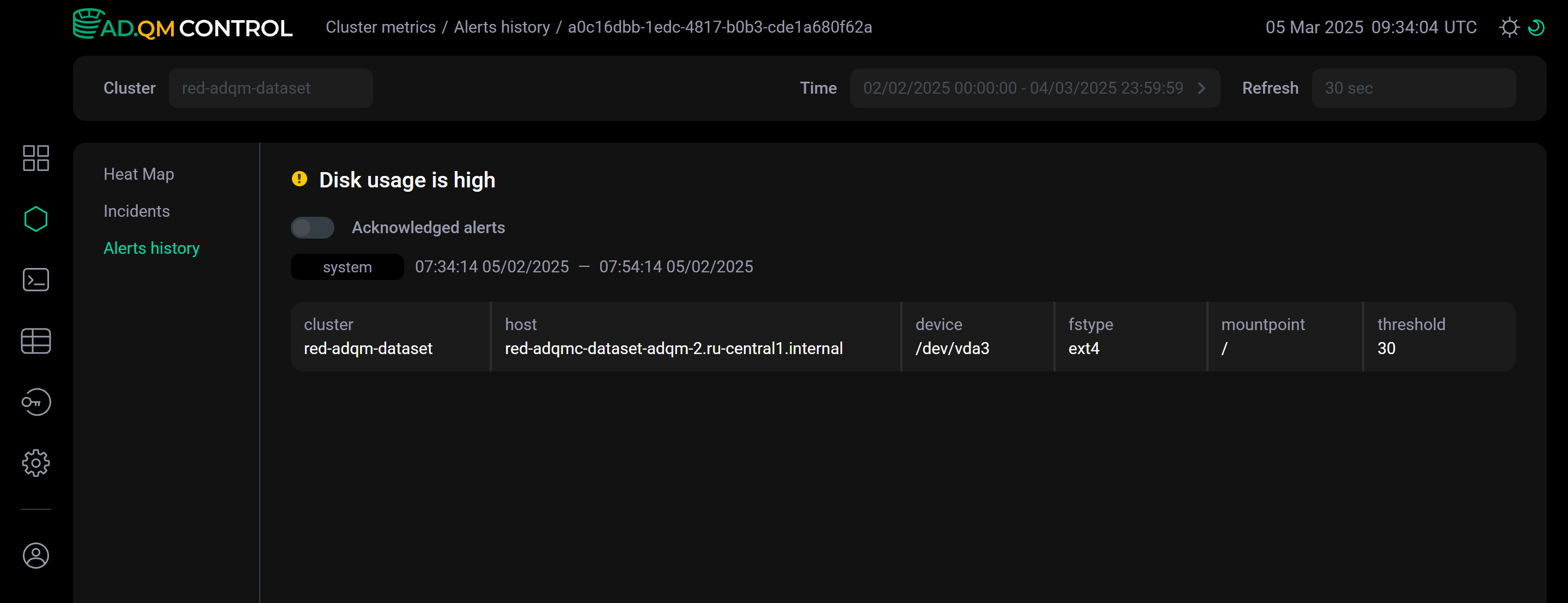 Детали оповещения на отдельной странице
Детали оповещения на отдельной странице
Incidents
На вкладке Incidents ближайшие друг к другу по времени создания оповещения о проблемах на хостах кластера, найденных в выбранный интервал времени, объединяются в группы — инциденты.
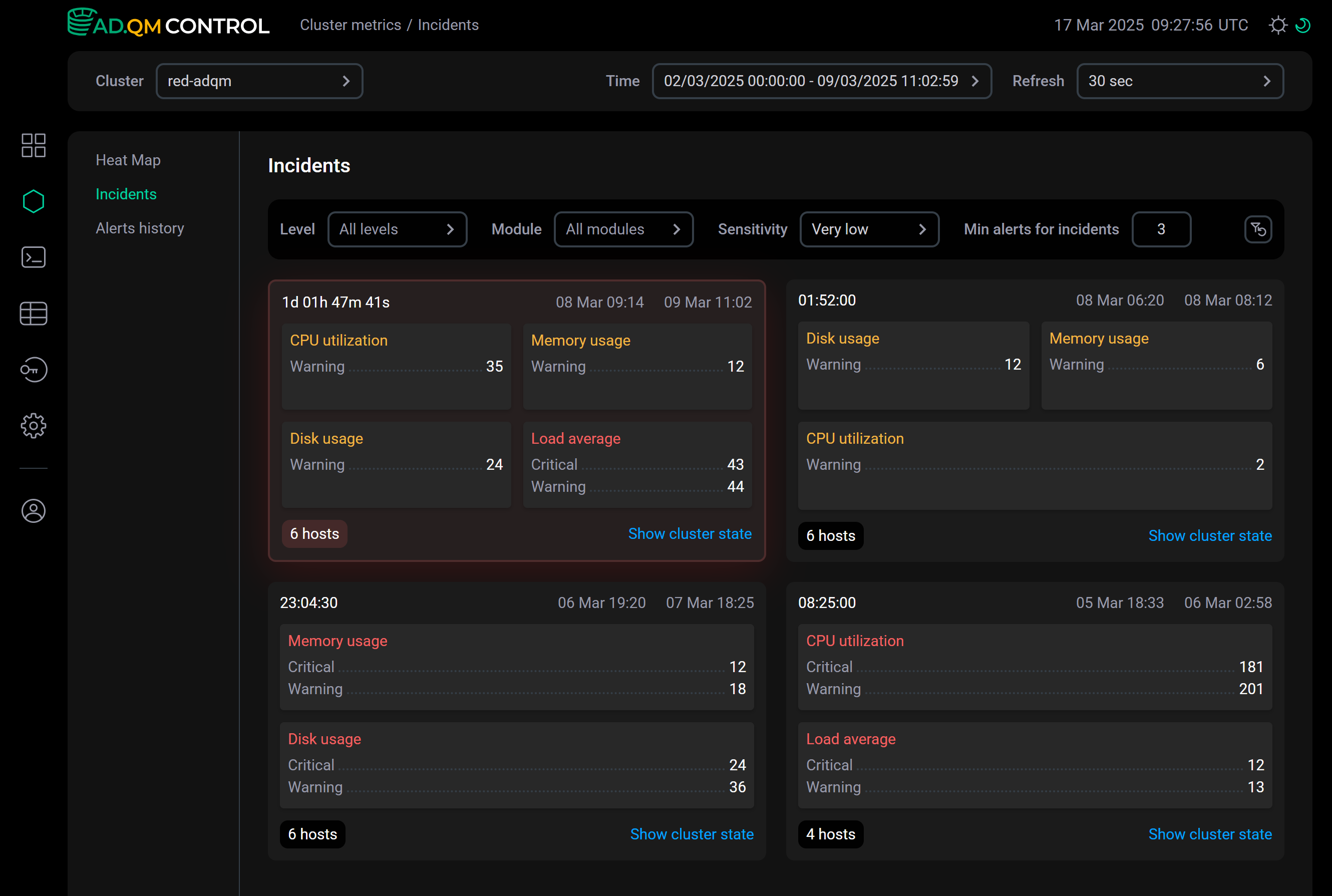
Инцидент изображается в виде блока, который включает:
-
длительность инцидента;
-
временной интервал инцидента — от времени, когда было сгенерировано первое оповещение в инциденте, до времени, когда перестало быть актуальным последнее оповещение в инциденте (связанная с метрикой проблема была решена);
-
метрики, по которым были превышены пороговые значения на хостах кластера, с информацией о том, сколько предупреждений (Warning) и оповещений высокого уровня важности (Critical) было сгенерировано;
-
количество хостов, на которых обнаружены проблемы;
-
ссылка Show cluster state — ведет на страницу Dashboard c включенной опцией Acknowledged alerts и временным окном Time, равным интервалу инцидента. При этом если интервал инцидента меньше часа, он автоматически увеличивается до 1 часа добавлением равных частей к каждой границе (так как 1 час — это минимально допустимый интервал времени, который может быть установлен в Time). На странице Dashboard можно проанализировать состояние кластера в период времени, соответствующий инциденту — например, посмотреть на каких именно хостах были проблемы; были ли в этот период слишком долгие запросы или запросы, требующие много памяти; какие таблицы были самыми большими по размеру и в какие таблицы было направлено больше всего запросов.
Блок, подсвеченный красным цветом, обозначает активный инцидент — если придет новое оповещение, оно будет добавлено в этот инцидент.
Как формируются инциденты
Чтобы сформировать инциденты, ADQM Control вычисляет временные интервалы между оповещениями и по этим данным рассчитывает межквартильный размах (Interquartile Range, IQR). Затем вычисляет пороговое значение, которое определяет минимальный временной интервал между оповещениями, при котором очередное оповещение будет добавлено в новый инцидент: , где — установленный через параметр Sensitivity уровень чувствительности.
На следующем рисунке показана последовательность формирования инцидентов и их расположение на странице.
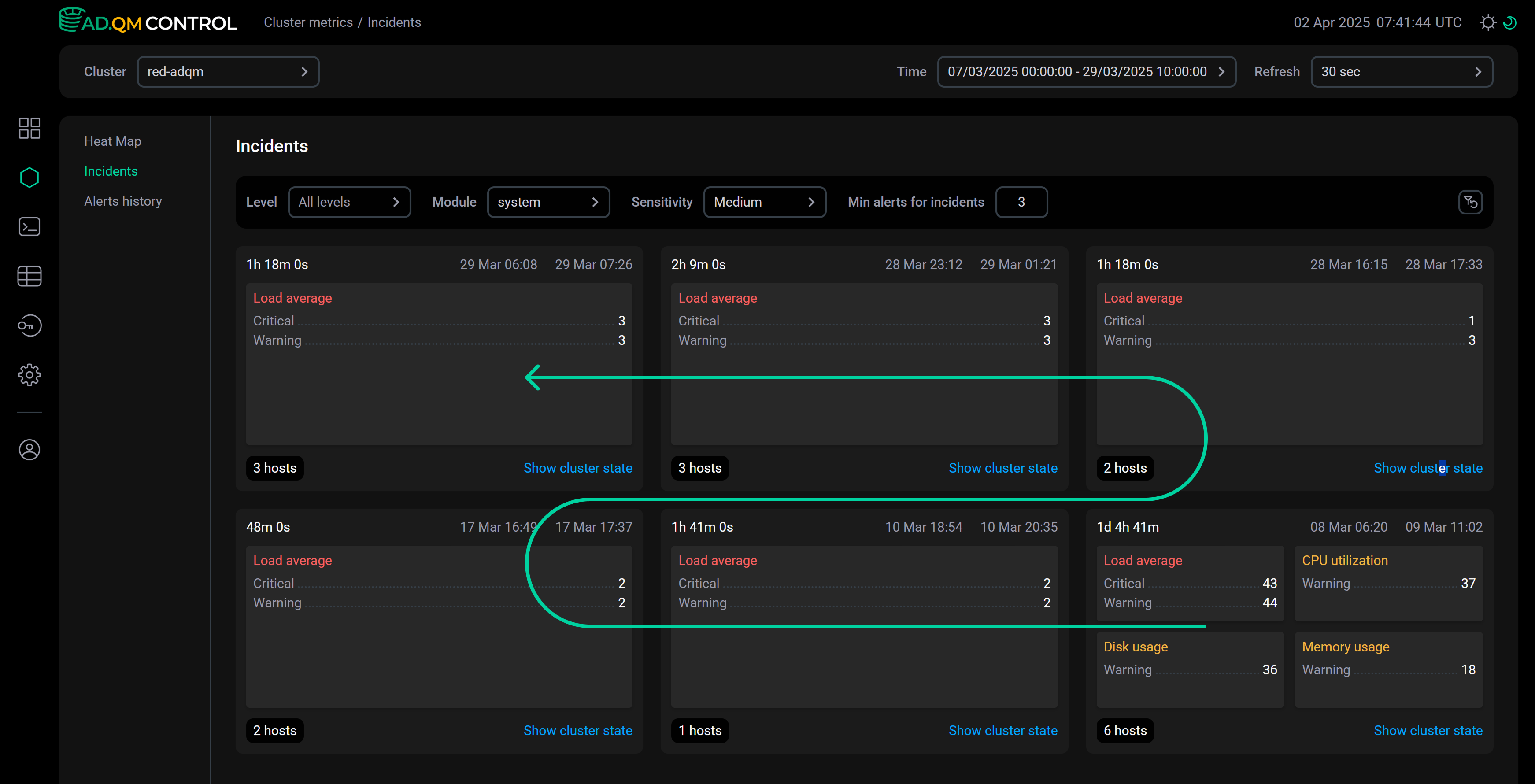
Оповещения группируются в инциденты динамически в зависимости от установленных настроек (см.раздел ниже) и временного интервала, выбранного в поле Time:
-
Для фиксированного временного интервала в прошлом структура инцидентов генерируется при открытии страницы Incidents и остается фиксированной, так как набор оповещений для этого интервала не меняется.
-
Если выбран интервал времени относительно текущего момента (например, интервал
now-12h,now-2d,now-1Mи др.), структура инцидентов на странице может меняться, так как с течением времени фактические границы интервала времени смещаются, а значит может изменяться набор действующих оповещений (могут быть получены новые оповещения, или время актуальных ранее оповещений может оказаться за пределами текущего интервала Time).
Настройки
На вкладке Incidents доступны следующие параметры, влияющие на то, по каким оповещениям строятся инциденты и как происходит объединение оповещений:
-
Level — уровень важности оповещений. Возможные значения:
warning,critical. -
Module — модуль, в состав которого входят оповещения. Возможные значения:
system,internal. -
Sensitivity — коэффициент, влияющий на то, каким должен быть промежуток времени между очередным оповещением и предыдущим, чтобы они попали в разные инциденты. Чем меньше чувствительность, тем большее время должно быть между оповещениями, чтобы поместить их в разные инциденты. Возможные значения:
Very low,Low,Medium,High,Very high.ПримерНа рисунках ниже приведены примеры распределения оповещений одного и того же временного интервала по инцидентам в зависимости от указанной чувствительности.
-
При чувствительности
Very lowвсе оповещения за выбранный период времени объединены в один инцидент.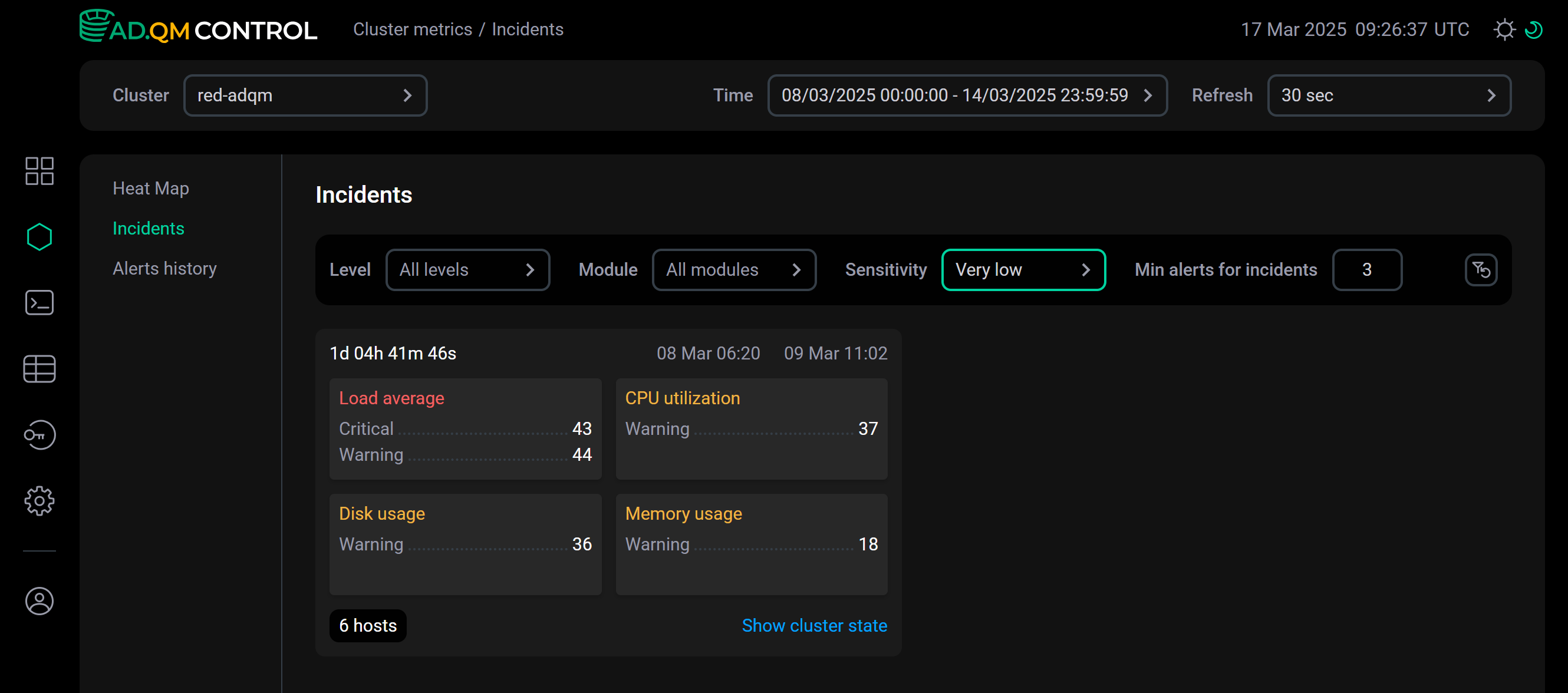 Значение параметра Sensitivity равно Very low
Значение параметра Sensitivity равно Very low -
При чувствительности
Very highоповещения за тот же период времени сгруппированы в два инцидента.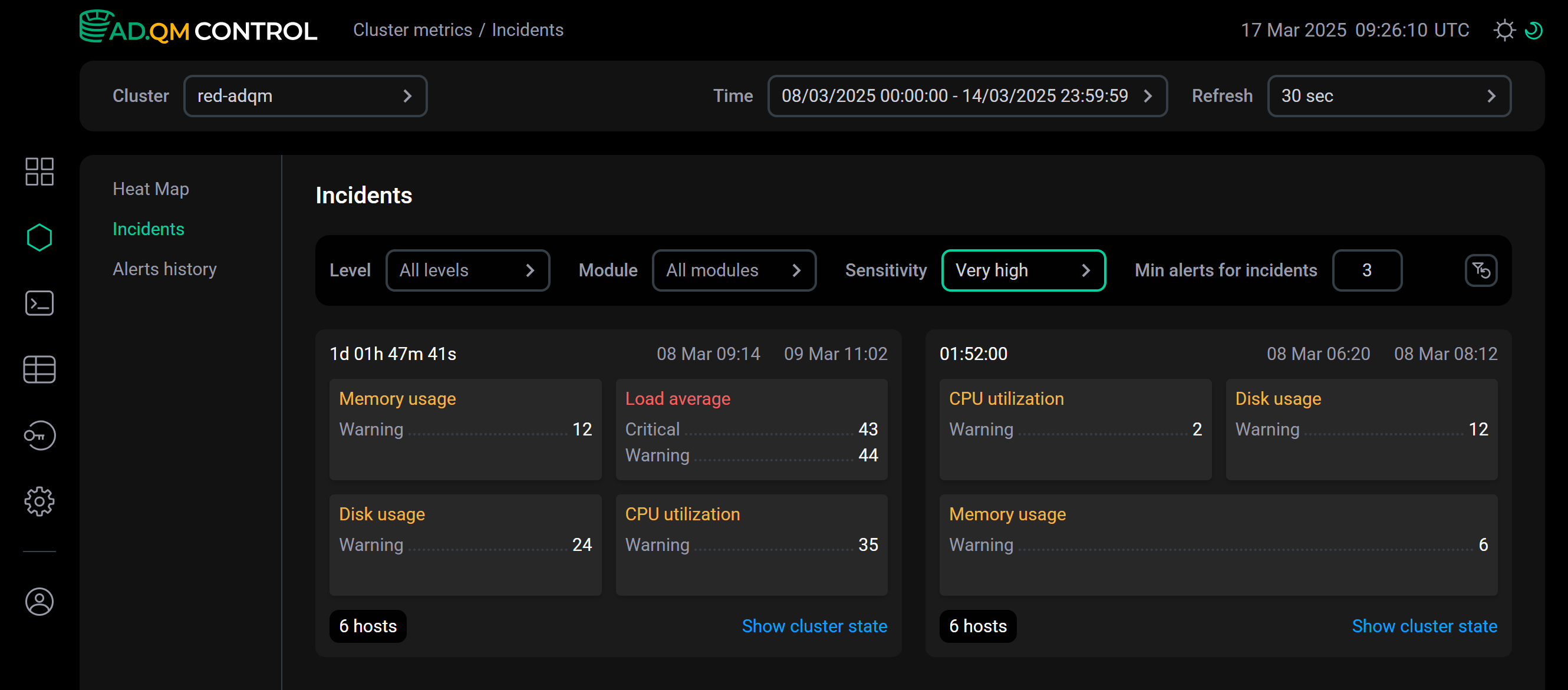 Значение параметра Sensitivity равно Very high
Значение параметра Sensitivity равно Very high
-
-
Min alerts for incidents — минимальное количество оповещений для создания инцидента.
Alerts history
На вкладке Alerts history выводится полный список оповещений, которые были сгенерированы на основе значений системных метрик на хостах кластера за указанный период времени (в поле Time верхней части экрана).
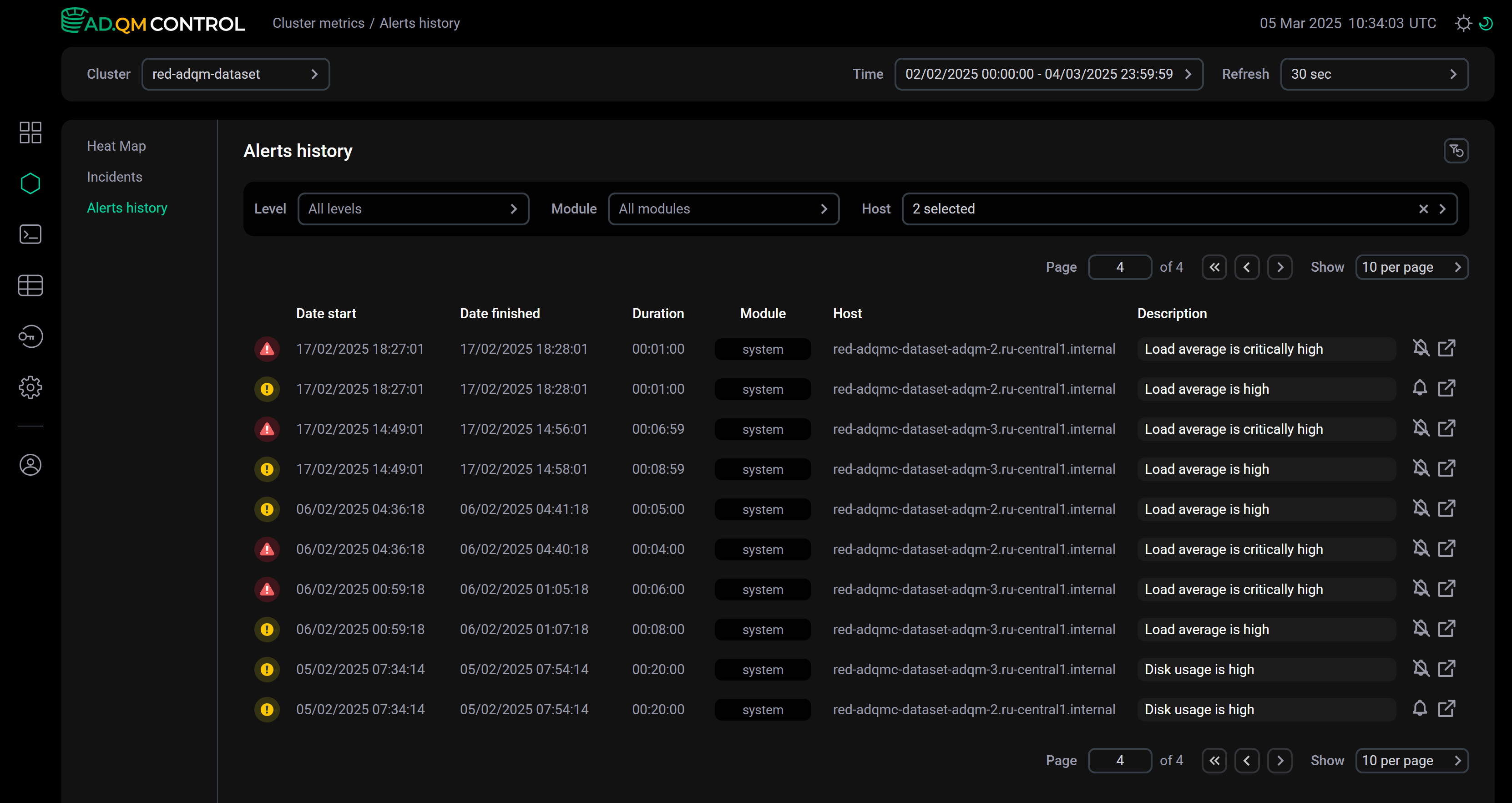
Большая часть полей в таблице со списком оповещений на вкладке Alerts history совпадает с полями, описанными выше для вкладки Heat map. Добавляются только следующие поля:
-
Date finished — дата и время (в формате
DD/MM/YYYY HH:mm:ss), когда оповещение перестало быть актуальным, то есть связанная с системной метрикой проблема была устранена на хосте. Если оповещение продолжает оставаться актуальным, в поле указывается время в будущем. -
Host — хост, на котором обнаружена проблема.
Иконка ![]()
![]() или
или ![]()
![]() служит индикатором того, требует ли проблема внимания или она отмечена как известная (acknowledged).
служит индикатором того, требует ли проблема внимания или она отмечена как известная (acknowledged).
Фильтрация оповещений
Над таблицей со списком оповещений расположены фильтры, которые можно использовать для отбора необходимых данных:
-
Level — уровень важности оповещений. Возможные значения:
-
warning— потенциальные проблемы на хостах (); -
critical— критические проблемы на хостах ().
-
-
Module — модуль, в который сгруппированы оповещения. Возможные значения:
system,internal. -
Host — хост, для которого требуется вывести оповещения о проблемах, найденных в системе. Можно выбрать несколько хостов или все хосты одновременно.
Чтобы сбросить все примененные фильтры, нажмите на иконку ![]()
![]() Reset all filters.
Reset all filters.
Детали оповещения
Как и на вкладке Heat map, есть возможность получить детальную информацию об оповещении двумя способами:
-
Кликните по строке оповещения в списке — под строкой появятся детали оповещения.
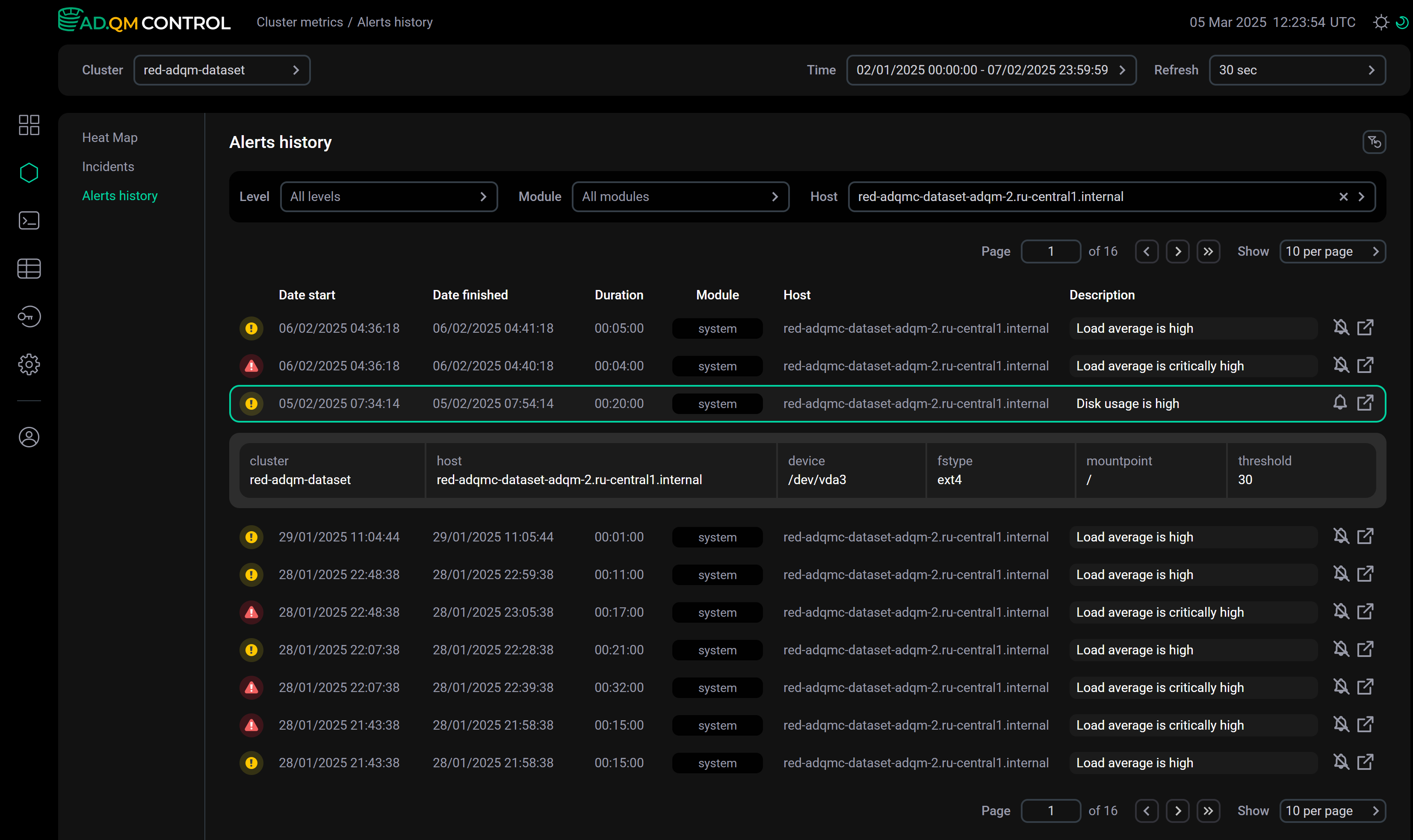 Детали оповещения в списке
Детали оповещения в списке -
Кликните по иконке
в строке оповещения — откроется отдельная страница с деталями оповещения.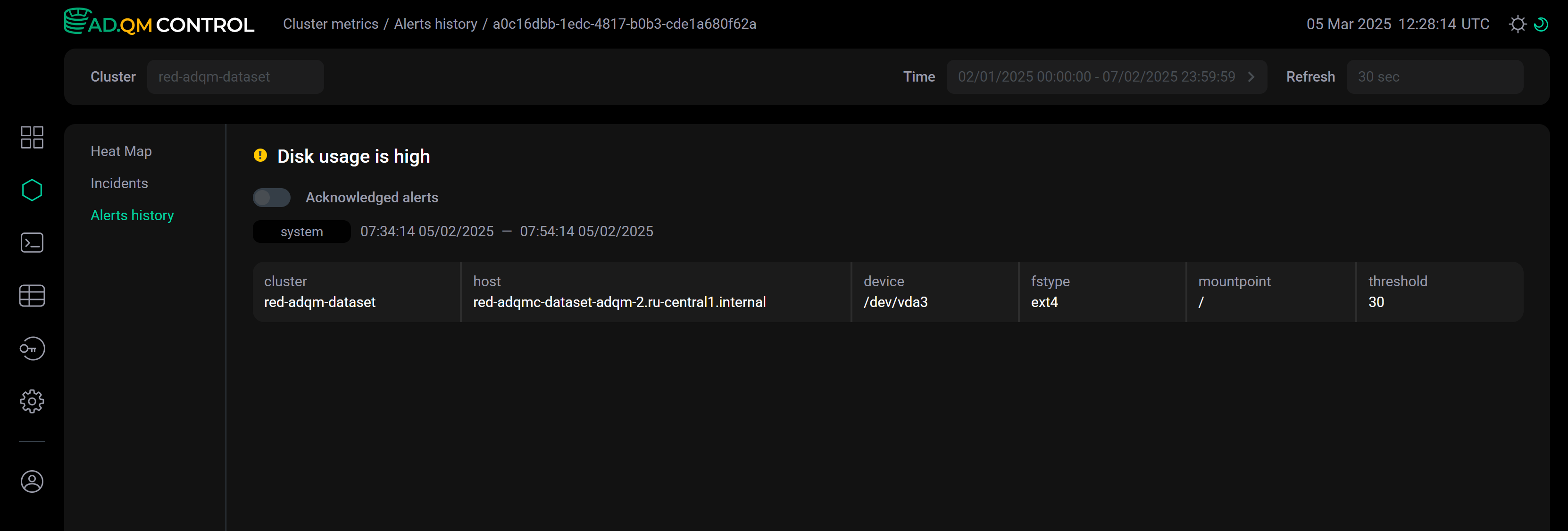 Детали оповещения на отдельной странице
Детали оповещения на отдельной странице