Интерпретаторы в Apache Zeppelin¶
- Обзор
- Интерпретатор Zeppelin
- Настройка интерпретатора
- Группа интерпретаторов
- Режим привязки интерпретатора
- Подключение к существующему удаленному интерпретатору
Обзор¶
В разделе рассказывается об интерпретаторах, их группах и настройках в Apache Zeppelin. Концепция интерпретатора Zeppelin позволяет подключать любой язык/фреймворк обработки данных. В настоящее время Zeppelin поддерживает множество интерпретаторов, таких как Scala (с Apache Spark), Python (с Apache Spark), Spark SQL, JDBC, Markdown, Shell и другие.
Интерпретатор Zeppelin¶
Интерпретатор Zeppelin – это плагин, который позволяет пользователям Apache Zeppelin использовать определенный язык/фреймворк обработки данных. Например, чтобы использовать Scala-код в Zeppelin, понадобится %spark интерпретатор.
На странице интерпретатора при нажатии кнопки “+Create” в открывшемся диалоговом окне в выпадающем списке поля “Interpreter” отображаются все доступные интерпретаторы на сервере (Рис.20.).
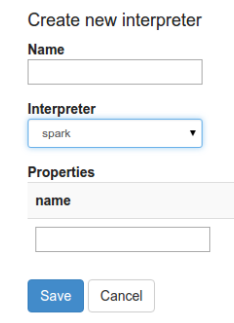
Рис. 20. Создать новый интерпретатор
Настройка интерпретатора¶
Настройка интерпретатора Zeppelin – это конфигурация данного интерпретатора на сервере Zeppelin. Например, ниже приведены свойства, необходимые для подключения интерпретатора hive JDBC к Hive серверу (Рис.21.).
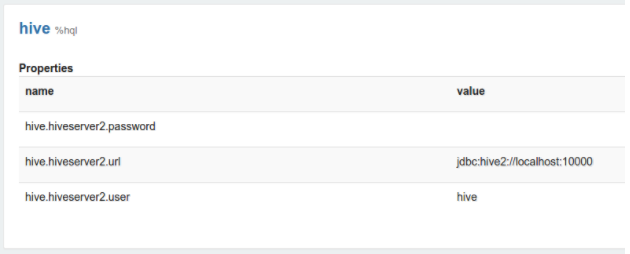
Рис. 21. Свойства интерпретатора
Для экспорта свойств в качестве переменной среды окружения необходимо, чтобы имя свойства состояло из символов верхнего регистра, цифр и подчеркивания ([A-Z_0-9]). В противном случае свойства задаются как свойство JVM.
Каждый блокнот может быть связан с несколькими конфигурациями одного интерпретатора, для этого следует использовать значок настройки в правом верхнем углу блокнота (Рис.22.).
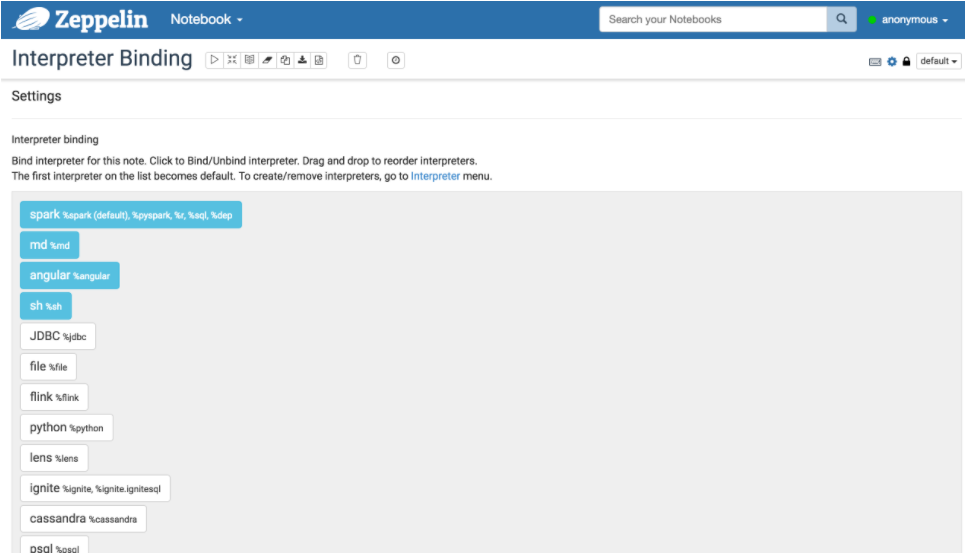
Рис. 22. Настройки интерпретатора
Группа интерпретаторов¶
Каждый интерпретатор принадлежит к группе интерпретаторов. Группа интерпретаторов (Interpreter Group) – это единый блок, позволяющий одновременно управлять (start/stop) несколькими интерпретаторами. По умолчанию каждый интерпретатор принадлежит к одной группе, но группа может содержать больше интерпретаторов. Например, группа интерпретаторов Spark включает поддержку Spark, pySpark, Spark SQL и загрузчик зависимостей %dep.
Технически, интерпретаторы Zeppelin одной группы запускаются в одной JVM. Каждый из интерпретаторов может относиться к одной группе. Все их свойства перечислены в настройках интерпретатора (Рис.23.).
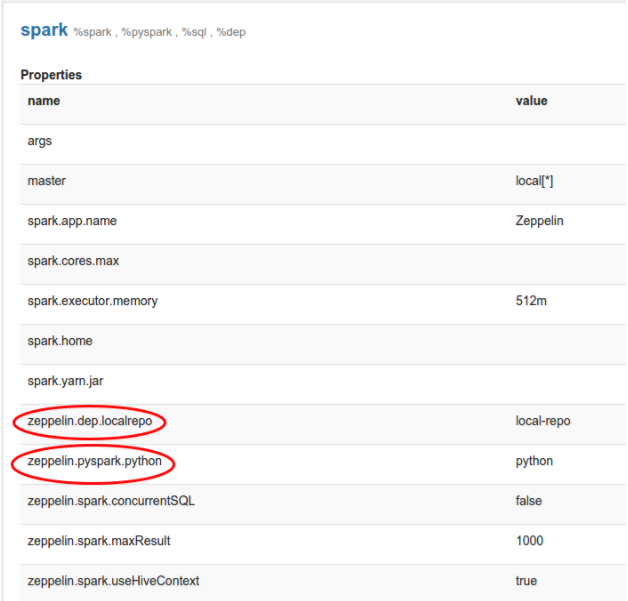
Рис. 23. Свойства групп интерпретатора
Режим привязки интерпретатора¶
Каждая конфигурация интерпретатора может быть сделана в одном из приведенных режимов привязки: “shared” – общедоступный, “scoped” – ограниченный, “isolated” – отдельный (Рис.24.). В режиме “shared” каждый блокнот, связанный с конфигурацией интерпретатора, совместно использует один экземпляр интерпретатора. В режиме “scoped” каждый блокнот создает новый экземпляр интерпретатора в том же процессе интерпретатора. В режиме “isolated” каждый блокнот создает новый процесс интерпретатора.
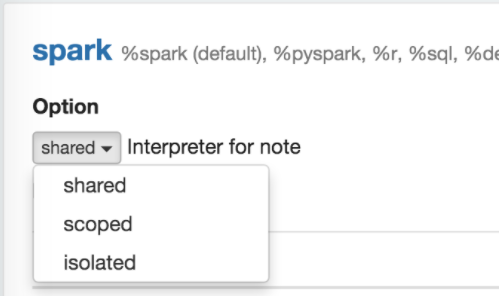
Рис. 24. Режимы привязки интерпретатора
Подключение к существующему удаленному интерпретатору¶
Существует возможность запуска потока интерпретатора пользователем Zeppelin на удаленном узле. Для этого необходимо создать экземпляр RemoteInterpreterServer и запустить его следующим образом:
RemoteInterpreterServer interpreter=new RemoteInterpreterServer(3678); // Here, 3678 is the port on which interpreter will listen. interpreter.start()
Данный код запускает поток интерпретатора внутри процесса. После запуска интерпретатора можно настроить Zeppelin для подключения к RemoteInterpreter, установив флаг “Connect to existing process” и указав узел (Host) и порт (Port), который слушает процесс интерпретатора (Рис.25.).
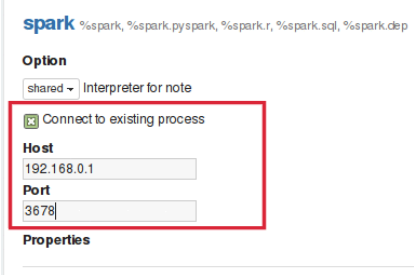
Рис. 25. Подключение к удаленному интерпретатору