

Обзор YARN high availability
ResourceManager (RM) является ключевым компонентом YARN, отвечающим за распределение ресурсов (CPU/RAM) в кластере Hyperwave, а также за планирование запуска приложений, таких как MapReduce-задачи.
Два или более RM могут работать в режиме высокой доступности (High Availability, HA), обеспечивая непрерывную работу даже в случае отказа узла кластера с активным RM. Если активный RM вдруг становится недоступен, один из резервных RM автоматически занимает его место с помощью специального алгоритма избрания.
Начиная с версии ADH 2.1.10.b1 активация HA-режима выполняется автоматически и не требует никаких специальных действий. Режим HA включается автоматически при добавлении двух или более компонентов YARN ResourceManager через интерфейс ADCM, как показано на рисунке ниже.
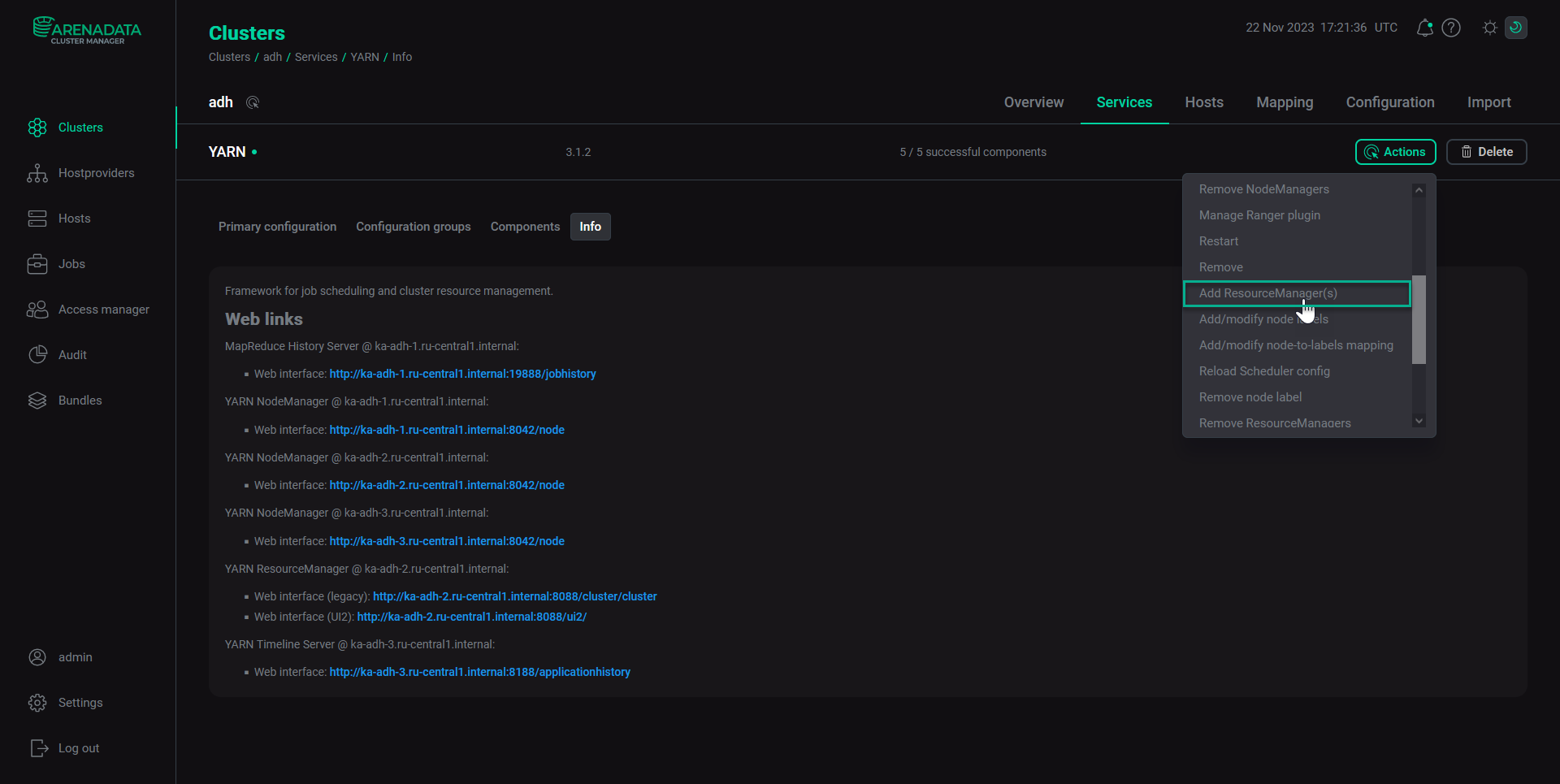
Для обеспечения HA необходимы сервисы ZooKeeper и HDFS.
Архитектура
В основе режима высокой доступности для RM лежит подход "активный-пассивный" (active-standby), то есть в любой момент времени один из RM является активным, а один или несколько других RM являются резервными. Последние находятся в режиме ожидания (standby) и готовы занять место активного RM при необходимости.


Режим автоматической отказоустойчивости
По умолчанию система автоматически переключается на резервный RM в случае сбоя активного RM. При переключении система должна убедиться, что не возникнет сценария split-brain.
Сценарий split-brain — это ситуация, когда несколько RM берут на себя роль активного RM. Такая ситуация нежелательна, поскольку несколько RM могут начать одновременно управлять узлами кластера, что приводит к несогласованности в управлении ресурсами и может стать причиной отказа кластера в целом.
Таким образом, в любой момент времени необходимо быть уверенным в том, что в кластере задействован один и только один активный RM. Для этих целей используется ZooKeeper, позволяющий координировать процесс переключения с помощью метода избрания лидера (Leader Election), который описан далее.
Выбор лидера
Для лучшего понимания процесса выбора активного RM стоит упомянуть ключевые понятия ZooKeeper.
Клиент ZooKeeper (пользователь, сервис или приложение) может создавать Znodes двух типов:
-
Эфемерный (ephemeral). Эфемерный Znode удаляется, если сессия, в которой был создан Znode, отключилась. Например, если RM1 создал эфемерный Znode с именем
eph_znode, этот Znode будет удален, если сессия взаимодействия RM1 с ZooKeeper по какой-либо причине завершится. -
Постоянный (persistent). Постоянный Znode существует в ZooKeeper до тех пор, пока не будет удален. В отличие от эфемерных Znode, постоянный Znode не зависит от существования процесса, который его создал. Например, если RM1 создает постоянный Znode, то этот Znode продолжает существовать и после завершения работы RM1. Такой Znode можно удалить только явным образом.
Более подробная информация об архитектуре и модели данных ZooKeeper доступна в разделе Архитектура ZooKeeper.
Алгоритм выбора
Допустим, имеется кластер с двумя RM (RM1 и RM2), которые претендуют на роль активного RM.
Выбор RM выполняется следующим образом: RM, который первым смог создать эфемерный Znode с именем ActiveStandbyElectorLock, получает активную роль.
Важно, что только один RM может создать Znode с именем ActiveStandby.


Если RM1 выйдет из строя, Znode ActiveStandbyElectorLock будет автоматически удален, поскольку он является эфемерным.
В таком случае резервный RM2 станет активным.


Иногда RM может отключаться на короткое время, а затем снова подключаться к ZooKeeper.
Однако ZooKeeper не может различать такие краткосрочные отключения, поэтому он удаляет эфемерные Znodes, созданные этим RM.
Это может привести к сценарию split-brain, когда оба RM действуют как активные.
Чтобы избежать этого, RM2 считывает информацию об активном RM из persistent Znode ActiveBreadCrumb, в который RM1 ранее записал информацию о себе (имя хоста и TCP-порт).
Как только RM2 понимает, что RM1 активный, он пытается изолировать RM1, создавая "ограждение" (fencing).
После этого RM2 перезаписывает данные в persistent Znode ActiveBreadCrumb, сохраняя в нем информацию о себе (имя хоста и TCP-порт RM2), поскольку RM2 теперь является активным RM.


Действия клиентов, ApplicationMaster и NodeManager при переключении RM
При наличии нескольких RM файл конфигурации yarn-site.xml, используемый клиентами и узлами, должен содержать список всех RM.
Клиенты, мастеры приложений (ApplicationMasters) и менеджеры узлов (NodeManagers) пытаются подключиться к RM, перебирая этот список по кругу, пока не обнаружат активный RM. Если используемый ими RM перестает быть активным, они проходятся далее по списку, пока не обнаружат "новый" активный RM.
Политика переключения на новый активный RM определяется с помощью одного из следующих параметров настройки:
-
Если используется режим HA, логику попыток определяет параметр
yarn.client.failover-proxy-provider, по умолчанию указывающий на классorg.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider. Эту логику можно изменить, назначив другой класс, расширяющийorg.apache.hadoop.yarn.client.RMFailoverProxyProvider. -
Если режим HA не используется, логику попыток определяет параметр
yarn.client.failover-no-ha-proxy-provider.