Общий обзор¶
Открытый веб-блокнот для интерактивной аналитики данных
Apache Zeppelin – это новый многофункциональный веб-блокнот, обеспечивающий считывание, анализ и визуализацию данных, их обмен и взаимодействие с Hadoop и Spark (Рис.2.).
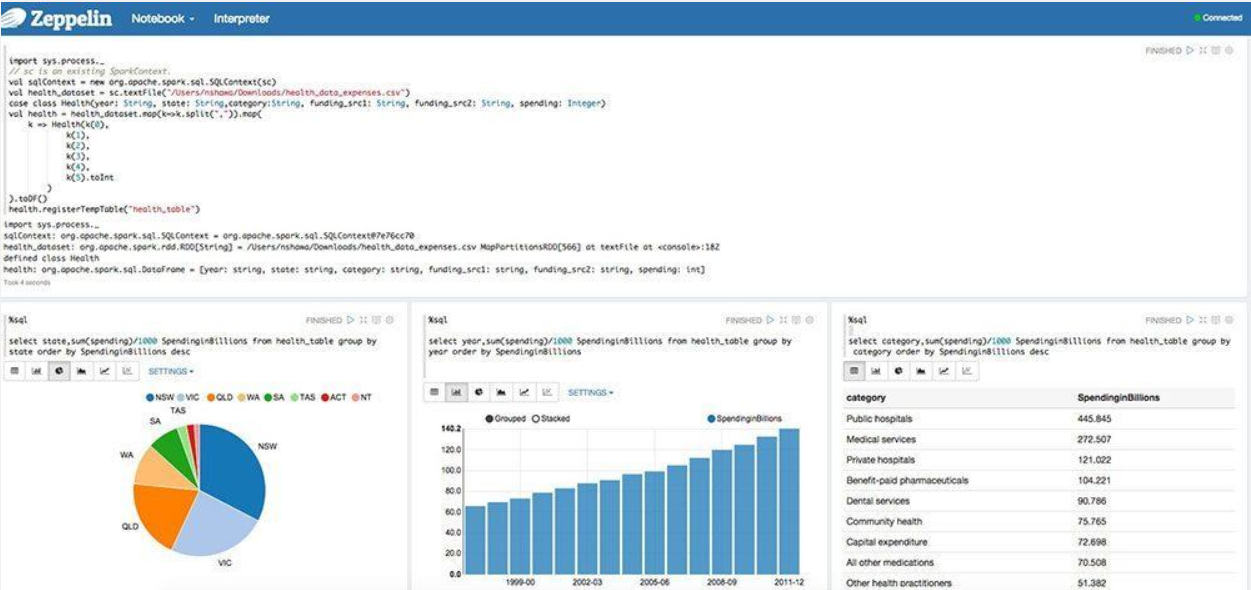
Рис. 2. Apache Zeppelin
Интерактивные браузерные блокноты позволяют инженерам данных, аналитикам и ученым в области данных более продуктивно выполнять работу, благодаря совместному использованию кода данных, его разработке, организации и выполнению, а также благодаря визуализации результатов без необходимости обращения к командной строке или к компонентам кластера. Блокноты обеспечивают пользователям не только выполнение задач, но и интерактивную работу с долго выполняющимися потоками операций.
Apache Zeppelin – это новый веб-блокнот, который предоставляет функции поиска, визуализации, совместного использования и функциональное взаимодействие с Apache Spark. В него встроена интеграция со Spark, что избавляет от необходимости создания отдельного модуля, плагина или библиотеки, и это дает следующие преимущества:
- Автоматическое создание SparkContext и sqlcontext;
- Загрузка jar-зависимостей из локальной файловой системы или репозитория maven во время выполнения задачи;
- Возможность отмены задания и отображение хода его выполнения.
Apache Zeppelin поддерживает Python, но при этом концепция интерпретатора блокнота позволяет подключать любой язык/фрейворк обработки данных в Zeppelin. В настоящее время Zeppelin поддерживает множество интерпретаторов, например, такие как Scala, Hive, SparkSQL, Shell и Markdown (Рис.3.).

Рис. 3. Интерпретаторы
Некоторые базовые диаграммы уже включены в Apache Zeppelin, но визуализация не ограничивается запросом Spark SQL и любой результат с любого языка может быть распознан и визуализирован (Рис.4.).
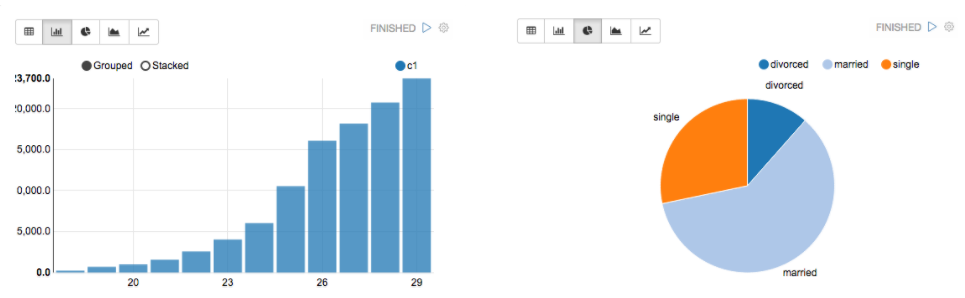
Рис. 4. Визуализация данных
Apache Zeppelin агрегирует значения и отображает их в сводной диаграмме с простым перемещением drag-and-drop. Можно легко создать диаграмму с несколькими агрегированными значениями, в том числе: сумма, количество, среднее, минимальное, максимальное (Рис.5.).
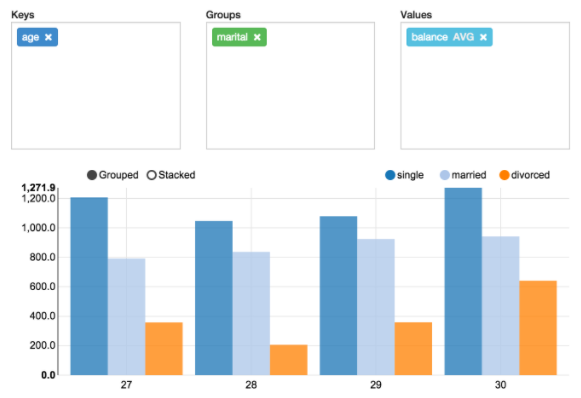
Рис. 5. Сводная диаграмма
Также Apache Zeppelin может динамически создавать некоторые формы ввода в блокноте пользователя (Рис.6.).
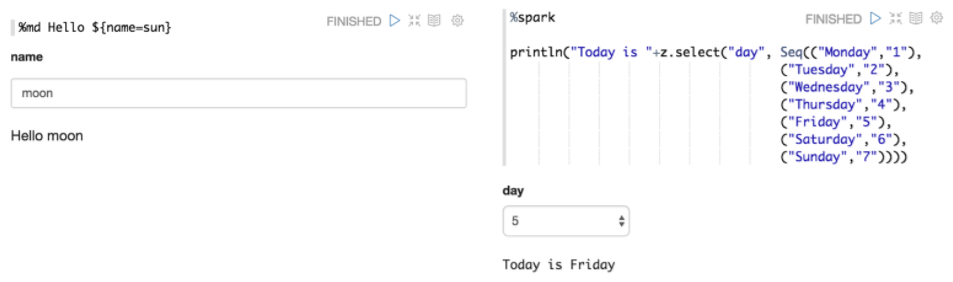
Рис. 6. Формы ввода в блокноте
Поиск данных, их анализ, отчетность и визуализация являются ключевыми компонентами рабочего процесса в области данных. Zeppelin предоставляет “Modern Data Science Studio” (“Современную научную студию данных”), которая поддерживает Spark и Hive из коробки. Фактически Zeppelin поддерживает несколько языков, которые в свою очередь имеют поддержку растущей экосистемы источников данных. Блокноты Zeppelin позволяют ученым в области данных в реальном времени создавать и выполнять небольшие фрагменты кода.
URL-адресом блокнота можно поделиться между сотрудниками. В таком случае Apache Zeppelin транслирует любые изменения в реальном времени точно так же, как при работе в Google docs. Но данный URL-адрес отображает только результат, страница не содержит никаких меню и кнопок для редактирования. Кроме того, при завершении работы с блокнотом можно создать отчет и при необходимости распечатать его или экспортировать (Рис.7.).
Рис. 7. Отчет о работе в Apache Zeppelin
В Arenadata мы считаем, что Spark и Hadoop идеально сочетаются. И что Zeppelin является ключевым компонентом для ускорения решений в области науки о данных.